
 Для меня это началось шесть с половиной лет назад, когда волею судеб меня затянуло в один закрытый проект. Чей проект — не спрашивайте, не расскажу. Скажу лишь, что идея его была проста как грабли: встроить clang front-end в IDE. Ну, как это недавно сделали в QtCreator, в CLion (в некотором смысле), и т. п. Clang тогда был восходящей звездой, многие тащились от появившейся, наконец, возможности использовать полноценный C++-парсер почти на халяву. И идея, так сказать, буквально витала в воздухе (да и встроенный в clang API автокомплит кода как бэ намекал), надо было просто взять и сделать. Но, как говорил на Боромир, "Нельзя просто так взять, и...". Так получилось и в этом случае. За подробностями — велкам под кат.
Для меня это началось шесть с половиной лет назад, когда волею судеб меня затянуло в один закрытый проект. Чей проект — не спрашивайте, не расскажу. Скажу лишь, что идея его была проста как грабли: встроить clang front-end в IDE. Ну, как это недавно сделали в QtCreator, в CLion (в некотором смысле), и т. п. Clang тогда был восходящей звездой, многие тащились от появившейся, наконец, возможности использовать полноценный C++-парсер почти на халяву. И идея, так сказать, буквально витала в воздухе (да и встроенный в clang API автокомплит кода как бэ намекал), надо было просто взять и сделать. Но, как говорил на Боромир, "Нельзя просто так взять, и...". Так получилось и в этом случае. За подробностями — велкам под кат.
Сначала о хорошем
Бенефиты от использования clang'а в качестве встроенного в IDE C++-парсера, безусловно, есть. В конце концов, функции IDE не сводятся только и исключительно к редактированию файлов. Это и база данных символов, и задачи навигации, и зависимости, и многое другое. И вот тут полноценный компилятор рулит во весь рост, ибо осилить всю мощь препроцессора и шаблонов в относительно простом самописном парсере — задача нетривиальная. Ибо обычно приходится идти на массу компромиссов, что очевидным образом влияет на качество разбора кода. Кому интересно — может посмотреть, скажем, на встроенный парсер QtCeator'а здесь: Qt Creator C++ parser
Там же, в исходниках QtCreator'а, можно увидеть, что перечисленное выше — далеко не всё, что требуется IDE от парсера. Кроме того нужно как минимум:
- подсветка синтаксиса (лексическая и семантическая)
- всяческие хинты "на лету" с отображением информации по символу
- подсказки о том, что с кодом не так и как это можно исправить/дополнить
- автодополнение (Code Completion) в самых разнообразных контекстах
- самый разнообразный рефакторинг
Поэтому на ранее перечисленных преимуществах (действительно серьёзных!) плюсы заканчиваются и начинается боль. Чтобы лучше эту боль понять, можно для начала посмотреть доклад Анастасии Казаковой (anastasiak2512) о том, что же на самом деле требуется от встроенного в IDE парсера кода:
Суть проблемы
А она проста, хоть может быть и неочевидна с первого взгляда. Если в двух словах, то: clang — это компилятор. И к коду относится как компилятор. И заточен на то, что код ему дают уже законченный, а не огрызок файла, который открыт сейчас в редакторе IDE. Огрызки файлов компиляторы не любят, как и незавершенные конструкции, неправильно написанные идентификаторы, retrun вместо return и прочие прелести, которые могут возникнуть здесь и сейчас в редакторе. Разумеется, перед компиляцией всё это будет вычищено, поправлено, приведено в соответствие. Но здесь и сейчас, в редакторе, оно такое, какое есть. И именно в таком виде попадает на стол встроенному в IDE парсеру с периодичностью раз в 5-10 секунд. И если самописная его версия прекрасно "понимает", что имеет дело с полуфабрикатом, то вот clang — нет. И очень сильно удивляется. Что получится в результате такого удивления — зависит "от", как говорится.
К счастью, clang достаточно толерантен к ошибкам в коде. Тем не менее, могут быть и сюрпризы — пропадающая вдруг подсветка, кривой автокомплит, странная диагностика. Ко всему этому нужно быть готовым. Кроме того, clang не всеяден. Он вполне имеет право не принимать что-нибудь в заголовках компилятора, который здесь и сейчас используется для сборки проекта. Хитрые интринсики, нестандартные расширения и прочие, эм..., особенности — все это может приводить к ошибкам разбора в самых неожиданных местах. Ну и, конечно же, перформанс. Редактировать файл с грамматикой на Boost.Spirit или работать над llvm-based-проектом будет одно удовольствие. Но, обо всём подробнее.
Код-полуфабрикат
Вот, скажем, начали вы новый проект. Вам среда сгенерировала дефолтную болванку для main.cpp, и в ней вы написали:
#include <iostream>
int main()
{
foo(10)
}Код, с точки зрения C++, прямо скажем, невалидный. В файле нет определения функции foo(...), строка не завершена и т. п. Но… Вы только начали. Этот код имеет право именно на такой вид. Как этот код воспринимает IDE с самописным парсером (в данном случае CLion)?
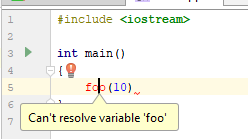
И если нажать на лампочку, то можно увидеть вот что:
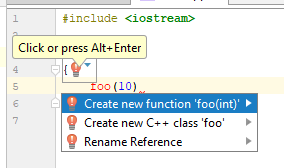
Такое IDE зная нечто, гм, большее о том, что происходит, предлагает вполне ожидаемый вариант: создать функцию из контекста использования. Отличное предложение, я считаю. Как же ведёт себя IDE на базе clang (в данном случае — Qt Creator 4.7)?
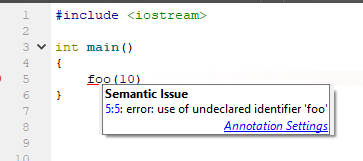
И что предлагается для того, чтобы исправить ситуацию? А ничего! Только стандартный rename!
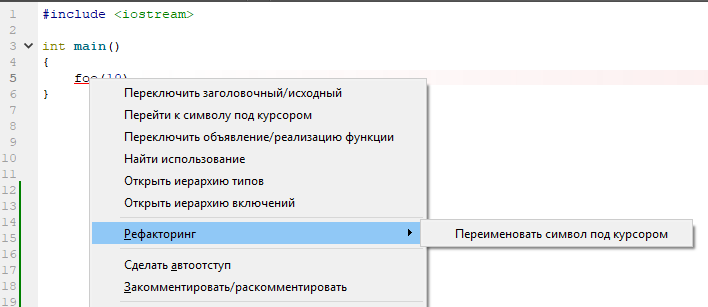
Причина такого поведения весьма проста: для clang'а этот текст является законченным (а ничем другим он и не может быть). И AST он строит исходя из этого предположения. А дальше всё просто: clang видит неопределённый ранее идентификатор. Это — текст на C++ (не на C). Никаких предположений о характере идентификатора не делается — он не определён, значит фрагмент кода — невалиден. И в AST для этой строчки ничего не появляется. Её просто нет. А чего нет в AST — то невозможно анализировать. Обидно, досадно, ну ладно.
Встроенный в IDE парсер исходит немного из других предположений. Он знает, что код — не закончен. Что у программиста вот прям сейчас прёт мысль и пальцы за ней не успевают. Поэтому не все идентификаторы могут быть определены. Такой код, конечно, некорректен с точки зрения высоких стандартов качества компилятора, но парсер знает, что с таким кодом можно сделать и предлагает варианты. Вполне разумные варианты.
Как минимум до версии 3.7 (включительно) похожие проблемы возникали в таком коде:
#include <iostream>
class Temp
{
public:
int i;
};
template<typename T>
class Foo
{
public:
int Bar(Temp tmp)
{
Tpl(tmp);
}
private:
template<typename U>
void Tpl(U val)
{
Foo<U> tmp(val);
tmp.
}
int member;
};
int main()
{
return 0;
}Внутри методов шаблонного класса автокомплит на основе clang'а не работал. Насколько мне удалось выяснить, причина была в двухпроходном парсинге шаблонов. Автокомплит в clang'е срабатывает на первом проходе, когда информации о фактически используемых типах может быть недостаточно. В clang 5.0 (судя по Release Notes) это починили.
Так или иначе, ситуации, в которых компилятор не в состоянии построить корректное AST (или сделать правильные выводы из контекста), в редактируемом коде вполне могут быть. И в этом случае IDE просто не будет "видеть" соответствующие участки текста и ничем не сможет помочь программисту. Что, разумеется, не здорово. Способность эффективно работать с некорректным кодом — это то, что жизненно необходимо парсеру в IDE, и что совершенно не нужно обычному компилятору. Поэтому парсер в IDE может использовать множество эвристик, которые для компилятора могут оказаться не только бесполезны, но и вредны. А реализовывать в нём два режима работы — ну, это ещё разработчиков убедить нужно.
"Эта роль — ругательная!"
IDE у программиста обычно одна (ну хорошо, две), а вот проектов и тулчейнов — много. И, разумеется, лишних телодвижений, чтобы переключиться с тулчейна на тулчейн, с проекта на проект, делать не хочется. Один-два клика, и конфигурация сборки меняется с Debug на Release, а компилятор — с MSVC на MinGW. А вот парсер кода в IDE остаётся прежним. И он должен, вместе с системой сборки, переключиться с одной конфигурации на другую, с одного тулчейна на другой. А тулчейн может быть какой-нибудь экзотический, или кросс. И задача парсера здесь — продолжить корректно разбирать код. По возможности с минимумом ошибок.
clang — достаточно всеяден. Его можно заставить принимать расширения компиляторов от Microsoft, компилятора gcc. Ему можно передать опции в формате этих компиляторов, и clang их даже поймёт. Но всё это не гарантирует, что clang примет какой-нибудь заголовок из потрохов собранного из танка gcc. Какие-нибудь __builtin_intrinsic_xxx могут стать для него камнем преткновения. Или языковые конструкции, которые текущая версия clang в IDE просто не поддерживает. На качество построения AST для текущего редактируемого файла это, вероятнее всего, не повлияет. А вот построение глобальной базы символов или сохранение precompiled-заголовков может сломаться. И это может оказаться серьёзной проблемой. Ещё большей проблемой может оказаться подобный код не в заголовках тулчейнов или thirdparty, а в заголовках или исходниках проекта. Кстати, всё это — достаточно существенная причина явно сообщать системе сборки (и IDE) о том, какие именно заголовочные файлы для вашего проекта "чужие". Это может упростить жизнь.
Опять же, IDE изначально рассчитана на то, что её будут использовать с разными компиляторами, настройками, тулчейнами и прочим. Рассчитана на то, что придётся иметь дело с кодом, часть элементов которого не поддерживается. Релизный цикл у IDE (не всех :) ) более короткий, чем у компиляторов, следовательно, есть потенциальная возможность более оперативно подтягивать новые фичи, реагировать на найденные проблемы. В мире компиляторов всё немного иначе: релизный цикл минимум в год, проблемы кросскомпиляторной совместимости решаются условной компиляцией и перекладываются на плечи разработчика. Компилятор не обязан быть универсальным и всеядным — его сложность и без того высока. clang тут не является исключением.
Борьба за скорость
Ту часть времени, проведенную за IDE, когда программист не сидит в отладчике, он редактирует текст. И его естественное желание здесь — это чтобы было комфортно (иначе зачем IDE? Можно и блокнотом обойтись!) Комфорт, в том числе, предполагает высокую скорость реакции редактора на изменения текста и нажатие хоткеев. Как верно заметила Анастасия в своём докладе, если через пять секунд после нажатия Ctrl+Space среда не отреагировала появлением менюшки или списка автокомплита — это ужасно (я серьёзно, сами попробуйте). В цифрах это означает, что у встроенного в IDE парсера есть примерно одна секунда, чтобы оценить изменения в файле и перестроить AST, и ещё полторы-две — чтобы предложить разработчику контекстно-зависимый выбор. Секунда. Ну, может две. Кроме того, ожидаемым поведением считается, что если разработчик поменял .h-ник, а потом переключился на .cpp-шник, то сделанные изменения будут "видны". Файлы то вот они, открытые в соседних окошках. А теперь простая калькуляция. Если clang, запущенный из командной строки, справляется с исходником секунд за десять-двадцать, то где основания полагать, что будучи запущенным из IDE он справится с исходником существенно быстрее и уложится в эту самую секунду-две? То есть сработает на порядок быстрее? В общем, на этом можно было бы и закончить, но я не буду.
Про десять-двадцать секунд на исходик я, конечно, утрирую. Хотя, если туда инклюдится какое-нибудь тяжёлое API или, скажем, boost.spirit с Hana наперевес, а потом всё это активно используется в тексте — то 10-20 секунд это ещё хорошие значения. Но даже если AST будет готово секунды через три-четыре после запуска встроенного парсера — это уже долго. При том условии, что такие запуски должны быть как регулярными (поддерживать модель кода и индекс в консистентном состоянии, подсвечивать, подсказывать и т. п.), а также по требованию — ведь code completion это тоже запуск компилятора. Можно ли как-то уменьшить это время? К сожалению, в случае использования clang в качестве парсера возможностей не так много. Причина: это thirdparty tool в который (в идеале) изменения вносить нельзя. То есть покопаться в коде clang'а perftool'ом, пооптимизировать, упросить какие-нибудь ветки — эти возможности недоступны и приходится обходиться тем, что предоставляет внешнее API (в случае использования libclang — оно ещё и достаточно узкое).
Первое, очевидное, и, на самом деле, единственное решение — это использовать динамически генерируемые precompiled headers. При адекватной реализации решение — убойное. Повышает скорость компиляции в разы как минимум. Суть его проста: среда собирает в один .h-файл все thirdparty-заголовки (или заголовки за пределами project root), делает из этого файла pch, после чего неявно включает этот pch в каждый исходник. Разумеется, появляется очевидный сайдеэффект: в исходниках (на этапе редактирования) могут быть видны символы, которые в него не include'ятся. Но это плата за скорость. Приходится выбирать. И всё было бы прекрасно, если бы не одна маленькая проблемка: clang это таки компилятор. И, будучи компилятором, он не любит ошибки в коде. И если вдруг (внезапно! — см. предыдущий раздел) в заголовках находятся ошибки, то .pch-файл не создаётся. По крайней мере так было вплоть до версии 3.7. Изменилось ли что-то с тех пор в этом отношении? Не знаю, есть подозрение, что нет. Возможности проверить тоже увы, уже нет.
Альтернативные варианты увы, недоступны всё по той же причине: clang — это компилятор и вещь "в себе". Активно вмешаться в процесс генерации AST, каким-либо образом заставить его мерджить AST из разных кусков, вести внешние базы символов и тэ дэ и тэ пэ — увы, все эти возможности недоступны. Только внешнее API, только хардкор и настройки, доступные через опции компиляции. А потом анализ результирующей AST. Если садиться на C++-версию API, то возможностей становится доступно чуть больше. Например, можно поиграться с кастомными FrontendAction'ами, сделать более тонкую настройку опций компиляции и т. п. Но и в данном случае основная суть не изменится — редактируемый (или индексируемый) текст будет откомпилирован независимо от других и полностью. Всё. Точка.
Возможно (возможно!) когда-нибудь появится форк апстрима clang'а, специально заточенный на использование в составе IDE. Возможно. Но пока что всё так, как оно есть. Скажем, у команды Qt Creator'а интеграция (до стадии "окончательно") с libclang'ом заняла семь лет. Я попробовал QtC 4.7 с движком на базе libclang — признаюсь, старый вариант (на самописном) лично мне нравится больше, просто потому, что на моих кейсах он работает лучше: и подсказывает, и подсвечивает, и всё остальное. Не возьмусь оценивать, сколько человекочасов они на эту интеграцию потратили, но рискну предположить, что за это время можно было бы свой собственный парсер допилить. Насколько я могу судить (по косвенным признакам), команда, работающая над CLion, в сторону интеграции с libclang/clang++ смотрит с опаской. Но это сугубо личные предположения. Интеграция на уровне Language Server Protocol — интересный вариант, но конкретно для случая C++ я склонен рассматривать это больше как паллиатив по перечисленным выше причинам. Просто переносит проблемы с одного уровня абстракции на другой. Но, возможно, я ошибаюсь и за LSP — будущее. Посмотрим. Но так или иначе, жизнь разработчиков современных IDE для C++ полна приключений — с clang'ом в качестве бэкенда, или без него.
Комментарии (17)

ianzag
03.08.2018 17:08Смотрю в QtCreator 4.7 — clang backend опционален. Его можно не включать и в этом случае будет использоваться родной анализатор. Дальше уже каждый как ему нравится.
FlexFerrum Автор
03.08.2018 17:09Всё так. Только начиная с 4.7 clang backend по-умолчанию включен. И, насколько я понял из комментариев к релизу, развивать они дальше будут именно эту ветку, а не самописный парсер.
sergey_shambir
03.08.2018 17:22Такое IDE зная нечто, гм, большее о том, что происходит, предлагает вполне ожидаемый вариант: создать функцию из контекста использования.
Есть ещё вариант: если название похоже на другое название, то надо предложить исправить опечатку; clang это умеет делать, и QtCreator ЕМНИП умеет этим пользоваться.
Так что не всё так плохо с clang.FlexFerrum Автор
03.08.2018 17:47+2Да. Есть такая фича у clang. А теперь история о том, как я её нашёл. В попытках поднять перформанс работы связки IDE + clang я полез смотреть, а на что же clang тратит процессорное время. И довольно быстро обнаружил в первой двадцатке функций алгоритм подсчёта дистанции Левенштейна. «Что за фигня? — думаю, — Зачем?». Полез копаться дальше и наткнулся как раз на алгоритм подбора подходящего идентификатора к «неправильно написанному» в рамках видимого скоупа. Хорошая фича для компилятора. Но при работе в связке с IDE, когда компиляция запускается буквально на каждый чих — эмм… Не уверен. При условии, что невалидных идентификаторов может быть в достатке по тем или иным причинам. Пробежаться по скоупу может может и код, который автокомплит делает, а не FixIt-хинты для найденных ошибок. При работе в связке с IDE, разумеется.
haoNoQ
03.08.2018 18:07Как Вам
clangdпосле этого? Нужно/ненужно, поможет/не поможет?FlexFerrum Автор
03.08.2018 18:12Я не могу сходу ответить на этот вопрос — надо изучать реализацию. Могу лишь сказать, что наличие возможности в рамках одного проекта работать над исходниками с разными опциями компиляции/тулчейнами (что может серьёзно отражаться на AST) наличие единого сервера для моделей кода исходников становится сомнительным бенефитом. В контексте С++, разумеется. Но, возможно, это проблема как-то решена.
apro
03.08.2018 19:10Недавно было интересное обсуждение в рассылки clang,
называлось "clangd/libclang: how to emulate other compilers?"
Думаю там можно посмотреть как clangd собирается бороться с этим.
Интересная и уникальная возможность clangd на мой взгляд это индексация
во время компиляции, собрал проект — вот тебе и индекс, а то переключаешься
с проекта на проект и начинается — компиляция того что поменяли, плюс IDE
индексы перестраивает...dkozh
03.08.2018 22:38+2Интересная и уникальная возможность clangd на мой взгляд это индексация
во время компиляцииЭто работает, если есть возможность пересадить пользователя IDE на нужный компилятор (причем, желательно, свежий, а еще и свой форк, а то иначе функциональность IDE начинает зависить от того, что приняли в upstream, а что еще не успели). Кроме Apple+Xcode (которые, собственно, этот index-while-building и сделали) и in-house разработки в Google (которые в основном вкладываются в clangd), ни у кого такой возможности нет (ну еще MSVC, но там отдельная история).
Cheater
03.08.2018 19:38+1Мб захотите глянуть в сторону rtags — весьма хороший индексировщик C++, основанный на clang, работает в фоне в виде демона. Я его использую в своей IDE (emacs + cedet + rtags), ошибки подсветки несуществующего foo() у себя не наблюдаю.
Хотя, если честно, я обычно отключаю автодополнение/навигацию полностью, за исключением самых «тупых» функций (базовое текстовое автодополнение по C-/, вызов списка определений ф-й в данном файле, перескочить между cpp/h, и тому подобное). Скорость решает, ради неё можно жертвовать функциональностью. 5 секунд реакции на нажатие хоткея — это вечность (хотя 5 секунд в rtags не видел ни разу), IDE должна реагировать на нажатие клавиши за полсекунды. Замену имён и кодогенерацию можно опять же делать чисто текстовыми средствами (vim :bufdo и аналоги, сниппеты).
dkozh
03.08.2018 19:45+9Спасибо за статью!
(disclamer: я — разработчик в команде CLion, но я не обязательно сейчас рассказываю про наши планы или транслирую мнение компании, просто абстрактно рассуждаю исходя из своего опыта).
Описанная картина довольно мрачная и примерно соответствует действительности, но некоторые факты позволяют смотреть в будущее более позитивно:
- Поддержка IDE является одной из целей проекта, и, хотя пока она в достаточно примитивном состоянии, для нее заложен неплохой базис
- Достаточно много проектов вкладывается в IDE-составляющую clang, и достаточно много людей работает над этим на постоянной основе
- Если не использовать libclang (и не заботиться о том, чтобы работать со старыми стабильными версиями clang-а из коробки), то можно сделать достаточно много через C++ API уже сейчас.
В CLion 2018.2 мы включили подсветку ошибок через clang (по умолчанию в Linux и Mac, Windows на подходе), ограничимся мы ли только этим, или пойдем дальше — вопрос, требующий исследования, но смотрим мы на это все с осторожным оптимизмом.
Зачем — потому что хочется сконцентрироваться на создании крутых фич и полировке функционала, который реально полезен пользователям, а не гнаться за стандартами, творчески перереализовывая огромное количество кода из компилятора. При этом правильная поддержка языка сама по себе не приносит пользователям никакой дополнительной выгоды, а вот зато ее отсутствие — сразу заметно, потому что все новейшие идиомы и темные места C++ тут же проникают в пользовательский код через шаблоны используемых библиотек.
При этом все те оптимизации, которые позволяют IDE быть быстрее компилятора — это же не магия какая-то, возможная потому, что мы в IDE — надо сделать все ровно то же самое, что и компилятор, только в большем объеме сложнее (всякие ленивости и инкрементальности не достаются бесплатно с точки зрения поддержки и количества багов). Сэкономить негде — это же C++, в нем любой пункт из стандарта может повлиять (и влияет) на что угодно — от индексации до форматирования.
Чуть-чуть по статье:
И если самописная его версия прекрасно "понимает", что имеет дело с полуфабрикатом, то вот clang — нет. И очень сильно удивляется. Что получится в результате такого удивления — зависит "от", как говорится.
Это не принципиальное ограничение компилятора, это вопрос качества восстановления от ошибок. Это больше искусство, чем наука, и во многих случаях clang работает хуже, чем, например, CLion (а в каких-то — лучше). Но "поругаться на ошибку и пойти дальше, предположив, что же имелось в виду" — базовая функциональность компилятора, и в clang тоже потрачено много усилий на это. IDE, конечно, может немножечко пожертвовать корректностью работы на правильном, но экзотическом коде, чтобы лучше восстанавливаться на недописанном, но неправильном, но вообще такие жертвы обычно выходят боком через какое-то время (когда в STL написали как раз то, про что мы год назад подумали "ну, так нормальные люди не пишут").
Первое, очевидное, и, на самом деле, единственное решение — это использовать динамически генерируемые precompiled headers.
И libclang, и clangd умеют работать с т. н. "preambles" — это автоматически генерируемые PCH для всей пачки
#include-директив, которые идут в начале файла. Работает очень хорошо — если первая подсветка — примерно как компиляция, то последующее редактирование — гораздо приятнее.
Очевидный недостаток — поменял что-то в хедере — и вся преамбла инвалидировалась, перестраивай заново. В этом месте и находится пока что самый очевидный вектор атаки — сделать так, чтобы можно было переиспользовать куски AST из хедеров, которые были не затронуты изменением. Это сложно, это нужно долго исследовать, но если это сделать — жизнь начнется совсем другая. Благо, работа по реализации модулей — очень связана с этим (грубо говоря, надо динамически понять, можно ли использовать хедер так, как будто он был бы модулем), и тоже активно ведется.
Ну или можно подождать, когда все на модули перейдут, ха-ха.
Да, какие-то идеи про то, как должен работать C++-движок в IDE на основе clang реализовать невозможно, и есть вероятность, что "идеальная C++ IDE" должна работать на других принципах — если это так, то мы туда придем, а по дороге обеспечим (в том числе, и через clang) достойный user experience :)
С удовольствием могу ответить на какие-то более конкретные технические вопросы, если они возникнут.
FlexFerrum Автор
03.08.2018 20:52Вам спасибо за развёрнутый комментарий. Читать было интересно.
Описанная картина довольно мрачная и примерно соответствует действительности, но некоторые факты позволяют смотреть в будущее более позитивно
С моей ТЗ основная проблема в том, что очень сложно (в данном случае) усидеть на двух стульях. Всё-таки задача просто компиляции и задача поддержки IDE — достаточно разные, чтобы можно было эффективно их обьеденить под одной крышкой. Да, интегрируют, да, пользуются, но за прошедшие семь лет развития и того, и другого (а это довольно внушительный срок) — результат не очень впечатляет. По крайней мере меня. :)
Если не использовать libclang (и не заботиться о том, чтобы работать со старыми стабильными версиями clang-а из коробки), то можно сделать достаточно много через C++ API уже сейчас
Именно на этом API и сидел. В том числе для того, чтобы исключать лишние преобразования типов и дополнительного менеджмента.
Зачем — потому что хочется сконцентрироваться на создании крутых фич и полировке функционала, который реально полезен пользователям, а не гнаться за стандартами, творчески перереализовывая огромное количество кода из компилятора.
Хорошая цель. :) Насколько достижимая — вот вопрос. Но это как раз в тему форка кланга и пиления вполне конкретных фичей, специфичных для IDE, без оглядки на функции компиляции. Кстати, хороший вопрос возник: а что IDE должно делать с constexpr-функциями? А если они сложные и ресурсоемкие? :)
И libclang, и clangd умеют работать с т. н. "preambles" — это автоматически генерируемые PCH для всей пачки #include-директив, которые идут в начале файла. Работает очень хорошо — если первая подсветка — примерно как компиляция, то последующее редактирование — гораздо приятнее.
Да. И я даже ходил в эту сторону. Но есть нюанс. Даже два. Первый описан в статье — ошибки в хедере, и создание преамбулы обламывается. А ошибки возникали у меня как-то слишком часто (и в основном в системных заголовках). Второй — pch можно перекомпилировать реже, а польза от него почти такая же. Только в редких проектах исходники включают вязанку заголовков, и все они из project root. Чаще основной объем приходится на библиотеки/фреймворки. А так — да, что pch, что преамбула — это сериализованное AST. Шагов до комбинированния итогового AST из нескольких — совсем чуть чуть осталось. Но для того, чтобы такое комбинированния было возможно — сам clang парсер должен быть глубоко интегрирован в IDE. То есть IDE (та часть, которая занимается обработкой кода — с индексами и прочим) становится как бы фронтендом для библиотек clang'а. Но чтобы так сделать — довольно существенно всё перепиливать надо.
dkozh
03.08.2018 22:41ошибки в хедере, и создание преамбулы обламывается
По крайней мере, сейчас это не так. Там есть всякие досадные упущения (например, include not found считатется fatal error, а во время парсинга по коду расставлены на это оптимизации всякие — мол, после fatal error в режиме компиляции все равно не увидим), но все они решаемые, не принципиальные.
FlexFerrum Автор
03.08.2018 22:54Угу. Да. Вижу. github.com/llvm-mirror/clang/blob/4418c5b56fafe30928f418be4eaee39d275628dc/lib/Frontend/FrontendActions.cpp#L157
На 3.7 мне этот патч приходилось самому класть. А судя по блейму, появилось это не раньше пятой версии.
0xd34df00d
04.08.2018 04:28+2Тут как-то немножко выше про это писали, но я вынесу отдельным пунктом.
Писать свои легковесные парсеры и иметь адекватный автокомплит имеет смысл в C++03. В C++14 у вас уже есть полноценные constexpr-функции, могущие влиять на результат последующего синтаксического разбора кода. А это значит, что всё, приплыли, вам надо тащить в свой парсер полноценныйкомпиляторинтерпретатор C++.
А с нетривиальными constexpr-функциями я работаю сильно чаще, чем встречаю упомянутый вами в статье вариант с two-phase lookup, который проявляется лишь когда
1. шаблонна функция приватная,
2. шаблонная функция вызывается ровно один раз (вернее, с ровно одним типом аргументов), и
3. этот вызов уже написан.
Требовать от IDE автокомплита в этом случае, но не требовать поддержки constexpr — немножко нечестно, на мой взгляд.
Тем более, что в constexpr можно сразу диагностировать UB, и всякое такое прочее. Ну всё, теперь у вас не только интерпретатор well-formed С++, но и диагностики ill-formed. Почти полноценный компилятор написали.
ababo
Я когда-то тоже реализовывал авто-подсказки в Visual Studio с помощью libclang. Самым неприятным было столкнуться с недостаточной производительностью для набора текста в реальном времени. Пришлось реализовывать непростой конечный автомат, который асинхронно запускал libclang и сбрасывал результаты при превышении лимита времени или перемене фокуса ввода.
FlexFerrum Автор
Да. Всё так. :) Приходится извращаться.
sergey_shambir
В QtCreator это решается (или раньше решалось) переустановкой таймера на каждое изменение текста. Как только пользователь прекращает менять текст — срабатывает таймер и вычисляется подсветка и автодополнение. Также автодополнение вычисляется при явном запросе по хоткею.
В случае с Clang это действительно работает плохо. Хорошо бы сработал запрос разбора в момент, когда начинается написание идентификатора — т.е. пока пользователь вводит только символы, допустимые в идентификаторе, и не использует навигацию, можно вычислять автодополнение так, как будто идентификатор только начали вводить, и затем вручную фильтровать варианты, используя уже введённый текст.
Жаль, мне так и не довелось проверить эту идею на практике.