
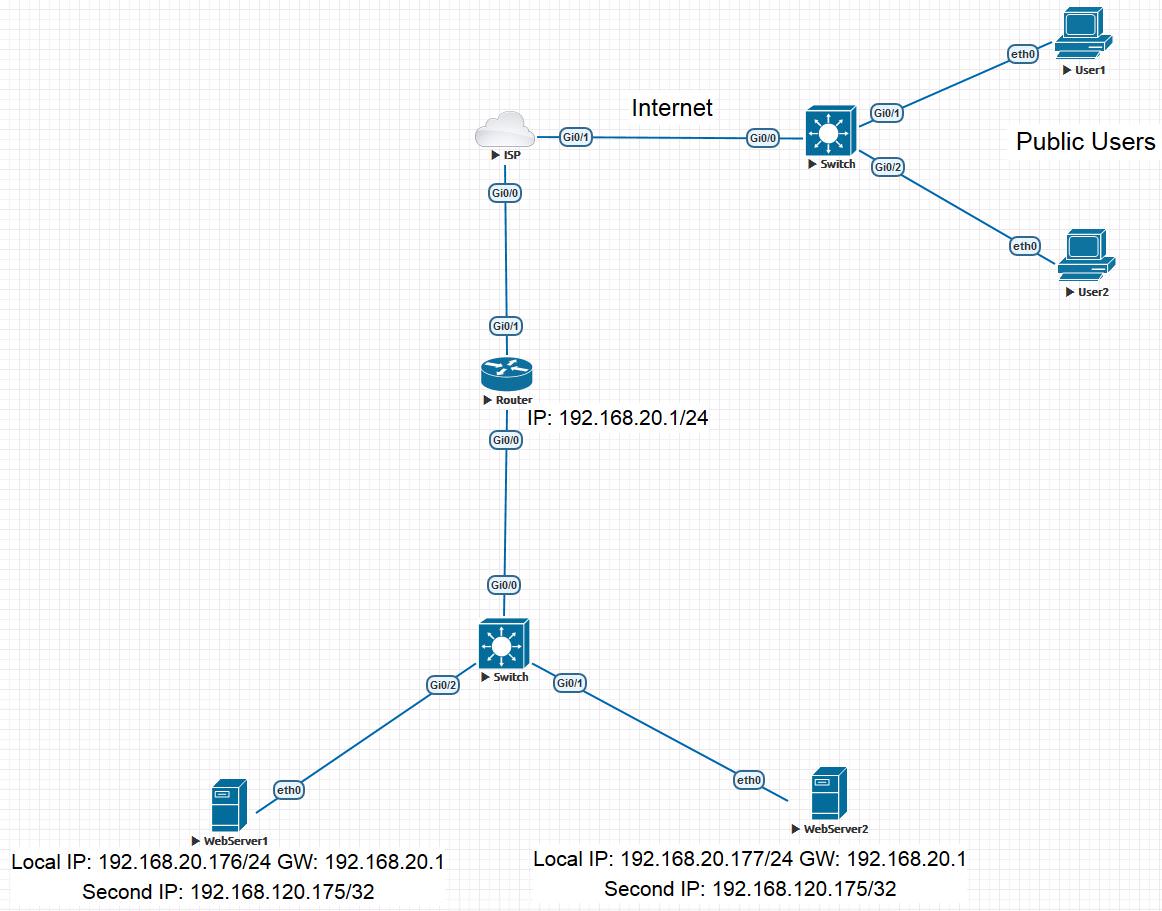
Есть Cisco Router, который выводит веб-сервера в интернет. Два веб-сервера на Centos 7 c nginx-ом. Ip адреса первого и второго веб-сервера — 192.168.20.176/24 и 192.168.20.177/24 соответственно. Для реализации плана, веб-серверам необходимо задать одинаковый вторичный ip адрес. Это может быть любой приватный ip адрес, который не используется в вашей сети. Я выбрал 192.168.120.175 и прописал его вторичным ip адресом основного интерфейса eth0 веб-серверов. На Centos-е это делается при помощи создания файла eth0:0 в директории /etc/sysconfig/network-scripts/. Содержимое файла:
TYPE="Ethernet"
DEVICE=eth0:0
BOOTPROTO="static"
IPADDR=192.168.120.175
NETMASK=255.255.255.255
ONBOOT="yes"
Важно заметить, что используется маска 255.255.255.255 и это позволяет избежать каких-либо ip конфликтов, так как веб-сервера не будут использовать его для генерации траффика. Так сказать, у нас будет Loopback интерфейсы на веб-серверах.
После этого, на маршрутизаторе можно реализовать распределение нагрузки при помощи статической маршрутизации. Данная технология реализуется при помощи Ip Cef на маршрутизаторах Cisco. Ссылка тут. У остальных вендоров, возможно, могут быть определенные нюансы.
В Cisco распределение потоков может быть двумя способами:
- Per-Destination (по умолчанию). Данный вариант нам и нужен. Все пакеты одного потока будут отправляться одному из двух серверов. Принцип работы заключается в том, что вычисляется хэш по source и destination ip адреса и в зависимости от этого хэша выбирается либо первый маршрут (сервер), либо второй. Далее, мы немного изменим данное поведение.
- Per-Packet. Данный вариант нам не подходит, так как балансировка будет происходит по пакетам. Грубо говоря, первый пакет по первому маршруту, второй пакет по второму.
Прописываем два маршрута это при помощи команд:
ip route 192.168.120.175 255.255.255.255 GigabitEthernet0/0 192.168.20.176
ip route 192.168.120.175 255.255.255.255 GigabitEthernet0/0 192.168.20.177
Таким образом, оба маршрута будут установлены в таблицу маршрутизации и по ним будет осуществляться распределение нагрузки:

Проверяем также правильно ли выбран способ балансировки:
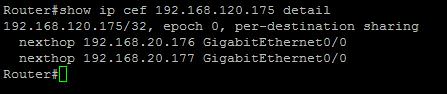
Source IP адрес будет изменяться, а Destination IP всегда будет оставаться один. Это может влиять на равномерность балансировки, учитывая NAT. Для оптимизации можно учитывать source port, который будет рандомно разным, в зависимости от сессии клиента. Для этого используем следующую команду:
ip cef load-sharing algorithm include-ports sourceТакже надо настроить static NAT для перенапраления веб запросов на адрес 192.168.120.175:
ip nat inside source static tcp 192.168.120.175 80 interface GigabitEthernet0/1 80Что же у нас получается? Запросы от пользователей из интернета будут попадать на наш маршрутизатор, который будет их распределять между нашими сервера по потокам, в зависимости от source port в TCP. При открытии новой сессии, клиент, возможно, попадет на новый сервер.
Что будет, если один из серверов упадет? Маршрут, который вел к этому серверу, будет удален из таблицы маршрутизации. Для оптимизации этого процесса можно использовать IP SLA. Следить за состояние серверов по пингу каждые 10 секунд:
ip sla 10
icmp-echo 192.168.20.176
frequency 10
ip sla schedule 10 life forever start-time now
ip sla 20
icmp-echo 192.168.20.177
frequency 10
ip sla schedule 20 life forever start-time nowДалее, добавив мониторинг к соответствующим маршрутам:
ip route 192.168.120.175 255.255.255.255 GigabitEthernet0/0 192.168.20.176 track 10
ip route 192.168.120.175 255.255.255.255 GigabitEthernet0/0 192.168.20.177 track 20
IP SLA на маршрутизаторах Cisco позволяет проводить мониторинг также по HTTP GET запросам, что поможет определить падение веб-сервера не только по его отсутствию в сети, но и при нерабочем состоянии веб сервиса.
Таким образом, для построение такой схемы не требуется дополнительное оборудование и какой-либо софт для веб-серверов. Необходим лишь маршрутизатор с возможностью балансировки траффика.
Комментарии (22)

blind_oracle
03.08.2018 17:07IP SLA на маршрутизаторах Cisco позволяет проводить мониторинг также по HTTP GET запросам, что поможет определить падение веб-сервера не только по его отсутствию в сети, но и при нерабочем состоянии веб сервиса.
Ок, так почему же в итоге было сделано через ICMP?
А вообще такая схема гораздо удобнее реализуется через Anycast как мне кажется. Немного сложнее т.к. требует поднятия OSPF или BGP, но работает более гибко. Можно реализовать разные healthcheck локально и приостанавливать анонс адреса на роутер в случае проблем.
В принципе можно это делать и в вашей топологии, но придется например дропать пинги или класть интерфейс.xcore78
03.08.2018 19:11У автора в сети может не быть никаких протоколов вообще судя по топологии, а вы v4anycast предлагаете :)
blind_oracle
03.08.2018 21:22Может и нет, но раз есть роутер от Цыски то никто не мешает поднять сессию между ним и серверами.
Ruslan_Mammadov Автор
03.08.2018 23:05Поднять протоколы маршрутизации проблем не составит, но зачем? В этой статье я привожу пример как можно обойтись более простой схемой. Не надо использовать сложные протоколы и софт на стороне сервера.
Ruslan_Mammadov Автор
03.08.2018 23:03Было сделано через ICMP потому, что план был реализован на Cisco ASA. Функционал IP Sla не позволял использовать HTTP GET, в отличие от маршрутизаторов Cisco.
Когда говорят Anycast, я представляю IPv6, что не есть тоже самое. По поводу простоты healthcheck, интересно какие процедуры применяются для этого?
Дропать пинги и класть интерфейс — один из вариантов, но самый простой — удалить роут из маршрутизатора.xcore78
03.08.2018 23:56v4anycast отличается от нативного v6 разве что только терминологией и поддержкой на уровне протокола. В v4 вы делаете все самостоятельно: route injection, алиасы на интерфейсах, доп. обвязка в виде bgp (я не сторонник каких-либо «или» в данном случае, но красота, как водится, в глазах смотрящего).
Ruslan_Mammadov Автор
04.08.2018 12:10Не сразу понял схему с v4anycast, извиняюсь. Но все равно, это более ресурсоемкая и сложная реализация.
xcore78
03.08.2018 19:10Получается, ваши сервисы уже кластеризованы, раз вам не требуется persistence на вашем самодельном «балансировщике».
Ruslan_Mammadov Автор
03.08.2018 23:08Не совсем понял про persistence, если можете киньте ссылку для ознокомления.
По поводу кластеризации:
1) Реализована синхронизация баз данных.
2) Реализована синхронизация необходимых директорий, при помощи средств ОС.xcore78
03.08.2018 23:26Ruslan_Mammadov Автор
03.08.2018 23:36Понял, согласен. А есть такие балансировщики с такими функционалом? Не имею ввиду кластеризацию, например, на уровне ОС или виртуальных машин.
xcore78
03.08.2018 23:50Из опенсорса навскидку — HAproxy, nginx. Seesaw я бы попробовал тоже.
(добавлено) прочитал, что есть что-то виртуальное от KEMP. Если это бесплатно или условно-бесплатно, обязательно попробуйте. Это коммерчески успешный продукт.Ruslan_Mammadov Автор
04.08.2018 07:29В силу простоты веб сервера, необходимости в persistence не было. Но не знал о данном функционале у HAproxy. Надо будет поднять в лабораторных условиях поднять.
vanyas
04.08.2018 10:58Так это же самы обычный ECMP, будет работать на большинстве вендоров. Ну и как хорошо выше заметили, лучше поднять между серверами (quagga, exabgp, gobgp, ...) и роутером BGP и анонсировать виртуальный ip с серверов, вместо статики. Таким образом админы серверов смогут сами спокойна, когда надо, выодить сервера из кластера и заводить назад, не залазия на сетевое оборудования или не пиная сетевого админа
Ruslan_Mammadov Автор
04.08.2018 12:07Если разбирать схему с динамическими протоколами, то в качестве плюса у нас — это то, что админ веб-сервера может выводить сам из строя сервер. В качестве минуса — сложность схемы, учитывая также и использование дополнительных ресурсов.
В схеме, указанной выше, тоже можно выводить сервер из строя на стороне сервера, добавляю одну строчку в iptables. Минусы от BGP понятные, плюс же не самый явный.
diver66
06.08.2018 12:42Уточните какие минусы есть у BGP или любого протокола динамической маршрутизации относительно статических маршрутов? Кстати да, ECMP умеет не только статика или BGP, а в принципе любой современный протокол.
Ruslan_Mammadov Автор
06.08.2018 14:26Минус для данной схемы у BGP в том, что схема сложнее, требует больше ресурсов, постоянный обмен сообщений, взамен каких-либо плюсов относительно статики нет. Значит, чем проще, тем лучше.Также, учитывая гибкость ip sla, можно мониторить состояние веб сервиса, что, в случае, bgp не приходит в голову как сделать.
diver66
06.08.2018 15:27IP SLA тоже потребляет ресурсы и еще не факт что будет потреблять меньше ресурсов чем два BGP соседа с одним префиксом каждый. Если привести конкретно цифры, то 1 маршрут в BGP таблице занимает 120 байт памяти (в реализации Cisco по крайней мере). Что касательно нагрузки на процессор — если ничего в сети не меняется, то и обновлений таблиц не происходит, так что нагрузка будет только на поддержание ТСР соединения, что тоже не факт что будет потреблять ресурсов больше чем пинги в вашей конфигурации IP SLA.
Плюсы относительно статики — легко масштабировать, например если понадобится добавить еще несколько адресов для балансировки, или несколько сотен адресов — вы будете это всё вколачивать статикой? Мониторить состояние сервиса с сетевой железки — такое себе решение, для этого существуют системы мониторинга, а задача сетевого оборудования побыстрее передавать пакеты из одного порта в другой. Ничего не мешает мониторить состояние сервиса чем угодно и по результату HTTP GET того же можно очень разными способами снимать анонс адреса с хоста где крутится сервис.Ruslan_Mammadov Автор
06.08.2018 15:38Если для сотни серверов руками поднимаете BGP сессии, то прописать маршрут не составит труда. Правда не знаю сколько требует ресурсов сервис и процессы BGP, но что-то да нужно. У статики это — место для в памяти для маршрута и пару сообщений каждые 10 секунж. Посмотрите плюсы статической маршрутизации перед динамической. Там несколько пунктов. Например, безопасность.
Я имел ввиду мониторить с сетевой железки для определение актуальности таблицы маршрутизации, а не в целом мониторить систему только с сетевой железки.
vrangel
04.08.2018 16:42Anycast — это больше про балансировку географически разнесенных ресурсов. Принцип работы основан на приоритете короткого маршрута в протоколе bgp. Как с помощью anycast резервировать ресурсы на одной площадке не совсем понятно.
Добавлю, что с помощью описанного метода можно балансировать не только сервера, но и любой трафик. Например, равнозначные по пропускной способности каналы передачи данных.diver66
06.08.2018 12:49> Принцип работы основан на приоритете короткого маршрута в протоколе bgp.
«короткого» — видимо тут имеется в виду атрибут BGP AS-PATH, хотя он далеко не единственный и даже не первый в алгоритме выбора лучшего маршрута. А еще BGP не обязан выбирать только один лучший маршрут, а может выбрать их два, три, четыре и больше — и все они будут с одинаковыми «длинами» и прочими атрибутами кроме next-hop, что приведет к балансировке.
> Как с помощью anycast резервировать ресурсы на одной площадке не совсем понятно.
Легко и просто, абсолютно никакой разницы находятся ресурсы в пределах одной стойки или разнесены по разным континентам.
Более того если использовать EIGRP то можно добиться неравномерного распределения трафика подкручивая метрики.
shgurbanov
Оригинально! В закладки!