
 Привет, Хаброжители! Недавно у нас вышел фундаментальный труд Майкла Керриска по программным интерфейсам операционной системы Linux. В книге представлено практически полное описание API системного программирования под управлением Linux.
Привет, Хаброжители! Недавно у нас вышел фундаментальный труд Майкла Керриска по программным интерфейсам операционной системы Linux. В книге представлено практически полное описание API системного программирования под управлением Linux.Сейчас мы рассмотрим раздел «Потоки выполнения: введение». Мы сначала ознакомимся с кратким обзором работы потоков, а затем сосредоточимся на том, как они создаются и завершаются. В конце будут рассмотрены некоторые факторы, которые следует учитывать при выборе между двумя разными подходами к проектирования приложений — многопоточным и многопроцессным.
29.1. Краткий обзор
По аналогии с процессами потоки выполнения представляют собой механизм для одновременного выполнения нескольких параллельных задач в рамках одного приложения. Как показано на рис. 29.1, один процесс может содержать несколько потоков. Все они выполняются внутри одной программы независимо друг от друга, разделяя общую глобальную память — в том числе инициализированные/неинициализированные данные и сегменты кучи (традиционный для UNIX процесс является всего лишь частным случаем многопоточного процесса; он состоит из одного потока).
На рис. 29.1 допущены некоторые упрощения. В частности, местоположение стеков у каждого из потоков может пересекаться с разделяемыми библиотеками и общими участками памяти; это зависит от порядка, в котором создавались потоки, загружались библиотеки и присоединялись общие участки памяти. Кроме того, местоположение стеков у потоков может меняться в зависимости от дистрибутива Linux.
Потоки в процессе могут выполняться одновременно. В многопроцессорных системах возможно параллельное выполнение потоков. Если один поток заблокирован из-за ввода/вывода, другой может продолжать работу (иногда имеет смысл создать отдельный поток, который занимается исключительно вводом/выводом, хотя, часто более подходящими оказываются альтернативные модели ввода/вывода; подробней об этом — в главе 59).
В некоторых ситуациях потоки имеют преимущество перед процессами. Рассмотрим традиционный для UNIX подход к обеспечению конкурентного выполнения за счет создания нескольких процессов. Возьмем для примера модель сетевого сервера, в которой родительский процесс принимает входящие подключения и создает с помощью вызова fork() отдельные дочерние процессы для общения с каждым клиентом (см. раздел 56.3). Это позволяет одновременно обслуживать сразу несколько подключений. Такой подход обычно хорошо себя проявляет, но в некоторых ситуациях он приводит к следующим ограничениям.

- Обмен информацией между процессами имеет свои сложности. Поскольку родитель и потомок не разделяют память (помимо текстового сегмента, предназначенного сугубо для чтения), мы вынуждены использовать некую форму межпроцессного взаимодействия для обмена данными.
- Создание процесса с помощью fork() потребляет относительно много ресурсов. Даже если использовать метод копирования при записи, описанный в подразделе 24.2.2, нам все равно приходится дублировать различные атрибуты процесса, такие как таблицы со страницами памяти и файловыми дескрипторами; это означает, что вызов fork() по-прежнему занимает существенное время. Потоки помогают избавиться от обеих этих проблем.
- Обмен информации между потоками является простым и быстрым. Для этого всего лишь нужно скопировать данные в общие переменные (глобальные или в куче). Но чтобы избежать проблем, которые могут возникнуть в ситуации, когда сразу несколько потоков пытаются обновить одну и ту же информацию, приходится применять методы синхронизации, описанные в главе 30.
- Создание потока занимает меньше времени, чем создание процесса — обычно имеем как минимум десятикратный выигрыш в производительности (в Linux потоки реализованы с помощью системного вызова clone(); отличия в скорости между ним и вызовом fork() показаны в табл. 28.3). Процедура создания потока является более быстрой, поскольку многие атрибуты вместо непосредственного копирования, как в случае с fork(), просто разделяются. В частности, отпадает потребность в дублировании страниц памяти (с помощью копирования при записи) и таблиц со страницами.
Помимо глобальной памяти, потоки также разделяют целый ряд других атрибутов (это когда атрибуты являются глобальными для всего процесса, а не для отдельных потоков). Среди них можно выделить атрибуты, перечисленные ниже.
— Идентификаторы процесса и его родителя.
— Идентификаторы группы процессов и сессии.
— Управляющий терминал.
— Учетные данные процесса (идентификаторы пользователя и группы).
— Дескрипторы открытых файлов.
— Блокировки записей, созданные с помощью вызова fcntl().
— Действия сигналов.
— Информация, относящаяся к файловой системе: umask, текущий и корневой каталог.
— Интервальные таймеры (setitimer()) и POSIX-таймеры (timer_create()).
— Значения отмены семафоров (semadj) в System V.
— Ограничения на ресурсы.
— Потребленное процессорное время (полученное из times()).
— Потребленные ресурсы (полученные из getrusage()).
— Значение nice (установленное с помощью setpriority() и nice()).
Ниже перечислены атрибуты, которые являются уникальными для каждого отдельного потока:
— Идентификатор потока (см. раздел 29.5).
— Маска сигнала.
— Данные, относящиеся к определенному потоку (см. раздел 31.3).
— Альтернативный стек сигналов (sigaltstack()).
— Переменная errno.
— Настройки плавающей запятой (см. env(3)).
— Политика и приоритет планирования в режиме реального времени (см. разделы 35.2 и 35.3).
— Привязка к ЦПУ (относится только к Linux, описывается в разделе 35.4).
— Возможности (относится только к Linux, описывается в главе 39).
— Стек (локальные переменные и сведения о компоновке вызовов функций).
Как можно видеть на рис. 29.1, все стеки, относящиеся к отдельным потокам, находятся внутри одного и того же виртуального адресного пространства. Это означает, что потоки, имея подходящие указатели, могут обмениваться данными через стеки друг друга. Это бывает удобно, но требует осторожности при написании кода, чтобы уладить зависимость, вытекающую из того факта, что локальная переменная остается действительной только на время существования стека, в котором она находится (если функция возвращает значение, участок памяти, использовавшийся ее стеком, может быть повторно задействован во время последующего вызова функции; если поток завершается, участок памяти, в котором находился его стек, формально становится доступным другому потоку). Неправильная работа с этой зависимостью может привести к ошибкам, которые будет сложно отследить.
29.2. Общие сведения о программном интерфейсе Pthreads
В конце 1980-х и начале 1990-х годов существовало несколько разных программных интерфейсов для работы с потоками. В 1995 году в стандарте POSIX.1 был описан API-интерфейс POSIX-потоков, который позже вошел в состав SUSv3. Программный интерфейс Pthreads основывается на нескольких концепциях. Мы познакомимся с ними, подробно рассматривая его реализацию.
Типы данных в Pthreads
Программный интерфейс Pthreads определяет целый ряд типов данных, часть из которых перечислена в табл. 29.1. Большинство из них будет описано на следующих страницах.
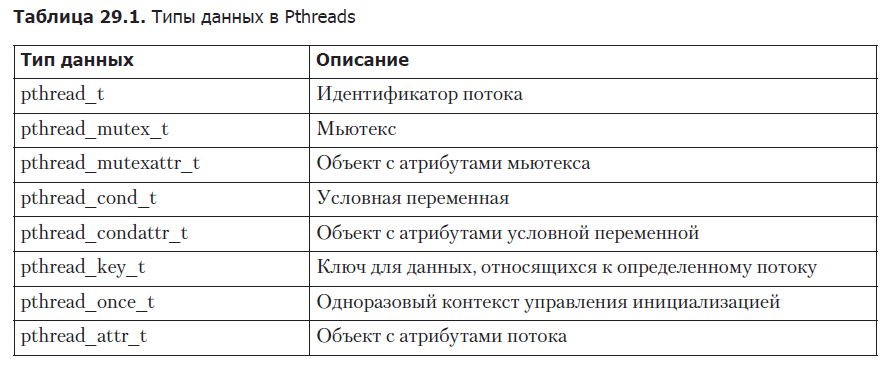
Стандарт SUSv3 не содержит подробностей о том, как именно должны быть представлены эти типы данных, поэтому переносимые приложения должны считать их непрозрачными. Это означает, что программа не должна зависеть от структуры или содержимого переменных любого из этих типов. В частности, мы не можем сравнивать такие переменные с помощью оператора ==.
Потоки и переменная errno
В традиционном программном интерфейсе UNIX переменная errno является глобальной и целочисленной. Однако этого недостаточно для многопоточных программ. Если поток вызвал функцию, записавшую ошибку в глобальную переменную errno, это может ввести в заблуждение другие потоки, которые тоже вызывают функции и проверяют значение errno. Иными словами, результатом будет состояние гонки. Таким образом, в многопоточных программах каждый поток имеет свой отдельный экземпляр errno. В Linux (и в большинстве реализаций UNIX) для этого используется примерно один подход: errno объявляется в виде макроса, который разворачивается в вызов функции, возвращающий изменяемое значение вида lvalue, уникальное для каждого отдельного потока (поскольку значение lvalue доступно для изменения, мы по-прежнему можем записывать в многопоточных программах операции присваивания вида errno = value).
Резюмируя вышесказанное: механизм errno был интегрирован в потоки так, что процедура оповещения об ошибках полностью соответствует традиционному подходу, применяющемуся в программных интерфейсах UNIX.
Значение, возвращаемое функциями в Pthreads
Традиционно системные вызовы и некоторые функции возвращают 0 в случае успеха и –1, если произошла ошибка. Для обозначения самой ошибки применяется переменная errno. Функции в программном интерфейсе Pthreads ведут себя иначе. В случае успеха так же возвращается 0, но при ошибке используется положительное значение. Это одно из тех значений, которые можно присвоить переменной errno в традиционных системных вызовах UNIX.
Поскольку каждая ссылка на errno в многопоточной программе несет в себе накладные расходы, связанные с вызовом функции, наша программа не присваивает значение, возвращенное функцией из состава Pthreads, непосредственно этой переменной. Вместо этого мы используем промежуточную переменную и нашу диагностическую функцию errExitEN() (см. подраздел 3.5.2), как показано ниже:
pthread_t *thread;
int s;
s = pthread_create(&thread, NULL, func, &arg);
if (s != 0)
errExitEN(s, "pthread_create");Компиляция программ на основе Pthreads
В Linux программы, которые используют программный интерфейс Pthreads, должны компилироваться с параметром cc -pthread. Среди действий этого параметра можно выделить следующие.
- Объявляется макрос препроцессора _REENTRANT. Это открывает доступ к объявлениям нескольких реентерабельных (повторно входимых) функций.
- Программа компонуется с библиотекой libpthread (эквивалент параметра -lpthread).
Конкретные параметры компиляции многопоточных программ варьируются в зависимости от реализации (и компилятора). В некоторых системах (таких как Tru64) тоже используется cc -pthread, хотя в Solaris и HP-UX применяется параметр cc -mt.
29.3. Создание потоков
Сразу после запуска программы итоговый процесс состоит из одного потока, который называют исходным или главным. В этом разделе вы узнаете, как создаются дополнительные потоки.
Для создания нового потока используется функция pthread_create().

Новый поток начинает выполнение с вызова функции, указанной в виде значения start и принимающей аргумент arg (то есть start(arg)). Поток, который вызвал pthread_create(), продолжает работу, выполняя инструкцию, следующую за данным вызовом (это соответствует поведению функции-обертки вокруг системного вызова clone() из состава библиотеки glibc, описанной в разделе 28.2).
Аргумент arg объявлен как void *. Это означает, что мы можем передать функции start указатель на объект любого типа. Обычно он указывает на переменную, находящуюся в глобальном пространстве или в куче, но мы также можем использовать значение NULL. Если нам нужно передать функции start несколько аргументов, мы можем предоставить в качестве arg указатель на структуру, содержащую эти аргументы в виде отдельных полей. Мы даже можем указать arg как целое число (int), воспользовавшись подходящим приведением типов.
Строго говоря, стандарты языка С не описывают результатов приведения int к void * и наоборот. Однако большинство компиляторов допускают эту операцию и генерируют предсказуемый результат — то есть int j == (int) ((void *) j).
Значение, возвращаемое функцией start, тоже имеет тип void * и может быть интерпретировано, как и аргумент arg. Ниже, при рассмотрении функции pthread_join(), вы узнаете, как используется это значение.
Во время приведения значения, возвращенного начальной функцией потока, к целому числу следует соблюдать осторожность. Дело в том, что значение PTHREAD_CANCELED, возвращаемое при отмене потока (см. главу 32), обычно реализуется в виде целого числа, приведенного к типу void *. Если начальная функция вернет это значение, другой поток, выполняющий pthread_join(), ошибочно воспримет это как уведомление об отмене потока. В приложениях, которые допускают отмену потоков и используют целые числа в качестве значений, возвращаемых из начальных функций, необходимо следить за тем, чтобы в потоках, завершающихся в штатном режиме, эти значения не совпадали с константой PTHREAD_CANCELED (чему бы она ни равнялась в текущей реализации Pthreads). Переносимые приложения должны делать то же самое, но с учетом всех реализаций, с которыми они могут работать.
Аргумент thread указывает на буфер типа pthread_t, в который перед возвращением функции pthread_create() записывает уникальный идентификатор созданного потока. С помощью этого идентификатора можно будет ссылаться на данный поток в дальнейших вызовах Pthreads.
В стандарте SUSv3 отдельно отмечается, что буфер, на который указывает thread, не нужно инициализировать до начала выполнения нового потока. То есть новый поток может начать работу до того, как вернется функция pthread_create(). Если новому потоку нужно получить свой собственный идентификатор, он должен использовать для этого функцию pthread_self() (описанную в разделе 29.5).
Аргумент attr является указателем на объект pthread_attr_t, содержащий различные атрибуты нового потока (к которым мы еще вернемся в разделе 29.8). Если присвоить attr значение NULL, поток будет создан с атрибутами по умолчанию, — именно это мы и будем делать в большинстве примеров в этой книге.
Программа не знает, какому потоку планировщик выделит процессорное время после вызова pthread_create() (в многопроцессорных системах оба потока могут выполняться одновременно на разных ЦПУ). Программы, которые явно полагаются на определенный порядок планирования, подвержены тем же видам состояния гонки, что были описаны в разделе 24.4. Если нам необходимо гарантировать тот или иной порядок выполнения, мы должны использовать один из методов синхронизации, рассмотренных в главе 30.
29.4. Завершение потоков
Выполнение потока прекращается по одной из следующих причин.
- Начальная функция выполняет инструкцию return, указывая возвращаемое значение для потока.
- Поток вызывает функцию pthread_exit() (описанную ниже).
- Поток отменяется с помощью функции pthread_cancel() (описанной в разделе 32.1).
- Любой из потоков вызывает exit() или главный поток выполняет инструкцию return (внутри функции main()), что приводит к немедленному завершению всех потоков в процессе.
Функция pthread_exit() завершает вызывающий поток и указывает возвращаемое значение, которое может быть получено из другого потока с помощью функции pthread_join().
include <pthread.h>
void pthread_exit(void *retval);Вызов pthread_exit() эквивалентен выполнению инструкции return внутри начальной функции потока, за исключением того, что pthread_exit() можно вызвать из любого кода, запущенного начальной функцией.
Аргумент retval хранит значение, возвращаемое потоком. Значение, на которое указывает retval, не должно находиться в стеке самого потока, поскольку по окончании вызова pthread_exit() его содержимое становится неопределенным (этот участок виртуальной памяти процесса может быть сразу же выделен под стек для нового потока). То же самое касается и значения, передаваемого с помощью инструкции return в начальной функции.
Если главный поток вызовет pthread_exit() вместо exit() или инструкции return, остальные потоки продолжат выполнение.
29.5. Идентификаторы потоков
Каждый поток внутри процесса имеет свой уникальный идентификатор. Он возвращается в вызывающий поток функцией pthread_create(). Кроме того, с помощью функции pthread_self() поток может получить собственный идентификатор.
include <pthread.h>
pthread_t pthread_self(void);Возвращает идентификатор вызывающего потока
Идентификаторы потоков внутри приложения можно использовать следующим образом.
- Задействуются различными функциями из состава Pthreads для определения того, в каком потоке они выполняются. В качестве примера можно привести функции pthread_join(), pthread_detach(), pthread_cancel() и pthread_kill(); все они описаны в этой и последующих главах.
- В некоторых приложениях может иметь смысл маркировать динамические структуры данных идентификатором определенного потока. Так мы можем определить создателя и «владельца» структуры; это также позволяет определить поток, который должен выполнить какие-то последующие действия со структурой данных.
Функция pthread_equal() позволяет проверить на тождественность два идентификатора потоков.

Например, чтобы проверить, совпадает ли идентификатор вызывающего потока со значением, сохраненным в переменной tid, можно написать следующий код:
if (pthread_equal(tid, pthread_self())
printf("tid matches self\n");Необходимость в функции pthread_equal() возникает из-за того, что тип данных pthread_t должен восприниматься как непрозрачный. В Linux он имеет тип unsigned long, но в других системах он может быть указателем или структурой.
В библиотеке NPTL pthread_t в самом деле является указателем, который приводится к типу unsigned long.
Стандарт SUSv3 не требует, чтобы тип pthread_t был скалярным. Это может быть структура. Таким образом, код для вывода идентификатора потока, представленный выше, не является переносимым (хотя он работает во многих системах, включая Linux, и может пригодиться во время отладки):
pthread_t thr;
printf("Thread ID = %ld\n", (long) thr); /* Неправильно! */В Linux идентификаторы потоков являются уникальными для всех процессов. Однако в других системах это может быть не так. В стандарте SUSv3 отдельно отмечается, что переносимые приложения не могут полагаться на эти идентификаторы для определения потоков в других процессах. Там же указывается, что поточные библиотеки могут повторно использовать эти идентификаторы после присоединения завершенного потока с помощью функции pthread_join() или после завершения отсоединенного потока (функция pthread_join() будет рассмотрена в следующем разделе, а отсоединенные потоки — в разделе 29.7).
Идентификаторы POSIX- и обычных потоков, возвращаемые системным вызовом gettid() (доступным только в Linux), — это не одно и то же. Идентификатор POSIX-потока присваивается и обслуживается реализацией поточной библиотеки. Идентификатор обычного потока возвращается вызовом gettid() и представляет собой число (похожее на идентификатор процесса), которое назначается ядром. И хотя в реализации библиотеки NPTL используются уникальные идентификаторы потоков, выданные ядром, приложениям зачастую не нужно о них знать (к тому же работа с ними лишает приложения возможности переносимости между разными системами).
29.6. Присоединение к завершенному потоку
Функция pthread_join() ждет завершения потока, обозначенного аргументом thread (если поток уже завершился, она сразу же возвращается). Эта операция называется присоединением.

Если аргумент retval является ненулевым указателем, функция получает копию возвращаемого значения завершенного потока, то есть значение, указанное при выполнении потоком инструкции return или вызове pthread_exit().
Вызов функции pthread_join() для идентификатора уже присоединенного потока может привести к непредсказуемым последствиям; например, мы можем присоединиться к потоку, который был создан позже и повторно использует тот же идентификатор.
Если поток не отсоединен (см. раздел 29.7), мы должны присоединиться к нему с помощью функции pthread_join(). Если нам не удастся это сделать, завершенный поток превратится в аналог процесса-«зомби» (см. раздел 26.2). Помимо пустой траты ресурсов, это может привести к тому, что мы больше не сможем создавать новые потоки (в случае если накопится достаточное количество потоков-«зомби»).
Процедура, которую выполняет функция pthread_join() для потоков, похожа на действие вызова waitpid() в контексте процессов. Но между ними есть и заметные различия.
Если аргумент retval является ненулевым указателем, функция получает копию возвращаемого значения завершенного потока, то есть значение, указанное при выполнении потоком инструкции return или вызове pthread_exit().
Вызов функции pthread_join() для идентификатора уже присоединенного потока может привести к непредсказуемым последствиям; например, мы можем присоединиться к потоку, который был создан позже и повторно использует тот же идентификатор.
Если поток не отсоединен (см. раздел 29.7), мы должны присоединиться к нему с помощью функции pthread_join(). Если нам не удастся это сделать, завершенный поток превратится в аналог процесса-«зомби» (см. раздел 26.2). Помимо пустой траты ресурсов, это может привести к тому, что мы больше не сможем создавать новые потоки (в случае если накопится достаточное количество потоков-«зомби»).
Процедура, которую выполняет функция pthread_join() для потоков, похожа на действие вызова waitpid() в контексте процессов. Но между ними есть и заметные различия.
- Потоки не имеют иерархии. Любой поток в процессе может воспользоваться функцией pthread_join() для присоединения к другому потоку в том же процессе. Представьте, к примеру, что поток А создал поток Б, который позже создал поток В; в этом случае поток А может присоединиться к потоку В и наоборот. Это отличается от иерархических отношений между процессами. Если родительский процесс создал потомка с помощью fork(), он и только он может ожидать этого потомка, используя вызов wait(). Между потоком, который вызывает функцию pthread_create(), и потоком, который при этом создается, нет таких отношений.
- Невозможно присоединиться к «любому потоку» (в случае с процессами мы можем это сделать с помощью вызова waitpid(–1, &status, options)); также не существует неблокирующей операции присоединения (аналога вызова waitpid() с флагом WNOHANG). Похожих результатов можно добиться с помощью условных переменных; пример этого будет показан в подразделе 30.2.4.
Ограничение, связанное с тем, что функция pthread_join() может присоединять потоки только при наличии конкретного идентификатора, было создано умышленно. Идея заключается в том, что программа должна присоединяться только к тем потокам, о которых она «знает». Проблема операции «присоединения к произвольному потоку» произрастает из того факта, что потоки не имеют иерархии, поэтому таким образом мы действительно могли бы присоединиться к любому потоку, в том числе и к приватному, созданному библиотечной функцией (применение условных переменных, описанное в подразделе 30.2.4, позволяет присоединяться только к известным потокам). В результате библиотека не смогла бы больше присоединиться к этому потоку, чтобы получить его статус, а попытки присоединения к уже присоединенному потоку привели бы к ошибкам. Иными словами, операция «присоединения к произвольному потоку» несовместима с модульной архитектурой приложения.
Пример программы
Программа, показанная в листинге 29.1, создает новый поток и присоединяется к нему.
Листинг 29.1. Простая программа, использующая библиотеку Pthreads
______________________________________________________________threads/simple_thread c
#include <pthread.h>
#include "tlpi_hdr.h"
static void *
threadFunc(void *arg)
{
char *s = (char *) arg;
printf("%s", s);
return (void *) strlen(s);
}
int
main(int argc, char *argv[])
{
pthread_t t1;
void *res;
int s;
s = pthread_create(&t1, NULL, threadFunc, "Hello world\n");
if (s != 0)
errExitEN(s, "pthread_create");
printf("Message from main()\n");
s = pthread_join(t1, &res);
if (s != 0)
errExitEN(s, "pthread_join");
printf("Thread returned %ld\n", (long) res);
exit(EXIT_SUCCESS);
}
______________________________________________________________threads/simple_thread.cЗапустив эту программу, мы увидим следующее:
$ ./simple_thread
Message from main()
Hello world
Thread returned 12Порядок вывода первых двух строчек зависит от того, как планировщик распорядится двумя потоками.
29.7. Отсоединение потока
По умолчанию потоки являются присоединяемыми; это означает, что после завершения их статус можно получить из другого потока с помощью функции pthread_join(). Иногда статус, возвращаемый потоком, не имеет значения; нам просто нужно, чтобы система автоматически освободила ресурсы и удалила поток, когда тот завершится. В этом случае мы можем пометить поток как отсоединенный, воспользовавшись функцией pthread_detach() и указав идентификатор потока в аргументе thread.

В качестве примера использования функции pthread_detach() можно привести следующий вызов, в котором поток отсоединяет сам себя:
pthread_detach(pthread_self());Если поток уже был отсоединен, мы больше не можем получить его возвращаемый статус с помощью функции pthread_join(). Мы также не можем снова сделать его присоединяемым.
Отсоединенный поток не становится устойчивым к вызову exit(), сделанному в другом потоке, или к инструкции return, выполненной в главной программе. В любой из этих ситуаций все потоки внутри процесса немедленно завершаются, вне зависимости от того, присоединяемые они или нет. Иными словами, функция pthread_detach() просто отвечает за поведение потока после его завершения, но не за то, в каких обстоятельствах тот завершается.
29.8. Атрибуты потоков
Ранее уже упоминалось, что аргумент attr функции pthread_create(), имеющий тип pthread_attr_t, может быть использован для задания атрибутов, которые применяются при создании нового потока. Мы не будем углубляться в рассмотрение этих атрибутов (подробности о них ищите в ссылках, перечисленных в конце главы) или изучать прототипы различных функций из состава Pthreads, которые позволяют работать с объектом pthread_attr_t. Мы просто отметим, что данные атрибуты содержат такие сведения, как местоположение и размер стека потока, политику его планирования и приоритет (это похоже на политики планирования в режиме реального времени и приоритеты процессов, описанные в разделах 35.2 и 35.3), а также информацию о том, является ли поток присоединяемым или отсоединенным.
Пример использования этих атрибутов приводится в листинге 29.2, где создается поток, являющийся отсоединенным на момент своего появления (а не в результате последующего вызова pthread_detach()). В самом начале этот код инициализирует структуру с атрибутами с помощью значений по умолчанию, потом устанавливает атрибуты, необходимые для создания отсоединенного потока, и затем создает с помощью этой структуры новый поток. По окончании процедуры создания объект с атрибутами удаляется за ненадобностью.
Листинг 29.2. Создание потока с «отсоединяющим» атрибутом
__________________________________________________ Из файла threads/detached_attrib.c
#include <pthread.h>
#include "tlpi_hdr.h"
static void *
threadFunc(void *x)
{
return x;
}
int
main(int argc, char *argv[])
{
pthread_t thr;
pthread_attr_t attr;
int s;
s = pthread_attr_init(&attr); /* Присваиваем значения по умолчанию */
if (s != 0)
errExitEN(s, "pthread_attr_init");
s = pthread_attr_setdetachstate(&attr, PTHREAD_CREATE_DETACHED);
if (s != 0)
errExitEN(s, "pthread_attr_setdetachstate");
s = pthread_create(&thr, &attr, threadFunc, (void *) 1);
if (s != 0)
errExitEN(s, "pthread_create");
s = pthread_attr_destroy(&attr); /* Больше не нужен */
if (s != 0)
errExitEN(s, "pthread_attr_destroy");
s = pthread_join(thr, NULL);
if (s != 0)
errExitEN(s, "pthread_join failed as expected");
exit(EXIT_SUCCESS);
}
__________________________________________________ Из файла threads/detached_attrib.c29.9. Сравнение потоков и процессов
В этом разделе мы кратко рассмотрим несколько факторов, которые следует учитывать при выборе между потоками и процессами в качестве основы для своего приложения. Начнем с обсуждения преимуществ многопоточного подхода.
- Обмениваться данными между потоками просто. Такой же обмен данными, но между процессами требует больше затрат (например, создания общего сегмента памяти или использование конвейера).
- Создание потока занимает меньше времени, чем создание процесса; потоки также могут выигрывать в плане скорости переключения контекста. Однако потоки имеют определенные недостатки по сравнению с процессами.
- Создавая программу на основе потоков, мы должны следить за тем, чтобы используемые функции были потокобезопасными или вызывались совместимым с потоками способом (понятие потоковой безопасности будет описано в разделе 31.1). Многопроцессные приложения могут об этом не заботиться.
- Ошибка в одном потоке (например, изменение памяти через неправильный указатель) может повредить остальные потоки в процессе, поскольку все они используют общее адресное пространство и некоторые другие атрибуты. Для сравнения, процессы являются более изолированными друг от друга.
- Каждый поток соперничает за возможность использования конечного адресного пространства своего процесса. В частности, стек и локальное хранилище каждого потока потребляет часть виртуальной памяти процесса, что делает ее недоступной для других потоков. И хотя адресное пространство имеет довольно большой объем (например, 3 Гбайт для архитектуры x86-32), этот фактор может стать существенным ограничением, сдерживающим процесс от создания большого количества потоков или потоков, требующих много памяти. Отдельные процессы, с другой стороны, могут задействовать весь диапазон свободной виртуальной памяти, ограниченный лишь размерами RAM и пространства подкачки.
Ниже приведены дополнительные моменты, которые могут повлиять на выбор между потоками и процессами.
- Работа с сигналами в многопоточном приложении требует тщательного проектирования (как правило, рекомендуется избегать использования сигналов в многопоточных программах). Больше о потоках и сигналах будет рассказано в разделе 33.2.
- В многопоточном приложении все потоки должны выполнять одну и ту же программу (возможно, задействуя разные ее функции). В многопроцессных приложениях разные процессы способны выполнять разные программы.
- Помимо самих данных, потоки разделяют и другую информацию (например, файловые дескрипторы, действия сигналов, текущий каталог, идентификаторы (имена) пользователя и группы). Это может быть как преимуществом, так и недостатком, в зависимости от приложения.
29.10. Резюме
В многопоточных процессах в одной и той же программе одновременно выполняются разные потоки. Все они имеют общие глобальные переменные и кучу, но у каждого из них есть свой отдельный стек для локальных переменных. Разные потоки одного и того же процесса также разделяют целый ряд атрибутов, включая идентификатор процесса, дескриптор открытых файлов, действия сигналов, текущего каталога и ограничения на ресурсы.
Ключевой особенностью потоков является более простой обмен информацией по сравнению с процессами; по этой причине некоторые программные архитектуры лучше ложатся на многопоточный подход, нежели на многопроцессный. Кроме того, в некоторых ситуациях потоки могут демонстрировать лучшую производительность (например, поток создается быстрее, чем процесс), однако этот фактор обычно является вторичным при выборе между потоками и процессами.
Потоки создаются с помощью функции pthread_create(). Любой поток может завершиться независимо от других, используя функцию pthread_exit() (если вызвать exit() в любом из потоков, все они будут немедленно завершены). Если поток не был помечен как отсоединенный (например, с помощью вызова pthread_detach()), он должен быть присоединен другим потоком посредством функции pthread_join(), которая возвращает код завершения присоединенного потока.
» Более подробно с книгой можно ознакомиться на сайте издательства
» Оглавление
» Отрывок
Для Хаброжителей скидка 20% по купону — Linux

savvadesogle
1241 страницы… Как же хочется научиться читать такие книги так же быстро как обычные…
А так… это на пол года, ну плюс/минус месяц)
MaximNov
По сути — это POSIX интерфейс. Достаточно хорошо его знать, а далее можно будет только углубляться в особенности *NIX системы.
Profi_GMan
Я 900 страниц (Лафоре ЯП С++) прочитал за 2 месяца. Просто каждый день я где-то 70-100 страниц прочитывал
myxo
«900 страниц… каждый день где-то 70-100 страниц „
либо вы где-то напортачили с расчетами, либо вы читали ну очень неэффективно =)
Free_ze
Лафоре достаточно жидок. С каким-нибудь Страутрупом не прокатило бы.
savvadesogle
У Лафоре я ~300 страниц изучал 1.5 месяца. И то потому, что там была вводная часть)
А после появилась трудность с выделением времени и места для погружения и процесс замедлился.