
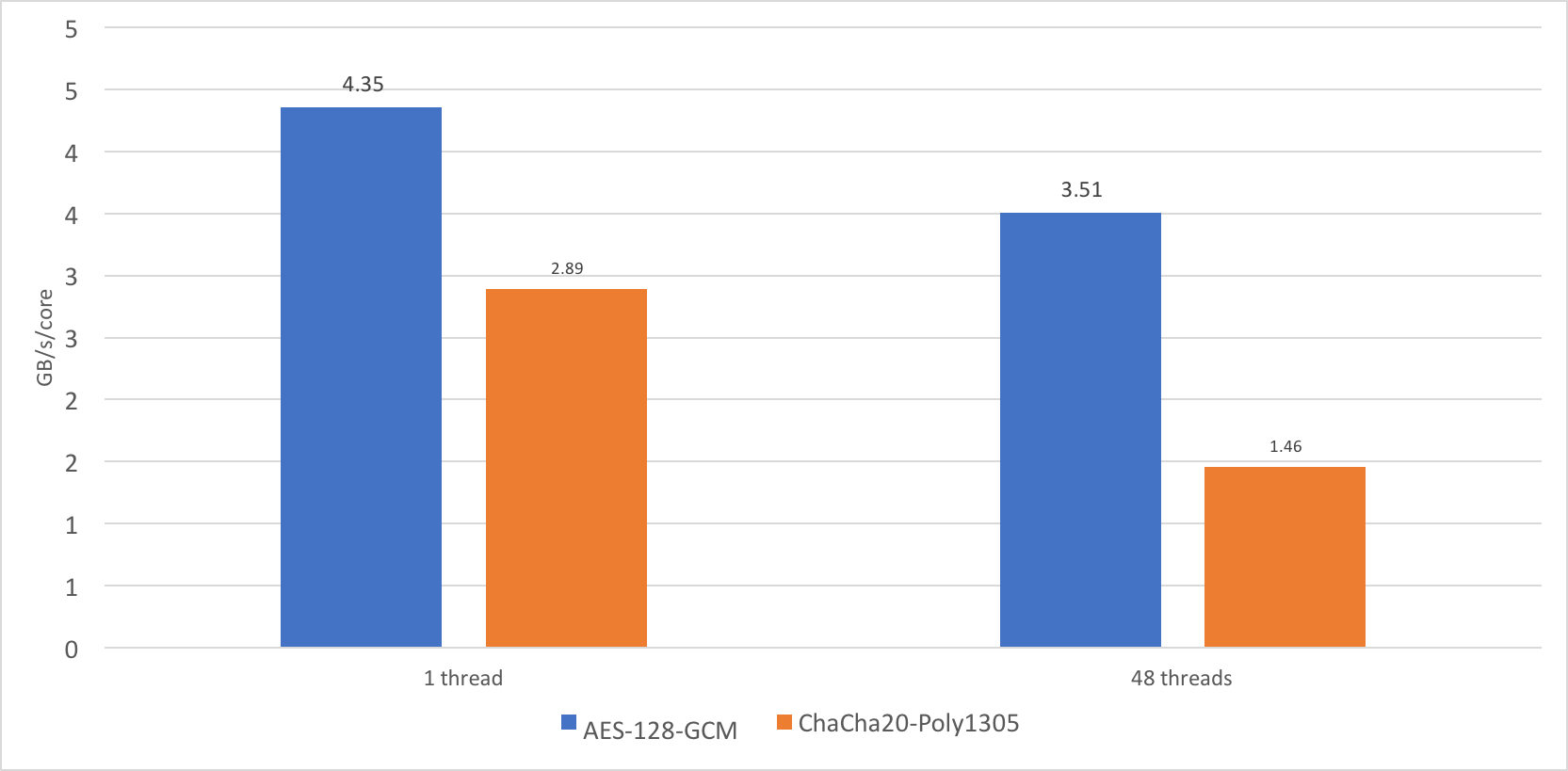
Во время сравнения нового серверного чипа Centriq от Qualcomm с имеющимися в наличии Intel Xeon поколения Skylake мною была замечена странная штука: производительность шифра ChaCha20-Poly1305 плохо масштабируется при добавлении ядер. Один поток работал на скорости примерно 2,89 Гбайт/с, а на 24 ядрах и при 48 потоках сумарная производительность составила всего лишь 35 Гбайт/с.
Неплохо, конечно, но я ожидал увидеть что-то вроде 69 Гбайт/с. 35 Гбайт/с это всего лишь 1,46 Гбайт/с на ядро, или около 50 % от производительности одного ядра. AES-GCM масштабируется в тех же условиях гораздо лучше, до примерно 80 % производительности одного ядра, что объясняется способностью процессора повышать частоту при нагрузке на одно ядро.

Почему же ChaCha20-Poly1305 масштабируется так плохо? Познакомьтесь с набором инструкций AVX-512, который расширяет большинство существующих SIMD-инструкций до 512 бит и добавляет несколько новых. Проблема в том, что они потребляют значительное количество энергии, ведь за один заход требуется выполнить от 8 до 64 обычных операций.
Для сохранения энергопотребления на приемлемом уровне Intel в семействе процессоров Haswell 3 года назад ввёл динамическое изменение частоты. Этот механизм уменьшает базовую частоту процессора в случае исполнения AVX2 или AVX-512 инструкций. Если исполняется только код AVX-512, всё в порядке. Частота ниже, но общее количество операций, выполняемых в единицу времени, больше.
OpenSSL 1.1.1dev содержит несколько вариантов реализации ChaCha20-Poly1305, включая использование AVX2 и AVX-512. BoringSSL реализует алгоритм несколько другим образом и только с использованием AVX2, поэтому его производительность на одном ядре всего 1,6 Гбайт/с вместо 2,89 Гбайт/с у OpenSSL.
Какое влияние это оказывает в ситуации, когда нагрузка представляет из себя смесь обычных вычислений и небольшой доли вычислений с использованием AVX-512? Мы используем Xeon Silver 4116 с базовой частотой 2,1 ГГц в двухсокетной конфигурации. Из таблицы, найденной на wikichip, видно, что выполнение инструкций AVX-512 даже на одном ядре уменьшит базовую частоту до 1,8 ГГц, а выполнение инструкций на всех ядрах уменьшит базовую частоту до 1,4 ГГц.
Представим, что у нас есть вебсервер (Apache или NGINX), на котором вдобавок выполняются приложения. Возникает вопрос: что будет, если начать шифровать трафик алгоритмом ChaCha-Poly1305, реализованным с помощью инструкций AVX-512?
Я собрал две версии NGINX: одну с OpenSSL 1.1.1dev, другую с BoringSSL — и установил их на сервер с двумя Xeon Silver 4116, получив в сумме 24 ядра. Вебсервер сконфигурирован на обработку и отдачу HTML-страницы среднего размера. Использовался LuaJIT для удаления переводов строк и лишних пробельных символов, а также сжатие страницы алгоритмом brotli. Затем я измерил количество запросов, которые сервер был способен обработать при полной нагрузке.

При использовании ChaCha20-Poly1305 вместо AES-GCM вебсервер, собранный с OpenSSL, обслужил на 10 % меньше запросов, что эквивалентно простаиванию двух ядер процессора. Можно предположить, что такая разница наблюдается в силу невысокой скорости работы самого алгоритма ChaCha20-Poly1305, но это не так.
Во-первых, BoringSSL показал одинаково хорошие результаты с обоими алгоритмами шифрования. Во-вторых, даже когда только 10 % запросов используют ChaCha20-Poly1305, производительность падает на 5,5 %, и на 7 % в случае, если доля таких запросов доходит до 20 %. Для справки: в реальном HTTPS-трафике Cloudflare доля запросов, использующих алгоритм ChaCha20-Poly1305, составляет 15 %.
По данным perf процессор тратит на обработку инструкций AVX-512 только 2,5 % времени при 100 % доле запросов с ChaCha20-Poly1305, и менее 0,3 % при доле таких запросов в 10 %. Независимо от доли запросов частота CPU снижается, ведь инструкции AVX-512 выполняются на всех ядрах сразу.
Сложно сказать, насколько понижается частота процессора в конкретный момент времени. Однако, понаблюдав за показаниями lscpu, я выяснил, что во время исполнения команды openssl speed -evp chacha20-poly1305 -multi 48 получается CPU MHz: 1199.963; для вебсервера с OpenSSL и алгоритмом AES-GCM получается CPU MHz: 2399.926, а для вебсервера с OpenSSL и алгоритмом ChaCha20-Poly1305 — CPU MHz: 2184.338, то есть на 9 % меньше.
Ещё одно интересное различие в том, что алгоритм ChaCha20-Poly1305 с использованием AVX2 немного медленнее работает в OpenSSL, но не теряет в производительности в BoringSSL. Причина в том, что BoringSSL не использует инструкции умножения AVX2 для Poly1305, а для ChaCha20 использует только относительно простые инструкции xor, shift, add, что позволяет ядру оставаться на базовой частоте.
OpenSSL 1.1.1dev всё ещё находится в разработке, поэтому я подозреваю, что эта проблема ещё никому не встретилась. Мы переключились на использование BoringSSL несколько месяцев назад, и производительность наших серверов не будет страдать от описываемого эффекта.
Что день грядущий нам готовит? Для будущих поколений Intel анонсировал новые наборы инструкций, которые должны ещё больше повысить производительность криптографических операций. Это расширения включают в себя AVX512+VAES, AVX512+VPCLMULQDQ и AVX512IFMA. Однако если проблемы с понижением частоты к тому времени не будут решены, использование новых наборов инструкций может принести с точки зрения производительности больше вреда, чем пользы.
Проблема не только и не столько в криптографических библиотеках. Авторов OpenSSL нельзя винить в том, что они ищут пути для увеличения производительности, наоборот, я сам написал приличное количество кода OpenSSL, использующего AVX-512. Наблюдаемое поведение это всего лишь печальный побочный эффект. Существует множество библиотек, которые используют AVX-512, и пользователи скорее всего не в курсе деталей их реализации. Если вам не требуется использование AVX-512 для специфических вычислительно-ёмких задач, я предлагаю вам выключить их поддержку на ваших серверах и персональных компьютерах во избежание нежелательного понижения частоты процессора.
Разумеется, эти факты описаны в руководящей документации: само по себе снижение частоты описано в Optimizing Performance with Intel Advanced Vector Extensions, а пределы её изменения в зависимости от количества занятых выпонением операций ядер для конкретного процессора семейства Skylake в Intel® Xeon® Processor Scalable Family Specification Update. Однако документы эти не для широкой публики в том смысле, что читают и даже знают об их существовании немногие, да и описано там далеко не всё, что хотелось бы знать. Мне не удалось отыскать, например, официальное описание работы PCU и собственно алгоритма понижения частоты при выполнении инструкций AVX-512 и её повышения после.
На Хабре уже были статьи, в которых обсуждалось применение AVX-512 в разработке (например, Как я сделал самый быстрый ресайз изображений. Часть 2, SIMD). Я нахожу очень полезным знать о нюансах поведения современных процессоров и системным администраторам тоже (как бы их сейчас не называли), поэтому и публикую перевод в хаб «Системное администрирование».
Разъяснение: переводчик никак не связан с Cloudflare, Inc. Перевод сделан из любви к искусству, все права у их обладателей. Автор КДПВ blumblaum, CC BY-SA 2.0. Заголовок придумал CodeRush.
Комментарии (7)

orcy
14.11.2017 11:29Выглядит это конечно довольно забавно: инструкции призванные для увеличения производительности на деле замедляют ее. Не знаю правильно ли я понял что это имеет место только для многопоточного случая, однопоточный режим работы наоборот получает повышение производительности?

Marwin
14.11.2017 11:36насколько я понимаю, уменьшение производительности тут косвенное ввиду неоднородной нагрузки, так как кроме собственно шифрования мы еще параллельно обслуживаем вебсервер, который начинает страдать от сниженной частоты. Если бы мы Только шифровали, эффект был бы положительным.
orcy
14.11.2017 13:26Стало интересно. Судя по ссылки из примечания переводчика процессор занижает частоту чтобы остаться в нужных пределах по нагреванию (TDP). Типа AVX инструкции требуют большее энергии:
«Intel AVX instructions require more power to run. When executing these
instructions, the processor may run at less than the marked frequency to maintain
thermal design power (TDP) limits.»
rzerda Автор
14.11.2017 15:23Комментарии выше верны: PCU «видит» исполнение инструкций AVX и в некоторых случаях (для некоторых инструкций) соответствующим образом снижает частоту. Изменение частоты занимает какое-то время, и даже небольшое число инструкций способно продержать процессор на пониженных частотах довольно долго (в некоторых источниках указывается время реакции на отсутствие AVX команд в 1 мс, что по меркам процессора вечность). В это же время на процессоре исполняется и «обычный» код, который от понижения частоты страдает. А так как как обычного кода в тестах автора подавляющее большинство, то и общая производительность падает довольно значительно.
Duss
14.11.2017 14:55Если вам не требуется использование AVX-512 для специфических вычислительно-ёмких задач, я предлагаю вам выключить их поддержку на ваших серверах
Не настолько силен в настройке серверов. Как-то можно отключить набор инструкций? Т.е. имеется в виду отключить на уровне сервера, я верно понял?rzerda Автор
14.11.2017 15:42Пока мало видел серверов на Skylake, но, скорее всего, в BIOS просто так выключить набор инструкций нельзя. В ход можно пустить маскирование результатов инструкции CPUID (в основном, в виртуализации), либо пересборку ПО без использования этих инструкций.
navion
Стоит добавить, что с двумя AVX-512 FMA ситуация намного лучше (Xeon Gold 6126 и выше).