
Вот к такому можно стремиться
У нас больше 350 своих разработчиков ПО и тестировщиков по всей стране, плюс мы часто взаимодействуем с инженерами и разработчиками заказчиков. Чтобы перейти на практическое использование devops, нам нужно было обеспечить не только внедрение методологии, но и приучить любимых российских заказчиков к некоторой базовой культуре. Просто пара диалогов для понимания:
— Почему у нас всё упало?
— Потому что вы откатали это на стенде, всё протестировали, а потом развернули на проде. Вот у вас настройка, которая не попала в инструкции, и жила только в голове старого админа.
Или:
— Почему не запускается по всей стране?
— Потому что у вас несколько десятков разных региональных инсталляций, каждая делалась руками, и на каждой разные конфиги. И ещё в паре случаев инженер ошибся.
— Поправите до завтра? Очень нужно! Только доступ удалённо мы вам не дадим.
— ..! Конечно, у нас есть команда высокооплачиваемых спецов, обожающих ездить на Дальний Восток. Нет проблем.
Культур-мультур
— Что с тестовым стендом?
— Он занят демонстрацией для финдиректора.
— А где мне тестировать?
— Ну, раскатай себе маленький такой же, потом сверни в частном облаке.
— Два часа на стенд. Я тебя просто обожаю!
— Стой, у тебя что, шаблона нет?
Или вот:
Параллельный подрядчик на проекте:
— Здрасьте, дорогой госзаказчик, а мы вам бинарник принесли!
Вмешиваемся мы:
— Не-не-не, у дорогого госзаказчика репозиторий, сборка, все дела. Сложите код вот сюда, зачекиньте, посмотрим, как развёртывается…
— ОЙ! МЫ ТАК НЕ РАБОТАЕМ!
— Сколько, говорите, у вас админов?
— Ну, около сотни, кто ж их считает-то.
— А почему так много?
— Контур большой, а автоматизацию пока не делали, что-то дорого… Хотя стоп!
В общем, под базовой культурой я понимаю примерно следующее:
- Инфраструктуру от поднятия в облаке до разливки системного софта нужно получить в виде кода.
- Разливать успешную сборку с билд-сервера автоматически по процессу, не трогая ничего руками (то есть единообразно, лишь управляя настройками в частных случаях). Ладно, рукой можно нажать кнопку «Старт».
- Удобно визуально контролировать ход движения всех сборок по конвейеру поставки — от чекина до прогона автоматических тестов.
В итоге будут сэкономлены время и деньги. А ещё при получении кода от подрядчиков не будет такого, что через два года дорогой заказчик обнаружит, что диск с исходниками, сложенный на стеллаже, не имеет никакого отношения к тому, что крутится на сервере, а подрядчик канул в лету.
Насаждение этой культуры
Это боль, сопли, слёзы и прочие драмы. Часто общение происходит примерно вот в таком духе:
— Да-да, круто. Я читал посты на Хабре, знаю, как это круто. Автоматизация нужна.
— Так давайте внедрим?
— Нет, что вы. У нас Documentum не последней версии.
— Ну и что?
— И Java старая…
— Смотрите, уже на пяти проектах такой конвейер обкатали. Именно с вашей конфигурацией софта. Включая Альфреску и Вебсферу.
— У нас дедлайн горит.
— Хорошо, а когда он перестанет гореть?
— Ну, уже два года горит, наверное, ещё год где-то. Потом и внедрим.
— Вы понимаете, что у вас инженеров свободных нет и можно проект реально ускорить?
— Дааа, а что надо?
— Скачайте готовую роль, подключите в Ansible — и всё развернётся. Вот инженер, который вам поможет и всё настроит. И ещё вас обучит.
— Хорошо, давайте я рассмотрю ваше предложение в январе на совещании…
До прошлого года у нас в проектах разработки жёстко требовался только Continuous Integration (сборка на TeamCity/Jenkins, анализ кода, юнит-тесты). Полноценный переход к continuous delivery и continuous deployment на уровне компании осложнялся разнообразием используемых инфраструктуры, технологий, нюансами работы с внешними заказчиками. Так что до прошлого года у нас не было единого стандарта и набора рекомендаций для инженеров, занимающихся эксплуатацией (служб эксплуатации у заказчиков), — каждый работал со своим стеком.
Мало кто понимает, как работает автоматизация. Одни считают, что это дорого и сложно — «Мы не будем рисковать на этом проекте». Но для примера — после того как несколько команд обкатали свой стек внутри КРОК, многие на практике поняли, что сэкономленные временные и человеческие ресурсы куда реалистичнее, чем кажутся. И с этого момента понеслось. Поэтому если инженер с прошлого проекта получает задачу от менеджера «Разверни мне десяток серверов вручную», то он имеет полное право предложить пойти в сторону автоматизации, и я как руководитель буду на его стороне.
Поскольку мы не привыкли насаждать культуру административными мерами, то устроили ресёрч, выбрали инструменты и обкатали на самых заковыристых проектах с разнообразными технологическими стеками (интеграционные проекты на Вебсфере, ECM проекты на Documentum и Alfresco, заказная разработка на java & .Net). В результате получили довольных парней (и девчонок), железобетонные аргументы для убеждённых пессимистов и базу наработок.
Дальше — история обзора инструментов и внедрения. Если вы всё знаете — идите сразу вниз, в разделе «Инструменты» вряд ли встретится что-то интересное для экспертов, это больше ликбезы.
Инструменты
350 разработчиков работают со своими стеками технологий, своими зоопарками — плюс есть и Amazon EC2 API, и Openstack с VMware в виртуальной лаборатории КРОК. Ещё у нас была куча скриптовых инструментов на нижнем уровне. Но наверху непонятно, что где отвалилось, где какой билд, как выглядит конвейер и что происходит. Нужен был инструмент визуализации.
Перед нами возникла непростая задача собрать комплексное решение по автоматизации конвейера поставки из бесплатного свободно распространяемого ПО, которое бы в свою очередь не сильно уступало промышленным проприетарным решениям данного класса.
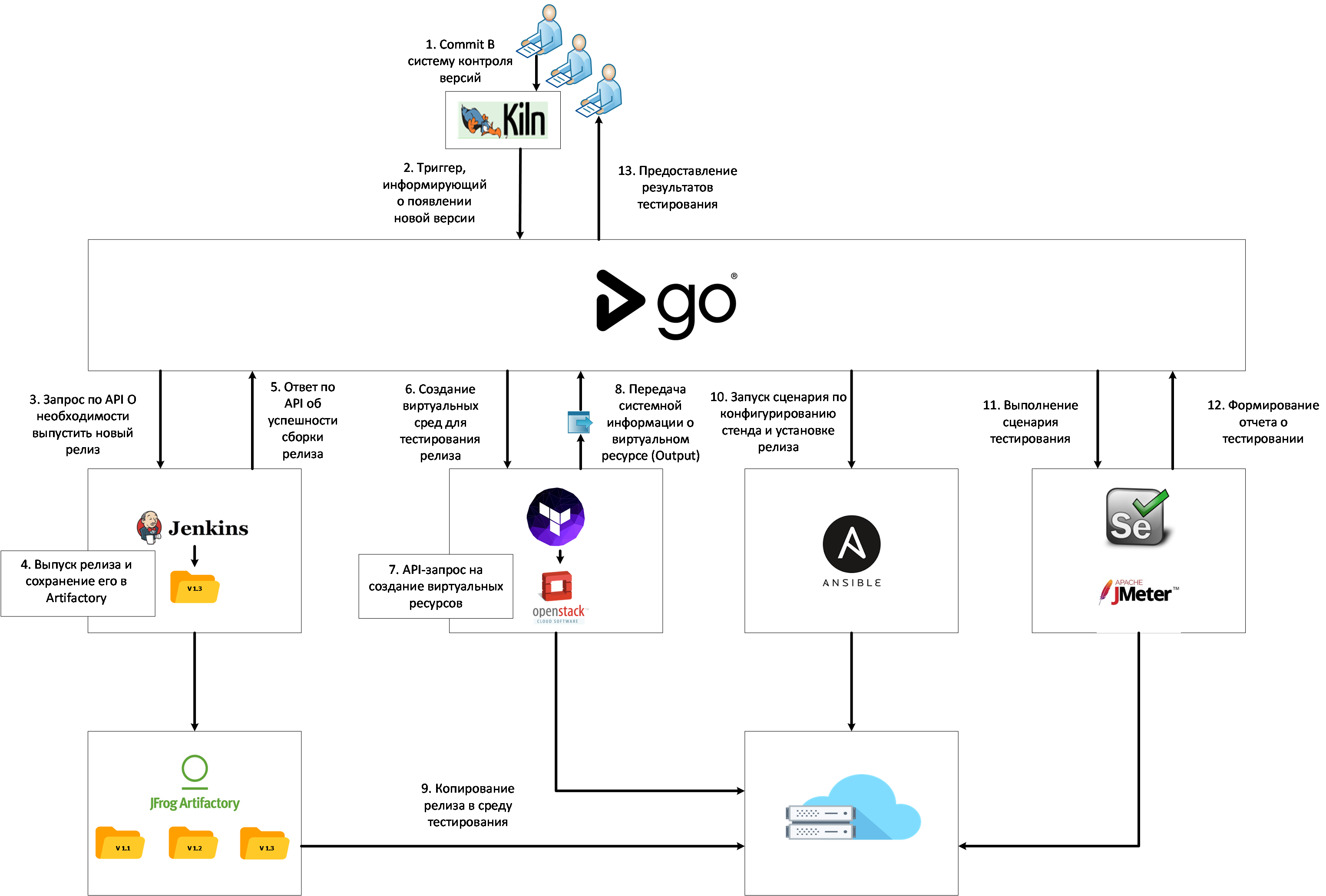
Архитектура систем такого класса состоит из трёх компонентов:
• На верхнем уровне — решение для автоматизации и визуализации конвейера поставки приложения. Это прежде всего веб-интерфейс, в котором конечный пользователь может проследить прохождение всех стадий релиза — от первичной сборки пакета из исходного кода до прохождения всех тестов, перезапустить какую-либо стадию, посмотреть логи, если процесс завалился.
• Решение для автоматизации развёртывания инфраструктуры. Это некий оркестратор, задача которого создать инфраструктуру под наше приложение — виртуальные машины в том или ином облачном провайдере. В данном кейсе компонент отвечает за создание базовой инфраструктуры, за тонкую настройку и конфигурацию ПО отвечает следующий компонент.
• Решение для управления конфигурациями, необходимое для настройки уже созданной инфраструктуры, как-то: установки системного ПО, дополнительных приложений, необходимых релизу, конфигурации БД и серверов приложений, инициации выполнения различных скриптов и непосредственно установки релиза нашего приложения.
Для каждого из блоков мы провели анализ наиболее актуальных и востребованных инструментов, подходящих для нас. Рассмотрим каждый из компонентов поподробнее, начнём с верхнего уровня.
Что мы хотели от инструментов и что смотрели
Основными критериями выбора инструментов (помимо того, что это должен быть опенсорс) были:
• универсальность в части интеграций: инструмент должен поддерживать все основные системы контроля исходного кода, которые используются на проектах (git, mercurial, TFS), должен дружить с CI Jenkins и Teamcity, уметь работать с системами тестирования Selenium и JMeter, должно быть легко настраиваемым взаимодействие с опенсорсными системами развёртывания инфраструктуры и управления конфигурациями;
• возможность экспорта/импорта настроенного конвейера и настроек в текстовый конфиг (Pipeline-as-a-Code);
• кривая обучения: требовалось в конечном счёте обучить найденному инструменту рядовых инженеров-внедренцев. Инструмент должен быть несложным в освоении и настройке.
Начали с Jenkins: в качестве CI он у нас уже стоял и функционировал. Подошёл бы он нам в качестве решения CD и Pipeline Automation? Как оказалось — нет, несмотря на огромное количество плагинов и интеграций, и вот почему:
• проект Blue Ocean не предполагает пока административного интерфейса, можно наблюдать красивые картинки прохождения релиза по стадиям, но нельзя из того же интерфейса перезапустить конкретный шаг;
• сам конвейер необходимо писать в виде исходного кода, причём язык написания декларативных пайплайнов всё ещё сыроват — сложности при администрировании и обучении;
• наряду с Jenkins мы эксплуатируем Teamcity, для части проектов он удобнее.
Из-за этих причин, из соображений стабильности (есть стабильный функционирующий Jenkins, который не хотелось грузить дополнительными плагинами) и функционального разделения (всё-таки Jenkins, как и TeamCity, у нас используются как серверы CI для непосредственно сборки ПО) мы продолжили исследование.
Hygeia, проект разработчиков банковской фирмы CapitalOne, привлёк нас прежде всего информативным пользовательским интерфейсом, в котором, помимо всего прочего, можно увидеть и статистическую информацию по коммитам и контрибьюторам, сводку по задачам спринта, список реализуемых в спринте фич. Тем не менее, несмотря на исчерпывающий web ui, инструмент оказался узкоспециализированным для задач создателей.
Под наши критерии Hygeia не подошла из-за отсутствия необходимых нам интеграций, недостаточного на момент исследования документирования и из-за сложностей с расширением и кастомизацией функционала инструмента.
Далее мы обратили внимание на Сoncourse CI, созданный сообществом Cloud Foundry Foundation прежде всего для сопровождения проектов, связанных с Cloud Foundry. Concourse CI подходит для очень крупных проектов с необходимостью развёртывания и тестирования по нескольку релизов в минуту, интерфейс позволяет оценить статус сразу нескольких веток релизов приложения. Для наших задач Concourse не подошёл из-за отсутствия нужной нам гибкости и универсальности в части интеграций, плюс нам требовалась более детальная картина отображения прохождения разных версий релизов конкретной ветки приложения (в Concourse на общей картине статус только последних версий).
Последним мы рассмотрели проект GoCD. Историю свою GoCD ведет с 2007-го, в 2014-м был выложен исходный код в сообщество. GoCD удовлетворил нашим критериям универсальности интеграций: всё, что нам было необходимо в GoCD, поддерживалось из коробки или была возможность легко настроить. Также в GoCD есть важная для практик DevOps реализация парадигмы Pipeline-as-a-code.
Среди минусов можно отметить:
• не интуитивную для быстрого погружения вложенность сущностей: нелегко сразу разобраться со всеми stages, jobs, tasks и т. д.;
• необходимость установки агентов, a для масштабирования и многопоточности требуется установка дополнительных агентов.
С верхним уровнем определились, рассмотрим оставшиеся два блока
Основным критерием выбора инструментов развёртывания инфраструктуры была поддержка гетерогенных сред известных облачных провайдеров: AWS, Openstack и VMware vSphere. Мы рассматривали Bosh, Terraform и Cloudify.
Bosh, как и Concourse CI, создан сообществом Cloud Foundry Foundation. Достаточно мощный инструмент с непростой архитектурой, среди плюсов можно отметить:
• возможность мониторинга развёрнутых через Bosh сервисов;
• возможность восстановления после сбоев развёрнутых сервисов как автоматически, так и по кнопке;
• объектовый репозиторий для развёртываемых компонентов;
• встроенный функционал контроля версионности развёртываемых компонентов.
Однако богатая функциональность обеспечивается за счёт собственных форматов шаблонов виртуальных машин, по этой причине и по причине общей сложности инструмента Bosh нам не подошёл.
Terraform — широко известный в сообществе инструмент компании Hashicorp. Как и другие свободно распространяемые продукты компании — архитектурно представляет собой бинарный файл. Прост в установке, прост в освоении: достаточно описать в декларативном формате необходимую для развёртывания инфраструктуру, проверить, как всё это будет развёрнуто командой terraform plan, и запустить на непосредственно выполнение командой terraform apply. Для промышленного применения недостатком бесплатного Terraform может являться отсутствие серверной части, агрегирующей логи, следящей за состоянием запущенных процессов (другими словами, отсутствие централизованного управления и аудита). Этот момент решается в платном Terraform, но нас интересовали исключительно бесплатные инструменты, поэтому в некоторых кейсах помимо Terraform мы решили использовать Cloudify.
Cloudify — инструмент развёртывания инфраструктуры, созданный компанией GigaSpaces. Отличительной особенностью инструмента является де-факто поддержка в декларативных шаблонах IaaC стандарта OASIS TOSCA. По функциональности Cloudify близок к Bosh: есть возможность мониторинга развёрнутых из Cloudify сервисов, есть процесс восстановления после сбоев, а также масштабирования развёрнутого сервиса. В отличие от Bosh, у Cloudify есть интуитивный веб-интерфейс, Cloudify для развёртывания инфраструктуры использует стандартные для облачного провайдера шаблоны ВМ. Функционал инструмента расширяется за счёт плагинов, есть возможность написания собственных плагинов на языке Python. Но нужно сказать, что большая часть графических интерфейсов в последней версии продукта перешла в платную версию.
Итак, для развёртывания инфраструктуры мы выбрали Terraform за счёт простоты, скорости обучения и внедрения и бесплатную версию Cloudify за счёт функциональности и универсальности. Быстренько сделали OpenStack-совместимый API для виртуальной лаборатории, чем подружили его с Terraform.
Осталось определиться с решением для управления конфигурациями. Мы рассматривали большую четвёрку: Ansible, Chef, Puppet и Salt.
Puppet и Chef — «старички» на рынке инструментов управления конфигурациями (первые версии вышли в 2005 и 2009 году соответственно). Написаны на Ruby, хорошо масштабируются, имеют клиент-серверную архитектуру. Для наших задач не подошли прежде всего из-за высокого порога вхождения: очень не хотелось обучать инженеров внедрения языку Ruby, на котором в том числе написаны шаблоны конфигураций.
Salt — решение поновее, написано на Python. Шаблоны конфигураций уже в удобном YAML-формате. Интересной особенностью Salt является возможность как агентского, так и безагентского способа взаимодействия с управляемыми машинами. Тем не менее документация у Salt плохо структурирована и сложна для понимания, нам хотелось работать с ещё более простым для новых пользователей инструментом.
И такой инструмент есть — это Ansible. Этот инструмент прост в установке, прост в использовании, лёгок в освоении. Ansible тоже написан на Python, шаблоны конфигураций — в YAML-формате. У Ansible безагентская архитектура, клиенты на управляемые машины ставить не надо — взаимодействие осуществляется через SSH/PowerShell. Конечно, в инфраструктуре объёмом больше тысячи хостов безагентская архитектура — не лучший выбор из-за возможных просадок по скорости, но перед нами такой проблемы не стояло: объём инфраструктуры наших проектов значительно меньше, Ansible подошёл нам идеально.
Решение
В итоге мы получили следующий набор инструментов для автоматизации конвейера DevOps.
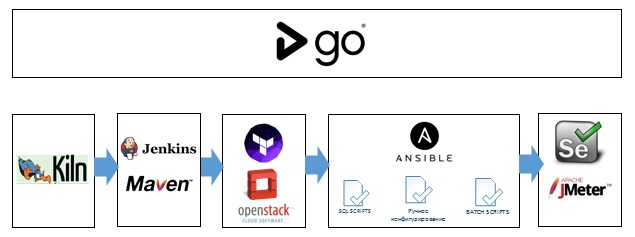
Под капотом Ansible и (в зависимости от кейса) Cloudify или Terraform. На верхнем уровне GoCD.
Далее расскажем о практическом применении выбранных инструментов на одном из наших проектов. Кейс использования DevOps-практик для этого проекта был нетривиален. Разработка велась в нескольких mercurial-репозиториях, не было централизованного хранилища релизов. Отдельного внимания заслуживает техническая документация по развёртыванию ПО, которая предоставлялась Release-инженерам (специально обученным людям, осуществлявшим ручную установку обновлений). Чтобы докопаться до истины, потребовалось по крупицам собирать информацию из документов word, записей в Confluence и сообщений в Slack. Иногда документация была больше похожа на беллетристику с элементами фэнтези. Цитата:
Часть вторая врата ада. Наполнение БД.
2.1 В этой части нас ждёт особенно много трудностей и испытаний, будь внимателен. Для начала подключимся к БД под пользователем SYS с правами DBA
2.2 Читаем заклинания Выполняем скрипты.
После аудита и унификации всех операций разработчикам удалось доработать документацию и представить её в удобном формате, понятном и для человека, и для систем управления конфигурациями.
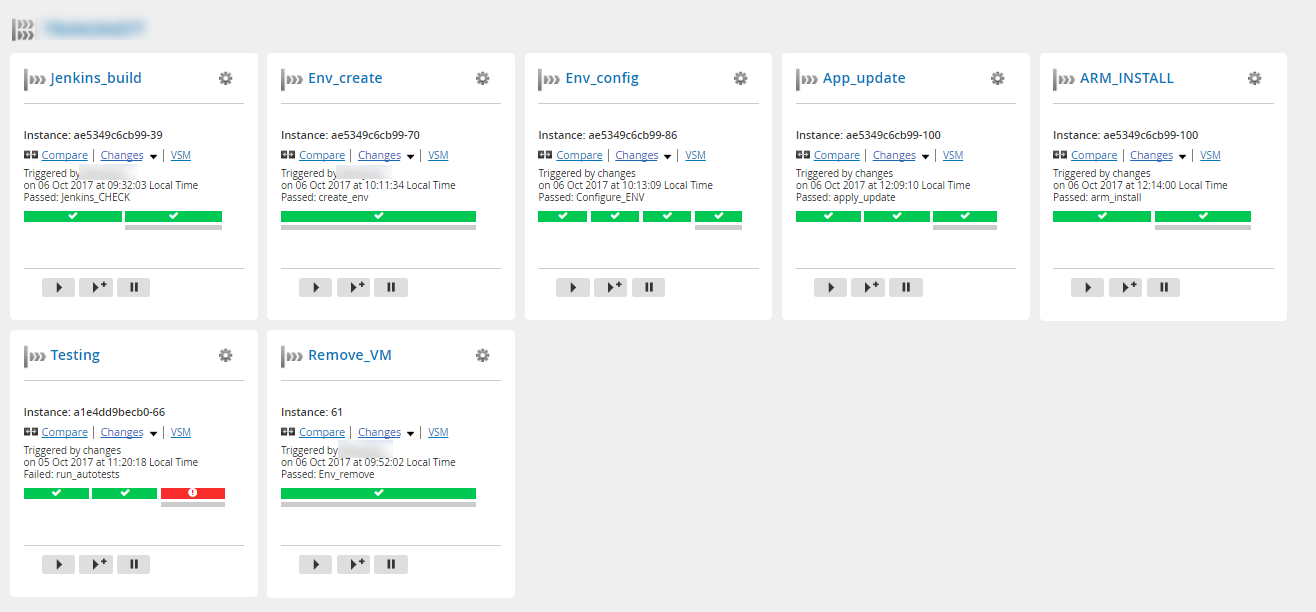
Разработка велась под несколько стендов с незначительными изменениями. Тестовая среда содержала наиболее полный пайплайн CI/CD, который можно разбить на 7 этапов:
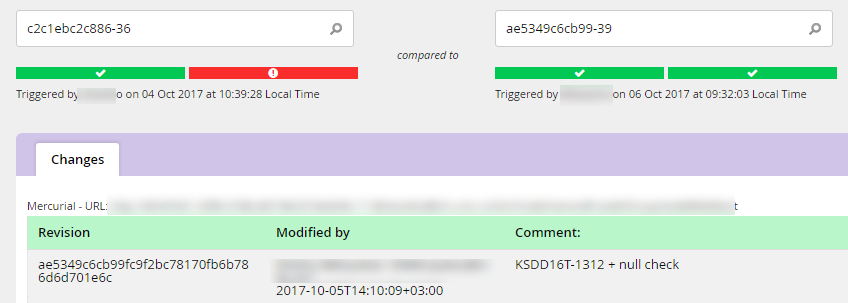
1. Cборка релиза в Jenkins
Заказчик и до нас пользовался Jenkins, правда, делал сборки локально на машине разработчика, а релизы передавал в виде архивов. Мы рассказали, что неплохо бы перенести сборку на централизованный Jenkins-сервер, а артефакты сохранять в Artifactory. Это дало нам возможность иметь сквозную индексацию всех артефактов, возможность оперативно устанавливать нужную версию, тестировать отдельные блоки сценария и видеть, какие изменения повлекли за собой ошибки в сценарии:
2. Развёртывание инфраструктуры
Мы перенесли тестовую среду в виртуальную лабораторию КРОК и перестали содержать её в перманентном состоянии. По запросу тестировщика или автоматически после появления нового релиза в Jenkins среда поднимается на основе Terraform-манифеста из шаблонов ВМ, предварительно загруженных в Openstack нашей виртуальной лаборатории КРОК.
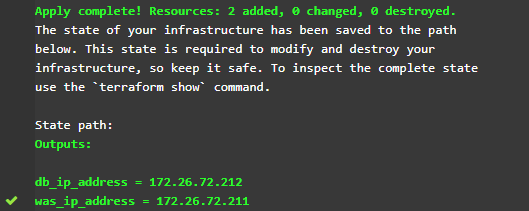
В виде выходных переменных получаем адреса стендов и используем их в дальнейшем в нашем сценарии.
3. Конфигурирование стендов
Наиболее трудозатратной частью пайплайна было разработать механизм автоматизированного конфигурирования стендов.
Нужно было сконфигурировать БД Oracle, настроить шину IBM MQ и сервер приложений IBM WAS. Ситуацию осложнял факт, что все эти настройки необходимо было проделать на русскоязычной Винде (sic!). Если с БД ещё более-менее всё прозрачно, то MQ и WAS до нас в проекте никто не настраивал из CLI или другими автоматизированными средствами, а могли лишь показать, куда нужно нажать в интерфейсе, чтобы всё заработало.
Нам удалось написать универсальные плейбуки, которые за 11 минут выполняют то, на что инженеру требовалось пару дней.

4. Установка основных приложений
Для установки и обновления приложений в WAS заказчик выполнял bat-скрипты, мы не стали сильно в них вникать и в исходном виде встроили в конвейер. Проверяем exit-код, и если он не нулевой, то уже тогда смотрим логи и разбираемся, почему то или иное приложение не взлетело. Логи выполнения скрипта храним в виде артефактов сценария:

5. Установка приложения, предоставляющего пользовательский интерфейс
Этот этап очень похож на предыдущий и выполняется из того же шаблона пайплайна. Отличие лишь в том, какой конфигурационный файл используется в bat-скрипте. Однако нужно было выделить его в отдельный этап для удобства обновления, поскольку не на всех стендах необходим пользовательский интерфейс.
6. Тестирование
Для тестирования приложений использовали разные средства (Selenium, JMeter). Сценарий позволяет варьировать несколько тест-планов, выбор которых задаётся в виде переменных на этом этапе. По итогам тестирования формируются отчёты, для которых мы сделали кастомную вкладку. Теперь их удобно просматривать напрямую из интерфейса GoCD:
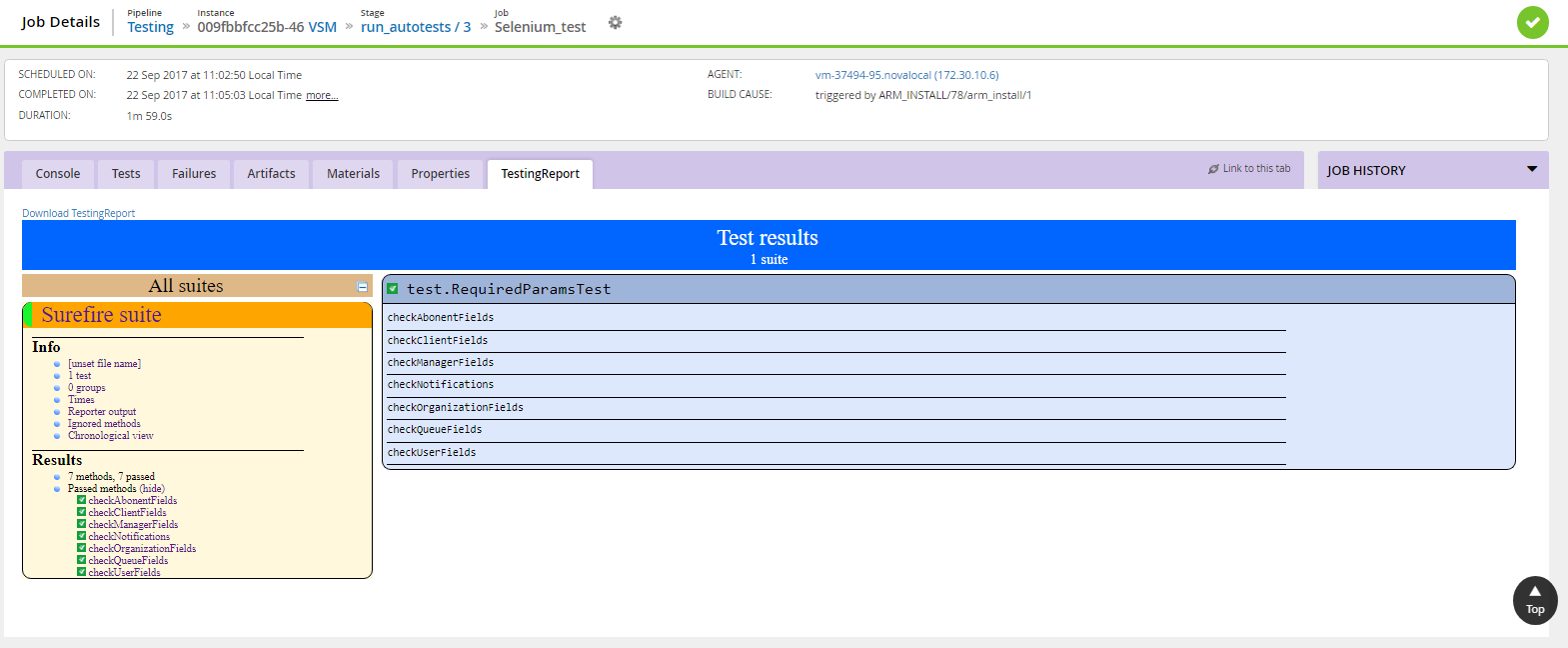
7. Удаление инфраструктуры
По итогам тестирования ответственные лица получают нотификации и принимают решения, пускать ли эту сборку в прод или требуется внести изменения. Если всё хорошо, то тестовые стенды можно удалить и не тратить ресурсы виртуальной лаборатории КРОК.
В итоге получилась следующая логика применения конвейера DevOps для данного проекта:
И вот эти интерфейсы:
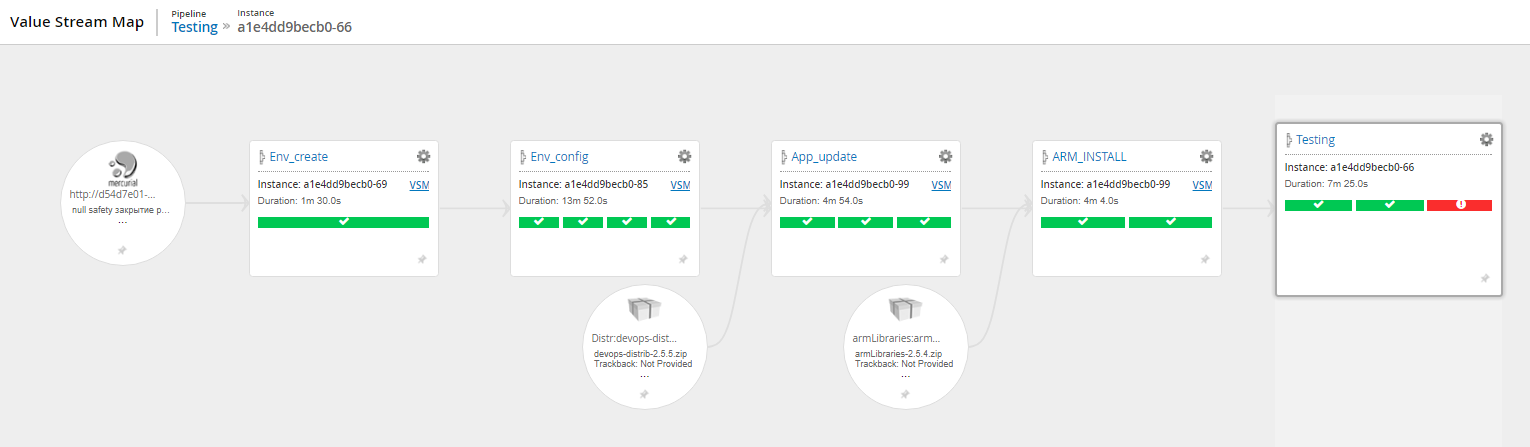
Карта потока (движение релиза от коммита в систему контроля версий до выполнения тестов)
Визуализация статусов выполнения этапов одного сценария
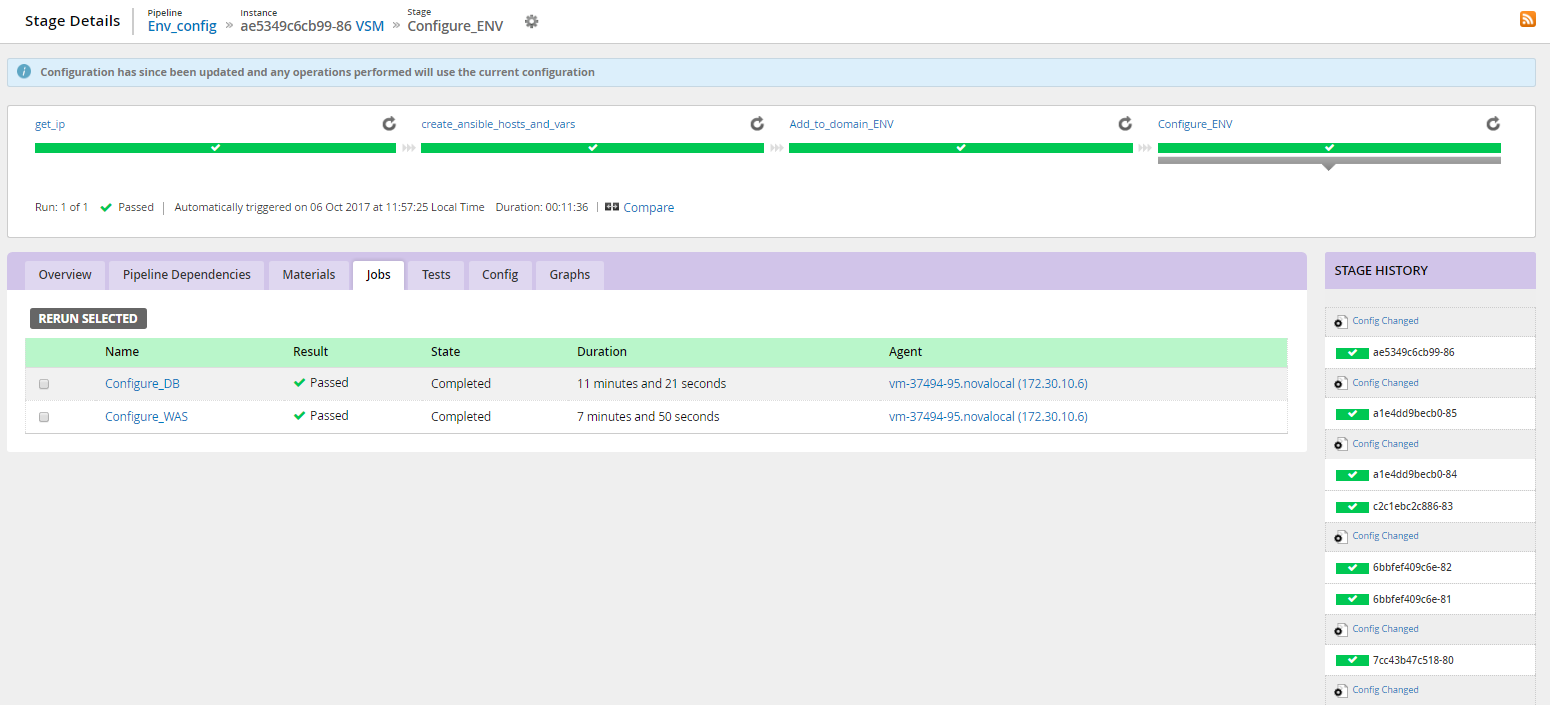
Подробная информация об этапах выполнения сценария (логи, история изменений сценария, время выполнения этапов)
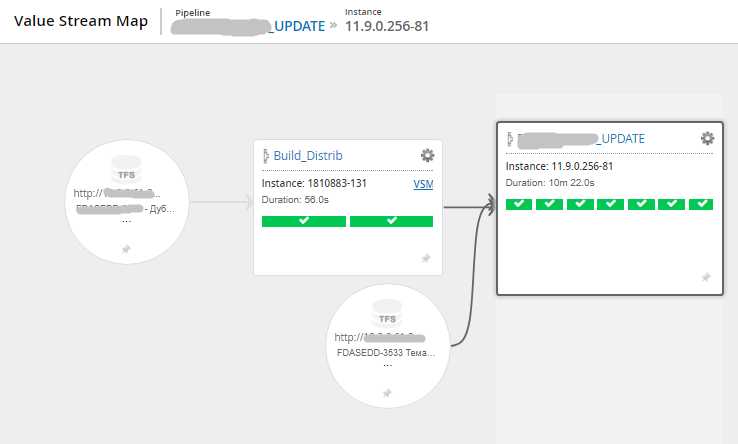
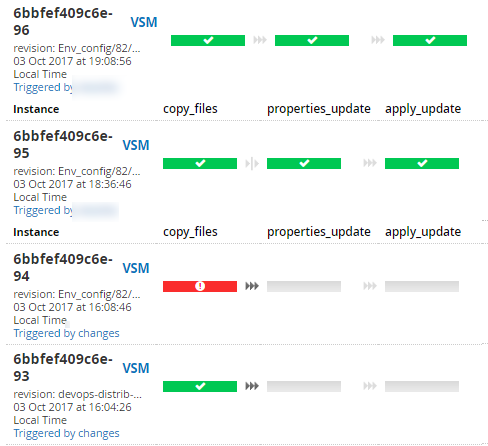
Карта потока (другой проект, более компактная)
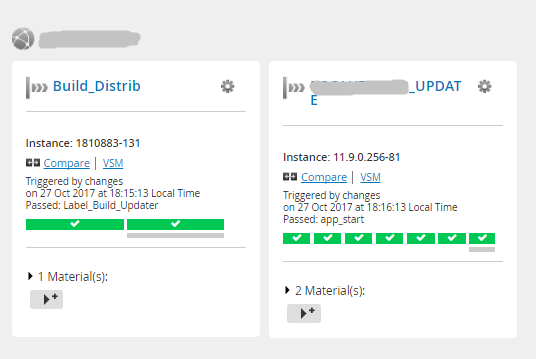
Общий вид сценария из 2 pipeline
Другой пример — на картинке до ката общий вид сценария из 7 pipeline.
По итогам внедрения нового конвейера поставки было важно получить обратную связь от команды (без купюр):
«Значительно (с дней до часов) снизилось время создания новых стендов. Появилась возможность не держать несколько стендов под разные версии. При необходимости нужная версия поднимается с нуля, а сам стенд гарантированно соответствует своему состоянию на момент выпуска нужной версии, т. к. код DevOps версионируется вместе с кодом проекта. Выросло качество экспл. документации. Так как код DevOps явно повторяет инструкции, в них не осталось «подразумевающихся» вещей и т. п. Снизилось количество рутинных операций для инженеров.
Возможность тестировщикам создавать тестовые стенды под сложные случаи (нагрузка, отказоустойчивость) с минимальным привлечением инженеров. Первый шаг к управлению инфраструктурой проекта — версионирование, тестирование и пр. Быстро, удобно, непонятно».
Непонятно, непривычно — довольно частые слова, поэтому мы периодически проводим обучение принятым инструментам.
А это обратная связь из проекта для энергетической компании:
«Автоматизация длительных рутинных операций. Экономия порядка 0,5–1 человекодня в неделю. А в периоды подготовки релиза фактически на 50% один инженер раньше занимался сборками-обновлениями. Ускорение процесса обновления. Время регламентных работ по обновлению всех площадок (7 штук) в среднем составляет 3 часа — автоматизация обновления + автотесты + убедиться глазами (т. е. фактически сверхурочная работа сведена к минимуму). Упорядочивание хранения информации обо всех окружениях, гарантия её актуальности и своевременность актуализации. Внедрение ночного автодеплоя и автотестирования — увеличение прозрачности состояния продукта. Повышение качества продукта. Практически отсутствует необходимость выпускать Hot fix-ы. Сократились затраты на выпуск релизов».
Что получили
- Оперативная информация по качеству собранного билда, визуальное представление конвейера поставки.
- Всегда наличие сборки в стандартном хранилище дистрибутивов.
- Возможность оперативно видеть на стенде текущие изменения.
- Возможность программировать инфраструктуру (infrastructure as a code) во всём нашем разнообразии виртуализации.
- Возможность быстро развернуть нужную инфраструктуру и прикладную систему нужной версии on demand.
- Типовые роли Ansible для конфигурирования типовых проектов.
Пришлось приостанавливать работы над некоторыми проектными задачами, чтобы наладить инфраструктуру. Чем раньше будет внедрен devops, тем меньше затрат времени. А иначе приходится внедрять в периоды низкой активности в проекте, а когда они бывают?
Продолжаем мягко доносить внутри компании и вокруг о необходимости автоматизации. Вежливо. Аккуратно.
Ссылки:
- Забавный велосипед нашего опса за год до начала централизации всего этого дела
- Вот результаты проекта в атомной энергетике, где мы использовали этот стек
- Про наши центры разработки по всей стране (кстати, с тех пор к ним добавились ещё центры в Воронеже и Челябинске).
- Моя почта — sstrelkov@croc.ru.
Комментарии (11)


lilo_panic
23.12.2017 16:15Для Continuous Delivery есть еще Drone. Вы его рассматривали с каких-нибудь сторон? Спасибо.

SStrelkov Автор
25.12.2017 13:57+1Первый релиз Drone вышел 26 июня, а мы проводили исследование и выбор инструментов в начале года. Один из ключевых недостатков – отсутствие интеграции с LDAP для управления пользователями. Ну и на первый взгляд решение еще достаточно сырое, что можно сказать, хотя бы по главной странице сайта:

Wer
25.12.2017 11:48А девопс — это только автоматизация, разве? Ну то есть тут написали про инструменты, причины выбора, а про то как это всё работает или должно работать с организационной точки зрения — нет. И работает это прямо в одном конвейре с админами ваших клиентов? Одними и теми же инструментами удаётся пользоваться и вашим разработчикам и админам заказчиков? Если да, то огромные шаблоны виртуалок как передаёте?
SStrelkov Автор
25.12.2017 16:24В посте акцент был намеренно смещен на инструменты DevOps, это верно подмечено.
По поводу организации, как говорится «it depends», есть разные ситуации (у нас довольно много проектов и заказчиков):
1. Заказчик предоставил доступ в инфраструктуру и широкие полномочия. В этом случае конвейер поставки единый, мы централизованно управляем развертыванием в тесте, пред-проде, проде и т.п на стороне заказчика. Теми же инструментами, что и у себя.
2. Доступ ограничен, заказчик хочет контролировать развертывание сам. У заказчика настраивается свой конвейер поставки. В зависимости от уровня зрелости конвейер может начинаться как с хранилища предоставленных дистрибутивов так и с хранилища исходников плюс бинарный репозиторий. Инструментарий DevOps в этом случае установлен на стороне заказчика. Инструменты могут отличаться от наших, особенно если у заказчика уже что-то раньше использовалось в других проектах.
Шаблоны виртуальных машин мы стараемся не передавать, это противоречит принципу infrastructure as a code.
alex005
25.12.2017 13:51Уверен, что для заказчика такой проект будет стоить больше $100.000. При этом он получает набор разнородного и весьма сложного софта с кучей костылей в интеграции, завязанный к тому же на API одного облачного провайдера.
Нормальный ИТ-директор покупает в коробке Atlassian-стек Bitbucket+JIRA+Confluence+Bamboo+Hipchat) за $100.000, нанимает несколько Devopp-eров и живет спокойно.SStrelkov Автор
26.12.2017 11:30Можно с нуля купить монолитную коробку с готовым функционалом, но в большинстве случаев у заказчиков уже частично есть инструменты практик CI/CD с соответствующими капитальными вложениями. Нам требовалась универсальность и совместимость с различными уже работающими в инфраструктуре CI (Jenkins и TeamCity), поэтому наше решение строилось по модульному принципу, подбирая для каждого модуля наиболее оптимальное решение.
Ну и мы ориентировались на open source решения, не все готовы потратить $100.000alex005
26.12.2017 13:24Задумка понятная, собрать свое из OpenSource, а потом продавать, тем кто не может это сделать сам, как готовое решение. В этом наверное и весь смысл поста, а хотелось бы видеть howto.
У нас больше 350 своих разработчиков ПО> 100.000$ я написал из расчета этого количества, реально если штат разработчиков 10-15 человек, то будет гораздо скромней. 100.000$ это не такая большая цифра (стоимость автомобиля представительского класса), если сравнивать с ФОТ тех же 350 разработчиков.
Пришлось приостанавливать работы над некоторыми проектными задачами, чтобы наладить инфраструктуру. > Вот это, в общем-то, и определяет сложность подобного проекта на Open Source. Согласен, что имеющаяся инфраструктура может тянуть назад, но на это не нужно ориентироваться. Иногда проще все сломать и сделать гомогенную среду разработки, тестирования и доставки приложений, чем тратить ресурсы на интеграцию не интегрируемого. Монолитный стек внедряется устанавливается за один день (даже в режиме кластеризации), еще неделя нужна чтобы наладить процесс, а остальное зависит от мотивации. При этом имеется поддержка множества плагинов, если нужно расширить функционал.
Pentoxide
О, прям админ-порн. Круто получилось! Моя хотеть.
Про автоматизацию WAS можно поподробнее?
SStrelkov Автор
Вместе c WASовской утилитой wsadmin использовали питоновскую библиотеку wsadminlib.py (которую пришлось чуть дописать) для реализации функций:
— создания и конфигурации transport chain,
— создания и конфигурации виртуального хоста,
— настройки параметров аутентификации (ИБ) и создания пользователей.