
Софту мы не доверяем уже давно, и поэтому осуществляем его аудит, проводим обратную инженерию, прогоняем в пошаговом режиме, запускаем в песочнице. Что же насчёт процессора, на котором выполняется наш софт? – Мы слепо и беззаветно доверяем этому маленькому кусочку кремния. Однако современное железо имеет те же самые проблемы, что и софт: секретную недокументированную функциональность, ошибки, уязвимости, малварь, трояны, руткиты, бэкдоры.

ISA (Instruction Set Architecture) x86 – одна из самых долгих непрерывно изменяющихся «архитектур набора команд» в истории. Начиная с дизайна 8086, разработанного в 1976 году, ISA претерпевает постоянные изменения и обновления; сохраняя при этом обратную совместимость и поддержку исходной спецификации. За 40 лет своего взросления, архитектура ISA обросла и продолжает обрастать множеством новых режимов и наборов инструкций, каждый из которых добавляет к предшествующему дизайну, и без того перегруженному, новый слой. Из-за политики полной обратной совместимости, в современных процессорах x86 присутствуют даже те инструкции и режимы, которые на сегодняшний день уже преданы полному забвению. В результате мы имеем архитектуру процессора, которая представляет собой сложно переплетающийся лабиринт новых и антикварных технологий. Такая чрезвычайно сложная среда – порождает множество проблем с кибербезопасностью процессора. Поэтому процессоры x86 не могут претендовать на роль доверенного корня критической киберинфраструктуры.
Вы всё ещё доверяете своему процессору?
Безопасность программ и операционной системы – зиждется на безопасности железа, на котором они развёрнуты. Как правило разработчики софта не учитывают того факта, что железо, на котором разворачивается их софт – может быть недоверенным, вредоносным. Когда железо ведёт себя ошибочно (независимо оттого, преднамеренно или нет), программные механизмы безопасности – полностью обесцениваются. Уже много лет предлагаются различные модели защищённых процессоров: Intel SGX, AMD Pacifica и др. Тем не менее, завидная регулярность, с которой публикуется информация о критических сбоях (из недавних, например Meltdown и Spectre) и обнаруженных недокументированных «отладочных» функциях – наводит на мысль, что наше беззаветное доверие к процессорам беспочвенно.
Современные процессоры x86 представляют собой очень громоздкое и запутанное переплетение новейших и антикварных технологий. У 8086 было 29 тыс. транзисторов, у Pentium – 3 млн., у Broadwell – 3,2 млрд, у Cannonlake – больше 10 млрд.
При таком количестве транзисторов неудивительно, что современные процессоры x86 испещрены недокументированными инструкциями и аппаратными уязвимостями. Среди недокументированных, – обнаруженных почти случайно, – инструкций: ICEBP (0xF1), LOADALL (0x0F07), apicall (0x0FFFF0) [1], которые позволяют разблокировать процессор для несанкционированного доступа к защищённым областям памяти.
Что же касается многочисленных аппаратных уязвимостей процессоров (см. два рисунка ниже), то они позволяют киберзлоумышленнику осуществлять эскалацию привилегий [3], извлекать криптографические ключи [4], создавать новые ассемблерные инструкции [2], менять функциональность уже существующих ассемблерных инструкций [2], устанавливать хуки на ассемблерные инструкции [2], брать под контроль «аппаратно ускоренную виртуализацию» [7], вмешиваться в «атомарные криптографические вычисления» [7] и, – сладкое напоследок, – входить в «режим бога»: подчинять себе легальный аппаратный бэкдор Intel ME (который позволяет получать удалённый доступ даже к выключенному компьютеру) [8]. И всё это – не оставляя каких-либо цифровых следов.
Современные процессоры – это больше софт, чем железо
Строго говоря, современные процессоры даже нельзя назвать «железом» в полном смысле этого слова. Потому что наиболее критичная их функциональность (в том числе, ISA) – обеспечивается перепрошиваемым микрокодом. Изначально микрокод отвечал в основном за то, чтобы управлять декодированием и выполнением сложных ассемблерных инструкций: операции с плавающей точкой, MMX-примитивы, обработчики строк с префиксом REP и т.п. Однако с течением времени на микрокод возлагается всё больше и больше ответственности за обработку операций внутри процессора. Так например, современные расширения процессоров Intel, такие как AVX (Advanced Vector Extensions) и VT-d (аппаратная виртуализация) – реализованы на микрокоде.
Кроме того, сегодня микрокод отвечает, в числе прочего, за сохранение состояния процессора, за управление кэшем и также за управление энергосбережением. Для энергосбережения, на микрокоде реализован механизм прерываний, обрабатывающий состояния электропитания: С-состояния (степень энергосберегающего сна: от активного состояния до глубокого сна) и P-состояния (разные комбинации вольтажа и частоты). Так например, за обнуление L2-кэша при входе в состояние C4, а также при выходе из него – отвечает именно микрокод.
Зачем производители процессоров пользуются микрокодом?
Производители процессоров x86 используют микрокод для разложения сложных ассемблерных инструкций (длина которых может достигать 15 байт) в цепочку простых микроинструкций, – в целях упрощения аппаратной архитектуры и облегчения диагностики. По сути, микрокод это интерпретатор между внешней (видимой для пользователя) CISC-архитектурой и внутренней (аппаратной) RISC-архитектурой.
При обнаружении ошибок в CISC-архитектуре (в ISA, прежде всего), производители публикуют обновление микрокода, которое можно закачать в процессор через BIOS/UEFI материнской платы или через операционную систему (во время процесса загрузки). Благодаря такой системе обновлений, основанной на микрокодах, производители процессоров обеспечивают себе гибкость и снижение затрат – при исправлении ошибок в своём оборудовании. Нашумевшая ошибка с fdiv, которая сильно подкосила процессоры Intel Pentium в 1994 году – сделала ещё более очевидным тот факт, что высокотехнологичное железо подвержено ошибкам точно также, как и софт. Данный инцидент породил у производителей ещё больше интереса к архитектуре процессоров на основе микрокода. Поэтому Intel и AMD стали строить свои процессоры с применением технологии микрокодов. Intel – начиная с Pentium Pro (P6), выпущенного в 1995 году. AMD – начиная с K7, выпущенного в 1999 году.
Всё тайное становится явным
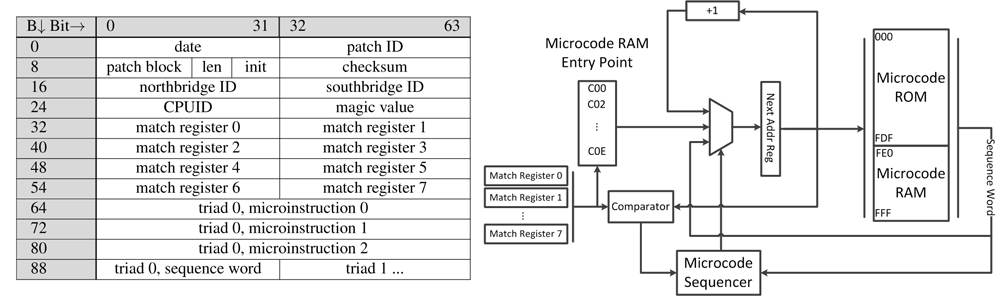
Несмотря на то, что производители процессоров стараются держать архитектуру микрокодов и механизм их обновления в строжайшем секрете, – враг не дремлет. Крупицы разрозненной информации (в основном из патентов, вроде AMD RISC86 [5]) и вдумчивый реверсинг официальных обновлений для BIOS (как это было с K8 [6]), – постепенно проливают свет на тайну микрокода (см. например, на рисунке ниже «механизм обновления микрокода процессоров AMD»). А благодаря постоянной эволюции инструментария для реверсинга (как программного, так и аппаратного) [2], перспективным методикам фаззинга [1] и появлению таких OpenSource-инструментов как Microparse [9] и Sandsifter [10] – киберзлоумышленник может узнать о микрокоде всё необходимое для того, чтобы писать на нём микрокодовую малварь.
Так например, в [2] на правах «Hello world!» (первый шаг к троянизации микрокода) разработан «микрохук» (микрокодовая программа, перехватывающая ассемблерную инструкцию), который подсчитывает, сколько раз процессор обращался к команде div. Этот микрохук представляет собой инъекцию в обработчик ассемблерной инструкции div.

Там же [2] представлен более продвинутый микрохук, – который спокойно себе сидит в ассемблерной инструкции div ebx, ничем не выдавая своего присутствия, и активируется только когда при обращении к div ebx выполняются конкретные условия: в регистре ebx содержится значение B, а в регистре eax содержится значение A. Активируясь, этот микрохук увеличивает значение регистра eip (указатель текущей инструкции) на единицу. В результате выполнение программы (которая имела смелость обратиться к инструкции div ebx) продолжается со смещением: ни с первого байта следующей за div ebx команды, а с её второго байта. Если же в регистрах eax и ebx заданы другие значения, то div ebx работает в обычном режиме. Какая в этом практическая ценность? Например, чтобы незаметно активировать скрытую цепочку ассемблерных инструкций, при использовании обфускационной техники с «перекрываемыми инструкциями» [11].
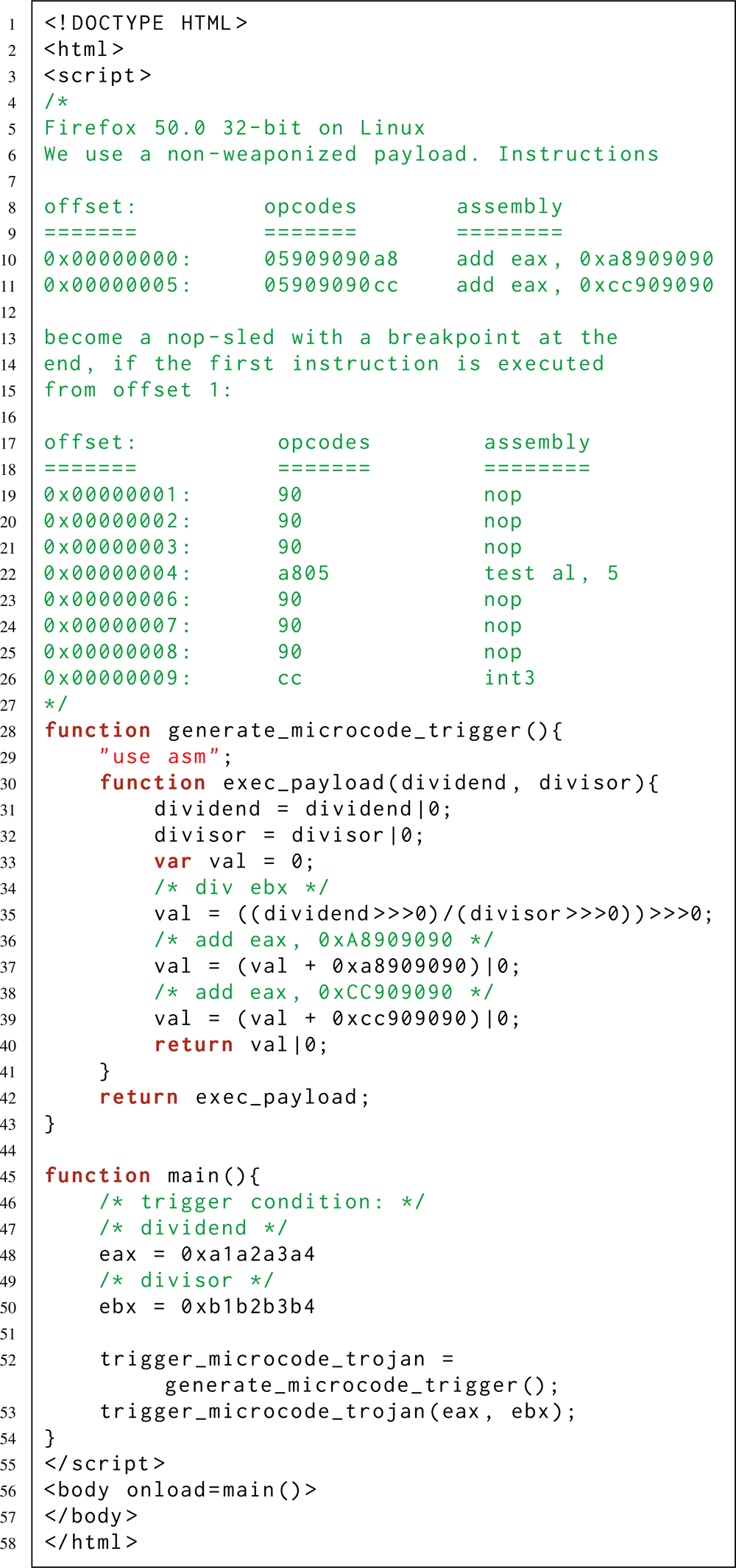
Эти два примера демонстрируют, как законные ассемблерные инструкции можно использовать для сокрытия в них произвольного троянского кода.
При этом, киберзлоумышленник может активировать свою вредоносную полезную нагрузку – в том числе и удалённо. Например, когда необходимое для активации условие выполняется на веб-странице, контролируемой злоумышленником. Это возможно благодаря компиляторам Just-in-Time (JIT) и Ahead-of-Time (AOT), встроенным в современные веб-браузеры. Эти компиляторы позволяют испускать предопределённый поток ассемблерных инструкций машинного кода – даже если вы пишете программу исключительно на высокоуровневом JavaScript (см. последний листинг – чуть выше).
- Christopher Domas. Breaking the x86 ISA // DEFCON 25. 2017.
- Philipp Koppe. Reverse Engineering x86 Processor Microcode // Proceedings of the 26th USENIX Security Symposium. 2017. pp. 1163-1180.
- Matthew Hicks. SPECS: A Lightweight Runtime Mechanism for Protecting Software from Security-Critical Processor Bugs // Proceedings of the 28th International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS). 2015. pp. 517–529.
- Adi Shamir. Bug Attacks // Proceedings of the 28th Annual conference on Cryptography: Advances in Cryptology. 2008. pp. 221–240.
- John Favor. RISC86 Instruction Set // US Patent 6336178. 2002.
- Opteron Exposed: Reverse Engineering AMD K8 Microcode Updates. 2004.
- Saming Chen. Security Analysis of x86 Processor Microcode.2014.
- Catalin Cimpanu. Malware Uses Obscure Intel CPU Feature to Steal Data and Avoid Firewalls. 2017.
- Daming Chen. Microparse: Microcode parser for AMD, Intel, and VIA processors // GitHub. 2014.
- Sandsifter: The x86 processor fuzzer // GitHib. 2017.
- Карев В.М. Как написать на ассемблере программу с перекрываемыми инструкциями (ещё одна техника обфускации байт-кода) // Хабрахабр. 2018. URL: (дата обращения: 25 октября 2018).
Комментарии (80)

GamaleyVV
25.10.2018 19:36Не доверяю UEFI. После установки SUSE Linux переменные UEFI изменить стало не возможно ни стандартными способами (efibootmgr и виндовым аналогом) из BIOS Setup то же ни чего не поправляется. Ноут Lenovo Z7080…
dartraiden
25.10.2018 19:39+5Виновата, конечно, спецификация UEFI, а не вендор, коряво реализовавший прошивку. Lenovo вообще славится тем, что можно программно из их железок делать кирпичи.
В плане безопасности UEFI, говорят, лучшие прошивки у HP и Dell — сказывается то, что они ещё являются и крупными игроками на корпоративном рынке. Оперативно латают дыры и вообще, такого ужаса, как «прошивка при затирании переменных не генерирует дефолтные, превращая устройство в тыкву» у них не встречается.
Sirikid
26.10.2018 05:13+1А с LiveCD/USB? У меня нечто похожее с T440s, с LiveUSB переменные нормально меняются, а с основной системы нет.
Arxitektor
25.10.2018 20:14+3Lenovo вообще славится тем, что можно программно из их железок делать кирпичи.
Как раз из недавнего Сломать ноутбуки Lenovo ThinkPad можно одной настройкой BIOS
rPman
25.10.2018 20:18+2Лучше подумайте, какие существуют на текущий момент способы защиты от подобного? Какое железо относительно безопасно? для intel — выпуска 2008 года и не обновлять BIOS, OS и прочее? Что говорит arm-сторона банкета?
khim
26.10.2018 03:16+1Что говорит arm-сторона банкета?
Что ядра там простые и безопасные, можно все исходники получить и реально проверить… но вот когда из этого делают SOC… тушите свет.
advan20092
28.10.2018 09:26+1Вроде в макбуках ме отключается производителем, да и с прошивкой там неплохо поколдовали в плане безопасности
Arris
25.10.2018 20:23+2Эти компиляторы позволяют испускать предопределённый поток ассемблерных инструкций машинного кода
звучит как «испускать лучи ненависти в сторону правильно работающего микропроцессора».
Amomum
25.10.2018 20:39+4Полагаю, это видео должно быть здесь:
GOD MODE UNLOCKED — Hardware Backdoors in x86 CPUs
beeruser
25.10.2018 21:34+1у Cannonlake – больше 10 млрд.
Откуда дровишки?(с)
i3-8121U — единственный представитель микроархитектуры Cannon Lake, представляет собой крошечный двух-ядерный чип.
ark.intel.com/products/136863/Intel-Core-i3-8121U-Processor-4M-Cache-up-to-3-20-GHz-
Для сравнения — 22-ядерный Xeon E5 (Broadwell) имеет чуть более 7 миллиардов транзисторов.
Lazytech
26.10.2018 08:21+1Intel 10 nm Process Increases Transistor Density by 2.7x Over 14 nm: Report | TechPowerUp
Отрывок (на английском)Intel's 10 nanometer FinFET silicon fabrication is coming together at a slower than expected rate, however when it does, it could vastly enlarge the canvas for the company's chip designers, according to a technical report by Tech Insights. The researchers removed the die of an Intel «Cannon Lake» Core i3-8121U processor inside a Lenovo Ideapad330, and put it under their electron microscope.
Its summary mentions quite a few juicy details of the 10 nm process. The biggest of these is the achievement of a 2.7-times increase in transistor density over the current 14 nm node, enabling Intel to cram up to 100.8 million transistors per square millimeter. A 127 mm? die with nothing but a sea of transistors, could have 12.8 billion transistors.Solexid
26.10.2018 16:55-2intel закрыла разработку 10nm.
Lazytech
26.10.2018 17:22+1intel закрыла разработку 10nm.
Если верить английской Википедии, это не совсем так (по крайней мере, Intel это отрицает), и процессоры Intel Core i3-8121U все-таки производятся по 10-нанометровой технологии, пусть и в ограниченных количествах.
Cannon Lake (microarchitecture) — Wikipedia
Отрывок (на английском)Cannon Lake was initially expected to be released in 2016, but the release was pushed back to 2018.[6] Intel demonstrated a laptop with an unknown Cannon Lake CPU at CES 2017[7][8] and announced that Cannon Lake based products will be available in 2018 at the earliest.
At CES 2018 (January 9–12, 2018) Intel announced that it had started shipping mobile Cannon Lake CPUs at the end of 2017 and would ramp up production in 2018.[9][10][11]
On April 26, 2018 in its report on first-quarter 2018 financial results Intel stated it was currently shipping low-volume 10 nm product and expects 10 nm volume production to shift to 2019.[12] In July 2018, Intel announced that volume production of Cannon Lake would be delayed yet again, to late H2 2019. [13]
The first laptop featuring a Cannon Lake CPU, namely Intel Core i3-8121U, a dual core CPU with HyperThreading and Turbo Boost but without an integrated GPU, was released in May, 2018 in very limited quantities.[14][15]
According to non-official sources the 10nm process technology for Cannon Lake had too low yields to be profitable, and thus a future 10nm process will have an increased structure size in order to increase yields.[16]
A more recent rumour states that Intel «pulled the plug on their struggling 10nm process».[17] However, Intel has denied these claims.[18]
Обратите внимание на подчеркнутый мною текст.khim
26.10.2018 18:17-2Всё что выпускается — было выпущено в рамках рекламной акции «всё хорошо, прекрасная маркиза». Мизерный тираж, дикие цены и более высокое энергопотребление — это то, чем вы ждали от 10nm, ведь правда?
Им нужно было показать инвесторам, что у них запущен 10nm «в срок» (ага, после кучи переносов) — они это сделали.
Что-то путное будет не раньше конца следующего года, а сколько там нанометров напишут — одни маркетологи знают…
beeruser
26.10.2018 18:28+1Этот техпроцесс (P1274) закрыт. Сейчас у них новый 10нм, у которого плотность сильно меньше. Залить кристалл равномерным слоем транзисторов это одно, а вот найти куда применить 10 миллиардов в крошечном двух-ядерном процессоре это надо очень постараться.
semibiotic
25.10.2018 22:51+3Строго говоря, «ассемблерные инструкции» это неграмотно. Такие инструкции должны называться машинными или просто «инструкциями процессора».
Команда на языке ассемблера это текст. Машинная инструкция — цепочка кодов.mxms
25.10.2018 23:25+1Верно.
Ассемблер это (в основном) мнемоническое обозначение машинных кодов.MacIn
26.10.2018 13:12Ну, если уж так придираться, то ассемблер — это программа-транслятор, переводящая программу на языке мнемокодов в программу на языке машинных команд.
Не язык «Ассемблер», а язык ассемблера, т.е. входной язык такого транслятора.
Зануда mode off
powerman
26.10.2018 00:19+2Строго говоря, в такой строгости нет реальной необходимости. Учитывая, что ассемблер мапится в коды почти один-в-один вполне можно позволить использовать оба термина как взаимозаменяемые (исключая ситуации/контексты, в которых различие между ними действительно имеет значение).
Правильные термины — это важно, но не стоит забывать, что это не некая абсолютная важность, соблюдать которую необходимо любой ценой. Это важно только потому, что нужно чтобы все понимали, о чём речь. И пока все всё понимают и без строгого использования верных терминов — требование строгости выглядит банальным занудством.
cens
26.10.2018 11:26+1А использование неверной терминологии, видимо, стильно, модно, молодёжно?
powerman
26.10.2018 11:40+1Нет, это просто обычное легаси — так уж исторически сложилось. Кроме того, попытка использовать максимально точные термины любой ценой приводит к сленгу, который очень напоминает юридический/бюрократический/научный, и который намного сложнее воспринимать. Иными словами — всё хорошо в меру, а перегибы (в любую сторону) ни к чему хорошему не приводят.
cens
26.10.2018 14:35+1Вы переводите от частного к общему и уводите тему в сторону:)
Использование правильного термина «машинные инструкции» — это совсем не перегиб и занудство, а исторически сложилось говорить неправильно — это, видимо, в вашем окружении.
Вообще, занудство — хорошее качество для программиста.powerman
26.10.2018 15:06+1Окей, вернёмся к частному: покажите, пожалуйста, каким образом использование конкретно в этой статье правильного термина как-то улучшит понимание сути статьи читателями? В каком месте некорректный термин ввёл читателей в заблуждение?
Как по мне — перевод от частного к общему делаете именно Вы. Я всё время говорю о том, что есть текущий контекст (частное), и его не стоит игнорировать в пользу абстрактно правильных идей (общего). Использование корректных терминов, безусловно, идея правильная. Но конкретно в данном случае реальной необходимости на этом настаивать нет — потому что исходя из содержимого статьи и широкораспространённого в русскоязычной IT-среде понимания термина ассемблер все всё поняли корректно.
Контекст очень важен, и игнорировать его не лучшая идея. Когда я обсуждаю текущий проект с другими разработчиками я могу сказать "база юзеров", и все отлично поймут, что это сокращение от "база данных", что в данном проекте традиционной базы данных как таковой нет т.к. данные лежат в трёх json-файлах, и что я имел в виду один конкретный файл из этих трёх (в котором данные с профайлами юзеров — хотя формально в остальных двух файлах данные тоже относятся к юзерам). Конечно, я могу сказать то же самое терминологически точно, напр. "файл слеш-data-слеш-db-слеш-users-точка-json содержащий список объектов описывающих профиль юзера в формате json", но, честное слово, никто из участников дискуссии не поблагодарит меня за "точность" в описании если они будут вынуждены прослушивать эту конструкцию каждый раз вместо "неточной" фразы "база юзеров". И даже если бы я использовал вышеупомянутое "точное" определение, всегда найдётся зануда, который попросит уточнять, что "слеш" это "прямой слеш", чтобы не спутали случайно с "обратный слеш", и что "объект описывающий профиль юзера" это недостаточно точно т.к. не указано какие поля и с каким содержимым содержит данный объект, и что путь к файлу это недостаточно точно без указания сервера на котором он находится, и наверняка ещё что-нибудь.
И, поймите правильно, я сам зануда, так что вопрос не в занудстве как таковом, а в том, есть ли реальный смысл занудствовать, какая от этого польза в данном конкретном случае. Если её нет — не надо занудствовать, пожалуйста.
cens
26.10.2018 16:00Я среагировал, скорее, на ваше «нет реальной необходимости», «банальным занудством» и «перегибы (в любую сторону) ни к чему хорошему не приводят». Т.е на «защиту» ошибочной терминологии.
MacIn
26.10.2018 13:19Учитывая, что ассемблер мапится в коды почти один-в-один вполне можно позволить использовать оба термина как взаимозаменяемые
Это не совсем так, потому что современные ассемблеры понимают и сложные макроинструкции, и ветвления, и вызов процедур и размещение данных и абстраткные данные (структуры, например).
SongOfBird
25.10.2018 23:44Если взять современные компы Dell или Hp, и грамотно их настроить, то даже при физическом доступе к компьютеру мало что можно сделать(а точнее ничего). Все дело в Intel ME и цифровой подписи Intel. Нет ключей — гуляй. Кроме того Hp и Dell (ну и другие в той или иной степени) создают свои собственные средства защиты и встраивают в UEFI, например в DXE фазе. Такая защита преодолевается лишь кропотливым трудом за большое количество времени.
dark_snow
26.10.2018 03:21+1Но вспоминая Stuxnet, возможна аналогичная ситуация — при необходимости можно уточнить оборудование\версии (а если «типовое», то еще веселее) и копать именно под него и тогда при достаточной выгоде, затраченное время компенсируется результатом.
SongOfBird
26.10.2018 09:12+1Полагаю что в работах такого уровня не обходится без слитой(добытой) информации от разработчика и тесного сотрудничества с серьезными дядями.
welga
25.10.2018 23:44+1Не понимаю зачем нужен загружаемый микрокод для команды деления. Почему бы для основных проверенных команд не сделать жесткий микрокод, без возможности загрузки.
Возможно на базе этих процессоров производители строят другие архитектуры процессоров. Но тогда надо разделять эти потоки.rPman
26.10.2018 00:16Это просто пример, наверное с таким же успехом это могла бы быть команда mul. Потому что там практически все команды определены микрокодом, внутри микропроцессор далеко не x86, а некий франкенштейн, заточенный на создание совместимого с помощью микрокода, при этом разработчики процессора оставили за собой гибкость в правке этого.
Не удивлюсь, что когда-нибудь, когда производители станут более открытыми, будет возможным написание микрокода процессора тупо под задачу с целью оптимизации энергопотребления, т.е. буквально под числодробилки будет перелопачиваться архитектура процессора. Очень жаль что этого мы можем тупо не дождаться, ибо бабло побеждает разум.khim
26.10.2018 03:24+1Это просто пример, наверное с таким же успехом это могла бы быть команда mul.
Нет, не могла бы. Через микрокод идут только хитровывернутые команды, выполняющиеся десятки тактов. Но никак не mul и не mov.
Потому что там практически все команды определены микрокодом
Наоборот. Через микрокод пропускается очень небольшой процент редких инструкций. Хотя, поскольку многие из них связаны с безопасностью, это всё равно страшно, да.
будет возможным написание микрокода процессора тупо под задачу с целью оптимизации энергопотребления, т.е. буквально под числодробилки будет перелопачиваться архитектура процессора.
Не будет в силу вышеописанного. Любая команда на микрокоде примерно на порядок медленнее, чем «простая» инструкция — даже если она ничего не делает.vanxant
26.10.2018 04:42+1Вы или очень хорошо знаете устройство современных процессоров, или выдаёте желаемое за действительное.
Конвейер длинный, на каком-то из первых этапов декодирования идёт обращение к базе микрокода, типа «а есть ли микрокод к вот этому опкоду».
Ящитаю, что там нет никаких проверок типа «а есть ли», там тупо опкоду mul соответствует микрокод длиной в одну команду mul. Так тупо быстрее (ну, ценой буквально +100500 байт во флэш-памяти микрокодов).
Насколько я помню таблицу опкодов, если mov и простейшие операции (add/adc/sub/sbb/cmp/or/and/xor) ещё можно выцепить маской по паре бит, то вот конкретно mul со всеми вариантами разрядности и знаковости — это отдельный геморрой.JerleShannara
26.10.2018 05:14+1x86 набор инструкций это вообще один большой геморрой, особенно начиная со времени включения всяких x64 инструкций.
beeruser
26.10.2018 05:53+1Ящитаю, что там нет никаких проверок типа «а есть ли», там тупо опкоду mul соответствует микрокод длиной в одну команду mul.
Вы путаете микрокод и микрооперации (МОП). Декодеры превращают инструкции в 1 или несколько микроопераций. К ПЗУ микрокода (Microcode Sequencer ROM — MSROM) происходит обращение лишь в сложных случаях, операциях типа MOVSB или например если инструкция требует > 4 МОП.
В таких случаях декодеры отключатся и выполнение идёт из MSROM.
Обычные инструкции MUL/DIV это один МОП.qw1
26.10.2018 07:43+2Обычные инструкции MUL/DIV это один МОП.
Как минимум, если операнд в памяти, нужно разбить на микрооперацию загрузки и собственно умножения.beeruser
26.10.2018 18:36Как минимум, если операнд в памяти, нужно разбить на микрооперацию загрузки и собственно умножения.
Раньше так и делали, и load-op инструкции были в 2 МОП.
Сейчас это один МОП.qw1
26.10.2018 20:19+1То есть, сейчас есть МОПы сложения со всеми видами адресации, умножения, косвенного вызова и т.д.?
Тогда какой смысл в МОПах, если их кол-во приближается к кол-ву CISC-инструкций?beeruser
26.10.2018 20:49+1Меньше МОП — меньше ресурсов требуется для отслеживания команды внутри ОоО-машины.
Смысл сделать их количество меньше чем количество CISC-инструкций =)
МОП-ы благодаря macrofusion могут содержать две отдельные инструкции — например cmp+jmp.
Skylake запускает 4 МОП за такт, но команд может быть больше.
khim
26.10.2018 08:01+1Обычные инструкции MUL/DIV это один МОП.
Только div на следующем этапе заменяется на подпрограмму из MSROM. Тупо потому, что, в отличие от mul, у ALU нет соответствующего блока! Там целая подпрограмма запускается — от этого и не фиксированное время исполнения и прочее.beeruser
26.10.2018 20:42Только div на следующем этапе заменяется на подпрограмму из MSROM. Тупо потому, что, в отличие от mul, у ALU нет соответствующего блока!
В разных процессорах по разному.
На AMD всего 1-2 МОП
www.agner.org/optimize/instruction_tables.pdf стр 93, например.
На Intel Skylake IDIV генерирует десяток микроопераций.
Не смотря на это в Интел блок для деления имеется (radix 16 divider со времён Penryn) — он висит на порту 0
«Improvements in the Intels Coret2 Penryn Processor Family Architecture and Microarchitecture»
citeseer.ist.psu.edu/viewdoc/download;jsessionid=13CD375361DAF8C4C188F1D3C67730F0?doi=10.1.1.217.155&rep=rep1&type=pdf
Так же можете почитать тут
www.imm.dtu.dk/~alna/pubs/ARITH20.pdfkhim
26.10.2018 23:01То, что используетс всего пара ?op'ов не обозначает, что там нет микрокода.
Во всех описанных вами статьях очень чётко видно, что аппаратной реализации деления нет ни в одном процессоре. Во всех аппаратно реализован вспомогательный алгоритм, а собственно деление — реализовано поверх него, итеративно.
Если в процессоре есть уже микрокод — то его как раз для подобных вещей логично задействовать…
DrZlodberg
26.10.2018 09:03+2Мне в этом всём больше интересно следующее: разве этот микрокод написан в х86 кодах? Это же совершенно не логично. Лучше было написать уже во внутренних кодах, чтобы:
1. не перекодировать.
2. никто не мог декодировать т.к. все без спецификаций это было бы изрядной проблемой. Да и компилить было бы проблематично. Проблема решаема, но тем не менее…
khim
26.10.2018 08:29Конвейер длинный, на каком-то из первых этапов декодирования идёт обращение к базе микрокода, типа «а есть ли микрокод к вот этому опкоду».
Это было бы не глупо, а очень глупо. Не забудьте, что x86 — это CISC, а современные процессоры — суперскаляры. К микрокоду может обращаться только один декодер из двадцати (да-да, в современных CPU не два, не три, но двадцать декодеров… вернее 16+4 — подумайте почему так).
Так тупо быстрее (ну, ценой буквально +100500 байт во флэш-памяти микрокодов).
Так вы уж определитесь — «ценой буквально +100500 байт во флеш-памяти микрокодов» или «тупо быстрее». Вас не смущает разница между этими числами примерно так на порядок (не двоичный — в 10 раз)? Декодер должен обрабатывать 3-4 инструкции за один такт, а обращение к кешу L1 (по размеру он сравним с микрокодов) — занимает в современных CPU больше одного такта!
P.S. Многие не осознают того, что обозначают частоты в 3-4GHz и миллиарды транзисторов для разработчиков CPU. А обозначают они одну простую вещь: вы не можете позволить себе иметь большие блоки, работающие на полной тактовой частоте. Можете сделать 100 или даже 1000 мини-блоков, каждый из которых будет состоять из нескольких тысяч транзисторов. А можете сделать да, большой блок из 100500 транзисторов (как кеш L3) — но тогда этот блок даже на частоте процессора не сможет работать, хорошо, если 1/3 или 1/4 «осилит»…rogoz
26.10.2018 13:21А можете сделать да, большой блок из 100500 транзисторов (как кеш L3) — но тогда этот блок даже на частоте процессора не сможет работать, хорошо, если 1/3 или 1/4 «осилит»…
? Сейчас же вроде все кэши работают на частоте CPU. Вроде бы во времена Slot 1 были процессоры с половинной частотой кэша.
www.anandtech.com/show/399/4khim
26.10.2018 16:53Кеши тактуются полной частотой, но это не значит, что они на ней работают. Во всяком случае задержки в 3-4 такта для L1 (и в десятки тактов для L3) и их пропускная способность с гипотезой о том, что кеши работают на полной частоте плохо согласуются.
welga
26.10.2018 21:10В ЕС ЭВМ 3 поколения это уже было реализовано. Там можно было программно изменять память микрокоманд процессора и тем самым добавлять новые команды либо изменять алгоритм существующих, например для ОС СВМ(система виртуальных машин), менялся алгоритм команды прерывания.
JerleShannara
26.10.2018 01:07+3Инструкция fdiv была реализована ещё в 8087 сопроцессоре, в 80387 она стала поддерживать стандарты IEEE на счет плавающей точки, а в 80587 (пускай такого и не существовало, но обзову это так) реализацию fdiv изменили (с чего и зачем — это у штеуда надо спросить). И опа, ошибка готова. Плюс к закату эпохи Pentium 2 в интел пришли к итогу, что CISC в полноценной CISC реализации это огроменный гемморой, гипер-печка и штука, которая не даёт задрать частоты (т.к. цепочка логических элементов получается длинной), но отказаться от неё нельзя (Была даже шутка, что Интел были бы рады смыть всю архитектуру CISC в море, но их бы оштрафовали за загрязнение природы) и постепенно выкатили CISC to RISC транслятор в своих камнях. Идя дальше — вполне вероятно что какие-то логические примитивы, которые идеально подходили для реализации на них полноценной логики в 198х годах, к 201х годам с изменениями технологий стали неоптимальны, и их заменили на другие, что повлекло за собой изменение реализаций конечных кусков АЛУ, например команды add. Гораздо проще реализовать возможность на лету исправить ошибку, чем снова получить прикол формата 4.0/2.0=3.99999999997.
vitalyvitaly
27.10.2018 00:51Точнее, первый процессор Intel x86 c RISC-транслятором — это уже Pentium Pro, у AMD еще раньше начиная с ядра K5.
khim
27.10.2018 01:40+1Чисто для справки: Pentium Pro появился на рынке на полгода раньше, чем K5.
vitalyvitaly
27.10.2018 09:39+1Там формально разница ноябрь 1995 vs. март 1996. Я помню те времена и анонс Pentium Pro и сам имел дело с его первой моделью на 150 мегагерц в сервере. Но надо учесть, что в народе ранний PPro быстро завоевал дурную славу и тех, кто стремился купить его себе домой, я не встречал. 5k86/K5, в отличие от него, широко продавались, хотя тоже страдали от имиджевых проблем и обвинений в несовместимости и медленности на фоне «образцового» Pentium 133 и позже 166,200 и MMX.
khim
27.10.2018 13:12+1Это всё ньюансы. AMD всегда отставала от Intel «на полшага» и во времена PPro/K5 — тоже. Так что говорить о том, что у AMD что-то там появилось раньше можно только в исключительных случаях (типа появления 64-битной архитектуры, которую Intel не делал, так как сильно верил в Itanic).
robert_ayrapetyan
26.10.2018 01:43+2Ну вот fdiv в 94-м была «основной проверенной».
khim
26.10.2018 03:27+1Не была она. Весь модуль FPU был переделан в Pentium с нуля — это вам любой игрок в Quake подтвердит (AMD и 486е были не в два раза медленнее, как можно было бы подумать, а чуть ли не в 10 раз).
Вряд ли что-то реализованное с нуля на совсем других принципах можно считать «проверенным».
walti
26.10.2018 06:51+1Почему бы программистам не выпускать программы без ошибок?
/офф
i7-690 — 80 записей в таблице с эррата
самосгораемый атом- 250.
И по каждой выпускать новый степпинг, отзывая проданные.
Ох уж эти идеалисты
wlbm_onizuka
26.10.2018 10:03При таком количестве транзисторов неудивительно, что современные процессоры x86 испещрены недокументированными инструкциями и аппаратными уязвимостями.
Звучит весьма противоречиво
willmore
26.10.2018 10:32+3сложно переплетающийся лабиринт новых и античных технологий
Нет, вы опять за свое? :) Что у нас там из античных технологий? Литье бронзы, гончарное дело, колесницы и рабский труд. Но никаких процессоров х86.VolKarev Автор
26.10.2018 10:34Каюсь. )) Специально в одном месте «антикварные» вписал, а в другом видимо на автомате поставил. Поправлено.
Insane11
26.10.2018 12:18"… претендовать на роль доверенного корня...", это вы так доверенный корневой центр сертификации обозвали? = )
mayorovp
26.10.2018 13:08Нет. Корень доверия / доверенный корень — это такая штука, которой доверяете лично вы, и которая способна проверить другие части системы: процессор проверяет подпись прошивки, прошивка — проверяет подпись ОС, ОС проверяет подписи драйверов.
AlexAV1000
26.10.2018 13:10-1Процессоры «Эльбрус» — наше всё.
snizovtsev
26.10.2018 14:25+5Под Эльбрус даже компилятор (lcc) проприетарен, не говоря уже о таких более глубоких вещах как микрокод. Так что для тех, кто не имеет отношения к нашим спецслужбам, особой разницы в плане безопасности не вижу. OpenRISC вот — другое дело.
firk
27.10.2018 02:42При таком количестве транзисторов неудивительно, что современные процессоры x86 испещрены недокументированными инструкциями и аппаратными уязвимостями. Среди недокументированных, – обнаруженных почти случайно, – инструкций: ICEBP (0xF1), LOADALL (0x0F07), apicall (0x0FFFF0) [1], которые позволяют разблокировать процессор для несанкционированного доступа к защищённым областям памяти.
Ну что за глупости. Количество транзисторов тут совершенно ни при чём, тем более что значительная их доля — это кеш-память, а вовсе не логика.
По поводу инструкций — не знаю насчёт apicall, но вот 0xF1 явно никто прятать не собирался, а LOADALL вполне штатно используется (или использовалось по крайней мере) биосами.JerleShannara
28.10.2018 03:34+1Я на примере LOADALL и ещё парочки команд с префиксами REP/LOCK показываю, что такое обработчик Unknown OpCode, благо БИОСы это эмулируют (но не используют). Штатно LOADALL был на 80286 и в himem.sys, а уж из-за himem.sys пришлось встраивать эмуляцию этой команды как минимум в биосы 80486ых.
firk
28.10.2018 10:03+1Да, перепутал насчёт LOADALL, она там и правда эмулировалась а не использовалась. И всё же я не думаю что тон, которым упомянуты эти инструкции в этой статье, оправдан. LOADALL, например, вполне чтит кольца защиты и никаких бекдоров таким образом не предоставляет. Любая операционная система должна допускать возможность её запуска на проце, чуть более новом чем тот под который она проектировалась, и с чуть большим набором команд. Таким образом, наличие неизвестных ей (по не важно каким причинам) инструкций не должно ничему угрожать до тех пор, пока они вписываются в общую концепцию прав доступа.
Alex_Q
Есть какая либо возможность считать микрокод и сравнить его хэш с референсным значением?
dartraiden
А зачем? Микрокод обязательно должен быть подписан Intel, иначе процессор его просто не примет. Применяется RSA-2048, удачи злоумышленнику в попытках сбрутить.
У AMD тоже проверяется подпись, если мне не изменяет память.
nidalee
Можно без вопросов прошить тем, что вы считаете надежным (тем же референсом). Но зачем?
Hanabishi
Официально — нет. В статье же написано, что микрокод всячески скрывается производителем.
TheDaemon
Не правда. Можно вполне нормально сдампить микрокод. Но вот как он устроен — это скрывается производителем :)