

Инструменты web scraping (парсинг) разработаны для извлечения, сбора любой открытой информации с веб-сайтов. Эти ресурсы нужны тогда, когда необходимо быстро получить и сохранить в структурированном виде любые данные из интернета. Парсинг сайтов – это новый метод ввода данных, который не требует повторного ввода или копипастинга.
Такого рода программное обеспечение ищет информацию под контролем пользователя или автоматически, выбирая новые или обновленные данные и сохраняя их в таком виде, чтобы у пользователя был к ним быстрый доступ. Например, используя парсинг можно собрать информацию о продуктах и их стоимости на сайте Amazon. Ниже рассмотрим варианты использования веб-инструментов извлечения данных и десятку лучших сервисов, которые помогут собрать информацию, без необходимости написания специальных программных кодов. Инструменты парсинга могут применяться с разными целями и в различных сценариях, рассмотрим наиболее распространенные случаи использования, которые могут вам пригодиться. И дадим правовую оценку парсинга в России.
1. Сбор данных для исследования рынка
Веб-сервисы извлечения данных помогут следить за ситуацией в том направлении, куда будет стремиться компания или отрасль в следующие шесть месяцев, обеспечивая мощный фундамент для исследования рынка. Программное обеспечение парсинга способно получать данные от множества провайдеров, специализирующихся на аналитике данных и у фирм по исследованию рынка, и затем сводить эту информацию в одно место для референции и анализа.
2. Извлечение контактной информации
Инструменты парсинга можно использовать, чтобы собирать и систематизировать такие данные, как почтовые адреса, контактную информацию с различных сайтов и социальных сетей. Это позволяет составлять удобные списки контактов и всей сопутствующей информации для бизнеса – данные о клиентах, поставщиках или производителях.
3. Решения по загрузке с StackOverflow
С инструментами парсинга сайтов можно создавать решения для оффлайнового использования и хранения, собрав данные с большого количества веб-ресурсов (включая StackOverflow). Таким образом можно избежать зависимости от активных интернет соединений, так как данные будут доступны независимо от того, есть ли возможность подключиться к интернету.
4. Поиск работы или сотрудников
Для работодателя, который активно ищет кандидатов для работы в своей компании, или для соискателя, который ищет определенную должность, инструменты парсинга тоже станут незаменимы: с их помощью можно настроить выборку данных на основе различных прилагаемых фильтров и эффективно получать информацию, без рутинного ручного поиска.
5. Отслеживание цен в разных магазинах
Такие сервисы будут полезны и для тех, кто активно пользуется услугами онлайн-шоппинга, отслеживает цены на продукты, ищет вещи в нескольких магазинах сразу.
В обзор ниже не попал Российский сервис парсинга сайтов и последующего мониторинга цен XMLDATAFEED (xmldatafeed.com), который разработан в Санкт-Петербурге и в основном ориентирован на сбор цен с последующим анализом. Основная задача — создать систему поддержки принятия решений по управлению ценообразованием на основе открытых данных конкурентов. Из любопытного стоит выделить публикация данные по парсингу в реальном времени :)

10 лучших веб-инструментов для сбора данных:
Попробуем рассмотреть 10 лучших доступных инструментов парсинга. Некоторые из них бесплатные, некоторые дают возможность бесплатного ознакомления в течение ограниченного времени, некоторые предлагают разные тарифные планы.
1. Import.io
Import.io предлагает разработчику легко формировать собственные пакеты данных: нужно только импортировать информацию с определенной веб-страницы и экспортировать ее в CSV. Можно извлекать тысячи веб-страниц за считанные минуты, не написав ни строчки кода, и создавать тысячи API согласно вашим требованиям.
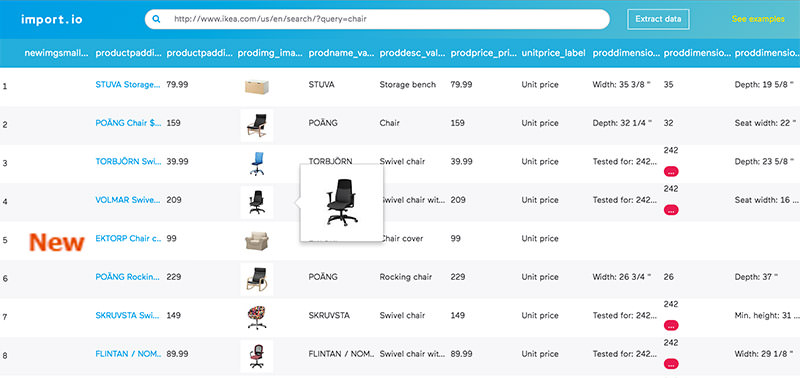
Для сбора огромных количеств нужной пользователю информации, сервис использует самые новые технологии, причем по низкой цене. Вместе с веб-инструментом доступны бесплатные приложения для Windows, Mac OS X и Linux для создания экстракторов данных и поисковых роботов, которые будут обеспечивать загрузку данных и синхронизацию с онлайновой учетной записью.
2. Webhose.io
Webhose.io обеспечивает прямой доступ в реальном времени к структурированным данным, полученным в результате парсинга тысяч онлайн источников. Этот парсер способен собирать веб-данные на более чем 240 языках и сохранять результаты в различных форматах, включая XML, JSON и RSS.

Webhose.io – это веб-приложение для браузера, использующее собственную технологию парсинга данных, которая позволяет обрабатывать огромные объемы информации из многочисленных источников с единственным API. Webhose предлагает бесплатный тарифный план за обработку 1000 запросов в месяц и 50 долларов за премиальный план, покрывающий 5000 запросов в месяц.
3. Dexi.io (ранее CloudScrape)
CloudScrape способен парсить информацию с любого веб-сайта и не требует загрузки дополнительных приложений, как и Webhose. Редактор самостоятельно устанавливает своих поисковых роботов и извлекает данные в режиме реального времени. Пользователь может сохранить собранные данные в облаке, например, Google Drive и Box.net, или экспортировать данные в форматах CSV или JSON.
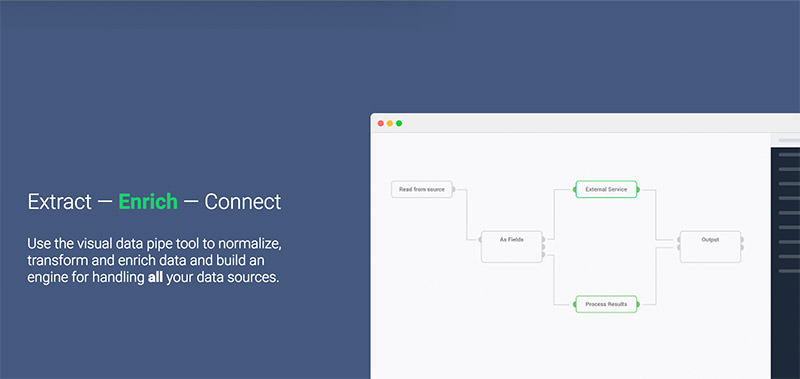
CloudScrape также обеспечивает анонимный доступ к данным, предлагая ряд прокси-серверов, которые помогают скрыть идентификационные данные пользователя. CloudScrape хранит данные на своих серверах в течение 2 недель, затем их архивирует. Сервис предлагает 20 часов работы бесплатно, после чего он будет стоить 29 долларов в месяц.
4. Scrapinghub
Scrapinghub – это облачный инструмент парсинга данных, который помогает выбирать и собирать необходимые данные для любых целей. Scrapinghub использует Crawlera, умный прокси-ротатор, оснащенный механизмами, способными обходить защиты от ботов. Сервис способен справляться с огромными по объему информации и защищенными от роботов сайтами.

Scrapinghub преобразовывает веб-страницы в организованный контент. Команда специалистов обеспечивает индивидуальный подход к клиентам и обещает разработать решение для любого уникального случая. Базовый бесплатный пакет дает доступ к одному поисковому роботу (обработка до 1 Гб данных, далее — 9$ в месяц), премиальный пакет дает четырех параллельных поисковых ботов.
5. ParseHub
ParseHub может парсить один или много сайтов с поддержкой JavaScript, AJAX, сеансов, cookie и редиректов. Приложение использует технологию самообучения и способно распознать самые сложные документы в сети, затем генерирует выходной файл в том формате, который нужен пользователю.

ParseHub существует отдельно от веб-приложения в качестве программы рабочего стола для Windows, Mac OS X и Linux. Программа дает бесплатно пять пробных поисковых проектов. Тарифный план Премиум за 89 долларов предполагает 20 проектов и обработку 10 тысяч веб-страниц за проект.
6. VisualScraper
VisualScraper – это еще одно ПО для парсинга больших объемов информации из сети. VisualScraper извлекает данные с нескольких веб-страниц и синтезирует результаты в режиме реального времени. Кроме того, данные можно экспортировать в форматы CSV, XML, JSON и SQL.
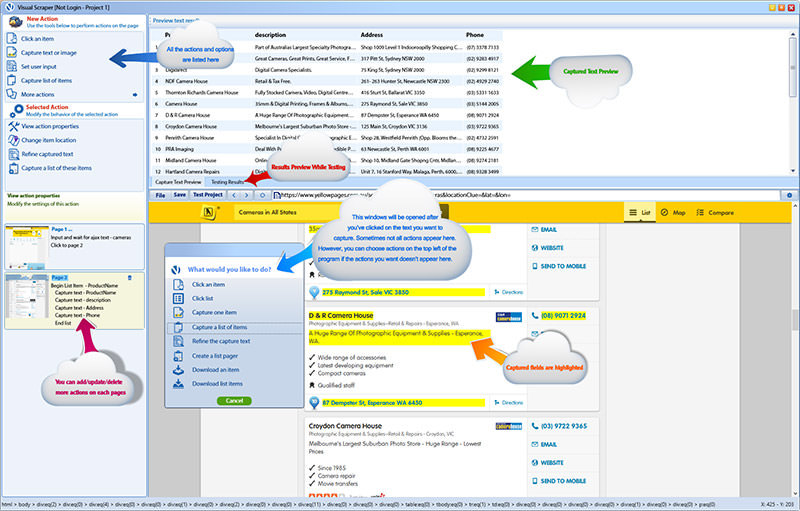
Пользоваться и управлять веб-данными помогает простой интерфейс типа point and click. VisualScraper предлагает пакет с обработкой более 100 тысяч страниц с минимальной стоимостью 49 долларов в месяц. Есть бесплатное приложение, похожее на Parsehub, доступное для Windows с возможностью использования дополнительных платных функций.
7. Spinn3r
Spinn3r позволяет парсить данные из блогов, новостных лент, новостных каналов RSS и Atom, социальных сетей. Spinn3r имеет «обновляемый» API, который делает 95 процентов работы по индексации. Это предполагает усовершенствованную защиту от спама и повышенный уровень безопасности данных.
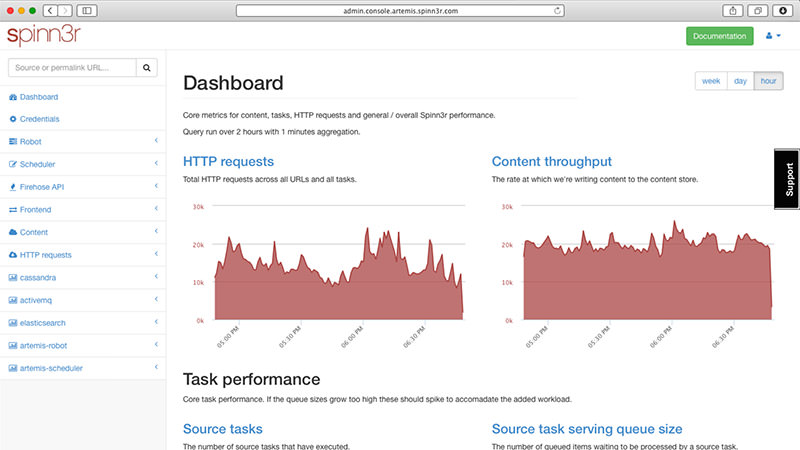
Spinn3r индексирует контент, как Google, и сохраняет извлеченные данные в файлах формата JSON. Инструмент постоянно сканирует сеть и находит обновления нужной информации из множества источников, пользователь всегда имеет обновляемую в реальном времени информацию. Консоль администрирования позволяет управлять процессом исследования; имеется полнотекстовый поиск.
8. 80legs
80legs – это мощный и гибкий веб-инструмент парсинга сайтов, который можно очень точно подстроить под потребности пользователя. Сервис справляется с поразительно огромными объемами данных и имеет функцию немедленного извлечения. Клиентами 80legs являются такие гиганты как MailChimp и PayPal.

Опция «Datafiniti» позволяет находить данные сверх-быстро. Благодаря ней, 80legs обеспечивает высокоэффективную поисковую сеть, которая выбирает необходимые данные за считанные секунды. Сервис предлагает бесплатный пакет – 10 тысяч ссылок за сессию, который можно обновить до пакета INTRO за 29 долларов в месяц – 100 тысяч URL за сессию.
9. Scraper
Scraper – это расширение для Chrome с ограниченными функциями парсинга данных, но оно полезно для онлайновых исследований и экспортирования данных в Google Spreadsheets. Этот инструмент предназначен и для новичков, и для экспертов, которые могут легко скопировать данные в буфер обмена или хранилище в виде электронных таблиц, используя OAuth.
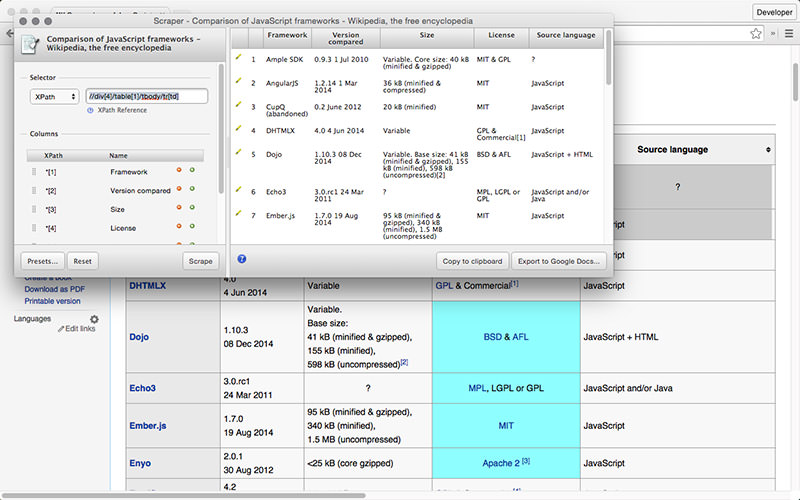
Scraper – бесплатный инструмент, который работает прямо в браузере и автоматически генерирует XPaths для определения URL, которые нужно проверить. Сервис достаточно прост, в нем нет полной автоматизации или поисковых ботов, как у Import или Webhose, но это можно рассматривать как преимущество для новичков, поскольку его не придется долго настраивать, чтобы получить нужный результат.
10. OutWit Hub
OutWit Hub – это дополнение Firefox с десятками функций извлечения данных. Этот инструмент может автоматически просматривать страницы и хранить извлеченную информацию в подходящем для пользователя формате. OutWit Hub предлагает простой интерфейс для извлечения малых или больших объемов данных по необходимости.
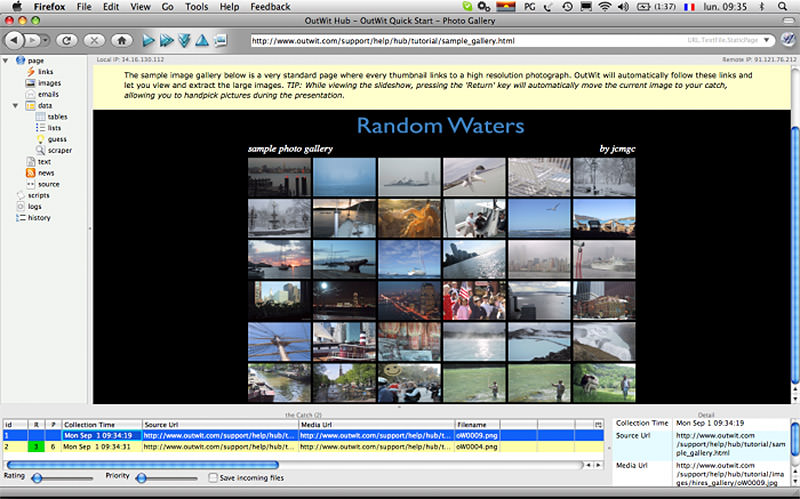
OutWit позволяет «вытягивать» любые веб-страницы прямо из браузера и даже создавать в панели настроек автоматические агенты для извлечения данных и сохранения их в нужном формате. Это один из самых простых бесплатных веб-инструментов по сбору данных, не требующих специальных знаний в написании кодов.
Самое главное — правомерность парсинга?!
Вправе ли организация осуществлять автоматизированный сбор информации, размещенной в открытом доступе на сайтах в сети интернете (парсинг)?
В соответствии с действующим в Российской Федерации законодательством разрешено всё, что не запрещено законодательством. Парсинг является законным, в том случае, если при его осуществлении не происходит нарушений установленных законодательством запретов. Таким образом, при автоматизированном сборе информации необходимо соблюдать действующее законодательство. Законодательством Российской Федерации установлены следующие ограничения, имеющие отношение к сети интернет:
1. Не допускается нарушение Авторских и смежных прав.
2. Не допускается неправомерный доступ к охраняемой законом компьютерной информации.
3. Не допускается сбор сведений, составляющих коммерческую тайну, незаконным способом.
4. Не допускается заведомо недобросовестное осуществление гражданских прав (злоупотребление правом).
5. Не допускается использование гражданских прав в целях ограничения конкуренции.
Из вышеуказанных запретов следует, что организация вправе осуществлять автоматизированный сбор информации, размещенной в открытом доступе на сайтах в сети интернет если соблюдаются следующие условия:
1. Информация находится в открытом доступе и не защищается законодательством об авторских и смежных правах.
2. Автоматизированный сбор осуществляется законными способами.
3. Автоматизированный сбор информации не приводит к нарушению в работе сайтов в сети интернет.
4. Автоматизированный сбор информации не приводит к ограничению конкуренции.
При соблюдении установленных ограничений Парсинг является законным.
Какой инструмент для извлечения данных Вам нравится больше всего? Какого рода данные вы хотели бы собрать? Расскажите в комментариях о своем опыте парсинга и свое видение процесса…
p.s. Для тех, кто хочет получить гораздо больше информации по разным инструментам в сети Интернет, советуем обратиться к публикациям на сайте http://startup.today
Комментарии (37)

syno
13.10.2017 15:42Только сегодня писал блокиратор для подобных сервисов с баном ip на несколько часов.

dernasherbrezon
13.10.2017 15:46А мне как разработчику такой штуки кстати интересно почему Вы заблокировали. Обычно парсят сайты не потому что хотят положить конкурента, а потому что нет API для получения данных.
А что у Вас парсят/ищут?
syno
13.10.2017 15:48Основное, что беспокоит — тырят оригинальные описания товаров и фотки.

makasin4ik Автор
13.10.2017 15:49фотки и описания — действительно могут быть объектом авторского права, а ведь могут и не быть!
syno
13.10.2017 16:23Мы не собираемся ни с кем судиться за кусок текста, просто максимально усложним работу подобным сервисам и программам по скачиванию сайтов. Эти сервисы будут получать 404 практически на все страницы. Все что мы захотим отдать во вне, мы отдадим через api.
makasin4ik Автор
13.10.2017 16:26А что у вас за сайт такой, извините, что вы так прямо дорожите контентом? :) Можно взглянуть? Обычные Инет-магазины обычно дублируют контент друг у друга.
syno
13.10.2017 16:37+2Мы производим жалюзи. Сами пишем тексты. Покупаем фото на стоках, сканируем текстуру материалов, если поставщик не предоставил фотографии. Периодически возникают сайты с полной копией наших текстов и фотографий, вплоть до полных зеркал. Вот, захотелось усложнить людям жизнь :)
dernasherbrezon
13.10.2017 15:52Да, так делать не стоит. Но и блокировка по ip долго не протянет. Тут как бы война меча и щита.
Можно кстати посмотреть как Яндекс или Гугл защищают свои карты. Их ведь тоже по идее можно скачать. Так вот на таких картах рисуют несуществующую улицу/дом. И если карту крадут, то крадут и намеренно сделанную ошибку. Соответственно доказать уникальность материала достаточно просто. В теории :)
syno
13.10.2017 15:56Ручное скачивание не беспокоит. Беспокоит машинное. Именно его и блочим :)
dernasherbrezon
13.10.2017 16:01Мне пришла безумная идея. А что если не блочить, а продавать Ваш контент? Тогда Вы отберете хлеб у парсеров. И тому кому, нужен будет контент будет проще его купить у Вас, чем заморачиваться с парсерами. Что то вроде http://www.istockphoto.com только для описаний.
makasin4ik Автор
13.10.2017 15:50Это не проблема, обходится через прокси.
syno
13.10.2017 15:54Тестировал. Лист блокировки заполняется десятками заблокированных адресов прокси за несколько секунд. Я пропущу только, если вы прикинитесь гуглоботом и аккуратно прочитаете все директивы robots.txt и не будете лезть куда запрещено.
dernasherbrezon
13.10.2017 15:57Кстати большинство парсеров (мой в том числе) вполне дружелюбны к robots.txt. Конечно, есть наколеночные скрипты, которые туда не смотрят. Но если бизнес построен на извлечении данных (import.io — достаточно хороший пример), то компании стараются вести себя дружелюбно.

dernasherbrezon
13.10.2017 15:44Мне нравится мой собственный написанный :)
https://mystopcrawl.com
croupier
13.10.2017 16:08+2Тогда уж похвастались бы чем он крут, а то без регистрации ничего не посмотреть.
dernasherbrezon
13.10.2017 16:17- Визуальный редактор. Просто кликаете на те части страницы которые нужно извлечь и нажимаете кнопку "готово".
- Данные можно трансформировать. Например, преобразовать ссылку "img/lowResPic.jpg" в "https://example.com/img/highResPic.jpg"
- API который возвращает данные в json и поддержка webhook'ов. Например, если поменялись данные на сайте (курс биткоина), то сервис сам дёрнет Ваш сервис и через POST передаст новое значение.
- Под Ваш проект создается виртуалка (привет модным облачным апишечкам), в которой находится только Ваш проект. Соответственно диск, процессор и память всецело Ваши.

norlin
13.10.2017 16:43Ещё есть специализированный прокси-сервис для бизнеса – luminati.io – позволяющий смотреть сайты конкурентов из разных гео-локаций (причём, с очень высокой точностью выбора локации). Ну и обходить всевозможные блокировки по IP и всё такое.

ProstoDesign
13.10.2017 19:08-2Пользуясь случаем, задам вопрос, возможно кто-либо знает адекватный вариант. Есть задача стащить все картинки и описания с одного интернет-магазина и засунуть в другой. Т.е. нужен какой-то парсер/граббер который это сможет. Посоветуете?
makasin4ik Автор
13.10.2017 20:47xmldatafeed.com попробуйте, но вы держите в уме, что вы можете нарушить авторские права правообладателя.
ProstoDesign
13.10.2017 21:05Спасибо, посмотрю. Речь идет не об авторских описаниях товаров, а о «заводских».
Nekhebeth
13.10.2017 21:08Из вышеуказанных запретов следует, что организация вправе осуществлять автоматизированный сбор информации, размещенной в открытом доступе на сайтах в сети интернет если соблюдаются следующие условия:
1. Информация находится в открытом доступе и не защищается законодательством об авторских и смежных правах.
Законодатель определяет Интернет как информационно-телекоммуникационную сеть, которая не является местом, открытым для свободного посещения, по смыслу ст. 1276 ГК Российской Федерации — Определение № 84-КГ15-1 Судебной Коллегии по гражданским делам ВС РФ.
Информация никак не может быть «незащищённой законодательством об авторских и смежных правах», потому что данные права возникают автоматически и не требуют ни какого-то подтверждения, ни регистрации (ст. 1259 ГК РФ).
Далее, правообладатель может по своему усмотрению разрешать или запрещать другим лицам использование результата интеллектуальной деятельности или средства индивидуализации. Отсутствие запрета не считается согласием (разрешением) — ГК РФ, ст. 1229.makasin4ik Автор
13.10.2017 21:08В РФ то, что не запрещено законом, априори разрешено. Отсюда и следствие по парсингу.
Nekhebeth
13.10.2017 21:17В данном случае как раз запрещено — читайте выделенный текст, а лучше сразу всю часть 4 ГК РФ.

pvp
13.10.2017 22:12«Информация никак не может быть «незащищённой законодательством об авторских и смежных правах»
Информация не охраняется авторским правом. „Читайте лучше сразу всю 4 часть ГК“.Nekhebeth
13.10.2017 22:25Информация — сведения, воспринимаемые человеком и (или) специальными устройствами как отражение фактов материального или духовного мира в процессе коммуникации.
Иными словами, она включает в себя всё, что мы видим, слышим или осязаем, в любой форме.
Вы путаете информацию с определением «сообщение о событиях и фактах, имеющее чисто информационный характер» — то есть, не несущее на себе отпечаток интеллектуального труда.
Если же Вы имеете в виду информацию в виде какой-то статистики или даже просто массива данных, то она точно так же защищается законодательством об интеллектуальной собственности, как и любая другая, потому что за ней стоит составитель и (или) изготовитель.pvp
13.10.2017 23:551. «Сообщение… имеющее информационный характер» и «информация» — одно и то же. Вы зачем-то выдумали себе какую-то «информацию, несущую отпечаток интеллектуального труда», такой информации быть не может. Потому что…
2. «ФЕДЕРАЛЬНЫЙ ЗАКОН ОБ ИНФОРМАЦИИ, ИНФОРМАЦИОННЫХ ТЕХНОЛОГИЯХ И О ЗАЩИТЕ ИНФОРМАЦИИ
Статья 1. Сфера действия настоящего Федерального закона
…
2. Положения настоящего Федерального закона не распространяются на отношения, возникающие при правовой охране результатов интеллектуальной деятельности и приравненных к ним средств индивидуализации, за исключением случаев, предусмотренных настоящим Федеральным законом.»
Информационные правоотношения и «авторское право» — это две разных правовых сферы, которые взаимно не пересекаются. Авторское право охраняет форму произведения, а информационное — его содержание.Nekhebeth
14.10.2017 01:09Вы зачем-то выдумали себе какую-то «информацию, несущую отпечаток интеллектуального труда
Я ничего такого не говорила, прочтите внимательнее. Я Вам объяснила суть "сообщения чисто информационного характера" (это определение есть в ГК).
«Сообщение… имеющее информационный характер» и «информация» — одно и то же.
Абсолютно нет. Информация — собирательное словарное определение любых сведений, которые мы воспринимаем, а «сообщения о событиях и фактах, имеющие исключительно информационный характер» — это регулятивная норма гражданского права (точнее, её диспозиция). И правоприменение основывается именно на нормах права, а не на философских концепциях. Но эти два понятия не идентичны, даже если абстрагироваться от сферы юриспруденции: первое является составной частью второго.
Информационные правоотношения и «авторское право» — это две разных правовых сферы, которые взаимно не пересекаются.
Вы сделали совершенно неверные выводы из процитированного параграфа. То, что положения 149-ФЗ «не распространяются на отношения, возникающие при правовой охране результатов интеллектуальной деятельности и приравненных к ним средств индивидуализации», означает лишь, что в этой части данный закон следует нормам, применяемым ГК РФ.
И не стоит уводить дискуссию в другую плоскость — речь в статье идёт о парсинге материалов с чужих сайтов.pvp
14.10.2017 10:38Вы зачем-то подменяете определение «информации», данное в законе, на «словарное», после чего делаете из этого выводы космического масштаба. Не надо так.
Nekhebeth
14.10.2017 12:34Я ничего не подменяю, это Вы пытаетесь смешивать понятия, говоря о том, что, цитирую,
Информация не охраняется авторским правом
На что я Вам отвечаю, что это утверждение — некорректно, поскольку нигде в законодательстве РФ Вы такого определения не найдёте. Информация как таковая — это совокупность понятий, которая имеет большое количество подмножеств, и каждое из этих подмножеств, а также входящие в них объекты, в праве классифицируются и рассматриваются отдельно.
Приведённый же Вами в качестве примера Федеральный Закон вообще никакого отношения к обсуждаемой теме не имеет. Да, он не регулирует отношения в области авторских и смежных прав, но только потому, что его цели лежат совершенно в иной плоскости. Точно так же, скажем, ФЗ «Об основах охраны здоровья граждан РФ» не регулирует вопросы семейного права, хотя косвенно они там тоже затрагиваются.

{kind=link}
xDimus
14.10.2017 10:40А для мониторинга цен на товары в личных масштабах другие сервисы/программы или какой то из перечисленных подойдет? Интересует скажем процессор i5-2500, искать хочу на ebay, aliexpress и avito, нужно при появлении товара по хорошей цене получить уведомление на почту или мессенджер.
Rambalac
Забыли упомянуть, что нахождение частной информации даже в открытом виде на одних сайтах не даёт права использовать эти данные третьими лицами.
makasin4ik Автор
да, вы правы. Если мы говорим про цены конкурентов, то это не является объектом авторского права :) и использовать можно как угодно.
hudson
И конкуренцию не ограничивает, а стимулирует )
makasin4ik Автор
точно, поэтому суд будет на стороне ответчика :)