
Когда мы придумывали задание для конкурса по обратной разработке, который состоялся на форуме PHDays V, то хотели отразить реальные проблемы, с которыми сталкиваются специалисты по RE, но при этом старались избежать шаблонных решений.
Как обычно выглядят задачки на реверс? Есть исполняемый файл под Windows (или Linux, или MacOS, или другую популярную операционную систему), его можно запускать, смотреть под отладчиком, крутить как угодно в виртуальных средах. Формат файла — известный. Система команд процессора — x86, AMD64 или ARM.
Библиотечные функции и системные вызовы — задокументированы. Доступ к оборудованию — только через механизмы операционной системы.
С использованием существующих инструментов (например, IDAPro с HеxRays и всеми сопутствующими возможностями) анализ подобных приложений становится практически детской забавой: все получается просто и быстро.
Конечно, иногда для усложнения задачи в программу добавляют виртуальные машины со своим набором инструкций, замусоривание кода, защиту от отладки и т. п. Но если говорить честно — насколько часто крупные производители ПО используют все это в своих исполняемых файлах? Да почти никогда! Какой же смысл делать конкурс, нацеленный на демонстрацию навыков, которые редко требуются в реальной жизни?
Однако есть еще одна область применения reverse engineering, все больше востребованная в последние годы, — анализ firmware. И тут ситуация оказывается совсем не такой, как в традиционном RE.
Входной файл (с прошивкой) может быть в любом формате, может быть даже запакован или зашифрован. Операционная система может быть совсем не популярная — или вообще может отсутствовать. Часть кода может быть жестко прописана в устройстве и не обновляться через прошивку. Архитектура процессора может быть любая! IDAPro, например, «знает» более 100 разных процессоров, но далеко не все. И, разумеется, нет почти никакой документации, почти никогда не доступна отладка, а зачастую и обычное выполнение кода невозможно: прошивка есть, а устройства нет…
Примерно такую задачу мы и решили предложить конкурсантам (принять участие мог любой интернет-пользователь). Каждый из них должен был проанализировать исполняемый файл и найти правильный ключ, соответствующий его email.
Первая часть: загрузчик
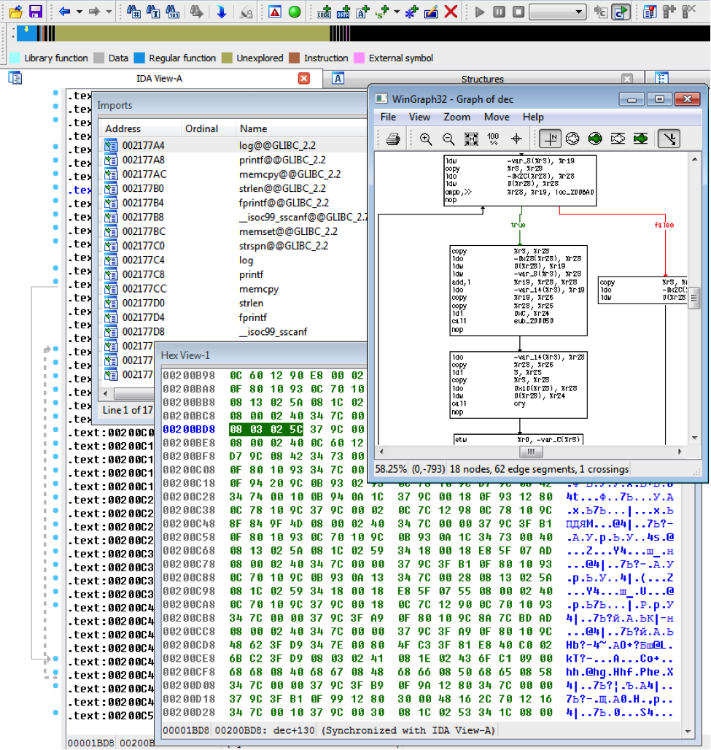
На первом этапе входным файлом был ELF, скомпилированный кросс-компилятором под архитектуру PA-RISC. IDA умеет работать с этой архитектурой, но не так хорошо как с x86. Многие обращения к стековым переменным автоматически не распознаются, и приходится помогать IDA руками. Но хотя бы видны все библиотечные функции (log, printf, memcpy, strlen, fprintf, sscanf, memset, strspn) и даже символические имена некоторых функций программы (с32, exk, cry, pad, dec, cen, dde).
Довольно просто понять, что программа ждет на вход два аргумента — email и key.
Легко выяснить также, что key должен состоять из двух частей, разделенных символом ‘-’. Первая часть (7 знаков) должна состоять только из разрешенных символов MIME64 (0-9A-Za-z+/), а вторая (32 знака) — из шестнадцатеричных символов, которые превращаются в 16 байт.

Далее видны вызовы функции
c32, складывающиеся в:t = c32(-1, argv[1], strlen(argv[1])+1)k = ~c32(t, argv[2], strlen(argv[2])+1)Имя c32 является подсказкой: используется СRC32, что подтверждается константой
0xEDB88320.Далее идет вызов функции dde (сокращение от doDecrypt), принимающей в первом аргументе инвертированный выход CRC32 — ключ шифрования, а во втором и третьем — адрес и размер расшифровываемого массива.
Расшифрование выполняется алгоритмом BTEA на основе кода, позаимствованного из Википедии. Догадаться, что это именно BTEA, можно по константе
DELTA==0x9E3779B9. Правда, она используется и в других алгоритмах, являющихся предшественниками BTEA, но вариантов совсем немного.Ключ должен быть 128-битовый, а CRC32 возвращает 32-битовое значение, так что три дополнительных DWORD-а получаются в функции
exk (expand_key) домножением предыдущего значения на все то же значение DELTA.Правда BTEA применяется не совсем обычно. Во-первых, у этого алгоритма настраиваемый размер блока, и в задании используется 12-байтовый блок: если бывают процессоры с 24-битовыми регистрами и ячейками памяти, то почему размер блока должен быть степенью двойки? :) А во-вторых, функции зашифрования и расшифрования поменяны местами — так тоже можно.
Так как шифруется поток данных, применяется зацепление блоков в режиме CBC (Cipher Block Chaining). Для расшифрованных данных в функции cen
(calc_enthropy) вычисляется энтропия, и если ее значение превысит 7, то результат расшифрования признается неверным, и программа завершается с соответствующим сообщением.Так как ключ шифрования имеет длину всего 32 бита, может показаться, что его легко подобрать. Однако если следовать логике программы, для проверки каждого ключа надо сначала расшифровать 80 килобайт данных, a потом подсчитать для них энтропию. И поиск ключа шифрования «в лоб» займет слишком много времени.
Однако, после проверки энтропии вызывается еще одна функция, pad (оригинальное название — strip_pad), которая проверяет и отрезает
PKCS#7 padding. Из-за свойств режима CBC для проверки дополнения надо расшифровать только один блок (самый последний), взять из него последний байт N, проверить, что его значение лежит в диапазоне от 1 до 12 включительно и что каждый из последних N байт имеет значение N.Это позволяет значительно сократить количество операций для проверки одного ключа, но если последний расшифрованный байт будет равен 1 (а это будет справедливо для 1/256 ключей), все равно придется делать полную проверку…
Чтобы найти ключ быстрее, достаточно предположить, что расшифрованные данные будут иметь длину, выравненную на DWORD (4 байта). Тогда в последнем DWORD-е последнего блока может оказаться только одно из трех возможных значений —
0x04040404, 0x08080808 или 0x0C0C0C0C. И используя такую эвристику можно перебрать все возможные ключи (и гарантированно найти правильный) менее чем за 20 минут.Если все проверки после расшифрования (энтропия и целостность паддинга) пройдены успешно, вызывается функция fire_second_proc, которая симулирует запуск второго процессора и загрузку в него расшифрованных данных (прошивки) — ведь в современных устройствах часто более одного процессора, причем с совершенно разными архитектурами.
Если второй процессор удалось успешно запустить, ему через функцию send_auth_data передается email пользователя и 16 байт со второй частью ключа. В этом месте мы случайно допустили ошибку: вместо размера второй части ключа использовался размер строки с email.
Вторая часть: прошивка
С анализом второй части все несколько сложнее. Там не ELF, а просто образ памяти — без заголовков, имен функций и прочей метаинформации. И разумеется, неизвестен ни тип процессора, ни адрес загрузки.
Задуманный нами алгоритм определения архитектуры процессора — обычный перебор. Открываем в IDA, ставим следующий тип, смотрим на получившийся мусор, и повторяем до тех пор, пока IDA не покажет что-то похожее не код. Перебор, в идеале, должен привести к выводу, что это big-endian SPARC.
Теперь надо определить адрес загрузки. Функция по смещению 0x22E0 ниоткуда не вызывается, но содержит довольно много кода. Можно предположить, что это точка входа в программу, функция start.
В третьей инструкции функции start идет вызов неизвестной библиотечной функции с одним аргументом
== 0x126F0, и эта же функция вызывается из start еще 4 раза, всегда с разными, но близкими по значению аргументами (0x12718, 0x12738, 0x12758, 0x12760). А в середине программы, начиная со смещения 0x2490, присутствуют как раз 5 текстовых строк с сообщениями:00002490 .ascii "Firmware loaded, sending ok back."<0>
000024B8 .ascii "Failed to retrieve email."<0>
000024D8 .ascii "Failed to retrieve codes."<0>
000024F8 .ascii "Gratz!"<0>
00002500 .ascii "Sorry may be next time..."<0>
Если предположить, что адрес загрузки равен
0x126F0-0x2490 == 0x10260, то все аргументы при вызове библиотечной функции будут точно указывать на строки, а сама неизвестная функция окажется функцией printf (или puts, что в данном случае не важно).После изменения базы загрузки код будет выглядеть примерно так:

Значение
0x0BA0BAB0, передаваемое в функцию sub_12194, также встречается в первой части задания, в функции fire_second_proc, и сравнивается с тем, что получается из read_pipe_u32(). Значит, sub_12194 должна называться write_pipe_u32.Аналогично, два вызова библиотечной функции
sub_24064 — это memset(someVar, 0, 0x101) для email и code, а sub_121BC — это read_pipe_str(), обратная write_pipe_str() из первой части.Самая первая функция (по смещению 0 или адресу
0x10260) имеет характерные константы, которые позволяют в ней безошибочно определить MD5_Init:
А рядом с тем местом, где к
MD5_Init идет единственное обращение, легко обнаружить функции MD5_Update() и MD5_Final (), перед которыми идет вызов библиотечной strlen().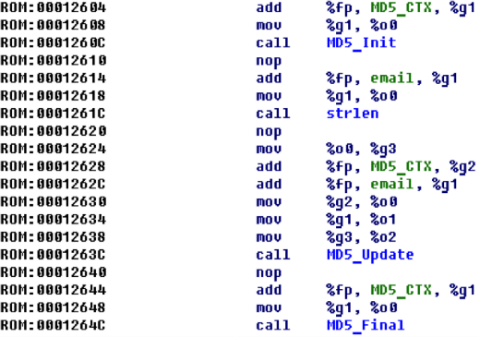
В функции
start() остается совсем немного неизвестных функций.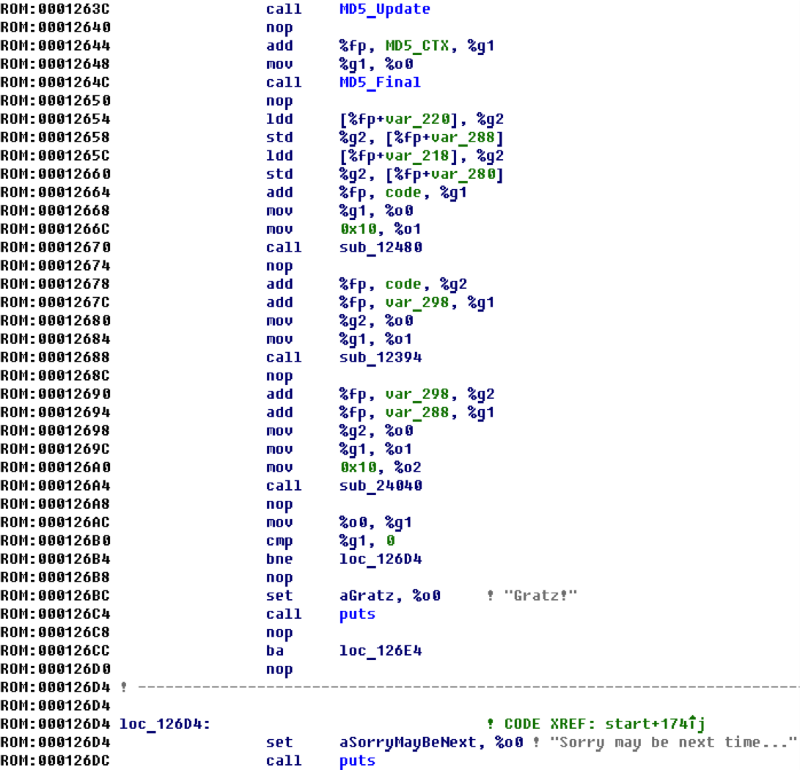
Функция
sub_12480 переворачивает байтовый массив заданной длины. Фактически, это memrev, на вход которой подается массив code длиной 16 байт.Очевидно, что в
sub_24040 принимается решение о том, правильный ли был код. При этом в аргументах передается указатель на вычисленное значение MD5(email), указатель на массив, заполненный в функции sub_12394, и число 16. Здесь вполне мог быть просто вызов memcmp!Основная магия выполняется в функции
sub_12394. Подсказок там почти никаких нет, зато сам алгоритм описывается одной фразой — перемножение двоичной матрицы размерности 128 на двоичный вектор размера 128. Матрица хранится в теле прошивки по адресу 0x240B8.Таким образом, код будет признан верным если
MD5(email) == matrix_mul_vector(matrix, code).Вычисление правильного ключа
Чтобы найти правильное значение code, надо решить систему двоичных уравнений, описываемую матрицей, когда в правой части стоят соответствующие биты из MD5(email). Если кто-то забыл линейную алгебру: это легко сделать методом Гаусса.
Когда известна правая часть ключа (32 шестнадцатеричных символа), надо подобрать первые 7 символов таким образом, чтобы результат вычисления CRC32 оказался равен найденному значению ключа для BTEA. Таких значений примерно 1024 штуки, и искать их можно как простым перебором (довольно быстро), так и обращая CRC32 и проверяя валидные символы (вообще моментально).
Остается собрать все вместе и получить ключ, который пройдет все проверки и будет признан нашим верификатором как валидный :)
Мы опасались, что задание окажется слишком сложным и никто не сможет его решить самостоятельно от начала и до конца. К счастью, Виктор Алюшин показал, что наши страхи были беспочвенными, за что ему огромное спасибо :) Его райтап с решением нашего конкурсного задания: nightsite.info/blog/16542-phdays-2015-best-reverser.html Напомним, Виктор побеждает в Best Reverser второй раз: он был лучшим в 2013 году.
Второе место, выполнив только часть задания, занял участник, попросивший не публиковать его имени.
Спасибо всем участникам конкурса!
Автор: Дмитрий Скляров, руководитель отдела анализа приложений Positive Technologies

mark_ablov
Веселое задание, как жаль, что я его не видел. Тем более SPARC мне знаком.
Как можно было узнать о нём?
PS: у необита тоже был реверс кода для sparc'ов. Правда, там уже совсем всё просто.