
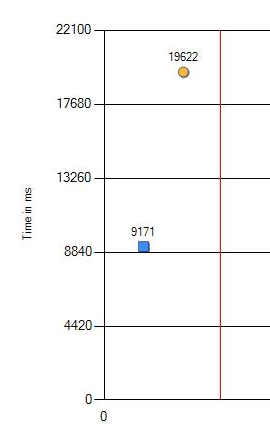
Та же ОС, то же оборудование, другой процессор: в 2 раза медленнее
Падение производительности с 9,1 до 19,6 секунд определённо можно назвать значительным. Мы провели дополнительные проверки со сменой версий тестируемых программ, Windows и настроек BIOS. Но нет, результат не изменился. Единственная разница проявлялась только на разных процессорах. Ниже представлен результат на новейшем CPU.
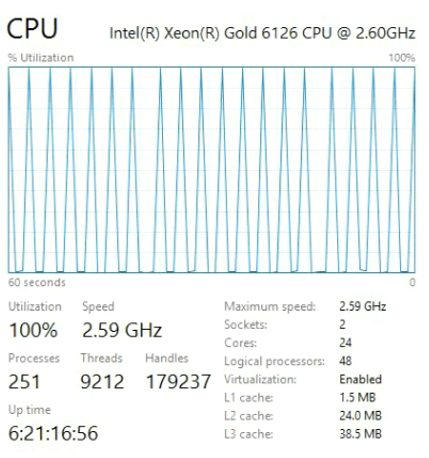
И вот тот, который используется для сравнения.

Xeon Gold работает на другой архитектуре под названием Skylake, общей для новых процессоров Intel с середины 2017 года. Если вы покупаете новейшее железо, то получите процессор с архитектурой Skylake. Это хорошие машины, но, как показали тесты, новизна и быстрота — не одно и то же.
Если больше ничего не помогает, то надо использовать профайлер для глубокого исследования. Проведём тест на старом и новом оборудовании и получим примерно такое:
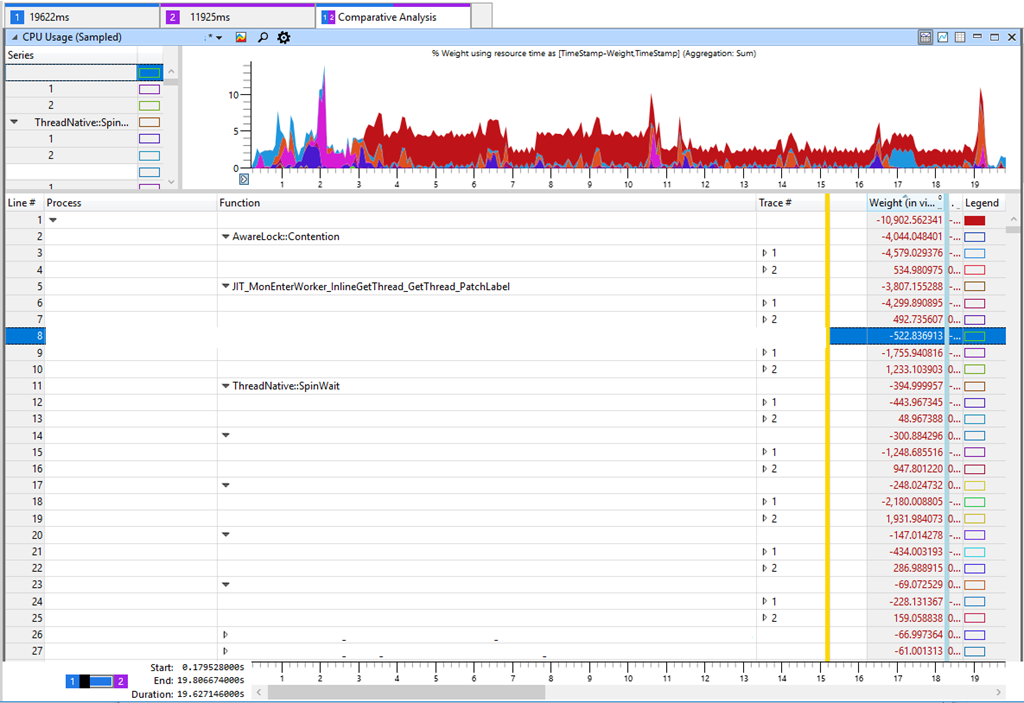
Вкладка в Windows Performance Analyzer (WPA) показывает в таблице разницу между Trace 2 (11 с) и Trace 1 (19 с). Отрицательная разница в таблице соответствует увеличению потребления CPU в более медленном тесте. Если посмотреть на самые значительные различия в потреблении CPU, то мы увидим AwareLock::Contention, JIT_MonEnterWorker_InlineGetThread_GetThread_PatchLabel и ThreadNative.SpinWait. Всё указывает на «спиннинг» в CPU [спиннинг (spinning) — циклическая попытка получить блокировку, прим. пер.], когда потоки борются за блокировки. Но это ложный след, потому что спиннинг не является основной причиной снижения производительности. Усиленная конкуренция за блокировки означает, что нечто в нашем программном обеспечении замедлилось и удержало блокировку, что как следствие привело к усилению спиннинга в CPU. Я проверял время блокировки и другие ключевые показатели, такие как показатели диска, но не удалось найти ничего значимого, что могло бы объяснить снижение производительности. Хотя это не логично, но я вернулся к увеличению нагрузки на CPU в различных методах.
Было бы интересно найти, где именно застревает процессор. В WPA есть столбцы file # и line #, но они работают только с приватными символами, которых у нас нет, потому что это код .NET Framework. Следующее лучшее, что мы можем сделать — получить адрес dll, где находится инструкция под названием Image RVA. Если загрузить эту dll в отладчик и сделать
u xxx.dll+ImageRVA то мы должны увидеть инструкцию, которая сжигает большинство циклов CPU, потому что это будет единственный «горячий» адрес.
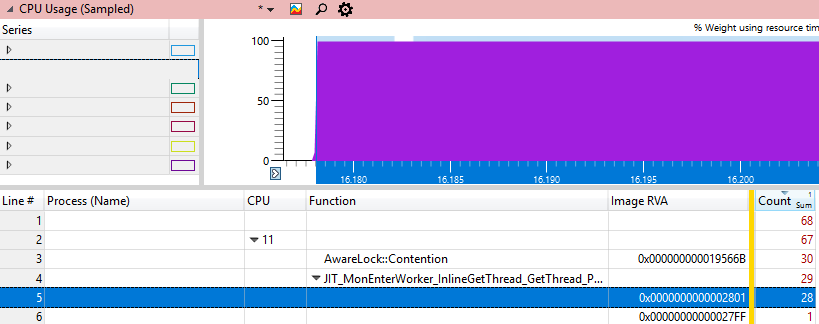
Изучим этот адрес различными методами Windbg:
0:000> u clr.dll+0x19566B-10
clr!AwareLock::Contention+0x135:
00007ff8`0535565b f00f4cc6 lock cmovl eax,esi
00007ff8`0535565f 2bf0 sub esi,eax
00007ff8`05355661 eb01 jmp clr!AwareLock::Contention+0x13f (00007ff8`05355664)
00007ff8`05355663 cc int 3
00007ff8`05355664 83e801 sub eax,1
00007ff8`05355667 7405 je clr!AwareLock::Contention+0x144 (00007ff8`0535566e)
00007ff8`05355669 f390 pause
00007ff8`0535566b ebf7 jmp clr!AwareLock::Contention+0x13f (00007ff8`05355664) И различными методами JIT:
0:000> u clr.dll+0x2801-10
clr!JIT_MonEnterWorker_InlineGetThread_GetThread_PatchLabel+0x124:
00007ff8`051c27f1 5e pop rsi
00007ff8`051c27f2 c3 ret
00007ff8`051c27f3 833d0679930001 cmp dword ptr [clr!g_SystemInfo+0x20 (00007ff8`05afa100)],1
00007ff8`051c27fa 7e1b jle clr!JIT_MonEnterWorker_InlineGetThread_GetThread_PatchLabel+0x14a (00007ff8`051c2817)
00007ff8`051c27fc 418bc2 mov eax,r10d
00007ff8`051c27ff f390 pause
00007ff8`051c2801 83e801 sub eax,1
00007ff8`051c2804 75f9 jne clr!JIT_MonEnterWorker_InlineGetThread_GetThread_PatchLabel+0x132 (00007ff8`051c27ff)Теперь у нас есть шаблон. В одном случае горячий адрес является инструкцией jump, а в другом случае это вычитание. Но обеим горячим инструкциям предшествует одна и та же общая инструкция pause. Разные методы выполняют одну и ту же инструкцию процессора, который по какой-то причине выполняется очень долго. Давайте замерим скорость выполнения инструкции pause и посмотрим, правильно ли мы рассуждаем.
Если проблема задокументирована, то она становится фичей
| CPU | pause в наносекундах |
| Xeon E5 1620v3 3,5 ГГц | 4 |
| Xeon® Gold 6126 @ 2,60 ГГц | 43 |
Pause в новых процессорах Skylake выполняется на порядок дольше. Конечно, что угодно может стать быстрее, а иногда и немного медленнее. Но в десять раз медленнее? Это скорее похоже на баг. Небольшой поиск в интернете об инструкции паузы приводит к руководству Intel, где явно упоминаются микроархитектура Skylake и инструкция паузы:

Нет, это не ошибка, это документированная функция. Есть даже страница с указанием времени выполнения почти всех инструкций процессора.
- Sandy Bridge 11
- Ivy Bridege 10
- Haswell 9
- Broadwell 9
- SkylakeX 141
Здесь указано количество циклов процессора. Для вычисления фактического времени нужно разделить количество циклов на частоту процессора (обычно в ГГц) и получить время в наносекундах.
Это означает, что если запустить сильно многопоточные приложения на .NET на последнем железе, то они могут работать намного медленнее. Кто-то уже заметил это и ещё в августе 2017 года зарегистрировал баг. Проблему исправили в .NET Core 2.1 и .NET Framework 4.8 Preview.
Улучшенный spin-wait в нескольких примитивах синхронизации для лучшего выполнения на Intel Skylake и более поздних микроархитектурах. [495945, mscorlib.dll, Баг]
Но поскольку до выхода .NET 4.8 ещё год, я попросил бэкпортировать исправления, чтобы .NET 4.7.2 вернулся к нормальной скорости на новых процессорах. Поскольку взаимоисключающая блокировка (спинлок) есть во многих частях .NET, то следует отследить увеличенную нагрузку на CPU при работе Thread.SpinWait и других методов спиннинга.

Например, Task.Result внутренне использует спиннинг, так что я предвижу существенный рост нагрузки на CPU и снижение производительности и в других тестах.
Насколько всё плохо?
Я посмотрел код .NET Core на предмет того, сколько процессор будет продолжать спиннинг, если блокировка не освобождена, прежде чем вызывать WaitForSingleObject для оплаты «дорогостоящего» переключения контекста. Переключатель контекста занимает где-то микросекунду или гораздо больше, если много потоков ожидают один и тот же объект ядра.
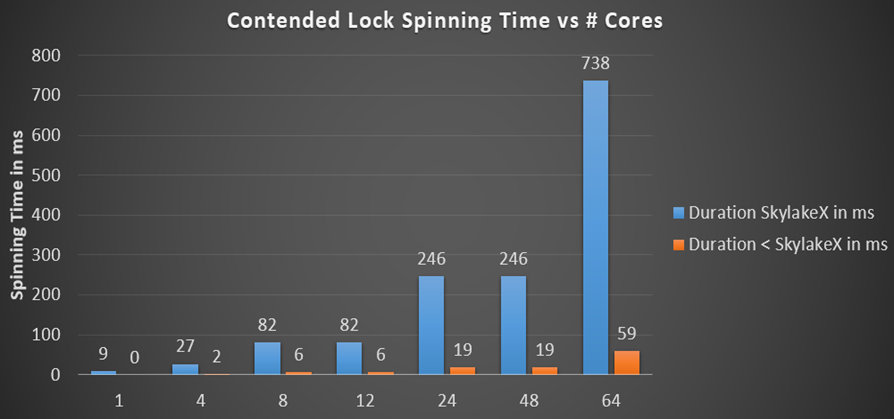
.NET-блокировки умножают максимальную продолжительность спиннинга на количество ядер, если брать абсолютный случай, где поток на каждом ядре ожидает одной и той же блокировки, а спиннинг продолжается достаточно долго, чтобы все немного поработали, прежде чем оплатить вызов ядра. Спиннинг в .NET использует алгоритм экспоненциальной выдержки, когда он начинается с цикла из 50-ти вызовов pause, где для каждой итерации количество спинов утраивается, пока следующий счётчик спинов не превысит их максимальную продолжительность. Я подсчитал общую продолжительность спиннинга в расчёте на процессор для различных процессоров и разного количества ядер:
Ниже упрощённый код спиннинга в .NET Locks:
/// <summary>
/// This is how .NET is spinning during lock contention minus the Lock taking/SwitchToThread/Sleep calls
/// </summary>
/// <param name="nCores"></param>
void Spin(int nCores)
{
const int dwRepetitions = 10;
const int dwInitialDuration = 0x32;
const int dwBackOffFactor = 3;
int dwMaximumDuration = 20 * 1000 * nCores;
for (int i = 0; i < dwRepetitions; i++)
{
int duration = dwInitialDuration;
do
{
for (int k = 0; k < duration; k++)
{
Call_PAUSE();
}
duration *= dwBackOffFactor;
}
while (duration < dwMaximumDuration);
}
}Раньше время спиннинга находилось в миллисекундном интервале (19 мс для 24 ядер), что уже немало по сравнению с упоминавшимся временем переключения контекста, которое на порядок быстрее. Но в процессорах Skylake общее для процессора время спиннинга просто взрывается до 246 мс на 24-х или 48-ядерной машине просто потому, что инструкция pause замедлилась в 14 раз. Это действительно так? Я написал небольшой тестер для проверки общего спиннинга на CPU — и рассчитанные цифры хорошо соответствуют ожиданиям. Вот 48 потоков на 24-ядерном CPU, ожидающих одну блокировку, которую я назвал Monitor.PulseAll:
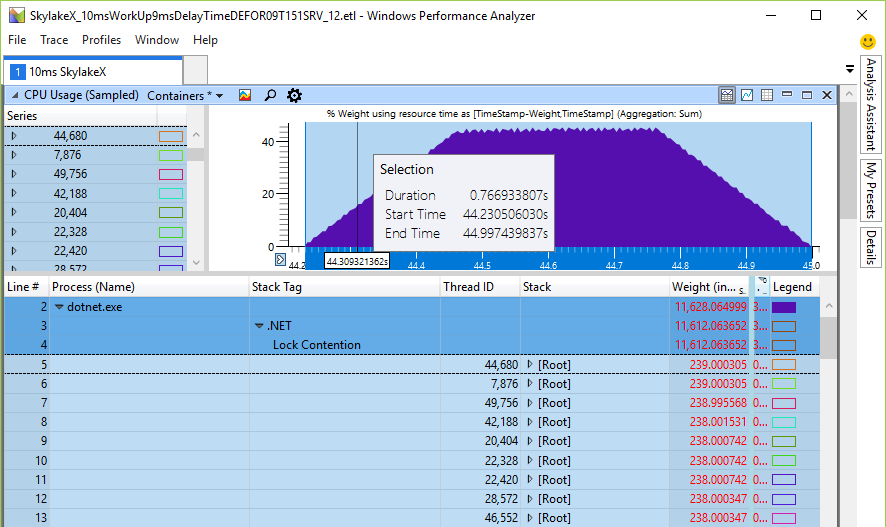
Только один поток выиграет гонку, но 47 продолжат спиннинг до потери пульса. Это экспериментальное доказательство того, что у нас действительно есть проблема с нагрузкой на CPU и очень долгий спиннинг реален. Он подрывает масштабируемость, потому что эти циклы идут вместо полезной работы других потоков, хотя инструкция pause освобождает некоторые общие ресурсы CPU, обеспечивая засыпание на более продолжительное время. Причина спиннинга — попытка быстрее получить блокировку без обращения к ядру. Если так, то увеличение нагрузки на CPU было бы лишь номинальным, но вообще не влияло на производительность, потому что ядра занимаются другими задачами. Но тесты показали снижение производительности в почти однопоточных операциях, где один поток добавляет что-то в рабочую очередь, в то время как рабочий поток ожидает результат, а затем выполняет некую задачу с рабочим элементом.
Причину проще всего показать на схеме. Спин для состязательной блокировки происходит с утроением спиннинга на каждом шаге. После каждого раунда блокировка снова проверяется на предмет того, может ли текущий поток её получить. Хотя спиннинг пытается быть честным и время от времени переключается на другие потоки, чтобы помочь им завершить свою работу. Это увеличивает шансы на освобождение блокировки при следующей проверке. Проблема в том, что проверка на взятие возможна только по завершении полного спин-раунда:

Например, если в момент начала пятого спин-раунда блокировка сигнализирует о доступности, взять её можно только по завершении раунда. Вычислив длительность спина последнего раунда, можно оценить худший случай задержки, для нашего потока:

Много миллисекунд ожидания до окончания спиннинга. Это реальная проблема?
Я создал простое тестовое приложение, в котором реализована очередь производителей-потребителей, где рабочий поток выполняет каждый элемент работы 10 мс, а у потребителя задержка 1-9 мс перед следующим рабочим элементом. Этого достаточно, чтобы увидеть эффект:
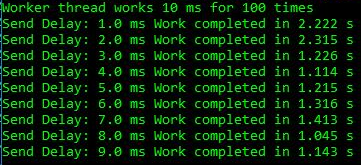
Мы видим для задержек в 1-2 мс общую продолжительность 2,2-2,3 с, тогда как в других случаях работа выполняется быстрее вплоть до 1,2 с. Это показывает, что чрезмерный спиннинг на CPU — не просто косметическая проблема чрезмерно многопоточных приложений. Она реально вредит простой поточности производителя-потребителя, включающей только два потока. Для прогона выше данные ETW говорят сами за себя: именно рост спиннинга является причиной наблюдаемой задержки:
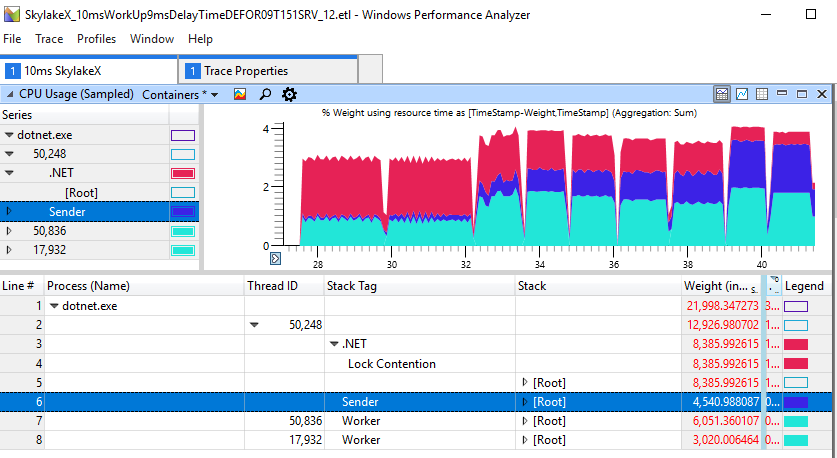
Если внимательно посмотреть на секцию с «тормозами», мы увидим в красной области 11 мс спиннинга, хотя воркер (светло-синий) завершил свою работу и давно отдал блокировку.
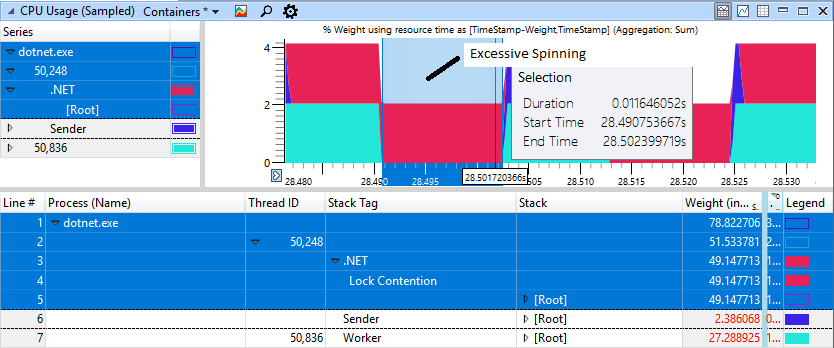
Быстрый недегенативный случай выглядит намного лучше, здесь только 1 мс тратится на спиннинг для блокировки.
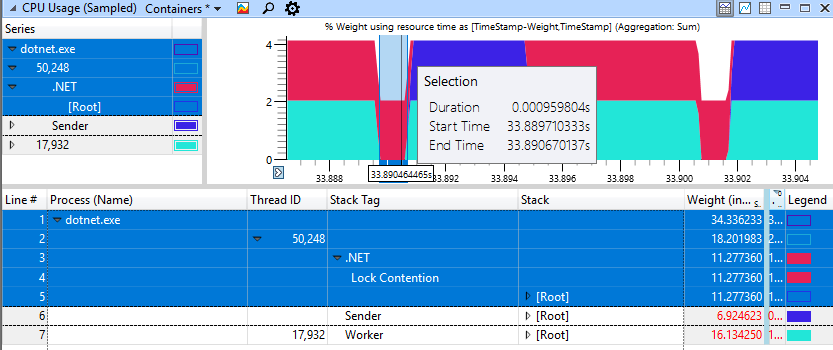
Я использовал тестовое приложение SkylakeXPause. В zip-архиве собраны исходный код и двоичные файлы для .NET Core и .NET 4.5. Для проведения сравнения я установил .NET 4.8 Preview с исправлениями и .NET Core 2.0, который по-прежнему реализует старое поведение. Приложение предназначено для .NET Standard 2.0 и .NET 4.5, производящих и exe, и dll. Теперь можно проверить старое и новое поведение спиннинга бок о бок без необходимости что-либо исправлять, так очень удобно.
readonly object _LockObject = new object();
int WorkItems;
int CompletedWorkItems;
Barrier SyncPoint;
void RunSlowTest()
{
const int processingTimeinMs = 10;
const int WorkItemsToSend = 100;
Console.WriteLine($"Worker thread works {processingTimeinMs} ms for {WorkItemsToSend} times");
// Test one sender one receiver thread with different timings when the sender wakes up again
// to send the next work item
// synchronize worker and sender. Ensure that worker starts first
double[] sendDelayTimes = { 1, 2, 3, 4, 5, 6, 7, 8, 9 };
foreach (var sendDelay in sendDelayTimes)
{
SyncPoint = new Barrier(2); // one sender one receiver
var sw = Stopwatch.StartNew();
Parallel.Invoke(() => Sender(workItems: WorkItemsToSend, delayInMs: sendDelay),
() => Worker(maxWorkItemsToWork: WorkItemsToSend, workItemProcessTimeInMs: processingTimeinMs));
sw.Stop();
Console.WriteLine($"Send Delay: {sendDelay:F1} ms Work completed in {sw.Elapsed.TotalSeconds:F3} s");
Thread.Sleep(100); // show some gap in ETW data so we can differentiate the test runs
}
}
/// <summary>
/// Simulate a worker thread which consumes CPU which is triggered by the Sender thread
/// </summary>
void Worker(int maxWorkItemsToWork, double workItemProcessTimeInMs)
{
SyncPoint.SignalAndWait();
while (CompletedWorkItems != maxWorkItemsToWork)
{
lock (_LockObject)
{
if (WorkItems == 0)
{
Monitor.Wait(_LockObject); // wait for work
}
for (int i = 0; i < WorkItems; i++)
{
CompletedWorkItems++;
SimulateWork(workItemProcessTimeInMs); // consume CPU under this lock
}
WorkItems = 0;
}
}
}
/// <summary>
/// Insert work for the Worker thread under a lock and wake up the worker thread n times
/// </summary>
void Sender(int workItems, double delayInMs)
{
CompletedWorkItems = 0; // delete previous work
SyncPoint.SignalAndWait();
for (int i = 0; i < workItems; i++)
{
lock (_LockObject)
{
WorkItems++;
Monitor.PulseAll(_LockObject);
}
SimulateWork(delayInMs);
}
}Выводы
Это не проблема .NET. Затронуты все реализации спинлока, использующие инструкцию pause. Я по-быстрому проверил ядро Windows Server 2016, но там на поверхности нет такой проблемы. Похоже, Intel была достаточно любезна — и намекнула, что необходимы некоторые изменения в подходе к спиннингу.
О баге для .NET Core сообщили в августе 2017 года, а уже в сентябре 2017 года вышел патч и версия .NET Core 2.0.3. По ссылке видна не только великолепная реакция группы .NET Core, но и то, что несколько дней назад проблема устранена в основной ветке, а также дискуссия о дополнительных оптимизациях спиннинга. К сожалению, Desktop .NET Framework двигается не так быстро, но в лице .NET Framework 4.8 Preview у нас есть хотя бы концептуальное доказательство, что исправления там тоже реализуемы. Теперь я жду бэкпорт для .NET 4.7.2, чтобы использовать .NET на полной скорости и на последнем железе. Это первый найденный мною баг, который непосредственно связан с изменением производительности из-за одной инструкции CPU. ETW остаётся основным профайлером в Windows. Если бы я мог, то попросил бы Microsoft портировать инфраструктуру ETW на Linux, потому что текущие профайлеры в Linux по-прежнему отстойные. Там недавно добавили интересные возможности ядра, но инструментов анализа вроде WPA до сих пор нет.
Если вы работаете с .NET Core 2.0 или десктопным .NET Framework на последних процессорах, которые выпускались с середины 2017 года, то в случае проблем со снижением производительности следует обязательно проверить свои приложения профайлером — и обновиться на .NET Core и, надеюсь, вскоре на .NET Desktop. Моё тестовое приложение скажет вам о наличии или отсутствии проблемы.
D:\SkylakeXPause\bin\Release\netcoreapp2.0>dotnet SkylakeXPause.dll -check
Did call pause 1,000,000 in 3.5990 ms, Processors: 8
No SkylakeX problem detected или
D:\SkylakeXPause\SkylakeXPause\bin\Release\net45>SkylakeXPause.exe -check
Did call pause 1,000,000 in 3.6195 ms, Processors: 8
No SkylakeX problem detected Инструмент сообщит о проблеме, если вы работаете на .NET Framework без соответствующего апдейта и на процессоре Skylake.
Надеюсь, вам расследование этой проблемы показалось настолько же увлекательным, как и мне. Чтобы по-настоящему понять проблему, нужно создать средство её воспроизведения, позволяющее экспериментировать и искать влияющие факторы. Остальное — просто скучная работа, но теперь я намного лучше разбираюсь в причинах и последствиях циклической попытки получить блокировку в CPU.
Комментарии (54)

ange007
25.06.2018 02:57«Если вы покупаете новейшее железо, то получите процессор с архитектурой Skylake.»
Прошу прощения но с телефона (из приложения) не понятно это перевод или нет?
Сейчас 8 поколение — CoffeLake, а Skylake это 6.
Думается сейчас ситуация уже должна измениться, или нет?VADemon
25.06.2018 06:03Микроархитектура у Intel не менялась со времени выхода первого Skylake для ПК: Skylake 6xxx — Kaby Lake 7xxx (14nm+) — Cofee Lake 8xxx (14nm++, 6 ядер в настольном сегменте)
Серверные процессоры: Skylake-X и Skylake-SP (заменили кольцевую шину на меш). Только лишь на конец года намечен преемник — Cascade Lake.
nidalee
25.06.2018 06:18На самом деле даже архитектура не имеет значения — это изменение Intel сделал по каким-то своим соображениям специально, а значит в следующих архитекутрах (скорее всего) будет повторять.
dimkrayan
25.06.2018 08:36Предположу, что это сделано для того, чтобы иметь большую возможность распоряжаться ресурсами во время wait-а.
Если как сказано выше «спиннинг начинается с 50 вызовов паузы» — так почему бы грубо говоря вместо 50 не сделать 1 вызов? Зачем возвращаться?
Наверное, решение правильное, если вовремя поддержать это производителями софта.vagran
25.06.2018 09:19И на мой взляд проблема всё-таки в .net. Почему 50, а не 42? Они делают какие-то допущения о длительности паузы, вместо того, чтобы проверить, сколько реально прошло (чтением tsc, например). Вполне возможно, что длительность паузы в будущих процессорах вообще станет динамической, в зависимости от состояния конвеера на других логических ядрах.
dimkrayan
25.06.2018 09:31А как узнать, что прошло N квантов времени? Для этого нужно прерваться и сравнить. Будете слишком часто прерываться — производительность упадет. Будете слишком много вычислять во время спинлока — производительность упадет.
Плюс, предположу, что сам по себе получение текущего времени — обращение к ядру. Так зачем тогда спинлок?
Вообще, эта задержка должна легко вычисляться при старте программы. Видимо, не ожидали.vagran
25.06.2018 10:12Инструкция процессора такая есть — rdtsc, в большинстве ОС доступна в user space. Ничего прерывать или обращаться к ядру не надо.
dimkrayan
25.06.2018 11:54спасибо, не писал на ассемблере(и не интересовался новыми инструкциями) со времен 486.
Но все равно, 50 раз уснуть — это намного проще, чем уснуть, прочитать, сравнить… и не задействует ценные блоки процессора. А нужное количество тактов можно и при старте посчитать.
Плюс, интересно, что это значит: «Точные замеры могут быть невозможны при однократном исполнении измеряемого фрагмента инструкций из-за влияния кэшей процессора при обращении к памяти. Традиционно решается многократным измерением фрагмента программы или повторением измеряемого фрагмента в цикле.» Если оно может слишком рано выйти из спинлока — думаю, это не очень страшно. А если слишком поздно (тем более — если неограниченно поздно) — могут быть проблемы.
Aquahawk
25.06.2018 15:02С rdtsc тоже всё не просто. 1. Это счётчик циклов в процессоре с плавающей частотой. Вы получите такты а не циклы. 2. Это счётчик конкретного ядра. Если ОС перебросит вас на другое ядро, то вы получите совершенно другой счётчик, он может быть как больше так и меньше. 3. Не помню его битности но лично сталкивался с его переполнением на долго работающих машинах, да и вообще с уровня драйвера в него писать может кто угодно что угодно, во всяком случае на CORE2 архитектуре, когда я этим занимался, мы случайно набажили в драйвере и вместо считывания писали туда нули на каждом переключении контекста, что удивительно ничего не ломалось.
dimkrayan
25.06.2018 15:11ну, переполнение — не страшно в данном контексте. А вот прочитать данные из другого ядра — это может все сломать и вместо нескольких сотен тактов процессора прождете пол-дня.
А расскажите пожалуйста, где сейчас востребована эта магия? Можно ли по удаленке устроиться? А то иногда хочется чуть большего, чем в спринге аннотации развешивать.Aquahawk
26.06.2018 11:38Студенческий проект по разработке профилировщика. Performance countres, хук swapContext в винде xp. И собирали метрики о кешмиссах и прочих тормозных ситуация в проце. Хукать надо потому что эти счётчики считают метрики просто по ядру и ему пофиг что там задачи переключаются.
Temtaime
25.06.2018 15:251. Такт и цикл это синонимы. Что вы имеете в виду? Если вы про то, что процессор может уменьшать или увеличивать частоту, то это не приводит к тому, что иногда время измеряется быстрее, а иногда медленней — возвращаемое число тактов имеет константный интервал. Т.е. rdtsc игнорирует состояния энергосбережения процессора.
2. Нет, на современных процессорах счётчики синхронны между ядрами. Поэтому rdtsc предлагают иногда в качестве замены ACPI и HPET, т.к. накладные расходы минимальны.
3. Его разрядность 64 бита. Не знаю, что у вас за машины, но 2^64 / 3 giga / 60 / 60 / 24 / 365 даёт результат в 194980805785024010823 лет для его переполнения.
Как это вы его изменяли, если его невозможно изменить и есть только инструкция считывания? Его может сбросить только перезагрузка ПК.Aquahawk
26.06.2018 11:36Дело было в 2007 году примерно, тогда точно на CORE 2 разные на разных ядрах были. Про переполнение опять же дело было на 32х битных ОС. Может только половинку его читали. Деталей точно не припомню, но у интела есть специальные регистры для снятия метрик производительности, количество фейлов бранч предиктора, кешмиссов и тп. И эти штуки из драйвера можно настроить. Мы делали профилировщик и на swapContext снимали метрики всякие. И тогда при ошибки получили обнуление TSC.
DistortNeo
25.06.2018 17:14+11, 2. Насколько я помню, RDTSC уже давно является таймером, а не счётчиком циклов, причём синхронизированным между ядрами. Точнее, это зависит от режима работы процессора.
The time stamp counter in newer processors may support an enhancement, referred to as invariant TSC. Processor’s support for invariant TSC is indicated by CPUID.80000007H:EDX[8]. The invariant TSC will run at a constant rate in all ACPI P-, C-. and T-states. This is the architectural behavior moving forward. On processors with invariant TSC support, the OS may use the TSC for wall clock timer services (instead of ACPI or HPET timers). TSC reads are much more efficient and do not incur the overhead associated with a ring transition or access to a platform resource.
3. Да пускай переполняется, нас же разница интересует, а не абсолютное значение.
Aquahawk
26.06.2018 11:40Хм интересно, а как теперь именно такты померять? Для некоторых вещей в тактах как раз ценнее инфа чем в абсолютном времени.
DistortNeo
25.06.2018 17:17Главное не оказаться в ситуации, когда rdtsc доступна, но виртуализована, т.е. один вызов rdtsc превратится в несколько сот тактов из-за обращения к гипервизору.
Danik-ik
25.06.2018 19:47Вычисление паузы — проходили уже, когда программы на паскале с модулем crt (любые с цветным выводом в текстовом режиме) в конце 90-х начали вываливаться при запуске с делением на ноль. Скорость вычисляли. И тоже при этом "не ожидали". Нет в мире совершенства.
dimkrayan
25.06.2018 19:58а что мешает такой же факап допустить при вычислении паузы в любое другое время?
Raimon
25.06.2018 12:18Кстати в оригинальной статье, разработчик из MS написал workaround для текущих версий .NET, через изменение значений в реестре:
aloiskraus.wordpress.com/2018/06/16/why-skylakex-cpus-are-sometimes-50-slower-how-intel-has-broken-existing-code/#comment-274
Antervis
25.06.2018 14:27На самом деле, алгоритм предусматривает определенные допущения:
Спиннинг в .NET использует алгоритм экспоненциальной выдержки, когда он начинается с цикла из 50-ти вызовов pause, где для каждой итерации количество спинов утраивается, пока следующий счётчик спинов не превысит их максимальную продолжительность.
Планка может быть и не 50. Это значение явно было выбрано из каких-то формальных оценок (скорее всего, энергопотребления), не учитывающих скайлейки. Ну, бывает, поставят 5-10 и будет всё почти как раньше.
Axam
26.06.2018 03:20На серверный рынок Skylake попал с значительным опозданием. У крупных производителей модели начали появляеться в прошлом году только. Intel Xeon Scalable Gold/Platinum основан на Skylake микроархитектуре. Более новых процессоров пока нет.
Skerrigan
26.06.2018 07:54Меня другое интригует — я себе стац в конце 2015-го собирал на самых-самых первых Skylake, какие только появились на Amazone. А тут речь ведут про:
на последних процессорах, которые выпускались с середины 2017 года,
И как это понимать то? Автор допустил ошибку или смена (микро-изменение) логики вышла позже, чем я железо себе сменил?
Arxitektor
25.06.2018 06:42это изменение Intel сделал по каким-то своим соображениям специально
А потом уберут и всем будет хорошо. )
Сделай плохо и затем верни как было )
Ну ни фига себе. На амд такого нет?
И ведь проблема как я понял будет везде где есть эта инструкция.
Больше ядер хороших и быстрых.SergeyMax
25.06.2018 15:50+1На амд такого нет?
As I said before – AMD has a different latency, so it’s an issue with a software in the first place.
Bulldozer – 50
Zen – 10
Jaguar – 50
Pretty big difference from pre Skylake architectures
aamonster
25.06.2018 08:38Я правильно понимаю, что проблема только с кодом, который много и часто ждёт освобождения Critical Section?
Если да — можно выдохнуть: такой код всё равно оставлять нельзя (надо уменьшать периоды локов или переходить на lock-free структуры данных). Ну и MS, опять же, заткнул со своей стороны.roscomtheend
25.06.2018 09:16MS звткнул — другие не заткнули, есть ещё унаследованный код, есть AMD с другими временами, есть более старые процессоры с другими временами.
RKGeek
25.06.2018 11:10Тоже согласен что к многопоточному программированию лучше так не подходить, один раз подождал блокировку и получил огромную пачку данных для работы, а не каждый раз ждать небольшую порцию.
aamonster
25.06.2018 12:00Если "получил огромную пачку для работы" — в идеале вообще не через наивные блокировки делать, а эту пачку давать как задание свободному (или специально созданному) воркеру.
Вообще многопоточность, грабли в ней и методы обхода этих граблей — интереснейшая тема, в которой регулярно всплывают новые (или хорошо забытые старые) решения.
tgregory
25.06.2018 13:09К сожалению, не всякая вычислительная задача укладывается в подобную парадигму. В некоторых задачах требуется обмен информацией между потоками в малых объёмах с низкой задержкой и высокой частотой.
RKGeek
26.06.2018 07:02кстати данная статья как раз доказывает что C# это не про производительность и что бы торговые роботы не сорили деньгами их нужно писать на C/C++/Asm/Go
Antervis
26.06.2018 11:41+1а с чего вы взяли что под капотом примитивов синхронизации в c/c++/go не используются те же самые спинлоки на тех же самых инструкциях паузы?
Antervis
25.06.2018 14:29авторы торговых роботов за каждую микросекунду воюют, а вы предлагаете подождать пачку…
DistortNeo
25.06.2018 17:20Вряд ли авторы торговых роботов используют библиотечные решения для своих задач.
RKGeek
25.06.2018 18:40Например при обработке колизий в физическом движке можно хорошо распаралелить нахождение столкновений и тоже касается рассчетов силы и скоростей, или например в задачах факторизации чисел.
olgerdovich
26.06.2018 01:26Если я правильно понимаю, то это как раз тот случай, когда gpu в разы быстрее делают работу cpu за в разы меньший прайс? Может, тогда им это и предоставить?
RKGeek
26.06.2018 07:07Вообще GPU это процессор для графики, на него лучше грузить задачи по отрисовке. Можно сказать что тут нужен баланс загрузки ресурсов.
Antervis
26.06.2018 09:09+1любые хорошо распараллеливающиеся вычисления с плавающей точкой имеет смысл вычислять на GPU. Включая ту самую физику коллизий (PhysX, например), машинное обучение, майнинг и много чего еще
Raimon
25.06.2018 08:58удивительная история, спасибо за расследование. как будто уже сталкивался с таким. а как дела обстоят под виртуализацией? по идее тоже должно воспроизводится.
stanislavskijvlad
25.06.2018 09:14"Я по-быстрому проверил ядро Windows Server". Крутой вы ))
(no irony)
rinnaatt
25.06.2018 12:52сделал замер в mono (linux) на AMD Ryzen, проблем нет:
rinat@linuxmint-desktop ~/SkylakeXPause/SkylakeXPause/bin/Release/net45 $ mono SkylakeXPause.exe -check Did call pause 1 000 000 in 0,8401 ms, Processors: 8 No SkylakeX problem detected
vtsymbal
25.06.2018 14:09Если бы я мог, то попросил бы Microsoft портировать инфраструктуру ETW на Linux, потому что текущие профайлеры в Linux по-прежнему отстойные. Там недавно добавили интересные возможности ядра, но инструментов анализа вроде WPA до сих пор нет.
Бесспорно, WPA — неплохой профайлер для Windows, но не единственный, а из статьи создается впечатление, что без него прямо никак. Автор оригинального текста сильно не в курсе про профайлеры под Linux.0xd34df00d
25.06.2018 18:09Интересно, кстати, как бы выглядел этот анализ с vtune.
vtsymbal
25.06.2018 19:02На Windows он бы выгдядел как спин-локи в топах объектов ожидания, и соответственно, стеки вызовов функций синхронизации. Но в WPA выглядит красивее, т.к. VTune не инструментирует .Net API и не покажет, например, Sender/Worker.

mvy
25.06.2018 22:06У ETW/WPA только один недостаток — нет микроархитектурных данных. Иногда нужно видеть зарежки при доступе к памяти, проблемы с предсказанием ветвлений.
askad
25.06.2018 22:06Как исправить
D:\SkylakeXPause\SkylakeXPause\bin\Release\net45>SkylakeXPause.exe -check
Did call pause 1 000 000 in 62,6168 ms, Processors: 4
SkylakeX CPU with unpatched .NET Framework detected.
последние патчи и фреймворк стоят
винда 10 домашняя
Carburn
26.06.2018 01:30Хорошо, что я использую процессор 2013 года версии U и у меня такой проблемы нет.
dimkrayan
Интересно, а как с этим у джавы?
И у других языков?
MikeVentris
Да, очень интересно было бы посмотреть на подобное исследование по другим языкам. Скажем, Java и Gо — как другие представители популярных языков, где рядовые разработчики часто не задумываются, как оно живет «под капотом».
nikitasius
Блаблабла, сейчас столько фреймворков, что почти всем пофигу как оно живет под капотом.
dimkrayan
до тех пор, пока из-под капота дым не пойдет в виде замедления работы.