
На скорую руку попытался понять что это для бд и для клиента вообще:
- enum — статический упорядоченный набор значений
- Значение enum занимает на диске 4 байта
- Регистр имеет значение, т. е. 'happy' и 'HAPPY' — не одно и то же
- Разные enum сравнивать меж собой нельзя (можно, если привести к общему типу или запилить операторы для них)
- Невозможно в колонку перечисляемого типа подсунуть значение, которое отсутствует в самом перечислении
Ок, вроде всё как обычно, только в Postgres
У нас есть ряд таблиц, в которых статусы храним в текстовом виде для удобства чтения глазками
Интересу ради сделал фул вакуум одной из таких таблиц, создал её копию, но статусную колонку заменил на соответствующий enum, что получилось:
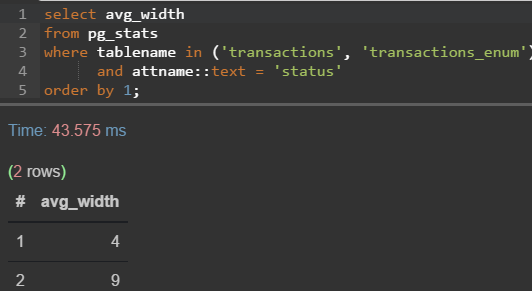
Тестовых данных у меня не много, потому разница не сильно заметна
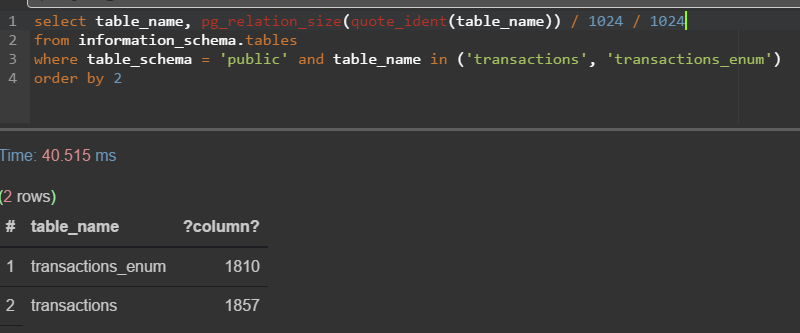
А вот на примере чуть большего объёма данных, но тоже тестовых данных
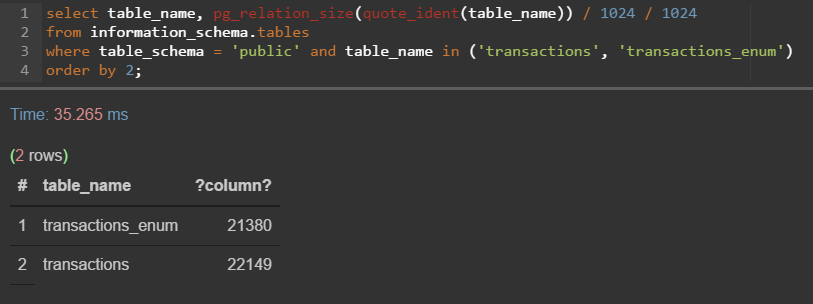
В любом случае — грубо почти 1 гигабайт экономии, а в проде это наверняка несколько гигов (пусть будет 2, но, конечно, больше)!
Допустим бекапы делаются ежедневно и хранятся 90 дней.
Enum уберёт 180 гигов лишних данных, не так плохо для микрооптимизации в несколько байт.
А в этой табличке аж 9 видов перечислений (их размеры пока не оценивал)
В самой выборке разницы нет (колонка status стала перечисляемого типа)
select date, contragentname, amount, currency, status
from transactions
where companyid = '208080cd-7426-430a-a5c8-a83f019da923'
limit 10;
select date, contragentname, amount, currency, status
from transactions_enum
where companyid = '208080cd-7426-430a-a5c8-a83f019da923'
limit 10;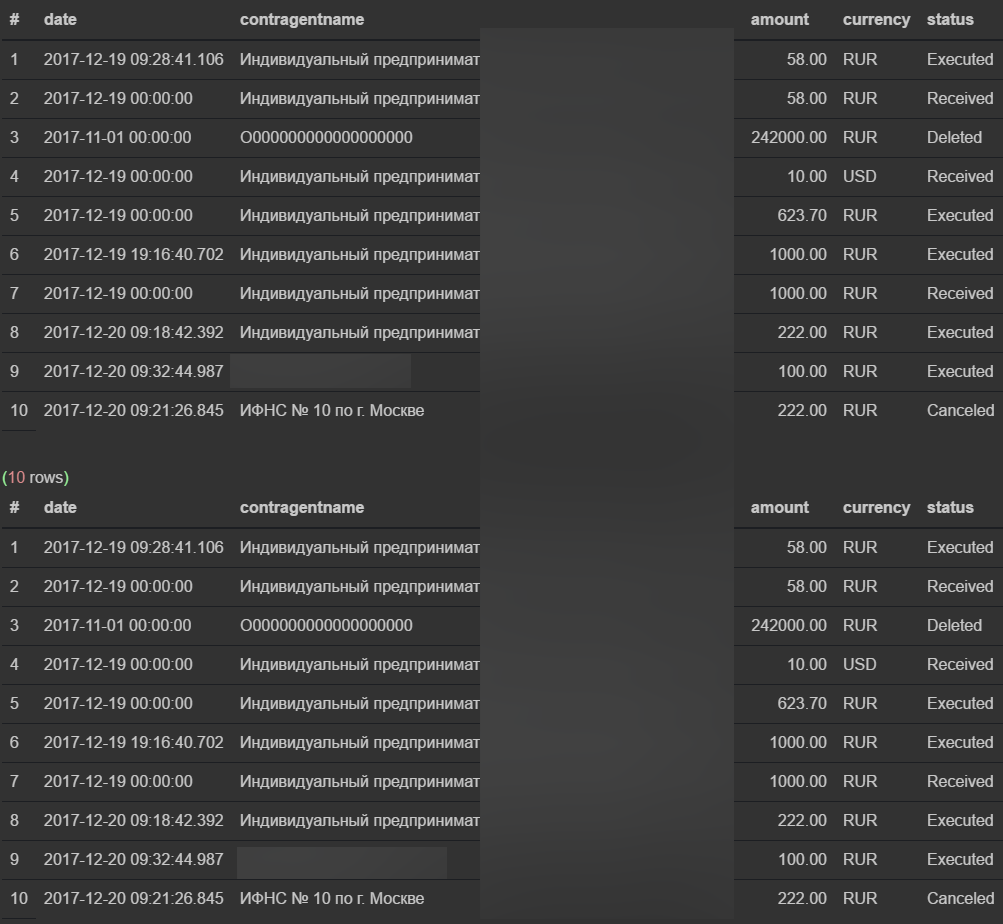
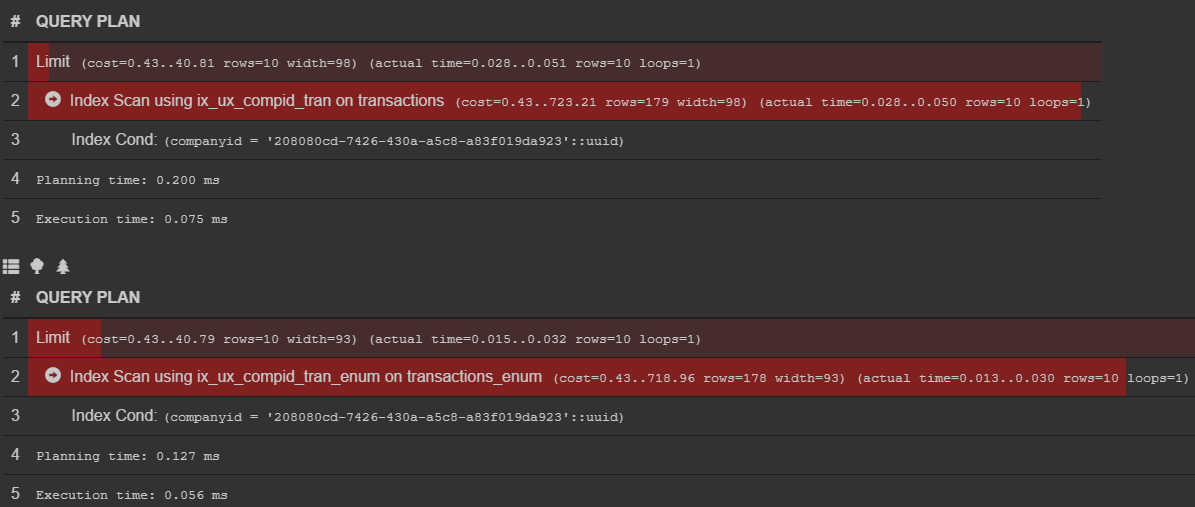
Обрати внимание на width в плане выполнения запроса
Код на чтение, при том, менять не приходится совсем (BLToolkit + Npgsql).
Но зависит это только от вашего кода, например у нас на беке .NET и соответствующие enum, а маппит данные BLToolkit, потому мы при отправке запроса на место enum полей подставляем что-то вроде
(CASE currency WHEN 'NAN' THEN 0 WHEN 'RUR' THEN 1 WHEN 'USD' THEN 2 WHEN 'EUR' THEN 3 WHEN 'CNY' THEN 4 ELSE 0 END) as currencyПотому с чтением проблем нет. А с записью следующая трабла:
error: column status is of type enum_transaction_status but expression is of type textТ.к. запрос формируется такой:
update transactions_enum set status = $1::text where id = $2Для тех кто не понял — явно указывается тип text.
Это очень просто обходится:
CREATE FUNCTION enum_transaction_status_from_str (text)
returns enum_transaction_status
AS 'select $1::varchar::enum_transaction_status'
-- дополнительное приведение к varchar, чтобы не допустить рекурсию
LANGUAGE SQL
IMMUTABLE
RETURNS NULL ON NULL INPUT;
-- создаётся приведение текста в перечисление
CREATE CAST (text AS enum_transaction_status)
WITH FUNCTION enum_transaction_status_from_str(text)
AS ASSIGNMENT;Писать case when..then… так себе идея, а с лёту сделать простое чтение не получилось и тут я решил, что BLToolkit это не хорошо и попробовал Dapper.
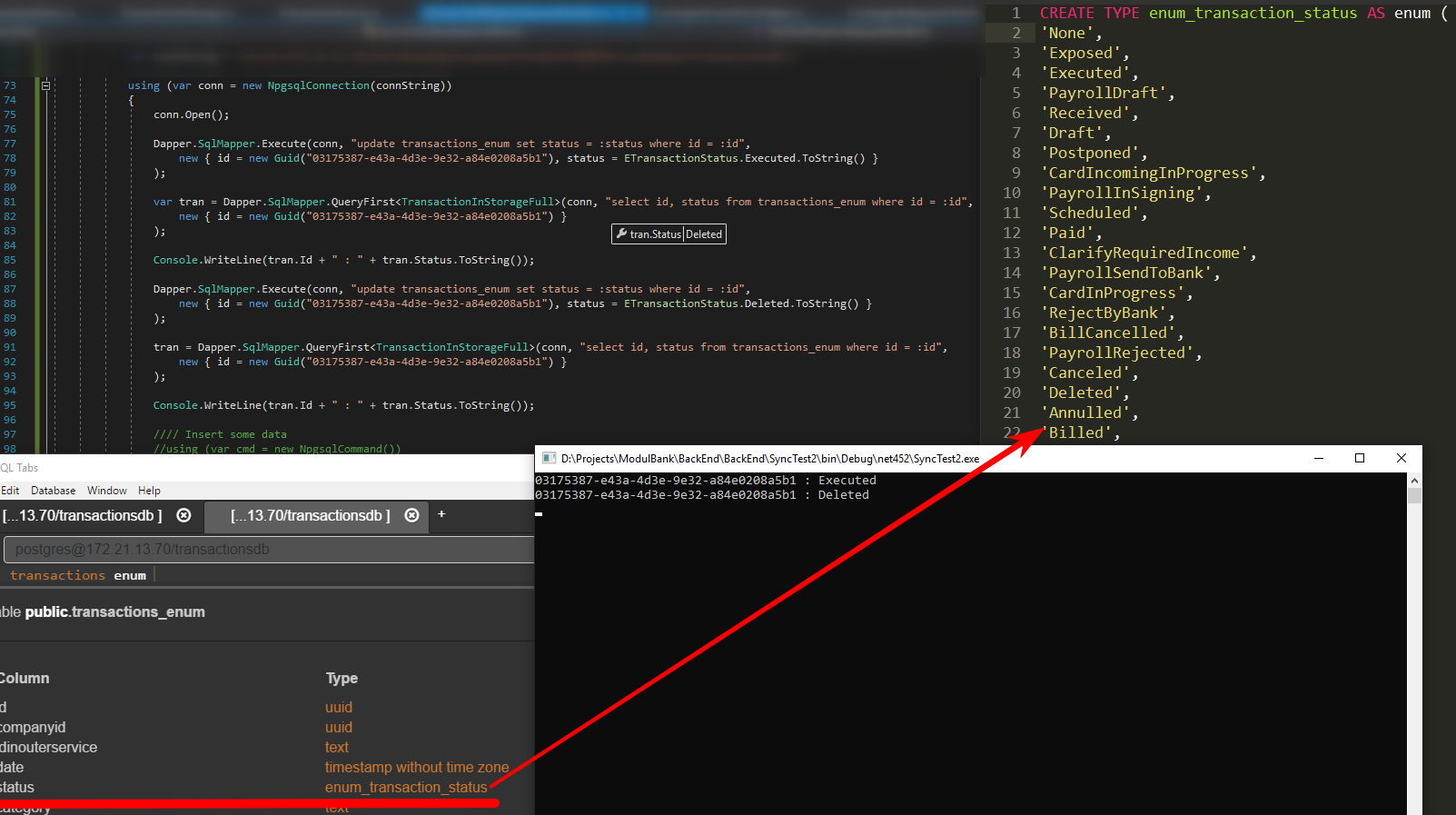
И без всякой магии и костылей, что хотел читать/писать — то и указал в запросе
using (var conn = new NpgsqlConnection(connString))
{
conn.Open();
Dapper.SqlMapper.Execute(conn,
"update transactions_enum set status = :status where id = :id",
new {
id,
status = ETransactionStatus.Executed.ToString()
}
);
var tran = Dapper.SqlMapper.QueryFirst<TransactionInStorageFull>(conn,
"select id, status from transactions_enum where id = :id",
new { id }
);
Console.WriteLine(tran.Id + " : " + tran.Status.ToString());
Dapper.SqlMapper.Execute(conn,
"update transactions_enum set status = :status where id = :id",
new {
id,
status = ETransactionStatus.Deleted.ToString()
}
);
tran = Dapper.SqlMapper.QueryFirst<TransactionInStorageFull>(conn,
"select id, status from transactions_enum where id = :id",
new { id }
);
Console.WriteLine(tran.Id + " : " + tran.Status.ToString());
}
Уже ясно, что enum это круто, потому предлагаю посмотреть, как с ним работать:
- Создание
CREATE TYPE e_contact_method AS ENUM ( 'Email', 'Sms', 'Phone') - Использование в таблице
CREATE TABLE contact_method_info ( contact_name text, contact_method e_contact_method, value text) - При вставке, обновлении, сравнении не нужно приводить строку к перечислению, достаточно, чтобы строка входила в перечисление (в противном случае — ошибка invalid input value for enum, что является большим плюсом, имхо)
INSERT INTO contact_method_info VALUES ('Jeff', 'Email', 'jeff@mail.com') - Просмотр всех возможных значений
select t.typname, e.enumlabel from pg_type t, pg_enum e where t.oid = e.enumtypid and typname = 'e_contact_method'; - Добавление новых значений
ALTER TYPE e_contact_method ADD VALUE 'Facebook' AFTER 'Phone'; - Изменение строки на enum в существующей таблице
ALTER TABLE transactions_enum ALTER COLUMN status TYPE enum_transaction_status USING status::text::enum_transaction_status;
Всё норм, только плюсы, а добавлять новые значения можно и нужно миграциями.
Немного ссылок:
- postgrespro.ru/docs/postgrespro/10/datatype-enum
- postgrespro.ru/docs/postgrespro/10/catalog-pg-enum
- postgrespro.ru/docs/postgrespro/10/functions-enum
- postgrespro.ru/docs/postgrespro/10/sql-createcast
- www.npgsql.org/doc/types/enums_and_composites.html
- 8 Reasons Why MySQL's ENUM Data Type Is Evil — не помешает также и критику послушать
Комментарии (25)

skymal4ik
15.04.2018 22:42Возможно, что-то не так понял, но можно ведь создать отдельную таблицу со статусами, связать их ключами, и сделать вьюху, если прямо хочется смотреть на данные глазками. И нормализация, и ещё меньше места должно занимать.

kalininmr
16.04.2018 00:24тут про немного другую задачу.
ваше предложение сродни тому, как вместо имен переменным давать просто номера, а имена хранить в отдельном словаре

voidnugget
16.04.2018 02:34но можно ведь создать отдельную таблицу со статусами
Если у вас меньше 100 статусов — overkill, так как, в случае с отдельной табличкой, будет храниться больше различных счётчиков для оптимистических/пессимистических блокировок, UNIQUE индекс и последовательность.
Нормализация нормализацией, но есть размеры структур СУБД, которые, как и законы физики, преодолеть без паранормальных способностей не представляется возможным.

LaXiTy
16.04.2018 05:58В своё время, в MySQL активно использовали тип enum, всем хорош: и места занимает, и контроль данных, и визуально сразу понятно, что за значение. Но стоит захотеть добавить или убрать значение, то надо делать ALTER TABLE, который на миллионах записях мог довольно долго выполняться.
Решили что проще делать использовать TINYINT и константы в коде. Если очень критично (или есть желание сделать правильно и красиво), то создаём отдельную таблицу-справочник и внешним ключом контролируем, что там может быть только то, что есть в справочнике.
SanSYS Автор
16.04.2018 05:59Хорошо, что у нас postgres
При добавлении нового значения проблем не заметил вообщеoxidmod
16.04.2018 08:43А при удалении на 500кк-1ккк записей?
SanSYS Автор
16.04.2018 09:19С тиниинтом проще было бы?
Вообще моветон менять прошлое, имхо
Мне из енамов пока не приходилось ничего удалять, но да, при обновлении большого количества строк, да ещё если в одном запросе, то проблемы будут, но зачем?oxidmod
16.04.2018 09:29+1Ну у меня был кейс, когда поменялся бизнес-флоу и статусы new / pending слились в один new.
Я был рад, что не использовал enumSanSYS Автор
17.04.2018 06:14Кстати, может будет интересно #PostgreSQL. Ускоряем деплой в семь раз с помощью «многопоточки»
если коротко — как чуваки делают большие update — ранжируют данные на логические части, допустим через ntile, и обновляют частями
как пример — 50к обновлений по 10 тыс. строк — незаметны локи совсем, и… это быстро, т.к. не в одном запросе, а в несколько
и многопоточку сделали на гошечке (реально, в нём из коробки таки это удобно)
короч имейте в виду
Sioln
16.04.2018 15:25+1Невозможно в колонку перечисляемого типа подсунуть значение, которое отсутствует в самом перечислении
Enum же бывает флаговый.
Типа
Black=1,
White=2,
Yellow=4
И потом в коде используется значение Black and White = 3 и плюсом к этому удобно работать потом с данными через битовые операторы.
SanSYS Автор
16.04.2018 17:13Спасибо, очень дельное замечание!
У нас есть пара мест с подобным применением
И колонки, естественно, числовые
Конечно можно заюзать массив… строк, енамов (не пробовал), гуидов, но… это уже будет не так удобно, как просто число
Ice2burn
16.04.2018 17:14Не поделитесь, каким инструментарием пользуетесь для работы с postgres? Это SQL Tabs у вас на скриншоте 4 и 5?
SanSYS Автор
16.04.2018 17:22SQL Tabs v0.18.0 — посмотрите, что он умеет. Как правило его юзаю для написания запросов, когда нужно именно писать запросы, смотреть план, исполнять несколько запросов разом
pgAdmin 1.22.2 — когда хочется просто мышкой покликать (типа топ 100, фильтрануть по значению из колонки..)
dbForge Studio for PostgreSQL — есть бесплатная версия, плохо дружит с таблицами/колонками «в кавычках».
Просто пробую всё новое иногда, так у меня не остались — navicat, DataGrip, pgAdmin 4Ice2burn
17.04.2018 12:33pgAdmin 3 (pgAdmin 1.22.2) очень доволен, стабильнее и быстрее pgAdmin 4. pgAdmin 4 способен привести к взаимоблокировке при выполнении простых скриптов, перемудрили с многопоточностью. А вот что пока не удаётся найти, так это адекватный дебаггер.
Есть, кстати, интересный проект для поиска ошибок в хранимках и триггерах: plpgsql_check
mgremlin
16.04.2018 18:34Лучше всего — psql :-)
если про красивые картинки — остановился на DBeaver Community в итоге.SanSYS Автор
16.04.2018 19:26psql, я уж спецом его не написал ))
по поводу DBeaver пока только минусы:
1. слишком монструозен
2. требует яву! Ну не было её у меня до этого
3. чтобы качнуть дрова для оракла — потребовалась рега на oracle.com (хотя для пг не запросил и скачал молча)
4. Коннектит именно к БД, т.е. с лёту не увидел, как именно получить список всех бд в дереве объектов
Хотя… есть плюсик — всё же комьюнити версия бесплатна и очень мне помогла в коннекте к продовской чужой бдaleksandy
16.04.2018 22:13слишком монструозен
Эта монструозность проявляется только на старте.
требует яву!
Есть дистрибутивы с предустановленной jre, тупо распаковать архив и запустить.
потребовалась рега на oracle.com
Это не вина бобра. Ораклового драйвера нет в публичных репозиториях.
Коннектит именно к БД
Опять же это ограничение не бобровое. It is not possible to access more than one database per connection.
Можно использовать галочку «Show non-default databases» диалоге настройки соединения, чтобы видеть все имеющиеся БД на сервере. А также «Switch default database on access» для переподключения к другой базе при необходимости. Но проще настроить несколько подключений к разным БД.
mgremlin
17.04.2018 18:42Монструозен? Странно — для меня это почти стоп-фактор по жизни, но тут я этого не заметил/замечаю. ява — это большой минус, согласен.
Дрова для Оракла? У меня ничего такого не было нужно. Или имеется в виду коннектор к ДБ?
Список дб получить нетрудно в psql :-)SanSYS Автор
17.04.2018 18:56Да, должно быть это был коннектор, я не уверен в верности терминологии в данной ситуации
aleksandy
17.04.2018 21:00я этого не заметил/замечаю
Не соглашусь, этого сложно просто не заметить. Не обращать внимания — да, но не замечать невозможно. Не будете же спорить, что запускается бобёр куда как медленнее, нежели pgadmin, например.
Дрова для Оракла? У меня ничего такого не было нужно.
Имелся ввиду jdbc-драйвер.mgremlin
17.04.2018 21:19Специально засек: меньше 10 секунд. Учитывая, что я не перегружаюсь неделями — меня это вполне устраивает. pgadmin мне понравился меньше, прежде всего возможностями работы с результатами запроса. Еще я часто подключаюсь к mysql и maria тоже. И pgadmin у меня постоянно вылетал.
Но, еще раз, лучший клиент — в консоли. Еще бы там редактировать полегче было…
VolCh
Лично мне излишним в своё время при миграции с MySQL показалось не сами перечисления как таковые (в мускуле они как раз были), а обход строгой типизации постгри тем или иным способом. На уровне ORM просто не получилось, а лезть в «хранимки» очень не хотелось, собственно одна из целей перехода на постгри было избавление от них.