
Часть I. R извлекает и рисует
Конечно, PostgreSQL с самого начала создавалась как универсальная СУБД, а не как специализированная OLAP-система. Но один из больших плюсов Постгреса — в поддержке языков программирования, с помощью которых из него можно сделать что угодно. По изобилию встроенных процедурных языков ему просто нет равных. PL/R — серверная реализация R — любимого языка аналитиков — один из них. Но об этом позже.
R – удивительный язык со своеобразными типами данных —
list, например, может включать в себя не только данные разных типов, но и функции (вообще, язык эклектичный, и говорить о принадлежности его к определенному семейству не будем, чтобы не порождать отвлекающие дискуссии). В нем есть симпатичный тип данных data.frame, который подражает таблице РСУБД — это матрица, у которой столбцы содержат разные типы данных, общие на уровне столбца. Поэтому (и по другим причинам) работать в R с базами данных довольно удобно.Мы будем работать в командной строке в среде RStudio и соединяться с PostgreSQL через драйвер ODBC RpostgreSQL. Их несложно установить.
Поскольку R создавался как этакий вариант языка S для тех, кто занимается статистикой, то и мы приведем примеры из простенькой статистики с простенькой графикой. У нас нет цели знакомить с языком, но есть цель показать взаимодействие R и PostgreSQL.
Обрабатывать данные, хранящиеся в PostgreSQL, можно тремя путями.
Во-первых, можно выкачать данные из базы любыми удобными средствами, упаковать их, скажем, в JSON – их понимает R – и обрабатывать дальше в R. Это обычно не самый эффективный способ и точно не самый интересный, мы его рассматривать здесь не будем.
Во-вторых, можно связываться с базой – читать из нее и сбрасывать данные в нее – из среды R как из клиента, используя драйвер ODBC/DBI, обрабатывая данные в R. Мы покажем, как это делается.
И, наконец, можно делать обработку средствами R уже на сервере базы, используя PL/R как встроенный процедурный язык. Это имеет смысл в ряде случаев, так как в R есть, например, удобные средства агрегирования данных, которых нет в
pl/pgsql. Мы покажем и это.Распространенный подход это использование 2-го и 3-го варианта в разных фазах проекта: сначала отладка кода как внешней программы, а затем перенос ее внутрь базы.
Начнём. R интерпретируемый язык. Поэтому можно действовать по шагам, а можно сбросить код в скрипт. Дело вкуса: примеры в этой статье коротенькие.
Сначала нужно, конечно, подключить соответствующий драйвер:
# install.packages("RPostgreSQL")
require("RPostgreSQL")
drv <- dbDriver("PostgreSQL")Операция присвоения выглядит в R, как можно было заметить, своеобразно. Вообще в R a < — b значит то же, что и b -> a, но более распространен первый способ записи.
Базу данных возьмем готовую: демобазу авиаперевозок, которую используют учебных материалах Postgres Professional На этой странице можно выбрать вариант базы по вкусу (то есть по размеру) и почитать ее описание. Схему данных воспроизводим для удобства:
Предположим, что база установлена на сервере 192.168.1.100 и называется
demo. Соединяемся: con <- dbConnect(drv, dbname = "demo",
host = "192.168.1.100", port = 5434,
user = "u_r")Продолжаем. Посмотрим вот таким запросом, в какие города чаще всего запаздывают рейсы:
SELECT ap.city, avg(extract(EPOCH FROM f.actual_arrival) - extract(EPOCH FROM f.scheduled_arrival))/60.0 t FROM airports ap, flights f WHERE ap.airport_code = f.departure_airport AND f.scheduled_arrival < f.actual_arrival AND f.departure_airport = ap.airport_code GROUP BY ap.city ORDER BY t DESC LIMIT 10;Для получения минут опоздания мы использовали конструкцию postgres
extract(EPOCH FROM ...) для извлечения «абсолютных» секунд из поля типа timestamp и поделили на 60.0, а не на 60, чтобы избежать отбрасывания остатка при делении, понятом как целочисленное. EXTRACT MINUTE использовать нельзя, так как встречаются опоздания больше часа. Усредняем времена опоздания оператором avg.Передаем текст в переменную и отправляем запрос на сервер:
sql1 <- "SELECT ... ;"
res1 <- dbGetQuery(con, sql1)Теперь разберемся, в каком виде пришел запрос. Для этого в языке R имеется функция
class()class (res1)Она покажет, что результат был упакован в тип
data.frame, то есть, напоминаем, аналог таблицы базы: фактически это матрица со столбцами произвольных типов. Она, кстати, знает названия столбцов, а к столбцам, если что, можно обращаться, например, так:print (res1$city)Пора задуматься, как визуализировать результаты. Для этого можно посмотреть, чем мы располагаем. Например, выбрать подходящую графику из этого списка:
- R-Bar Charts (линейчатые)
- R-Boxplots (биржевые)
- R-Histograms (гистограммы)
- R-Line Graphs (графики)
- R-Scatterplots (точечные)
Надо иметь в виду, что для каждого вида на вход подается подходящий для картинки тип данных. Выберем линейчатую диаграмму (лежачие столбики). Для нее требуются два вектора для значений по осям. Тип «вектор» в R это просто набор однотипных значений.
c() — конструктор векторов.Сформировать нужные два вектора из результата типа
data.frame можно так:Time <- res1[,c('t')]
City <- res1[,c('city')]
class (Time)
class (City)Выражения в правых частях выглядит странновато, но это удобный прием. Более того, в R можно очень компактно записывать различные выражения. В квадратных скобках перед запятой индекс ряда, после запятой — индекс колонки. То, что перед запятой ничего не стоит, значит всего лишь, что будут выбраны все значения из соответствующей колонки.
Класс Time получится
numeric, а класс City — character. Это разновидности векторов. Теперь можно заняться самой визуализацией. Надо задать файл картинки.
png(file = "/home/igor_le/R/pics/bars_horiz.png")После этого следует нудноватая процедура: задать параметры (
par) графиков. И не сказать, чтобы всё в графических пакетах R было интуитивно. Например, параметр las определяет положение надписей со значениям по осям относительно самих осей:- 0 и по умолчанию — параллельно осям;
- 1 — всегда горизонтально;
- 2 — перпендикулярно осям;
- 3 — всегда вертикально
Все параметры расписывать не будем. Вообще их много: поля, масштабы, цвета — ищите, экспериментируйте на досуге.
par(las=1)
par(mai=c(1,2,1,1))Наконец, строим график из лежачих столбиков:
barplot(Time, names.arg=City, horiz=TRUE, xlab="Опоздание (мин)", col="green", main="Среднее время опоздания", border="red", cex.names=0.9)Это не всё. Надо сказать напоследок:
dev.off()
Для разнообразия нарисуем еще точечную диаграмму опозданий. Из запроса уберем LIMIT, остальное то же самое. Но точечной диаграмме нужен один вектор, а не два.
Dots <- res2[,c('t')]
png(file = "/home/igor_le/R/scripts/scatter.png")
plot(input5, xlab="Кучность",ylab="Опоздания",main="Распределение опозданий")
dev.off()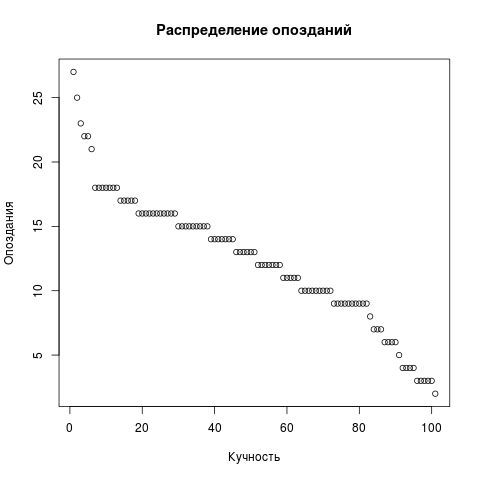
Для визуализации мы использовали стандартные пакеты. Понятно, что R язык популярный и пакетов существует примерно бесконечность. Об уже установленных можно спросить так:
library()Часть II. R генерирует пенсионеров
R удобно использовать не только для анализа данных, но и для их генерации. Где есть богатые статистические функции, там не может не быть разнообразных алгоритмов создания случайных последовательностей. В том числе можно использовать типичные (Гауссовские) и не совсем типичные (Ципфовские) распределения и для симуляции запросов к базе.
Но об этом в следующей части.
Комментарии (12)

BkmzSpb
30.10.2018 00:14+1require("RPostgreSQL")
Обычно
requireрекомендуется использовать в функциях, т.к. в случае ошибки он выдаетwarning. Для загрузки пакета лучше использоватьlibraryодин раз в начале.
Time <- res1[,c('t')] City <- res1[,c('city')]
Несовсем понятно зачем использовать функцию
c()для создания вектора длиной… 1 элемент. Достаточно написатьres1[, "t"]или дажеres1$t.
Ну и про оператор присваивания. Их так-то 5 штук, и на месте
<-спокойно можно использовать=(дело вкуса / соглашения).=необходим при вызове функций и передачи аргументов по имени.
dev.off(), кстати, тоже выполняет определенную функцию и в целом его вызов может не требоваться. Зависит от окружения в котором вы строите графики (например, IDE).dev.off()необходим для I/O, его можно скобинировать сtryCatch({ expr;}, finally = dev.off())чтобы не оставить ваш "девайс" в подвешенном состоянии если во время построения графика что-то отвалится.Igor_Le Автор
30.10.2018 00:40Спасибо! Моя цель показать, что R + PostgreSQL полезное сочетание. Я, как можно догадаться, «со стороны» PG, и такие дополнения, как ваши, очень к месту.

Val83
30.10.2018 00:42Если бы прочитал такое пару лет назад — желание изучать R отпало бы. Примитив какой-то описан.
Igor_Le Автор
30.10.2018 00:43У меня не было цели рекламировать R.
BkmzSpb
30.10.2018 00:47Вообще лучше бы прорекламировали. На хабре так мало статей про
R, хотя для работы с данными это один из лучших инструментов. Не говоря уже оtidyverse, где можно обложиться пайпами и non-standard evaluation и переквалифицироваться в функциональщину.
Ananiev_Genrih
30.10.2018 09:40статья из разряда "ну совсем вводная" и конечно не про рекламу R ибо такую "бородатую" визуализацию на R нынче мало кто делает.
Больше интересно было бы про нагрузочное тестирование в этой связке, какие есть вилы/грабли при связке dbplyr+СУБД, какие есть возможности тюнинга для повышения эффективности работы этой связки.
Например недавно коллеги подбросили интересную ссылку по сравнению производительности связки одной колоночной аналитической СУБД как в классической связке (R+Server) так и СУБД развернутой внутри самой R-сессии (вообще огонь). Там к примеру есть сравнение как с (PL/R-naive) так и с (PL/R-tuned), вот про тюнинг было бы интересно почитать как описание личного опыта/эксперимента.StepanTomsk
30.10.2018 10:16Если есть возможность то поднимайте slave read only для аналитики — снижаете риск «положить» прод. Когда это не помогает экспортируйте данные, желательно совместно с обработкой и денормализацией, например в clickhouse или в Vertica (до 1 ТБ — бесплатно).
Если у Вас обработка данных разовая то порой проще выгрузить весь набор данных за период не фильтруя в БД, seq-scan дешевле (особенно на ssd).
Join это боль, лучше делать его на самом последнем этапе, и не в БД.
Если таблица в PostgreSQL разбита на партиции то лучше выгружать и обрабатывать данные по каждой партиции отдельно. Большая боль будет если одновременно нужно сделать join по нескольким партишированным таблицам.
Основной подход — выгрузить данные и обрабатывать их за пределами реляционной БД.
StepanTomsk
30.10.2018 09:55Доброго всем дня.
Статью можно рассматривать как первый шаг к дальнейшему погружению в R и/или статистическую обработку данных, особенно если у Вас уже есть PostgreSQL (или иная БД с ODBC).
Существует одна ошибка начинающих аналитиков — работая с R мы продолжаем мыслить в рамках терминов баз данных, писать SQL… и, по факту, тратить свое время не на исследование данных.
В R есть великолепный инструмент dplyr, который позволяет абстрагироваться от синтаксиса SQL и перейти непосредственно к обработке данных. Но dplyr не ограничивает Вас и позволяет исполнять «рукописные» запросы.
Когда нужны «рукописные» запросы? Здесь варианты, например — сложные join, ручная оптимизация, вызов табличных функций. Да, в этих случаев иногда стоимостный оптимизатор PostgreSQL справляется не блестяще, но не забываем у нас не OLAP БД.
Рекомендую к прочтению Why SQL is not for Analysis, but dplyr is (eng).
kolu4iy
Долго думал — что за неизвестный продукт космической индустрии "Союз R".
Igor_Le Автор
:)