
Пациент приходит к врачу и жалуется на боль в животе. «Срочно на операцию! — отвечает врач. — Сейчас мы вас разрежем, покопаемся и постараемся зашить как было».
Когда пользователи ругались на работу системы, называя программистов негодяями, мы поднимали журнал событий и смотрели, что пошло не так. А потом перешли на ELK. Теперь мы мониторим ошибки в моменте, не тормозя работу сервисов.
В этой статье мы расскажем, как адаптируем и применяем стек ELK на Java и .Net-проектах и находим ошибки в онлайн режиме без вскрытия или малоинвазивными методами. Да, мы разобрались и поняли, что не очень важно, Microsoft ли сделал это решение или Open Source — всё одинаково можно настроить под свои нужды.

О каких проектах речь?
Тяжело и тщательно: реалии Java
Наш продукт на Java — это федеральная система розничной продажи билетов. Она должна работать бесперебойно, зависания и приостановка работы недопустимы. А в случае сбоя нужно быстро и точно понять причину, ведь это потери живых денег клиента.
Тут ELK работает как онлайн-мониторинг и инструмент работы нашей службы поддержки. Мы логируем «сырые» данные, чтобы при обращении заказчика в техподдержку мы знали, какие данные обсуждаем, какой был ключ шифрования и т.д.
Ретроспективный анализ ошибок на .Net-проектах
.Net-проекты в основном представляют собой сервисы поддержки продаж и клиентов. Им пользуются более 20 тысяч человек. Тоже немало, но нагрузки не такие большие, как в Java.
Логируем ошибки и информацию, которая показывает динамику бизнес-операций. Например, сколько юзеров зарегистрировалось на сайте. И когда видим, что два дня не было регистраций, то сразу ясно, что там что-то случилось. Или наоборот — продали миллион билетов и отправили об этом письмо директору, порадовали человека.
Как работаем с ELK
Логирование: Serilog + ELK
На .Net-проектах мы также в основном используем Serilog, поскольку у него широкие возможности по выливанию данных. Здесь нет смысла использовать beats или Logstash, поскольку Serilog умеет логировать структурировано: такой-то юзер в такое-то время зашёл в систему. А ещё можно настроить значения нужным кускам информации: API, времени и т.п. И когда он начнет писать логи в Elastic, это ляжет не строкой, а свойством объекта, по которому можно искать. То есть мы минуем Filebeat и Logstash, исключая двойную работу.
Durable mode
Мы используем режим Serilog под названием Durable mode — он гарантирует доставку сообщений, даже если Elastic какое-то время лежит. Он действует примерно так же, как Filebeat плюс Logstash — сперва складывает всё в файл, потом пытается экстренно доставить до Elastic, если это не удается, то Serilog периодически пытается, пока Elastic не поднимется. Можно настроить, как часто он будет обращаться в Elastic.
Здесь можно прочитать инструкцию по настройке.
Контейнеры для логов
на Java-проектах пишем много логов, — до 5 Гб в день. Эти файлы бьем на куски по 5 Мб, чтобы они занимали меньше места и их стало легче хранить. ELK храним и поднимаем в Docker-контейнерах на наших компьютерах — получается виртуальная машина, просто более легкая, которую кто-то уже настроил до тебя.
На .NET проектах не такие большие логи, как на Java-проектах, поэтому там мы бьем файлы не по размеру, а по дням. А потом анализируем логи, выделяя типы ошибок.

Мониторинг Zabbix
У каждой записи есть Trace ID, а браузер меряет время старта и конца операции — мы логируем эти данные на сервере, а потом мониторим через Zabbix.
Kibana/ Grafana
Kibana используем для ежедневного мониторинга ошибок. В Kibana можно сделать поиск по логам. Мы используем эту функцию на проде и на тестовых серверах. У нас также есть Grafana — визуализация у неё лучше, на одном дашборде показаны все наши проекты. Здесь мы можем посмотреть все данные. Красным помечаются все ошибки — это повод залезть в Kibana и посмотреть детали. Мы видим, где ошибка, её место в коде, когда она возникла, условия окружения. У нас есть один ID, который связывает все системы воедино и может проследить полный путь ошибки.
Если ошибка неизвестная, начинаем разбираться более пристально. Например, недавно мы выложили на прод один бизнес-процесс. Тестирование со стороны заказчика прошло хорошо, но мы заглянули в логи и увидели, что там ошибка. Мы сразу поправили её, и никто ничего не заметил.
Например, на этом скриншоте видно количество регистраций на одном проекте:
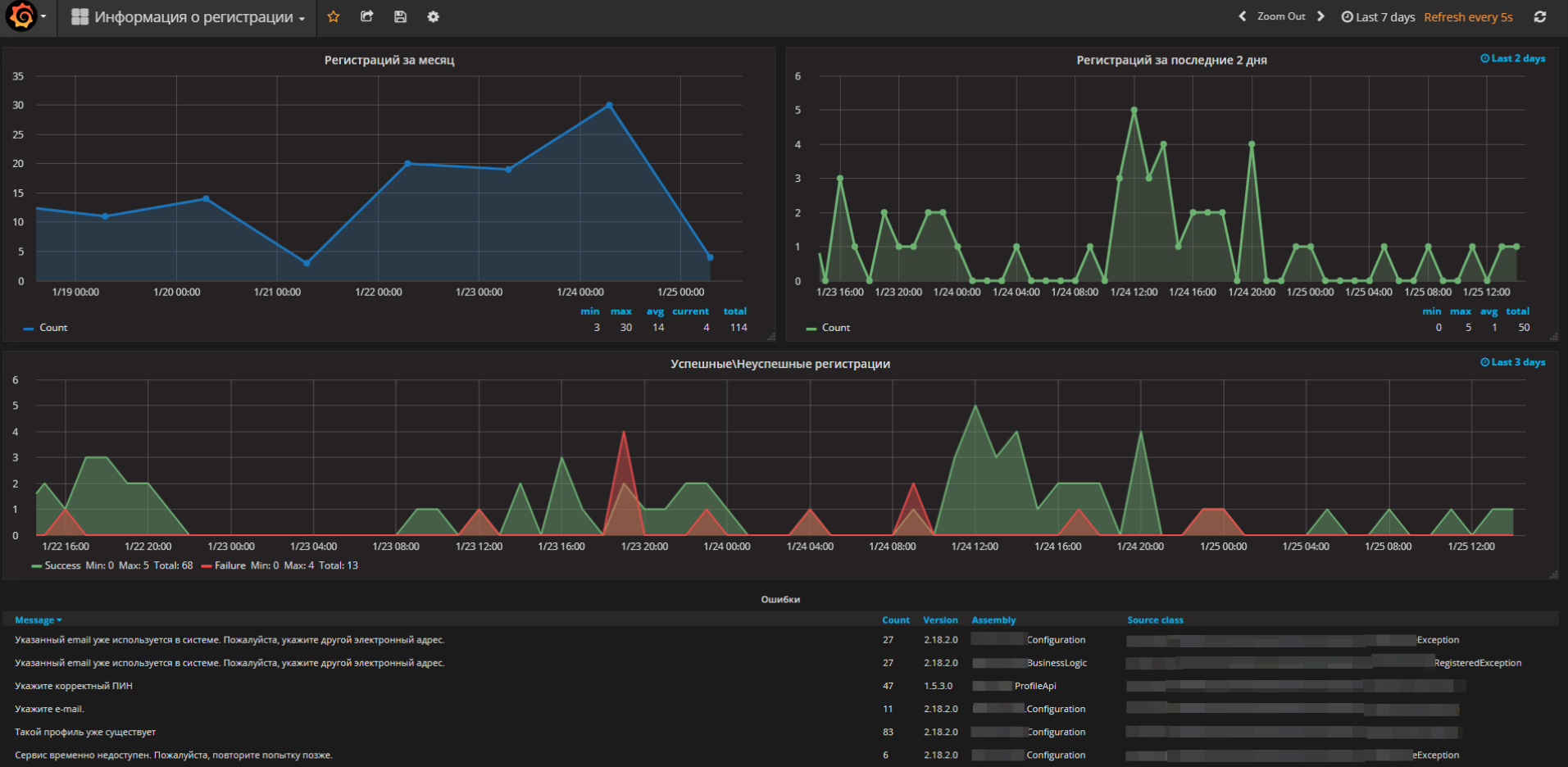
Анализ ошибок
Ежедневно мы получаем из ELK все ошибки, определяем среди них новые, классифицируем их, и заодно даём человеко-понятное название.
Наблюдаем за динамикой уже классифицированных ошибок, отлавливаем всплески и разбираемся в причинах. Инженер техподдержки заводит задачи на устранение причин. За сутки в логах нужно проанализировать тысячи и десятки тысяч строк, а на Java-проектах и того больше. Многие ошибки повторяются ежеминутно.
Начинали, как и многие с визуального просматривания всех логов. Но быстро поняли, что при наших объемах так жить нельзя. И настроили Excel-таблицу с макросами, которые умеют забирать из Kibana данные за сутки, выбирать из них ошибки и распределить их по существующим категориям.
В итоге Excel выдаёт отчет, где для каждой ошибки есть информация, сколько раз за сутки эта ошибка произошла. Отдельным списком мы получаем новые ошибки, и можем быстро проанализировать сначала их — есть там критичное, или нет.
В Kibana ходим смотреть детальную информацию по каждой новой ошибке.
Что позволяет делать файл:
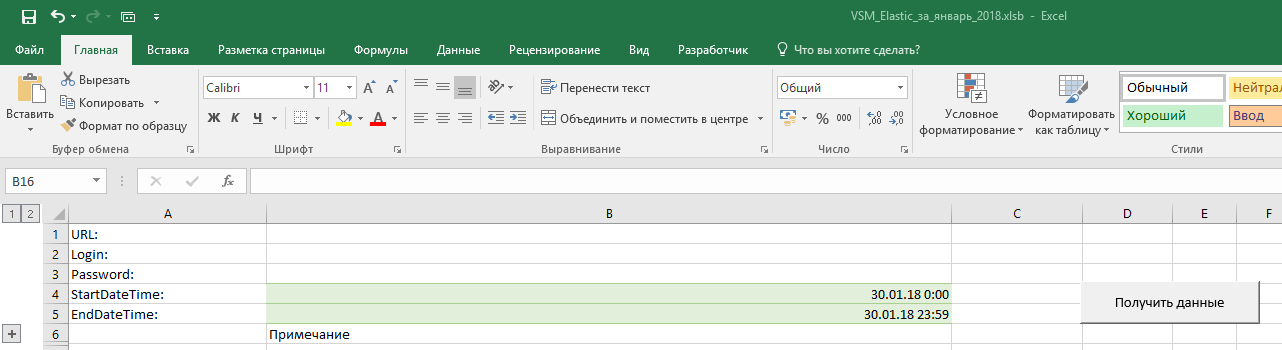
- Получить из Elasticsearch в одну таблицу нужные сообщения по нужным проектам за нужный период. Для этого указываем исходные данные в настройках.
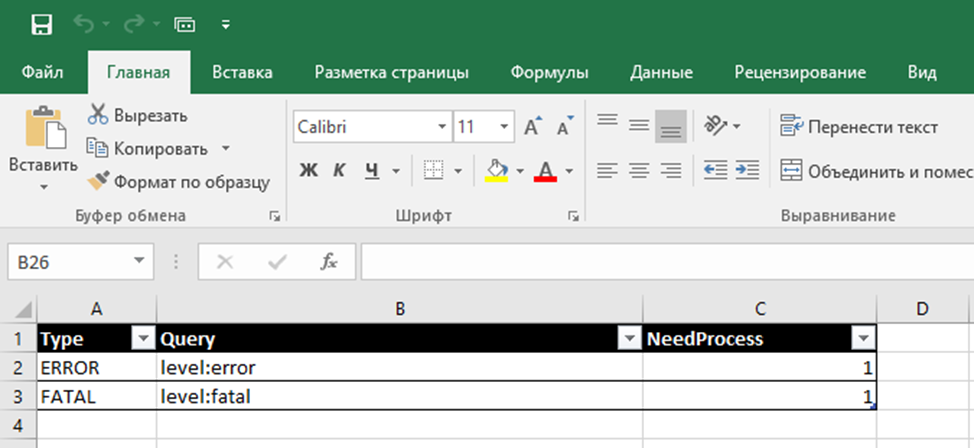
- Присвоить «имена» ошибкам. С помощью регулярных выражений задается шаблон поиска и ему присваивается человекопонятное обозначение. Затем все подходящие под шаблон ошибки в исходной таблице маркируются этим именем.
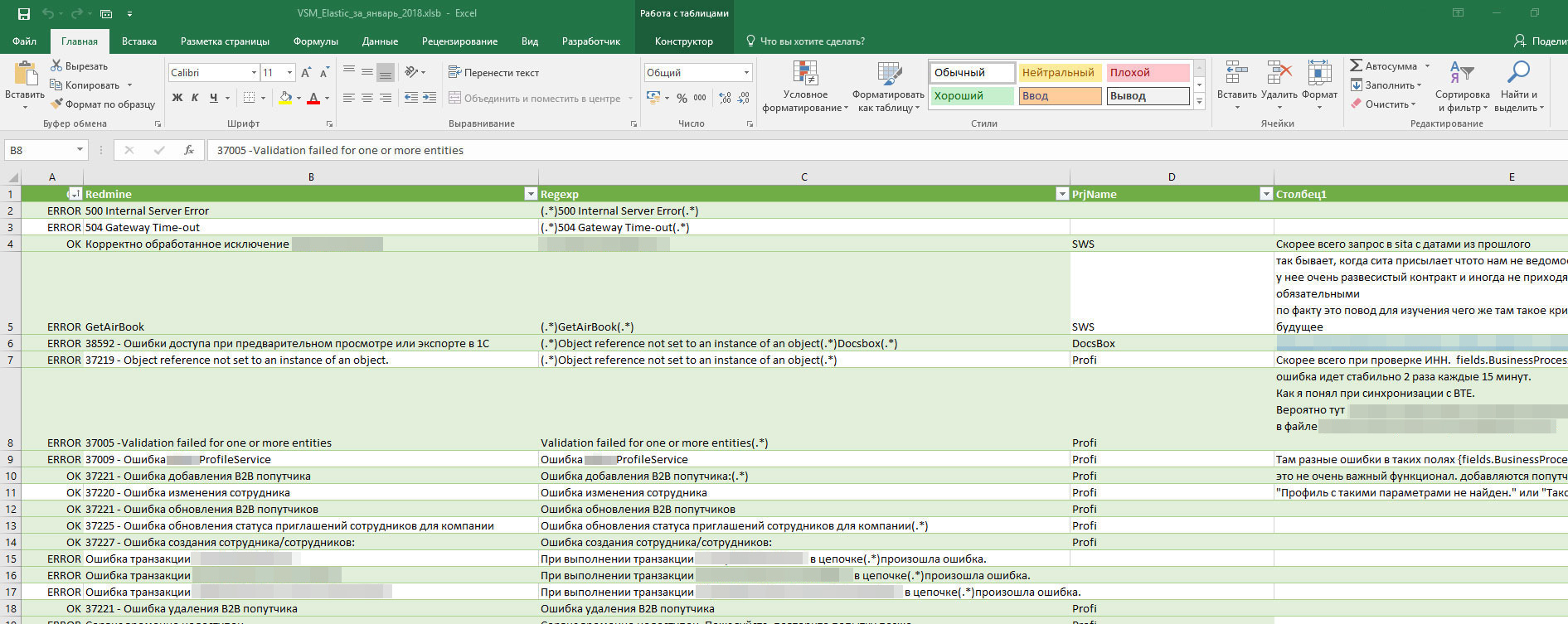
- Также присваиваются категории ОК и ERROR, обозначающие, стоит ли обращать внимание на сообщение или нет. По этим типам можно фильтровать. OTHER – показывает общее число сообщений по проекту (не только ошибки, но и просто информационные). И присваиваются номера задач в TFS, если они уже заведены.
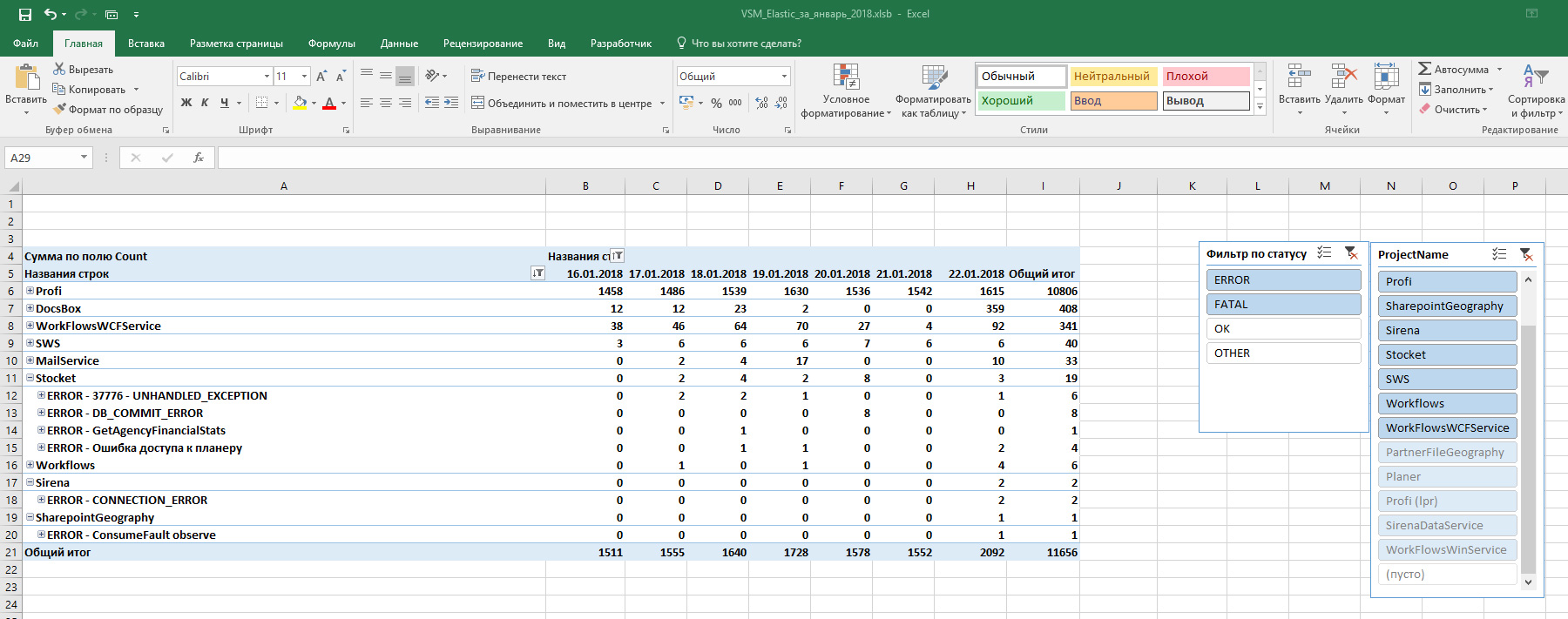
- Строится график для более удобного анализа с возможностью фильтрации.
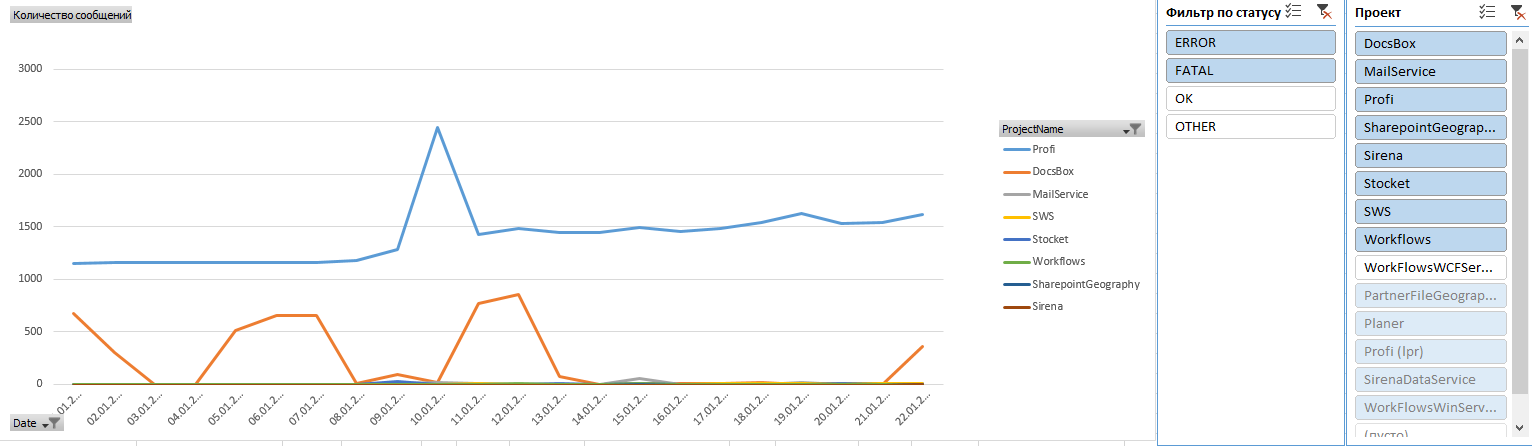
Разберем на примере одного из проектов свежие ошибки за последние пару дней:
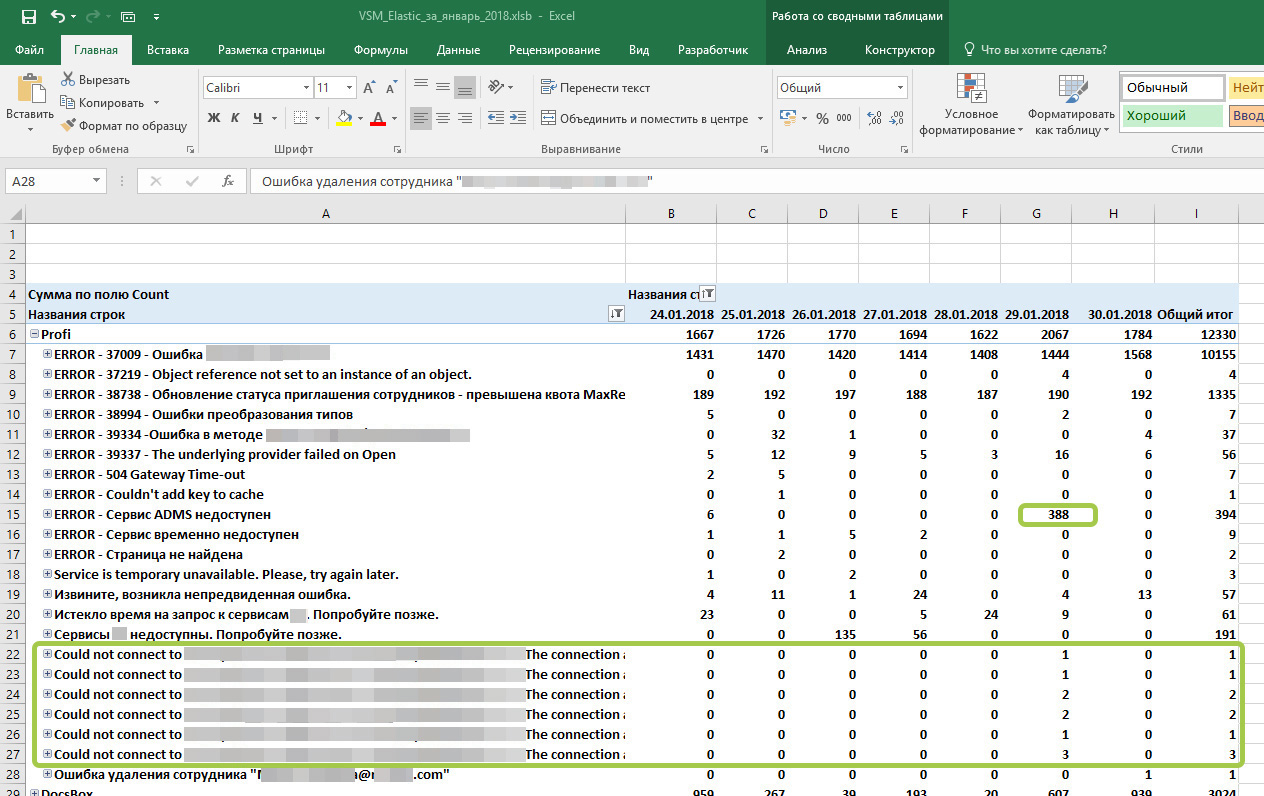
Что мы видим:
1) ошибки в верхней части, которым присвоены номера задач – не критичны, ждут решения разработчиками, им присвоены номера задач из TFS.
2) ошибка «Сервис ADMS недоступен» возникла 388 раз за сутки – несколько часов сервис был недоступен, что мы увидели, обратившись в Kibana за уточнением.
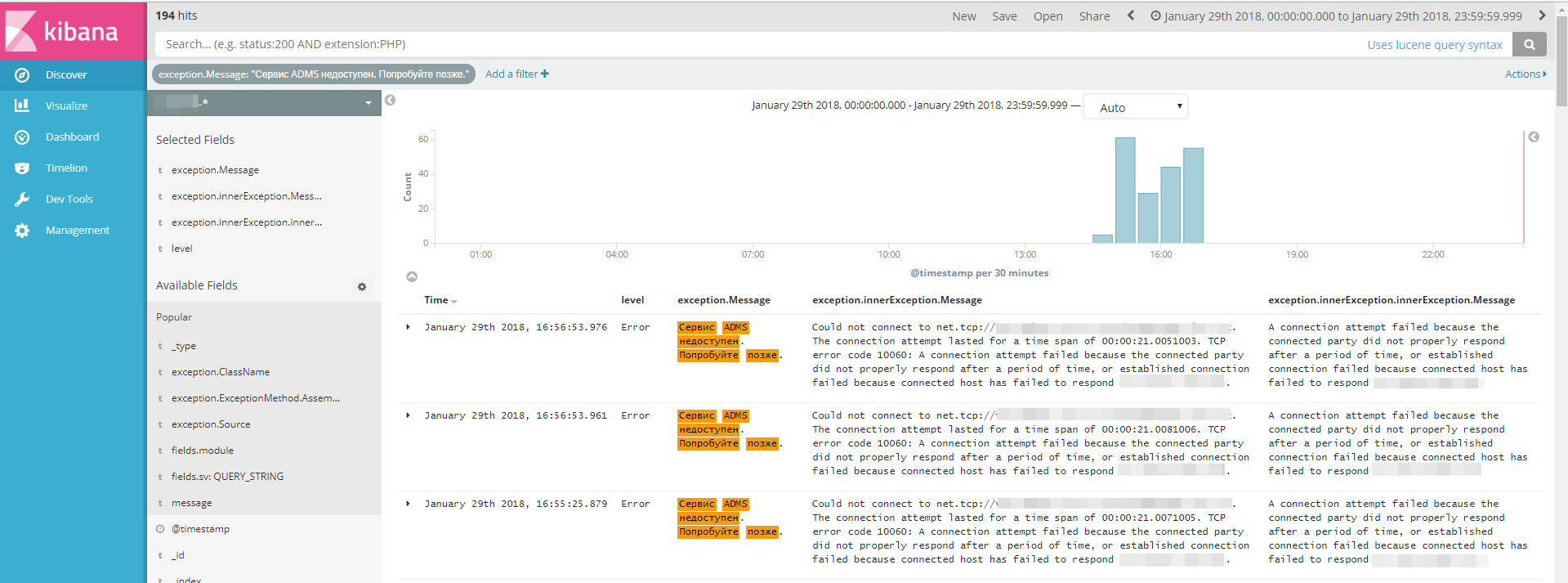
3) появился новый тип ошибки «Could not connect to…» – она связана с предыдущей, просто логировалась еще в одном месте.
Мы собираемся «расследовать» эти два вида ошибок, чтобы выяснить причины, вероятность повторения и способы предотвращения их в будущем. Им будет присвоено общее обозначение, чтобы эти ошибки «свернулись» в одну строку.
Что планируем улучшить
Сейчас мы работаем над отдельной системой, которая сама по расписанию будет выбирать все ошибки из Elasticsearch, уведомлять оператора о новых и уведомлять о всплесках ошибок. Она будет работать быстрее, чем файл Excel, который постоянно растет. Эта система позволит строить график с различной дискретностью, а не только сутки. Оператор все так же будет анализировать новые ошибки, давать им имена и реагировать на непредвиденные ситуации.
P.S. Теперь благодаря ELK врач сам замечает, что пациент приболел, может быстро поставить диагноз и вручить полезную пилюлю, а операции оставим для самых крайних случаев.
Комментарии (13)

rumatavz
01.02.2018 23:24Durable mode elastic синка не работает! Не делайте так!
Я терял сообщения с тремя разными симптомами:
1) Отправка сообщений зависла до перезагрузки сервиса(три дня без мониторинга). В текстовых буферах сообщения есть, а в эластике нет.
2) Иногда одиночные сообщения есть в текстовых буферах но нет в эластике. github.com/serilog/serilog-sinks-elasticsearch/issues/125
3) Если у вас сервис падает при старте и даже если вы корректно деалете диспоуз то при определенных условиях вы ничего не получите в эластике github.com/serilog/serilog-sinks-elasticsearch/issues/130
eastbanctech Автор
02.02.2018 06:56Спасибо за наводку! Слышали про подобные вещи, но сами не встречали. Будем мониторить и исследовать.

Alghazanth
02.02.2018 06:11> настроили Excel-таблицу с макросами, которые умеют забирать из Kibana данные за сутки, выбирать из них ошибки и распределить их по существующим категориям
А почему не используете визуализации и дашборды в самой Кибане? Судя по вашем описанию, нужные вам метрики можно нарисовать и там.eastbanctech Автор
02.02.2018 06:27По регламенту нашего клиента логи в ELK хранятся 2 недели, а мы хотим накапливать данные для анализа за более длительный срок, чтобы иметь возможность, например, сравнивать общую статистику с прошлым годом.

zip-imp
04.02.2018 16:21>Мы видим, где ошибка, её место в коде, когда она возникла, условия окружения. У нас есть один ID, который связывает все системы воедино и может проследить полный путь ошибки.
Как создаётся TraceId? И как Вы место в коде и окружение собираете?
Не уловил роль Zabbix?eastbanctech Автор
05.02.2018 09:51На одном проекте мы запускали WebApi через Owin. Там есть возможность обогатить контекст логера любыми данными, в данном случае это был просто Guid. Эти данные автоматом прицепляются ко всем сообщениям логгера (обращение к других API в рамках исходного запроса), как только исходный запрос завершается — контекст логера уничтожается.
Про Zabbix: мы создаем периодическую проверку — последовательно выполнять определенные цепочки запросов, это имитирует какой-то из бизнес-процессов. Замеряем успешность и время выполнения. Сбои на каком-то из этапов служат поводом для оповещения специалистов поддержки.
vba
В сторону Seq не смотрели? Раз уж вы с Serilog работаете.
eastbanctech Автор
Мы серьёзно рассматривали Seq, но в итоге отказались от него. У нас уже построена инфраструктура, и инженерам техподдержки удобнее работать с этим инструментом (ELK). Держать два инструмента с дублирующимся функциями кажется бессмысленным. И всё перетачивать не Seq не видим смысла. Гораздо удобнее, когда и на Java, и на .NET-проектах используется один и тот же стек ELK.
vba
Ну как сказано ниже у Serilog и ES есть свои изъяны. Хотя если вам нужно хостить логи и из java и из .net окружений то тогда да, ибо порт Serilog на java архи плох.