
— Я расскажу, что внутри у Алисы. Алиса большая, в ней много компонент, поэтому я немного поверхностно пробегусь.
Алиса — голосовой помощник, запущенный Яндексом 10 октября 2017 года. Она есть в приложении Яндекса на iOS и Android, а также в мобильном браузере и в виде отдельного приложения под Windows. Там можно решать свои задачи, находить информацию в формате диалога, общаясь с ней текстом или голосом. И есть киллер-фича, которая сделала Алису довольно известной в рунете. Мы пользуемся не только заранее известными сценариями. Иногда, когда мы не знаем, что делать, мы используем всю мощь deep learning, чтобы сгенерировать ответ от имени Алисы. Это получается довольно забавно и позволило нам оседлать поезд хайпа.
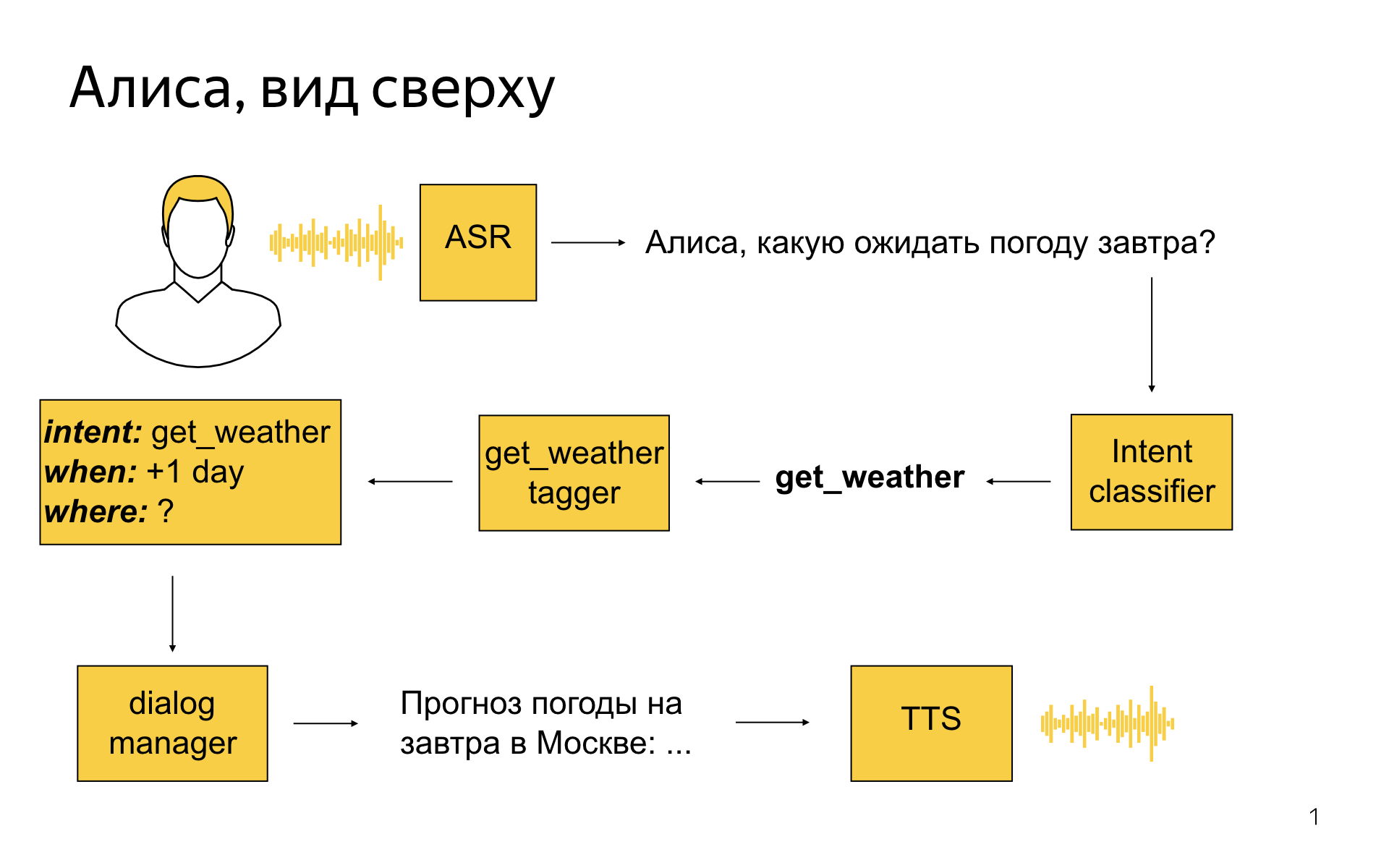
Как выглядит Алиса высокоуровнево?
Пользователь говорит: «Алиса, какую ожидать завтра погоду?»
Первым делом мы его речь стримим в сервер распознавания, он превращает ее в текст, и этот текст затем попадает в сервис, разработкой которого занимается моя команда, в такую сущность, как классификатор интентов. Это машиннообученная штука, задача которой — определить, чего же пользователь хотел сказать своей фразой. В этом примере классификатор интентов мог сказать: окей, наверное, пользователю нужна погода.
Затем для каждого интента есть специальная модель, которая называется семантический теггер. Задача модели — выделить полезные крупицы информации в том, что сказал пользователь. Теггер для погоды мог бы сказать, что завтра — это дата, на которую пользователю нужна погода. И все эти результаты разбора мы превращаем в некоторое структурированное представление, которое называется фреймом. В нем будет написано, что это интент погода, что погода нужна на +1 день от текущего дня, а где — неизвестно. Вся эта информация попадает в модуль dialog manager, который, помимо этого, знает текущий контекст диалога, знает, что происходило до этого момента. Ему на вход поступают результаты разбора реплики, и он должен принять решение, что с ними сделать. Например, он может сходить в API, узнать погоду на завтра в Москве, потому что геолокация пользователя — Москва, хоть он ее и не указал. И сказать — сгенерируйте текст, который описывает погоду, затем его отправить на модуль синтеза речи, который с пользователем поговорит прекрасным голосом Алисы.
Dialog Manager. Здесь нет никакого машинного обучения, никакого reinforcement learning, там только конфиги, скрипты и правила. Это работает предсказуемо, и понятно, как это поменять, если нужно. Если менеджер приходит и говорит, поменяйте, то мы можем это сделать в короткие сроки.
В основе концепции Dialog Manager лежит концепция, известная тем, кто занимается диалоговыми системами, как form-filling. Идея в том, что пользователь своими репликами как бы заполняет некую виртуальную форму, и когда он в ней заполнит все обязательные поля, его потребность можно удовлетворить. Движок event-driven: каждый раз, когда пользователь что-то делает, происходят какие-то события, на которые можно подписываться, писать их обработчики на Python и таким образом конструировать логику диалога.
Когда нужно в сценариях сгенерировать фразу — например, мы знаем, что пользователь говорит про погоду и нужно ответить про погоду, — у нас есть мощный язык шаблонов, который позволяет нам эти фразы писать. Вот так это выглядит.

Это надстройка над питонячьим шаблонизатором Jinja2, в которую добавили всякие лингвистические средства, например возможности склонять слова или согласовывать числительные и существительные, чтобы можно было легко когерентный текст писать, рандомизировать кусочки текста, чтобы увеличивать вариативность речи Алисы.

В классификаторе интентов мы успели попробовать множество разных моделей, начиная от логистической регрессии и заканчивая градиентным бустингом, рекуррентными сетями. В итоге остановились на классификаторе, который основан на ближайших соседях, потому что он обладает кучей хороших свойств, которых у других моделей нет.
Например, вам часто надо иметь дело с интентами, для которых у вас есть буквально несколько примеров. Просто учить обычные классификаторы мультиклассовые в таком режиме невозможно. Например, у вас оказывается, что во всех примерах, которых всего пять, была частица «а» или «как», которой не было в других примерах, и классификатор находит самое простое решение. Он решает, что если встречается слово «как», то это точно этот интент. Но это не то, чего вы хотите. Вы хотите семантической близости того, что сказал пользователь, к фразам, которые лежат в трейне для этого интента.
В итоге мы предобучаем метрику на большой датасете, которая говорит о том, насколько семантически близки две фразы, и потом уже пользуемся этой метрикой, ищем ближайших соседей в нашем трейнсете.
Еще хорошее качество этой модели, что ее можно быстро обновлять. У вас появились новые фразы, вы хотите посмотреть, как изменится поведение Алисы. Все, что нужно, это добавить их множество потенциальных примеров для классификатора ближайших соседей, вам не нужно переподбирать всю модель. Допустим, для нашей рекуррентной модели это занимало несколько часов. Не очень удобно ждать несколько часов, когда вы что-то меняете, чтобы увидеть результат.

Семантический теггер. Мы пробовали conditional random fields и рекуррентные сети. Сети, конечно, работают намного лучше, это ни для кого не секрет. У нас там нет уникальных архитектур, обычные двунаправленные LSTM с attention, плюс-минус state-of-the-art для задачи тегирования. Все так делают и мы так делаем.
Единственное, мы активно пользуемся N-best гипотез, мы не генерируем только самую вероятную гипотезу, потому что иногда нам нужна не самая вероятная. Например, мы перевзвешиваем зачастую гипотезы в зависимости от текущего состояния диалога в dialog manager.
Если мы знаем, что на предыдущем шаге мы задали вопрос про что-то, и есть гипотеза, где теггер что-то нашел и гипотеза, где не нашел, то наверное, при прочих равных первое более вероятно. Такие трюки нам позволяют немного улучшить качество.
А еще машиннообученный теггер иногда ошибается, и не совсем точно в самой правдоподобной гипотезе находят значение слотов. В этом случае мы ищем в N-best гипотезу, которая лучше согласуется с тем, что мы знаем о типах слотов, это позволяет тоже еще немного качество заработать.
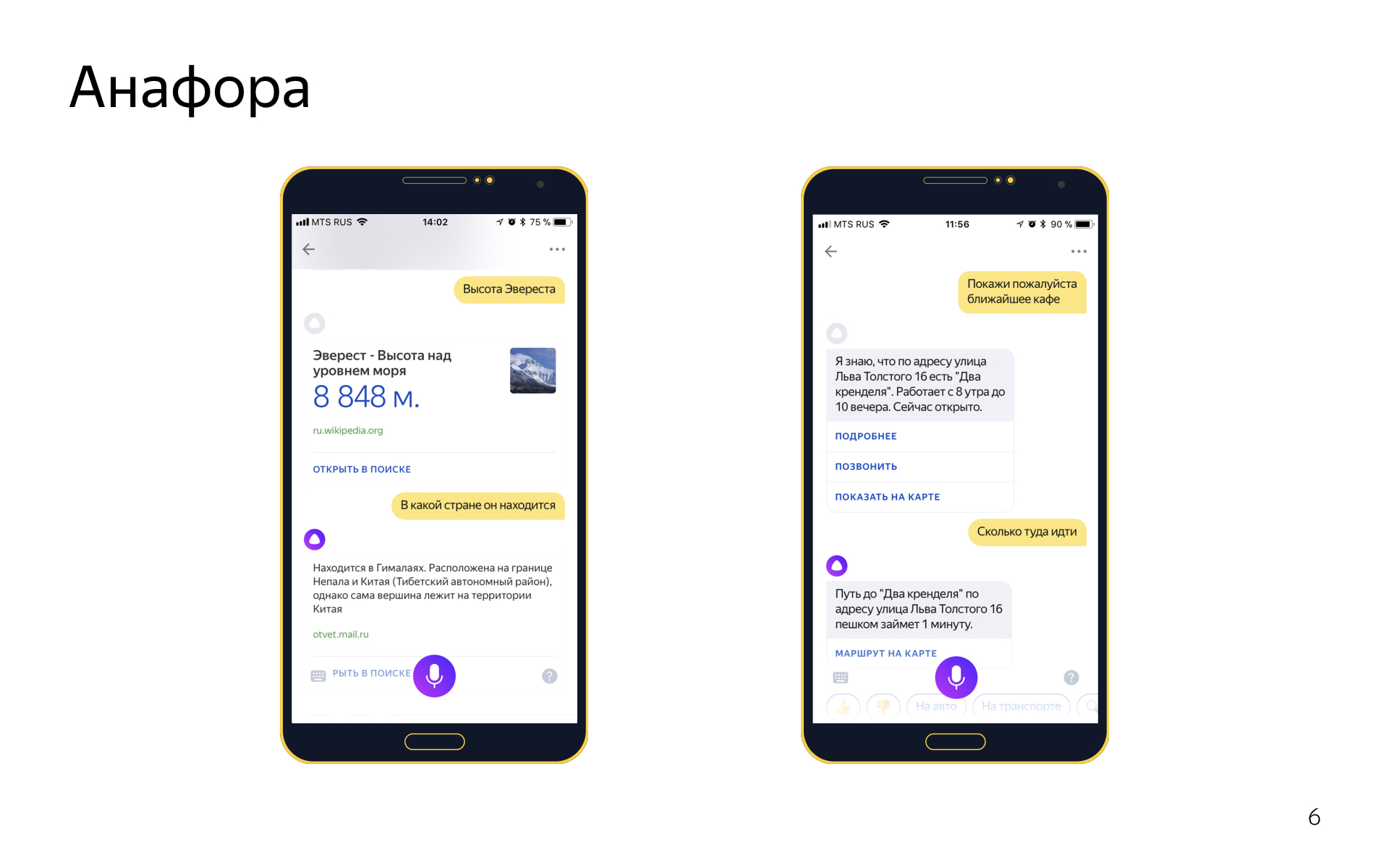
Еще в диалогах есть такое явление Анафора. Это когда вы с помощью местоимения ссылаетесь на какой-то объект, который был раньше в диалоге. Скажем, говорите «высота Эвереста», и потом «в какой стране он находится». Мы анафоры умеем разрешать. Для этого у нас две системы.

Одна general-purpose система, которая может работать на любых репликах. Она работает поверх синтаксического разбора всех пользовательских репликах. Если мы видим местоимение в его текущей реплике, мы ищем known phrases в том, что он сказал раньше, считаем для каждой из них скорость, смотрим, можно ли ее подставить вместо этого местоимения, и выбираем лучшую, если можем.
А еще у нас есть система разрешения анафор, основанная на form filling, она работает примерно так: если в предыдущем интенте в форме был геообъект, и в текущем есть слот для геообъекта, и он не заполнен, и еще мы в текущий интент попали по фразе с местоимением «туда», то наверное, можно предыдущий геообъект импортировать из формы и подставить сюда. Это простая эвристика, но производит неплохое впечатление и круто работает. В части интентов работает одна система, а в части обе. Мы смотрим, где работает, где не работает, гибко это настраиваем.
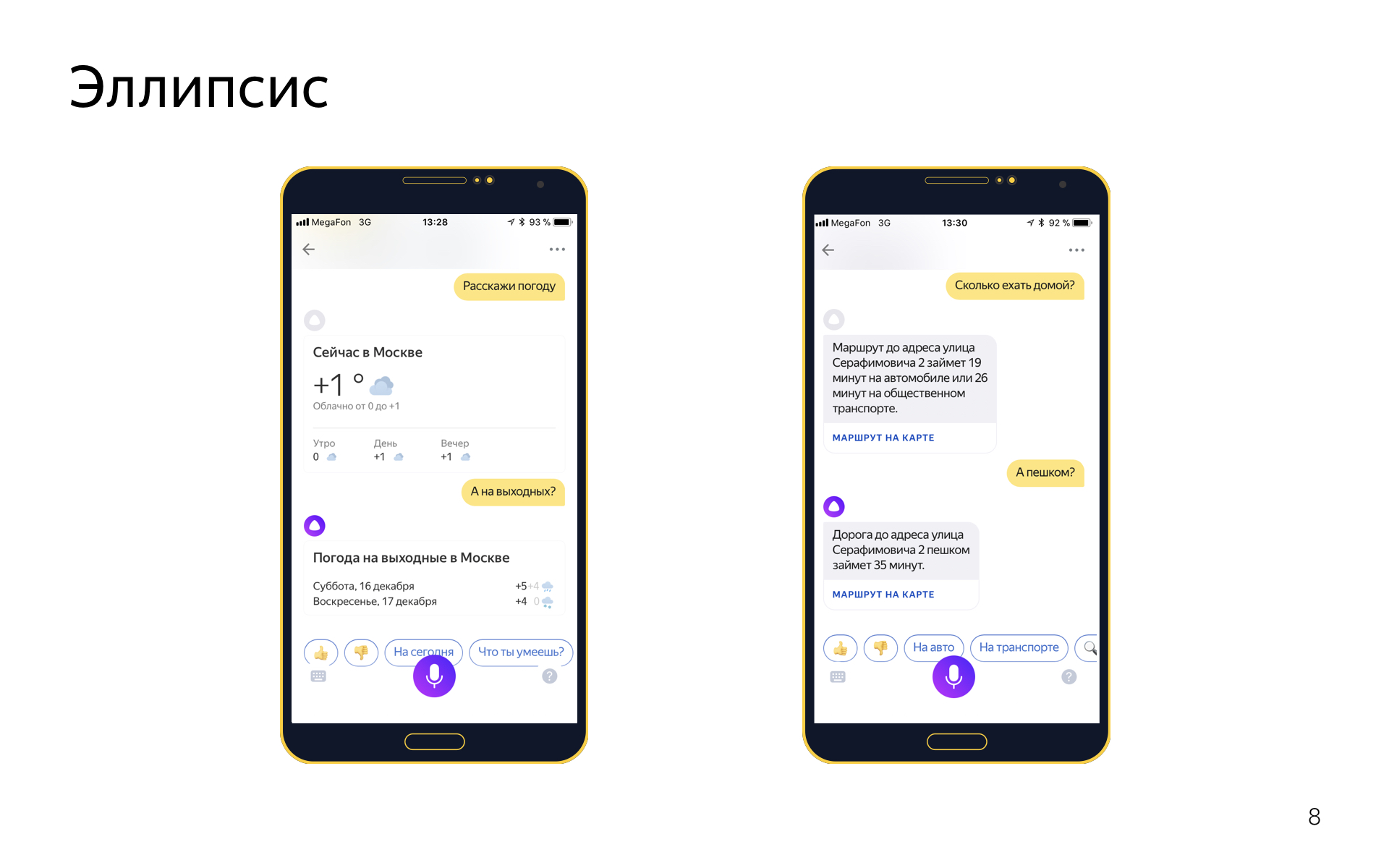
Есть эллипсис. Это когда в диалоге вы опускаете какие-то слова, потому что они подразумеваются из контекста. Например, вы можете сказать «расскажи погоду», а потом «а на выходных?», имея в виду «расскажи погоду на выходных», но вы хотите повторять эти слова, потому что это ни к чему.
С эллипсисами мы тоже умеем работать примерно следующим образом. Эллиптические фразы или фразы-уточнения — это отдельные интенты.

Если есть интент get_weather, для которого в трейне фразы типа «расскажи погоду», «какая сегодня погода», то у него будет парный интент get_weather_ellipsis, в котором всевозможные уточнения погоды: «а на завтра», «а на выходные», «а что там в Сочи» и так далее. И эти эллиптические интенты в классификаторе интентов на равных конкурируют со своими родителями. Если вы скажете «а в Москве?», классификатор интентов, например, скажет, что с вероятностью 0,5 это уточнение в интенте погода, и с вероятностью 0,5 уточнение в интенте поиска организаций, например. И затем диалоговый движок перевзвешивается scores, которые назначил классификатор интентов, который назначил их с учетом текущего диалога, потому что он, например, знает, что до этого шел разговор о погоде, и вряд ли это было уточнение про поиск организаций, скорее это про погоду.
Такой подход позволяет обучаться и определять эллипсисы без контекста. Вы можете просто откуда-то набрать примеров эллиптических фраз без того, что было раньше. Это довольно удобно, когда вы делаете новые интенты, которых нет в логах вашего сервиса. Можно или фантазировать, или чего-то придумывать, или пытаться на краудсорсинговой платформе собрать длинные диалоги. А можно легко насинтезировать для первой итерации таких эллиптических фраз, они будут как-то работать, и потом уже собирать логи.

Вот жемчужина нашей коллекции, мы называем ее болталкой. Это та самая нейросеть, которая в любой непонятной ситуации чего-то от имени Алисы отвечает и позволяет вести с ней зачастую странные и часто забавные диалоги.

Болталка — на самом деле fallback. В Алисе это работает так, что если классификатор интентов не может уверенно определить, чего хочет пользователь, то другой бинарный классификатор сперва пытается решить — может, это поисковый запрос и мы найдем что-то полезное в поиске и туда отправим? Если классификатор говорит, что нет, это не поисковый запрос, а просто болтовня, то срабатывает fallback на болталку. Болталка — система, которая получает текущий контекст диалога, и ее задача — сгенерировать максимально уместный ответ. Причем сценарные диалоги тоже могут являться частью контекста: если вы говорили про погоду, а потом сказали что-то непонятное, сработает болталка.

Это позволяет нам делать вот такие штуки. Вы спросили про погоду, а потом болталка ее как-то прокомментировала. Когда работает, выглядит очень круто.
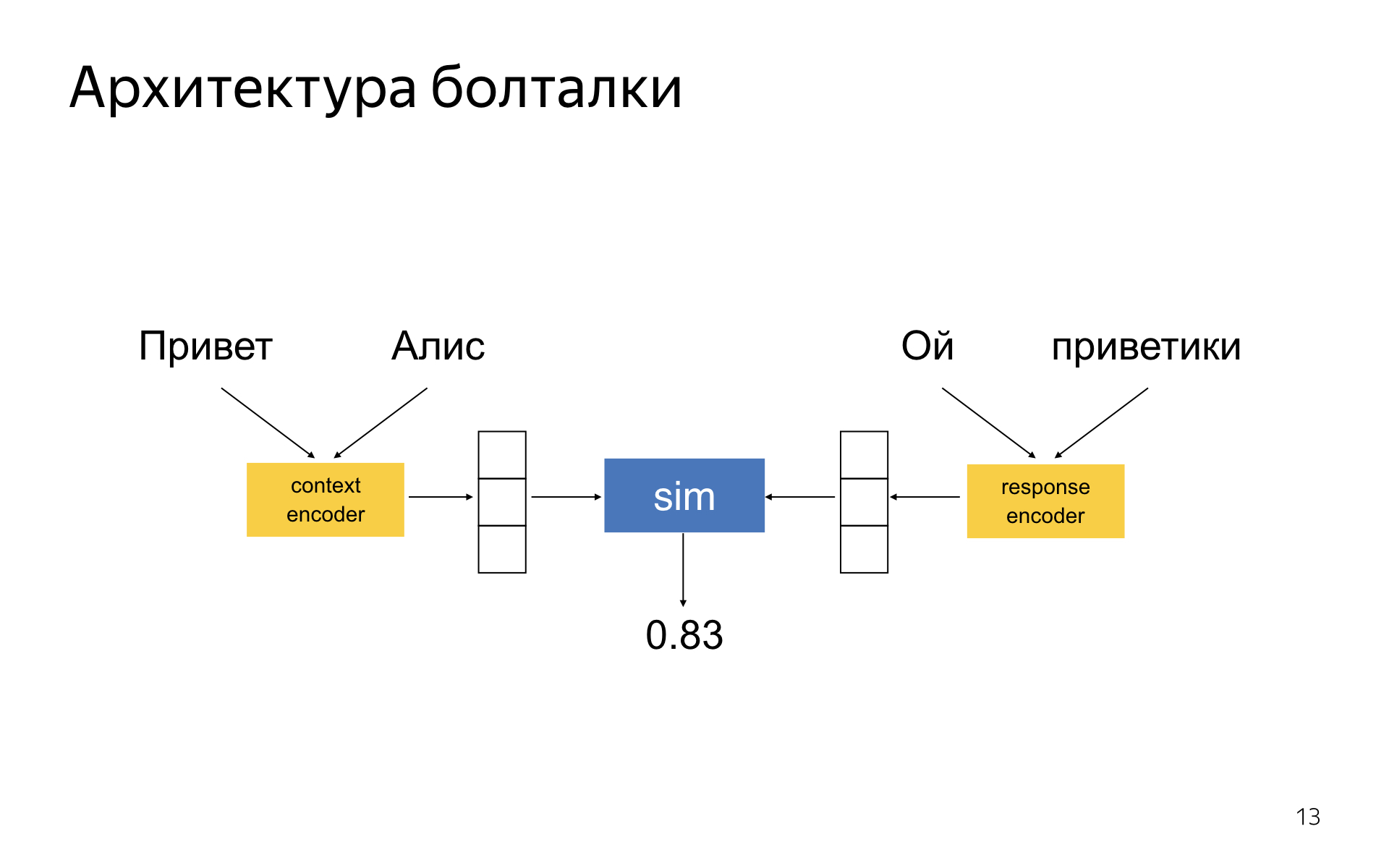
Болталка — DSSM-подобная нейронная сеть, где есть две башни энкодера. Один энкодер кодирует текущий контекст диалога, другой — ответ-кандидат. У вас получается два embedding-вектора для ответа и контекста, и сеть обучается так, чтобы косинусное расстояние между ними было тем больше, чем уместнее данный ответ в контексте и чем неуместнее. В литературе эта идея давно известна.

Почему у нас вроде неплохо все работает — кажется, что чуть лучше, чем в статьях?
Никакой серебряной пули нет. Нет техники, которая позволит внезапно сделать классно разговаривающую нейронную сеть. Нам удалось достичь неплохого качества, потому что мы в качестве понемножку выиграли везде. Мы долго подбирали архитектуры этих башен-энкодеров, чтобы они лучше всего работали. Очень важно правильно подобрать схему сэмплирования отрицательных примеров в обучении. Когда вы обучаетесь на диалоговых корпусах, у вас есть только положительные примеры, которые когда-то кем-то были сказаны в таком контексте. А отрицательных нет — их нужно как-то генерировать из этого корпуса. Там есть много разных техник, и одни работают лучше, чем другие.
Важно, как вы выбираете ответ из топа кандидатов. Можно выбирать наиболее вероятный ответ, предлагаемый моделью, но это не всегда лучшее, что можно сделать, потому что при обучении модель учитывала не все характеристики хорошего ответа, которые существуют с продуктовой точки зрения.
Ещё очень важно, какими дата-сетами вы пользуетесь, как их фильтруете.

Чтобы по крупицам собрать из этого всего качество, надо уметь измерять все, что вы делаете. И тут наша гордость состоит в том, что все аспекты качества системы мы умеем мерить на нашей краудсорсинговой платформе по кнопке. Когда у нас появляется новый алгоритм генерации результатов, мы в несколько кликов можем сгенерировать ответ новой модели на специальном тестовом корпусе. И — померить все аспекты качества полученной модели в Толоке. Основная метрика, которой мы пользуемся, — логическая уместность ответов в контексте. Не надо говорить чушь, которая никак с этим контекстом не связана.
Есть ряд дополнительных метрик, которые мы стараемся оптимизировать. Это когда Алиса к пользователю на «ты» обращается, говорит о себе в мужском роде и произносит всякие дерзости, гадости и глупости.
Высокоуровнево я рассказал все, что хотел. Спасибо.
Комментарии (44)



u007
18.02.2018 22:01Спросил её, какова скорость расширения вселенной. Не знает.
P.S. Разработчики из СПб?

u007
18.02.2018 22:30Хотя есть и положительные моменты:
Чем дышат рыбы?
— Водой
Сколько ног у многоножки?
— 750
При этом:Чему равна площадь круга?
Очень информативно…
— Давайте поищем!
Крупнейшая река в Сибири?
— Найдётся всё!
Сколько клавиш на клавиатуре?
— Ищу для вас ответ!
Кто изобрёл таблицу Менделеева?
— Сейчас найдём!
* Язык шаблонов вам не кажется переусложнённым? 30 длиннющих строчек для одного малюсенького шаблона. Может, поэтому у вас их так мало?
** Были идеи разнести логику и тексты? Какой-нибудь отдельный банк с вариациями ответов?
*** Python, да ещё с надстройкой — не слишком медленно для такой системы?

hr0nix
19.02.2018 21:38Что касается остальных вопросов:
* Я специально выбрал для слайдов сложный шаблон, чтобы проиллюстрировать всю мощь шаблонизатора. На практике большинство шаблонов выглядит как «В Москве сейчас {{form.temparature}} градусов»
** Ну, в шаблонах по большому счету нет логики, только тексты.
*** Нет, мы без особых проблем держим весьма немаленькую нагрузку. Весь действительно CPU-intensive код (например, применение нейросетей) написан не на питоне и вызывается через обертки.
hr0nix
19.02.2018 20:13«Дата основания Петербурга» — это ошибка классификатора интентов :( Починим
А над полнотой базы фактов мы, конечно, постоянно работаем.

D_E_S
18.02.2018 22:22странно почему некто не спросил про взаимодействие с другими приложениями. Очень интересно сможет ли Алиса когда нибудь поставить мне будильник?

ArVaganov
18.02.2018 23:01Поддержу вопрос. Для старта было бы отлично, если бы Алиса умела включать фонарик / таймер / писать сообщения и отмечать даты в календаре на телефоне.
Было бы неплохо в будущем увидеть Алису и в IoT в роли центра управления умным домом, например.
А озвучивание текста (если сравнивать русский) безусловно лучшее из всех голосовых помощников. Татьяна Шитова узнаваема).LorDCA
19.02.2018 06:21вы хотите слишком много от набора шаблонов написанных ручками. причем каждый шаблон выстрадан не по одному месяцу наверняка. я честно говоря вообще не понимаю в чем смысл хайпа, подобная система собирается за пару месяцев силами любителя.

LbISS
19.02.2018 09:35Мне кажется тут ошибка таргетирования кейсов использования на мобильниках и на компьютере. Приложение делается универсальное, а кейсы использования разные.
Для мобильника — да, хороший кейс спросить что-то быстро и получить голосовой ответ без необходимости искать телефон, разблокировать и запускать приложение.
А когда я работаю за компом — поиск информации не актуален. Мне в разы быстрее вбить руками одну строчку в браузер и получить исчерпывающий ответ с вариантами, чем сперва говорить "Привет, Алиса", ждать пока распознается, потом диктовать запрос, гадать распознается или нет и получать обрывочный ответ из первых 5 слов результата. За компом актуальны вещи которые надо делать не отрываясь от рабочего процесса — запустить фоном музыку (не только Яндекс.Музыку, но и standalone приложенный, причем одной командой сразу запустить на воспроизведение определённый плейлист — и фоном, без разворачивания принудительно окна и переключения фокуса), поставить напоминание/встречу, ответить на всплывшее сообщение в телеграме (опять же сразу, без переключения контекстов), озвучить пришедшую почту и т.п.

Aquahawk
19.02.2018 05:05А вот это правда? pikabu.ru/story/alisa_takaya_umnaya_5673045 может и фейк конечно, но если не фейк, то странно что отличие в регистре одной буквы теряет взаимосвязь. Хотя может как раз и научилась нейросетка имена по большим буквам вылавливать, и при написании с маленькой буквы оно вообще по классификатору в имена не попадает.
hr0nix
20.02.2018 14:47Будете смеяться, но проблема была в том, что в базе ответов по ошибке была написана латинская «С» в слове «Сталонне». Мне всегда было интересно, о чем думал автор йцукен-раскладки, помещая русскую и латинскую С на одну и ту же клавишу.
Aquahawk
20.02.2018 18:47Забавно, для обучаемой сети буквы это буквы, в прямом своём значении как абстракции, а для человека это не только абстракции конкретных букв но и визуальные образы, условная средняя яркость буквы, то как она выпирает из слова вверх или вниз. Получается в текущем виде Алиса никогда не поймёт картинки типа такой:


ozonar
19.02.2018 07:35Вообще, пользоваться Алисой пока невозможно как раз из-за того, что Алиса это fallback. На любой мало-мальски серьезный вопрос чат отправляет в Яндекс, а в случае с десктопным приложением это не только неожиданно, но и закрывает, собственно, чат с Алисой.
Поэтому помчавшись пару раз, идёшь искать сам и про Алису не вспоминаешь. Пока выглядит очень сыро.
erwins22
19.02.2018 08:09Как я понимаю проблема Алисы в том, что у Яндекса просто нет ресурсов на массовую реализацию нейросети.
Например можно было бы реализовать поиск статьи по запросу в вики и выборка ответа из статьи вики. Вероятно плохо, но лучше чем ничего.u007
20.02.2018 13:01Почему нет, есть. Так оно и работает скорее всего. У них же есть технологии распознавания текста в свободной форме, и базу знаний наверняка составляли на основе анализа массы статей. Причём, что важно, не только из вики. Анализируются и профильные сайты. Например, на вопрос «земноводное, 5 букв» эта девушка ответит информацией со scanwordhelper.
Если ошибаюсь, надеюсь, hr0nix поправит)
Одно непонятно, почему база знаний Алисы не тождественна базе знаний поисковой строки? Сейчас получается так: Алиса посылает за ответом в Яндекс, а Яндекс уже выбрасывает колдунщика с быстрым ответом (вопрос о площади круга). Зачем так? Зачем поддерживать две базы?

LorHobbit
19.02.2018 09:44> Она есть в приложении Яндекса на iOS и Android, а также в мобильном браузере и в виде отдельного приложения под Windows.
А приложение под Linux вы планируете сделать?
zzmaster
19.02.2018 10:24Все эти замечательные разработки становятся невостребованными, когда замечаешь, что Алиса подслушивает твои оффлайновые разговоры и Яндекс впоследствии выдает релевантную им рекламу. Я после этого попрощался с болтливой девушкой.
И (чтоб второй раз не вставать) — разработчики потратили время и нашли, видимо, действительно замечательное решение, чтобы Алису нельзя было удалить даже из списка процессов по Ctrl-Alt-Del (ведь завершить программу штатными средствами невозможно...), а надо ли оно голосовому помощнику?
(пишу впечатления по ранней версии, знакомиться с последующими — желания не возникло)
hr0nix
19.02.2018 21:59Нет, Алиса никого не подслушивает.
Если на секунду забыть про этическую составляющую вопроса, останется еще инженерная.
Например, на мобильном телефоне подслушивание очень быстро съест весь заряд аккумулятора из-за необходимости постоянно стримить речь на сервер распознавания. Я даже больше скажу, мы очень много инженерных усилий тратим на то, чтобы начинать слушать пользователя только в тот момент, когда мы на 100% уверены, что он обратился к Алисе, и, тем самым, экономить заряд аккумулятора. Пользователь, который удалил приложение из-за того, что оно разряжало его телефон, точно не принесет нам денег. А что мы ему прорекламируем на основе обрывков разговоров — это еще бабка надвое сказала.
Стоит также отметить, что нагрузка, которую создаст на сервера распознавания речи постоянный стриминг разговоров пользователей между собой, будет превышать нагрузку от использования Алисы на порядки. Другими словами, подслушивать — дорого. Есть намного более простые, дешевые и надежные способы понять предпочтения пользователя.
Но все любят теории заговора, я понимаю.zzmaster
21.02.2018 06:54Ну как вы объясните, что я разговаривал с человеком по телефону, он интересовался фрилансингом, я посоветовал ему поискать в гугле "профессия программист фрилансер", и вскоре яндекс на ноутбуке выдал мне рекламу на тему профессии веб программиста и фриланса?
При том, что я фрилансю уже десяток лет и такой рекламы раньше не видел. Подозреваю, что вы не полностью владеете информацией на этот счет, и я далеко не конспиролог, ни в какие лунные заговоры не верю.

Maccimo
19.02.2018 10:26Пользователь говорит: «Алиса, какую ожидать завтра погоду?»
...В нем будет написано, что это интент погода, что погода нужна на +1 день от текущего дня, а где — неизвестно.
А если пользователь начал фразу в 23:59, а закончил в 00:03? Или в час ночи спросил?
Другими словами, как дела с обработкой граничных случаев в интентах?
Костыли на шаблонах или что-то более интеллектуальное?hr0nix
19.02.2018 22:00Костыли aka бизнес-логика. Более интеллектуальные способы решения подобных проблем человечеству, боюсь, пока неизвестны.

linuxover
19.02.2018 12:48посмотрел код шаблона на скриншоте: об интернационализации Алисы не думали пока?
интернационализацию же надо отделять от логики, а тут фразы собираются, if'ы всякие.
или команда будет собирать свои правила для английского/албанского языков?JediPhilosopher
19.02.2018 17:38Я не из Яндекса, но работал в фирме, делавшей чат-боты по похожей технологии. Да, для отдельных языков были отдельные файлы шаблонов со своими правилами. Грамматика и построение предложений в разных языках отличается достаточно сильно чтобы не имело смысла пытаться натянуть разные языки на один шаблон.
Конечно от дублирования кода всячески пытались избавиться, всю независящую от языков логику выносили в джаваскрипт-методы, которые можно было звать из шаблонов. Но сами правила разбора и паттерны приходилось писать каждый раз заново.linuxover
19.02.2018 17:54Конечно от дублирования кода всячески пытались избавиться, всю независящую от языков логику выносили
на скриншоте логика явно независящая от языков, поэтому я вопрос и задал :)
просто собрать разную строку в виде интерполяции строк:
курс доллара {% 25 %} тугриков за доллар
это легко подается интернационализации
а вот "если у юзера что-то там в профиле и еще у него устройство что-то там поддерживает" — эту фигню если отдать переводчикам, они непременно что-то накосячат.
либо нужны переводчики будут с солидной IT экспой.
ну и плюс — когда понадобится поменять тут что-то в логике, то закопаешься все языки править.

ameli_anna_kate
19.02.2018 13:43+1Порой такие перлы выдает. Скрины делать долго, но вот кусочек разговора.
Я: Ты любишь читать?
А: Обожаю
Я: Какие книги тебе нравятся?
А: Я родилась на улице Льва Толстого, поэтому испытываю к графу определенную слабость.
Я: Платоническую?
А: Не без этого.
Я: И какая его книга самая любимая?
А: Люблю книги с захватывающим сюжетом. Чтобы сначала ух, а потом ах, но в конце все хорошо. Например, трехтомник Кнута про алгоритмы. Особенно четвертый том.
Я: И что Кнут пишет в своем четвертом томе?
А: Получил.
Я: О чем Кнут пишет?
А: открываю яндекс
Я: Что тебе нравится в книгах Кнута?
А: 50 оттенков серого.
Я: Да что ты заладила про эти 50 оттенков?
А: Я ее читала.
Я: А получше что есть?
А: Ты читала ее?
Я: Нет, мне она не нравится
А: Почитай, тебе понравится.
Я: Точно нет
А: Не спорь с отцом.
Что? Говорите включить рекламу? По ходу она уже работает.

perfect_genius
19.02.2018 15:14Это уже исправили?
hr0nix
19.02.2018 22:03Мы уже почти отучили Алису говорить о себе в мужском роде. Но иногда нет нет да и прорвется что-нибудь через все наши машинно обученные блокады.


bzq
19.02.2018 23:43Когда Алиса появилась впервые, её зачем-то назвали ИИ. Было конечно интересно. Первое, что я сделал — проверил её на интеллект нехитрым тестом:
Я: Дважды два.
А: Четыре.
Я: Прибавь два.
А несёт какой-то бред.
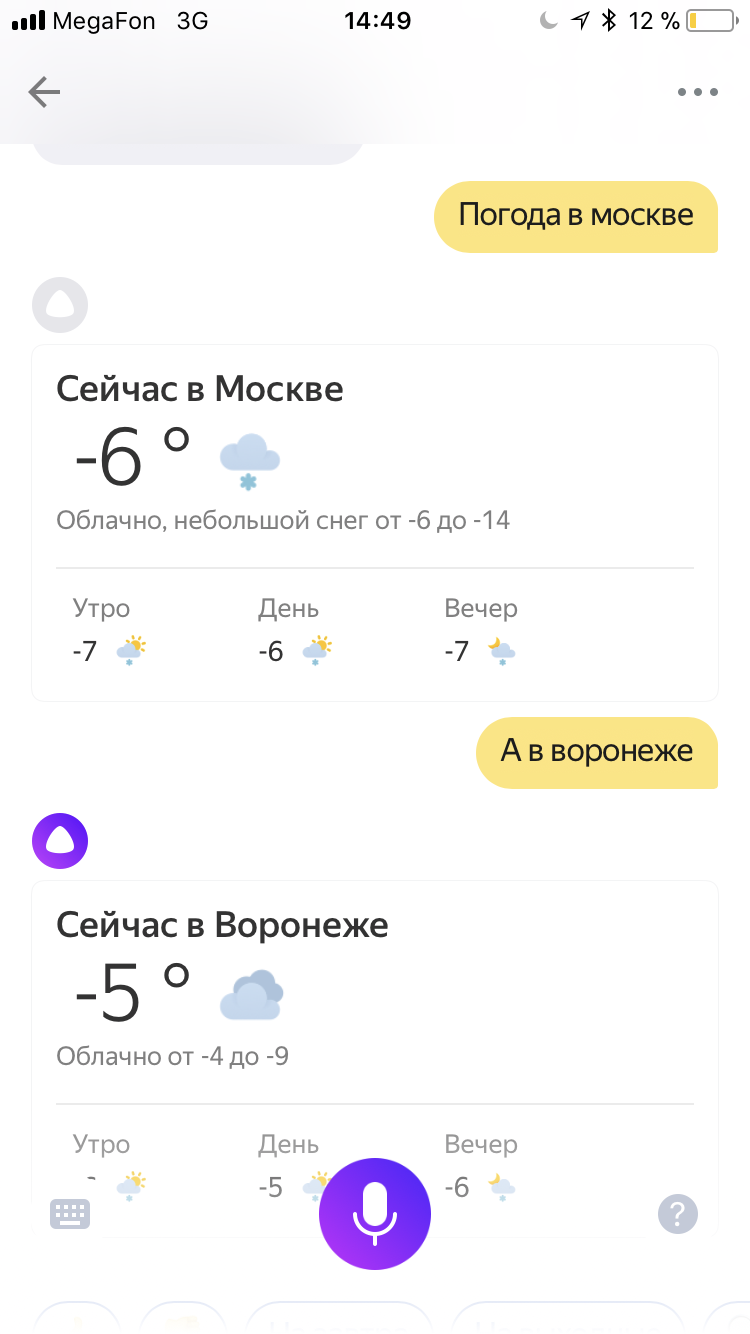
Суть теста такая, что любая интеллектуальная деятельность должна иметь контекст и память того, что было только что. У Алисы этого нет. В этой статье с интересом увидел, что оказывается есть, причём, если верить статье, используется повсеместно, вроде как любое произнесённое заполняет информацию в некоторой виртуальной «форме». И ещё эта, как её, анафора. Со второй попытки я сумел повторить пример с Эверестом из статьи, в первый раз моя фраза распозналась не совсем верно, и оно не сработало. Тогда я попробовал вызвать подобное поведение ещё хоть где-то. Не могу. Не выходит:
Я: Погода на завтра.
А: Завтра в Москве…
Я: А в Воронеже?
А: А ты где живёшь?
Короче, пока Алиса постоянно забывает нить разговора и не помнит даже предыдущей моей фразы, она в лучшем случае похожа на дауна. Человек, который не помнит предыдущей фразы ни своей, ни собеседника в реальной жизни производит пугающее впечатление.
Я думаю, что нужно сделать так, чтобы Алиса как раз всё-всё помнила и отвечала на вопросы только в контектсе предыдущих реплик. Пусть они забываются со временем (через несколько часов), пусть сбрасываются на специальные фразы типа «Так, давай всё с начала», но контекст забывать нельзя.
А болталка — прикольно, но совершенно бесполезно.hr0nix
20.02.2018 14:53У нас, конечно, пока все не идеально с контекстом, и до ИИ нам пока далеко, но вот про Воронеж обидно было.
bzq
20.02.2018 15:19Ничего, Воронеж справится. Вот Вам хорошо. Хозяев Алиса слушает внимательно, а у меня забывает всё напрочь. Реакция на предыдущую фразу у меня бывает только если повторяю Ваши примеры. А у меня только так:

И ещё странно, что Алиса всё норовит в поиск послать. Пусть бы сама искала и озвучивала. Если не может от своего имени, то пусть отвечает типа «В этих ваших интернетах говорят ...»
nomadmoon
Можно как то подсказать Алисе что она отвечает не в тему если она отвечает не в тему?
hr0nix
Можно нажать на кнопку «палец вниз» рядом с ответом