
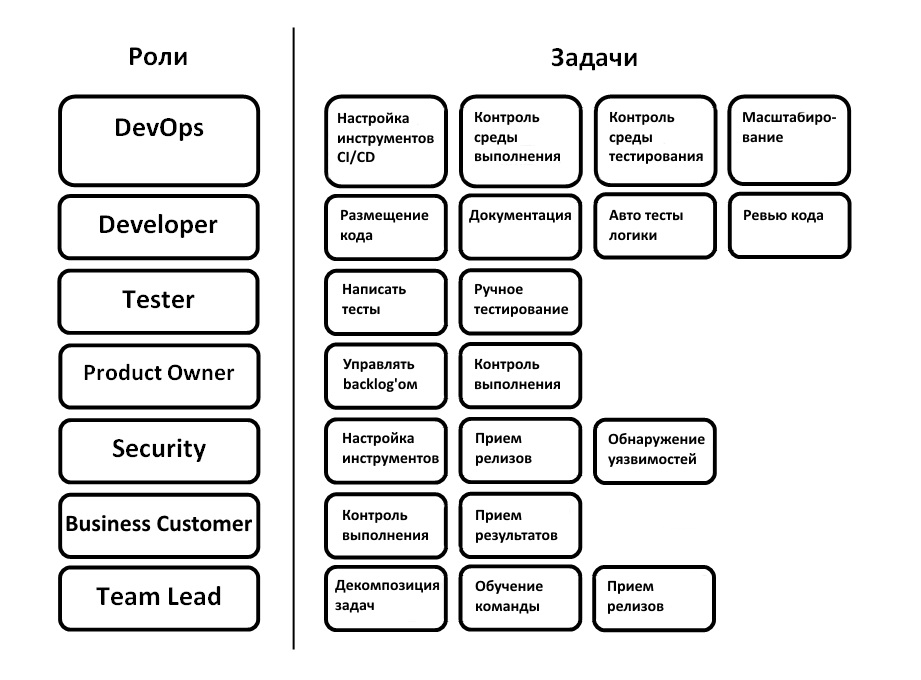
Мы делаем проект облака для разработки — платформу, способную максимально упростить жизнь девопсам, разработчикам, тестировщикам, тимлидам и другим вовлеченным в процесс разработки специалистам. Это продукт не для сейчас и не для завтра, и потребность в нём только-только формируется.
Основная идея — вы можете разворачивать конвейер с уже преднастроенными инструментами, но при этом с возможностью внесения целого ряда настроек, и вам останется только деплоить код.
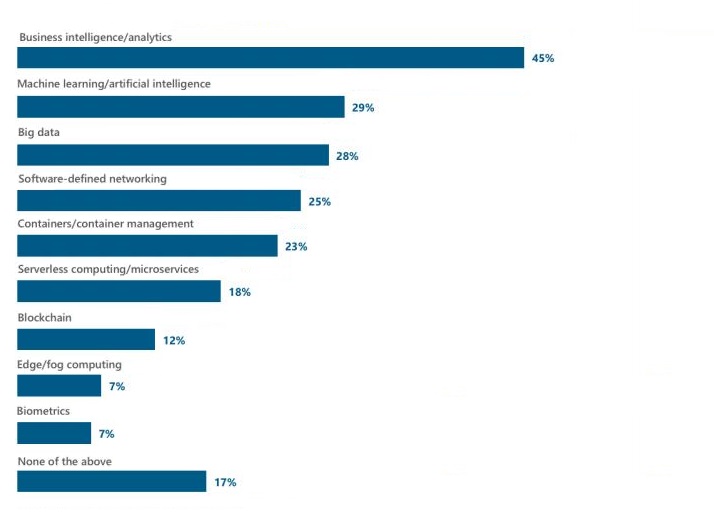
Откуда такое извращение? Мы видим чёткий тренд, что сейчас скорость развёртывания новых проектов влияет на рынок. От того, как быстро будут поставляться релизы, зависит коммерция. От того, как быстро будут исправляться баги, как быстро будут заниматься новые ниши. В начале 2018 глобальная компания «451 Research» провела опрос, какие технологии будут приоритетным при развитии. В первую десятку вошли технологии создания и управления контейнерами, а также бессерверная архитектура приложений и микросервисы, обогнав даже такую хайповую тему, как блокчейн.
И вот теперь у нас есть к вам пара вопросов.
Диаграмма из опроса:
А нужно ли это?
Использование контейнеров при разработке нового продукта имеет как свои достоинства, так и недостатки. Использовать данную технологию или нет нужно решать исходя из поставленных задач. Для ряда задач без использования контейнеров не обойтись, а для некоторых они попросту лишние. Например, для сайтов с низкой посещаемостью будет вполне достаточно простой архитектуры из двух серверов. Но если же планируется значительный рост разработки, а также огромный прирост посетителей за короткое время, то в таком случае стоит рассматривать инфраструктуру с использованием контейнеров.
У использования контейнеров есть ряд преимуществ:
- Каждое приложение запускается изолированно в собственном контейнере, что позволяет свести проблемы, связанные с конфигурированием, к минимуму.
- Безопасность приложений достигается также за счет изоляции каждого контейнера.
- В связи с тем, что контейнеры используют ядро операционной системы, теперь не нужна гостевая операционка, за счет чего освобождается большое количество ресурсов.
- Также благодаря использованию ядра операционной системы и потому, что не нужно полагаться на гипервизор, контейнерам требуется гораздо меньше ресурсов в сравнении с другими стеками.
- Опять же в связи с тем, что контейнеры не требуют гостевой операционной системы, их легко мигрировать с одного сервера на другой.
- Благодаря тому, что каждое приложение запускается в изолированном контейнере, легко можно осуществить перенос с локальной машины в облако;
- Очень “дешево” запустить и остановить контейнер из-за использования ядра операционной системы.
В связи со всем вышеизложенным, мы считаем, что технология контейнеризации на текущий момент – самый быстрый, ресурсоэффективный и наиболее безопасный стек. Благодаря преимуществам контейнеров можно иметь одинаковую среду как на локальной машине, так и в продакшене, что облегчает процесс непрерывной интеграции и непрерывной поставки.
Преимущества контейнеров настолько убедительны, что они определенно будут использоваться еще долгое время.
При чём тут облако для разработки?
В идеальном мире разработчика любой commit кода должен по нажатию кнопки, как по мановению волшебной палочки, выкатываться в продакшн.
У нас было так: есть Гитлабчик с задачами и исходником. Когда нужно что-то собрать — GitLab Runner. Работаем по Git Flow, все фичи по отдельным веткам. Когда ветка попадает в хранилище, в GitLab’е запускаются тесты по этому коду. Если тесты прошли, разработчик этой ветки может сделать мердж реквест, фактически запрос на ревью кода. После ревью ветка принимается, вливается в dev-ветку, по ней еще раз проходят тесты. При деплое GitLab Runner собирает Docker-контейнер и выкатывает на стеджинговый сервер, где его можно будет покликать и порадоваться. И вот тут первый затык — код мы просматриваем руками на предмет соответствия функционалу и это первое, что мы исправляем. После этого мы вливаем код в ветку релиза. И для неё у нас раскатывается отдельный пред-продуктивный вариант нашего решения, который смотрят наши бизнес-заказчики. После того как заапрувлена версия на пре-проде, мы ее катим в продакшн и она раскатывается на продуктовые ноды. Есть автогенерация release notes и отчёты по багам. Скорость сборки была больше 30 минут, сейчас на порядок меньше. Мы подобрали набор инструментов для себя и теперь думаем о том, как сделать такой же готовый SaaS.
Непосредственно типовой процесс вывода релиза для нас выглядит следующим образом:
- Постановка задач на реализацию новых фич
- Локализация кода
- Внесение изменений согласно поставленным задачам. Написание автоматических тестов перед билдом.
- Проверка кода, как ручная, так и автотестами
- Сливание кода в dev-ветку
- Сборка dev-ветки
- Разворачивание тестовой инфраструктуры
- Деплой релиза на тестовой инфраструктуре
- Запуск тестирования, функционального, интеграционного и т.д.
- В случае возникновения багов, допиливание их сразу в dev-ветке
- Перенос dev-ветки в master-ветку
Вот схема с деталями для нашего процесса:
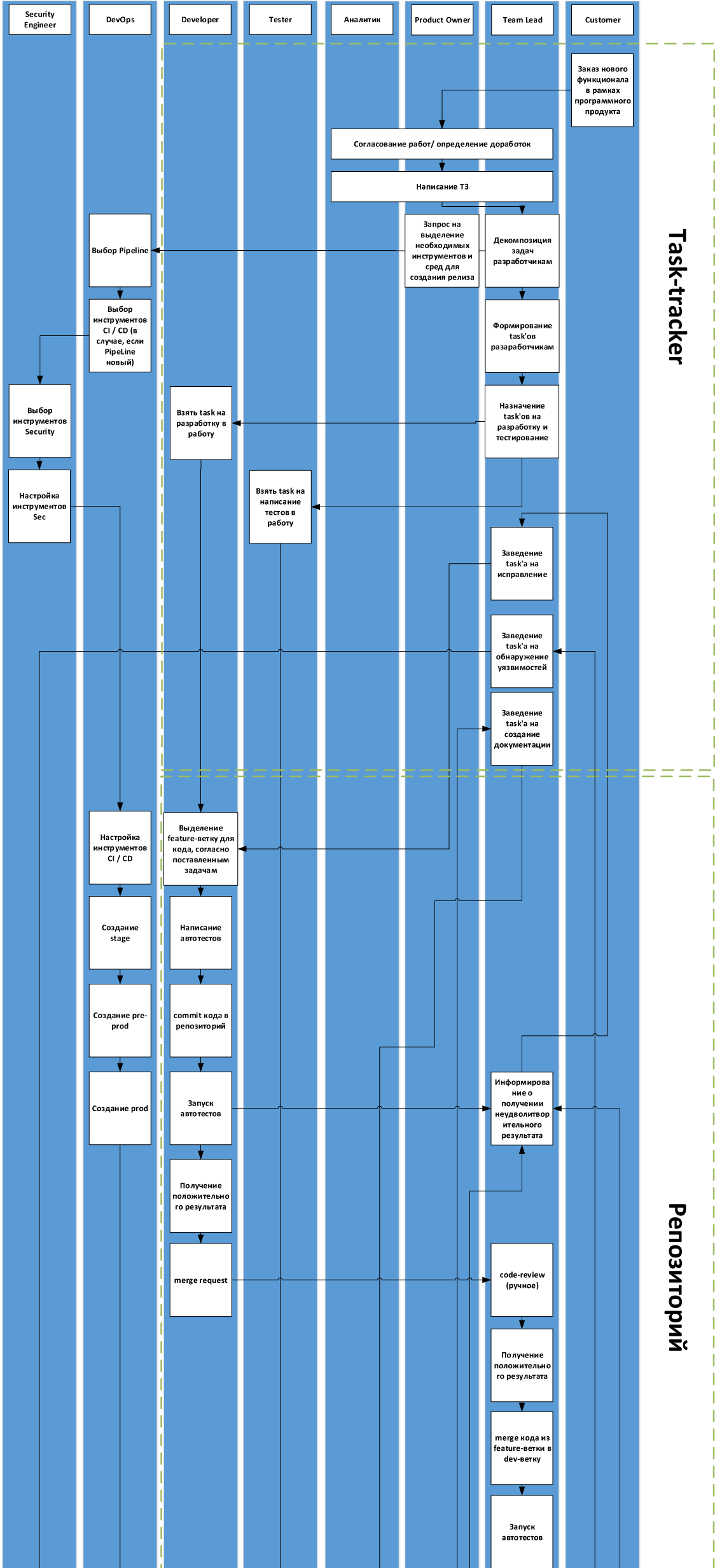
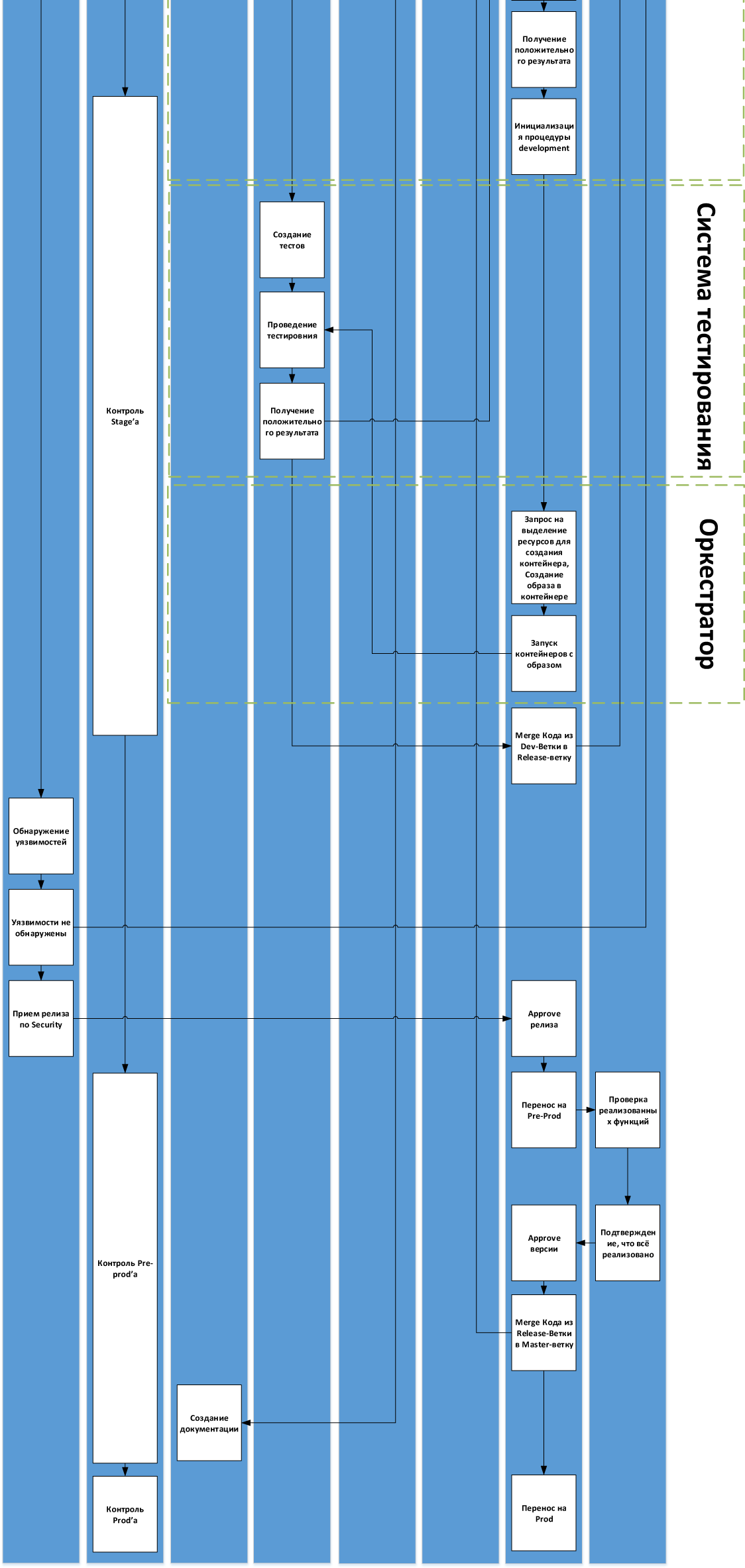
Собственно, первый вопрос — расскажите, пожалуйста, где какие грабли у вас были и насколько универсальна или нет эта схема. Если вы используете воркфлоу, очень отличающийся от этого, — то добавьте пару слов, почему так, пожалуйста.
Что за продукт мы планируем?
Мы решили не копировать Amazon в этом плане, а вести свою разработку с учётом специфики рынка. Сразу оговоримся, что все выкладки — наше субъективное мнение, основанное на нашем анализе. Мы открыты к конструктивному диалогу и готовы менять roadmap продукта.
При анализе существующего pipeline от Amazon мы пришли к выводу, что он обладает колоссальными возможностями, но при этом акцент сделан на очень крупные корпоративные команды. Как нам показалось, чтобы выкатить в Docker’е микросервис нужно необоснованно много времени, больше, чем если бы, например, выкатывали в Kubernetes, т.к. имеет место быть настройка внутренних конфигов, определение внутренних соглашений и т.д. и во всем этом нужно долго разбираться.
С другой стороны есть, например, Heroku, где можно деплоить в один клик. Но в силу того, что проекты, как правило, довольно разветвленные, со сторонними микросервисами, — в какой-то момент становится нужно выкатывать кастомные docker-образы с DBaaS’шными сервисами и все это в Herocku не особо помещается, потому что либо дорого, либо неудобно.
Мы хотим найти другой вариант. Золотую середину. В зависимости от типа проекта и задач предоставить вам набор уже преднастроенных инструментов, уже интегрированных в единый конвейер, при этом оставить как возможность глубокого изменения настроек, так и возможность замены самих инструментов.
Так что это будет?
Экосистема, включающая в себя портал и набор инструментов и сервисов, позволяющих минимизировать взаимодействие разработчиков с инфраструктурным уровнем. Вы определяете параметры среды, не привязанные к физическому окружению:
- Среда разработки (система управления конфигурациям, система постановки задач, репозиторий для хранения кода и артефактов, таск-трекер)
- CI – Continuous Integration (сборка, инфраструктура и оркестрация)
- QA – Quality Assurance (тестирование, мониторинг и логирование)
- Staging – Среда интеграции / Предрелизный контур
- Production – Продуктивный контур
Выбирая инструменты, мы ориентировались на best-practice на рынке.

Мы будем выстраивать инфраструктуру с Stage’ом и Prod’ом, с использованием Docker и Kubernetes с параллельным запиливанием фич.
Это будет происходить итерационно — на первом этапе запланирован сервис, который позволит брать Docker-файл из проекта, после чего собрать требуемый контейнер и раскладывает их Kubernetes.
Также мы планируем уделять особое внимание сервису по контролю процесса разработки и непрерывной поставки. Что мы понимаем под этим сервисом? Это возможность сформировать иерархическую модель KPI с показателями типа % покрытия юнит-тестами, среднее время устранения инцидента или дефекта, среднее время от коммита до поставки и т.д.
Сбором исходных данных из разных систем — систем управления тестированием, управления задачами, компонентов CI/CD, средств мониторинга инфры и т.д
А самое главное — это показать в адекватном, доступном для быстрого анализа виде — дашборды с возможностью дриллдауна, сравнительного анализа показателей.
Что мы хотим сделать
Собственно, от вас мне бы очень хотелось услышать мнение по поводу всего вот этого и наших планов по шагам. Сейчас они такие:
- Инфраструктура и оркестрация — Docker & Kubernetes
- Постановка задач, хранение кода и артефактов, task-tracker — Gitlab, Redmine, S3
- Производство и разработка — Chef / Ansible
- Сборка — Jenkins
- Тестирование — Selenium, LoadRunner
- Мониторинг и логирование — Prometheus & ELK
- Кстати, а как вы смотрите на то, если в рамках платформы будет возможность выбора — захотел, выбрал Jenkins, не захотел — GitLab Runner?
- Или же не важно, что внутри, главное, чтобы всё как надо билдилось, тестилось и деплоилось?
Как можно помочь?
Продукт будет развиваться для отечественных разработчиков. Если вы сейчас расскажете нам, как лучше сделать, с высокой вероятностью это войдёт в релиз.
Прямо сейчас расскажите, пожалуйста, какие стеки вы используете. Можно — в комментах или письмом на почту team@ts-cloud.ru.
UPD: для удобства мы сделали короткий опросник в Гугл-форме — вот тут.
Дальше мы будем держать вас в курсе разработки — и в какой-то момент дадим помогавшим участникам доступы в бету (по сути, бесплатный доступ к хорошим вычислительным ресурсам облака в обмен на обратную связь).
Комментарии (31)

usego
09.08.2018 11:53>Например, для сайтов с низкой посещаемостью будет вполне достаточно простой архитектуры из двух серверов. Но если же планируется значительный рост разработки, а также огромный прирост посетителей за короткое время, то в таком случае стоит рассматривать инфраструктуру с использованием контейнеров
Это если смотреть лишь со стороны инфраструктуры. Не менее важная функция докеризации — это деливери продукта от разработчика в целостном неизменяемом виде. 2 сервера под сайтик за 2 года зарастают таким мхом, что потом проще переставлять всё с нуля.Ssklabovskiy Автор
09.08.2018 14:37Даже и сайтик про котиков с низкой посещаемостью, который крутится на 1-2 виртуалках, в 2к18 скорее всего:
- делается на каком-нибудь web-фреймворке или генераторе статических сайтов;
- хранит исходники в системе контроля версий;
- кодится и тестируется хипстером (вариант — хардкор-девелопером-отцом) на своем макбуке с макосью (вариант — леново со слакой) с докер-контейнерами для тестовой базы и тестовым redis, потому что их проще всего поднять и погасить.
Из этого состояния, как мне кажется, идея настроить авто-деплой в кубернетис-кластер посредством конфиг-файла, который помещается вместе с исходниками, выглядит достаточно привлекательно и почти совсем не оверхед.
Какие есть альтернативы для сайта с котиком? Делать руками git pull на виртуалке с сайтиком при изменениях сорца и настроить там хуки, чтобы переподнимать сервис при обновлении? Сделать ansible-плейбук и запускать его вручную? Написать скрипт для тревиса, который подключится к github-у (вариант — описать bitbucket-pipeline), который scp-скопирует файлы в целевую виртуалку и перезапустит service по ssh?
К альтернативным способам тоже есть вопросы. Как бы это делали вы?
Xandrmoro
09.08.2018 12:37… и снова нам предлагают отдать критическую инфраструктуру куда-то, где в любой момент может произойти что угодно и как угодно могут измениться условия и где никто ни за что не несёт ответственности. Эх.
Ssklabovskiy Автор
09.08.2018 13:21+1В этом мире вы всё равно будете доверять провайдерам сети, облачному провайдеру (например, нам), производителям железа, разработчикам софта. Есть несколько способов правильно параноить, но они подразумевают собственное производство процессоров в конечном итоге. Что и делают военные в ряде ситуаций.
Assargin
09.08.2018 13:46Доверять, конечно, будем, но:
- провайдеры сетей — резервируются
- облачные провайдеры, если их возможно использовать до определённого уровня абстракции, не понижая его до уровня vendor lock-in — взаимозаменяемы
- софт, библиотеки, пакеты — эти зависимости продукта и среды замораживаются на уровне конкретных версий, и с ними продукт тестируется вдоль и поперёк
- Производители железа — без комментариев
Xandrmoro
09.08.2018 14:19Разница между софтом/железом и облаком в первую очередь в том, что в облаке нельзя зафиксировать версию и быть уверенным, что никто не придёт причинять тебе новые фичи вместо старых, а сетевые протоколы достаточно хорошо инкапсулированы, чтобы перейти с одного провайдера на другого можно было щелчком пальцев — в отличие от, опять же, облаков, где унификацией и не пахнет.
k1tos
09.08.2018 14:33Это ведь вопрос репутации провайдера. В конечном счёте провайдер рискует всем своим бизнесом, достаточно одной-двух серьёзных ошибок, и клиенты начнут отворачиваться. Наверное, выбирая провайдера, который борется за свою репутацию, можно минимизировать риски.
Cryvage
09.08.2018 15:13достаточно одной-двух серьёзных ошибок, и клиенты начнут отворачиваться
Всегда есть шанс, как раз, оказаться жертвой этих одной-двух серьёзных ошибок. В какую сторону после этого начнут вертеться другие клиенты — дело десятое.
powerman
09.08.2018 13:00+1"Мерж dev в release" >
"Заведение таска на обнаружение уязвимостей" >
"Обнаружение уязвимостей" >
"Уязвимости не обнаружены" >
"Информировании о получении неудовлетворительного результата" >
"Заведение таска на исправление":)
Ssklabovskiy Автор
09.08.2018 13:22Да, критичные обновления у нас обычно прогоняются через ИБ, возможно это не быстро, но зато безопасно.
ievgen
09.08.2018 13:37Вот у товарищей есть что-то подобное, но с уклоном в 1С vanessa.services и есть еще статический анализатор кода, но это скорее в блок тестирования можно включить.
Подробнее может alexey-lustin рассказать. И да, как выразился Xandrmoro, основной вопрос был в опасении передачи своих исходников куда-то.
powerman
09.08.2018 13:51+1У DevOps полно задач помимо контроля площадок: настройка конфигурации с которой запускается проект на разных площадках, управление всяческими ключами/паролями, масштабирование, оптимизация CI по скорости сборки, подготовка и обновление базовых образов докера используемых приложением, etc.
Что до Security Engineer, то на схеме отсутствует основная точка, где необходимо контролировать наличие уязвимостей — ревью кода на pull/merge request. Плюс есть такая штука как архитектурные уязвимости, поэтому крайне желательно дополнительное ревью ТЗ между этапами его написания и декомпозиции задач разработчикам. Причём, по моему опыту, зачастую в проектах нет ресурсов на отдельный этап "Обнаружение уязвимостей" перед релизом, но есть возможность контролировать их на ревью в описанном мной стиле.
"commit кода в репозиторий" >
"Запуск автотестов" >
"Информировании о получении неудовлетворительного результата" >
"Заведение task'а на исправление"Никто так не делает при запуске тестов после коммита, это совершенно жуткая излишняя бюрократизация, все необходимые исправления кода чтобы тесты прошли делаются в рамках изначальной задачи.
"code-review (ручное)" >
"Получение положительного результата"А что, отрицательного на ваших ревью не бывает? Это вообще основная проблема схемы — в каких-то местах она избыточно (и некорректно) детальна, а в других местах отсутствует масса негативных веток (скорее всего потому, что они бы дико усложнили схему — вроде отмены фичи или переделки ТЗ в связи с фактами проявившимися в процессе реализации). Но Вы ведь вроде бы сервис хотите сделать, так вот сервис как раз такие ситуации учитывать обязан.
"merge кода из feature в dev" >
"запуск автотестов"Пустая трата времени, тесты этого коммита уже выполнились перед ревью.
"merge кода из release в master" >
"Заведение task'а на создание документации"Плохая привычка, документацию нужно писать одновременно с кодом, и, в идеале, мержить в том же PR что и фичу.
Ещё одна плохая привычка — наделять ветку master конкретным смыслом. В таких схемах лучше использовать названия веток по их сути (feature, dev, staging, pre-prod, prod), потому что в разных проектах ветка master может быть синонимом любой из них (кроме feature).
Из важных этапов пропущена одна нетривиальная тема: миграции БД. Ещё пропущены сложные задачи постепенного (с обновлением только части узлов) выката новой версии на prod и откат prod при проблемах (что может потребовать отката и миграции БД).
Постановка задач, хранение кода и артефактов, task-tracker — Gitlab, Redmine, S3
Redmine это кошмар, лучше посмотрите на Youtrack — я с ним работал мало, но по первому впечатлению это самый юзабельный трекер из имеющихся в данный момент (если не считать гитхабовского, но он не очень подходит если в проекте несколько репо и с трекером должны активно работать менеджеры и бизнес).
Кстати, а как вы смотрите на то, если в рамках платформы будет
возможность выбора — захотел, выбрал Jenkins, не захотел — GitLab Runner?Очень положительно. А ещё лучше, чтобы из коробки был именно GitLab Runner, а не Jenkins.
Или же не важно, что внутри, главное, чтобы всё как надо билдилось, тестилось и деплоилось?
Может, когда-нибудь, в далёком будущем, когда оно будет работать как часы. А пока всё это продолжает создавать проблемы лучше понимать, что под капотом и иметь возможность это фиксить.
grinCo
09.08.2018 19:55«commit кода в репозиторий» >
«Запуск автотестов» >
«Информировании о получении неудовлетворительного результата» >
«Заведение task'а на исправление»
Никто так не делает при запуске тестов после коммита, это совершенно жуткая излишняя бюрократизация, все необходимые исправления кода чтобы тесты прошли делаются в рамках изначальной задачи.
Я думал все так делают. Если конечно речь о пуше в удаленный репозиторий, а не коммите в локальную ветку.powerman
09.08.2018 20:45В схеме в этом месте речь об открытом pull/merge-request. Т.е. создали фиче-бранч под таску, написали кода и тестов, сделали git push на гитхаб, CI по этому пушу запустил тесты, которые провалились. Кто-то действительно в этот момент будет создавать отдельную таску "пофиксить проваливающиеся автотесты"?
grinCo
09.08.2018 21:29Из схемы я понял, что речь о стандартном подходе:
1) сделали фича бранч и написали код, прогнали тесты
2) сделали пул-реквест в мастер (девелоп)
3) после создания пул-реквеста автоматичски запускаются тесты
4) если тесты прошли успешно, то можем мержить (т.е. по хорошему кнопка мерж должна быть физически заблокированна до успешной сборки и прогона тестов)
5) если тесты провалились, то делаем тикет на фикс кода или теста(смотря что сломалось) и фиксим его
В маленьких командах можно, конечно, так не делать, а просто локально прогнать тесты и сделать пул-реквест или запушить в девелоп (мастер) сразу. Но это на начальных этапах разработки и (или) на проектах где можно себе позволить сломать мастер (дев) энв.
Когда команда большая, лучше подстраховаться и прогнать тесты перед мержем. Из 50 человек за год обязательно кто-то забудет запустить тесты локально, или специально не запустит т.к. будет уверен что он не может ошибиться, или из-за спешки сознательно не запустить тесты чтобы быстрее фикс на прод доставить.powerman
09.08.2018 21:34Подход именно такой, но я писал о том, что в пункте 5 нет никакого смысла создавать отдельный тикет, фиксить это надо в рамках исходной задачи — собственно, пока ветка этой задачи не смержена (а мерж автоматом блокируется если не проходят тесты) — задача не считается закрытой, так что все работы до мержа продолжаются в её рамках.
ProSerg
09.08.2018 14:32+1Большое спасибо за статью. Мне нравиться эта тема. И видно, что определился базовый набор инструментов для постройке pipeline. Далее по тексту pipeline — это всё что связано с постановки задачи до доставки проект заказчику.
Главный вопрос который повис «Зачем?». Я не против того чтобы рос уровень компетенции на российском рынке. Я только за! Ребята вы молодцы! Так держать!
Если бы мне пришлось отвечать за выбор, то я бы не стал бы выносить в аутсорс или компетенцию критически важных компонентов производственного процесса. Чем и является то самый pipeline который вы хотите предложить как услугу.
Эту задачу обзовём как AutoDevops решает и MS с его слиянием TFS + github.
И Gitlab у которого есть и CI и СD. недавно прикрутили разваривание нодов для Kubernetes одним кликом. Gitlab отлично интегрируется со множеством инструментов и сервисов. Если будет ещё одни сервис, который решает похожую задачу отлично я только за.
Для меня devops это философия, набор лучших практик. Но всё это нужно применять аккуратно и с учётом со спецификой бизнеса и команды. По мне, devops это не только технологии, но и коммуникации между участниками процесса. Последние вы не затронули, её в схеме нет. В тоже время вы предлагаете devops как готовое решение, что крайне амбициозно.
Так же очень странно сам посыл заменить devops. Опять же я из хожу, что devops-инженера нету. Это просто инженер-программист. Поэтому что вы хотите заменить? Как вы хотите помочь бизнесу? Какие задачи хотите на себя взять? Почему вы считаете, что знаете как строить pipeline лучше чем сам разработчик? Как вы хотите предугадывать потребности разработчиков и бизнеса?
Вы позиционируете свой инструмент как универсальный devops решение. Но в вашей схеме нет работу с моделями и зависимостями, нету chatops. Да и ваше решение вряд ли справиться с проектами, который разрабатываются под embedded и desktop.
Пару слов про потенциальный рынок. Моё мнение такое, что вы ориентируется на маленькие команды, или начинающие проекты. Это значит, что в плане потока денег от них будет не очень. Раз не очень, то развивать свой продукт будет крайне сложно.
Я думаю, что средний и крупный бизнес вряд ли вашим продуктом заинтересуются.
— С точки зрения безопасности, плохая идея выносить важный процессы на аутсорс.
— Сами могу себе позволить создать и настроить под себя свой pipeline.
— Удобнее из компонентов собрать свой pipeline, нежели купить супер-пупер комбайн и с ним долго разбираться.
Подытожим. У меня два основных вопроса:
1. Зачем? Если есть куча инструментов из них можно построить свой pipeline.
2. Почему вы считаете что ваша компетенция в данном вопросе лучше чем у всех остальных?
Спасибо!Ssklabovskiy Автор
09.08.2018 15:55Большое спасибо за комментарий и вопрос.
1. Мы хотим сделать не просто набор инструментов из которых можно собрать pipeline, а интегрировать их, связать предварительными настройками и сделать единый фронт.
Особое внимание мы хотим уделить фичам по мониторингу реализации задач исполнителями — быстрый срез основных метрик, начало этапов сборки/тестирование/деплоя, процент выполнения ревью кода, процент документирования, соответствия стандартам кода и т.д.
А также удобным механизмам для сбора KPI и отображение в виде наглядных дашбородов, которые позволят бизнесу видеть оперативные показатели качества работы команд — скорость, качество кода, делать бенчмаркинг по показателям между командами, проверять результативность изменений в работе команд (как меняются показатели по результатам изменений. Примеры изменений — длина спринта, методы тестирования), а также выявлять тенденции деградации показателей для принятия мер по диагностике и устранению причин.
2. Мы не утверждаем, что у нас больше компетенций, например по Kubernetes, чем у специалистов Google. Мы опираемся на опыт нашей внутренней разработки, а также на ряд уже реализованных on-premise проектов (достаточно кастомизированных) для наших заказчиков.
powerman
09.08.2018 15:22Ещё один момент — совершенно не обязательно ограничиваться бесплатными продуктами при сборке pipeline. Многие могут захотеть держать код в приватных репо на гитхабе, или собирать в CircleCI.
maxbaluev
09.08.2018 15:47Вы придумали nanobox.io
Ssklabovskiy Автор
09.08.2018 18:15Наш подход в целом схож — максимально упростить работу команд разработки. Да, мы планируем реализовать набор преднастроенных типовых конфигураций. Тем не менее сам pipeline будет полностью прозрачен — пользователь будет видеть, какими инструментами пользуется — даже будет иметь возможность изменять настройки и заменять сами инструменты.
grinCo
09.08.2018 20:01Не понял в чем отличие от Azure, AWS, Google Cloud?
Ssklabovskiy Автор
10.08.2018 12:58Мы гибче подходим к разработке и открыты к диалогу, плюс находимся в РФ.
Vkuvaev
10.08.2018 02:41Как представитель вендора пишу, навскидку, добавил бы статический анализ кода, включая безопасность, репозиторий артефактов в общем смысле ну и подумал заменить LoadRunner на StormRunner Load, можем это обсудить
APXEOLOG
А возможности для разработчика задеплоить куда-то из своей feature-ветки вы не предусматриваете?
Ssklabovskiy Автор
Спасибо за вопрос. Да, мы планируем реализовать для разработчиков возможность разворачивать собственные песочницы, чтобы можно было самостоятельно деплоить в stage.
APXEOLOG
А как насчет большего кол-ва сред для деплоя? Например в моих текущих продуктах помимо stage'а есть еще dev, который крушат разработчики в процессе своих тестов чтобы не ломать stage
Ssklabovskiy Автор
Мы понимаем, что для больших команд и проектов необходимо наличие нескольких сред для деплоя и данную возможность планируем к реализации. Подскажите, какое количество сред вы обычно задействуете для своих проектов?
APXEOLOG
dev/stage/prod — самая частая композиция с которой я сталкивался. Бывали еще случаи с нескольким кол-вом тестовых сред (например с добавлением regression), но это единичные
grinCo
Feature-oriented development подразумевает отдельную среду для каждой фичи. У нас обычно одновременно развернуто 20-30 сред для разработки на проекте. После разработки фичи и релиза в прод — среду уничтожают.