
UPD: Ввиду бурной реакции обозначу в начале — это просто обзорный tutorial возможного быстрого парсинга страниц)
Объем данных, доступных в Интернете, постоянно растет как по количеству, так и по форме. И эти данные очень часто бывают нужны для обучения ИИ. Большая часть этих данных доступна через API, но в то же время многие ценные данные по-прежнему доступны только через парсинг.
В данном руководстве будут рассмотрены несколько вариантов получения данных.
Для примера данных возьмем список мероприятий Рунета
Посмотрим исходный код страницы, чтобы понимать откуда мы будем извлекать данные
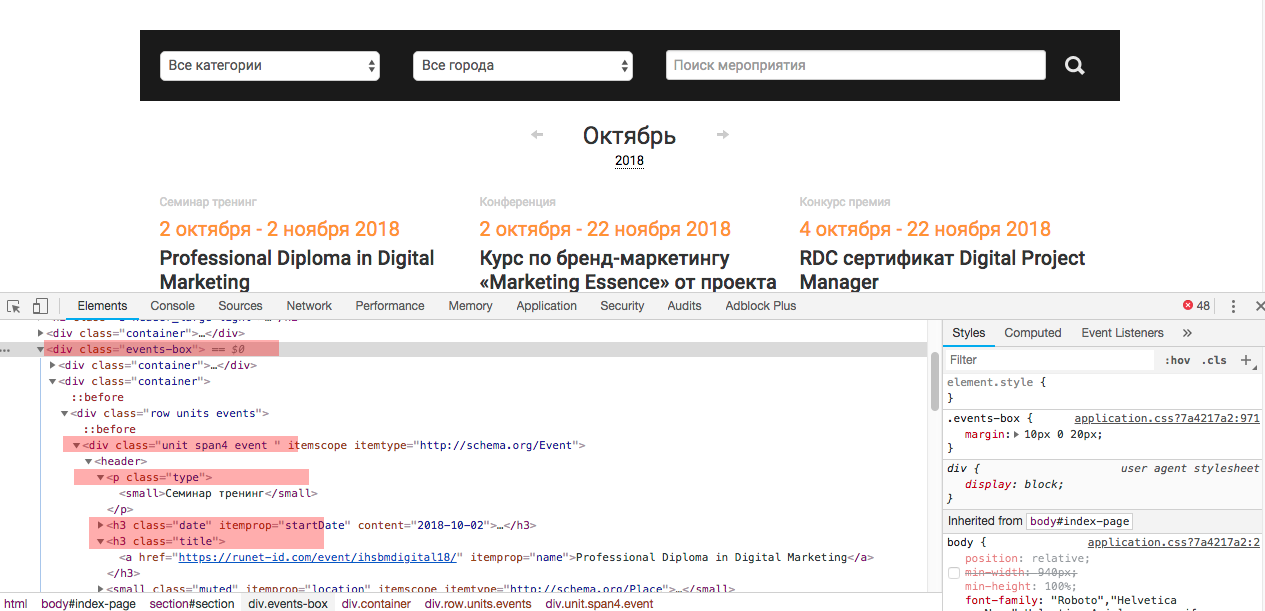
Как видно — все события выводятся в слое —
<div class="events-box">отдельное событие выводится в слое —
<div class="unit span4 event " itemscope="" itemtype="http://schema.org/Event">и каждое событие имеет определенные атрибуты, которые мы и будем собирать
- Тип
<p class="type">- Заголовок
<h3 class="title">- Содержание
<p itemprop="description">Теперь, когда мы имеем представление, что конкретно из содержимого нам нужно можно приступать к парсингу.
1. Получение данных с помощью применения библиотек Requests и Beautiful Soup.
Для начала установим библиотеки
$ pip install requests$ pip install bs4После установки приступим непосредственно к парсингу
Начнем с подключения библиотеки Requests и проверки правильно ли отрабатывается запрос
import requests
url = 'https://runet-id.com/events/'
requests.get(url)Получим вывод в консоли:
<Response [200]>
Значит все верно сделано и страница получена.
Теперь посмотрим в каком виде она нам передается, добавим к нашему коду:
req = requests.get(url).text
print(req[:100]) #отображение 100 символовРезультат:
<html>
<head>
<link rel="stylesheet" type="text/css" href="/javascripts/jquery.uКак видно мы получили html код страницы. Но данный формат не удобен для анализа — поэтому мы будем использовать библиотеку Beautiful Soup, чтобы данные получить в нужном формате.
Для этого мы импортируем библиотеку
from bs4 import BeautifulSoupсоздадим объект и передадим ему содержимое
soup = BeautifulSoup(req.text, 'lxml')Обозначим Beautiful Soup, что является контейнером данных и что затем в нем искать
events = soup.find('div', {'class': 'events-box'}).findAll('div', {'class', 'unit span4 event '})И создадим словарь, в который разместим все события с атрибутами
i = 0
events_dict = {}
for event in events:
event_type = event.find('small').text
event_title = event.find('h3', {'class', 'title'}).text
event_desc = event.find('p', {'itemprop': 'description'}).text
events_dict[i] = [event_type, event_title, event_desc]
i += 1Можно все оформить как функцию
import requests
from bs4 import BeautifulSoup
def get_upcoming_events(url):
req = requests.get(url)
events_dict = {}
i = 0
soup = BeautifulSoup(req.text, 'lxml')
events = soup.find('div', {'class': 'events-box'}).findAll('div', {'class', 'unit span4 event '})
for event in events:
event_type = event.find('small').text
event_title = event.find('h3', {'class', 'title'}).text
event_desc = event.find('p', {'itemprop': 'description'}).text
events_dict[i] = [event_type, event_title, event_desc]
i += 1Вызов функции:
get_upcoming_events('https://runet-id.com/events/')2. Получение данных с помощью Scrapy
Scrapy — очень популярный фреймворк для извлечения данных.В предыдущем пункте мы использовали библиотеки requests для получения и Beautiful Soup для извлечения данных. Scrapy предлагает все эти функции со многими другими встроенными модулями и расширениями.
Scrapy предлагает ряд мощных функций, которые стоит упомянуть:
- Встроенные расширения для создания HTTP-запросов и обработки сжатия, проверки подлинности, кэширования, управления user-agent и HTTP заголовками
- Встроенная поддержка выбора и извлечения данных с использованием выбора языков, таких как CSS и XPath, а также поддержка использования регулярных выражений для выбора контента и ссылок
- Поддержка кодирования для работы с языками и нестандартными объявлениями кодирования
- Гибкие API для повторного использования и написания собственных промежуточных программ и конвейеров, которые обеспечивают простой способ реализации таких задач, как автоматическая загрузка изображений или файлов и хранение данных в хранилищах, таких как файловые системы, S3, базы данных и другие
Его принцип действия схож с обходчиками поисковых систем.
Начнем с установки фреймворка
$ pip install scrapyВсе в Scrapy вращается вокруг создания "паука". "Пауки" сканируют страницы в Интернете на основе правил, которые мы предоставляем. "Паук" создается с определением класса, от которого он происходит. Наш происходит от scrapy.Spider класса.
Каждому "пауку" присваивается имя, а также один или несколько start_urls, которые сообщают, с чего начать сканирование.
class PythonEventsSpider(scrapy.Spider):
name = 'pythoneventsspider'
start_urls = ['https://runet-id.com/events/', ]Затем обозначается метод, который будет вызываться для каждой страницы, которую собирает "паук".
for events in response.xpath('//div[contains(@class, "unit span4 event ")]'):
event_type = events.xpath('.//small/text()').extract_first()
event_title = events.xpath('.//h3[@class="title"]/a/text()').extract_first()
event_desc = events.xpath('.//p[@itemprop="description"]/text()').extract_first()
events_dict[i] = [event_type, event_title, event_desc]
i += 1Реализация этого метода использует XPath для получения данных со страницы (XPath — встроенное средство навигации по HTML в Scrapy).
Оставшийся код выполняет программный запуск "паука".
process = CrawlerProcess({ 'LOG_LEVEL': 'ERROR'})
process.crawl(PythonEventsSpider)
spider = next(iter(process.crawlers)).spider
process.start()Он начинается с создания CrawlerProcess, который выполняет фактическое сканирование и множество других задач. Мы передаем ему LOG_LEVEL OF ERROR, чтобы предотвратить объемный вывод Scrapy. Измените это на DEBUG и запустите его, чтобы увидеть разницу.
Затем мы сообщаем процессу, что нужно использовать нашу реализацию "паука".
И запускаем все это — вызывая process.start ().
Полный код:
import scrapy
from scrapy.crawler import CrawlerProcess
class PythonEventsSpider(scrapy.Spider):
name = 'pythoneventsspider'
start_urls = ['https://runet-id.com/events/', ]
events_dict = {}
def parse(self, response):
i = 0
for events in response.xpath('//div[contains(@class, "unit span4 event ")]'):
event_type = events.xpath('.//small/text()').extract_first()
event_title = events.xpath('.//h3[@class="title"]/a/text()').extract_first()
event_desc = events.xpath('.//p[@itemprop="description"]/text()').extract_first()
events_dict[i] = [event_type, event_title, event_desc]
i += 1
if __name__ == "__main__":
process = CrawlerProcess({'LOG_LEVEL': 'ERROR'})
process.crawl(PythonEventsSpider)
spider = next(iter(process.crawlers)).spider
process.start()
Комментарии (15)

ArsenAbakarov
30.10.2018 19:02+3В чем полезность статьи?
Думал что тут будет проблема завязывания на селекторы, использование машинки для обхода проблемы.
Даже асинхронщины нет, просто унылый паук.wegres
30.10.2018 20:17А что это такое — машинка для обхода проблемы завязывания на селекторы?
ArsenAbakarov
31.10.2018 14:13Это про то, как твое приложение умеет по картинкам, текстам, другим признакам понимать что за контент представлен на странице и парсит его без всяких селекторов, это было на PyCon 2018,
www.youtube.com/watch?v=l11caoD_MFc
afrikyan Автор
30.10.2018 20:24-2Не все являются продвинутыми разработчиками. Так же как и не претендую на это звание)Это просто небольшой tutorial
saluev
30.10.2018 20:47+2Бытует заблуждение, что для того, чтобы написать tutorial, достаточно освоить что-то на поверхностном уровне. Дескать, ну я же сам в этом только что разобрался, напишу-ка по горячим следам tutorial. Но увы, это не так. Чтобы написать качественный туториал, освоить материал нужно на уровне сильно выше среднего.
vchslv13
30.10.2018 20:04+3Жесть, статья в неболших плюсах (а не глубоко в минусах, как я ожидал) и 38 закладок…
Пора, наверно, писать сказ о том, как я 200+ ежедневно запускаемых пауков на Scrapy писал — разлетится, как горячие пирожки, похоже.
Ах да, ещё тег «data science» нужно не забыть добавить. Я то думал, я какой-то фигнёй полтора года маюсь, а это «data science» была.
vchslv13
«Непонятно зачем, неизвестно на кой...»(с)
Автор, зачем Вы это написали? Во-первых, в интернете есть 100500 статей с описанием основ использования BS и Scrapy (включая официальную документацию). А во-вторых, это описание у Вас ещё и откровенно вредное, если говорить о Scrapy (хотя и не только).
Позвольте начать с вопроса о том, что это за фигня у Вас творится с питоньими структурами данных? В первом разделе Вы пишете «И создадим словарь» и тут же создаёте список. Дальше он у Вас таки стаёт словарём, но зачем? И на кой эта возня с индексом, если у питоньих списков есть метод append()?
«Можно все оформить как функцию» Какую к чёрту функцию, если это полноценный модуль?
Всё, что связано со Scrapy — это вообще жесть. Загляните, пожалуйста в официальную документацию, не поленитесь. И удалите всю эту байду, чтобы кто-то не напоролся на неё в качестве первого источника информации.
Вообще, мне кажется, что если Вы спрячете прямо сейчас эту статью в черновик навсегда, то для общего информационного пространства и для Хабра в частности это будет исключительно полезным действием.
afrikyan Автор
Комментатор, я думаю
Согласен, была опечатка. А насчет разницы между списками и словарями — разница как минимум в структурированности, это особенно может пригодится при больших объемах данных.— «In Python a function is defined using the def keyword». Две строки импорта библиотек указаны для удобства.
И в документацию Scrapy я заглядывал и в Python Web Scraping Cookbook — не волнуйтесь
Спасибо за Ваше мнение)
YourChief
При больших объёмах данных как раз лучше использовать наиболее компактную и подходящую по функциям структуру, а может даже вообще всю обработку выстроить цепью из генераторов. Ваш словарь с целочисленным индексом здесь ничем не оправдан.
Там где вы записываете результаты в словарь лучше и правда использовать список, а там где вы используете списки для сохранения троек результатов — лучше использовать кортеж (tuple) или даже именованный кортеж.
По самой содержательной части — да, это очередное весьма скудное руководство сразу по двум разным библиотекам, да ещё и без объяснений откуда что взялось и как был составлен этот XPath. Для новичков неполно, для бывалых скудно. По актуальности вторично, сейчас уже третий питон актуален, эффективные краулеры лучше писать на asyncio.
afrikyan Автор
Именованный действительно хорошо, но подключать еще модуль не хотелось)
Все библиотеки со ссылками, что на мой взгляд для глубокого изучения достаточно. Все описанное сделано в d 3.7
vchslv13
Разница между структурами данных состоит в структурированности… вроде и правда, но абсолютно ничего не объясняет. Допустим, что я тупой (это абсолютно валидное предположение учитывая мой небольшой возраст и опыт).
Объясните, пожалуйста, тупому, в чём преимущество использования словаря для хранения коллекции индексированных элементов и списка для хранения структурированных данных (это я о вместо какого-то ). В моём тупом мире всё происходит наоборот.