
Движущая сила микросервисов
Возможность разрабатывать, развертывать и масштабировать различные бизнес-функции независимо друг от друга — это одно из самых разрекламированных преимуществ перехода на микросервисную архитектуру.
Пока властители дум всё ещё не могут определиться, справедливо ли это утверждение или нет, микросервисы уже успели войти в моду — причем до такой степени, что для большинства стартапов они де-факто стали архитектурой, выбираемой по умолчанию.
Однако, когда дело доходит до тестирования (или, чего похуже, разработки) микросервисов, выясняется, что большинство компаний по-прежнему испытывает привязанность к допотопному способу тестирования всех компонентов вместе. Создание сложной инфраструктуры считается обязательным условием для проведения сквозного (end-to-end) тестирования, при котором набор тестов для каждого сервиса обязательно должен быть выполнен — делается это для того, чтобы убедиться, что в сервисах не появилось регрессий или несовместимых изменений.
От переводчиков. В оригинальной статье Синди Шридхаран используется большое количество терминологии, для которой нет устоявшихся русских аналогов. В некоторых случаях используются употребляемые англицизмы, их нам кажется разумным писать по-русски, а в спорных случаях, во избежание неверной интерпретации, мы будем писать и исходный термин.
Сегодня мир не испытывает недостатка в книгах и статьях, посвященных лучшим практикам тестирования программного обеспечения. Однако в нашей сегодняшней статье мы сосредоточимся исключительно на теме тестирования бэкенд-сервисов и не станем затрагивать тестирование десктоп-приложений, систем с особыми требованиями по технической безопасности, инструментов с графическим интерфейсом и остальных видов ПО.
Стоит заметить, что в понятие «распределенной системы» различные специалисты вкладывают разный смысл.
В рамках нашей сегодняшней статьи, под «распределенной системой» имеется в виду система, состоящая из многочисленных движущихся частей, каждая из которых обладает различными гарантиями и видами отказов, эти части работают вместе в унисон для того, чтобы реализовывать определенную бизнес-функцию. Пусть моё описание и весьма отдаленно похоже на классическое определение распределенных систем, но оно применимо к тем системам, с которыми мне регулярно приходится сталкиваться — и я готова поспорить, что как раз такие системы подавляющее большинство из нас разрабатывает и поддерживает. Далее в статье речь идёт про распределенные системы, которые сегодня принято называть «микросервисной архитектурой».
«Полный стек в коробке»: история-предостережение
Мне часто приходится сталкиваться с компаниями, которые пытаются целиком воспроизвести топологию сервисов локально на ноутбуках разработчиков. С этим заблуждением мне пришлось столкнуться лично на прошлом месте работы, где мы пытались развернуть весь наш стек в Vagrant-боксе. Репозиторий Vagrant называли «полным стеком в коробке»; как вы уже могли догадаться, идея состояла в том, чтобы одна простая команда vagrant up должна была позволить любому инженеру в нашей компании (даже фронтенд и мобильным разработчикам), развернуть абсолютно весь стек на их рабочих ноутбуках.
Собственно говоря, это не была полноценная микросервисная архитектура масштабов Amazon, содержащая тысячи сервисов. У нас было два сервиса на бекэнде: API-сервер, основанный на gevent, и работающие в фоновом режиме асинхронные воркеры на Python, у которых был целый клубок из нативных зависимостей, включавших boost на C++ — причем, если мне не изменяет память, он компилировался с нуля каждый раз, когда запускался новый бокс на Vagrant.
Моя первая рабочая неделя в этой компании целиком ушла лишь на то, чтобы локально поднять виртуальную машину и победить великое множество ошибок. Наконец, к вечеру пятницы мне удалось заставить Vagrant работать, и все тесты успешно отработали на моём ПК. Напоследок я решила задокументировать все проблемы, с которыми мне пришлось столкнуться, чтобы у других разработчиков было меньше подобных проблем.
И что же вы думаете, когда новоприбывший разработчик начал настраивать Vagrant, то он столкнулся с совсем другими ошибками — причём у меня даже не получилось воспроизвести их на моей машине. По правде говоря, вся эта хрупкая конструкция и на моем ноутбуке дышала на ладан — я боялась даже обновить библиотеку для Python, поскольку выполненный однажды pip install ухитрился поломать настройки Vagrant, и при локальном запуске перестали проходить тесты.
В процессе разбора полетов выяснилось, что аналогичным образом дела с Vagrant обстояли и у программистов из команд мобильной и веб-разработки; устранение проблем с Vagrant стало частым источником запросов, поступающих в команду саппорта, где я тогда работала. Конечно, кто-то может заявить, что мы просто должны были потратить больше времени на то, чтобы раз и навсегда «пофиксить» настройки Vagrant, чтобы всё «просто работало», в свою защиту скажу, что описанная история происходила в стартапе, где времени и инженерных циклов вечно ни на что не хватает.
Фрэд Эбер написал замечательную рецензию на данную статью, и сделал замечание, которое в точности описывает мои ощущения:
… просьба запустить облако на машине разработчика эквивалентна необходимости поддержки нового облачного провайдера, причем худшего из всех возможных, с каким вам только доводилось сталкиваться.
Даже при том условии, что вы будете следовать самым современным методикам эксплуатации — «инфраструктура как код», неизменямая инфраструктура — попытка развернуть облачное окружение локально не принесёт вам пользы, соизмеримой с усилиями, которые уйдут у вас на его поднятие и долгосрочную поддержку.
Поговорив со своими друзьями, я выяснила, что описанная проблема отравляет жизнь не только тем, кто работает в стартапах, но и тем, кто трудится в больших организациях. За последние несколько лет мне довелось услышать немало анекдотов о том, с какой легкостью разваливается подобная конструкция и как дорого обходится эксплуатации ее поддержка. Теперь я твердо уверена в том, что идея развертывания всего стека на ноутбуках разработчиков порочна вне зависимости от того, какой размер имеет ваша компания.
Фактически, подобный подход к микросервисам равносилен созданию распределенного монолита.
Предсказание на 2020 год: монолитные приложения снова в моде, после того, как люди ознакомились с недостатками распределенных монолитов.
Как замечает блогер Тайлер Трит:
От души посмеялся над обсуждением микросервисов на Hacker News. «Разработчики должны иметь возможность развернуть окружение локально, всё остальное — это признаки плохих инструментов». Ну да, конечно, умник, попробуй запусти штук 20 микросервисов с разными БД и зависимостями на своем Макбуке. Ах да, я же забыл, что docker compose решит все твои проблемы.
Везде одно и то же. Люди начинают создавать микросервисы, при этом не меняя своего «монолитного» склада ума, и это всегда заканчивается настоящим театром абсурда. «Мне нужно запустить все это на своей машине с выбранной конфигурацией сервисов для того, чтобы протестировать одно единственное изменение». Что же с нами стало…
Если кто-нибудь, не дай бог, случайно чихнет, то мой код сразу станет не поддающимся тестированию. Что ж, удачи вам с подобным подходом. Даже невзирая на то, что масштабные интеграционные тесты, затрагивающие значительное число сервисов, являются анти-паттерном, в этом по-прежнему тяжело убедить остальных. Переход к микросервисам означает использование правильных инструментов и методов. Перестаньте использовать старые подходы в новом контексте.
В масштабах всей индустрии, мы по-прежнему привязаны к методологиям тестирования, изобретенным в далекую от нас эпоху, которая разительно отличалась от той реальности, в которой мы находимся сегодня. Люди по-прежнему увлечены идеями вроде полного покрытия тестами (настолько сильно, что в некоторых компаниях merge будет заблокирован, если патч или бранч с новой фичей приводит к понижению степени покрытия кодовой базы тестами более, чем на определенную долю процента), разработкой через тестирование и полным end-to-end тестированием на системном уровне.
В свою очередь, такие убеждения приводят к тому, что большие инженерные ресурсы вкладываются в построение сложных CI пайплайнов и замысловатых локальных окружений разработки. Достаточно быстро поддержка подобной расширенной системы оборачивается необходимостью содержать команду, которая будет создавать, поддерживать, устранять неполадки и развивать инфраструктуру. И если большие компании могут себе позволить настолько глубокий уровень изощрённости, то всем остальным лучше просто воспринимать тестирование как оно есть: это наилучшая возможная верификация системы. Если мы будем с умом подходить к оценке стоимости нашего выбора и и идти на компромиссы, то это и будет наилучшим вариантом.
Спектр тестирования
Традиционно принято считать, что тестирование производится перед релизом. В некоторых компаниях были — и существуют поныне — отдельные команды тестировщиков (QA), главной обязанностью которых является выполнение ручных или автоматизированных тестов для ПО, созданного командами разработки. Как только компонент ПО проходит QA, его передают команде эксплуатации для запуска (в случае сервисов), или же релизят в виде продукта (в случае десктоп-приложений и игр).
Эта модель медленно, но верно уходит в прошлое — по крайней мере, в отношении сервисов; на сколько я могу судить по стартапам в Сан-Франциско. Теперь команды разработчиков отвечают и за тестирование, и за эксплуатацию сервисов, которые они создают. Этот новый подход к созданию сервисов я нахожу невероятно мощным — он по-настоящему позволяет командам разработчиков думать о масштабе, целях, компромиссах и компенсациях на всем спектре методов тестирования — причем в реалистической манере. Для того, чтобы всецело разобраться, как функционируют наши сервисы, и удостовериться в корректности их работы, нам очевидно требуется возможность выбора правильного подмножества методов тестирования и инструментов с учетом требуемых параметров доступности, надежности и корректности работы сервиса.
Прямо как с языка сняли. Тестирование перед деплоем — это частичная подготовка к тестированию в продакшне. Перефразировав ваше утверждение: тестирование перед деплоем может научить, помочь прорепетировать и усилить необъективные ментальные модели системы, и на самом деле работает против вас в проде, делая вас невосприимчивым к реальности.
По большому счету, понятие «тестирование» может охватывать несколько видов деятельности, которые традиционно относят к сферам «релиз-инжиниринга», эксплуатации или QA. Некоторые из методов, перечисленных в таблице ниже, строго говоря не считаются формами тестирования — например,в официальном определении chaos engineering классифицируется как форма эксперимента; кроме того, приведенный список отнюдь не является исчерпывающим — в нем отсутствуют сканирование уязвимостей (vulnerability testing), тестирование на проникновение (penetration testing), моделирование угроз (threat modeling) и прочие методы тестирования. Однако, в таблицу включены все самые популярные способы тестирования, с которыми мы сталкиваемся ежедневно.

Разумеется, таксономия методов тестирования в приведенной таблице не совсем отражает реальность: как показывает практика, некоторые методы тестирования могут относиться сразу к обеим категориям. Так, к примеру, «профилирование» в ней отнесено к тестированию в продакшне — однако, к нему часто прибегают и во время разработки, поэтому его можно отнести и к тестированию в пре-продакшне. Аналогичным образом, shadowing — метод, при котором небольшое количество трафика с продакшна прогоняется по небольшому количеству тестовых инстансов — может считаться и тестированием в продакшне (ведь мы используем реальный трафик), и тестированием в пре-продакшне (ведь реальных пользователей оно не затрагивает).
Различные языки программирования обладают различной степенью поддержки тестирования приложений в продакшне. Если вы пишите на Erlang, то вполне возможно вы знакомы с руководством Фреда Эбера по использованию примитивов виртуальной машины для отладки систем в продакшне пока они продолжают работать. Языки вроде Go поставляются вместе со встроенной поддержкой профилирования кучи, блокировок, CPU и горутин для любого из запущенных процессов (тестирование в продакшне) или при запуске юнит-тестов (это можно квалифицировать как тестирование в пре-продакшне).
Тестирование в продакшне — замена тестирования в пре-продакшне?
В своей прошлой статье я уделила много внимания тестированию в «пост-продакшне», в основном с точки зрения наблюдаемости. К таким формам тестирования относятся мониторинг, оповещения, исследование и динамическая инструментация (вставка анализирующих процедур в исполняющийся код). Возможно, к тестированию в продакшне можно отнести и такие техники, как gating и использование флагов функций (feature flags, при помощи которых можно включать/отключать функциональность в коде с помощью конфигурации). Взаимодействие с пользователем и оценка пользовательского опыта — например, A/B тестирование и мониторинг реального пользователя также относятся к тестированию в продакшне.
В узких кругах идет обсуждение того, что такие методы тестирования могут прийти на смену традиционному тестированию в пре-продакшне. Недавно подобную провокационную дискуссию развернула в Twitter Сара Мей. Конечно, она в ней сразу поднимает несколько трудных тем, и я не во всем с ней согласна, но многие из ее замечаний в точности соответствуют моим ощущениям. Сара заявляет следующее:
Народная мудрость утверждает следующее: прежде, чем зарелизить код, полный набор регрессионных тестов должен стать «зеленым». Необходимо быть уверенным в том, что изменения не поломают чего-нибудь где-то еще в приложении. Но есть способы убедиться в этом, не прибегая к набору регрессионных тестов. Особенно сейчас, с расцветом сложных систем мониторинга и понимани я частоты ошибок на стороне эксплуатации.
С достаточно продвинутым мониторингом и большим масштабом реалистичной стратегией становится написание кода, его «пуш» в прод и наблюдение за количеством ошибок. Если в результате что-то в другой части приложения сломается, это станет очень быстро понятно по возросшему количеству ошибок. Вы можете пофиксить проблему или сделать откат. Проще говоря, вы позволяете своей системе мониторинга выполнять ту же роль, что регрессионные тесты и continuous integration в других командах.
Многие люди восприняли это так, будто стоит убрать тестирование перед продакшном вовсе как невостребованное, но я думаю, что идея была не в этом. За этими словами скрывается факт, с которым многие разработчики ПО и профессиональные тестировщики никак не могут смириться — одно только ручное или автоматизированное тестирование зачастую могут быть недостаточными мерами — вплоть до того, что порой они совсем нам не помогают.
В книге «Lessons Learned in Software Testing » (официального перевода на русский язык нет, но есть любительский) есть глава под названием «Автоматизированное тестирование», в которой авторы утверждают, что автоматические регрессионные тесты находят лишь меньшинство багов.
Согласно результатам неофициальных опросов, процент багов, которые обнаруживаются при помощи автоматизированных тестов, на удивление низок. Проекты со значительным количеством удачно спроектированных автоматизированных тестов сообщают, что регрессионные тесты способны обнаруживать 15 процентов от общего количества багов.
Автоматизированные регрессионные тесты обычно помогают обнаружить больше багов во время разработки самих тестов, чем при выполнении тестов на последующих этапах. Однако, если вы возьмете ваши регрессионные тесты и найдете способ переиспользовать их в различных окружениях (например, на другой платформе или с другими драйверами), то ваши тесты с большой вероятностью смогут обнаружить проблемы. По факту, в таком случае они уже не являются регрессионными тестами, поскольку они используются для тестирования конфигураций, которые прежде не тестировались. Тестировщики сообщают, что подобная разновидность автоматизированных тестов способна находить от 30 до 80 процентов ошибок.
Книга, безусловно, успела немного устареть, и мне не удалось найти ни одного недавнего исследования насчет эффективности регрессионных тестов, но здесь важен сам факт того, что мы настолько привыкли к тому, что лучшие практики тестирования и дисциплины основаны на безусловном превосходстве автоматизированного тестирования, и любая попытка усомниться приводит к тому, что вас считают еретиком. Если я что-то и уяснила для себя из нескольких лет наблюдений за тем, как отказывают сервисы, то это вот что: тестирование перед продакшном — это наилучшая возможная верификация некоторого небольшого набора гарантий системы, но при этом, его одного будет явно недостаточно, для проверки систем, которые будут работать длительное время и с часто меняющейся нагрузкой.
Возвращаясь к тому, о чем писала Сара:
Эта стратегия строится на многочисленных предположениях; в ее основе лежит то, что в наличии у команды есть сложная система эксплуатации, которой нет у большинства команд разработчиков. И это не все. Предполагается, что мы можем сегментировать пользователей, отображать изменения-в-процессе каждого разработчика на различном сегменте, и также определять частоту ошибок для каждого сегмента. Помимо этого, подобная стратегия предполагает такую продуктовую организацию, которая комфортно чувствует себя при экспериментах с «живым» трафиком.Опять же, если команда уже производит A/B тестирование для изменений в продукте на «живом» трафике, то это просто расширяет саму идею до изменений, сделанных разработчиками. Если у вас получится все это осуществить и получать фидбек на изменения в реальном времени — будет просто замечательно.
Выделение — мое, это, как мне кажется, самый большой блок на пути обретения большей уверенности создаваемых системах. По большей части, самым большим препятствием для перехода к более комплексному подходу в тестировании является необходимый сдвиг в мышлении. Идея привычного тестирования в пре-продакшне прививается программистам с самого начала их карьеры, в то время как идея экспериментирования с «живым» трафиком видится им либо прерогативой инженеров эксплуатации, либо встречей с чем-то страшным вроде аварийной сигнализации.
Все мы с детства приучены к неприкосновенной святости продакшна, с которым нам не положено играться, даже если это лишает нас возможности проверки наших сервисов, и все, что остается на нашу долю — это другие окружения, которые суть есть лишь бледные тени продакшна. Проверка сервисов в средах, «максимально похожих» на продакшн, сродни генеральной репетиции — вроде бы от этого и есть некоторый прок, однако между выступлением в полном зале и пустой комнате есть огромная разница.
Неудивительно, что подобное мнение разделили многие собеседники Сары. Ее ответ им был следующим:
Мне тут пишут: «но ваши пользователи увидят больше ошибок!» Это утверждение прямо-таки состоит из неочевидных заблуждений — я даже не знаю, с чего мне начать…
Перенос ответственности за поиск регрессий с тестов на мониторинг в продакшне выльется в то, что пользователи скорее всего будут генерировать больше ошибок в вашей системе. Это означает, что вы не сможете позволить себе применить подобный подход без соответствующего изменения вашей кодовой базы — все должно работать таким образом, чтобы ошибки были меньше заметны (и производили меньший эффект) на ваших пользователей. На самом деле, это такое полезное давление, которое может помочь сделать опыт ваших пользователей значительно лучше. Некоторые пишут мне, что «пользователи сгенерируют больше ошибок» -> «пользователи увидят больше ошибок» -> «вам плевать на ваших пользователей!» Нет, это абсолютно не так, просто вы думаете неправильно.
Вот это бьет в самую точку. Если мы переносим регрессионное тестирование в мониторинг после продакшна, то такое изменение потребует не просто смены образа мышления, но и готовности принимать риски. Гораздо важнее то, что потребуется полный пересмотр дизайна системы, а также серьезные вложения в продвинутые практики релиз-инжиниринга и инструменты. Другими словами, здесь речь идет уже не просто про архитектуру с учетом сбоев — по сути, здесь идет программирование с учетом сбоев. В то время как золотым стандартом всегда было программирование ПО, которое работает без сбоев. И вот здесь подавляющее большинство разработчиков точно почувствуют себя некомфортно.
Что тестировать в продакшне, а что — в пре-продакшне?
Поскольку тестирование сервисов представлено целым спектром, обе формы тестирования должны быть учтены во время проектирования системы (причем здесь подразумеваются как архитектура, так и код). Это позволит понять, какую функциональность системы обязательно нужно будет протестировать до продакшна, а какие ее характеристики, больше напоминающие длинный хвост из особенностей, лучше исследовать уже в продакшне с применением соответствующих средств и инструментов.
Как определить, где лежат эти границы, и какой метод тестирования подойдет для той или иной функциональности системы? Это должны решать вместе разработка и эксплуатация, и, повторюсь, это должно быть сделано на этапе проектирования системы. Подход «сверху-вниз» в применении к тестированию и мониторингу после этого этапа успел доказать свою несостоятельность.
Найм «команды SRE» не даст дополнительной надежности вашим сервисам. Подход «сверху-вниз» к надежности и стабильности не работает — здесь нужен подход снизу вверх. Для достижения этих целей вы должны уверовать в SWE вместо того, чтобы продолжать заигрывать с эксплуатацией.
Чарити Мэйджорс выступила в прошлом году с докладом на Strangeloop, где она рассказала о том, что различие между наблюдаемостью и мониторингом сводится к «известным неизвестным» и «неизвестным неизвестным».
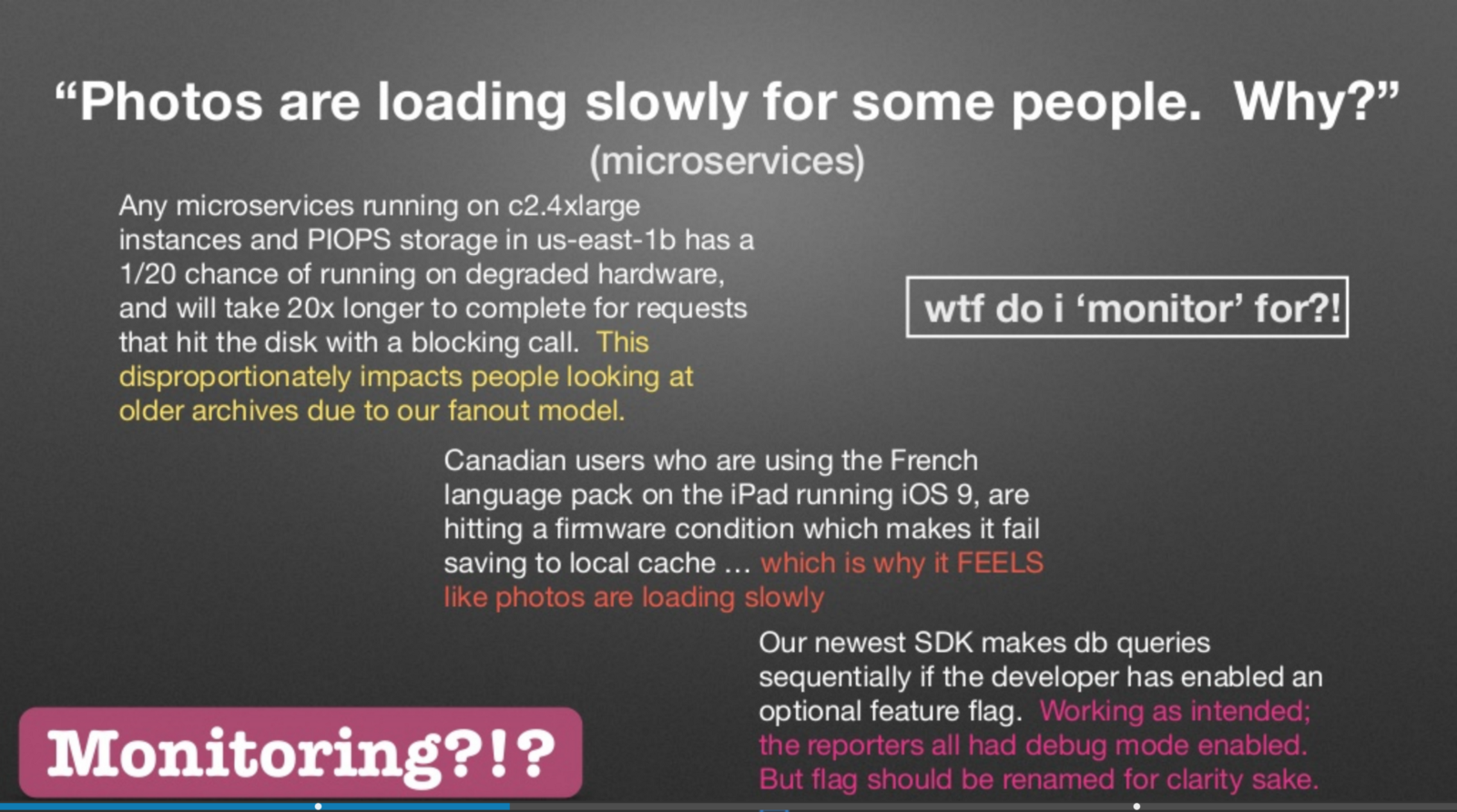
Слайд из доклада Чарити Мэйджорс на Strangeloop в 2017 году
Чарити права — перечисленные на слайде проблемы — это не то, что в идеале вам хотелось бы мониторить. Аналогично, это не те проблемы, которые вам хотелось бы тестировать в пре-продакшне. Распределенные системы патологически непредсказуемы, и невозможно предусмотреть все возможные трясины того болота, в котором могут оказаться различные сервисы и подсистемы. Чем скорее мы смиримся с тем фактом, что сама попытка заранее предугадать каждый способ, которым может быть выполнен сервис, с последующим написанием регрессионного тестового кейса является дурацкой затеей, тем быстрее мы начнем заниматься менее дисфункциональным тестированием.
Как заметил Фред Эбер в своей рецензии на эту статью:
… по мере того, как большой сервис, использующий много машин, растет, увеличиваются и шансы того, что система никогда не будет работоспособной на все 100%. В ней всегда где-то будет происходить частичный сбой. Если тесты требуют 100% работоспособности, то учтите — у вас назревает проблема.
В прошлом, я утверждала, что «мониторинг всего» — это анти-паттерн. Теперь мне кажется, что аналогичное утверждение касается и тестирования. Вы не можете, и поэтому не должны пытаться, протестировать абсолютно все. Книга про SRE утверждает, что:
Оказывается, что после определенной точки, увеличение надежности отрицательно сказывается на сервисе (и его пользователях), вместо того, чтобы делать жизнь лучше! Экстремальная надежность имеет свою цену: максимизация стабильности ограничивает скорость разработки новых функций и скорость предоставления их пользователям, и значительно увеличивает их стоимость, что в свою очередь уменьшает количество функций, которая команда сможет реализовать и предложить пользователям.
Наша цель — нащупать явные границы между риском, который возьмет на себя сервис, и риском, который готов нести бизнес. Мы стремимся сделать сервис достаточно надежным, но не более того, чем от нас требуется.
Если вы в цитате выше замените «надежность» на «тестирование», совет от этого не перестанет быть менее полезным.
Однако, настало время задаться следующим вопросом: что лучше подходит для тестирования до продакшна, а что — после?
Исследовательское тестирование не предназначено для тестирования до продакшна
Исследовательское тестирование — это подход к тестированию, который применяется с 80-ых. Практикуют его в основном тестировщики-профессионалы; данный подход требует меньшей подготовки от тестировщика, позволяет находить критические баги и показал себя «более стимулирующим на интеллектуальном уровне, чем выполнение скриптовых тестов». Я никогда не была профессиональным тестировщиком и не работала в организации, в которой есть отдельная команда тестирования, и поэтому узнала про этот вид тестирования лишь недавно.
В уже упоминавшейся книге «Lessons Learned in Software Testing» в главе «Думай, как тестировщик» есть один очень толковый совет, который звучит так: чтобы тестировать, вы должны исследовать.
Чтобы протестировать что-то как следует, вы должны с ним поработать. Вы должны разобраться. Это исследовательский процесс, даже если у вас на руках есть идеальное описание продукта. До тех пор, пока вы не исследуете эту спецификацию, прокрутив ее в своей голове или поработав с самим продуктом, тесты, которые вы решите написать, будут поверхностными. Даже после того, как вы изучите продукт на достаточно глубоком уровне, вам предстоит продолжить исследование уже ради поиска проблем. Поскольку все тестирование представляет собой анализ выборки, и ваша выборка никогда не будет полной, подобный способ мышления позволяет максимизировать пользу от тестирования проекта.
Под исследованием мы подразумеваем целенаправленное блуждание — навигацию сквозь пространство с определенной миссией, но без обозначенного пути. Исследование включает в себя обучение и экспериментирование; оно подразумевает бэктрекинг, повторение и другие процессы, которые стороннему наблюдателю могут показаться пустой потерей времени.
Если в приведенной выше цитате вы замените каждое слово «продукт» словом «сервис», то, согласно моим представлениям, это будет максимумом того, чего мы можем добиться с помощью тестирования микросервисов перед продакшном — учитывая то, что по большей части тесты в пре-продакшне бывают крайне поверхностными.
Более того, пусть я и абсолютно согласна со значимостью возможности исследовать сервис, я не думаю, что данную технику следует обязательно применять лишь в фазе релиза перед продакшном. В книге есть дополнительные подробности о том, как включить исследования в свое тестирование:
Исследование — это работа детектива. Это свободный поиск. Думайте об исследовании как о передвижении через пространство. Оно подразумевает прямое, обратное и латеральное мышление. Вы продвигаетесь вперед за счет построения лучших моделей продукта. Эти модели в последующем позволяют вам проектировать более эффективные тесты.
Прямое мышление: Двигайтесь в работе от того, что вы хорошо знаете, к тому, чего вы не знаете.
Обратное мышление: Начинайте работу с того, о чем вы подозреваете или имеете некоторое представление, и двигайтесь к тому, что вы знаете, пытаясь подтвердить или опровергнуть свои гипотезы.
Латеральное мышление: Давайте себе отвлекаться от работы на идеи, которые лезут вам в голову, исследуя задачи, связанные с основной «по касательной», после чего возвращайтесь к основной теме.
Возможно, данный вид тестирования действительно необходимо выполнять до релиза при построении систем, критических с точки зрения безопасности, систем, связанных с финансами и, может быть, даже мобильных приложений. Однако, при создании инфраструктурных сервисов метод исследования гораздо лучше подходит для отладки проблем или проведения экспериментов в продакшне; но вот применение исследования на этапе разработки сервиса можно сравнить с попыткой бежать впереди паровоза.
Это связано с тем, что понимание характеристик производительности сервиса часто приходит после наблюдения за ним в продакшне, а исследование становится гораздо более продуктивным, когда мы проводим его базируясь на каких-либо доказательствах, а не на чистых гипотезах. Также важно заметить, что в отсутствие исключительно опытных и хорошо разбирающихся в эксплуатации разработчиков, которым можно доверить выполнение подобного исследования в продакшне, подобные эксперименты потребуют от вас не только наличие современного инструментария, который обеспечит вам безопасность, но и хорошего понимания между продуктовой и инфраструктурной/эксплуатационной командами.
Вот одна из причин, по которой разработчики и эксплуатация должны тесно работать вместе в пределах организации. Соперничество между ними убивает всю идею. У вас даже не получится начать ее применять, если ответственность за так называемое «качество» повешено на одну из сторон. Определенно возможны и гибридные подходы, в которых небольшие, быстрые наборы тестов пробегают по критическому коду, а все остальное мониторится в проде.
Сара Мей
Разработчики должны свыкнуться с идеей тестирования и развития их систем на основании той разновидности точного фидбека, который они могут получить лишь наблюдая за поведением системы в продакшне. Если они будут полагаться исключительно на тестирование до продакшна, то это может сослужить им плохую службу — не только в будущем, но даже и в набирающем распределенные обороты настоящем — в том момент, когда им придется столкнуться с чуть менее тривиальной архитектурой.
Я не считаю, что каждый из нас — инженер эксплуатации. Но вот в чем я точно уверена, так это в том, что эксплуатация — это общая ответственность. Понимание основ того, как работает «железо», позволяет разработчику продвинуться дальше в своем развитии — равно как и понимание того, как сервисы работают в продакшне.
Даю 1000%, что рано или поздно сбой случится. Черт побери, возможно даже, что вы к этому не будете иметь никакого отношения (это я про тебя говорю, S3zure). И причина этого не в деплое — причина в интернете. Если ваше ПО не работает в «коробке», то вы теперь тоже работаете в Ops. Пишите ваш код соответствующим образом.
Разработчики должны научиться писать (и тестировать!) код соответствующим образом. Впрочем, подобное заявление можно считать поверхностным; давайте все-таки определимся, что же это скрывается под предложением «писать код соответствующим образом».
По моему мнению, все сводится к трем основным принципам:
- пониманию эксплуатационной семантики приложения;
- пониманию эксплуатационные характеристик зависимостей;
- написанию отлаживаемого кода.
Эксплуатационная семантика приложений
Это понятие предполагает написание кода, во время которого вы озадачиваетесь следующими вопросами:
- как осуществляется деплой сервиса, с помощью каких инструментов;
- сервис забинден на порт 0 или на стандартный порт?
- как приложение обрабатывает сигналы?
- как стартует процесс на выбранном хосте;
- как сервис регистрируется в service discovery?
- как сервис обнаруживает апстримы?
- как сервису отключают коннекты, когда он собирается завершиться;
- должен ли производиться graceful restart или нет;
- как конфиги — статические и динамические — скармливаются процессу;
- модель конкурентности приложения (многопоточное, или чисто однопоточное, event driven, или на акторах, или гибридной модели);
- каким образом реверс-прокси на фронте приложения держит соединения (пре-форк или потоки или процессы).
Во многих компаниях принято считать, что эти вопросы нужно снимать с плеч разработчиков и перекладывать на платформы или стандартные инструменты. Лично я считаю, что хотя бы базовое понимание этих вопросов сможет по-настоящему помочь разработчикам с работой над сервисами.
Эксплуатационные характеристики зависимостей
Мы строим свои сервисы поверх все более дырявых абстракций (которые порой еще и хрупкие) со слабо понятными видами отказов. Примерами подобных характеристик, которые за последние три года стали для меня устоявшимися, были:
- режим консистентности чтения по умолчанию в клиентской библиотеке Consul (по умолчанию обычно стоит «строгая консистентность», а это не совсем то, что хотелось бы использовать для обнаружения сервисов);
- гарантии кэширования, предлагаемые RPC-клиентом или стандартными TTL;
- потоковая модель официального клиента Confluent Python Kafka и последствия его использования в событийном сервере на Python;
- размер пула соединений по умолчанию для pgbouncer, переиспользование соединений (по умолчанию стоит LIFO) и выяснение того, подходят ли установки по умолчанию для топологии установки Postgres.
Отлаживаемый код
Написание отлаживаемого кода включает в себя возможность задать в будущем вопросы, что в свою очередь подразумевает:
- хорошую степень инструментации кода;
- понимание выбранного формата наблюдаемости — метрик, логов, трекеров ошибок, трейсов и их комбинации, — а также его плюсов и минусов;
- умение выбрать наилучший формат наблюдаемости, учитывая требования конкретного сервиса, эксплуатационные нюансы зависимости и хорошую инженерную интуицию.
Если все вышеизложенное звучит пугающе, то пожелание «пишите код соответственным образом» (и, что критически важно, «тестируйте соответственным образом») подразумевает вашу готовность принять этот вызов.
Тестирование в пре-продакшне
Теперь, когда мы с вами обсудили гибридный подход к тестированию, давайте рассмотрим суть второй половины нашей статьи — тестирование микросервисов перед продакшном.
Написание и запуск тестов НИКОГДА не является самоцелью. Мы занимаемся этим ради нашей команды или ради бизнеса. Если вы можете найти способ получить те же преимущества, что дают вам тесты, вы должны пойти этим путем — поскольку ваши конкуренты скорее всего уже его выбрали.
Сара Мей
У нас часто доходит до того, что любой из видов тестирования становится фетишем (будь то традиционное тестирование, мониторинг, исследование или что там у вас используется); вместо того, чтобы работать на достижение цели, тестирование превращается в религию. Как бы непривычно это не звучало, тестирование — это не абсолют, нет никакого стандартизованного набора метрик, которые могли бы использоваться в качестве универсального критерия хорошо протестированной системы.
Однако, четыре оси — цель, масштаб, уступки, выгода — могут на практике служить хорошим способом определить, насколько эффективна может быть та или иная форма тестирования.
Цель тестирования перед продакшном
Как утверждалось ранее, для меня тестирование перед продакшном — это наилучшая возможная верификация корректности системы, и вместе с тем — наилучшая возможная симуляция известных видов отказов. Целью тестирования в пре-продакшне, как видите, является не доказательство отсутствия багов (за исключением, наверное, багов в парсерах и любых приложениях, связанных с деньгами и безопасностью), но возможность убедиться, что «известные-известные» хорошо покрыты тестами, а для «известных-неизвестных» есть соответствующая инструментация.
Охват тестирования перед продакшном
Охват тестирования перед продакшном может быть широким лишь настолько, насколько хороша наша способность находить при помощи эвристики то, что может оказаться предшественником ошибок в продакшне. Это включает способность аппроксимировать, либо интуитивно осознавать границы системы, успешные пути выполнения, а также ошибочные пути выполнения, плюс постоянное совершенствование используемых эвристик.
Обычно на работе я неизменно занимаюсь написанием и кода, и тестов к нему. Даже когда кто-то другой делает ревью моего кода, это все равно оказывается человек из той же самой команды. Таким образом, охват тестов сильно сокращается из-за предубеждений, которые могут быть у инженеров в команде, а также любых не выраженных явно допущений, на основе которых была создана система.
Учитывая данные цели и охват, давайте оценим различные виды тестирования до продакшна с точки зрения данных целей и охвата, а также рассмотрим их достоинства и недостатки.
Юнит-тестирование
Микросервисы строятся на понятии разделения единиц бизнес-логики на автономные сервисы, при сохранении принципа единственной ответственности, где каждый отдельный сервис отвечает за автономную часть бизнес- или инфраструктурного функционала. Эти сервисы взаимодействуют между собой по сети либо по некоторому виду синхронного RPC-механизма, или сообщаются при помощи асинхронной передачи сообщений.
Некоторые сторонники микросервисов призывают к использованию стандартизированных шаблонов для межсервисной организации компонентов, для того чтобы все сервисы стали выглядеть структурно схоже и состояли из множества компонентов, которые могли бы быть соединены слоями вместе так, чтобы способствовать тестированию каждого слоя в изоляции.
Другими словами, данный подход (заслуженно) побеждает в части декомпозиции на уровне кода для каждого индивидуального сервиса с целью отделения различных доменов, вследствие чего сетевая логика отдельна от логики парсинга протокола, бизнес-логики и логики сохранения данных. Традиционно, для достижения этих целей использовались библиотеки (у вас есть библиотека парсинга JSON, другая библиотека для обращения к хранилищу данных, и так далее), и один из часто употребимых преимуществ такого вида декомпозиции в том, что каждый из слоев может быть протестирован юнит-тестом отдельно от остальных. Юнит-тестирование повсеместно принято считать дешевым и быстрым способом тестирования минимального возможного функционального юнита.
Ни одно обсуждение тестирования нельзя считать полным без упоминания пирамиды автоматизации тестирования, предложенной Майком Коном в его книге «Succeeding with Agile» (в переведе не русский «Scrum. Гибкая разработка ПО»), которая снова стала популярной после упоминания Сэмом Ньюманом в его книге «Building Microservices: Designing Fine-Grained Systems». На нижнем уровне пирамиды располагаются юнит-тесты, которые мы считаем быстрым и дешевым способом тестирования, над ними располагаются сервисные тесты (или интеграционные тесты), а затем тесты при помощи UI (или сквозные end-to-end тесты). По мере того, как вы взбираетесь наверх по пирамиде, скорость выполнения тестов уменьшается, а стоимость выполнения теста растет.
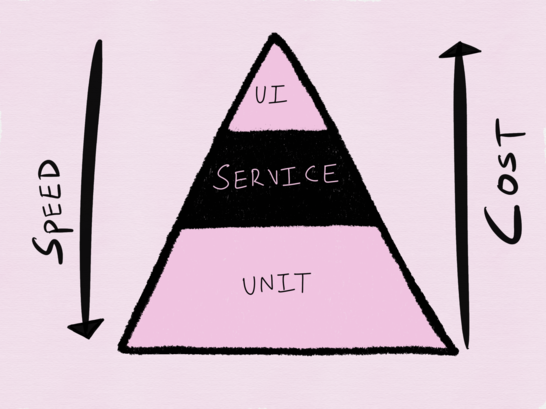
Пирамида автоматизации тестирования Майка Кона
Пирамида тестирования была задумана в эпоху монолитов, и в отношении тестирования подобных приложений она имеет большой смысл. В качестве тестирования распределенных систем, я нахожу подобный подход не просто устаревшим, но и недостаточным.
Из моего опыта, индивидуальный микросервис (за исключением, может быть, сетевых прокси) почти всегда представляет собой программу-фронтенд (с ложкой бизнес-логики), взаимодействующую к некоторым видом stateful-бэкенда вроде базы данных или кэша. В подобных системах, большинство — если не все — рудиментарных юнитов функциональности часто включают некоторую форму I/O (хочется верить, что неблокирующего), будь то получение байтов из сети или чтение данных с диска.
Не все I/O равны
На PyCon 2016 Кори Бэндфилд представил замечательный доклад, где он утверждал, что большинство библиотек допускают ошибку в том, что не разделяют парсинг протокола от ввода/вывода — что в итоге делает и тестирование, и переиспользование кода затруднительным. Это действительно крайне важная мысль, с которой я абсолютно согласна.
Однако, я считаю, что не все виды I/O можно считать равными. Библиотеки для разрбора протокола, RPC-клиенты, драйверы баз данных, клиенты AMQP и прочие — все выполняют I/O, однако все они используют различные формы I/O с различными ставками, которые определяются ограниченным контекстом микросервиса.
Для примера, возьмем тестирование микросервиса, который отвечает за управление пользователями. В данном случае для нас важнее будет возможность проверки того, были ли успешно созданы пользователи в базе данных, а не тестирование того, работает ли как надо парсинг HTTP. Конечно, баг в библиотеке парсинга HTTP может быть единой точкой отказа для этого сервиса, но в то же время парсинг HTTP играет лишь поддерживающую роль в общей схеме, и он второстепенен по отношению к основной обязанности сервиса. Помимо этого, библиотека для работы с HTTP — это та часть, что будет переиспользована всеми сервисами (и потому в данном случае большую пользу может принести фаззинг), она должна стать общей абстракцией. Как известно, наилучший метод найти равновесие при работе с абстракциями (даже самыми «дырявыми») — это, пусть и нехотя, довериться обещанному контракту сервиса. Пусть подобное решение и трудно назвать идеальным выходом, как по мне, этот компромисс имеет полное право на существование, если мы собираемся зарелизить уже хоть что-то.
Однако, когда речь идет о самом микросервисе, то абстракция, которой он является по отношению к остальной системе, включает переходы состояний, которые непосредственно отображаются на определенную часть бизнес или инфраструктурной логики, и поэтому эта его функциональность должна быть протестирована на уровне герметичной единицы.
Аналогично представим, что у нас есть сетевой прокси-сервер, который использует Zookeper и обнаружение сервисов для балансировки запросов к динамическим бэкендам; в таком случае гораздо важнее иметь возможность протестировать, может ли прокси корректно отвечать на триггер контрольного значения (watch) и, если это возможно возможно, выставлять новое контрольное значения. Именно это и является здесь юнитом, который надо тестировать.
Смысл всего сказанного выше состоит в том, что самой важной единицей функциональности микросервиса оказывается абстракция лежащая в основе I/O, который используется для взаимодействия с бэкендом, и поэтому должна статьтой самой герметичной единицей базовой функциональности, которую мы будем тестировать.
Самое интересное, что несмотря на все сказанное, подавляющее большинство «лучших практик» тестирования таких систем относится к лежащему в основе микросервиса I/O не как к его неотделимой части, которую тоже надо тестировать, а как к помехе, которую необходимо устранить при помощи моков. Вплоть до того что все юнит-тестирование в наши дни стало синонимом активного использования моков.
Юнит-тестирование такого критически важного для сервиса I/O с моками по сути своей является «забиванием» на тестирование сервиса, поскольку приносит в жертву скорости точность и приучает нас думать о системах, которые мы создаем, противоположное тому, как они работают на самом деле. Здесь я бы пошла дальше и сказала бы, что юнит-тестирование при помощи моков (можем обозначить его термином «моковое тестирование») — это по большей части проверка нашей неполной, и скорее всего ошибочной, ментальной модели работы критически важных бизнес-компонентов системы, над которой мы работает, в результате которого мы становимся заложниками одной из самых коварных форм предвзятости.
Мне симпатична мысль о том, что мокинг влияет на наше мышление. Моки ведут себя предсказуемо, а вот сети и базы данных — нет.
Самый большой недостаток моков в качестве инструмента тестирования состоит в том, что при симуляции успешного выполнения, равно как и сбоя, моки остаются программистским миражом, ни разу не отражающим хотя бы приблизительной картины реального мира продакшна.
Здесь некоторые заявят, что с этой проблемой лучше справиться другим способом: отследить все возможные отказы на уровне сети и соответственно добавить их в тестовый набор с дополнительными моками, которые покроют все эти тестовые кейсы, которые мы раньше игнорировали. Что ж, помимо того, что учесть все возможные проблемы представляется слабо возможным, этот подход скорее всего приведет к раздутому набору тестов с большим количеством разнообразных моков, которые выполняют схожие функции. И в итоге все это в свою очередь ляжет тяжелой ношей на плечи того, кому в будущем предстоит заниматься поддержкой этого добра.
Раз речь зашла о поддержке тестов, то здесь активно проявляет себя еще один недостаток моков: они делают код тестов излишне подробным и сложным для понимания. Из моего опыта, это особенно справедливо, когда целые классы превращают в моки, и имплементация моков внедряется в тест в качестве зависимости только для того, чтобы мок мог подтвердить, что конкретный метод класса был вызван n-ное число раз или с определенными параметрами. Подобная форма моков сейчас активно используется при написании тестов для проверки поведения сервисов.
Мой синопсис использования объектов-моков в тестах: все закончится тем, что вы будете тестировать имплементацию, а не поведение, почти во всех тестовых кейсах. Это глупо: первое правило клуба тавтологии — это первое правило клуба тавтологии.
К тому же, вы увеличиваете размер своей кодовой базы в разы. В итоге, вам будет гораздо тяжелее производить изменения.
Примиряемся с мокингом
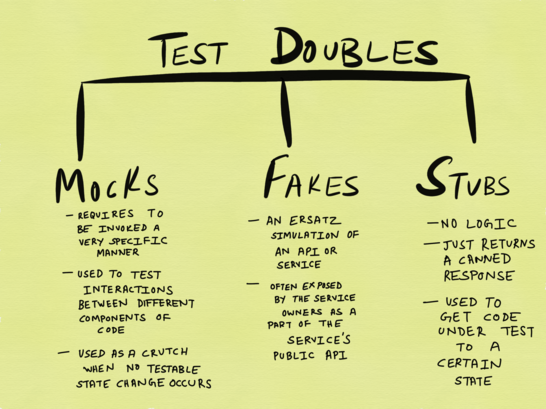
Из блога Google про тестирование, пост про объекты-двойники
Моки, стабы и фейки — это все виды так называемых «тестовых двойников». Практически все, что я написала до этого про моки, применимо и к другим формам тестовых двойников. Однако, давайте не будем ударяться в крайности и утверждать, что моки (и их варианты) не содержат никаких преимуществ; аналогично, не каждый юнит-тест всегда должен включать в себя тестирование I/O. В юнит-тесты имеет смысл включать I/O только тогда, когда тест включает единственную I/O операцию без любых дальнейших сайд-эффектов, к которым нам стоит подготовиться (это является основной причиной того, почему я не вижу особого смысла в тестировании подписки-публикации подобным способом).
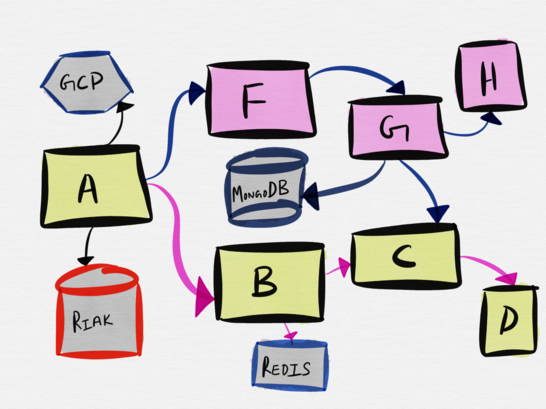
Рассмотрим следующую топологию весьма правдоподобного примера архитектуры микросервиса.
Взаимодействие сервиса A с сервисом B включает коммуникацию сервиса B с Redis и сервисом C. Однако, наименьшей тестируемой единицей здесь является взаимодействие сервиса A с сервисом B, и простейший способ простестировать это взаимодействие — это развернуть фейк для сервиса B и тестировать взаимодействие сервиса A с фейком. Тестирование контрактов может быть особенно полезным для тестирования подобных интеграций. Soundcloud известен тем, что использует контрактные тесты для тестирования всех своих 300+ микросервисов.
Сервис A также сообщается с Riak. Минимальная тестируемая единица в данном случае включает в себя реальное сообщение между сервисом A и Riak, поэтому имеет смысл развертывание локального инстанса Riak на время тестирования.
Когда дело доходит до интеграции со сторонними сервисами вроде GCP, AWS, Dropbox или Twilio, в идеальном случае у биндингов или SDK, предоставленными вендорами, уже есть готовые хорошие фейки, которые мы можем использовать в своем наборе тестов. Еще лучше, если вендоры предоставляют возможность производить реальные вызовы API, но в тестовом режиме или в «песочнице», поскольку это позволяет разработчикам тестировать сервисы в более реалистической манере. К таким сервисам я отношу Stripe, который предоставляет тестовые токены.
Итак, мы с вами выяснили, что тестовые «двойники» сполна заслуживают своего места в нашем спектре тестирования, однако не надо зацикливаться на них как на единственном средстве проведения юнит-тестов или перебарщивать с их использованием.
Неприметные достоинства юнит-тестов
Модульное тестирование не ограничивается теми методами, которые мы с вами успели обсудить. Было бы упущением начать обсуждать юнит-тесты и не поговорить о property-based тестировании и фаззинге. Ставшее популярным благодаря библиотеке QuickCheck для Haskell (которая после была портирована на Scala и остальные языки) и библиотеке Hypothesis для Python, property-based тестирование позволяет запускать один и тот же тест несколько раз с разными вводами без необходимости для программиста генерировать фиксированный набор входных данных для тестового кейса. Превосходный доклад по этой теме сделала Джессика Керр, а Фред Эбер даже написал по этому теме целую книгу. В своей рецензии на эту статью Фред упоминает про различные виды подходов к различным инструментам для property-based тестирования:
Относительно property-based тестировани я скажу следующее: большая часть инструментов приближает его к фаззингу, но если немного поднапрячься, то вы сможете провести его на манер white-box тестирования с более тонким подходом. Другими словами, если фаззинг заключается в выяснении того, «падает» ли данная часть системы или нет, то property-based тестирование помогает проверить, всегда ли в системе соблюдается определенный набор правил или свойств. Существует 3 больших семейства property-тестов:
— Семейство Haskell QuickCheck. Эта разновидность основана на использовании информации о типе для генерирования данных, на которых будет выполнен тест. Основное преимущество: тесты становятся меньше, а их покрытие и полезность — выше. Недостаток: тяжело масштабировать.
—?Семейство Erlang QuickCheck. Эта разновидность основана на динамических генераторах данных, которые представляют собой составные функции. Вдобавок к функциональности предыдущего типа, в таких фреймворках доступны stateful-примитивы моделирования. Больше напоминают model checking, поскольку вместо поиска перебором выполняют вероятностный поиск. Соответственно, здесь мы уходим от фаззинга в зону «проверки моделей», которая является совершенно другим семейством методов тестирования. Мне доводилось слушать доклады, авторы которых прогоняли такие тесты по разным облачным провайдерам и использовали их для обнаружения «железных» ошибок.
— Hypothesis: уникальный подход к делу. Основывается на механизме, схожем с фазз ингом, в котором генерация данных производится на основе потока байтов, который может становиться легче/тяжелее по шкале сложности. Имеет уникальное устройство и является самым применимым инструментом из перечисленных. Я не слишком хорошо знакома с тем, как Hypothesis работает «под капотом», но этот инструмент умеет делать гораздо больше, чем его аналоги на Haskell.
Фаззинг, с другой стороны, позволяет скармливать заранее невалидные и мусорные входные данные приложению для того, чтобы убедиться, что приложение завершит работу со сбоем так, как и было запланировано.
Для фаззинга существует большое количество различных инструментов: есть фаззеры, которые основываются на покрытии, вроде afl, а также инструменты address sanitizer, thread sanitizer, memory sanitizer, undefined behavior sanitizer и leak sanitizer и другие.
Юнит-тестирование может предоставить и другие преимущества помимо обычной верификации того, что что-то работает как задуманно для определенного входного набора данных. Тесты могут выступать в роли превосходной документации для API, выставленного приложением. Языки вроде Go позволяют создавать example tests, в которых функции, начинающиеся с Example вместо Test, живут рядом с обычными тестами в файле _test.go в любом из выбранных пакетов. Эти функции-примеры компилируются (и опционально выполняются) как часть тестового набора пакета, после чего отображаются как часть документации пакета и позволяют выполнять их в качестве тестов. Смысл этого, как утверждает документация, заключается в следующем:
Подобный подход гарантирует, что, при изменении API, документация к пакету не устареет.
Другим преимуществом юнит-тестов является то, что они оказывают определенное давление на программистов и проектировщиков по части структурирования API, с которым было бы легко работать сторонним сервисам. В блоге Google про тестирование был опубликован замечательный пост «Дискомфорт как средство мотивирования изменений», который проливает свет на то, что требование от авторов API предоставлять его реализацию в виде фейков позволяет им лучше понять тех, кто будет работать с этим API, и уменьшить количество боли в этом мире.
В 2016 году а занималасс организацией митапов по Python Twisted в Сан-Франциско. Одной из популярный тем для обсуждения было то, что было ошибкой сделать event loop в Twisted глобальным (которую Python 3 впоследствии воспроизведет в реализации asyncio, чем приведет в ужас коммьюнити Twisted) и то, насколько проще стало бы тестирование и использование, если бы Reactor (который предоставляет базовые интерфейсы для всех видов сервисов, включая сетевое взаимодействие, потоки, диспетчеризацию событий и так далее) передавался потребителям как явная зависимость.
Однако, здесь требуется сделать оговорку. Как правило, хороший дизайн API и хорошее тестирование — это две совершенно не зависящие друг от друга цели, и в реальности (впрочем, делать этого не рекомендуется) не составляет труда спроектировать невероятно удобное и интуитивное API, которому недостает тестирования. Впрочем, гораздо чаще люди проектируют API, которое пытается достичь стопроцентного покрытия тестами (не важно, как вы там его измеряете, по строкам кода или как-то иначе), но в итоге получается преждевременно абстрагированным заDRYенным артефактом несостоятельности. Пусть модульное тестирование, основанное на моках, и является путем к хорошему дизайну API, оно не гарантирует, что ваш код будет выполняться должным образом.
VCR — кэшируем или повторяем тестовые ответы
Чрезмерное использование моков/фейков/тестовых двойников/стабов — не самый надежный выбор техник тестирования (хотя иногда от этого не уйти), но когда в дело вступает кэширование в стиле VCR, отладка непрошедших тестов становится еще тяжелее.
Учитывая общую ненадежность моков, я нахожу абсолютно нелепым предложение отдельных лиц зайти еще дальшезаписывать ответы в качестве фиксаций (test fixture). Я нахожу этот метод неэффективным, как в качестве способа ускорения интеграционных тестов (хотя какие они интеграционные, если используют такие методики тестирования), так и в отношении ускорения юнит-тестов. Лишняя перегрузка вашего мозга во время отладки не прошедших тестов с нагромождением лишних слоев не стоит потраченного на нее времени.
Интеграционное тестирование
Если юнит-тестирование при помощи моков настолько ненадежно и неправдоподобно, означает ли это, что интеграционное тестирование спешит нам на помощь и спасет нас?
Вот что я писала по этому вопросу в прошлом:
Это может прозвучать слишком радикально, но хорошее (и быстрое) интеграционное тестирование (локальное и удаленное) на пару с хорошим инструментированием зачастую работает лучше, чем стремление достичь 100% покрытия тестами.
В то же время, крупные интеграционные тесты, касающиеся каждого доступного сервиса, взаимодействующего с нашим, масштабируется не слишком хорошо. Он и будут медленным по умолчанию, а интеграционные тесты приносят максимальную пользу лишь в том случае, когда обратную связь от них можно получить быстро.
Нам нужны лучшие паттерны тестирования распределенных систем.
Некоторые читатели моего Twitter указали мне на то, что эти два моих заявления конфликтуют друг с другом; с одной стороны, я призываю писать больше интеграционных тестов вместо юнит-тестов, с другой стороны утверждаю, что интеграционные тесты плохо масштабируются в случае распределенных систем. Эти точки зрения не являются взаимоисключающими, и возможно мое первое утверждение действительно требует подробных разъяснений.
Дело здесь вовсе не в том, что на смену юнит-тестированию в этом случае приходят сквозные end-to-end тесты; суть в том, что умение правильно определить «юнит», или единицу, которую мы должны тестировать зачастую обозначает переход от традиционного юнит-тестирования к тому, что мы обычно называем «интеграционным тестированием», поскольку оно включает коммуникацию по сети.
В самых тривиальных сценариях сервис общается с одной базой данных. В таких случаях, неразделимый юнит, который мы тестируем, однозначно включает в себя используемый им I/O. В тех случаях, когда транзакции являются распределенными, определение этого самого юнита становится нетривиальной задачей. Единственной известной мне компанией, которая пытается решить эту задачу является Uber, но, увы, когда я задала своему другу, работающему там, вопрос о том, как они производят тестирование, все, что он cмог мне ответить, было: «это все еще сложная задача». Гипотетически, если бы я хотела реализовать этот паттерн в новом сервисе, перспектива использования моков или фейков для того, чтобы проверить, была ли корректно отменена распределенная транзакция или применена компенсирующая транзакция, не кажется мне надежным вариантом. Юнит, который мы тестируем, становится транзакцией-долгожителем.
Event Sourcing — это паттерн, набравший популярность за счет растущей популярности Kafka. Паттерн разделения ответственности команд и запросов (Command and Query Responsibility Segregation) и связанные с ним анти-паттерны живет и здравствует уже более 10 лет. Он основывается на идее разделения изменения состояний (writes) от получения состояний (reads). Чего я обычно никогда не слышу в докладах про эти достаточно нетривиальные архитектурные паттерны, так этого того, какие методики следует применять для тестирования подобных архитектур, за исключением моков на уровне кода и сквозного тестирования на системном уровне.
Обычно перенос такой верификации на полномасштабное интеграционное тестирование не только замедляет цикл получения фидбека, но также становится причиной роста сложности интеграционных тестов до такого масштаба, что они могут превзойти саму систему, которую мы тестируем, и для ее поддержки потребуется неадекватное количество рабочего времени (и, вполне возможно, внимание всей команды).
Интеграционное тестирование не просто неэффективно для сложных распределенных систем; это черная дыра для вашего рабочего времени, которая не принесет соответствующей пользы проекту.
Еще одним недостатком применения интеграционных тестов в сложных системах является требование поддержки нескольких различных окружений для разработки, тестирования и/или стейджинга. Многие компании пытаются поддерживать эти окружения в идентичном состоянии и «синхронизируют» их с продакшном, это обычно подразумевает повтор всего «живого» трафика (по крайней мере записей) на тестовом кластере для того, чтобы хранилища данных в тестовом окружении соответствовали продакшну. Как ни крути, этот подход требует значительных вложений в автоматизацию и ее дальнейшую поддержку и мониторинг.
Теперь, когда мы познакомились со всеми этими ограничениями и подводными камнями, можно перейти к наилучшему компромиссу, который только существует. Я называю его «Правилом шага наверх».
Правило шага наверх
Основная его идея состоит в том, что тестирование следует начинать на один уровень выше, чем обычно рекомендуется. Согласно этой модели, юнит-тесты скорее выглядят как интеграционные тесты (поскольку учитывают I/O как часть тестируемого юнита внутри ограниченного контекста), интеграционное тестирование будет выглядеть как тестирование в реальном продакшне, а вот тестирование в продакшне —как мониторинг и исследование. Знакомая нам пирамида тестирования в случае распределенных систем выглядит следующим образом:
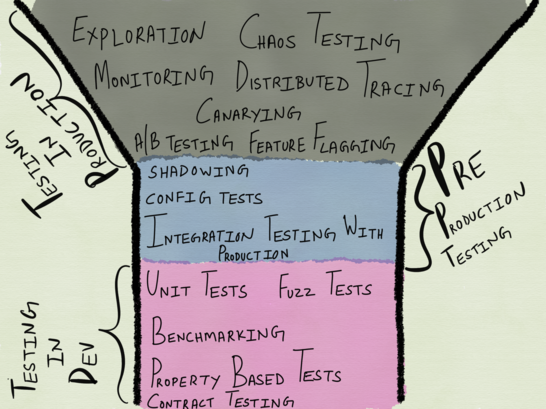
Пирамида тестирования для распределенных систем
Чтобы понять, как эту идею можно применить в реальном мире, давайте рассмотрим упрощенную до невозможности архитектуру сервисов, над которыми я работаю в качестве разработчика последние пару лет (при этом мы опустим все резервные хранилища данных, инструменты для observability и другие интеграции со сторонними компонентами). То, что описывается ниже — это всего лишь малая часть всей инфраструктуры; более того, важно сразу отметить, что границы приведенной системы чрезвычайно консервативны — мы разбиваем ее только тогда, когда этого нельзя избежать, чтобы учесть требования. Скажем, раз балансировщик нагрузки никогда не сможет выполнять функции распределенной файловой системы или распределенной многоуровневой системы кэширования, это будут разные системы.

Для нас не имеет значения, что делает тот или иной сервис, нам только нужно знать, что они являются разрозненными, написаны на различных языках и получают разное количество трафика. Все они используют Consul для обнаружения сервисов. У всех сервисов свой собственный график деплоя — центральный API-сервер (с версионируемыми эндпоинтами) деплоится несколько раз в день, в то время как сервис G деплоится примерно пару раз за год.
Идею о том, что все эти сервисы можно развернуть локально на моем Macbook во время разработки сервиса API, можно назвать смехотворной (и нет, я этого не делаю). Аналогично смехотворной можно считать идею разворачивания всех этих сервисов в тестовом окружении и запуске интеграционных тестов для каждого билда. Вместо этого, нужно решить, как лучше тестировать каждый отдельный сервис, основываясь на преимуществах и ставках, учитывая функциональность каждого сервиса, его гарантии и паттерны доступа.
Юнит-тесты больше напоминают интеграционные тесты
Свыше 80% функциональности центрального сервера API включает в себя взаимодействие с MongoDB, поэтому большая часть юнит-тестов содержит реальное подключение к локальному инстансу MongoDB. Сервис E — это прокси авторизации на LuaJIT, который балансирует трафик, возникающий на трех различных источниках, к трем различным инстансам центрального API. Одной из критический частей функциональности сервиса E является проверка, подходящий ли обработчик вызывается для каждого контрольного значения(watch) в Consul, и поэтому некоторые из юнит-тестов действительно раскручивают дочерний процесс Consul, чтобы с ним взаимодействовать, и затем «убивают» его, когда тест завершается. Оба приведенных примера сервисов лучше было бы тестировать при помощи такого типа юнит-тестов, которые пуристы называют интеграционными тестами.
Интеграционное тестирование больше напоминает тестирование в продакшне
Давайте рассмотрим сервисы G, H, I и K (нет на диаграмме выше).
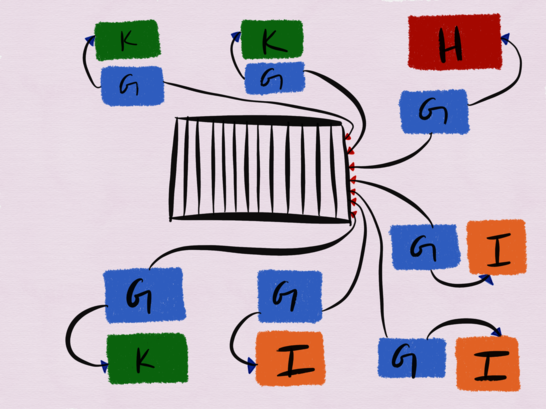
Сервис G — это однопоточный процесс Python, который подписывается на топик брокера Kafka для чтения обновлений, поступающих от пользователя, и периодически перезагружает конфиги сервисов H, I и K. Сервис G совместно размещен на каждом из хостов, где развернуты H, I и K, и в любой момент времени работает где-то 15-20 инстансов сервиса G (на диаграмме отображены лишь 7). Главная ответственность сервиса G — это убедиться в том, что сообщения, которые он читает из топика Kafka, передаются в сервисы H, K и I.
H, K и I — это независимые сервисы. Сервис H — это фронтенд nginx (если точнее, Openresty) к большой распределенной системе (она на диаграмме не показана), в сердце которой находится распределенная файловая система, в дополнении к LevelDB в режиме write through cache (запись производится в основную память и при этом дублируется в кэш), хранилище метаданных MySQL, трекеры метаданных, выборка и обрезка файлов на Go. Сервис K — это HAProxy, а сервис I — это HTTP-сервер LuaJIT. А еще требуется, чтобы сервисы H, I и K сходились в обновлениях конфигурации Kafka. К нашему счастью, нам хотя бы не требуются гарантии строгой консистентности.
Что подводит нас к следующему вопросу: каким образом будет лучше всего протестировать согласованность (eventual consistency) этих систем?
Способ, которым тестируется данные сервисы, заключается не в том, чтобы запустить все эти сервисы и провести end-to-end тестирование, чтобы проверить корректно ли употребляется любое отправленное в топик Kafka сообщение сервисом G, и сходятся ли после этого сервисы H, I и K на конкретной конфигурации. Подобная процедура, будучи выполненной в «тестовой среде», не станет гарантом корректной работы данной конструкции в продакшне, особенно если мы учтем, что:
- сервис K — это HAProxy (причем до самого последнего времени невозможно было использовать HAProxy с нулевым временем простоя при перезапуске)
- сервис H в продакшне держит сотни (иногда тысячи) запросов в секунду на процесс, что не так-то просто воспроизвести в тестовом окружении без серьезных вложений в инструменты и автоматизацию загрузки. Кроме того, это потребует от нас тестирования того, приводит ли перезапуск мастер-процесса nginx сервиса H к корректному запуску нескольких свежих рабочих процессов. Постоянной проблемой с сервисом H в продакшне является то, что перезапуск мастер-процесса nginx не всегда приводит к «убийству» старых рабочих процессов, из-за чего старые рабочие процессы продолжают висеть в памяти и отъедать трафик, хотя пост в официальном блоге такую ситуацию называет «крайне редкой»:
В редких случаях могут возникнуть проблемы, когда слишком много поколений рабочих процессов NGINX ожидают закрытия соединений, но они быстро разрешаются.
На практике, по крайней мере для HTTP2, это самое «редко» до самого последнего времени случалось совсем не редко, и, исходя из моего опыта, самым простым способом решения этой проблемы был мониторинг старых рабочих процессов nginx и убивание их вручную. Опять же, задержка в сходимости для трех сервисов H, I и K — это то, что нужно мониторить и на чем должно висеть оповещение.
Я привела всего лишь один пример системы, в которой интеграционное тестирование не приносит заметной пользы, в то время как мониторинг мог бы существенно облегчить жизнь. Несмотря на то, что мы могли точно симулировать все виды отказов в окружении интеграционного тестирования, нам по-прежнему требуется мониторинг, поэтому в итоге все преимущества применения интеграционного тестирования не могут компенсировать накладных расходов на его использование и обслуживание.
Шейпинг трафика при помощи Service Meshes
Одной из причин, по которой мне так сильно нравится набирающая популярность парадигма service meshes — это то, что прокси позволяет производить шейпинг трафика таким способом, который невероятно хорошо «ложится» на тестирование. С помощью небольшого количества логики в прокси для маршрутизации staging трафика на staging инстанс (этого можно достичь таким элементарным способом, как установка специального HTTP-заголовка во всех запросах не с продакшна, или основываясь на IP-адресе входящего запроса), вы фактически можете использовать стек с продакшна для всех сервисов за исключением того сервиса, который вы тестируете. Такой подход позволяет производить реальное интеграционное тестирование с продакшн-сервисами без лишнего оверхеда от поддержки переусложненного тестового окружения.
Я считаю, что интеграционное тестирование в «тестовых» кластерах практически бесполезно и должно исчезнуть — будущее за живым трафиком. Сегодня я узнала, что Facebook практикует подобный подход уже достаточно давно. https://t.co/zMrt1YXaB1
Парадигма Service Meshes позволит нам раскрыть истинный потенциал тестирования.
Разумеется, здесь нужно уделить внимание соблюдению безопасности, целостности данных и т. п., однако я искренне верю, что тестирование на «живом» трафике с хорошей наблюдаемостью в результате проведенных тестов — это дорога в будущее в сфере тестирования микросервисов.
Выбор данной модели тестирования принесет еще одно преимущество, выраженное в стимуляции улучшенной изоляции между сервисами и проектировании более совершенных систем. Инженерам придется усиленно думать над межсервисными зависимостями и над их возможным влиянием на целостность данных, и это заставит проектировщиков архитектуры лишний раз задуматься. Кроме того, возможность протестировать один сервис со всеми остальными в продакшне потребует того, чтобы тестируемый сервис не имел никаких побочных эффектов, которые могли бы повлиять на любые из зависимостей в апстриме или даунстриме, что мне видится вполне разумной целью при проектировании системы.
Заключение
В рамках данной статьи я не ставила перед собой цели доказать преимущество того или иного метода тестирования. Я не могу называться экспертом по этой теме, поскольку мой образ мышления был сформирован под влиянием тех типов систем, с которыми мне довелось поработать, и на него наложили свой отпечаток те ограничения, в которых мы находились (главным образом, это были крайне ограниченное время и ресурсы), а также организационная структура самих компаний. Вполне возможно, что в иных сценариях и обстоятельствах озвученные в моей статье идеи не будут нести никакого смысла.
Прислушивайтесь к так называемым «экспертам», но и почаще включайте голову. «Эксперты» часто дают излишне обобщенные советы. Поэтому думайте своей головой и не ленитесь!
Учитывая, насколько широк спектр тестирования, становится ясно, что не существует единственного «истинно верного» способа произвести тестирование правильным образом. Любой подход подразумевает необходимость идти на компромиссы и жертвы.
В конечном счете, каждая команда — эксперт в своих собственных обстоятельствах и потребностях, а ваше мышление — это не то, что следует отдавать на аутсорс.
Мы очень любим подобные масштабные концептуальные обсуждения, особенно приправленные собственными примерами, ведь в решение таких вопросов вовлечены не только отдельные разработчики, а практически все команды проекта. Приглашаем специалистов, опыт которых уже позволяет обсуждать философские вопросы разработки ПО, выступить на РИТ++ 2018.
Комментарии (9)

vba
22.02.2018 22:06Началась статья за здравие, кончилась за упокой. Я не совсем понял, если моки и стабы так плохи и монолитическая облачная структура на одном компе тоже попахивает, то как же тогда тестировать например общение с БД? Ведь все же знают что тестить лучше с белого листа, а следовательно нужно иметь БД на машине разработчика, удалять данные после каждого теста, тоже самое в CI. Docker например упрощает в этом плане жизнь, но ведь автор против
docker-compose up.
Вот еще бы помимо пурги автор привела бы реальные примеры и подкрепила бы их расчетами о степени эффективности выявления багов того или иного подхода.
Так же не убедила она и об абсолютной нужде тестирования в продакшене. Если вы используете
CloudFormationв связке сserverlessи деплоите наawsто ваши среды абсолютно зеркальны, в чем тогда хайп тестов в продакшене?
biseptol
23.02.2018 02:01> то как же тогда тестировать например общение с БД?
Видимо, надо выделять части, которые требуют общения с БД в отдельные (end-to-end?) тесты, и гонять их на dev. А если вообще все 20 контейнеров требуют БД — значит в архитектуре что-то не так. Хотя YMMV, конечно.

igor_suhorukov
23.02.2018 00:22В целом, в публикации много толковых и практичных мыслей. Я бы сказал что не столько откровения, сколько очевидная реальность. Да и отладка на проде была не раз. Там уж точно самые реалистичные данные и проблемы, которые никогда не будут на синтетических окружениях tst/uat. Только цена ошибки там в разы больше.
Идею о том, что все эти сервисы можно развернуть локально на моем Macbook во время разработки сервиса API, можно назвать смехотворной (и нет, я этого не делаю).
А вот с этим могу поспорить. Нет ничего хуже отлаживать распределенную систему. И если возможно все компоненты запустить в одном процессе — это в сотни раз ускоряет разработку и отладку и раннее нахождение проблем.
Как думаете, сложно ли эмулировать инфраструктуру AWS (S3, SQS, RDS, Redshift) в JVM процессе?
KirEv
23.02.2018 03:16Сначало было увлекательно, потом слепили все в кучу…
тесты, конечно, здорово и полезно, но не увидел в статье упоминания TDD, тесты же не ради тестов…
есть логика функции\метода, описывается юнит тест логики с моками и т.п., реализуется, тест говорит ОК, добавляется работа с БД, создается интеграционный тест. помоему никакой магии.
оно все индивидуально от случая, проект над которым работал содержал чуть более 10ти микросервисов, go+mysql, развертывание dev-окружения делалось запуском одного bat-файла в windows, и делалось в тех редких случаях, когда была необходимость за раз прогнать все тесты, и все что нужно — наличие mysql на компе QA\QC.
К примеру, случай, когда микросервисы должны возвращать ответы в одном шаблоне… для этого обычно делают пакет\библиотеку, тест пишется на целевой код, а не покрывается тестами каждый сервис, используемый эту либу\пакет…
К чему это я… ах да… если тест содержит моки, разумный подход — понять цель создания моков и их природу, а не вестись на хайп и сразу: виновен.
VolCh
23.02.2018 11:15Лично я до конца не определился имеет ли смысл разворачивать всё локально (при условии что оно заведомо влезет). Есть и плюсы, и минусы. Наверное, имеет смысл локально поднимать то, с чем непосредственно работаешь и его зависимости типа баз и редисов, а остальное держать общее для всех разработчиков и тестировщиков. С другой стороны, как ни странно, но всю инфраструктуру зачастую легче поднять локально, чем частично, если это частично динамически меняется. Скажем, с утра нужен просто один микросервис с его базой, а в обед другой, плюс фронт к нему, плюс их общий раббит и редис. Я пытался так делать — сложно, гораздо сложнее чем иметь локально 2 полных окружения для двух веток.
По тестам:
отказываться от юнит-тестов без io для сервисов со сложной логикой смысла не вижу. io для них вещь инфраструктурная, логика от не зависит, даже от абстракций над ним. В интеграционных тестах мокаем абстракции io или используем легковесные имплементации, в функциональных уже нужно ставить реальные.igor_suhorukov
23.02.2018 11:36Локально проще проводить отладку, профилирование. Нет интерференции между разработчиками — не нужно писать в групповом чате «Я занимаю dev3. Не влезай — убьет». Единственный вопрос — сложность развернуть так для некоторых технологий и проектов «прибитых гвоздями» к инфраструктуре.
VolCh
23.02.2018 23:06Я про dev-test инфраструктуры, где интерференции нет. Скажем, два десятка сервисов, соответствующих продакшену, и только те, которые собираешься менять «форкаешь» к себе на локальную машину.
malvina8
24.02.2018 20:50Читал читал и дочитал. А толку?
Ну работал человек тестировщиком, потом за прилежность повысили и стал чуть чуть кодить ну и тесты уже не ручками а кодом реализовывать. Судя по всему человек общительный и голосистый(вон сколько выплеснул), ну а значит опять повысили теперь он модный девопс. Ну а профит то в чем? Как была в голове каша так и осталась. Как поддержкой занимался так и занимается. А леса за деревьями так и не увидел.
А если по теме статьи, то все можно было уложить в три предложений:
1) Стоимость тестов — самый дешевый(быстрый) это компилятор! а не юнит. Второй…
2) Мониторить продакше это хорошо и чем больше у вас метрик тем лучше.
3) Тесты и в частности ТДД это не только про то что метод работает так как задумывалось, это еще и про многие ограничения накладываем на разработчиков приводящие к удешевлению(сокращение времени разработки и поддержания), доки, примеры,…
Singaporian
Это было очень длинно :-)
Но спасибо за прекрасную статью.