

Александр Алексеев (Postgres Professional)
Отличный обзорный доклад конференции HighLoad++ 2016 о том, как надо проводить профилирование программного кода. О типичных ошибках, происходящих при измерениях. И, конечно, об инструментах:
— gettimeofday
— strace, ltrace, truss
— gprof
— gdb / lldb
— perf
— pmcstat
— SystemTap
— DTrace
— HeapTrack
— BPF / bcc
В начале у меня будет не слишком техническая часть, о том, как не надо делать benchmark’и.
Я наблюдаю, что люди часто делают типичные ошибки, когда делают benchmark’и. И вот первая из них…
Если вы не знаете, то у всех докладчиков HighLoad++ проходит суровый коучинг, многократный, по разным векторам. Один коучинг обязательный, остальные — опциональные. Опциональный коучинг — это как побороть боязнь сцены, например. То есть очень суровый подход к организации всего этого дела. И когда я подавал доклад на HighLoad++, организаторы предложили убрать всю эту техническую часть и добавить больше кулстори, красивых скриншотов и так далее. А те, кому интересно, как это запустить, какие команды набрать, могут обратиться к документации — и вот поэтому — ссылка на мой бложик, потому что все там есть.В начале у меня будет не слишком техническая часть, о том, как не надо делать benchmark’и.
Если вас интересует, к примеру, как SystemTap сложно собирается на Linux, то открываем ссылку на блог и там будет прямо все. А в этом докладе будет скорее такой обзор, чтобы вы представляли, какие инструменты вообще есть, что они дают и когда какой использовать.
Я наблюдаю, что люди часто делают типичные ошибки, когда делают benchmark’и.
- Во-первых, это неповторяемость. Когда вы открываете какой-нибудь бложик, и там такая классная статья, что мы «померяли что-то, получили такие красивые графики, и наше решение, которое стоит так, делает это в 500 раз быстрее». При этом не приводится никаких данных для повторения этого эксперимента, никаких скриптов и ничего. Ну, это хреновый benchmark, и нужно это сразу страницу закрыть. Если вы не можете его повторить, как можно ему верить?

Вы должны хотя бы примерно такие же результаты мочь воспроизвести.
- Вы измеряете не то, что думаете. Типичный пример: мы хотим померить, как у нас жесткий диск работает. Мы весело набираем dd if что-нибудь куда-нибудь. Пишем в диск и меряем, а как быстро он, собственно, пишет. Кто-нибудь из зала может сказать, почему это не измерение скорости диска?
Правильно — потому что на самом деле вы померяли скорость, с которой у вас кэш файловой системы работает. Как это обойти — это тоже интереснаяпроблема.
- Взятие среднего. Это меня всегда бесило на наших митингах, и я вижу в первом ряду слушателя, который меня понимает. Нам нужно понимать, как быстро мы отвечаем пользователю на запросы — давайте построим график среднего времени ответа. Проблема в том, что на этом графике может быть среднее время красивое — 15 миллисекунд, но есть пики по 15 секунд. Они могут быть очень редки, и это взятие среднего их смазывает. Вы думаете, что у вас все здорово и замечательно, на самом деле это не так. Поэтому стройте хотя бы среднее и максимум — это уже даст вам хорошую картину. Если для вас это слишком просто, стройте перцентили, 95-ую, 99-ую — это даст вам еще более хорошее представление. Их не очень дешево строить, но, в принципе, решаемо.
- Кто будет бенчмаркать бенчмарки? Это такая проблема. Например, вы написали клевый тест, который меряет, сколько ответов в секунду генерит ваше приложение. Померили, получили, скажем, 4000 запросов в секунду. Думаете: «Как-то маловато, надо оптимайзить». Проблема в том, что ваш benchmark однопоточный. А под реальной нагрузкой ваше приложение работает в сотнях, в тысячи потоков. И, собственно, вы не учли, что ваш собственный benchmark — это bottleneck в данном случае. Это нужно понимать.
- Отсутствие анализа. Это когда вы померяли, говорите: «Что-то тупит, надо все отрефачить, все переписать». То есть нужно понимать, почему оно тупит.
- Игнорирование ошибок. Опять же, вернемся к примеру с вашим бенчмарком. Допустим, это не ваш benchmark, это A/B, и вы его натравили на свой сервис, померили, получили 5 млн. запросов в секунду и радуетесь: «У нас все очень быстро». Но вы не посмотрели, что все это ответы 404, например. То есть нужно ошибки тоже высчитывать.
- Неправильные настройки. В моей сфере, в базах данных, это частая проблема, потому что настройки Postgres по умолчанию предполагают, что вы пытаетесь запустить его на микроволновке. Сейчас сервера мощные, поэтому все настройки по умолчанию надо очень сильно менять. Побольше шарить buffers, побольше work_mem. И понимать, что эти настройки делают. Если вы видите бенчмарк, даже с данными, на которых тестировалось, и даже со скриптами, но там сказано, что «мы тестировали с настройками по умолчанию» — по умолчанию MongoDB и Postgres — все, можно закрывать. Настройки по умолчанию — это неконструктивный способ понимать, что быстрее.
- Нетипичная нагрузка. У вас 90% времени что-то читает, 10% что-то пишет, а вы решили: напишем benchmark, который фифти/фифти — и так, и так делает. Зачем такое тестировать? То есть вы что-то соптимизируете, просто это вам в продакте не сильно поможет.
- Маркетинг и подгон. Тут у меня есть небольшая кулстори. Я достоверно знаю, что были лет …дцать назад такие производители железа, которые знали бенчмарки, по которым некий журнал тестирует компьютеры. Они свое железо собирали так, чтобы на этих бенчмарках выглядело хорошо. В результате все очень здорово продавалось. Это первый способ подгона.
Другой способ подгона — можем MongoDB привести. Они всегда на маленьких DataSet’ах свои бенчмарки гоняют, поэтому у них все помещается в памяти, здорово работает. Когда у вас DataSet перестает помещаться в память, все перестает здорово работать.
То есть нужно понимать, что это существует, это не иллюзорная вещь.
- Ну, и другие свойства. Близкий мне пример: Oracle против Postgres — что быстрее? Может быть, Oracle быстрее в 10 раз, но он и стоит как не в себя. Это надо тоже учитывать. А, может, и нет — я не бенчмаркал Oracle ни разу и вообще его никогда не видел, если честно.

Для создания полноты картины начну с того, как не надо бенчмаркать код. Самый простой способ — gettimeofday(). Дедовский метод, когда у нас есть кусочек кода, мы хотим узнать, насколько он быстрый или медленный — мы померили время в начале, выполнили код, померили время в конце, посчитали дельту и сделали вывод, что код выполняется столько времени.

На самом деле не самый идиотский способ, он удобен, например, когда у вас этот код иногда тупит, то есть очень редко — один раз на 10000 запросов, например. Плюс к этому он не такой дорогой, как принято думать, что у вас не происходит системный вызов, как можно было бы думать. В Linux этот механизм называется VDSO. По сути, у вас есть страница в ядре, которая мапится в адресное пространство всех процессов, и ваш gettimeofday() превращается в обращение к оперативной памяти, никакого syscall’а не происходит.
Не стоит его использовать, несмотря на то, что он дешевый, если вы делаете что-то со спинлоками. Потому что спинлоки сами по себе довольно быстро работают. То есть то, что вы меряете, должно хотя бы миллисекунды выполняться, иначе у вас погрешность будет на уровне измерений.

Инструменты, такие как strace, ltrace, truss — прикольные инструменты, у них есть флажок -с, который показывает, сколько времени у вас какие syscall’ы выполнялись. Ну, ltrace измеряет библиотечные процедуры, а strace — syscall’ы, но тоже, в принципе, могут быть удобны где-то в каких-то задачах. Не могу сказать, что я этим часто пользуюсь.

Gprof, есть такой прикольный инструмент, на слайде приводится пример его текстового отчета. Тоже понятно — вот у нас есть процедуры в программе, вот столько раз они были вызваны, столько времени это в процентах выполнялось. Простой, наглядный отчет, если вы написали микробенчмарк, то можно пользоваться.
С помощью gprof еще можно генерировать такие картинки:

Это, скорее, пример того, как не надо делать. Запомните эту картинку, здесь 6 квадратиков. Обратите внимание, как много места они занимают, тут имена процедур, над стрелками все время что-то написано, ничего не понятно — очень много места занимает. Мы увидим намного более наглядные отчеты, чем этот. Но, в принципе, красивая картинка, можно начальству показать, понтануться.

Отладчики. На самом деле, это уже пример инструментов, которые приходится использовать на практике при профайлинге, потому что у них есть клевые свойства выполнять команды batch’ем и можно написать в этот набор batch-команд (bt) получение бэктрейса. Это очень удобно при отладке lock contention, когда у вас происходит борьба за локи.

http://habr.ru/p/310372/
Здесь у меня есть небольшая кулстори. Это, по-моему, был самый первый патч, который я написал для Postgres. Или второй, не помню. У Postgres есть своя реализация хэш-таблиц, сильно заточенных под задачи Postgres. И она, в том числе, может быть создана с такими флагами, чтобы использоваться разными процессами. Пришел клиент с проблемой, что «вот у меня на таких-то запросах, в такой-то схеме все тупит, помогите». Интересно, что сначала с помощью приема с бэктрейсом это выглядело так, что вы запускаете gdb 10 раз, в 5 случаях у вас бэктрейс висит на взятии лока, а еще в половине случаев — на чем-то другом, то есть явно у вас процесс часто висит на локе, что-то не так.
Кстати, мы выложили в открытый доступ видеозаписи последних пяти лет конференции разработчиков высоконагруженных систем HighLoad++. Смотрите, изучайте, делитесь и подписывайтесь на канал YouTube.
По бэктрейсу удалось найти, что это за код такой, который то берет, то освобождает лок. Это долгая история, можете по ссылке прочитать статью на Хабре. Там же есть ссылка на обсуждение в hackers, где есть технические детали.
На слайде выше — кусочек кода, между взятием и освобождением лока, он в свою очередь там проваливался куда-то в dynahash, где крутился на взятии спинлока. Это удалось с помощью отладчиков найти, исправить, предложить патч. И тот спинлок, который в dynahash (это хэш-табличка в Postgres), превратили в 8 или 16 спинлоков, которые при определенных условиях берутся разные. Удалось его пошардить и это уже есть в 9.6.

Perf — замечательный инструмент, потому что perf top показывает топ процедур. В данном случае в указанном процессе, сколько времени они выполняются. Вверху мы видим 30%, 20% и мы видим ResourceOwner — это неспроста в именах процедур, потому что следующая кулстори тоже про реальный патч.

Пришел клиент, сказал: «У меня такие запросы и такая схема. Все тупит. Что делать?». Начали отладку. А у него энтерпрайзное приложение, у него есть таблицы, тысяча дочерних таблиц (в Postgres, если кто не знает, есть наследование таблиц). И с помошью perf top мы видим, что в ResourceOwner все тупит. ResourceOwner — это такой объект (насколько слово объект применимо для языка С), который хранит в себе разные ресурсы, файлы, шареную память и что-то еще. И он написан в предположении, что обычно мы ресурсы выделяем и кладем в массив, а освобождаем в обратном порядке. Поэтому при удалении ресурсов, он начинает их искать с конца. Размер массива он знает, ну, в смысле — у него есть индекс последнего элемента. Оказалось, что это условие выполняется не всегда и ему приходится во все стороны искать по этому массиву, поэтому он тупит. Патч заключается в том, что при определенном количестве ресурсов (около 16 или число порядка этого) этот массив превращается в хэш-таблицу. Когда вы конфликт разрешаете, вы по хэшу пришли в заданный индекс массива, а потом идете в одну из сторон.
Кстати, если кого-то интересует вопрос, кому в третьем тысячелетии приходится писать свои хэш-таблицы, то вот я сижу и в двух патчах пишу свои хэш-таблицы, потому что не подходят нам стандартные реализации. Это тоже уже есть в 9.6, там ResourceOwner не тупит, если у вас партицированная сильно таблица. В смысле, он все еще тупит, но слабее.

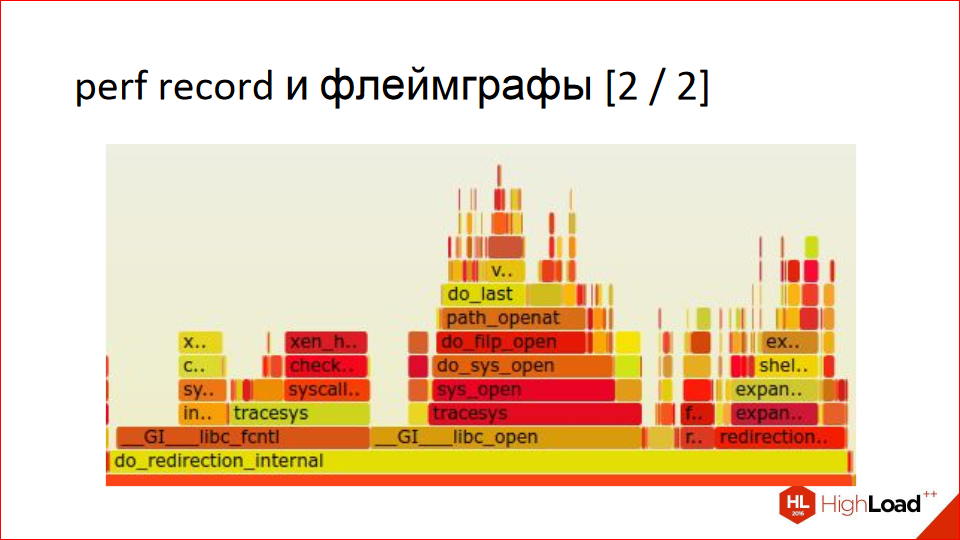
С помощью perf можно строить такие красивые картинки, они называются флеймграфы. Это читается снизу вверх. Внизу у нас есть процедура, потом — пропорционально тому, сколько времени где она проводит и в свою очередь вызывает — у нас поделено на другие процедуры. Потом вверх идем, у нас так же пропорционально делится, сколько времени она где проводит. И далее вверх. Это очень наглядно, но может быть непривычно, если вы первый раз такое видите. На самом деле, это очень наглядный отчет, намного нагляднее примера с графом, который Gprof строит. Обратите внимание, как экономно используется место, на слайдах это нельзя показать, но во все это можно кликать. И у него есть подсказка, которая показывает проценты.
Вот увеличенный кусок, это где-то из середины часть:
Собственно это, наверное, все. Мы этим часто пользуемся. На предыдущей работе мы таким же образом анализировали логи. Там была другая история — был АК-кластер, распределенное приложение, и мы по логам строили такие вещи, пытаясь понять, где же у нас тормозит код. Логи, разумеется, нужно было со всех бэкендов агрегировать. В общем, удобная штука, всем рекомендую.
http://youtu.be/tDacjrSCeq4
Это Брендон Грегг. Он изобрел flame graphs и чуть ли не сам perf. Наверное, он не совсем один писал, но существенно в него вложился. Также он известен в видео на YouTube, где он орет на жесткие диски в дата-центре, и у него увеличивается latency при обращении к этим дискам — замечательное видео. Если кому интересно, это реальная тема, правда, с SSD работает это или нет — не знаю.
Недавно было похожая история, про то, как во время пожарных учений в банке вырубило весь дата-центр, потому что слишком громко свистели трубы, которые подают газ, который тушит огонь. То есть вибрация воздуха вырубила все диски.
К Брендону мы еще вернемся, потому что он знает все про профайлинг и очень много в это все вложил, сейчас он этим занимается в Netflix.

http://eax.me/freebsd-pmcstat/
Pmcstat — это инструмент исключительно под FreeBSD. Когда я делал эти слайды, я думал что ни у кого не будет FreeBSD, поэтому здесь нет особых подробностей про pmcstat, т.к. остальным это не очень интересно. Но краткое содержание такое, что с его помощью можно делать все то же самое, что с помощью perf. Он также делает top, тоже строит flame graphs и он ничем не хуже, просто команды другие. Кому интересно, вот ссылка на конкретную статью.

Переходим к более серьезным инструментам. SystemTap. Выше до этого был профайлинг CPU, где что-то тормозит, а SystemTap позволяет делать еще больше — вы можете посмотреть буквально на все, что угодно, в ядре, померить, сколько у вас пакетов по сети уходит, обращение к диску померить и все что угодно, ограничено только вашей фантазией. SystemTap позволяет писать вот такие скрипты, в данном случае трейсится вызов ip_rcv, то есть получение какого-то iP пакета.

Плюсы и минусы. Главных минусов 2. Во-первых, это не какой-то официальный инструмент для Linux, это чуваки из Red Hat запилили в основном для себя, для отладки своего кода, как я это понимаю. Его очень неудобно устанавливать, нужно скачивать пакет с отладочными символами ядра, потом его устанавливать, потом очень долго компилить сам SystemTap, он тоже так не просто компилируется, нужны версии. Но в конечном счете оно начинает работать. Второй недостаток — то, что вам нужно хорошо понимать базу того, что вы хотите проанализировать, потрейсить. Не все знают наизусть ядро Linux. Но если вы хорошо знаете свой код, вы можете это использовать.
Есть интересное свойство — код транслируется в С, потом это компилируется в модуль ядра, который подгружается и собирает всю статистику, все трейсит. При этом вы можете не бояться делить на ноль, разыменовывать указатели неправильные. Если это написать в скриптовом языке, это не приведет к крэшу ядра, оно просто аккуратно свернет лапки и выгрузится, но ваше ядро продолжит работать.
Есть автоматический вывод типов. Правда, там всего два или три типа, зато они автоматически выводятся.
Лично мне страшно было бы использовать это в продакшне, потому что он не производит впечатления стабильного инструмента. Один тот факт — у вас скрипт секунд 10 компилируется и загружается, а что в это время будет там тормозить, не тормозить, не очень понятно. Я бы не рискнул, но, может, вы смелее.

DTrace — это тоже прикольный инструмент, не только для FreeBSD, в Linux тоже есть, все хорошо. Он похож на SystemTap, в этом примере мы трейсим системный вызов poll, притом для процессов, которые называются postgres. Здесь трейсится, с какими аргументами он вызывается и что возвращается.

Плюсы и минусы. Во-первых, он, в отличие от SystemTap, прямо есть в системе из коробки, ничего не надо устанавливать, компилировать. Есть во FreeBSD, в Mac OS. Для Linux он тоже есть, если вы каким-то образом используете Oracle Linux. Кроме того, есть проект dtrace4linux на GitHub, он компилируется, работает, я проверял. В принципе, можно пользоваться.
В отличие от SystemTap, DTrace не страшно использовать в продакшне — заходите на ваш Mac в боевом окружении и трейсите все, что угодно. По моим субъективным ощущениям, DTrace больше для админов, потому что у вас в ядре есть куча пробов на все что угодно, вам не нужно знать кодовую базу, вы просто говорите: «Хочу собрать статистику по IP-пакетам — сколько пришло, сколько ушло». Кстати, есть наборы готовых утилит, вам не нужно обязательно скриптами все самим писать. DTrace Toolkit называется.
А SystemTap скорее не для админов, а для разработчиков: «Я знаю код ядра, я хочу вот в этом месте потрейсить, без написания какого-то кода, не патча его».

До сих пор мы говорили про профайлинг в плане использования ЦПУ, но еще частая проблема — это «а что, если у меня отжирается много памяти?». Лично мне нравится инструмент HeapTrack, если вы когда-нибудь использовали Valgrind Massif, то он такой же, только быстрый, но с ограничением — работает только на Linux.
Здесь (на слайде выше) пример текстового отчета, найдено место, которое отъедает больше всего памяти, есть конкретные номера строк, имена файлов с исходниками и так далее.

Кроме того, он может строить вот такие красивые отчеты в инструменте Massif Visualizer. В нем можно все открывать, это все в динамике. Там память росла, потом достигла своего пика, потом она начала падать, освобождаться, выделяться, справа есть трейсы. Все очень наглядно и красиво.

Плюсы и минусы. Он быстрый, в отличие от Valgrind. Может цепляться к запущенным процессам, можно запускать под ним процессы. Красивые отчеты. Он умеет находить мемори лики. Немного криво их находит, если у вас стандартная библиотека языка выделила 16 кБ под какие-то свои внутренние нужды и потом их не освободила, потому что «ну, зачем?», он скажет, что это мемори лик. Но, в принципе, довольно полезный инструмент, несмотря на все это.
Можно построить гистограмму, что у меня кусочки размером в 8 байт выделяются больше всего, а кусочки памяти размером 32 байта выделяются чуть реже. Такая красивая гистограмма получается.
Про стек он ничего не знает, если вам нужен стек или нужно что-то за пределами Linux, то используйте Valgrind. Я Linux’оид, поэтому ничего не знаю про Valgrind.

Есть такая тема в Linux, называется BPF, изначально это был Berkeley Packet Filter и, как можно догадаться по названию, имеет отношение к Berkeley и какой-то там фильтрации пакетов, но BPF он где-то в 2.6 ветку приземлил в свое время. Но в результате его доработали и, по сути, он превратился, не без помощи уже упомянутого Брендона Грегга, в DTrace в Linux.
Он позволяет делать абсолютно все то же самое. Недавно у Брендона был пост в блоге, где он пишет, что в ядро 4.9, которое сейчас все еще релиз-кандидат, но скоро будет, туда приземлились окончательно изменения в BPF. Больших, крупных изменений не будет, может, они что-то зарефачат, может, немного поправят, но чтобы активно добавлять — такого уже не будет.
Bcc — это набор утилит, который использует BPF для профайлинга разных мест ядра. На картинке это все названия утилит. Вы фактически любое место в ядре можете потрейсить, попрофайлить в ядре.
Недостаток у BPF в том, что у него нет еще своего скриптового языка, как есть у DTrace, SystemTap, но в этом направлении уже есть наработки. В частности, парни из Red Hat подключились, они взяли свой SystemTap и сделали его сборку для BPF. То есть используется язык SystemTap, но работает оно на BPF. Оно пока какое-то ограниченное, вообще не поддерживает строковый тип, но они работают над этим.
Суть в том, что BPF — это, похоже, наше далекое светлое будущее, и он является наибольшим общим знаменателем, к которому в итоге пришли все компании, потому что там были какие-то скрипты у Facebook, был SystemTap у Red Hat, потому что им нужно было для разработки что-то такое трейсить. Они свою задачу решили и им больше ничего не надо. А BPF — это то, что должно в результате решать нужды всех, и оно уже прямо в ядре из коробки готовое и, похоже, в итоге все к этому придут и через пару лет наступит большое счастье.

Главный вопрос, который будоражит умы миллионов: «Хорошо, много инструментов, что и когда использовать?». Что лично я использую. Отладчики. Если вы подозреваете lock contention, его легко довольно заподозрить, вы в perf top не будете видеть, что кто-то жрет большое количество времени, наверное, оно висит в локах. Perf, если вы думаете, что уперлись в СPU, это в обычном htop видно — вот процесс, он жрет много СPU. Pmcstat, если у вас FreeBSD, SystemTap, мне кажется, бесполезный инструмент по той причине, что есть perf — он удобнее. Имеется в виду в контексте именно профайлинга, то есть профайлить я могу perf’ом, а для трейсировки SystemTap он ничего, он только не про профайлинг.
DTrace — это, если вы сидите под Mac, то он — ваше все, потому что он умеет все.
HeapTrack для памяти, Vagrant Massif — если вы на Linux, и BPF — это светлое будущее, но сейчас я бы не стал ставить 4. 9 в продакт, но, может, вы смелее, опять же.

Хочу порекомендовать книги с соавторством Брендона Грегга.
Первая — Systems Performance: Enterprise and the Cloud — потрясающая книга, ее обязательно нужно читать всем поголовно. Это одна из лучших книг, которую я читал и которая связана с программированием. Она взорвала мозг мне, потом шрапнелью задела мозги коллег, в общем, просто прочитайте.
Вторая книга про DTrace — тоже книга Брендона Грегга в соавторстве с парнем, который я не знаю, чем примечателен. Ее я не читал, полистал, это такой большой сборник рецептов про DTrace. Там дается команда, и что она делает, примеры скриптов. И так на тысячу страниц. Мне кажется, это не очень интересное чтиво, но если вы сильно интересуетесь DTrace, вечером полистать вредно не будет.
Куча онлайн-ресурсов:
- Это ссылка на мой бложик;
- http://www.brendangregg.com/blog/index.html — блог Брендона Грегга — подписаться обязательно, он там постит умопомрачительные вещи.
- http://dtrace.org/blogs/ — блог DTrace я тоже читаю, там есть интересные статьи.
- Дальше. https://sourceware.org/systemtap/ — сайт SystemTap’а.
- FreeBSD в wiki — https://wiki.freebsd.org/DTrace
- И в handbook’е можно прочитать про DTrace. Даже если вы пользуетесь Mac, все равно полистайте handbook, там есть хорошие примеры — https://www.freebsd.org/doc/handbook/dtrace.html
- И в конце мануал Intel — http://www.intel.com/content/www/us/en/processors/architectures-software-developer-manuals.html. Там можно почитать, собственно, на чем паразитирует perf, что такое РMC, прямо в процессорах есть инструкции, которые позволяют все это мерить.
У меня все.
Этот доклад — расшифровка одного из лучших выступлений на конференции разработчиков высоконагруженных систем HighLoad++. До конференции HighLoad++ 2017 осталось меньше месяца.
У нас уже готова Программа конференции, сейчас активно формируется расписание.
В этом году доклады по тегу "Правильные ручки":
- Хочу всё сжать / Андрей Аксенов
- Защищаемость от DDoS на этапе проектирования системы / Рамиль Хантимиров
- Чем заняться вечером, если я знаю, сколько будет ++i + ++i / Андрей Бородин
- Как развивать библиотеку компонентов, не ломая её / Артур Удалов
Также некоторые из этих материалов используются нами в обучающем онлайн-курсе по разработке высоконагруженных систем HighLoad.Guide — это цепочка специально подобранных писем, статей, материалов, видео. Уже сейчас в нашем учебнике более 30 уникальных материалов. Подключайтесь!

zuborg
Интересный материал, хотя и несколько поверхностный
Но все равно спасибо! )