
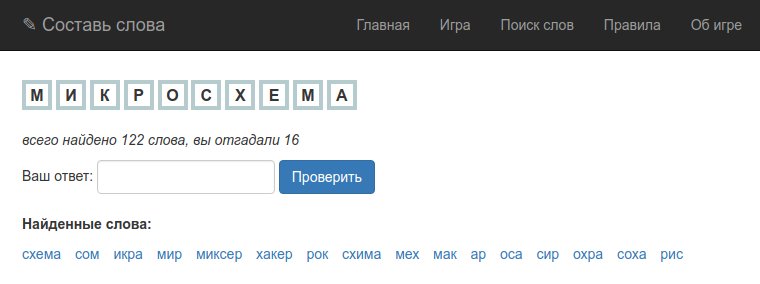
Хочу поделиться своим опытом работы над веб-проектом: реализацией игры «Составь слова». Игра представляет собой известную головоломку, в которой нужно составлять разные слова из одного длинного слова.
Суть статьи — в том, как именно и что конкретно пришлось сделать, чтобы довести всю задумку от идеи до реализации.
Введение
Время от времени я играл в «бумажный» вариант этой игры: мы загадывали длинное слово (например: «Трицераптос» или «Спасо-Преображенский») и за 7-10 минут старались составить как можно больше слов из имеющихся букв. Затем — по очереди называли свои слова, повторяющиеся у соперников вычеркивали. У кого последнего оставались слова — тот и выиграл.
В это же время я искал варианты для проекта, на котором хотел комплексно потренироваться-поучиться веб-разработке.
Требования к проекту были такими:
- не сложный, но и не легкий (по применяемым навыкам и технологиям);
- со сроком реализации примерно в месяц (± две недели, чтобы не затянулся надолго, но и не успел надоесть)
- с применением современных технологий и знаний, которые мне не известны (профессиональное развитие)
- интересный по сути
- общественно-полезный
При всей кажущейся простоте, придумать такую идею сходу у меня долго не получалось. Я обдумывал различные варианты, откладывал, прикидывал — и наконец идея полностью «созрела», обрела четкость и конкретные рамки. Начался этап активных действий, раздумывания остались позади.
План работ, задумки, идеи, архитектура
Общая идея выглядела следующим образом: система будет состоять из бекэнда и фронтэнда (одного или нескольких). На бекэнд возлагается основная нагрузка по расчетам, реализации логики и математики. В виде входных данных на него приходит длинное слово (для разгадывания), результат работы — данные об возможных существующих в русском языке вариантах комбинаций слов. Данные отдаются в формате JSON, бекэнд работает в виде REST-сервиса.
Фронтэнд обращается к веб-сервису с клиентским запросом, получает ответ (набор возможных комбинаций слов) и далее реализует то или иное игровое взаимодействие с пользователем.
На данный момент реализованы два метода АПИ на бекэнде:
http://api.combination.cf/web/words/портал
http://api.combination.cf/web/description/механизмПервый метод отдает возможные комбинации слов, второй — предназначен для толкования значения конкретного слова.
1. Бекэнд
1.1. Словарь, база слов
Чтобы какие-то слова пользователю выдавать, надо их сначала знать и где-то хранить. Изначально собирался парсить какой-то большой онлайн-словарь или базу знаний (БСЭ, Википедия и т. п.). Но, поискав в Сети, нашел уже собранные и готовые толковые словари в виде отдельных файлов (в текстовом формате). Парсить их, конечно же было намного проще, нежели выкачивать в несколько потоков и разбирать десятки тысяч страниц с сырыми данными. Не говоря уже о том, что список страниц для парсинга так же надо было подготовить.
Базой для игрового словаря послужили следующие источники:
- Ожегов С. И. Словарь русского языка. Ок. 65 000 слов / 16-е изд., — М.: 1984.
- Ефремова Т. Ф. Толковый словарь. — М.: Рус. яз., 1996.
Дабы не засорять игру различными малоупотребительными и редкими словами, отбрасывались некоторые местные, устаревшие слова, прилагательные, множественные формы. Конечно, такая чистка не является совершенной, более корректный результат можно получить привлекая к данной работе человека (желательно филолога).
Но, хорошо хоть в базе данных не оказалось имен, фамилий, названий городов, стран и т. п. (которые есть в энциклопедических словарях, но отсутствуют в толковых).
Если удастся использовать все буквы исходного слова — то получится анаграмма (Анаграмма — литературный приём, состоящий в перестановке букв или звуков определённого слова, что в результате даёт другое слово или словосочетание).
Пример: австралопитек — ватерполистка.
1.2. Размещения без повторений
Итак, у нас есть база слов (базовый словарь). Алгоритм поиска слов сводится к тому, чтобы получить все возможные варианты сочетаний букв и проверить их на наличии в словаре.
Из длинного выражения можно составлять короткие слова различной длины. Значит, нам нужна комбинаторика, раздел «Размещения без повторений». Будем искать слова длиной от 2-х до («длина слова» — 1) символов.
Рассчитаем, сколько вариантов нам надо будет перебрать при различной длине исходного слова. Применим следующую формулу:
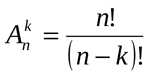
Сочетания, размещения, перестановки.
В комбинаторике размещением (из n по k) называется упорядоченный набор из k различных элементов из некоторого множества различных n элементов.
Элементами множества могут быть числа, буквы и вообще любые объекты. Главное, чтобы эти элементы были различными. Т. к. любому объекту можно сопоставить число, то обычно используют конечное множество целых чисел, например, {1; 2; 3; 4; 5}. Хотя множества из букв также можно часто встретить в литературе.
Пример: некоторые размещения элементов множества {А, Б, В, Г, Д}:
по два элемента: {А, Б}, {Б, Д}, {Г, А}
по три элемента: {Д, А, Б}, {А, Б, Д}, {Г, Б, В}
по четыре элемента: {Д, А, Б, Г}, {А, Б, Д, В}
В отличие от сочетаний, размещения учитывают порядок следования предметов. Так, например наборы {А, Б, В} и {В, Б, А} являются различными, хотя и состоят из одних и тех же элементов {А, Б, В} (то есть совпадают как сочетания).
Число размещений без повторений из десяти элементов по K:
| К |
Количество размещений |
| 1 | 10 |
| 2 | 90 |
| 3 | 720 |
| 4 | 5040 |
| 5 | 30240 |
| 6 | 151200 |
| 7 | 604800 |
| 8 | 1814400 |
| 9 | 3628800 |
| Всего: | 6235300 |
Число вариантов для проверки слова длиной N символов:
(суммируем все варианты размещений для слова данной длины)
| N | Количество вариантов для проверки |
| 2 | 2 |
| 3 | 9 |
| 4 | 40 |
| 5 | 205 |
| 6 | 1236 |
| 7 | 8659 |
| 8 | 69280 |
| 9 | 623529 |
| 10 | 6235300 |
| 11 | 68588311 |
| 12 | 823059744 |
| 15 | 2246953104075 |
| 20 | 4180411311071440000 |
| 25 | 2.6652630354867E+25 |
1.3. Бекэнд, YII2
Бекэнд реализован на PHP (YII2), в качестве БД выбран MySQL, кеширование — Memcached. Здесь все просто: создаем отдельный модуль для API, пишем необходимые выборки из базы. Данные отдаем в формате JSON.
1.4. Оптимизация
А вот теперь начинается самое интересное. Требовалось оптимизировать потребление ресурсов приложением и обеспечить быструю работу скриптов. Будем отслеживать использование памяти, процессорного времени, и общее время выполнения скриптов.
Изначально оптимизировал работу с памятью. При передаче слова длиной в восемь символов скрипт падал с ошибкой:
PHP Fatal error: Out of memory (allocated 128545216) (tried to allocate 77824 bytes) in /home/xxxxx/public_html
Этот вопрос удалось решить с использованием генераторов в PHP-коде. Функция стала отдавать данные частями, а не накапливать весь результат в себе. Так же помогло использование функции mysql_free_result($result) для высвобождения всей памяти, занимаемой результатом запроса к БД. Использование памяти теперь не превышало 12-14 Мб.
Использование процессора. Изначально нагрузка на ЦП составляла 100% во все время работы скрипта. Путем оптимизации кода и разбиения запросов на большее количество мелких (вместо небольшого количества больших) запросов удалось снизить нагрузку до 60-80%.
Оптимизация времени работы скрипта была достигнута путем использования
Memcached для хранения списка всех слов из словаря. Таким образом удалось убрать нагрузку на MySQL и ускорить время получения результата. Как альтернативу я перепроверил так же и файловый кеш FileCache, но здесь результаты были хуже, нежели Memcached.
Результаты оптимизации
На локальном сервере (четырехядерный процессор) время перебора всех комбинаций для слова из 10-ти букв составляет около 22 секунд. При этом два ядра загружены на 60% — 80% постоянно. Eщё 10-11 секунд требуется на проверку всех этих комбинаций в словаре (при использовании Memcached).
Итого (для слова из 10 символов): 22 сек. (генерация вариантов) + 10 секунд (проверка слов) = 32 секунды (общее время работы).
Рост времени линейный: 9 символьное слово проверяется примерно за 3 секунды, 10 символов — за 32 секунды, 11 символов — 350 секунд.
Т.е. слова из 11-ти букв уже недоступны (за разумное время) для перебора вариантов (для данного алгоритма, при данном железе); 10 символов — более-менее терпимо, предел; 9 и менее — достаточно быстро, незаметно для пользователя.
2. Фронтэнд
Я решил написать два фронтенда (исходя из поставленных целей). Один на PHP (YII2) — основной рабочий вариант игры «Угадай слова» с полным пользовательским функционалом; второй на React JS — то же самое клиентское приложение, но с сокращенным функционалом (учебный проект для изучения JS).
Реализовывать функционал игры на PHP (YII2) + верстка Bootstrap было просто, быстро и приятно. Программирование в удовольствие, творческое занятие: создавай (и придумывай, дорабатывай на ходу) интерфейсы взаимодействия с пользователем, диалоговые окна, элементы меню, кнопки; наполняй страницы контентом, выводи информационные сообщения; делай для всего этого дизайн; продумывай редиректы и т. п.
А вот с React JS у меня было все не так просто. Вылезли пробелы в знаниях, пришлось заново повторять и проходить основы JavaScript (помимо изучения особенностей самой библиотеки React JS). Иногда приходилось по несколько часов искать как сделать простейшее действие: скачать файл, вывести блок текста. Но так и планировалось изначально: знаниями HTML + Jquery сейчас уже не отделаешься. В результате получился собранный билд статического сайта для выгрузки на хостинг.
Пользователю игры доступны следующие варианты взаимодействия:
- Игра в слова — загадывается большое длинное слово, можно придумывать варианты и проверять их. Найденные слова сохраняются, ведется подсчет статистики, выдаются информационные сообщения (слово найдено/не найдено, ошибка, комбинация уже отгадана и т. п.). Игру можно отложить и продолжить в другое время. Игру можно завершить или начать заново.
- Поиск слов — просто показываются все возможные комбинации слов, которые можно составить из исходных букв. Некий вариант «подсказки» для игры или отдельный сервис.
- Значение слова — показывается толкование отгаданного или сгенерированного слова. Онлайн вариант электронного словаря.
3. Хостинг
Ничего особо нового здесь не напишу, надо подбирать хостинг под конкретный проект, исходя из требований и возможностей. Из того что удивило — почти у всех компаний качественная техподдержка: отвечают быстро и по сути, помогают решить возникшие затруднения. На собственном опыте убедился, что работа сисадмина и девопса нужна и важна.
Возможные доработки и идеи
Можно двинуться в двух направлениях: оптимизировать бекэнд (сделать работу АПИ более быстрой) и фронтэнд (расширять и «шлифовать» интерфейсы работы с пользователями). Оба варианта являются перспективными.
Бекэнд — наверное, здесь возможностей PHP для быстрой обработки большого объема цифровых данных будет недостаточно. Возможно подойдет написание некого отдельного быстрого модуля или скрипта на ином языке программирования, который бы быстро делал все расчеты. Может, что-то из результатов можно закешировать!? Для быстрой переборки словаря скорее всего стоит посмотреть в сторону NoSQL баз данных. Так же уместным видится увеличение сервисов (возможностей) системы.
По пользовательскому интерфейсу — здесь уместным будет привлечение специалистов по игровому дизайну в качестве консультантов (или сесть самому и пару вечеров подумать, что можно быстро и просто реализовать, все мы играли за свою жизнь в сотни разных компьютерных игр): продумывание игровых интерфейсов, расширение сервисов, добавление регистрации пользователя, сбор статистики, таблицы рекордов, сохраненные игры и т. п.
Не лишним будет, наверное, покрытие кода тестами (приемочными на фронтэнде и юнит-тестами на бекенде). Чтобы не тестировать все вручную снова и снова при обновлениях и расширении функционала.
Заключение
Вообще лингвистика и филология, оказывается, это очень интересно само по себе. Узнал много нового об русском языке в процессе работы над проектом.
Приведу ссылки на исходные коды в репозиториях и ссылки на рабочий сайт (хостинг — базовый VPS, возможно «падение» сайта под «Хабраэффектом»).
Множество багов и неточностей удалось найти и исправить в процессе разработки. Но, некоторые, наверняка остались. Прошу не судить строго, если вы с ними столкнетесь.
Сайт с игрой
Репозиторий с бекэндом (АПИ) и фронтэндом (PHP)
Репозиторий с фронтендом на React JS
Комментарии (26)

ShakhnoDV
30.01.2018 13:12С таким количеством возможных комбинаций легче просматривать все 65000 слов и проверять подходят ли они под введенное слово.

volmir Автор
30.01.2018 13:16Все равно, потребуется сравнить 65000 слов и 4.1804 E+18 вариантов.
Базу из 65000 слов можно полностью закешировать.
Задача разлагается на две подзадачи:
1) Сгенерировать 4.1804 E+18 комбинаций.
2) Проверить сгенерированные комбинации в словаре из 65000 слов.ShakhnoDV
30.01.2018 15:28Потребуется только сравнить 65000 слов и одно введенное слово. Нет необходимости генерировать все возможные варианты
doctorpepper608
30.01.2018 14:22некоторые слова некоректны и нужно отбрасывать. Например, при наборе api.combination.cf/web/words/%D0%90%D0%91%D0%92%D0%93%D0%94%D0%95%D0%96%D0%97%D0%98:
volmir Автор
30.01.2018 14:30Да, конечно. Когда наберется достаточная статистика и пропарсятся все доступные словари (например, сейчас в базе не хватает современных слов, вошедших в язык за последнее десятилетие) — можно будет «ручками» или автоматически пройтись по словам, откорректировать их.
JuniorNoobie
30.01.2018 14:57Думаю, что в сети уже должны быть словари, в которых у слова можно выбрать следующие параметры: имя нарицательное, существительное, именительный падеж, единственное число. Затем этот словарь загружаем в свою базу данных, ибо читать с файлика каждый раз слова… ну это так себе. Затем строим индексы по количеству букв. Затем пишем запрос и вуаля: готова выдача всех возможных комбинаций слов.
В интерфейсе я бы добавил для начала сортировку уже отгаданных слов по количеству букв и по алфавиту. Еще лучше (я так думаю) выводить слова в столбцах по количеству букв.volmir Автор
30.01.2018 15:00Спасибо за идеи.
Над пользовательским интерфейсом ещё работать и работать.
Ещё одна интересная фишка (увидел её в аналогичных сервисах): «получить подсказку».
Т.е. при нажатии на кнопку выводится в модальном окне толкование одного или нескольких неразгаданных слов.
volmir Автор
30.01.2018 15:05В Сети есть словари русского языка в текстовом формате:
www.speakrus.ru/dict
bi0w0rm
30.01.2018 16:00Сейчас после успешного или неуспешного набора слова фокус уходит из поля ввода. Чтобы начать вводить следующее слово, приходится либо табом фокус листать, либо мышь брать. А хочется: ввести слово — нажать Enter, ввести слово — нажать Enter и т.д. Было бы очень приятно, если бы фокус оставался в поле ввода.

IhorL
31.01.2018 09:03В дизайне UI заложена проблема изначально. Видимо из-за попытки попробовать React и получилось, что-то вроде (зато работает). Ушел от Jquery как писал в статье, но все равно добавил в проект. И даже имея Jquery, создал статические страницы с submit всей страницы саму на себя. За попытку молодец. Но… в погоне за React делаем откат лет на 10 назад.
Говорим об оптимизации и вместо чистого запроса нового слова, перегружаем каждый раз страницу на POST снова генерим ее клиенту. В итоге чтобы побороть неудобство фокуса, добавим костыль с установкой фокуса после отрисовки страницы. И так далее, с ростом UI, костыли будут только рости.
Напоминает попытку, перфоратором закручивать шурупы… да это возможно, но вроде и глупо.volmir Автор
31.01.2018 09:54На React JS написан отдельный сайт: js.combination.cf
Но там функционал обрезанный (по сравнению с полной версией api.combination.cf/web), есть ряд особенностей связанных с хостингом (локально работает — на хостинге «нет»).
Разрабатывать удобный, современный и функциональный UI — мне этому ещё учиться и учиться. Пока в приоритете бекэнд (60-70% усилий), на фронтенд — оставшиеся 30-40%.
volmir Автор
Пример запроса из 20-ти букв (на сайтах в сети, которые предоставляют похожие сервисы):
1) поискслов.рф/anagram/search?query=абвгдежзиклмнорпстуф
Найдено: 155 страниц слов (размещения с повторениями).
Время ответа сервера: менее одной секунды на страницу.
2) wordhelp.ru/comb/абвгдежзиклмнорпстуф
Найдено: 9736 слов.
Время ответа сервера: 4 секунды.
Вопрос: Как можно обработать 4,180,411,311,071,440,000 комбинаций за 1-4 секунды? И по всем этим словосочетаниям сделать поиск по словарю?
Конечно, вопросы сложные и нетривиальные, простых ответов не будет. Но, возможно, хотя бы получится узнать направления того куда «смотреть», что «копать»…
arandomic
Смотрите.
Как вам уже сказали и пару раз скажут, построить 4*10^18 комбинаций и искать их в наборе 65000 слов — контрпродуктивно.
Значит нужно как-то отсеивать нужные слова из 65000
Отсеивать — по какому признаку? По наличию нужных букв и отсутствию тех, которых в запросе нет.
Берем словарь и для каждого слова строим вектор из 33 чисел. каждое число — количество повторений соответствующей буквы.
Эти вектора можно сохранить в базу и построить по ним индексы.
И потом select woridId from vectors where 'A' <= 1, 'Б' <=1 итп
Это если «влоб» и не пытаться написать более эффективной реализации.
volmir Автор
Сама сложная задача (как это я вижу сейчас) — сгенерировать эти самые 4.1804 E+18 комбинаций (за разумное время и минимально возможными ресурсами процессора).
А как их проверить — можно будет потом уже придумать (алгоритм составить или закешировать).
А если на Си (или ином языке программирования, каком?) написать перебор комбинаций, быстрее будет работать? Насколько быстрее, нежели на PHP? Не сталкивался с такими задачами раньше, хочется посоветоваться.
arandomic
Вы неправильно разбили задачу на подзадачи.
Не нужно генерировать комбинации.
Вообще.
Никак.
Нам не важен порядок букв в словах.
Нам важны множества букв и именно множества букв мы будем сравнивать.
Словарь необходимо хранить в предобработанном виде. (см мой комментарий)
Введенное пользователем слово преобразуем в описание множества букв.
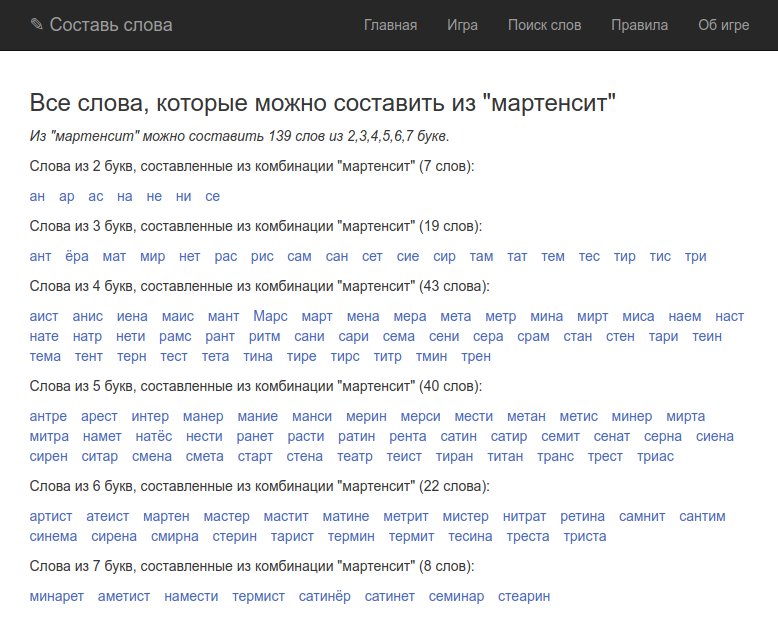
Вот пример ваш со словом «мартенсит»:
мартенсит = {аеимнрстт}
Весь наш словарь уже представлен в таком виде (в виде множества букв)
И нам не нужно искать среди слов сгенерированные слова — нам нужно найти все множества которые являются подмножеством множества {аеимнрстт}
Как хранить множества в памяти и как их сравнивать — вопрос реализации, да
volmir Автор
Это именно то, что я искал.
О таком направлении я не думал вообще.
Спасибо вам огромное за идею и участие!
Буду пробовать реализовать подобный алгоритм.
MisterX
У меня таким образом работает разгадывание анаграм. База sqllite ~ 220 тыс слов. Поиск занимает 0,01 — 0,2 секунды.
volmir Автор
Переделал систему по предложенной вами схеме (ищем слово в индексе из 65000 слов словаря). Теперь все летает!
Запрос из 20-ти символов выполняется с следующими результатами:
Память: 12.02 megabytes
Время: 0.500537 сек.
Сам запрос:
Т.е. все буквы, которых нет в слове включаем в запрос через отрицание, а в результате получаем множества, которые состоят из нужных нам букв.
Структура таблицы vector:
andreyvlv
Однажды делал такую же игру. Также начинал с генерации комбинаций. На 12-и или 13-и буквах программа искала слова около часа, что неприемлемо. Оказалось, что достаточно отсекать от словаря все неподходящие слова. Вот пример похожего поиска: bit.ly/2FuZT8G. Написан на C# (с PHP не сильно знаком), но в комментариях к коду постарался описать принцип работы.
volmir Автор
Спасибо, сейчас читаю код. В принципе, все понятно (алгоритм), осталось разобраться в деталях :)
volmir Автор
Сейчас алгоритм работает следующим образом:
1) Генерируются блоки комбинаций (размер блока: 50000-100000 слов) (66% времени на итерацию).
2) Этот блок проверяется на наличие в словаре (34% времени на итерацию).
Далее цикл повторяется…
Т.е. оптимизировать надо и первый шаг и второй.