

Над большой тестовой инсталляцией, на которой крутился сторадж на базе ScaleIO от Dell EMC, мы издевались всяческим образом пару лет точно, а то и больше. Внесли огромное количество исправлений и допилили наконец-то продукт под нашу облачную инфраструктуру. Сторадж заполняет у нас крайне востребованную нишу между обычным медленным хранилищем на базе HDD и скоростным решением на all-flash массивах. Более того, в силу своей Software Defined специфики он позволяет собирать отказоустойчивые стораджи чуть ли не из палок с ветками. Только учтите, что совсем экономить на железе смысла нет, стоимость лицензии перевесит выгоды от экономии.
Короче говоря, сегодня я расскажу вам, как мы внедряли ScaleIO и ходили по граблям с закрытыми глазами. Про архитектурные особенности стораджа и его интеграцию в Облако. И, конечно, будет про нагрузочное тестирование. За подробностями — добро пожаловать под кат.
«Почти как у AWS»
Как было сказано выше, в Облаке КРОК есть два типа хранения дисков – «стандартный» и «флэш». Первый построен на базе массивов с магнитными дисками, LUN’ы с СХД презентуются на сервера Облака и собираются в кластерную файловую систему. Второй тип, в свою очередь, построен на базе all-flash массивов, известных в узких кругах как «массивы-скрипки», LUN’ы которых презентуются непосредственно на сервера Облака с гипервизором и пробрасываются напрямую в ВМ для максимальной производительности.
С каждым из этих решений у нас были различные проблемы во время эксплуатации. «Массивы-скрипки» при большом количестве LUN’ов (точнее, их экспортов на сервера) резко увеличивают время ответа на API-запросы. В особо тяжелых случаях они вообще перестают подавать признаки жизни. Время презентации самих LUN при этом тоже сильно возрастает. Кластерная ФС на базе магнитных дисков с возрастанием нагрузки теряет стабильность, особенно во время попыток масштабирования. Плюс несколько раз подводило железо.
Оба типа хранения построены достаточно консервативно, с минимумом слоев абстракции. В итоге их ощутимо сложнее обслуживать, чем классические «облачные» решения, плюс сюда добавляются проблемы с масштабируемостью и отказоустойчивостью. Поэтому в качестве основы для нового типа хранения было решено рассматривать именно решения Software Defined Storage (SDS), в которых большинство подобных проблем решено уже на архитектурном уровне.
Мы провели сравнение множества доступных SDS-решений на рынке, среди которых, помимо продукта Dell EMC, были Ceph (RBD), GlusterFS, MooseFS, LizardFS и ещё несколько продуктов. Кроме функциональных возможностей, критичным фактором для нас была производительность решения на магнитных дисках. Именно ScaleIO по этому параметру опередил всех остальных как при последовательных, так и при рандомных IO-операциях. Наш коллега Роман (RPOkruchin) в своих статьях уже писал об интересных решениях на базе этого продукта: «Не спешите выкидывать старые серверы, из них можно собрать быструю Ethernet-СХД за час» и «Как можно сделать отказоустойчивую систему хранения данных из отечественных серверов».
Забегая вперёд, скажу, что по результатам тестирования производительности мы решили позиционировать новый тип хранения как более быстрый «Throughput Optimized HDD (st1)» тип от AWS, но снизили ограничение по минимальному размеру диска до 32 Гб и дали возможность использовать в качестве загрузочного диска. Из-за гибкости получившегося решения мы назвали новый тип хранения – «универсальный» (st2), позиционируя его как улучшенный вариант от AWS.
Архитектура
Для начала опишу, из каких компонентов состоит кластер Dell EMC ScaleIO.
- MDM (Meta Data Manager) — управляет ScaleIO кластером и хранит всю его конфигурацию. Все возможные задачи по управлению остальными компонентами ScaleIO проходят через него. Может быть представлен одним сервером или управляющим кластером из трех или пяти серверов. В задачи MDM-кластера также входит мониторинг всей системы: отслеживание ошибок и сбоев, rebuild и rebalance кластера, отправка логов на удаленный сервер;
- Tie Breaker MDM (TB) — используется в кластере MDMов для голосования и поддержания кворума, не хранит данные;
- SDS (ScaleIO Data Server) — сервис, агрегирующий локальные диски сервера в Storage Pool’ы ScaleIO. Принимает все клиентское IO, выполняет репликацию и прочие операции с данными;
- SDC (ScaleIO Data Client) — драйвер устройств, который представляет диски ScaleIO в качестве блочных устройств. В Linux представлен модулем ядра;
- Gateway (GW) — сервис, принимающий запросы REST API и перенаправляющий их на MDM: всё общение Облака с MDM-кластером происходит именно через него. Также на этих серверах располагается Installation Manager (IM), через WEB-консоль которого происходит автоматическая установка/обновление/анализ кластера;
- Также для управления всем кластером с помощью вышеупомянутого IM необходимо, чтобы на всех серверах кластера был установлен LIA (Light Installation Agent), который позволяет производить автоматическую установку и обновление пакетов.
В общем виде собранный кластер ScaleIO внутри нашего Облака на каждой площадке можно изобразить приблизительно так:
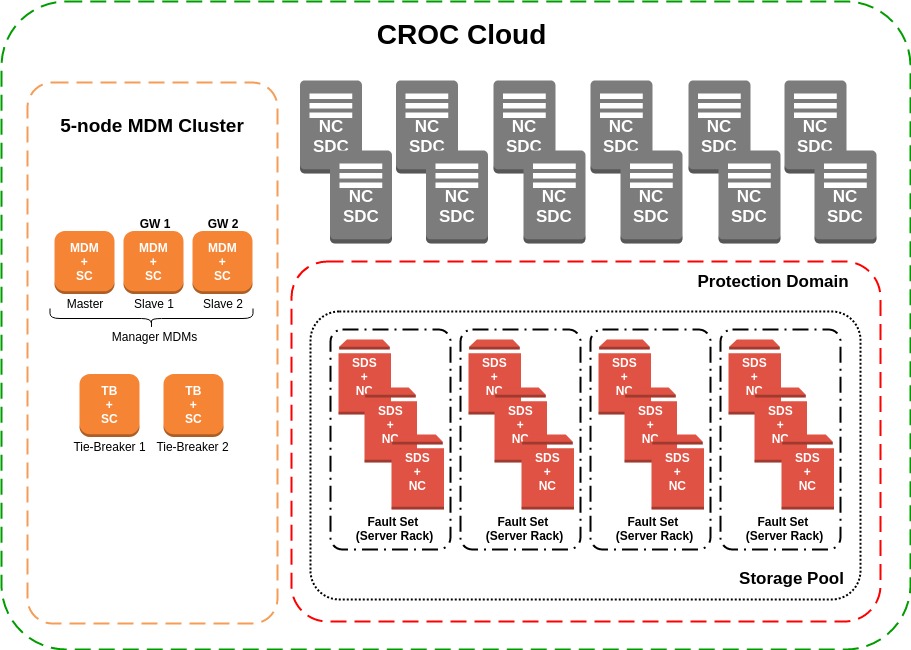
В Облаке существует сервис SC (Storage Controller), который контролирует выполнение всех операций, связанных с дисками для виртуальных машин. Создание LUN’ов на различных системах хранения, используемых у нас, их дальнейший экспорт на нужный гипервизор, увеличение размера, удаление и весь остальной жизненный цикл устройств. Наиболее логичным решением в данной архитектуре было развертывание MDM-кластера именно на этих серверах. Физически SC и MDM живут на серверах Dell EMC PowerEdge R510 с CentOS 7.2 в качестве ОС. Также на двух серверах этой группы располагаются ScaleIO Gateway, которые предоставляют REST API для управления кластером. Каждый находится в состоянии Active, но Облако обращается к ним через балансировщик, настроенный в режиме Active-Backup.
Для pre-production тестирования мы подготовили пул из 12 SDS, в каждом из которых 4 SAS диска — Seagate 12Гбит/с 10K 1.8Tb 2.5". Далее все SDS добавили в один Protection Domain, т.к. сервера географически располагаются в одном ЦОД, и в один Storage Pool. После этого SDS были объединены группами в Fault Set. Fault Set — крайне интересная концепция, предполагающая разбиение серверов на кластеры с высокой вероятностью одновременного отказа. Причем причины этого могут быть любыми: как особенности установленной ОС, так и расположение в одной стойке в местности с повышенной вероятностью падения метеоритов. Данные будут зеркалироваться таким образом, чтобы избежать попадания копий в одну группу риска.
При использовании Fault Set необходимо также выделить некий процент от общего сырого объема для Spare-пространства. Это зарезервированное место, равное наибольшему Fault Set, которое будет использовано при потере диска/сервера/Fault Set во время ребилда кластера. Поэтому мы объединяем сервера в группы по расположению SDS в серверных стойках, что гарантирует доступность копии данных даже после потери всех серверов в одном Fault Set, например, при сбое в электроснабжении стойки. Хотя, в нашем ЦОД с сертификацией TIER-III вероятность этого крайне мала. Итоговый размер тестируемого пула:
- 78.5 Тб сырого пространства;
- 25% Spare пространства — 19.6 Тб;
- 29.5 Тб полезного пространства (учитывая фактор репликации — 2).
Все SDS расположены на нодах с гипервизором (NC) и SDC — наш вариант конвергентности систем. К решению разместить SDS на серверах с гипервизором пришли осознанно. Во время первоначальных тестов мониторили нагрузку, создаваемую на сервер с дисками, пытались обнаружить заметное влияние, нагрузку на CPU, RAM и ОС — тщетно. Что нас приятно удивило. А так как держать выделенные сервера под диски с простаивающим CPU не очень выгодно, и в дальнейшем предполагается увеличение количества SDS, решение напросилось само собой.
Клиентами (SDC), соответственно, являются сервера с гипервизором, предоставляющие диски ScaleIO как блочные устройства для ВМ. Физически SDC и SDS располагаются на серверах Dell EMC PowerEdge R720/R740 и той же CentOS 7.2. Что касается сетевой составляющей, то передача данных происходит по 56 Гбит/с InfiniBand (IPoIB), управление – 1 Гбит/с Ethernet.
Собрав весь кластер и убедившись, что он работает, мы приступили к его тестированию.
Первичные тесты и анализ
Первоначальные тесты производительности проводились без участия гипервизора и виртуальных машин: тома подключались к пустующим серверам и нещадно нагружались в попытках нащупать потолок производительности по IOPS и Мбит/с. Попутно мы определяли максимальный latency в различных условиях: пустующий кластер, забитый до отказа и т. п. Получив разнящиеся результаты, поняли, что магнитные диски — вещь не самая стабильная, особенно под максимальной нагрузкой. Но примерный предел производительности кластера мы для себя получили: для тестового кластера из 48 1.8 Тб SAS 12 Гбит/с 10K дисков с «сырым» объемом в 78.5 Тб максимальным значением IOPS в самых сложных тестах стало около 8-9 тысяч IOPS (позже будет методика тестирования и остальные подробности). В дальнейшем мы уже ориентировались на эти показатели.
Параллельно со всем этим мы проанализировали нагрузку на системы хранения в продакшене и виртуальные диски, которые планировали переносить на ScaleIO. С двух площадок получили следующие усредненные показатели за период в 3 месяца:
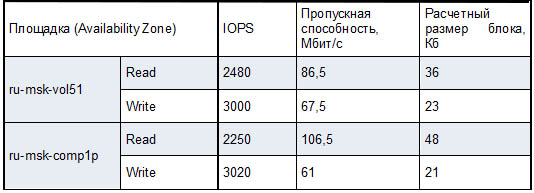
С одной стороны — запись происходит чаще чтения с соотношением 45/55 от количества операций, с другой — чтение происходит бо?льшими блоками и нагружает СХД на 30, а то и на 70 процентов больше. Полученные показатели мы использовали в дальнейшем при тестировании на виртуальных машинах, чтобы как можно точнее воспроизвести нагрузку на реальных серверах.
Внедрение никогда не проходит гладко
Дешевая комната страха: темно и везде грабли.
Головная боль во время внедрения нового типа стораджа была у каждой группы нашей Облачной команды. Тем не менее, подобные задачи и трудности — это всегда отличный опыт. Мы постарались перечислить наиболее важные проблемы.
API клиент к ScaleIO
Имея интересный опыт работы с API «массивов-скрипок», мы решили, что будем ещё на этапе выбора решения тестировать работоспособность API каждого из них под нагрузками и параллельными запросами. И так как большинство сервисов Облака, и в том числе SC (Storage Controller), написаны на языке python, было важно, чтобы и у решения был API-клиент на том же языке.
И вот тут нас подстерегала проблема: API-клиент ScaleIO был только для версии 1.32, а мы тестировали уже версию 2.0. Пришлось немного отложить тестирование и написать собственный API-клиент — pyscaleio. В нём получилось реализовать не только базовые CRUD-операции, но и полноценный ORM для некоторых сущностей API, валидацию ответов и управление инстансами клиентов. А самое главное, весь код был покрыт unit-тестами, и на самые важные API-операции были написаны функциональные тесты, которые можно запустить на работающем кластере ScaleIO.
Конечно же, удалось найти несколько багов в API. Например, можно было выставить лимитирование IO для диска (троттлинг), но нельзя было его снять, потому что «iopsLimit (0) must be a number larger than 10». Но мы не собирались использовать троттлинг на уровне SDS, поэтому это было не критично. В целом, ScaleIO API под нагрузкой показало себя отлично: не было проблем ни при большом количестве созданных дисков, ни при выполнении параллельных запросов.
Троттлинг
Во время первоначального нагрузочного тестирования, о котором было написано чуть выше, стал понятен примерный предел производительности кластера ScaleIO, и нам предстояло решить, как лимитировать диски заказчиков и как позиционировать новый тип хранения. Проанализировав результаты, было принято решение ограничить диски по IO-операциям в 500 IOPS, а пропускную способность ограничивать в зависимости от размера диска. Точно так же делает AWS для своих «Throughput Optimized HDD» дисков. При увеличении размера диска ограничение пересчитывается автоматически.
Например, для диска в 104 Гб (диски в ScaleIO должны быть кратны 8 Гб — системное ограничение):
| Size (GiB) |
MBPS Baseline |
MAX MB/s |
| 104 |
0.25 |
26 |
(MBps Throughput / KB per IO) * 1024 = MAX IOPS
26 / 53 * 1024 = 502 IOPS
15,6 / 32 * 1024 = 500 IOPS
26 / 64 * 1024 = 416 IOPS
26 / 128 * 1024 = 208 IOPS
Если нужна бОльшая производительность, диск придется увеличить. А если нужна большая производительность на небольших дисках, то придется перейти на тип хранения «флэш» с гарантированными IOPS и возможностью их изменения. К счастью, в Облаке предусмотрена live-миграция дисков между типами хранения, что сильно упрощает жизнь.
«Тонкие» диски и пустота
И как раз во время тестирования live-миграции с других типов хранения на подопытный ScaleIO, оказалось, что диск становится «толстым», полностью аллоцированным, хотя создавался «тонким», а исходный диск заполнен данными меньше чем наполовину.
Неэффективная трата ресурсов — это всегда печально, поэтому мы начали искать причину утечек.
В Облаке в качестве гипервизора используется QEMU-KVM, что дало нам возможность изучить проблему на низком уровне. Драйвер блочных устройств в гипервизоре умеет эффективно писать нули на устройство, выполняя системный вызов BLKDISCARD и деаллоцируя пространство внутри диска. Однако кроме поддержки операции BLKDISCARD, от блочного устройства нужна ещё и поддержка опции BLKDISCARDZEROES. Иначе чтение из тех блоков, на которые был вызван BLKDISCARD, может вернуть не нули.
Поддержки опции BLKDISCARDZEROES у дисков ScaleIO не оказалось. Но если выполнить BLKDISCARD на весь диск ScaleIO, пространство будет корректно деаллоцированно. Получается либо в ScaleIO семантика BLKDISCARDZEROES реализована как-то по-особенному, либо флаг просто выставлен некорректно. На форуме Dell EMC подсказали, что полноценно семантика BLKDISCARDZEROES не поддерживается, а для того, чтобы эффективно записывать нули, реквесты BLKDISCARD должны быть кратны 1MiB.
Решение проблемы было найдено и оставалось «научить» гипервизор этой специфической семантике эффективной записи нулей. Для этого были сделаны правки в драйвер блочных устройств QEMU-KVM, по аналогии с похожим поведением для XFS. Мы достаточно часто делаем различные правки в гипервизор, и по большей части это бэкпорты из более новых версий или апстрима, но на этот раз это наши собственные изменения, чему мы очень рады. Теперь во время live-миграции дисков место на кластере расходуется эффективно.
А точно пустота?
Во время повторного тестирования live-миграции с обновленным гипервизором мы заметили еще одну проблему: исходный и целевой диски после миграции отличались, причём в случайных местах — то в самых первых блоках, то в середине. Пришлось перепроверить недавние правки драйвера в гипервизоре, целостность исходных образов дисков, использование page cache при записи. Было достаточно трудно изолировать проблему, но нам удалось это сделать за несколько часов, поэтапно исключая все посторонние факторы. Мы создали новый тонкий диск, проверили, что в начале находятся нули, записали в начало некоторый паттерн, после чего деаллоцировали начало диска с помощью BLKDISCARD, и при повторной попытке чтения видели тот самый записанный паттерн.
Получается, что пространство деаллоцируется, но данные остаются. Несмотря на то, что это очень похоже на баг, лучше не спешить с выводами и перечитать документацию. А в ней сказано, что у Storage Pool в ScaleIO есть опция «Zero padding policy», которая отвечает за заполнение секторов нулями при первой записи, чтобы из них можно было прочитать те самые заветные нули. По умолчанию эта опция выключена и изменить её можно, только если в пул не добавлены физические диски. Так как инсталляция ScaleIO в продакшене уже собрана, готова и активно тестируется, пул придётся пересобирать.
Разумеется, дополнительные операции записи нулей, при первой операции записи в неаллоцированный блок, должны влиять на производительность. Для оценки этого влияния мы повторили часть кейсов из нагрузочного тестирования и увидели деградацию до 15% при первой записи, но нагрузка на SDS не изменилась.
Таким образом, драйвер собственной разработки помог нам найти свои же ошибки в сборке кластера. После пересборки пулов и включения нужной опции все заработало как надо.
Наименование устройств
Как ранее уже было сказано, каждый сервер с SDS является ещё и гипервизором, и на нём располагается внушительное число ВМ. А это значит, что общее количество блочных устройств на сервере может быть довольно велико, более того, они могут очень часто изменяться, так как виртуальные машины можно мигрировать, а диски присоединять и отсоединять.
Среди всех этих дисков необходимо выделять устройства, презентуемые для ScaleIO. Если добавлять их по короткому имени, например, /dev/sdx, то в случае, если диск был добавлен после непостоянных устройств для ВМ, после перезагрузки это имя изменится, и ScaleIO диск потеряет. В итоге его придется заново добавлять в пул, что означает проведение rebalance в случае каждых регламентных работ. Естественно, нас это не очень устраивает.
Мы собирали пул ScaleIO и делали первые тесты на пустых серверах без виртуальных машин. Задумались об этом, только когда стали планировать увеличение основного пула и ждали новую партию SAS-дисков.
Как избежать такой ситуации? Можно использовать символьные ссылки на блочное устройство:
# udevadm info -q symlink /dev/sdx
disk/by-id/scsi-36d4ae5209bf3cc00225e154d1dafd64d
disk/by-id/wwn-0x6d4ae5209bf3cc00225e154d1dafd64d
disk/by-path/pci-0000:02:00.0-scsi-0:2:2:0В документации от RedHat сказано, что для надежного определения SCSI устройств нужно использовать системно независимый идентификатор — WWID (World Wide Identifier). Более того, для нас это не новость, так как такие идентификаторы мы используем при презентации блочных устройств от «массивов-скрипок». Но ситуация осложняется тем, что мы используем физические диски, подключенные через RAID-контроллер, который нельзя использовать в Non-RAID режиме (device pass-through, JBOD). И нам приходится собирать RAID-0 из каждого физического диска с помощью MegaCli, пересборка которого есть новое SCSI устройство с новым WWID, а значит использовать его нецелесообразно.
Пришлось пойти на компромисс и использовать символьную ссылку disk/by-path, в которой есть данные, уникально идентифицирующие физический диск на шине PCI. Так как диски уже были введены неправильно, дежурным администраторам пришлось каждый физический диск добавить по новому пути в пул ScaleIO, с трепетом созерцая прогресс-бар ребаланса кластера в течение нескольких десятков часов.
Тестирование производительности внутри ВМ
Так как диски ScaleIO все-таки планировали использовать как диски для ВМ, мы дождались большого релиза от нашей команды разработки, в котором получили долгожданные доработки, описанные выше. А с учетом результатов первичных тестов и анализа нагрузки на заменяемый сторадж мы начали тестировать диски ScaleIO уже на виртуальных машинах.
Алгоритм был выбран следующий: 30 виртуальных машин на CentOS 7.2, к каждой вторым блочным устройством подключен диск ScaleIO размером 128 Гб (соответственно, имеет ограничение в 32 Мбит/с и 500 IOPS), один Zabbix-сервер для наблюдения со снятием метрик каждую секунду и еще одна ВМ, постоянно пишущая последовательно, 4k блоком, которая будет сигнализировать, что недополучает ресурсов стораджа, если запись на ней упадет ниже 500 IOPS. На определенном количестве тестовых ВМ одновременно запускаем тест утилитой fio с одинаковыми параметрами и наблюдаем за ScaleIO GUI и тестовым Zabbix. Параметры запуска fio:
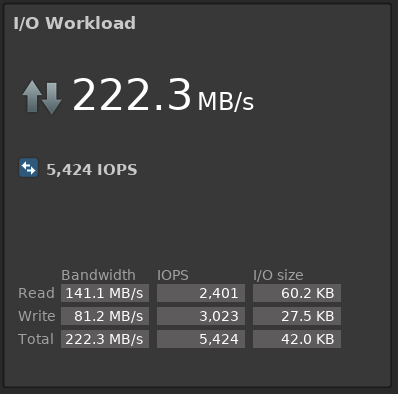
fio --fallocate=keep --ioengine=libaio --direct=1 --buffered=0 --iodepth=16 --bs=64k,32k --name=test --rw=randrw --rwmixread=45 --loops=2 --filename=/dev/vdbВ ScaleIO GUI при нагрузке с 10 ВМ практически точно моделируем среднюю нагрузку на production storage:
Zabbix:
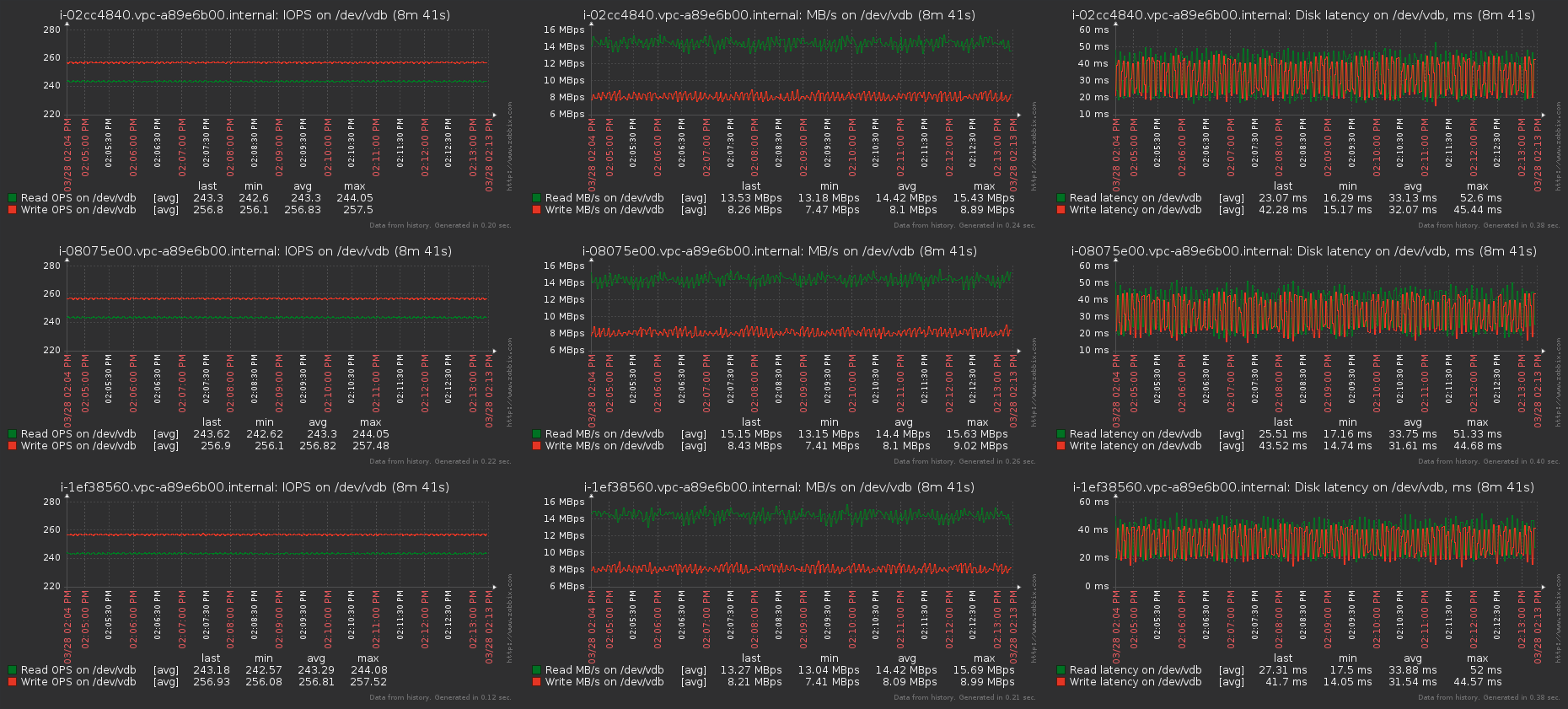
Каждая ВМ получает свои обещанные IOPS и MB/s, latency высок из-за заданной глубины очереди теста. При iodepth=1 latency составляет около 1.6 — 2 ms, что, учитывая прослойку виртуализации, довольно неплохо. Кстати, могу посоветовать хорошую статью про IOPS, latency и storage performance в целом — Understanding IOPS, Latency and Storage Performance.
На графиках отдельно стоящей ВМ, проверяющей влияние и просадки производительности, не было замечено отклонений от нормы за все время проведения теста.
Дальше постепенно увеличивали количество одновременно пишущих виртуальных машин и достигли предела производительности примерно на 9000 IOPS и 800 Мбит/с, когда еще не начинаются просадки на остальных ВМ. Эти цифры примерно совпали с теми, что мы получили, тестируя кластер без использования ВМ, поэтому посчитали их нормальными для текущего количества и характеристик дисков.
После этих тестов мы решили понять, как будет расти производительность при расширении объема кластера. Вывели 2 SDS и начали проводить повторные замеры производительности при добавлении каждого узла обратно. В качестве предварительного вывода установили, что добавление каждого нового SDS в кластер прямо пропорционально увеличивает потолок IOPS / Мбит/с. Так что мы уже ждем доставки новых дисков для увеличения нашего полезного объема примерно в 5-6 раз, поэтому пиковые нагрузки текущего production storage с новыми показателями производительности и умным троттлингом нам будут не страшны.
Еще одним из кейсов тестирования была отказоустойчивость: мы доставали диски из серверов, выключали целиком сервера в пределах одного Fault Set и творили прочие непотребства. Разве что только топором кабели не рубили. Кластер не подвел, данные продолжали быть доступны, а производительность почти не страдала: на минуту IOPS проседали на 10-15%. Главное было правильно подобрать rebuild / rebalance policy, который устанавливается следующими командами:
scli --set_rebalance_policy
scli --set_rebuild_policyМы остановились на ограничении количества IO и пропускной способности ребилда / ребаланса в Мбит/с для каждого диска, подключенного к SDS.
Заключение
В данный момент кластер проходит пилотную эксплуатацию на внутренних учетных записях, чтобы отловить максимум возможных проблем или ошибок на себе, а не на заказчиках. После исправления последних незначительных ошибок в работе Облачных сервисов для всех наших заказчиков станет доступным для создания дисков новый тип хранения — Универсальный (Universal).
Получить демо-доступ в наше Облако или задать вопросы можно по контактам ниже.
Ссылки
- Облако КРОК
- Почта Облачной команды — cloudteam@croc.ru
- Моя личная почта — IEmmanuylov@croc.ru
swiing
Я правильно понимаю что теперь Dell будет поставлять ScaleIO только с железом VxRack? По всей видимости ScaleIO Free теперь тоже нельзя скачать, а я так хотел поиграть… Правда уже не понятно зачам смотреть на free версию учитывая что VxRack стоит как самолет и явно мне не светит.
iemmanuylov Автор
swiing Да, с недавнего времени Dell-EMC прекращают распространение ScaleIO Software отдельно. Для тех заказчиков, кто успел приобрести поддержку только на ПО, сервис остается. Имея аккаунт на support.emc.com до сих пор можно скачать старые версии 2.0.1.4, 2.5 именно ScaleIO Software.