
Не люблю, когда в сети нет простых пошаговых инструкций без умных слов, показывающих, как делать не самые очевидные вещи. Поэтому без лишних вступлений сегодня расскажу, как правильно бекапить отказоустойчивый (Failover) кластер SQL. Да-да, именно кластер, а не отдельно стоящий SQL сервер. Как раз про них написано много, а кластера почему-то избегают.
И без долгих предисловий рассмотрим нашу лабу:
- Windows кластер с Windows Server 2012 r2 под капотом и неким количеством нод. Для удобства в моей лабе их всего две. Возникает законный вопрос: а зачем ставить кластер на кластер? Объясню чуть ниже.
- К кластеру по iSCSI зацеплено три диска: кворум, диск с базой (базами), диск для логов. Можно больше, можно меньше, тут кому как нравится. Иногда нравится так: два локальных диска (один для системы, второй для установки самого SQL), диск для кворума, совмещённый диск для root и system database, диск для базы, диск для логов, диск для TempDB и диск для Backups. Системщики говорят, что так тоже правильно. Но я считаю, что сколько у вас будет дисков — совершенно никакой роли не играет. Если именно у вас работает, значит вы правы и молодец.
- На каждой ноде установлен инстанс SQL, понимающий, что он часть SQL кластера, а Windows кластер видит роль SQL Server.
Теперь — до того как мы приступим — давайте договоримся про две важные вещи:
- Примите решение и перестаньте сомневаться (хотел сюда вставить анекдот про баню, крестик и трусы, но
цензура зарезаларешил обойтись без). Один объект инфраструктуры должен обрабатываться только одним решением. Если для бекапа SQL используете решение А, а для бекапа кластера решение В, то В ни при каких условиях не должен трогать SQL. Или лучше решение А не использовать вообще, если В умеет делать гранулярные бекапы машин на уровне приложений. Почему? Давайте представим, что оба приложения умеют транкейтить логи SQL и успешно это сделают. SQL своё отработает, конечно, но в следующий проход бекапа вы получите сообщение о неконсистентном состоянии сервера в лучшем случае, а в худшем — не сможете восстановиться по логу транзакций. - Я знаю, что есть “мильён и тыща” вариантов бекапного софта, все они несомненно лучше потому что input_reason_here, но извините уж, я напишу только про один, который умеет это делать не хуже других, а, возможно, даже и лучше.
Поехали!
Итак, как уже ясно, бекапить мы будем ноды целиком. Сразу возникает первый вопрос: зачем, если Microsoft SQL кластер из коробки даёт нам очень и очень приличный уровень защиты от падения? Всегда, например, можно увести роль SQL и ресурсы на другую ноду.
Это рассуждение верно, но упускается тот вариант, что ноды сами по себе уязвимы. Если кратко: кластер на уровне ОС закрывает риски, связанные с функционированием ОС конкретной машины, а SQL кластер закрывает риски, связанные конкретно с базами данных. Да и бекапить такую конфигурацию интересней.
Давайте представим, что к нам придёт зловред шифровальщик и начнёт одну за одной класть ноды кластера. Тут у нас уже не получится быстренько восстановить только файлы БД. А ещё бывают неудачные обновления ОС, умирающее железо и т.д.
Поэтому предлагаю считать, что о необходимости бекапа всего сервера мы договорились, и теперь переходим к инструментарию. Я напишу, как достичь поставленных целей и быть восхитительным с помощью Veeam Backup & Replication 9.5 Ещё версию назад Veeam умел централизованно бекапить только виртуальные машины, но теперь он получил полноценную поддержку бекапов физических серверов, и грех будет в этом не разобраться.
Protection Groups
Для бекапа мы будем использовать Protection Group. Это простая логическая сущность, по сути — контейнер, где группируются машины, которые надо забекапить. Например, в нём можно сгруппировать несколько объектов из AD и не беспокоиться, что новые машины не попадут в бекап. Protection Group автоматически сканирует изменения и выполняет остальные необходимые действия по заданному расписанию. Одним словом, очень удобная штука, особенно в больших смешанных инфраструктурах.
Но переходим от слов к делу: запускаем Veeam Backup & Replication, идём на вкладку Inventory и запускаем визард создания Protection Group

На первом шаге надо задать имя группы и какое-то описание по необходимости, тут всё ясно.
А вот на следующем шаге надо уже выбирать, откуда Protection Group будет получать информацию о защищаемых машинах. Можно добавить их по старинке вручную по DNS именам или IP, можно предоставить список в виде CSV файла, как делают настоящие джедаи, но мы люди попроще и будем использовать объекты Active Directory. В нашем случае это так же значит, что все ноды кластера будут обнаруживаться автоматически, в том числе и новые.
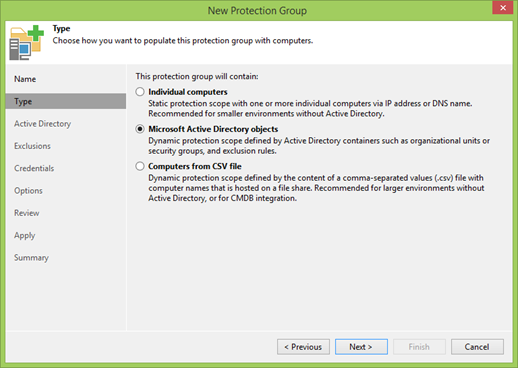
На следующем шаге вас первым делом попросят указать адрес контроллера домена, порт и данные пользователя для подключения.
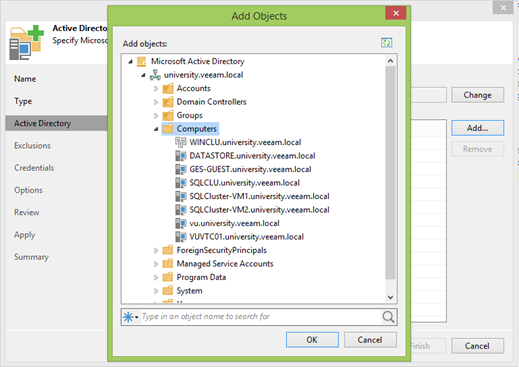
Если всё хорошо, нажимаете Add и выбираете нужные OU.
Важный момент: добавлять нужно только кластер! Отдельные ноды добавлять не надо.
Мой кластер называется WINCLU, его и добавлю.
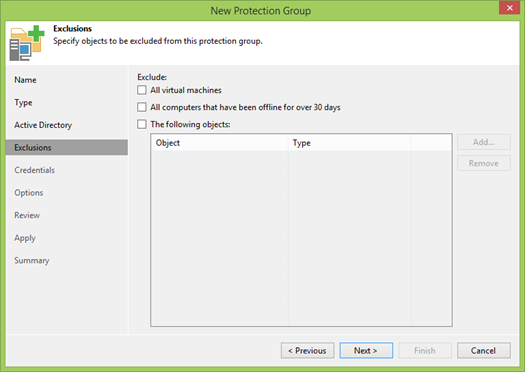
На следующем шаге задаются правила для исключения машин из сканирования. В современном мире OU зачастую содержат как виртуальные, так и физические машины, и в ряде случаев их бэкапят по разным сценариям. На самом деле бывают даже смешанные кластера, где использованы как физические, так и виртуальные машины. Этакий третий уровень защиты.
По умолчанию, первые две галочки выбраны, и вам их снимать, может быть, не обязательно, но моя лаба полностью виртуальная, а мы в начале договорились посмотреть на функционал бекапа физических машин.
Теперь надо указать, какого пользователя мы будем использовать. В неком идеальном случае у нас создан специальный пользователь в AD, имеющий права локального админа на всех машинах. Но если это не так, то Veeam позволяет назначить на каждый объект отдельного юзера.
Зачем нужен локальный админ?
- Во-первых, для установки на каждую машину Veeam Agent’а, который будет управлять процессом локального бекапа.
- Во-вторых, чтобы Veeam Agent’у сделать этот самый бекап, ему нужны права локального администратора для работы с VSS. Так уж устроена Windows, и с этим ничего не поделать.
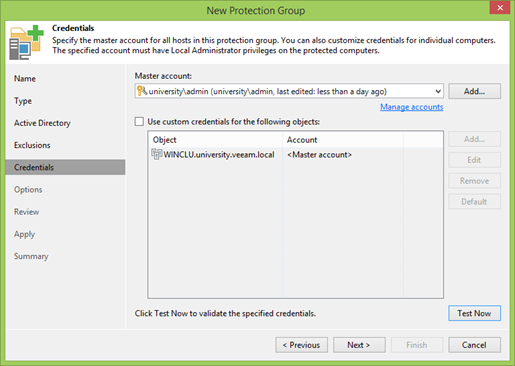
Отдельно надо заострить ваше внимание на кнопке Test Now. Отличная вещь, позволяющая быстро проверить, что все учётки введены правильно, а в случае кластера быть досрочно уверенным, что все ноды видны и доступны.
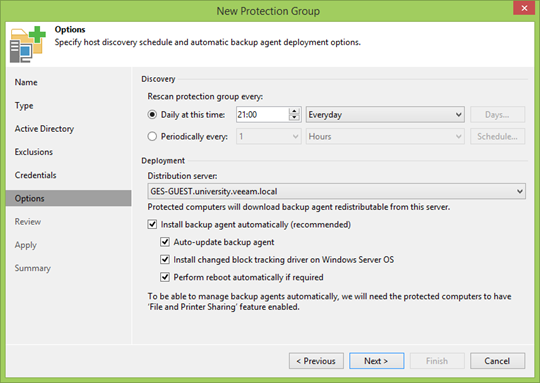
Потом надо задать интервал и время сканирования участников PG. Можно хоть раз в неделю, а можно и непрерывное обновление настроить. Тут решать вам, но обычно отличный вариант — это повторить частоту бекапа, дабы все новые участники смогли попасть в ближайшую точку восстановления.
Ниже находятся уже менее очевидные, но важные опции.
Distribution server — это машина, с которой будут устанавливаться Veeam Agents. В общем случае достаточно использовать Veeam Backup сервер, но в географически распределённых инфраструктурах с плохой связью имеет смысл указать вариант поближе. Во всех остальных случаях менять не имеет смысла.
Дальше. Причин, почему не следует устанавливать и не обновлять агентов в автоматическом режиме, я не знаю, но если не доверяете автоматике, можете смело отказываться. Но учтите, что из-за разницы версий вы можете остаться без очередной точки бекапа.
Также можно согласиться на установку нашего CBT драйвера, который будет отслеживать изменение дисков на уровне файловой системы. Это позволит отдавать в бекап только фактически изменившиеся сектора, а значит, точка восстановления меньше, бекап быстрее, нагрузка на сервер меньше. Но если не доверяете, трафик вам не важен, диски у вас большие и связь отличная, то можно и не ставить.
С автоматической перезагрузкой есть нюанс: она применяется не только при первой установке, но и при обновлениях. Так что не забудьте снять галочку, если вы не можете позволить себе такой роскоши.
На следующем шаге нас проинформируют о необходимости доустановки компонентов на Distribution сервер. Даже если их не окажется, через минуту они там будут по нажатию кнопки Apply.
На последнем шаге нас проинформируют, что Protection Group (PG) создана успешно, и предложат запустить discovery, т.е. группа по заданным условиям составит список машин и согласно настройкам запустит установку агентов. Пока будут происходить все необходимые операции, можно сходить налить себе кофе.
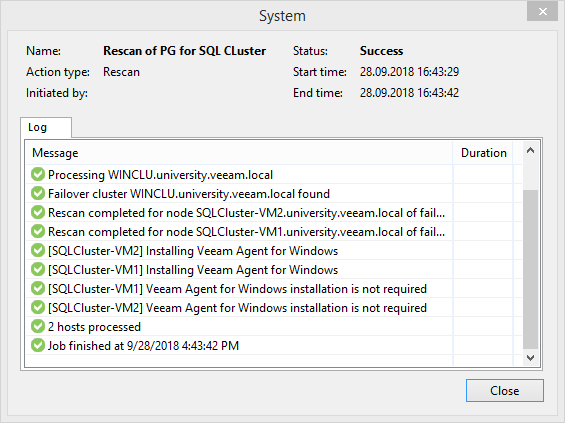
По опустошении чашки кофе можно обнаружить, что на одну из нод не удалось установить агента из-за ошибки доступа по сети. Если с вами приключилось подобное горе, то просто отключите от этой ноды диск с кворумом. Не часто, но бывает. А может, это и вовсе особенность именно моей лабы. Так и не хватило усидчивости разобраться с этой проблемой до конца.
Создаём бекап
Итак, если на предыдущем этапе всё закончилось успешно, то в вашей Protection Group теперь есть кластер и список его нод с успешно установленными агентами. Поэтому переходим к самому интересному: создаём бекап в режиме Failover Cluster, чтобы в него попали все ноды и все приатаченные диски.
В чём главное отличие и почему нельзя их просто забекапить как отдельные машины? Технически, можно так поступить со всеми нодами, кроме одной — текущего держателя роли кластера. Если её начать бекапить прямо в лоб, остальные ноды могут потерять с ней связь и начнут перетягивать одеяло на себя, что в итоге приведёт к развалу и остановке всего кластера. Это случается очень часто у загруженных систем.

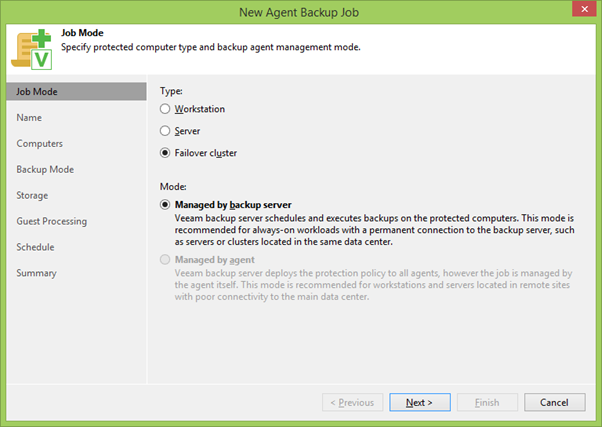
С помощью правой кнопки мыши (ПКМ), кликнув на PG, запускаем мастер создания бекапной джобы и сразу выбираем режим Failover Cluster. Такие задания могут быть созданы только на центральном Backup Server, в отличие от локальных агентских бекапов. Но это и логично: как вы помните, мы хотели заодно по полной бекапить SQL, а значит, будут регулярно транкейтиться логи – для чего в любом случае понадобится связь между серверами.
Затем выбираем имя джобы и список участников бекапа. По умолчанию тут будет только выбранная PG, но сюда также можно добавить что-то дополнительно.
На следующем шаге надо выбрать между бекапом отдельных дисков или всей машины целиком. В общем случае если можно бекапить всю машину, то нужно бекапить всю машину. В нашем случае это верно, т.к. мы должны забекапить все диски кластера, которые могут оказаться на любой ноде нашего кластера.
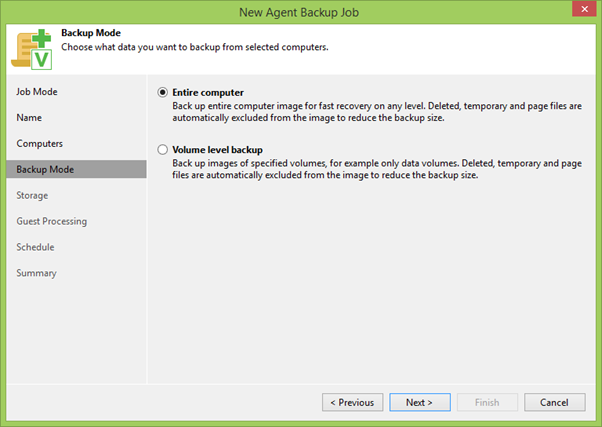
Потом выбираем репозиторий для бекапов и указываем, сколько точек восстановления у нас будет. По кнопке Advanced можно вызвать меню тонкой настройки, где можно выбрать, каким способом создавать цепочку бекапов, включить дополнительные проверки целостности файлов и многое другое, на что сейчас мы не будет тратить время, потому что впереди самое интересное — раздел Guest Processing.

Именно от настроек на этой вкладке зависит, получится ли у нас так называемый application consistent бекап (что переводят иногда как целостная резервная копия или как резервная копия с учётом состояния приложений, либо ещё не пойми как и, главное, зачем). Поэтому заходим в Applications, выбираем нашу PG и жмём Edit.

Убеждаемся, что на первой вкладке включен Application-Aware Processing. В этом случае будет задействована подсистема VSS, работа которой должна пройти без ошибок. Вернее, она может отработать с ошибками, но в этом случае бекап не будет создан и понадобится разобраться в причинах сбоя. Также здесь надо определить судьбу транзакционных логов: Veeam может игнорировать их, просто копировать в бекап или обрезать.
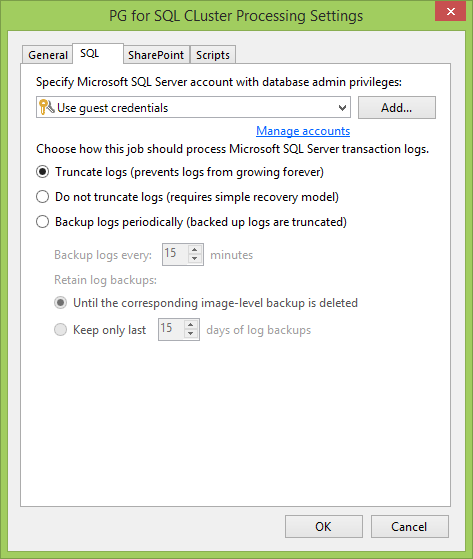
Теперь переходим к вкладке SQL. Первое, что надо сделать, это задать учётку пользователя для взаимодействия с SQL сервером и его базами. В идеальном мире она совпадает с локальным администратором, которого мы указывали при создании PG. В противном случае главное, что у этого пользователя должны быть Databases Owner права.
Затем выбираем, как мы будем взаимодействовать с логами. Например, если у вас база в режиме Full Recovery, очень удобно логи транкейтить. Или можно бекапть логи транзакций по отдельному расписанию, чтобы можно было быстрее откатить базу на нужный момент времени, а не терять всё, что было между бекапами. Конечно, можно ничего с логами и не делать вовсе.
Переходим к предпоследнему пункту Schedule, где устанавливаем расписание согласно вашим требованиям. Кому-то достаточно раз в день, кому-то раз в час, это только вам решать.
Завершаем создание задания, пару раз нажав Apply, и наслаждаемся результатом.
В идеальном мире, если у вас не приключится никаких фокусов с установкой агентов, которые работают связующим звеном между кластером и Veeam Server, или вы вдруг забыли подгрузить необходимую для агентов лицензию, джоба отработает на отлично, и вы увидите примерно следующую картину.
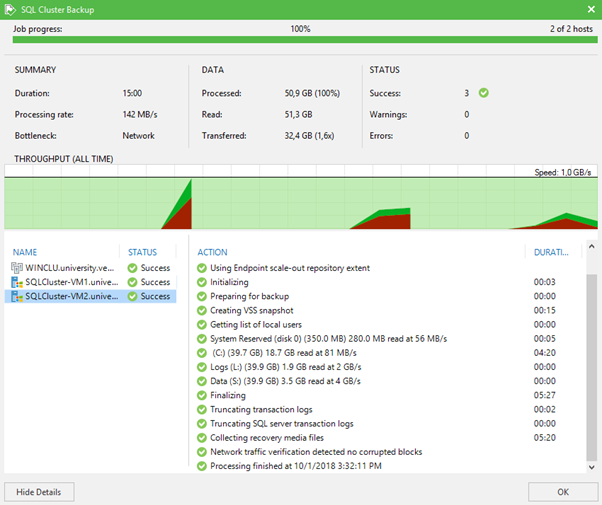
Вот и всё. Оказывается, бекапить кластеры не так уж и страшно, как об этом принято думать. Даже если это кластер внутри другого кластера.
Если интересно узнать о другом сценарии бекапа/рестора, то напишите в комментариях об этом, и мы всё расскажем в лучшем виде.
Комментарии (6)

kolu4iy
15.10.2018 12:37Прочитал. Подумал, что кроме DBA нужен еще специальный backup admin: надежды на мальчиков-зайчиков-энекейщиков при использовании софта подобной сложности просто нет.
Скажите, а что может произойти с кластером из пяти нод в двух разных дата-центрах, что оправдывает сохранение не только данных с SQL (с чем SQL сам справляется заметно лучше всякого софта, при включенной компрессии), а и настроек данного кластера?
Это не сарказм. Я пытаюсь осознать полезность.
P.S. Пример из текста — «Давайте представим, что к нам придёт зловред шифровальщик и начнёт одну за одной класть ноды кластера. Тут у нас уже не получится быстренько восстановить только файлы БД. А ещё бывают неудачные обновления ОС, умирающее железо и т.д.» — не работает в случае бекапа transaction log 1 раз в 10 минут. Пусть себе шифрует, отвалим ноду. Сломано 5 нод — собственно, значит остальная инфраструктура уже лежит, и надо тушить пожар…Loxmatiymamont Автор
15.10.2018 13:01Чтобы успеть отвалить одну (да пусть и несколько) ноду в реальной жизни, необходима хорошая скорость реакции мониторинга, отличные аналитические способности людей на местах, невероятная способность к принятию решений у персонала (отключать от боевого кластера ноды, это всё же надо решиться) и физическая близость к консоли управления (как известно, всё ломается, когда админ жуёт обед или сидит на горшке).
Но это лирика, давайте к практике. Пожар потушили, надо как-то поднимать. Если у нас есть бекап самого кластера, мы раскатываем его на железо и запускаем через минимальное время. Приналичии реплик или фич вроде запуска прямо из бекапа (instant vm restore в терминологии veeam), время восстановления получается действительно копеечное.
Если у нас есть только бекап SQL, то мы отдельно раскатываесм систему (предположим, что у нас есть образ со всеми нужными обновлениями), собираем кластер, ставим SQL (предположим, что тоже без мучительных обновлений), восстанавливаем базу и только потом запускаемся.
gotch
Подскажите, Георгий Гаджиев не у вас сейчас работает? Такое ощущение, что текст вышел из под его пера.
Loxmatiymamont Автор
Видимо это комплимент =)
Нет, Георгий к этому тексту не причастен 100%. Говорю как автор. А что, он больше не в Microsoft трудится?
gotch
Не знаю, честно говоря, но в блог больше не пишет.
Ну раз вы непосредственно автор этой статьи, то можно и вопросы позадавать?
Loxmatiymamont Автор
Задавайте )