
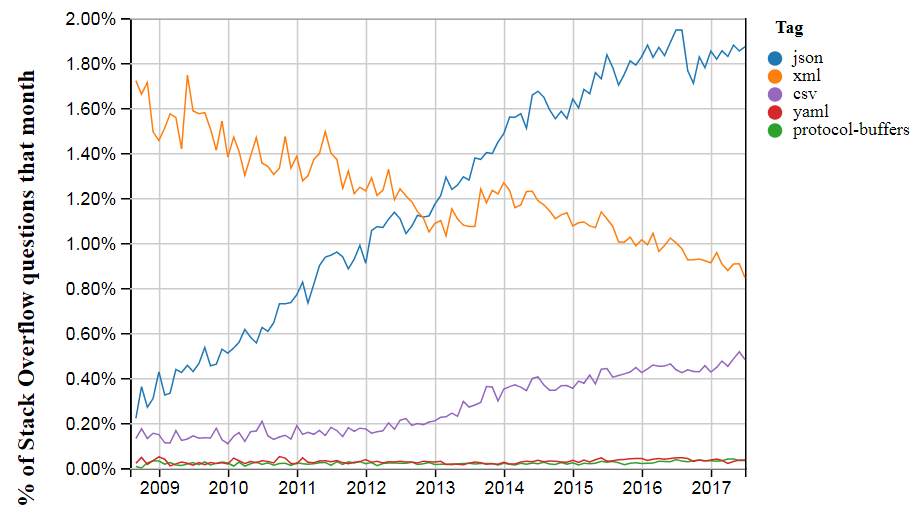
JSON захватил мир. Если сегодня любые два приложения общаются друг с другом через интернет, то скорее всего делают это с помощью JSON. Стандарт принят всеми крупными игроками: из десяти самых популярных Web API, которые разработаны в основном крупными компаниями, такими как Google, Facebook и Twitter, только один API передаёт данные в XML, а не JSON. Для примера, Twitter поддерживал XML до 2013 года, когда выпустил новую версию API исключительно на JSON. Среди остальных разработчиков JSON тоже популярен: согласно Stack Overflow, о JSON задаётся больше вопросов, чем о любом другом формате обмена данными.
XML ещё жив и много где используется. Например, в веб-форматах SVG, RSS и Atom. Если автор Android-приложения хочет объявить, что тому требуется разрешение от пользователя, то делает это в манифесте приложения, написанном на XML. И XML — не единственная альтернатива JSON: некоторые разработчики делают выбор в пользу YAML или Protocol Buffers от Google. Но эти форматы далеко не так популярны, как JSON, который сейчас стал практически стандартом де-факто для обмена данными между программами через интернет.
Доминирование JSON удивительно, ведь ещё в 2005 году все обсуждали потенциал «асинхронного JavaScript и XML», а не «асинхронного JavaScript и JSON». Конечно, есть вероятность, что это ничего не говорит об относительной популярности двух форматов, просто AJAX казался более привлекательной аббревиатурой, чем AJAJ. Но хотя в 2005 году некоторые уже использовали JSON вместо XML (на самом деле мало кто), до сих пор задаёшься вопросом, как XML мог так резко упасть, что спустя десятилетие фраза «асинхронный JavaScript и XML» вызывает ироническую усмешку. Что произошло за это десятилетие? Как JSON заменил XML во многих приложениях? И кто придумал этот формат данных, от которого теперь зависят инженеры и системы во всём мире?
Рождение JSON
Первое сообщение в формате JSON было отправлено в апреле 2001 года с компьютера в гараже неподалёку от Сан-Франциско. История сохранила имена причастных к событию: Дуглас Крокфорд и Чип Морнингстар, соучредители технологической консалтинговой компании State Software.
Эти двое занимались разработкой AJAX-приложений задолго до появления термина AJAX. Но поддержка приложений в браузерах была не очень хорошей. Они хотели передать данные в своё приложение после начальной загрузки страницы, но не нашли способа, который работал бы во всех браузерах.
Сегодня трудно поверить, но Internet Explorer в 2001 году был самым передовым браузером. Ещё с 1999 года Internet Explorer 5 поддерживал раннюю форму XMLHttpRequest через ActiveX. Крокфорд и Морнингстар могли применить эту технологию для получения данных в приложении, но она не работала в Netscape 4. Таким образом, пришлось искать другой формат, который работал в обоих браузерах.
Первое сообщение JSON выглядело так:
<html><head><script>
document.domain = 'fudco';
parent.session.receive(
{ to: "session", do: "test",
text: "Hello world" }
)
</script></head></html>Только небольшая часть сообщения напоминает JSON, каким мы его знаем сегодня. Само сообщение на самом деле представляет собой HTML-документ с парой строчек JavaScript. Часть, похожая на JSON, — просто литерал JavaScript для функции
receive().Крокфорд и Морнингстар решили злоупотребить фреймом HTML для отправки данных. Для фрейма можно указать URL, который вернёт HTML-документ, подобный приведённому выше. Когда HTML получен, JavaScript запускается и передаёт литерал обратно в приложение. Это работало при условии аккуратного обхода защиты браузера, предотвращающей доступ дочернего окна к родительскому: как видите, Крокфорд и Морнингстар явно установили домен документа. Такая техника иногда называется скрытым фреймом, она часто использовалась в конце 90-х до появления нормального XMLHttpRequest.
В первом сообщении JSON удивительно то, что здесь вообще не очевидно, что это первое использование нового вида формата данных. Тут всего лишь JavaScript! На самом деле идея использования JavaScript таким образом настолько проста, что сам Крокфорд считает, что он не первый это сделал — он утверждает, что кто-то в Netscape использовал литералы массива JavaScript для передачи информации ещё в 1996 году. Сообщение на простом JavaScript не требует какого-либо специального парсинга. Всё делает интерпретатор JavaScript.
На самом деле у первого в истории JSON-сообщения возникли проблемы с интерпретатором. JavaScript резервирует огромное количество слов — в ECMAScript 6 зарезервировано 64 слова — и Крокфорд и Морнингстар невольно использовали их в своём сообщении: а именно, зарезервированное слово
do в качестве ключа. Поскольку в JavaScript так много зарезервированных слов, Крокфорд решил не избегать их, а просто закавычивать все ключи JSON. Закавыченный ключ рассматривается интерпретатором JavaScript как строка, так что можно спокойно использовать зарезервированные слова. Вот почему ключи JSON по сей день закавычены.Крокфорд и Морнингстар поняли, что новый метод можно использовать во всех видах приложений. Они хотели назвать формат JSML (JavaScript Markup Language), но оказалось, что аббревиатура уже занята чем-то под названием Java Speech Markup Language. Поэтому выбрали Javascript Object Notation, то есть JSON. Они начали предлагать формат своим клиентам, но вскоре выяснилось, что те не рискуют использовать неизвестную технологией без официальной спецификации. Поэтому Крокфорд решил написать её.
В 2002 году Крокфорд купил домен JSON.org, опубликовал синтаксис JSON и пример реализации парсера. Веб-сайт до сих пор работает, хотя теперь демонстрирует ссылку на стандарт JSON ECMA, принятый в 2013 году. Кроме запуска сайта, Крокфорд практически ничего не предпринял для продвижения JSON, но вскоре появились реализации парсера JSON на самых разных языках программирования. Изначально JSON был явно связан с JavaScript, но затем стало понятно, что он хорошо подходит для обмена данными между произвольными парами языков.
Неправильный AJAX
JSON получил большой толчок в 2005 году. Тогда дизайнер и разработчик по имени Джесси Джеймс Гарретт в своей статье ввёл в обращение термин AJAX. Он старался подчеркнуть, что AJAX — не какая-то одна новая технология, а скорее «несколько по-своему хороших технологий, объединённых мощными новыми способами». Новому подходу к разработке веб-приложений Гарретт дал название AJAX. В блоге он рассказал, как разработчики могут использовать JavaScript и XMLHttpRequest для создания более интерактивных приложений. Он назвал Gmail и Flickr примерами сайтов, опирающихся на методы AJAX.
Конечно, «X» в AJAX означало XML. Но в последующих вопросах и ответах Гарретт назвал JSON вполне приемлемой альтернативой. Он писал, что «XML является наиболее функциональным средством обмена данными для клиента AJAX, но того же эффекта можно достичь с помощью Javascript Object Notation или любого подобного формата структурирования данных».
Разработчики действительно обнаружили, что могут легко использовать JSON для создания приложений AJAX, и многие выбрали его вместо XML. По иронии судьбы, интерес к AJAX привёл к взрыву популярности JSON. Примерно в это время JSON привлёк внимание блогосферы.
В 2006 году Дейв Уайнер, плодовитый блогер и создатель ряда XML-технологий, таких как RSS и XML-RPC, пожаловался, что JSON заново изобретает XML без уважительной причины:
«Конечно, я могу написать процедуру для парсинга [JSON], но посмотрите, как далеко они зашли в повторном изобретении технологии: по какой-то причине XML недостаточно хорош для них (интересно, почему). Кто создал эту пародию? Давай найдём дерево и повесим парня. Прямо сейчас».
Легко понять разочарование Уайнера. XML никогда особо не любили. Даже сам Уайнер сказал, что ему не нравится XML. Но XML был разработан как универсальная система для любых приложений, какие только можно вообразить. XML на самом деле является метаязыком, который позволяет определять доменные языки для отдельных приложений — например, RSS и SOAP. Уайнер считает, что важно выработать консенсус ради всех преимуществ, которые несёт общий формат обмена. По его мнению, гибкость XML в состоянии удовлетворить любые потребности. И всё же вот JSON — формат, не предлагающий никаких преимуществ по сравнению с XML, за исключением очистки от хлама, который сделал XML настолько гибким.
Крокфорд увидел сообщение в блоге Уайнера и оставил комментарий. В ответ на обвинение в том, что JSON заново изобретает XML, Крокфорд написал: «Повторное изобретение колеса хорошо тем, что можно сделать его круглым».
JSON vs XML
К 2014 году JSON официально признали стандартом ECMA и RFC. Он получил свой тип MIME. JSON вышел в высшую лигу.
Почему JSON стал намного популярнее XML?
На JSON.org Крокфорд перечисляет некоторые преимущества JSON по сравнению с XML. Он пишет, что JSON легче для понимания и людьми, и машинами, поскольку его синтаксис минимален, а структура предсказуема. Другие блогеры упоминают многословие XML и «налог на теги». Каждому открывающему тегу в XML должен соответствовать закрывающий тег, что означает много избыточной информации. Это делает XML намного больше эквивалентного документа JSON, но ещё важнее, что из-за этого XML-документ труднее читать.
Крокфорд называл ещё одно большое преимущество JSON: то, что он изначально разработан как формат обмена структурированной информации между программами. Хотя XML использовали для той же цели, но изначально он разработан как язык разметки документа. Он вырос из SGML (Standard Generalized Markup Language), который, в свою очередь, эволюционировал из языка разметки Scribe, предназначенного для разметки текста, как LaTeX. В XML внутри тега может находиться так называемое «смешанное содержимое», то есть текст со встроенными тегами, окружающими слова или фразы. Это напоминает редактора, помечающего рукопись красным или синим маркером, своеобразная метафора для языка разметки. С другой стороны, JSON не поддерживает точный аналог смешанного контента, что означает упрощение структуры. Документ лучше всего представить в виде дерева, но отказавшись от идеи документа, Крокфорд смог ограничить JSON словарями и массивами знакомых элементов, которые все программисты используют в создании своих программ.
Наконец, моя собственная догадка заключается в том, что людям не нравилась запутанность XML, и он действительно был таким из-за своего разнообразия. На первый взгляд трудно различить грань между собственно XML и его субъязыками, такими как RSS, ATOM, SOAP или SVG. Первые строки типичного XML-документа устанавливают версию XML, а затем конкретный подязык, которому должен соответствовать XML-документ. Это уже много вариантов по сравнению с JSON, который настолько прост, что никакая новая версия спецификации JSON никогда не будет написана. Разработчики XML в попытке создать единый формат обмена данными для всего пали жертвой классической ловушки программиста: чрезмерного технического усложнения. XML настолько общий, что его трудно использовать для чего-то простого.
В 2000 году началась кампания по приведению HTML в соответствие со стандартом XML. Опубликовали спецификацию для XML-совместимого HTML, впоследствии известного как XHTML. Некоторые производители браузеров сразу начали поддерживать новый стандарт, но быстро стало очевидно, что широкая публика, работающая с HTML, не желает менять свои привычки. Новый стандарт требовал более строгой проверки XHTML, чем было принято для HTML, но слишком многие сайты зависели от вольных правил HTML. К 2009 году активисты прекратили попытки написать вторую версию XHTML, когда стало ясно, что будущее за стандартом HTML5, который не требовал соответствия XML.
Если бы усилия XHTML увенчались успехом, возможно, XML стал бы общим форматом данных, как надеялись его разработчики. Представьте себе мир, в котором у HTML-документов и ответов API в точности одинаковая структура. В таком мире JSON, возможно, не стал бы таким популярным, как сегодня. Но я считаю провал XHTML своего рода моральным поражением лагеря XML. Если XML не помог HTML, возможно, есть лучшие инструменты и для других приложений. В реальном мире легко понять, почему простой и узкоспециализированный формат JSON получил столь большой успех.
Комментарии (134)

CheY
29.08.2018 16:02Сравнение на графике какое-то безумное) могли бы ещё добавить HTML, plain text, xlsx, blob'ы. Почему бы и нет? Могут ведь! Главное чтобы JSON был выше всех
justhabrauser
29.08.2018 20:56-1Потому что задача статьи — «Шок! Видео! Трепет! Скандалы!»
«Редактор GT» — оно такое. Это их работа.
Не стреляйте в пианиста.
excentro
29.08.2018 16:42Ну и в банках много где только XML.
hMartin
30.08.2018 11:57Именно, а самая частая ошибка при реализации доработок — забыть согласовать с потребителем/поставщиком XSD и долго с этим упражняться потом. Большинство из-за этого делают резиновые XSD, что влечет за собой бессмысленность валидации :(
(что, однако, не спасает от ошибок при очередных изменениях формата взаимодействия между системами)
vics001
29.08.2018 17:17+5Добавили бы в json комментарии, а то другие опять колесо изобретают yaml, hcl…
PAE
29.08.2018 17:28Уже "придумали" суперсет для JSON, так называемый JSON5.
Разумеется, станет ли это распространённым или нет — вопрос, но самые "болезненные" недостатки обозначены — trailing commas, отсутствие ссылок и комментариев.
Мне кажется — что нет, не станет. Проще использовать HCL [для людей], который полностью конвертируем в JSON [для машин и людей].
khim
29.08.2018 20:43+1Отсутствие ссылок и комментариев — это преимущество, а не недостаток.
Спросите себя: если комментарий, который вы хотите прибавить к данным, настолько неважен, что его никто-никто и никогда не должен видеть — то зачем он вам? А если комментарий всё-таки может быть полезен для обработки (пусть иногда) — то что мешает его сделать отдельным полем 'notes', который большинство пользователей будет игнорировать?
Ссылки, также, проблема: если вам где-то нужна ссылка, то заведите ЯВНОЕ поле URL и обрабатывайте его ЯВНО. Не создавайте пользователям странных и неожиданных обращений в сеть там, где их быть не должно.
На самом деле бы из JSON'а парочку вещей бы выкинул ещё… Но он и в текущем виде достаточно прост — ради совместимости можно потерпеть. Но добавлять туда точно ничего не нужно.KvanTTT
29.08.2018 20:57Спросите себя: если комментарий, который вы хотите прибавить к данным, настолько неважен, что его никто-никто и никогда не должен видеть — то зачем он вам? А если комментарий всё-таки может быть полезен для обработки (пусть иногда) — то что мешает его сделать отдельным полем 'notes', который большинство пользователей будет игнорировать?
Ну например если есть задача сделать строгую схему данных, в которой запрещены опциональные свойства.
gudvinr
29.08.2018 21:51Для валидации ведь есть, как минимум, JSON Schema.
Если этого требует какая-то частная задача — можно попотеть и написать/поискать валидатор.
От того, что вы добавите строгую схему данных в условном JSON 2.0 и запретите опциональные свойства, конечные потребители не станут следовать этим правилам ввиду того, что уже есть тонны реализаций каноничного JSON, и ни в одночасье, ни в обозримой перспективе они не перейдут на новый стандарт, потому что "работает — не трожь".
Тем более, что немало реализаций поддерживают де-/сериализацию JSON с учётом требований, о которых вы говорите, правда, не на уровне спецификаций JSON, а на стороне библиотеки.
Vorber
29.08.2018 22:13Схема и документ сущности всё-таки разные. И JSON-schema как раз позволяет (и по-умолчанию даже побуждает) описывать как раз такие форматы документов у которых нет опциональных свойтв в объектах.
PAE
29.08.2018 21:02+1Спросите себя: если комментарий, который вы хотите прибавить к данным, настолько неважен, что его никто-никто и никогда не должен видеть — то зачем он вам?
JSON — уже далеко не только формат обмена данными между машиной-и-машиной, это ещё и способ описания конфигураций и часто применяется как файл профилей или файл настроек (хотя эта сфера постепенно вытесняется YAML).
Комментарии нужны, если JSON будет просматриваться, редактироваться и адаптироваться людьми под какие-то свои нужды.
Ссылки, также, проблема: если вам где-то нужна ссылка, то заведите ЯВНОЕ поле URL и обрабатывайте его ЯВНО. Не создавайте пользователям странных и неожиданных обращений в сеть там, где их быть не должно.
Речь не про URL, вообще не об этом. Речь про возможность сослаться на другие переменные (параметры) или шаблонизировать (аналогии — надстройки над CSS).
xmetropol
29.08.2018 21:10Если JSON использовать только как формат для обмена данными, то комментарии действительно не нужны. Но сейчас JSON используют везде, и где надо, и где не надо. Вот допустим описание конфигурации чего-либо. Если я хочу временно отключить часть конфигурации, то в XML я могу просто воспользоваться комментарием.
justboris
29.08.2018 22:50+2Пару примеров, где комментарии в JSON могут быть полезными.
1) Настраиваю какую-то систему, играюсь с конфигом. Пусть это будет tsconfig.json, например. Иногда хочется быстро отключить пару опций, что-то потестить и включить обратно. Было бы удобно включать/отключать при помощи комментов:
{ "compilerOptions": { "module": "commonjs", //"noImplicitAny": true, //"sourceMap": true } }
2) Когда наконец-то нашел подходящее сочетание параметров, хочется оставить какое-то объяснение будущим разработчиком, что же здесь стоит именно такое значение:
{ "compilerOptions": { // use legacy module format until migration is complete "module": "commonjs", } }
К счастью, все это возможно в Typescript, потому что он поддерживает комментарии в JSON-синтаксисе.
xmetropol
29.08.2018 23:22К счастью, все это возможно в Typescript, потому что он поддерживает комментарии в JSON-синтаксисе.
Честно говоря, это похоже на ситуацию, когдалохматые гвоздикишурупы пытаются забивать молотком в гипсокартон. Т.е. вот даже из статьи вроде как выходит JSON появился на свет не как грамотно продуманное решение, а скорее как некий костыль для решения определенной задачи в условиях существующих на тот момент технологий (кстати отдаленно напоминает историю создания одного популярного языка программирования). Но сейчас в защиту преподносятся аргументы перед XML, такие как простота, выразительность, элегантность и т.д. Вот только незадача, не хватает комментариев и прочих вещей (может однажды и CDATA переизобретут), которые так нужны сейчас в решении несвойственных данному формату задач. Поэтому давайте доделывать всякие костыли, из которых, возможно, когда-нибудь получится XML. У меня всё чаще складывается ощущение, что я где-то пропустил свою остановку.justboris
29.08.2018 23:50Если использовать JSON только для общения сервера с клиентами, то комменты не нужны. Наоборот, чем меньше данных передается, тем лучше.
А вот в конфигурационных файлах нужно комментировать, почему настроено именно так, а не иначе. В каком формате вы обычно пишете конфигурацию?xmetropol
29.08.2018 23:59Вы точно у меня хотели спросить? Я думал по моему комментарию очевидно будет, что я не фанат JSON от слова «совсем». Я согласен с комментатором ниже, что конфиг в JSON — злое зло. Мой выбор XML. И этот выбор применителен не только к описанию конфигурации.
justboris
30.08.2018 10:44+2Я в свое время достаточно наредактировался файлов pom.xml, чтобы больше не хотеть пользоваться этим форматом. Или у вас есть рецепт, как писать конфигурацию на xml, чтобы было компактно и читаемо, а не вот это?
<plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-source-plugin</artifactId> <executions> <execution> <id>attach-sources</id> <goals> <goal>jar</goal> </goals> </execution> </executions> </plugin> </plugins>
4 строки значимой информации из 14. Такой конфиг почти как человек — на 70% состоит из воды.
mayorovp
30.08.2018 11:39Если такой формат перевести на JSON один в один, вы тоже не обрадуетесь.
А сократить можно было бы как-нибудь вот так:
<plugin groupId="org.apache.maven.plugins" artifactId="maven-source-plugin"> <execution id="attach-sources"> <goal>jar</goal> </execution> </plugin>mrsantak
30.08.2018 15:30Это будет работать до тех пор пока у вас один plugin, один execution и один goal (ну или если под execution не может лежать ничего кроме goal, под plugin — ничего кроме execution и т.д.).
mayorovp
30.08.2018 16:00Нет, это будет работать с произвольным числом произвольных элементов. Нет никаких проблем писать вот так:
<plugin ...> <execution>...</execution> <execution>...</execution> <execution>...</execution> <execution>...</execution> <foo>...</foo> <foo>...</foo> <bar>...</bar> </plugin>TerraV
30.08.2018 16:04А теперь уговорите сообщество перейти на этот формат. Про что вам собственно и говорят. XML это или мысль в камне или аццкая боль переделки.
mrsantak
30.08.2018 16:07Переделать как раз не проблема — в данном случае идет речь о xml покрытом хорошей xsd схемой, сконвертировать один формат в другой несложно каким-нибудь xslt.
mayorovp
30.08.2018 16:45А вы тогда уговорите сообщество перейти на JSON. Про что я собственно и говорю, что проблема не в XML, а в выбранной схеме.
mrsantak
30.08.2018 16:05Оно будет работать в том смысле, что распарсится, но оно не очень будет работать с точки зрения читаемости. Вот у plugin может быть произвольное кол-во execution и dependency. Если не использовать обертки типа executions и dependencies, то вы получите мешанину из execution и dependency в произвольном порядке. В итоге полученная «оптимизация» улучшает только простейший конфиг, но ухудшает читаемость реальных конфигов.
И вы же понимаете что то что вы написали со временем выродится в
<plugin ...> <execution>...</execution> <foo>...</foo> <execution>...</execution> <bar>...</bar> <bar>...</bar> <foo>...</foo> <execution>...</execution> <execution>...</execution> </plugin>mayorovp
30.08.2018 16:13Да, я это понимаю. И считаю что нужно сознательно дать возможность пишущему конфиг писать элементы в том порядке в котором ему будет удобнее.
Но если вы считаете по-другому — ничто не мешает и потребовать строгого порядка элементов, в XSD есть все инструменты для этого.
Что же до формата реальных конфигов — я все еще не верю что от слепого преобразования в JSON они выиграют в удобочитаемости.
mrsantak
30.08.2018 16:18Что же до формата реальных конфигов — я все еще не верю что от слепого преобразования в JSON они выиграют в читаемости.
Так ведь с этим никто вроде и не спорит. У json свои проблемы, у xml — свои.mayorovp
30.08.2018 16:25Да нет, в этой ветке как раз сравнивают форматы JSON и XML применительно к задаче написания конфигов на примере конфигов Typescript Compiler и Maven, против чего я и возражаю.

ris58h
30.08.2018 15:35У нас есть плагин.
mrsantak
30.08.2018 16:11Ну если для «человекочитаемого» формата нужен специальный редактор, чтобы его было удобно читать, то что-то не так с этим форматом.
ris58h
30.08.2018 21:44Это проблема многословности схемы самого Maven, а не формата (это как раз рядом обсуждают). И плагин решает именно эту проблему, и не какую-то ещё.
xmetropol
30.08.2018 17:12+1Хотя Вам уже ответили, но вот 2 версии вашего конфига:
xml
<plugins> <plugin groupId="org.apache.maven.plugins" artifactId="maven-source-plugin"> <executions> <execution id="attach-sources"> <goals> <goal>jar</goal> </goals> </execution> </executions> </plugin> </plugins>
json
{ "plugins": [ { "groupId": "org.apache.maven.plugins", "artifactId": "maven-source-plugin", "executions": [ { "id": "attach-sources", "goals": [ { "goal": "jar" } ] } ] } ] }
Что в xml версии больше "шума", так это факт, я спорить не буду. Но лично мне xml версия больше нравится.
taujavarob
30.08.2018 20:54Моя версия:
{ "plugins": [ {"org.apache.maven.plugins": { "maven-source-plugin": { "executions": [ { "attach-sources": { "goals": ["jar"] } } ] } } } ] }
Или же перепишем это одной строкой:
{"plugins": [{"org.apache.maven.plugins": {"maven-source-plugin": {"executions": [{"attach-sources": {"goals": ["jar"]}}]}}}]}
Если строка длинная, то можно переписать и так:
{"plugins": [ {"org.apache.maven.plugins": {"maven-source-plugin": {"executions": [ {"attach-sources": {"goals": ["jar"]}}] } } }] }
P.S.
Мы неявно(!) задаём ID («org.apache.maven.plugins», «maven-source-plugin», «attach-sources») по правилу:
Eсли значение свойства есть объект (исключая массив), то имя этого свойства есть ID это объекта.
Если у объекта есть два и более ID, в данном случае «groupId» и «artifactId», вначале указываем самое «верхнее», а потом то что «ниже» этого самого «верхнего» и т.д. (применительно к расположению в изначальном xml).xmetropol
30.08.2018 21:36Вы сейчас придумали оптимизацию, которая сэкономила на 1-м названии свойства для каждого объекта (Id). Зато сломали мозг пользователям, которые без вашего объяснения не будут знать, как править конфиг, а так же заставив разработчиков написать вручную десериализаторы для чтения таких конфигов т.к. я думаю ни в Java (для которой собственно и был пример приведён), ни в C#, ни в любом другом языке по умолчанию сериализаторы не будут знать о ваших оптимизациях.
taujavarob
31.08.2018 20:57Зато сломали мозг пользователям, которые без вашего объяснения не будут знать, как править конфиг
Они будут руководствуясь правилом: Eсли значение свойства есть объект (исключая массив), то имя этого свойства есть ID это объекта.
vintageНу и для сравнения то же самое на tree:
Ваша идея подсказала дальнейшее изменение моего кодa:
{"plugins": {"org.apache.maven.plugins": {"maven-source-plugin": {"executions": {"attach-sources": {"goals": "jar"}} } } } }
Или одной строкой:
{"plugins":{"org.apache.maven.plugins":{"maven-source-plugin": {"executions":{"attach-sources": {"goals": "jar"}}}}}}
Здесь правило простое: Если ожидается массив, а вместо этого «поступает» объект или «примитивный» тип данных, то это можно рассматривать как массив с единственным элементом.
Что теряем?
В исходном:
<groupId>org.apache.maven.plugins</groupId> <artifactId>maven-source-plugin</artifactId>
не имеет значения порядок, можно писать и так:
<artifactId>maven-source-plugin</artifactId> <groupId>org.apache.maven.plugins</groupId>
В моём предложении порядок имеет значение.
Но замечу, что
<groupId>org.apache.maven.plugins</groupId> <artifactId>maven-source-plugin</artifactId>
Фактически есть указание составного ID.
Да, при внесении нового ID, например:
<superGroupId>org.apache.maven</groupId> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-source-plugin</artifactId>
Также у меня поломает всё.
vintage
30.08.2018 21:15-2Ну и для сравнения то же самое на tree:
plugin groupId \org.apache.maven.plugins artifactId \maven-source-plugin execution id \attach-sources goal \jarmayorovp
31.08.2018 06:21А куда делся знак =?
vintage
31.08.2018 06:27Давно уже заменён на бэкслеш, чтобы не вводить в заблуждение. Это префикс сырых данных, а не разделитель ключа и значения.
mayorovp
31.08.2018 06:35Вот в этом и (еще одна) проблема языка tree — вы его меняете как пожелаете и держите изменения синтаксиса в секрете.
vintage
31.08.2018 06:48Не было никакого секрета. А как показало обсуждение без данного изменения у формата нет никаких шансов обрести популярность.
mayorovp
31.08.2018 06:51Надо статью править целиком, а не подобное незаметное обновление добавлять. Потому что сейчас про формат tree всего одна статья, и в той примеры некорректные...
Aries_ua
30.08.2018 10:07Если вы используете JS стек технологий, то напишите конфигурацию в JS файле. К примеру:
// file settings.js const settings = { host: 'localhost', port: 3000 }; export default Object.freeze(settings);
Для Python использовал подобную схему со словарями.justboris
30.08.2018 10:31Да, это самый лучший вариант.
К сожалению, Typescript не хочет поддерживать такой формат. Они мотивируют это тем, что JSON может пониматься большим числом инструментов, а для конфигурации в коде нужно обязательно тащить интерпретатор.
MikailBag
30.08.2018 16:22При этом вы теряете возможность менять конфиг не вручную. Например, скриптом для миграции.
michael_vostrikov
30.08.2018 06:14может однажды и CDATA переизобретут
А зачем? CDATA для произвольных данных бесполезен, потому что в них может встретиться
]]>. Все равно надо делать специальную обработку, проще уж что-то типаhtmlspecialchars()использовать. Для JSON чтобы не сломать разметку можно использовать ту же самую функцию, что его генерирует, в PHP этоjson_encode(). Там строки в кавычках, я бы даже сказал,<![CDATA[и]]>это переизобретение кавычек для строк. Если вы имеете в виду конфиги, то там бы конечно пригодилось, но в JSON это будет проще выглядеть, что-то типа"key": @"value"@. Так что XML все равно останется сложным и неудобным форматом.
khim
30.08.2018 01:55И всё это чудесным образом похерится как только кто-то откроет ваш конфиг а каком-нибудь визуальном редакторе JSON'а и сохранит его.
Совершенно непонятно что мешает сдать так:
Или так:{ "compilerOptions": { "module": "commonjs", "noImplicitAny": false, "sourceMap": false } }{ "compilerOptions": { "note": "Use legacy module format until migration is complete", "todo": "Remove when done", "module": "commonjs" } }justboris
30.08.2018 02:52И всё это чудесным образом похерится как только кто-то откроет ваш конфиг а каком-нибудь визуальном редакторе JSON'а и сохранит его.
Это проблема тулинга, а не комментариев как таковых
Совершенно непонятно что мешает сдать так:
С boolean еще более-менее удобно переключать, а если там enum? Вот в
moduleмогут быть 8 разных значений, переключаться между ними по памяти очень неудобно
Или так:
Ну это совсем костыли пошли. Нужно нормальное разделение: эта информация компьютерам, а остальная — людям.
vintage
30.08.2018 09:27-1Не нужно разделения. Вся информация должна легко читаться/писаться как компьютером, так и людьми. И если людям нужны комментарии, то машина должна иметь возможность как минимум их не терять, а как максимум — оперировать наравне с остальной информацией. Однако, модель данных JSON (словари, массивы и примитивы) не позволяет встраивать узлы с комментариями (и любой другой мета информацией, например, с позицией токена в исходном файле) в произвольное место дерева. Попытка решить эту проблему неизбежно приводит к чему-то типа DOM (списки типизированных узлов с детьми). JSON для сериализации DOM уже не подходит. XML подходит, но имеет кучу недостатков. Идеальный вариант — Tree, ибо разрабатывался специально для человекопонятного и машиночитаемого представления произвольных деревьев.
mayorovp
30.08.2018 09:39Вы про тот самый Tree, для которого невозможно построить DOM?..
vintage
30.08.2018 11:05В смысле невозможно? Там после парсинга получаетстя АСТ, который по сути и есть DOM.
mayorovp
30.08.2018 11:30Допустим я добавил в DOM значение "1\n2\n3", и сохранил в файл, а потом загрузил обратно. От нормального DOM я ожидаю что в нем будет нода с записанным значением, но Tree не позволяет реализовать это в принципе.
vintage
30.08.2018 21:22-2new $mol_tree({ value: '1\n2\n3' }).toString() "\1 \2 \3 " > $mol_tree.fromString( new $mol_tree({ value: '1\n2\n3' }) ).value "1 2 3"
Да, будет создано 4 ноды вместо одной, но это вполне прозрачно.
mayorovp
31.08.2018 06:22Хорошо, а как тогда будет выглядеть массив
[1,2,3]?vintage
31.08.2018 06:43Обычно массив получается как выборка:
const plugins = config.select( 'plugin' )
Но можно и модель JSON засунуть:
$mol_tree.fromJSON({ goals : [1,2,3] }).toString() "* goals / 1 2 3 "mayorovp
31.08.2018 06:49Э-э-э, что за знаки пуктуации? Вы когда про формат рассказывали обещали что массив будет выглядеть вот так:
goals \1 \2 \3vintage
31.08.2018 07:24Формат
treeне знает ничего про массивы, словари, множества и другие типы данных. Представить массив в tree можно как вы описали, но чтобы собрать массив обратно нужно написать соответствующий код, например:
const goals = config.select( 'goals' , '' ).sub.map( node => Number( node.value ) )
Если мы хотим на входе и выходе иметь модель данных JSON, то нам нужно обозначить соответствующие типы данных специальными узлами, чтобы можно было автоматически конвертировать обратно в JSON. Поэтому в языке
json.treeесть специальные токены:*для словарей и/для списков.
khim
30.08.2018 12:00
Нет такого разделения. В подавляющем большинстве форматов, которые поддерживают комментарии через какое-то время появлются всякие «комментарии для doxygen»а, «директивы препроцессора» и прочая муть, которая явно не только читателям этого файла адресована.Или так:
Ну это совсем костыли пошли. Нужно нормальное разделение: эта информация компьютерам, а остальная — людям.
Лучше изначально комментарии вставлять в машинно-читаемом виде и в более-менее стандартизованном формате.
Leopotam
30.08.2018 10:14Это все можно провернуть с любым парсером JSON, выкусив комментарии после чтения, например, так: gist.github.com/Leopotam/6216f793982f39571546a606a3a68ea5
justboris
30.08.2018 10:35А еще можно динамически генерировать файлы через код, где можно оставлять комменты. Но это все дополнительные пляски с бубном, которых можно избежать, если бы комментарии поддерживались нативно.
Leopotam
30.08.2018 10:40А можно изобрести телепатический передатчик и слать данные напрямую пользователю в мозг. Нужно соизмерять трудоемкость решения, выкусывание лишней информации одной регуляркой гораздо проще, чем куча кода по генерации данных руками. Ну и самое главное — это сохранит совместимость со всеми реализациями парсера, что важнее, чем удобство применения формата в одном конкретном случае.
Bronx
31.08.2018 08:27С этим как раз особой беды нет. Если нет строгой валидации, то «закомментировать» элементы можно их переименованием:
{ "option": "active", "-option": "inactive", ... }
Если валидатор не позволяет такое — можно просто удалять ненужные значения и полагаться на систему управления версиями.
А вот если захочется многострочных текстов (или даже просто длинных, или текстов с большим количеством кавычек), то беда.
mamont80
30.08.2018 09:53Если добавить комментарии в стандарт JSON, тогда их представление нужно добавлять в парсер. А тогда он перестанет быть простым. В DOM представлении XML можно достать и прочитать комментарии. Отсюда ещё усложняющий нюанс — комментарии начнут использовать в качестве управляющих конструкций. Так например произошло с SQL в Oracle. Там комментарии используются для указания хинтов запросов, какой индекс использовать. Типа так: /*+ RULE */
Для SQL это комментарий, а для СУБД нет. И мы получим уже навороченную конструкцию.
Обратная совместимость, ещё один момент. Разный софт долго может работать и считать что общается на одном диалекте JSON, пока что-то пойдёт не так. Думаю другие диалекты JSON навсегда останутся сторонними инструментами. Есть ещё вагон недостатков JSON, если на то пошло. Например нормального представления даты-времени, бинарники, ссылки и т.п., аппетит приходит во время еды.apapacy
30.08.2018 10:08www.w3.org/TR/xml/#sec-comments определяет что средства разбора могут но не должны обрабатывать комментарии.так что лучше на эту фразу не полагаться.
www.w3.org/TR/xml/#sec-pi как раз для этого сразу предусмотрели управляющие инструкцииkhim
30.08.2018 12:08www.w3.org/TR/xml/#sec-comments определяет что средства разбора могут но не должны обрабатывать комментарии.так что лучше на эту фразу не полагаться.
А никто на неё и не полагается. Типичный разработчик начинает читать документацию только тогда, когда что-то ломается. Так что если парсер комментарии не выкидывает (а хотя бы каким-то из них придётся это делать, потому что иначе, понимаете ли проблемы тулинга возникнут), то их будут использовать. Вот совершенно независимо от того, что написано в документации.
Собственно на эту тему есть всем известная статья — и если применить её к JSON, то станет понятно, что самая большая проблема с комментариями в JSON'е — это то, что существует много парсеров, которые принимают вроде-как-почти-но-не-совсем JSON-файлы с комментариями.
scg
29.08.2018 17:43+3Хм. Простой и элегантный, а количесво вопросов по нему на Stack Overflow растет. Парадокс.
track13
29.08.2018 18:38+4Там вопросы не по самому JSON, а по тому, как его использовать в том или ином фреймворке/языке/итд. К вопросу по QT ставят категорию C++, даже если спрашивают, как бэкграуд перекрасить, и C++ тут не при чём.

Umpiro
30.08.2018 14:03+1Что же тут парадоксального?
Простой -> Популярный -> Количество вопросов на SO
По пайтону недавно кто-то такую же зависимость обсуждал.
stepik777
29.08.2018 19:00+1К 2009 году активисты прекратили попытки написать вторую версию XHTML, когда стало ясно, что будущее за стандартом HTML5, который не требовал соответствия XML.
Стандарт HTML5 разрешает два варианта представления — в виде HTML и в виде XML (так называемый XHTML5). Так что XHTML вполне себе жив и поддерживается всеми современными браузерами.
ebt
29.08.2018 22:08В защиту XML перед JSON могу сказать, что длинные и сложные многоуровневые иерархические структуры всё-таки гораздо комфортнее просматривать и править в XML, а не в JSON.
Iqorek
30.08.2018 02:53+1В обвинение XML могу сказать, нужно избегать всеми средствами длинных, сложных, многоуровневых, иерархических структур. А XML, даже простой, читать совершенно некомфортно, из-за большого информационного шума, на каждый байт данных, там миниум 2 байта метаданных, а в реальности все 10, которые в 99.99% не нужны.
mayorovp
30.08.2018 08:44И как же вы ее избежите, если предметная область длинная, сложная и многоуровневая? :-)
Iqorek
30.08.2018 11:16Тогда первое что нужно сделать, это избавиться от XML, потому что он добавляет длинны, сложности и уровни. Дальше универсального рецепта нет, по обстоятельствам.
mayorovp
30.08.2018 13:04Или же можно перестать относиться к xml как к чему-то созданному чтобы добавлять сложность, и начать использовать его механизмы для уменьшения этой самой сложности...
DaylightIsBurning
30.08.2018 11:35Не совсем понял, почему XML в таком случае будет комфортнее. Можно пример?
ebt
30.08.2018 13:03В JSON уровни вложенности задаются с помощью квадратных и фигурных скобок. Так, на десятом уровне вам придётся отслеживать неестественную для глаз мешанину, где даже отступы не помогут. В таких ситуациях намного удобнее иметь дело с закрывающими тэгами XML.
Chamie
30.08.2018 13:47неестественную для глаз мешанину, где даже
Не могу представить. Опять же, JSON проще однозначно отформатировать отступами, чтобы всё было понятно, а в XML атрибуты и дочерние элементы непонятно, как отделять (речь про варианты с множеством атрибутов, которые не влезают в строку).mayorovp
30.08.2018 13:57Например, вот так:
<element attr1="..." attr2="..." attr3="..." > <child1>...</child1> <child2>...</child2> <child3>...</child3> </element>
yurec_bond
29.08.2018 23:46-1Сила XML в неймспейсах (namespace) — но их мало кто понимает
Как формат для передачи данных, в обоих форматах (XML и JSON) не хватает ссылок (внутренних ссылок между объектами в документе)
Читать JSON действительно легче. А вот писать ИМХО сложно и противно, в основном из-за запятых.
P.S. Использовать JSON в качестве формата для конфигурационных файлов — смертный грехIqorek
30.08.2018 03:22Эти неймспейсы ещё больше замусоривают код. Спасибо, что мы от них избавились.
Ссылки, за столько лет ни разу не было в них нужды, но тоже не проблема, например так:
{ "prop1": { "prop11": "val1" }, "prop2": "#ref://prop1/prop11" }
да после парсинга надо будет пробежаться по объекту и заменить #ref:// на ссылку на объект.
Но лучше чтобы объекты были простые и плоские.
Использовать JSON в качестве формата для конфигурационных файлов — смертный грех
Если XML, уж лучше JSON, но после множества перепробованных форматов, я склоняюсь, что лучший формат конфигурации, это старый добрый ini, простой, лаконичный, читабельный и даже если где то нет для него парсера, можно самому написать в 3 строки, иногда еще короче.
sand14
30.08.2018 09:36> Сила XML в неймспейсах (namespace) — но их мало кто понимает
В теории.
На практике, когда они используются, их не обрабатывают нормально, а делают всякие костыльные решения, вроде удаления неймспейсов перед чтением, или читая, игнорируя неймспейсы.
Так же, как никто не обрабатывает нормально XML схему перед чтением.
Суть в том, что XML это сложное решение, которое требует промышленного подхода в работе, и в эпоху скрама и аджайла с ним точно никто не будет работать нормально, к сожалению.
Сделать поддержку какого-нибудь сложного XML-based формата или конфига за пару дней никто ж е даст — это ж чуть ли не Epic Story, за которую нужно делать продуктовые таски.
apapacy
30.08.2018 01:12+2Есть одно существеное преимущество котрое делает JSON удобнее чем XML, если использовать XML без описания схемы документа (а такой случай довольно часто встречается). У JSON есть способ задания массива значений который исключает многозначаность, которая писутсвует в XML.
Сравним два документа
<root> ... <users> <user><name>John</name></user> </users> ... </root>
<root> ... <users> <user><name>John</name></user> <user><name>Joe</name></user> </users> ... </root>
При разборе второго случая ясно что это будет массив
$root['users']['user'][0]['name'] === 'John'
А что с первым случаем? Парсер если нет заданной схемы не знает как разобрать документ. И в зависимости от опций может выдать результат
$root['users']['user']['name'] === 'John'
Или если задать в опциях что все единичные элементы считаются массивами
$root['users'][0]['user'][0]['name'] === 'John'
Но в этом случае даже там где подразумеваются всегда единричные элементы приходится все писать через [0].
И еще ведь нельзя в XML задать чтобы было
$root['users'][0]['name'] === 'John'
Нужно обязательно вот это ['users']['user']
Обмен документами ХМL без заданной схемы это не такой уж надуманный случай. Я напрпимер недавно интегрировался с очень популярной у нас системой обработки заказов клиентов (примем заказа, изготовление, доставка) где обмен шел по SOAP. Казалось бы, SOAP по опредеению идет только по зараннее заданной схеме. Но наш разработчик найдет способ. Да по SOAP шел обмен. Но в документе был описано ровно один строковый элемент с именем xml который собствено и нужно было разбирать. Пришлось для каждого такого ответа самому создавать описание схемы чтобы можно было без больших проблем сделать парсинг этог документа.
Поэтому совсем не удивительно что для простых случаев JSON сейчсас превалирует.
Еси говорить чего не хватает то я бы назвал тип даты. С числами также нет возможность задать целые числа и числа с фиксированной точкой (точностью).mayorovp
30.08.2018 08:57Строковый элемент с именем xml? За такое руки отрывать надо, а не использовать эту ситуацию в качестве аргумента :-)
Что же до неоднозначности разбора XML — тут все просто. Надо не заниматься десериализацией без схемы, а использовать XPath. В запросе
/root/users/user[1]/nameнет никакой неоднозначности.
В том, что для простых случаев JSON подходит лучше — соглашусь, но не каждый случай простой. К примеру, если объектная модель использует полиморфизм — то в JSON приходится вводить служебные свойства для хранения имени типа (и разные библиотеки используют разные соглашения!), в то время как в XML имя типа отображается на имя тэга.
adeptoleg
30.08.2018 09:08Никто не спорит просто для передачи информации XML слишком жырный. А вот как средство удобного хранения конфигов XML я думаю по цена качество идеален
mayorovp
30.08.2018 09:23Рассмотрим для примера вот такую страницу: https://portal.eaeunion.org/sites/odata/_layouts/15/Registry/Share/CardView.aspx?Code=P.TS.01&EntityId=646 (это случайная карточка из случайного реестра, не ищите в выборе реестра и карточки скрытых смыслов)
Вы уверены, что запихнув все эти данные в JSON вы упростите передачу информации, а не усложните?
apapacy
30.08.2018 09:57Мы говорим в данном случае об xml без схемы. Если описать схему документа потом сериализовать в объект то конечный пользователь сервиса будет просто счастлив. Но если разбирать этот документ без схемы или ещё лучше запросами DOM или XPath то уверен с json проще.
mayorovp
30.08.2018 10:38Конечно же я говорю об XML со схемой! Любые сложные данные без схемы — это мусор, а не данные…
khim
30.08.2018 12:29А как насчёт реальности? Когда есть схема XML, есть данные — и эти данные схеме не очень-то соотвествуют? И нужные вам данные засунуты либо туда, где, по хорошему, должно лежать что-то другое, либо вообще в комментарии?
Как показывает практика — XML-базы очень быстро превращаются именно в этот вариант.mayorovp
30.08.2018 12:48Как показала практика — XML-база может годами оставаться в нормальном состоянии и ни во что не превращаться.
К примеру, если вы найдете XML-исходник для документа по ссылке выше — вы не найдете там никаких данных в комментариях или в нарушающем семантику тэге.khim
30.08.2018 13:33Хорошо если так. Но в моей практике — это происходит ровно до тех пор, пока в XML не приходится добавлять никаких новых сущностей. А в этом случае не только JSON, но и CSV хватает.
А вот если расширение требуется… То тут веселье и начинается.mayorovp
30.08.2018 13:44Добавление новых сущностей начинается с расширения схемы и ее согласования. Что значительно лучше чем JSON, где никому даже в голову не приходит использовать какую-то глупую схему и ее согласовывать, в результате чего о новой схеме все узнают по факту поломки взаимодействия, и хорошо еще если оно не на проде поломалось...
khim
30.08.2018 14:15Добавление новых сущностей начинается с расширения схемы и ее согласования.
Это идеал, который я очень редко видел применяющимся на практике. Особенно если данные должны «протуннелировать» через несколько слоёв. Потому что в этом случае гораздо проще договорится, скажем, что альтернативные имена познаются, по прежнему, в тег , но отделяются там запятыми или пробелами или ещё как нибудь. Ну вспомните хотя бы про аттрибут «class» в XHTML!
Что значительно лучше чем JSON, где никому даже в голову не приходит использовать какую-то глупую схему и ее согласовывать, в результате чего о новой схеме все узнают по факту поломки взаимодействия, и хорошо еще если оно не на проде поломалось...
Опять-таки, из практики: поломка — это гораздо лучше, чем когда у вас всё «как бы работает»… но неправильно. И да, отсутствие схемы сразу автоматически означает, что её не нужно согласовывать, а также, при грамотном использовании, то, что если у
вас несколько потребителей, то про ваши расширения, которые касаются не всех, не нужно будет всем и сообщать.mayorovp
30.08.2018 14:38А вот как раз в таких случаях и нужны пространства имен на которые тут уже жаловались. В общую схему добавляется
<xs:any namespace="..." processContents="lax" />и все. Кому эти данные предназначены, с тем согласовывается дополнительная схема, а остальные эти элементы игнорируют.khim
30.08.2018 22:14Опять двадцать пять. Вы опять исходите из идаелистичной картинки, где люди читают и пишут спеки, доки, и соблюдают то, что в них написано.
Но это же не так. Посмотрите на мои примеры, на пример с которого всё началось. Да, блин, посмотрите на OOXML — это, между прочим, международный стандарт. 6546 страниц документации. А описание принтера, с которым этот документ свёрстан — это, я извиняюсь, CDATA. Почти как тот «строковый элемент с именем xml», с которого всё началось.
Думаете это мелкая деталь реализации, которая мало на что влияет? Ага, я вам щаз губозакатывательную машинку подарю: вся вёрстка в MS Office завязана на характеристики конкретного принтера, для которого документ верстается. Вся. Вплоть до того, что если вы верстаете книжку под какой-нибудь матричник 360dpi, а потом пытаетесь послать её в типографию, чтобы там её распечатали на устройстве с 300dpi или 1200dpi, то зачастую сможете обнаружить что у вас в книжке стало другое количество страниц!
А вы говорите — сограсовывание схем и пространства имён… Ага. Щаз.
Может где-нибудь в NASA ваши идеи и будут работать, но в других местах… 90% разработчиков на поддрежку пространств имён просто забьют. А 90% из оставшихся реализуют поддержку — но сделают это с ошибками. Потому что док они не читают, ничего ни с чем не согласовывают, а код пишут путём дёрганья ответов на случайные вопросы на StackOverflow.
Это не то, что стоит обсуждать и не то, с чем стоит бороться — это просто данность. За написание программ и закрытие «тасков» платят, а за согласование «схемы» — нет. Всё дальнейшее из этого следует.
khim
30.08.2018 12:27Вы уверены, что запихнув все эти данные в JSON вы упростите передачу информации, а не усложните?
Уверен. Именно потому что данные будут иногда не лезть в оговоренный способ представления — и его придётся менять.
Вместо того, чтобы впихивать круглую палку в квадратное отверстие «очень сильным программистом», которое потом нужно будет расхлёбывать на стороне парсера.
MacIn
30.08.2018 13:29Смотря какие задачи… гляда на нынешние свои, могу с апломбом заявить, что INI файлы как средство для удобного хранения конфигов — юбер аллес.
apapacy
30.08.2018 09:52На самом деле это продукт используют наверное половина если не 90% служб по дизготовлению и доставке пиццы, суши и т.п. При их доходах можно было бы сделать все нормально. Тут и аргумент не нужен. Или так или никак. Кстати это не единственный в моей практике случай. Правда в других случаях я мог теоретически повлиять на ситуацию. Но не сделал этого т.к. понимал что сроки предоставления мне служб soap будут сорваны.
khim
30.08.2018 12:23Строковый элемент с именем xml? За такое руки отрывать надо, а не использовать эту ситуацию в качестве аргумента :-)
Вот спека. Расскажите, кому и когда вы будете отрывать руки. Вот вам ещё парочка (AArch32 и AArch64). Я работал со всеми тремя за последний год. Все ужасы, про которые тут говорится — там имеюются во всей красе.
Возьмём первую «машинночитаемую» спеку, чтоб не быть голословными.
В том, что для простых случаев JSON подходит лучше — соглашусь, но не каждый случай простой.
Каждый. Попытки использовать вышеописанные спеки напрямую — приводили к тому, что чуть не под каждую новую версию приходилось инструменты «допиливать». После того, как написали конвертор из XML в JSON — допиливать приходится только его. Иногда приходится допиливать и клиенты, но это всегда проще сделать, чем в случае с JSON'ом.
Что же до неоднозначности разбора XML — тут все просто. Надо не заниматься десериализацией без схемы, а использовать XPath. В запросе
Расскажите, пожалуйста, каким XPath-запросом вы будете получать тип поля computeWorkGroupSize из его следующего описания:/root/users/user[1]/nameнет никакой неоднозначности.
На всякий случай замечу, что речь идёт о типа<member><type>uint32_t</type> <name>computeWorkGroupSize</name>[3]</member>uint32_t[3]
Заранее спасибо за ваше умение в XPath-фу.mayorovp
30.08.2018 12:57Ничего сложного:
//member/name[.="computeWorkGroupSize"]/following-sibling::text()[1].
Ну или вот так тоже можно:
//member[name="computeWorkGroupSize"]/text()khim
30.08.2018 13:29Я боюсь, что вы так захватите вместе с типом ещё и имя. А если там окажется в промежутке ещё и (посмотрите на ссылку), то он тоже будет захвачен.
А для того, чтобы сгенерировать API — нужно-таки вычленить именноuint32_t[3]— у этого элемента именно такой тип.mayorovp
30.08.2018 13:39Нет, так я захватываю
[3]и только его (второй вариант захватывает еще и пробел).
Тип захватывается вот так://member[name="computeWorkGroupSize"]/type, я думал что это очевидно.khim
30.08.2018 14:22То, что тип можно захватить отдельно и текст [3] можно захватить отдельно — это я знаю. Проблема в том, что в vk.xml тип описывается как в C: базовый тип помечен как
type, но при этом всякие скобочки и звёздочки никак не помечены. И могут идти и до имени и после.
Проще всего взять тег «member», выбросить из него теги «comment» и «name» и объявить всё оставшееся типом. Но как это сделать на XPath — я не знаю…mayorovp
30.08.2018 14:50Тогда так:
//member[name="computeWorkGroupSize"]/node()[local-name() != 'name' and local-name() != 'comment']
Или вот так:
//member[name="computeWorkGroupSize"]/node()[not(self::name | self::comment)]TerraV
30.08.2018 15:59И как вам самому такое, нравится? Мне категорически нет (даже если оно делает то что нужно, в чем лично у меня большие сомнения).
mayorovp
30.08.2018 16:11А в чем проблемы этого запроса, за исключением того что это однострочник? Если вам не нравятся однострочники — ну пишите в несколько строчек! Применительно к xpath — делайте несколько запросов.
Или вот тот же самый запрос на Linq 4 Xml:
from member in doc.Descendants("member") where (string)member.Element("name") == "computeWorkGroupSize" from node in member.Nodes() where node.Name != "name" && node.Name != "comment" select node
mayorovp
30.08.2018 16:36Кстати, вот еще что мне подумалось. Если по-смотреть на вашу спеку внимательнее, то видно что она писалась ровно с одной целью — чтобы по ней было удобно генерировать человекочитаемую документацию.
В частности, содержимое member на самом деле — просто неструктурированная строка
uint32_t computeWorkGroupSize[3], в которой идентификатор uint32_t выделен как ссылка на тип, а computeWorkGroupSize — как имя.
В том же JSON такое просто не поместится. И будет либо что-то типа вот такого:
[ {token: "uint32_t", type: "type"}, " ", {token: "computeWorkGroupSize", type: "name"}, "[3]" ]
Либо будет вот такое:
\type{uint32_t} \name{computeWorkGroupSize}[3]
И это в лучшем случае — в худшем случае в json могут и кусок html-разметки запихать, как я уже много раз видел.
Будет ли удобно вырезать в таких форматах имя и комментарий? Почему-то мне кажется, что нет. Так что проблема этой спеки — вовсе не в формате XML.
khim
30.08.2018 22:44Если по-смотреть на вашу спеку внимательнее, то видно что она писалась ровно с одной целью — чтобы по ней было удобно генерировать человекочитаемую документацию.
А вы самый первый «comment» в ней прочитали, нет?
Цитирую:This file, vk.xml, is the Vulkan API Registry. It is a critically important and normative part of the Vulkan Specification, including a canonical machine-readable definition of the API
Увы — но это «canonical machine-readable definition of the API». Которым пользуются разработчики GPU, операционок и прочего для того, чтобы верифицировать данные… А вовсе не «заготовка книжки» как вам показалось…
В том же JSON такое просто не поместится.
И это прекрасно, великолепно, замечательно! Это и есть основное и самое главное достоинство JSON'а!
И будет либо что-то типа вот такого:
Зачем, почему, отчего? После конвертации там у нас что-то типа такого:
[ {token: "uint32_t", type: "type"}, " ", {token: "computeWorkGroupSize", type: "name"}, "[3]" ]
Всё просто, понятно, и легкоиспользуемо. Осовенно если учесть, что в другом месте там есть ещё и массив «types», примерно такого плана:"members" : [ ... { "name" : "maxComputeWorkGroupSize", "type" : "uint32_t[3]" } ... ]
"types" : { ... "uint32_t[3]" : { "kind" : "array", "element_type" : "uint32_t" }, ... }И это в лучшем случае — в худшем случае в json могут и кусок html-разметки запихать, как я уже много раз видел.
Могут. Но шансов на то, что это случится — гораздо меньше, чем если попросить породить XML. И это легко очень быстро заметить. Ну просто появление первого же символа "<" иди ">" приведёт к вопросам «что за <крепкое ругательство> здесь написано и когда это исправят»? В случае же с XML — оно живёт и здравствует уже который год…
Так что проблема этой спеки — вовсе не в формате XML.
Нет, её проблема — в том, что «ужас, летящий на крыльях ночи» (и порождённый, скорее всего, каким-нибудь perl'овым скриптом из заголовочных файлов) не выглядит при беглом взгляде как ужас.
Я где-то давно как-то увидел фразу, которая показывает главное и основное преимущество JSON перед XML: «great APIs are easy to use, greatest APIs are hard to abuse».
Так вот XML — это «great API», а JSON — это «greatest API». Именно, блин, потому, что ужас засунутый в JSON — таки выглядит как ужас (если у вас в «canonical machine-readable definition of the API» появляются теги «token», или, прости госсподи, HTML — то это легко заметить и понять что это — неправильно). А вот ужас засунутый в XML — выглядит неотличимо он нормального XML'я, который можно спокойно распарсить без применения бесконечного количества костылей…mayorovp
31.08.2018 06:31Зачем, почему, отчего? После конвертации там у нас что-то типа такого [...]
Так то у вас. Потому что у вас была задача сделать и правда машиночитаемую документацию. А вот перед разработчиками обсуждаемого документа такая задача если и стояла — они ее просто не поняли.
khim
31.08.2018 23:24+1Они её прекрасно поняли.
Понимаете, перед разработчиками этой спеки (а если вы хотя бы откроете Википедию, то увидите, что собственно выпуск подобных файлов — это то, за что они деньги получают) стояла задача: «к часу X иметь машинно-читаемую спеку». А у разработчиков GPU стояла другая задача: «у часу Y выпустить чип, с поддержкой спеки, а к часу Z — драйвера». А у разработчиков Андроида и MoltenVK задача была «сделать так, чтобы в час T можно было запускать на устройствах программы, соотвествуюшие спеке». И так далее. Потому что оно должно поступить в продажу либо в августе (если мы целимся в «back-to-school»), либо в конце ноября (если мы хотим дать это Санта-Клаусу), либо в январе-феврале (если мы со школами работаем) и так далее. Если мы совали сроки не на день-два, а скажем, на месяц — то мы влетели в миллиардные убытки…
И, что характерно, все более-менее со всеми своими задачами справились — именно потому что у них не было важных «Архитекторов и системных аналитиков», которые могли бы устроить многомесячные «согласования схемы» и сорвать к чертям собачьим все сроки. Вместо этого на всех уровнях было прикручено столько и таких костылей, сколько было нужно для того, чтобы вот это вот всё как-то заработало…
Я специально выбрал пример, который любой желающий может увидеть без всяких NDA и прочей шелухи. Вот так выглядит работа в индустрии, добро пожаловать в реальный мир.
JSON выигрывает у XML потому что в простых случаях (когда всё маленькое и простое, один разработчик, один заказчик) спека не помогает, и вообще, по большому счёту, не нужна — а когда в дело вовлечены десятки компаний, то шансов на то, что спека будет разработана, а потом ещё и будет соблюдаться — почти ноль. Ну или если вы работаете с правительством, где согласование спеки будет являться жёстким требованием контракта… тогда вы получите текстовый элемент с названием «xml», с которого наша дискуссия началась…
А без спеки и её согласования, как вы сами признаёте, шансов получить что-то вменяемое от XML — меньше, чем от JSON'а…mayorovp
01.09.2018 09:03Понимаете в чем дело, если бы передо мной стояла задача сделать XML-спеку для того чтобы из нее можно было генерировать человекочитаемую документацию для Си или С++ — я бы тоже, после некоторых раздумий, выбрал именно такою схему. А если бы передо мной стояла задача сделать машиночитаемую документацию — я бы выбрал совсем другую схему, причем думал бы куда меньше, потому что машиночитаемые форматы проще.
Именно поэтому мне кажется, что реально решаемая этой спекой задача отличается от заявленной.vintage
01.09.2018 09:46Прелесть XML спек в том, что их можно писать машиночитаемо, но тут же к ним приложить XSLT странсформацию, которая создаст человекочитаемое представление. Пример: nin-jin.github.io/harp/api=1
mayorovp
01.09.2018 13:24Вот только конкретно эту спеку явно писали одновременно с XSLT и для нужд именно этой XSLT, а не для чего-то еще.
khim
01.09.2018 14:07Да не обрабатывается эта спека никаким XSLT! Зачем думать и гадать? Всё ж открыто! Там и скрипты, которые спеку читают, есть и Relax NG schema и прочее. Никакого XSLT нигде нет — но сам документ… вот такой.
Если вы предположите, что и схему и документ породили люди, которые имели больше опыта работы с написанием документации, чем с написанием кода и потому понимали нужды XSLT лучше, чем нужны программистов на C/C++… то вы будете правы.
Но, тем не менее, результат — таков, каким вы его видите.
И не надо говорить про то, что это результат работы студентов: Khronos Group существует с 2000го года, сколько времени существует nVidia, AMD (ну пусть ATI… тут это релевантнее) — вы тоже примерно представляете.
То есть нет — это не «малобюджетный проект, которым занимались делетанты». Это — то, что вы реально (а не в ваших мечтах) получаете от XML в индустрии.
Great APIs are easy to use, greatest APIs are hard to abuse — так вот вторую часть XML проваливает с треском… его очень-очень «easy to abuse»…
adeptoleg
30.08.2018 09:05Я вот прикинул с практической точки зрения (реализации в синтаксисе типа данных) и мне кажется что незашло бы. JSON любят за простоту (как всё гениальное) добавить туда что то уже пойти на компромисс в ущерб чего то другого(удобство чтения, редактирования, читабельности).
Alter2
30.08.2018 10:55Представьте себе мир, в котором у HTML-документов и ответов API в точности одинаковая структура. В таком мире JSON, возможно, не стал бы таким популярным, как сегодня.
А ведь JSON-подобный HTML — неплохая идея для современных сайтов, где большие тексты уже не особо распространены.
akurilov
30.08.2018 11:11Имхо, не хватает вспомогательных стандартизованных технологий наподобие XSLT, XQuery, XPath. Но если сравнивать json и yaml, то последний всё-таки предпочтительнее, т.к. комментарии есть и меньше ненужной избыточности
apapacy
30.08.2018 12:11habr.com/company/sberbank/blog/421693 как будто специально по теме почему не всегда xml делает разработку проще.
Geos87
30.08.2018 13:07+1по-моему, единственная причина почему JSON победил — это то, что браузеры так и не реализовали нормальную поддержку XML/XPath. А JSON по умолчанию был столь простой что JSON2.js, по-моему, 200 строк в неминимизированном виде. Если бы в браузерах была поддержка XML на том же уровне что System.Xml.* в .NET, JSON вряд ли был так нужен.
muhaa
30.08.2018 13:39Шок! Стулья захватили мир! Это было поразительное изобретение, сделанное… в… году. Впервые четырехногий стул изготовили… Они столкнулись с массой трудностей, которые героически преодолели. Стульев в мире становится все больше (вот вам график) хотя некоторые все еще предпочитают табуретки, скамейки или кресла на колесиках.
Т.е. берем какие-нибудь простейшие и очевидные решения, придаем им статус прорывных технологий и пишем громкую статью.
springimport
30.08.2018 15:59Очень легко начать пользоваться json когда нужно просто:
{ "title": "Post title", "body": "Post Body" }
Однако в очередной раз не вышло серебряной пули. Уже начали появляться инструменты типа Swagger. Вопрос времени когда введут схемы и нэймспейсы.
DrPass
JSON — это тот чудесный редкий случай в IT, когда простой и элегантный формат вытесняет сложный, навороченный, но более функциональный. Обычно бывает наоборот.
OnYourLips
Наоборот тоже происходит, посмотрите на yaml.
Сложнее учится, сложнее парсится, зато легче читается, удобен в VCS, совместим с json.
chupasaurus
Несовместим он с JSON, но легко конвертируется.
TonyLorencio
Все-таки YAML это надмножество JSON, так что валидный JSON также является валидным YAML.
chupasaurus
Что не противоречит моему комментарию. «Голого» дефиса без кавычек в JSON нет, например.
mSnus
Всё ещё впереди. Поначалу Flash тоже был простой штукой и позволял просто делать милые анимации. Потом люди сказали — а давайте все улучшим, правда, придётся немного усложнить. И усложнили так, что Flash издох, не оставив альтернатив — слишком навороченной и сделай и сложной получилась поделка. Удержатся ли люди от "улучшения и усложнения" — только со временем увидим.
khim
Флешу чуть больше 20 лет, JSON — порядка 15. То есть если бы такие тенденции были — то они бы уже проявились. Но… За всё это время предложения «улучшнить и усложнить» высказывались много раз — и так же много раз «посылались».
Просто потому что все понимают — JSON есть JSON, а начни «улучшать» и конца-края не будет.