
Взлет интереса к машинному обучению во многом связан с тем, что модели способны дать ощутимый прирост прибыли в областях, связанных с предсказанием поведения сложных систем. В частности, той сложной системой, чье поведение предсказывать выгодно, является человек. Обнаружить мошенничество на ранней стадии, выявить склонность клиентов к оттоку – эти задачи возникают регулярно и уже стали классическими в Data Science. Безусловно, их можно решать различными методами, в зависимости от пристрастий конкретного специалиста и от требований бизнеса.
У нас была возможность использовать нейронные сети для решения задачи по предсказанию поведения людей, а специфика области применения была связана с индустрией красоты. Основной аудиторией для “опытов” стали женщины. Мы по сути пришли к вопросу: может ли искусственная нейронная сеть понять настоящую нейронную сеть (человека) в той области, в которой даже сам человек еще не осознал своего поведения. Как мы ответили на этот вопрос и что у нас получилось в итоге, можно узнать далее.

Британское маркетинговое агентство предложило нашей команде оптимизировать маркетинговые коммуникации для нескольких брендов из бьюти-индустрии. Для решения этой задачи нам пришлось проводить штурм покупателей с разных сторон. В итоге мы построили ряд предсказательных и рекомендательных моделей, помогающих находить индивидуальный подход к каждому из покупателей. Попутно мы решили несколько важных для бизнеса моментов, и его ключевые KPI подросли.
Любому ритейлеру хочется повысить свои продажи. Для этого нам надо предложить товары, которые клиент купит с наибольшей вероятностью, с помощью наиболее оптимального канала коммуникации и сделать это в подходящий момент. Таким образом, в первую очередь магазину нужна рекомендательная система, а также систематическая оркестровка каналов и несколько предсказательных моделей. Такую AI-задачу взяли мы, CleverDATA, по заказу агентства Beauty Brains.

В арсенале брендов была история покупок клиентов, история посещения клиентами сайта, а также информация о рассылках и реакции на рассылки со стороны каждого получателя. Таким образом, мы могли посмотреть, какие рассылки клиент получал, какие из них открывал, по каким ссылкам ходил и к чему это привело.
Для начала мы сделали рекомендательную систему, используя классические методы: разложение матриц, коллаборативную фильтрацию, ассоциативные правила и т. д. Потом решили поэкспериментировать, можно ли сделать что-то более эффективное для нашего конкретного случая, и пришли к рекомендательной системе на нейронных сетях.
Преимуществом новой экспериментальной системы стало то, что использовалась, во-первых, дополнительная информация о продуктах из их текстовых описаний, и во-вторых, учитывалась последовательность покупок клиентов.
Далее мы стали подключать различные каналы коммуникаций: в первую очередь, почтовую рассылку, которая является одним из самым дешевых каналов. Кроме того, адресатам стали доставляться сообщения в Facebook и реклама через Adwords.
В итоге мы подготовили для маркетологов заказчика self-driving решение, которое представляет собой ежедневный набор рассылок высокой степени персонализации. Естественно, количество кампаний ощутимо выросло, а численность получателей каждой из них драматически уменьшилась. То есть мы предоставили маркетологу в качестве инструмента множество “микрокампаний”, где каждый конкретный покупатель получает предложение с наиболее релевантным товаром на индивидуальных условиях (с персональной скидкой, подарками, пробниками, если последние интересуют покупателя и т.п.).
Кроме того, у нас в распоряжении было знание, полученное при анализе большого массива бьюти-блогов. О результатах анализа этого корпуса я уже подробно писал на Хабре.
Разумеется, в рассылках используются LTV-прогнозирование, предсказание оттока, расчет лояльности, предсказание подходящей скидки, а также предсказание восприимчивости клиента к подаркам и пробникам. Чем больше вероятность, что клиент скоро совершит покупку, тем меньшую скидку он получает. А если покупок давно не было, человек попадает в группу клиентов, которых бренд рискует потерять, скидки для него увеличиваются.
Тестирование системы проводилось в течение сентября-декабря 2017 года, в результате проект был признан успешным. Далее я рассмотрю конкретный случай, который нам пришлось решать в рамках проекта.
 Источник
Источник
Количество людей, подписанных на рассылку, обычно значительно больше числа покупателей. Естественно, есть и группа адресатов, в которой вероятность первой покупки повышена. На этих людей можно нацелить дополнительные рекламные кампании, однако запускать дополнительные кампании на всей базе контактов мы не можем, поскольку они требуют дополнительного бюджета.
Т.е. нам необходимо предсказать поведение людей и запускать кампании только на узкой целевой аудитории. Дополнительной информации об этих потенциальных клиентах нет, бренд знает только, как они открывали письма и по каким ссылкам переходили. Поэтому мы пришли к задаче научить машину понимать поведение людей.
Эту задачу возможно решить множеством способов. Мы пошли по направлению нейронных сетей.
Итак, мы будем работать с последовательностью действий получателя рассылки,
а для обработки серии событий хорошо подходят рекуррентные нейронные сети (часто их используют для обработки текстов). Про это семейство уже многократно писалось на Хабре (например, здесь или здесь). Рекуррентные нейронные сети в их классической реализации обладают рядом характерных проблем, например, они быстро забывают. Если мы будем тренировать классическую рекуррентную нейронную сеть на книге, то к середине главы она забудет, с чего эта глава начиналась.
Сегодня широкое распространение получили LSTM-нейронные сети, которым удалось преодолеть многие проблемы классических нейронных сетей. LSTM нейронные сети обладают памятью: они оперируют ячейками, которые могут запоминать, воспроизводить и забывать информацию. Кроме того, LTSM-сети хороши в тех случаях, когда события разделены временными лагами с неопределенной продолжительностью и границами.
 Источник
Источник
В принципе, можно тренировать LSTM-нейронную сеть на результате действий получателей рассылки, но такая модель будет хорошо справляться только с одним типом поведения, а признаки, полученные из такой модели, будет сложно интерпретировать и еще сложнее использовать в других моделях, не заглядывая ненароком в будущее: если мы тренируем модель на конкретном целевом действии, то эта модель должна обладать информацией о будущем, — совершит ли человек в будущем целевое действие будет известно модели на тренировочной выборке объектов тренировки.
Если мы результат работы модели планируем использовать в других моделях, то необходимо очень тщательно следить за тем, чтобы информация о будущем не перешла вместе с предсказаниями модели. Если непреднамеренно случится перетекание информации о будущем, то новая модель будет переобучаться. Поэтому для последующего использования будет удобнее тренироваться на событиях, не зная их результата, и сводить последовательность событий в признаки, которые потом можно было бы использовать в других предсказательных моделях. И в этом нам способен помочь автоэнкодер, или автокодировщик.
Про автоэнкодеры на Хабре тоже можно почитать, например здесь и здесь. Они построены так, что имеют одинаковую размерность на входе и выходе, а размерность в середине значительно меньше. Такое ограничение заставляет нейронную сеть искать обобщения и корреляции в последовательности событий, поэтому автокодировщики вынуждены как-то обобщать входящие данные.
В тренировке такой сети используется принцип обратного распространения ошибки, как в обучении с учителем, однако мы можем требовать, чтобы сигнал на входе и сигнал на выходе сети были максимально близкими. В итоге мы будем тренироваться, не используя информацию о результате, к которому привела последовательность действий, т.е. получится обучение без учителя.
 Источник. Автокодировщик способен эффективно уменьшать размерность пространства признаков: чем меньше размерность “бутылочного горлышка”, тем сильнее сжатие, но тем выше потери информации.
Источник. Автокодировщик способен эффективно уменьшать размерность пространства признаков: чем меньше размерность “бутылочного горлышка”, тем сильнее сжатие, но тем выше потери информации.
Общая структура нашей нейронной сети понятна: это будет автоэнкодер, использующий LSTM-ячейки. Осталось решить, как закодировать последовательность действий потенциального покупателя. Одним из вариантов является one-hot-encoding: действие кодируется единицей, остальные альтернативы действия — нулем.

Первая проблема, которая здесь возникает, — путь, который проходят люди от получения маркетинговой рассылки до покупки на сайте, различный по длине. С ней легко справиться: возьмем фиксированную длину последовательности векторов, лишнее отбросим, недостающее заполним нулями. Сеть быстро учится понимать, что на лишние нули в начале последовательности событий не надо обращать внимание.

А теперь стоит задуматься о том, что разным людям требуется разное время, чтобы, получив письмо, пройти по ссылкам и сделать покупку. Время играет немалую роль в понимании поведения человека. Как учесть время в последовательности действий клиента? Мы добавили временную разницу между событиями в качестве дополнительного элемента вектора, кодирующего действия получателя.

Если разница между событиями в секундах, то в некоторых случаях у временной компоненты вектора значения будут достигать 103-106, что негативно скажется на тренировке сети. Более удачным решением будет использование логарифма временной разницы между событиями. Для успешной тренировки нейронной сети рекомендуется работать с числами в диапазоне от нуля до единицы, поэтому еще лучше нормировать логарифм разницы во времени и добавить его в качестве еще одного элемента вектора действия получателя. Временную разницу для последнего события можно брать в виде разницы между последним событием и текущим моментом времени.
На одном из брендов мы получили датасет из нескольких тысяч компаний, рассылаемых на ~ 200 000 человек. Таким образом, тренировочная выборка состояла из примерно 200 000 векторов, кодирующих последовательность действий получателей рассылки.
В начале кодировщика ставим слой LSTM-ячеек, который будет переводить серию событий в вектор, содержащий информацию обо всей последовательности. Можно сделать ряд последовательных LSTM-слоев, постепенно уменьшая их размерность. Чтобы вернуть представление от вектора к последовательности событий, повторим этот вектор n раз перед тем, как подать его на вход LSTM-слоя декодера. Общая схема такого автокодировщика на keras будет занимать буквально несколько строк и приведена ниже. Обратите внимание на то, что LSTM-слой декодера должен возвращать не вектор, а последовательность, что указывается посредством параметра return_sequences=True.
Если ничего не напутать с размерностями тензоров, то сеть будет тренироваться. В дальнейшем для повышения качества модели мы добавили несколько дополнительных LSTM-слоев как в кодировщик, так и в декодировщик, а в качестве “бутылочного горлышка” использовали несколько обычных полносвязных слоев нейронов, естественно, не забывая про Dropout, Batch Normalization и другие приемы для тренировки нейронных сетей.
Для сравнения мы попробовали обучить актокодировщик на сверточных нейронных сетях (Сonvolution Neural Networks, CNN) на том же наборе данных. Сверточные слои помогают установить паттерны поведения объектов и позволяют сократить количество параметров модели, что ощутимо ускоряет обучение. Про сверточные нейронные сети тоже есть статьи на Хабре (здесь, здесь и, например, здесь), поэтому мы не будем останавливаться на них подробно. Схематично архитектура автокодировщика на сверточных нейронных сетях выглядит следующим образом:
Т.к. элементы тензоров принимают значения в диапазоне от 0 до 1, то можно воспользоваться функцией потерь перекрёстной энтропии (binary crossentropy).
Результат обучения автокодировщика на CNN по метрике качества оказался даже выше, чем автокодировщика на LSTM, а время обучения заметно быстрее.
Кроме того, возможно сделать автокодировщик на CNN и LSTM: сначала несколько сверточных слоев, затем автокодировщик на основе LSTM, завершающийся декодировщиком на основе сверточных слоев. Такой автокодировщик будет объединять положительные стороны обоих подходов. По нашему опыту, такой автокодировщик незначительно лучше автококодировщика на CNN и значительно лучше автокодировщика на LSTM по метрикам качества на валидационной выборке.
После тренировки кодировщик переводит последовательность действий для каждого получателя в вектор признаков, и таким образом мы получаем аналог word2vec для серии событий. Полученный вектор возможно использовать в других предиктивных моделях, кластеризации, в поиске близких по поведению людей, а также выполнять поиск аномалий.
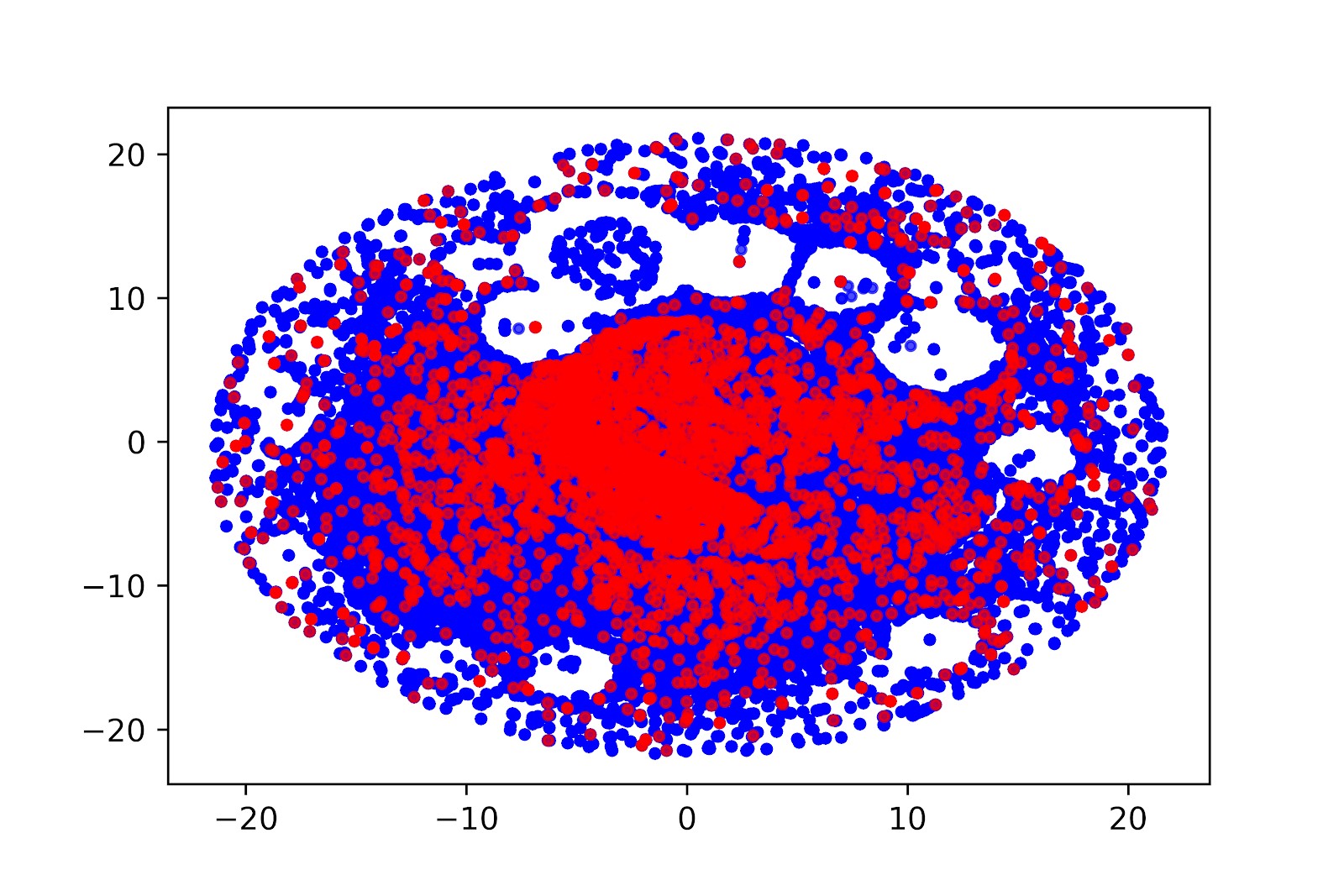 Проекция на двухмерное пространство векторов поведения получателей писем, полученных с помощью автокодировщика (t-SNE). Красные точки — получатели, совершившие покупку в ближайшем будущем, синие точки — получатели, не совершившие покупку. Видно, что есть области, в которых преобладают инертные получатели, и есть области с высокой концентрацией будущих покупателей.
Проекция на двухмерное пространство векторов поведения получателей писем, полученных с помощью автокодировщика (t-SNE). Красные точки — получатели, совершившие покупку в ближайшем будущем, синие точки — получатели, не совершившие покупку. Видно, что есть области, в которых преобладают инертные получатели, и есть области с высокой концентрацией будущих покупателей.
В нашем случае мы строили модель, предсказывающую вероятность покупки получателя письма. Модель на ряде основных признаках давала roc-auc 0.74-0.77, а с добавленными векторами, отвечающими за поведение человека, roc-auc достигал 0.84-0.88.
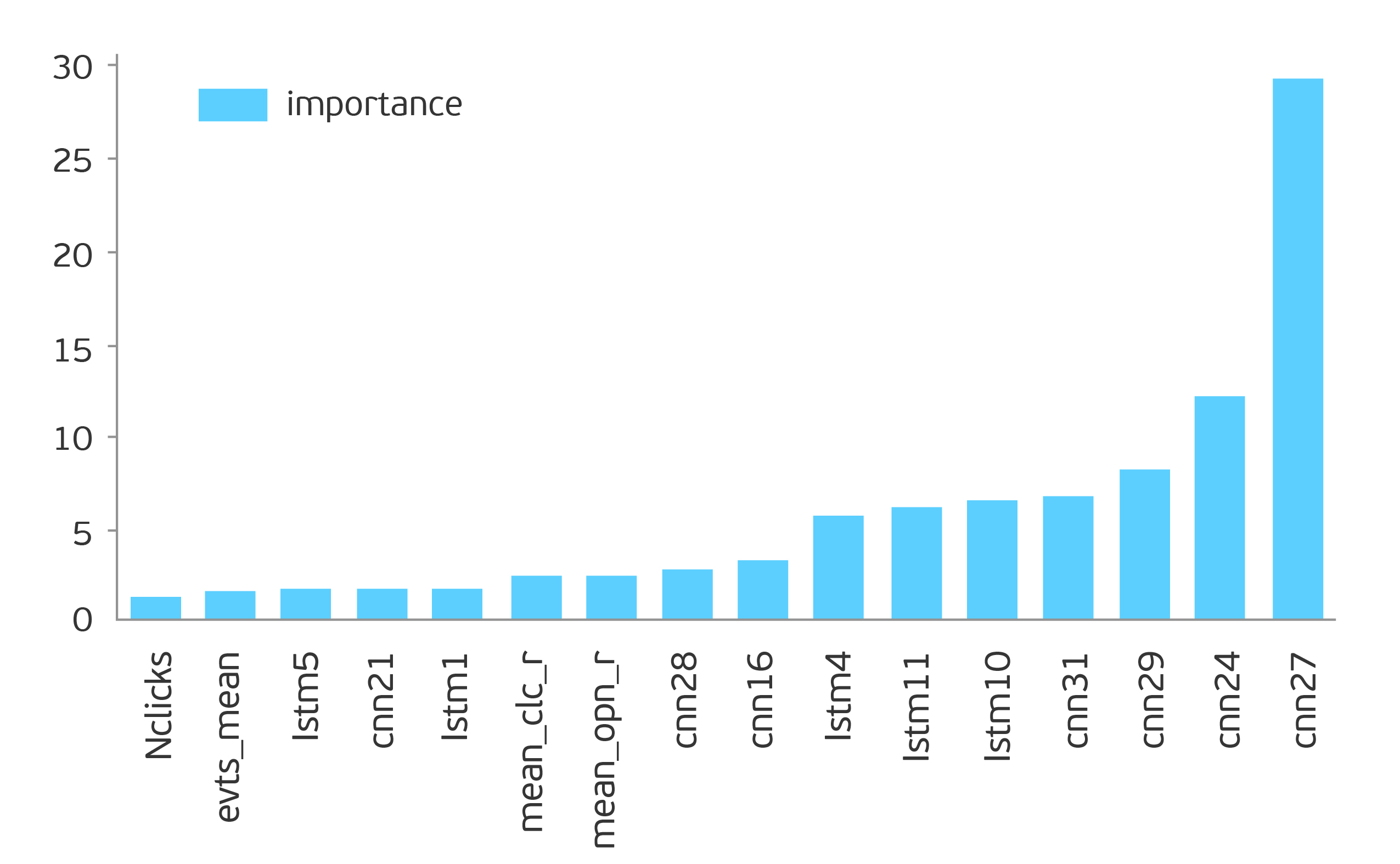 В списке наиболее значимых признаков доминирующее положение занимают признаки от двух автокодировщиков: на основе LSTM и CNN.
В списке наиболее значимых признаков доминирующее положение занимают признаки от двух автокодировщиков: на основе LSTM и CNN.
Необходимо признать, что использование автокодировщика на основе CNN для данной задачи давало более качественный результат, однако автокодировщик на основе LSTM давал вектора меньшей размерности и позволил немного дополнительно подтянуть roc-auc. Если использовать признаки на основе автокодировщика СNN + LSTM, то roc-auc получается в диапазоне 0.82-0.87.
 Сравнение ROC кривых двух моделей: roc-auc модели на основных признаках 0.74-0.77, roc-auc модели на основных признаках и признаках автокодировщика 0.84-0.88.
Сравнение ROC кривых двух моделей: roc-auc модели на основных признаках 0.74-0.77, roc-auc модели на основных признаках и признаках автокодировщика 0.84-0.88.
Наш опыт подтвердил тот факт, что поведение людей возможно закодировать посредством автокодировщика на нейронных сетях: в нашем случае последовательность поведения получателей рассылки были закодированы с помощью автокодировщиков на LSTM и на CNN-архитектурах. Рассылкой писем применение этого подхода не ограничено: закодированное поведение объектов можно использовать в других задачах, требующих работы с поведением человека: поиск мошеннических действий, предсказания оттока, поиск аномалий и т.д.
Предложенный подход можно развивать в сторону вариационных автокодировщиков, если в этом есть потребность в моделировании поведения людей.
Тот факт, что автокодировщик на основе CNN с рассмотренной задачей справляется лучше, чем на LSTM, дает возможность предположить, что паттерны поведения позволяют для данной задачи извлечь более информативные признаки, чем признаки на основе временных связей между событиями. Тем не менее, на подготовленном наборе данных есть возможность использовать оба подхода, и суммарный эффект от совместного использования признаков обоих автокодировщиков дает прирост к roc-auc на 0.01-0.02.
Таким образом, нейронные сети в состоянии понять по поведению человека, что он склонен к покупке, возможно даже до того, как сам человек это осознает. Удивительный пример фрактальности нашего мира: нейроны людей помогают организовать тренировку нейронных сетей с целью предсказать результат работы нейронов других людей.

У нас была возможность использовать нейронные сети для решения задачи по предсказанию поведения людей, а специфика области применения была связана с индустрией красоты. Основной аудиторией для “опытов” стали женщины. Мы по сути пришли к вопросу: может ли искусственная нейронная сеть понять настоящую нейронную сеть (человека) в той области, в которой даже сам человек еще не осознал своего поведения. Как мы ответили на этот вопрос и что у нас получилось в итоге, можно узнать далее.
Британское маркетинговое агентство предложило нашей команде оптимизировать маркетинговые коммуникации для нескольких брендов из бьюти-индустрии. Для решения этой задачи нам пришлось проводить штурм покупателей с разных сторон. В итоге мы построили ряд предсказательных и рекомендательных моделей, помогающих находить индивидуальный подход к каждому из покупателей. Попутно мы решили несколько важных для бизнеса моментов, и его ключевые KPI подросли.
Вместо массированных бомбардировок рекламой применяем точечные персонализированные предложения
Любому ритейлеру хочется повысить свои продажи. Для этого нам надо предложить товары, которые клиент купит с наибольшей вероятностью, с помощью наиболее оптимального канала коммуникации и сделать это в подходящий момент. Таким образом, в первую очередь магазину нужна рекомендательная система, а также систематическая оркестровка каналов и несколько предсказательных моделей. Такую AI-задачу взяли мы, CleverDATA, по заказу агентства Beauty Brains.
В арсенале брендов была история покупок клиентов, история посещения клиентами сайта, а также информация о рассылках и реакции на рассылки со стороны каждого получателя. Таким образом, мы могли посмотреть, какие рассылки клиент получал, какие из них открывал, по каким ссылкам ходил и к чему это привело.
Для начала мы сделали рекомендательную систему, используя классические методы: разложение матриц, коллаборативную фильтрацию, ассоциативные правила и т. д. Потом решили поэкспериментировать, можно ли сделать что-то более эффективное для нашего конкретного случая, и пришли к рекомендательной системе на нейронных сетях.
Преимуществом новой экспериментальной системы стало то, что использовалась, во-первых, дополнительная информация о продуктах из их текстовых описаний, и во-вторых, учитывалась последовательность покупок клиентов.
Далее мы стали подключать различные каналы коммуникаций: в первую очередь, почтовую рассылку, которая является одним из самым дешевых каналов. Кроме того, адресатам стали доставляться сообщения в Facebook и реклама через Adwords.
В итоге мы подготовили для маркетологов заказчика self-driving решение, которое представляет собой ежедневный набор рассылок высокой степени персонализации. Естественно, количество кампаний ощутимо выросло, а численность получателей каждой из них драматически уменьшилась. То есть мы предоставили маркетологу в качестве инструмента множество “микрокампаний”, где каждый конкретный покупатель получает предложение с наиболее релевантным товаром на индивидуальных условиях (с персональной скидкой, подарками, пробниками, если последние интересуют покупателя и т.п.).
Кроме того, у нас в распоряжении было знание, полученное при анализе большого массива бьюти-блогов. О результатах анализа этого корпуса я уже подробно писал на Хабре.
Разумеется, в рассылках используются LTV-прогнозирование, предсказание оттока, расчет лояльности, предсказание подходящей скидки, а также предсказание восприимчивости клиента к подаркам и пробникам. Чем больше вероятность, что клиент скоро совершит покупку, тем меньшую скидку он получает. А если покупок давно не было, человек попадает в группу клиентов, которых бренд рискует потерять, скидки для него увеличиваются.
Тестирование системы проводилось в течение сентября-декабря 2017 года, в результате проект был признан успешным. Далее я рассмотрю конкретный случай, который нам пришлось решать в рамках проекта.
Учим сети понимать людей. Какие инструменты выбрать?
{kind=link}
Количество людей, подписанных на рассылку, обычно значительно больше числа покупателей. Естественно, есть и группа адресатов, в которой вероятность первой покупки повышена. На этих людей можно нацелить дополнительные рекламные кампании, однако запускать дополнительные кампании на всей базе контактов мы не можем, поскольку они требуют дополнительного бюджета.
Т.е. нам необходимо предсказать поведение людей и запускать кампании только на узкой целевой аудитории. Дополнительной информации об этих потенциальных клиентах нет, бренд знает только, как они открывали письма и по каким ссылкам переходили. Поэтому мы пришли к задаче научить машину понимать поведение людей.
Эту задачу возможно решить множеством способов. Мы пошли по направлению нейронных сетей.
Итак, мы будем работать с последовательностью действий получателя рассылки,
а для обработки серии событий хорошо подходят рекуррентные нейронные сети (часто их используют для обработки текстов). Про это семейство уже многократно писалось на Хабре (например, здесь или здесь). Рекуррентные нейронные сети в их классической реализации обладают рядом характерных проблем, например, они быстро забывают. Если мы будем тренировать классическую рекуррентную нейронную сеть на книге, то к середине главы она забудет, с чего эта глава начиналась.
Сегодня широкое распространение получили LSTM-нейронные сети, которым удалось преодолеть многие проблемы классических нейронных сетей. LSTM нейронные сети обладают памятью: они оперируют ячейками, которые могут запоминать, воспроизводить и забывать информацию. Кроме того, LTSM-сети хороши в тех случаях, когда события разделены временными лагами с неопределенной продолжительностью и границами.
{kind=link}
В принципе, можно тренировать LSTM-нейронную сеть на результате действий получателей рассылки, но такая модель будет хорошо справляться только с одним типом поведения, а признаки, полученные из такой модели, будет сложно интерпретировать и еще сложнее использовать в других моделях, не заглядывая ненароком в будущее: если мы тренируем модель на конкретном целевом действии, то эта модель должна обладать информацией о будущем, — совершит ли человек в будущем целевое действие будет известно модели на тренировочной выборке объектов тренировки.
Если мы результат работы модели планируем использовать в других моделях, то необходимо очень тщательно следить за тем, чтобы информация о будущем не перешла вместе с предсказаниями модели. Если непреднамеренно случится перетекание информации о будущем, то новая модель будет переобучаться. Поэтому для последующего использования будет удобнее тренироваться на событиях, не зная их результата, и сводить последовательность событий в признаки, которые потом можно было бы использовать в других предсказательных моделях. И в этом нам способен помочь автоэнкодер, или автокодировщик.
Про автоэнкодеры на Хабре тоже можно почитать, например здесь и здесь. Они построены так, что имеют одинаковую размерность на входе и выходе, а размерность в середине значительно меньше. Такое ограничение заставляет нейронную сеть искать обобщения и корреляции в последовательности событий, поэтому автокодировщики вынуждены как-то обобщать входящие данные.
В тренировке такой сети используется принцип обратного распространения ошибки, как в обучении с учителем, однако мы можем требовать, чтобы сигнал на входе и сигнал на выходе сети были максимально близкими. В итоге мы будем тренироваться, не используя информацию о результате, к которому привела последовательность действий, т.е. получится обучение без учителя.
Общая структура нашей нейронной сети понятна: это будет автоэнкодер, использующий LSTM-ячейки. Осталось решить, как закодировать последовательность действий потенциального покупателя. Одним из вариантов является one-hot-encoding: действие кодируется единицей, остальные альтернативы действия — нулем.
Первая проблема, которая здесь возникает, — путь, который проходят люди от получения маркетинговой рассылки до покупки на сайте, различный по длине. С ней легко справиться: возьмем фиксированную длину последовательности векторов, лишнее отбросим, недостающее заполним нулями. Сеть быстро учится понимать, что на лишние нули в начале последовательности событий не надо обращать внимание.
А теперь стоит задуматься о том, что разным людям требуется разное время, чтобы, получив письмо, пройти по ссылкам и сделать покупку. Время играет немалую роль в понимании поведения человека. Как учесть время в последовательности действий клиента? Мы добавили временную разницу между событиями в качестве дополнительного элемента вектора, кодирующего действия получателя.
Если разница между событиями в секундах, то в некоторых случаях у временной компоненты вектора значения будут достигать 103-106, что негативно скажется на тренировке сети. Более удачным решением будет использование логарифма временной разницы между событиями. Для успешной тренировки нейронной сети рекомендуется работать с числами в диапазоне от нуля до единицы, поэтому еще лучше нормировать логарифм разницы во времени и добавить его в качестве еще одного элемента вектора действия получателя. Временную разницу для последнего события можно брать в виде разницы между последним событием и текущим моментом времени.
На одном из брендов мы получили датасет из нескольких тысяч компаний, рассылаемых на ~ 200 000 человек. Таким образом, тренировочная выборка состояла из примерно 200 000 векторов, кодирующих последовательность действий получателей рассылки.
От теории к практике
В начале кодировщика ставим слой LSTM-ячеек, который будет переводить серию событий в вектор, содержащий информацию обо всей последовательности. Можно сделать ряд последовательных LSTM-слоев, постепенно уменьшая их размерность. Чтобы вернуть представление от вектора к последовательности событий, повторим этот вектор n раз перед тем, как подать его на вход LSTM-слоя декодера. Общая схема такого автокодировщика на keras будет занимать буквально несколько строк и приведена ниже. Обратите внимание на то, что LSTM-слой декодера должен возвращать не вектор, а последовательность, что указывается посредством параметра return_sequences=True.
from keras.layers import Input, LSTM, RepeatVector
from keras.models import Model
inputs = Input(shape=(timesteps, input_dim))
encoded = LSTM(latent_dim)(inputs)
decoded = RepeatVector(timesteps)(encoded)
decoded = LSTM(input_dim, return_sequences=True)(decoded)
sequence_autoencoder = Model(inputs, decoded)
encoder = Model(inputs, encoded)Если ничего не напутать с размерностями тензоров, то сеть будет тренироваться. В дальнейшем для повышения качества модели мы добавили несколько дополнительных LSTM-слоев как в кодировщик, так и в декодировщик, а в качестве “бутылочного горлышка” использовали несколько обычных полносвязных слоев нейронов, естественно, не забывая про Dropout, Batch Normalization и другие приемы для тренировки нейронных сетей.
Для сравнения мы попробовали обучить актокодировщик на сверточных нейронных сетях (Сonvolution Neural Networks, CNN) на том же наборе данных. Сверточные слои помогают установить паттерны поведения объектов и позволяют сократить количество параметров модели, что ощутимо ускоряет обучение. Про сверточные нейронные сети тоже есть статьи на Хабре (здесь, здесь и, например, здесь), поэтому мы не будем останавливаться на них подробно. Схематично архитектура автокодировщика на сверточных нейронных сетях выглядит следующим образом:
from keras.layers import Input, Dense, Conv2D, MaxPooling2D, UpSampling2D
from keras.models import Model
input_tensor = Input(shape=input_dim)
x = Conv2D(16, (3, 3), activation='relu', padding='same')(input_tensor)
x = MaxPooling2D((2, 2), padding='same')(x)
x = Conv2D(8, (3, 3), activation='relu', padding='same')(x)
x = MaxPooling2D((2, 2), padding='same')(x)
x = Conv2D(8, (3, 3), activation='relu', padding='same')(x)
encoded = MaxPooling2D((2, 2), padding='same')(x)
x = Conv2D(8, (3, 3), activation='relu', padding='same')(encoded)
x = UpSampling2D((2, 2))(x)
x = Conv2D(8, (3, 3), activation='relu', padding='same')(x)
x = UpSampling2D((2, 2))(x)
x = Conv2D(16, (3, 3), activation='relu')(x)
x = UpSampling2D((2, 2))(x)
decoded = Conv2D(1, (3, 3), activation='sigmoid', padding='same')(x)
autoencoder = Model(input_tensor, decoded)Т.к. элементы тензоров принимают значения в диапазоне от 0 до 1, то можно воспользоваться функцией потерь перекрёстной энтропии (binary crossentropy).
Результат обучения автокодировщика на CNN по метрике качества оказался даже выше, чем автокодировщика на LSTM, а время обучения заметно быстрее.
Кроме того, возможно сделать автокодировщик на CNN и LSTM: сначала несколько сверточных слоев, затем автокодировщик на основе LSTM, завершающийся декодировщиком на основе сверточных слоев. Такой автокодировщик будет объединять положительные стороны обоих подходов. По нашему опыту, такой автокодировщик незначительно лучше автококодировщика на CNN и значительно лучше автокодировщика на LSTM по метрикам качества на валидационной выборке.
После тренировки кодировщик переводит последовательность действий для каждого получателя в вектор признаков, и таким образом мы получаем аналог word2vec для серии событий. Полученный вектор возможно использовать в других предиктивных моделях, кластеризации, в поиске близких по поведению людей, а также выполнять поиск аномалий.
В нашем случае мы строили модель, предсказывающую вероятность покупки получателя письма. Модель на ряде основных признаках давала roc-auc 0.74-0.77, а с добавленными векторами, отвечающими за поведение человека, roc-auc достигал 0.84-0.88.
Необходимо признать, что использование автокодировщика на основе CNN для данной задачи давало более качественный результат, однако автокодировщик на основе LSTM давал вектора меньшей размерности и позволил немного дополнительно подтянуть roc-auc. Если использовать признаки на основе автокодировщика СNN + LSTM, то roc-auc получается в диапазоне 0.82-0.87.
Выводы
Наш опыт подтвердил тот факт, что поведение людей возможно закодировать посредством автокодировщика на нейронных сетях: в нашем случае последовательность поведения получателей рассылки были закодированы с помощью автокодировщиков на LSTM и на CNN-архитектурах. Рассылкой писем применение этого подхода не ограничено: закодированное поведение объектов можно использовать в других задачах, требующих работы с поведением человека: поиск мошеннических действий, предсказания оттока, поиск аномалий и т.д.
Предложенный подход можно развивать в сторону вариационных автокодировщиков, если в этом есть потребность в моделировании поведения людей.
Тот факт, что автокодировщик на основе CNN с рассмотренной задачей справляется лучше, чем на LSTM, дает возможность предположить, что паттерны поведения позволяют для данной задачи извлечь более информативные признаки, чем признаки на основе временных связей между событиями. Тем не менее, на подготовленном наборе данных есть возможность использовать оба подхода, и суммарный эффект от совместного использования признаков обоих автокодировщиков дает прирост к roc-auc на 0.01-0.02.
Таким образом, нейронные сети в состоянии понять по поведению человека, что он склонен к покупке, возможно даже до того, как сам человек это осознает. Удивительный пример фрактальности нашего мира: нейроны людей помогают организовать тренировку нейронных сетей с целью предсказать результат работы нейронов других людей.
Кстати, в нашей компании есть вакансии!
Yarique
Подкинули сексизма на вентилятор(:
Analitik_Telecom
Причём тут сексизм? Есть дата сайнс, и её задача рассматривать массивы данных в разных целях — а чтобы была практическая ценность, нужен какой-то дифференцирующий признак: гендер, рост, да хоть марка автомобиля. И тогда данные становятся на службу бизнеса: например, косметической отрасли, которая и так напичкана технологиями по самое не могу.
Что касается статьи, как бывший аналитик люблю такое почитать и понять хотя бы на поверхности, как устроена она, аналитика, с которой наше поколение не работало :-)
dimm_ddr
Сексизм в выбранных иллюстрациях, сама статья вроде бы неплохая.
art_pro Автор
Мы ставим себе целью сделать женщин более счастливыми, а это уже делает ситуацию по отношению к мужчинам не равновесной. Если человек хочет увидеть что-то, то он это увидит в любом намеке, и именно на этом основан тест Роршаха.
dimm_ddr
То есть вы считаете что картинки с гендерными стереотипами делают женщин более счастливыми? Я конечно не знаю, но есть подозрения что не все с вами согласятся. Шуточки на тему таких стереотипов и есть одна из форм сексизма, о каких намеках вы тут говорите?
Kriger91
А можно травить учёных за футболки на своём уютном тамблере? Достали уже, страшно открыть консервы(с)
homm
Травить никого не стоит. Но сказать, что человек поддерживает дремучие стереотипы конечно можно.
Kriger91
Ведь это основная тема поста, ага. Без этого не понять и не научиться новому
dimm_ddr
А я разве кого-то травил? Я даже не говорил хорошо это или плохо. Вы, кстати, тоже так себе поступаете записывая меня в радикальную ветку феминизма.
Kriger91
Это отсылка к известному событию, если что. И поверьте, не «записываю» и не «феминизма». Просто хочу увидеть адекватную дискусию по теме поста и интересные вопросы, а не самоутверждение через придирки к картинкам
dimm_ddr
А я знаю к какому событию это отсылка. И я категорически не согласен с тем как затравили ученого. Но это не имеет никакого отношения к тому, что я написал здесь раньше. Из того что вы его упомянули я могу сделать вывод что либо вы не разбираетесь в теме и услышав слово "сексизм" сразу вспоминаете только тот случай, либо что вы решили что я один из sjw а значит и того несчастного с удовольствием бы травил. Возможно я что-то упускаю? Тогда объясните мне как тот случай относится к данному посту и моему комментарию. Зачем-то же вы его написали мне в ответ.
Kriger91
Рад что вы знаете это событие. Помимо запятых, вы упускаете тот факт, что это хабр, а не tumblr и что было бы не плохо вместо самоутверждения, навязывания своих взглядов не по теме и отрицания своего поведения увидеть интересные вопросы и дискуссию. У вас есть вопросы к тому что написано или к тому какие методы/подходы использовались? Если нет — просто промолчите, если да — то вот про это и пишите, пожалуйста. Иначе это не только неуважение к сообществу, но ещё и превращение полезного ресурса в очередную площадку-помойку.
Endeavour
Вопрос: зачем автор вставил тупые, прямо скажем, картинки не по теме, и зачем вы защищаете сейчас его решение?
dimm_ddr
Вы точно также навязываете свои взгляды здесь. Я вам еще раз повторяю, тот случай не имеет никакого отношения к текущему посту и моим комментариям, зачем вы его постоянно вспоминаете? Потому что удобно сражаться именно с ним? У меня есть вопросы к автору поста который непонятно зачем в нормальной статье разместил странные иллюстрации не к месту. Эти иллюстрации часть статьи? Если да, то обсуждать их не менее правильно обсуждения статьи. Если нет, то размещение их — то же самое неуважение к сообществу и превращение ресурса в помойку как вы выразились.
И вы так и не ответили на мой вопрос: как тот некрасивый случай с ученым в гавайской рубашке относится к тому, что написал я? Я понимаю что сражаться с соломенным чучелом удобнее, но может быть вы все таки проявите то уважение о котором говорите что у меня его нет и все-таки начнете писать по теме?
Kriger91
Сразу после вас. И как по мне изображения вполне уместны, особенно если учесть для каких клиентов работает заказчик данного решения
dimm_ddr
А я не говорил что они неуместны. Я ответил на вопрос где в этом посте сексизм. В иллюстрациях. Ваша очередь.
saluev
А ваша логика применима к чему угодно.
— В начале статьи автор написал, что чернокожие — не люди!
— Зачем вы пытаетесь самоутвердиться на теме расизма? Давайте дискутировать по существу статьи!
Myosotis
А меня шутка на картинке заставила улыбнуться.
Gearbeast
А может спросить самих женщин об их отношении к этим картинкам?
Какие все стали вдруг "(не)толерантные" и способные выступать (когда их еще не просили) за права тех, кто может и сам высказаться.
art_pro Автор
Перед публикацией я специально спрашивал у знакомых девушек, насколько предложенные иллюстрации обидные. Все сказали, что иллюстрации вполне забавные и невинные. Возможно, это просто окружение у меня такое – все легко относятся к стереотипам, способны к самоиронии и по жизни уделяют внимание более важным вопросам
roscomtheend
Возможно что оскорбятся такими иллюстрациями те же, что и известной рубашкой (кажется, это была не футболка).
saluev
Fixed that for you.
UberSchlag
Так себе фикс. Реакция всегда в голове реагирующего.
dimm_ddr
Они не обидные, они сексистские. Они построены на шутках о различии в логике полов. Если бы эти различия были научно доказаны — вопросов бы к вам не было. Но на данный момент это именно стереотипы. Причем в данном конкретном случае это стереотип о том, что у девушек логики либо нет, либо она какая-то неправильная. Что естественно может быть для кого-то обидным. Может и не быть в силу разных причин: кому-то нравится быть особенным, кто-то просто привык и считает это нормальным. Но от того что кто-то на эти иллюстрации не обижается они не перестают быть сексистскими.
m52
Тогда остальное можно было и не писать.
dimm_ddr
То есть если статья никого не обижает то и писать о ней не надо? Я искренне недоумеваю зачем автор добавил это в пост. Статья вроде достаточно адекватная чтобы и без такого срача набрать просмотров.
NadezhdaBaranova
Цель бизнеса — заработать денег. Цель вашей статьи — попиарить компанию. Цель моего комментария — высказать мнение, что и название статьи, и картинка с "шуткой" здесь неуместны и лично мне, как женщине, неприятны.
Gearbeast
Надежда, не могу не спросить
NadezhdaBaranova
Не поняла вопрос.
Jef239
Да полно их. Одна из самых известных.
gricom
а смешные?
roscomtheend
А вот это уже тянет на сексисткую шуку.
homm
Вы сейчас травите человека в профессонально сообщистве по половому признаку. Вам что, 12 лет?
bopoh13
Как вы определяете грань между юмором и травлей?
homm
Тут всё очевидно. Человек говорит «мне не нравится юмор, где присутствует гендерный стереотип». Ему отвечают юмором с гендерным стереотипом.
Fortisa
Как же вас на Хабр занесло, раз вы таких шуток не понимаете? Я одного не понимаю — вы все откуда это взяли, про сексизм? Вполне милые шутки про женскую логику. Я технарь по образованию, неплохой инженер в прошлом, ИТ-пиарщик и меня просто «улыбают» такие шутки. Знаете, почему? Потому что я на 150% уверена в себе, своём профессионализме и статусе. А раз вас задело — значит, про вас? :-)
NadezhdaBaranova
Вы уверены в себе настолько, чтобы хвастаетесь на хабре чувством юмора. А я — настолько, чтобы прямо написать о том, что мне не нравится.
lovespy
Извините, но я вам не верю. Хотя в этом никчемном мире все сводится к деньгам и бабам. Отсюда войны и дерьмо в межличностных отношениях.
vire
Додик-феминист — зрелище жалкое. Раз на хабре в теме про машинное обучение мы вынуждены сначала выяснить кто тут оскорбился и обсудить это нытье, то это вам Глупым курицам, бомбить будет очень долго.
EndUser
«Наш опыт подтвердил» — здесь подробнее можно? «До/после» в цифрах. Спасибо!
art_pro Автор
Мы не внедряли модель «до» (ROC AUC 0.74 -0.77), поскольку считали этот результат слишком низким и надеялись его улучшить. Увеличение качества модели «после» (ROC AUC 0.84 — 0.88) дало нам возможность достичь уровня, когда не стыдно внедрить наше решение. Конкретных цифр, к сожалению, не раскрою, т.к. эта тайна не наша, но могу сказать, что бренд остался доволен нашим решением
homm
Классные картинки. Спасибо за минутку гендерных стереотипов, я так скучал.
ChePeter
Расскажите про разбиение на тестовую и тренировочную выборки. Делали один раз или повторяли расчеты на разных? Если повторяли, то насколько они отличались.
Спасибо.
art_pro Автор
На самом деле мы работали над 2-мя моделями: моделью автоэнкодера и моделью предсказательной. В случае автоэнкодеров, тестировали качество на отложенной выборке. Для тренировки предсказательной модели несколько раз разбивали на трейн-тест, тренировали модель отдельно, тестировали отдельно: качество, конечно, варьируется, но в разумных пределах, указанных в статье. К тому же результату приводила кросс-валидация на нескольких фолдах. Эксперимент с тренировкой автоэнкодеров также повторяли несколько раз, итог приводил к одинаковым результатам. Спасибо за вопрос по делу!
ChePeter
Тогда ещё попытаю.
Вы определяли «купит ли участник тусовки в ближайшее время»? Правильно понял?
А пробовали определить тех, с которых покупки, как правило, начинаются? Инициативщиков
art_pro Автор
Действительно, мы предсказывали вероятность скорой покупки людей, но пока не решали задачу поиска лидеров мнений и инициативщиков. Надеюсь, эта задача еще появится у нас в будущем, однако можно ожидать, что для её решения анализ поведения с помощью нейронных сетей также пригодится.
ChePeter
Поиск лидеров мнений в состоявшемся бренде не так уж и проблематично и сложно, можно и без DS.
А вот при выводе нового бренда, когда мнений еще нет и лидеров тоже. Тратиться на тех, кто не станет лидером — бессмысленно, не искать потенциальных лидеров — опасно, конкуренты не дремлят.
Это хорошая задачка ))
uhf
Код автокодировщика для датасета MNIST, конечно, очень интересен, но я его уже видел в блоге Keras.
art_pro Автор
Рад, что обратили на это внимание. Мы предложили код автокодировщика в самом общем виде, для хрестоматийного случая. Если писать автокодировщик под конкретную задачу, то размерность тензоров будет зависеть от доступных данных, а также от этого будет зависеть архитектура сети, количество слоев и т.п. В статье специально приведен самый общий вариант, чтобы читатели обратили внимание на принцип, а сам подход адаптировали под свою специфическую задачу самостоятельно.
TrllServ
ставить опыты на людях, ипродавать секретписать статьи как получать максимальные скидки.PS: В соседней теме говорят скрывать нечего, шифровать не надо. Оказывается, теперь надо даже, чтоб получать скидку.
pdima
Вот подходящее применение Adversarial Attacks, если заработает так же неплохо как с картинками, возможно будет сгенерировать список товаров например после просмотра которых модель будет думать что клиент почти потерян
art_pro Автор
Доброе утро. Похоже, что вчера я был еще Data Scientist, а сегодня уже Data Sexist. Как считал Герострат, слава плохой не бывает.
DjoBlack
На самом деле, без шуток и любого сексизма, предсказать поведение мужчины намного проще, чем поведение женщины. Это НЕ хорошо и НЕ плохо одновременно, просто так есть, с этим надо жить и примеров тому множество. Ровно как и множество примеров обратному, с другой стороны)
TrllServ
А то пока это похоже на стереотипы и мифы.
WTYPMAH
Подскажите, чем опредляли feature importance? Не пробовали LIME?
art_pro Автор
Для предсказательной модели мы использовали CatBoost, который показал себя несколько лучше XGBoost на нашем наборе данных. Соотвественно, приведены feature importance этого классификатора. Касательно LIME: это хорошая идея, когда от нас потребуют высокой интерпретируемости модели, мы LIME обязательно попробуем.
AvioD
Честное слово, когда читал, то промелькнула в голове мысль «Как замечательно, что хотя бы на хабре никто не будет разводить срач из-за якобы оскорбительных сексистских шуток».
А потом зашел в комменты и как-то опечалился.
Коллеги, на мой взгляд, не стоит что-либо вообще доказывать людям, которые способны найти сексизм даже в подобных невинных иллюстрациях.
Ради интереса, опросил технарей женщин на работе. Ни одна не нашла в иллюстрациях чего-то оскорбительного для себя.
Так что, на мой взгляд, таких людей лучше просто игнорировать. Моська лает — слон идет.
Endeavour
Тем, что российское общество, и женщины, как его составляющая, имеет отсталые взгляды на современные проблемы, вы никого не удивите.
TrllServ