
Выборка данных
Выборка данных содержит порядка 8,5 млн строк и 29 столбцов.Вот некоторые из параметров:
- Широта-latitude
- Долгота-longitude
- Способ взятия пробы-method_name
- Дата и время взятия пробы-date_local

Задача
- Найти параметры максимально влияющие на уровень CO в атмосфере.
- Создание гипотезы, предсказывающей уровень CO в атмосфере.
- Создание нескольких простых визуализаций.
Импорт библиотек
import pandas as pd
import matplotlib.pyplot as plt
from sklearn import preprocessing
from mpl_toolkits.basemap import Basemap
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
from sklearn import preprocessing
import warnings
warnings.filterwarnings('ignore')
import random as rn
from sklearn.cross_validation import train_test_split
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import RandomForestRegressor
from sklearn.neighbors import KNeighborsClassifier
from sklearn.linear_model import LogisticRegression
from sklearn import svm
Далее необходимо проверить исходные данные на наличие пропусков
Выведем в процентом соотношение количество пропусков в каждом из параметров. Исходя из результатов ниже видно присутствие пропусков в параметрах ['aqi','local_site_name','cbsa_name'].
(data.isnull().sum()/len(data)*100).sort_values(ascending=False)method_code 50.011581
aqi 49.988419
local_site_name 27.232437
cbsa_name 2.442745
date_of_last_change 0.000000
date_local 0.000000
county_code 0.000000
site_num 0.000000
parameter_code 0.000000
poc 0.000000
latitude 0.000000
longitude 0.000000
...
Из описания к приложенному набору данных я сделал вывод, что можно пренебречь данными параметрами. Поэтому необходимо «вычеркнуть» эти параметры из набора данных.
def del_data_func(data,columns):
for column_name in columns: del data[column_name]
del_list = data[['method_code','aqi','local_site_name','cbsa_name','parameter_code',
'units_of_measure','parameter_name']]
del_data_func (data, del_list) Выявление зависимостей на исходном наборе данных
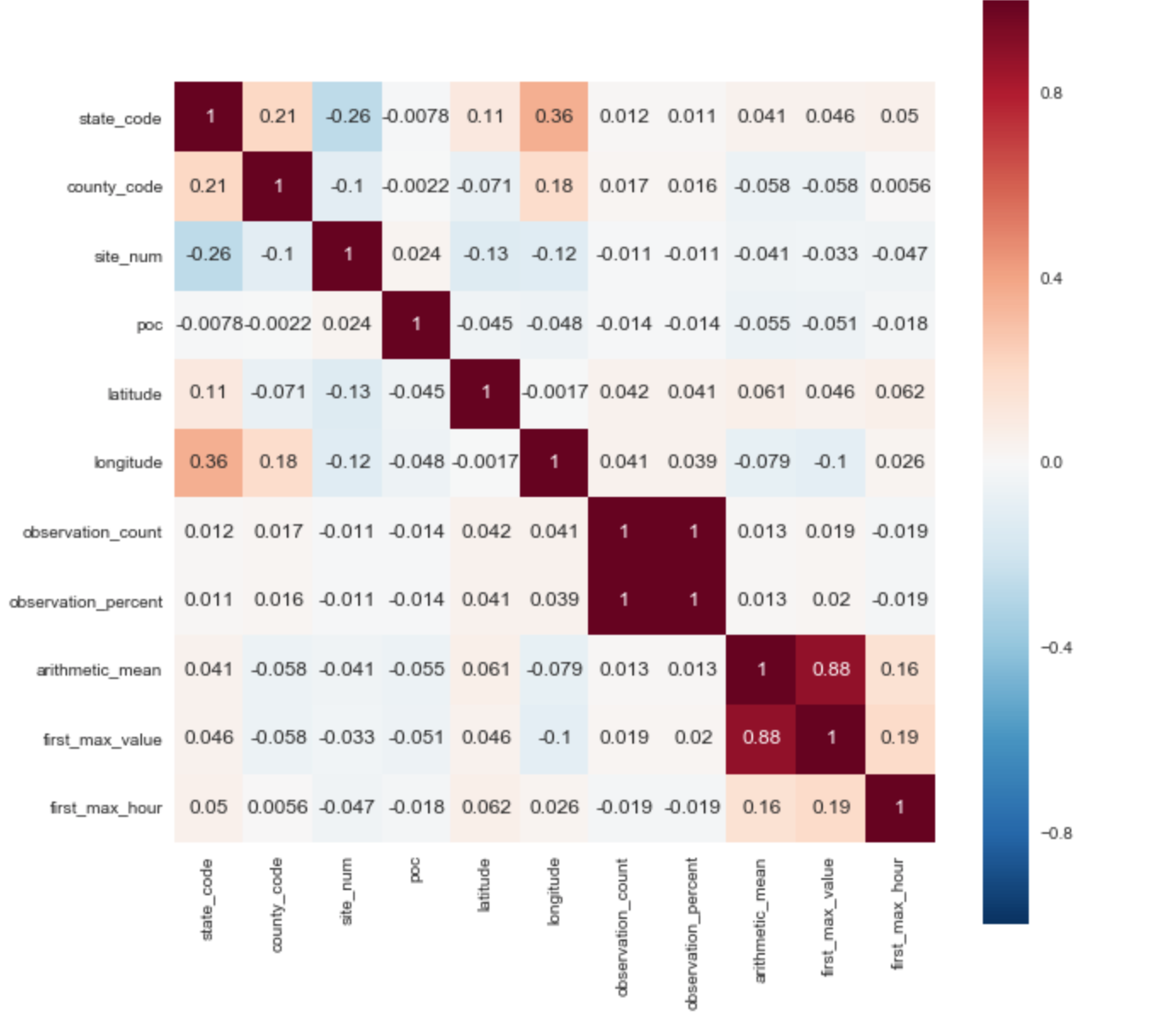
В качестве целевой переменной я выбрал параметр ['arithmetic_mean']. Исходя из корреляционной матрицы сразу можно выявить 2 положительные корреляции с целевым параметром: ['arithmetic_mean'] и ['first_max_hour'], ['first_max_hour'].
Из описания набора данных следует, что «first_max_value» — самое высокий показатель за день, а «first_max_hour» — час, когда было зарегистрировано самое высокий показатель.
Преобразование исходных параметров:
Для правильной работы алгоритма необходимо преобразование категориального признака в числовой.На представленных выше данных в глаза сразу бросается несколько параметров:
«pollutant_standard», «event_type», «address».
data['county_name'] = data['county_name'].factorize()[0]
data['pollutant_standard'] = data['pollutant_standard'].factorize()[0]
data['event_type'] = data['event_type'].factorize()[0]
data['method_name'] = data['method_name'].factorize()[0]
data['address'] = data['address'].factorize()[0]
data['state_name'] = data['state_name'].factorize()[0]
data['county_name'] = data['county_name'].factorize()[0]
data['city_name'] = data['city_name'].factorize()[0]Feature Engineering
В наборе данных у нас присутствует дата и время. Для выявления новых зависимостей и
увеличения точности предсказания необходимо ввести параметр сезонности времен года.
data['season'] = data['date_local'].apply(lambda x: 'winter' if (x[5:7] =='01' or x[5:7] =='02' or x[5:7] =='12') else x)
data['season'] = data['season'].apply(lambda x: 'autumn' if (x[5:7] =='09' or x[5:7] =='10' or x[5:7] =='11') else x)
data['season'] = data['season'].apply(lambda x: 'summer' if (x[5:7] =='06' or x[5:7] =='07' or x[5:7] =='08') else x)
data['season'] = data['season'].apply(lambda x: 'spring' if (x[5:7] =='03' or x[5:7] =='04' or x[5:7] =='05') else x)
data['season'].replace("winter",1,inplace= True)
data['season'].replace("spring",2,inplace = True)
data['season'].replace("summer",3,inplace=True)
data['season'].replace("autumn",4,inplace=True)
data["winter"] = data["season"].apply(lambda x: 1 if x==1 else 0)
data["spring"] = data["season"].apply(lambda x: 1 if x==2 else 0)
data["summer"] = data["season"].apply(lambda x: 1 if x==3 else 0)
data["autumn"] = data["season"].apply(lambda x: 1 if x==4 else 0)Также обозначим каждый год в хронологической цепочки в качестве отдельного параметра.
data['date_local'] = data['date_local'].map(lambda x: str(x)[:4])
data["1990"] = data["date_local"].apply(lambda x: 1 if x=="1990" else 0)
data["1991"] = data["date_local"].apply(lambda x: 1 if x=="1991" else 0)
data["1992"] = data["date_local"].apply(lambda x: 1 if x=="1992" else 0)
data["1993"] = data["date_local"].apply(lambda x: 1 if x=="1993" else 0)
data["1994"] = data["date_local"].apply(lambda x: 1 if x=="1994" else 0)
data["1995"] = data["date_local"].apply(lambda x: 1 if x=="1995" else 0)
data["1996"] = data["date_local"].apply(lambda x: 1 if x=="1996" else 0)
data["1997"] = data["date_local"].apply(lambda x: 1 if x=="1997" else 0)
data["1998"] = data["date_local"].apply(lambda x: 1 if x=="1998" else 0)
data["1999"] = data["date_local"].apply(lambda x: 1 if x=="1999" else 0)
data["2000"] = data["date_local"].apply(lambda x: 1 if x=="2000" else 0)
data["2001"] = data["date_local"].apply(lambda x: 1 if x=="2001" else 0)
data["2002"] = data["date_local"].apply(lambda x: 1 if x=="2002" else 0)
data["2003"] = data["date_local"].apply(lambda x: 1 if x=="2003" else 0)
data["2004"] = data["date_local"].apply(lambda x: 1 if x=="2004" else 0)
data["2005"] = data["date_local"].apply(lambda x: 1 if x=="2005" else 0)
data["2006"] = data["date_local"].apply(lambda x: 1 if x=="2006" else 0)
data["2007"] = data["date_local"].apply(lambda x: 1 if x=="2007" else 0)
data["2008"] = data["date_local"].apply(lambda x: 1 if x=="2008" else 0)
data["2009"] = data["date_local"].apply(lambda x: 1 if x=="2009" else 0)
data["2010"] = data["date_local"].apply(lambda x: 1 if x=="2010" else 0)
data["2011"] = data["date_local"].apply(lambda x: 1 if x=="2011" else 0)
data["2012"] = data["date_local"].apply(lambda x: 1 if x=="2012" else 0)
data["2013"] = data["date_local"].apply(lambda x: 1 if x=="2013" else 0)
data["2014"] = data["date_local"].apply(lambda x: 1 if x=="2014" else 0)
data["2015"] = data["date_local"].apply(lambda x: 1 if x=="2015" else 0)
data["2016"] = data["date_local"].apply(lambda x: 1 if x=="2016" else 0)
data["2017"] = data["date_local"].apply(lambda x: 1 if x=="2017" else 0)После преобразований размерность набора данных была значительно увеличена, так как возросло число параметров с 22 до 114.
Ниже приведу фрагмент (1/4 часть корреляционной матрицы конечного набора данных):

Модель предсказания:
В качестве инструмента для построения гипотезы предсказания я остановил свой выбор на линейной регрессии. Точность предсказания на исходном наборе данных составляла от 17% до 22%. Точность предсказания после введения новых переменных и преобразования набора данных составила:

Визуализация данных:
Карта США с отображением точек, где проводились измерения:
m = Basemap(llcrnrlon=-119,llcrnrlat=22,urcrnrlon=-64,urcrnrlat=49,
projection='lcc',lat_1=33,lat_2=45,lon_0=-95)
longitudes = data["longitude"].tolist()
latitudes = data["latitude"].tolist()
x,y = m(longitudes,latitudes)
fig = plt.figure(figsize=(12,10))
plt.title("Polution areas")
m.plot(x, y, "o", markersize = 3, color = 'red')
m.drawcoastlines()
m.fillcontinents(color='white',lake_color='aqua')
m.drawmapboundary()
m.drawstates()
m.drawcountries()
plt.show() 
Штаты с наибольшим средним количеством выбросов CO за все время(красной линией отмечен максимально допустим уровень пригодный для жизни):
graph = plt.figure(figsize=(20, 10))
graph = data.groupby(['state_name'])['arithmetic_mean'].mean()
graph = graph.sort_values(ascending=False)
graph.plot (kind="bar",color='blue', fontsize = 15)
plt.grid(b=True, which='both', color='white',linestyle='-')
plt.axhline(y=1.2, xmin=2, xmax=0, linewidth=2, color = 'red', label = 'cc')
plt.show ();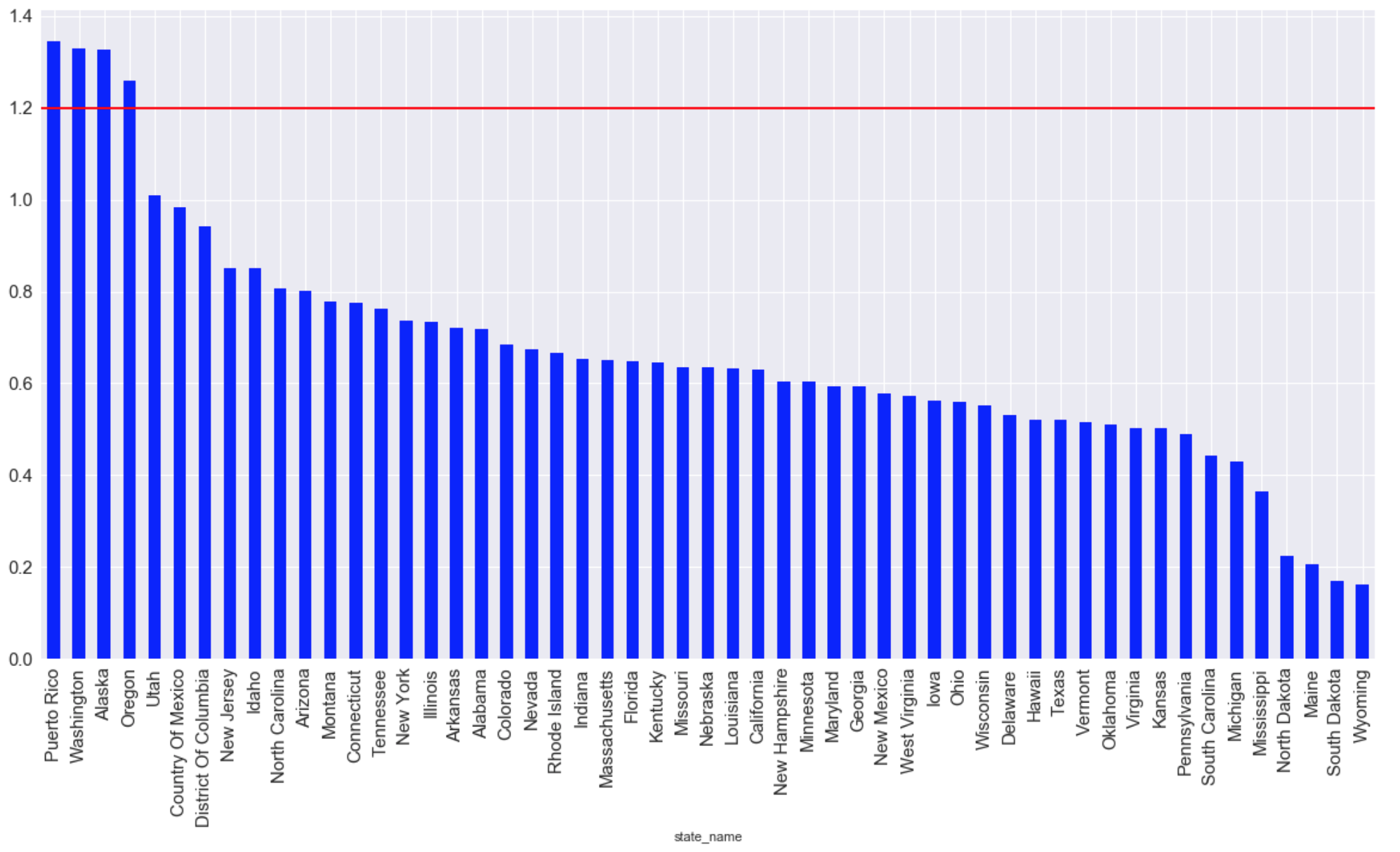
Хронология развития уровня количества выбросов:

Комментарии (16)

Mn0g0kratn0Ub1ennbIyNaGT
28.10.2017 21:37Что-то пропущено? После импорта библиотек сразу проверка данных. А где загрузка данных? Скиньте уж и мне тогда. Спасибо.
born_2fuck Автор
28.10.2017 21:38ну если так прям критично)
data = pd.read_csv('.../epa_co_daily_summary.csv') data.head(3)
Mn0g0kratn0Ub1ennbIyNaGT
28.10.2017 21:54«сразу можно выявить 2 положительные корреляции с целевым параметром: ['arithmetic_mean'] и ['first_max_hour'], ['first_max_hour'].» — опечатка?
Mn0g0kratn0Ub1ennbIyNaGT
28.10.2017 21:58data['county_name'] = data['county_name'].factorize()[0] — зачем дважды повторяется?
Как я понимаю, судя по вот этой строчке
data['address'] = data['address'].factorize()[0]
модель никак не учитывает географическую близость или удалённость измерений?born_2fuck Автор
28.10.2017 22:07с ['county_name'] нужен int, а не категориальный признак.
Mn0g0kratn0Ub1ennbIyNaGT
29.10.2017 01:03Я имел в виду, что преобразование адреса в координатты могло бы дать дополнитеьную ценную характеристику, которая показала бы зависимости между близко лежащими точками замеров. А так этот int в общем-то смысловой нагрузки не несёт.
Ещё соображение — 2 параметра имеют корреляцию 1 (observation-count и observation_percent) — один можно выкинуть без потери качества, нет?
Кроме того, имея координаты можно за ненадобностью выкинуть несколько геогрфических характеристик — штат, город, сounty
Mn0g0kratn0Ub1ennbIyNaGT
29.10.2017 01:18Ещё не понял идею с добавлением аж пяти характеристик — сезон и 4 времени года. Не достаточно ли было просто ввести номер месяца?
Аналогично — зачем каждый год заводить как отдельную характеристику? Почему не ограничиться одной колонкой — номер_года?born_2fuck Автор
29.10.2017 01:21Я согласен, но тут думаю дело вкуса, я решил распарсить на сезоны и года, мог бы еще отдельно и на месяца + просто из интереса решил посмотреть корреляции между целевой переменной и каждым отдельным годом.
tunelix
29.10.2017 16:49Расскажите какое у вас железо, и насколько быстро подобная выборка там ворочается
born_2fuck Автор
29.10.2017 21:55Macbook Pro 13(2015) 16GB, i-7 3,1Hz. При использовании простой линейной регрессии обучение занимало минут 40. Random Forest в зависимости от глубины и количества деревьев от 20 минут до 6-7 часов.
Mn0g0kratn0Ub1ennbIyNaGT
29.10.2017 20:58Поигрался с моделью и подведу итог.
1. Спасибо за пример и библиотеку mpl_toolkits.basemap — буду пользоваться
2. По части упорядочения характеристик (feature engineering) решение спорное
— не убраны характеристики с единичной корреляцией, не несущие никакой дополнительной информации, лишь перегружающие и без того огромный набор данных
— оставлены многочисленные дублирующие признаки — если есть координаты, то все прочие географичесие признаки — адрес, код кантона (не понял что это в США), имя кантона, код города, имя города, штат, номер сайта, имя сайта… — не несут никакой дополнительной информации, лишь перегружают набор данных
— созданы избыточные временные признаки — времена года и сезон, которые также не несут никакой дополнительной информации, лишь перегружают набор данных
— выделение каждого года в отдельный признак (+26 измерений в и без того распухшем пространстве!) не только сделали набор данных крайне тяжёлым, но это ещё и вредно. Т.к. в этом случае модель не видит, что 2007 год следует за 2006, для неё это просто независимые координаты, т.е. утрачена часть информации, которая безусловно была бы использована моделью.
Для анализа данных, может, и полезно, но для вычислений вредно. Итого, исчерпав всю память мой ноут сдох, поэтому повторить эксперимент не удалось.
Ну и последнее, я бы использовал для данной задачи нейронную сеть, а не линейную регрессию.
Не претендую на истину в конечной инстанции, в порядке обмена мнениями.
Ещё раз спасибо.
mouze1976
Хотелось бы посмотреть на весь код и исходные данные.
born_2fuck Автор
Могу вам скинуть