

Основанный в 2006 году BlaBlaCar считается крупнейшим в мире онлайн-сервисом поиска автомобильных попутчиков (ridesharing). Появившись во Франции, сервис прошёл активную экспансию в Европе, с 2014 года стал доступен в России и Украине, а позже добрался до стран Латинской Америки и Азии. Рост популярности онлайн-сервисов неизбежно связан с развитием стоящей за ними ИТ-инфраструктуры, и, как легко догадаться из названия статьи, сегодняшние потребности BlaBlaCar реализуются благодаря Kubernetes. К чему же пришли ИТ-инженеры компании?
Предыстория
В феврале 2016 года в блоге BlaBlaCar опубликовали заметку с рассказом о своём пути к контейнерам. Вся инфраструктура компании изначально строилась на своих серверах (bare metal), которые со временем (по мере роста вычислительных ресурсов) были сведены к нескольким типовым конфигурациям.
Для управления всеми программными службами на этих серверах долгое время использовался Chef с налаженным рабочим процессом, включающим в себя code review, тестирование и т.п. Для изоляции сервисов, не являющихся особенно требовательными к производительности (для нужд тестирования, pre-production и других), — кластер на основе VMware. Проблемы с ним описывались как сложность автоматизации, недостаточная производительность (по сравнению с bare metal) и высокая стоимость (когда речь идёт о большом количестве узлов). Тогда-то в BlaBlaCar и решили, не рассматривая другие «классические» варианты виртуализации, сразу перейти на контейнеры. В качестве дополнительного фактора в пользу контейнеров приводится возможность быстрого выделения ресурсов.
2015—2016: переход на контейнеры
В качестве контейнерного решения в BlaBlaCar выбрали… нет, не Docker, а rkt. Причиной тому стало «осознание существовавших в то время ограничений продукта, которые были очень важны для использования в production». И так уж совпало, что во время их экспериментов с контейнерами проект CoreOS анонсировал свою разработку — исполняемую среду для контейнеров rkt (известную тогда как Rocket).
Незадолго до этого инженеры BlaBlaCar успели полюбить операционную систему CoreOS (впоследствии именно на ней и остановились в качестве основной для контейнерной инфраструктуры), поэтому решили попробовать новый продукт того же проекта. И результат им понравился: «Мы были удивлены стабильности rkt даже в самых ранних её версиях, а все важные нужные нам функции были оперативно добавлены командой CoreOS».
Примечание: BlaBlaCar и на сегодняшний день остаётся в числе не таких уж многочисленных именитых пользователей rkt в production. Их официальный список можно найти на сайте CoreOS.
Продолжая использовать Chef уже для контейнеров, инженеры компании столкнулись с рядом неудобств, которые можно обобщить как излишние сложности там, где их быть не должно (например, не было простого способа кастомизации конфига при старте контейнера, когда необходимо сменить идентификатор узла в кластере). Начались поиски нового решения, требования к которому были сформулированы так:
- быстрая сборка;
- простота понимания для новых сотрудников;
- минимально возможная репликация кода;
- шаблоны, применяющиеся при запуске контейнера;
- хорошая интеграция с rkt.
Найти подходящий инструмент не удалось, поэтому авторы создали свой — dgr. Изначально он был написан на Bash, но затем авторы переписали на Go. В GitHub продукт называется «консольной утилитой, созданной для сборки и конфигурации во время запуска App Containers Images (ACI) и App Container Pods (POD), основываясь на концепте соглашения по конфигурации (convention over configuration)».
Общая схема работы dgr представляется следующим образом:

А непосредственное использование утилиты демонстрируется так:

Для оркестровки требовалось самое простое решение (не было времени на эксперименты с большими системами), поэтому выбор пал на стандартный инструмент всё того же CoreOS — fleet. В помощь к нему, для автоматизированного создания всех systemd units (на основе имеющегося в файловой системе описания окружений и сервисов в них), была разработана утилита GGN (green-garden).
Итог этапа в BlaBlaCar — переход от идеи использования контейнеров до запуска в них более 90 % production-сервисов за 7 месяцев. Большое желание продолжать использовать Chef — надёжный инструмент, в работу с которым инженеры вложили много времени, — пришлось скорректировать с пониманием, что «классические инструменты управления конфигурациями не подходят для сборки контейнеров и управления ими».
2016—2017: Актуальная инфраструктура и переход на Kubernetes
Обновлённые сведения об инфраструктуре компании появились совсем недавно — в конце прошлого месяца — в публикации «The Expendables?—?Backends High Availability at BlaBlaCar» от инженера BlaBlaCar. За минувшие почти 2 года в компании пришли к концепции «расходников» (expendables) в инфраструктуре, которая схожа с известной историей про скот и домашних животных (cattle vs. pets).
Общая суть сводится к тому, что каждый компонент инфраструктуры должен быть готов к рестарту в любой момент времени и не влиять при этом на работу приложений. Очевидно, что особая сложность при реализации такого подхода появляется у администраторов СУБД, так что вдвойне примечательно, что об опыте BlaBlaCar рассказывает соответствующий специалист — Maxime Fouilleul, занимающий позицию Database Engineer.
Итак, актуальная инфраструктура компании имеет следующий вид:

Все ACIs (Application Container Images) и PODs создаются и собираются с помощью уже упомянутой разработки компании — dgr. После сборки в системе непрерывной интеграции PODs попадают в центральный реестр и готовы к использованию. Для их запуска на серверах применяется специальный стек, названный Distributed Units System и основанный на fleet и etcd. Его предназначение — распределённый запуск обычных systemd units по всему дата-центру, как будто это происходит на локальной машине. Для указания целевого хоста в unit-файл добавляются специальные метаданные — например, это актуально для MySQL, инсталляция которой привязывается к конкретному серверу.
Примечание: СУБД в BlaBlaCar начиналась с асинхронной репликации в MySQL, однако — из-за сложностей восстановления при падении мастера (т.к. это единая точка отказа) и необходимости отслеживать задержку репликации в приложениях (иначе неконсистентные данные) — со временем перешли на синхронную репликацию на базе кластера Galera. На сегодняшний день в production используют MariaDB и Galera: такой вариант позволяет рассматривать все узлы с MySQL одинаковыми «расходниками», что актуально для экосистемы, построенной на контейнерах.
Наконец, для генерации и деплоя systemd units в компании используют другую (уже упомянутую) свою разработку — ggn. А сейчас инженеры работают над стандартизацией оркестровки своих PODs на базе Kubernetes.
Service discovery
Задачу обнаружения сервисов (service discovery) в BlaBlaCar по праву считают одним из ключей для построения отказоустойчивой и масштабируемой инфраструктуры. Чтобы добиться этого, в компании переписали на язык Go специализированный фреймворк от Airbnb — SmartStack. В его основе — два компонента:
- go-nerve — утилита для отслеживания состояния сервисов, запускающая различные проверки (по протоколам ?TCP и HTTP, системными вызовами, исполнением SQL-команд и т.п.) и сообщающая об их результатах в соответствующие системы; запускается на каждом экземпляре сервиса (более 2000 в BlaBlaCar) и передаёт состояние в хранилище Apache ZooKeeper;
- go-synapse — механизм непосредственного обнаружения сервисов, наблюдающий за сервисами (отслеживает значения ключей, хранимых в ZooKeeper) и обновляющий их состояние в маршрутизаторе (на базе HAProxy).
Обе утилиты являются не просто переписанными вариантами одноимённых разработок Airbnb (Nerve, Synapse), но и расширяют их возможности в соответствии с потребностями BlaBlaCar (подробнее см. в их GitHub-репозиториях по ссылкам выше). Общий алгоритм взаимодействия компонентов service discovery изображен на этой схеме:

Пример настройки (конфигов) service discovery для MySQL спрятан здесь для энтузиастов.
Nerve для MySQL (
Результат в ZooKeeper:
И настройки в Synapse (
env/prod-dc1/services/mysql-main/attributes/nerve.yml):override:
nerve:
services:
- name: "main-read"
port: 3306
reporters:
- {type: zookeeper, path: /services/mysql/main_read}
checks:
- type: sql
driver: mysql
datasource: "local_mon:local_mon@tcp(127.0.0.1:3306)/"
- name: "main-write"
port: 3306
reporters:
- {type: zookeeper, path: /services/mysql/main_write}
checks:
- type: sql
driver: mysql
datasource: "local_mon:local_mon@tcp(127.0.0.1:3306)/"
haproxyServerOptions: "backup"Результат в ZooKeeper:
# zookeepercli -c lsr /services/mysql/main_read
mysql-main_read1_192.168.1.2_ba0f1f8b3
mysql-main_read2_192.168.1.3_734d63da
mysql-main_read3_192.168.1.4_dde45787
# zookeepercli -c get /services/mysql/mysql-main_read1_192.168.1.2_ba0f1f8b3
{
"available":true,
"host":"192.168.1.2",
"port":3306,
"name":"mysql-main1",
"weight":255,
"labels":{
"host":"r10-srv4"
}
}
# zookeepercli -c get /services/mysql/mysql-main_write1_192.168.1.2_ba0f1f8b3
{
"available":true,
"host":"192.168.1.2",
"port":3306,
"name":"mysql-main1",
"haproxy_server_options":"backup",
"weight":255,
"labels":{
"host":"r10-srv4"
}
}И настройки в Synapse (
env/prod-dc1/services/tripsearch/attributes/synapse.yml):override:
synapse:
services:
- name: mysql-main_read
path: /services/mysql/main_read
port: 3307
serverCorrelation:
type: excludeServer
otherServiceName: mysql-main_write
scope: first
- name: mysql-main_write
path: /services/mysql/main_write
port: 3308
serverSort: dateKubernetes в BlaBlaCar. Enjoliver
Согласно интервью от апреля 2017 года, внедрение Kubernetes в BlaBlaCar происходило постепенно, и первые компоненты в production запустили «3 месяца назад». Однако, несмотря на неоднократные упоминания Kubernetes в инфраструктуре, подробностей о его устройстве в имеющихся статьях не так много. Пролить свет на этот вопрос помогает ещё один проект BlaBlaCar на GitHub — Enjoliver.
Enjoliver (от франц. слова «приукрасить») описывается как инструмент для «деплоя и поддержки годного к употреблению кластера Kubernetes». Свою публичную историю он ведёт с октября 2016 года, а основной его исходный код (включая его Engine и API) написан на Python. В качестве исполняемой среды для контейнеров в Enjoliver применяется, как все уже догадались, rkt от CoreOS, а также в кластере задействованы CoreOS Container Linux, Fleet, CNI и Vault. Общая архитектура представляется следующим образом:
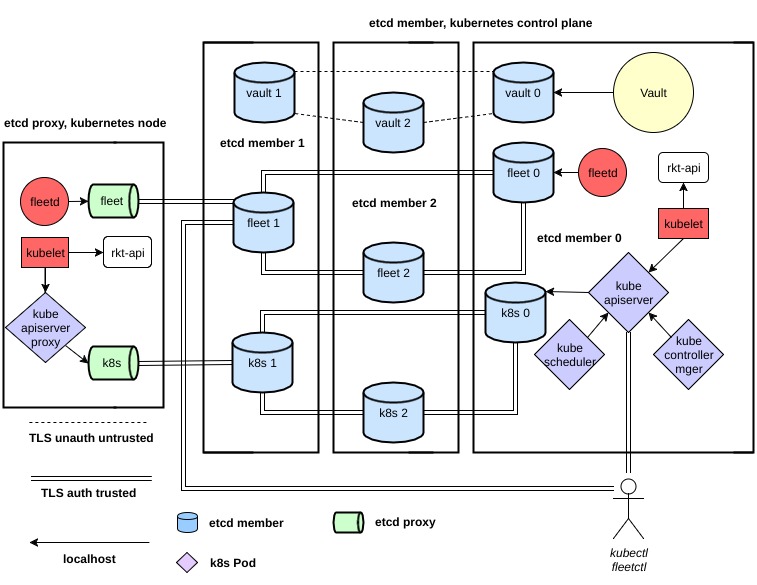
Авторы выделяют четыре главных области работы/развития Enjoliver:
- конфигурация ролей кластера Kubernetes (control plane и узлы);
- топология обнаружения сервисов, планирование ролей в Kubernetes и поддержка жизненного цикла кластера — за это отвечает Enjoliver Engine;
- e2e-тестирование Enjoliver;
- применение Kubernetes для целей разработки, включающее в себя готовые примеры использования Helm / Tiller, Heapster, Kubernetes Dashboard, Prometheus, Vault UI, CronJobs для бэкапов etcd.
Описание Enjoliver потянет на отдельный материал… Начать знакомство с ним можно с достаточно подробного README, включающего в себя краткую инструкцию для тестового развёртывания (см. главу «Development — Local KVM»), авторы которой, впрочем, обещают вскоре её улучшить.
Наконец, дополнительные сведения о применении Kubernetes в BlaBlaCar стали доступны из case study, написанного со слов инженера по инфраструктуре компании (Simon Lallemand) и опубликованного на сайте Kubernetes. В частности, там сообщается о следующем:
- Инженеры BlaBlaCar стремились предоставить разработчикам большую автономность в развёртывании сервисов (с использованием контейнеров rkt), и Kubernetes стал ответом на их запросы летом 2016 года, когда в системе начала появляться поддержка этой исполняемой среды. Первый запуск K8s в production состоялся к концу 2016 года.
- Обслуживанием всей инфраструктуры (ею пользуются около 100 разработчиков) занимается команда из 25 человек.
- На сегодняшний день у BlaBlaCar около 3000 подов, 1200 из которых работают на Kubernetes.
- Для мониторинга используется Prometheus.
Другие статьи из цикла
- «Истории успеха Kubernetes в production. Часть 1: 4200 подов и TessMaster у eBay».
- «Истории успеха Kubernetes в production. Часть 2: Concur и SAP».
- «Истории успеха Kubernetes в production. Часть 3: GitHub».
- «Истории успеха Kubernetes в production. Часть 4: SoundCloud (авторы Prometheus)».
- «Истории успеха Kubernetes в production. Часть 5: цифровой банк Monzo».
Комментарии (3)

JuriM
09.01.2018 21:19«со временем перешли на синхронную репликацию на базе кластера Galera»
Кластер не тормозит ли под нагрузкой?
helltone
интересный кейс, можно прояснить моменты- от Chef ушли к самописному dgr, я верно понял? а что из готовых систем управлением конфигурацией рассматривалось как альтернатива chef?
Distributed Units System на картинке выглядит как Distributed init system
shurup Автор
Что рассматривалось из готовых CM-систем, умалчивается, но основной посыл в том, что «классические инструменты управления конфигурациями не подходят для сборки контейнеров и управления ими». Т.е. они в принципе не особо подходили под специализированные задачи (в обслуживании уже контейнеров), и такой выбор можно понять…
Вот ещё цитата по теме (из упомянутого в конце статьи case study):
P.S. В сегодняшних вакансиях BlaBlaCar присутствует такое требование, как «Good knowledge of configuration management», но без указания каких-либо конкретных продуктов. Взял эти данные из их описания Senior Site Reliability Engineer.