
В «Ростелекоме» мы используем Hadoop для хранения и обработки данных, загруженных из многочисленных источников с помощью java-приложений. Сейчас мы переехали на новую версию hadoop с Kerberos Authentication. При переезде столкнулись с рядом проблем, в том числе и с использованием YARN API. Работа Hadoop с Kerberos Authentication заслуживает отдельной статьи, а в этой мы поговорим об отладке Hadoop MapReduce.

При выполнении заданий в кластере запуск отладчика усложняется тем, что мы не знаем, какой узел будет обрабатывать ту или иную часть входных данных, и не можем заранее настроить свой отладчик.
Можно использовать проверенный временем
Мы можем выводить сообщения в стандартный поток ошибок. Все, что пишется в stdout или stderr,
направляется в соответствующий файл журнала, который можно найти на веб-странице расширенной информации о задаче или в журнальных файлах.
Мы также можем включить в код средство отладки, обновлять сообщения о состоянии задачи и использовать пользовательские счетчики, которые помогут нам понять масштаб бедствия.
Приложение Hadoop MapReduce можно отлаживать во всех трех режимах, в которых может работать Hadoop:
Более подробно мы остановимся на первых двух.
Псевдораспределенный режим используется для имитации реального кластера. И может использоваться для тестирования в среде, максимально приближенной к продуктивной. В данном режиме все демоны Hadoop будут работать на одном узле!
Если у вас есть dev-сервер или другая песочница (например, Virtual Machine с настроенной средой разработки, такой как Hortonworks Sanbox с HDP), то можно отладить управляющую программу, используя средства удаленной отладки (remote debugging).
Для запуска отладки нужно задать значение переменной окружения:
Теперь, запустив скрипт
Осталось настроить IDE для удаленной отладки (remote debugging). Я использую intellij IDEA. Перейдем в меню Run -> Edit Configurations… Добавим новую конфигурацию
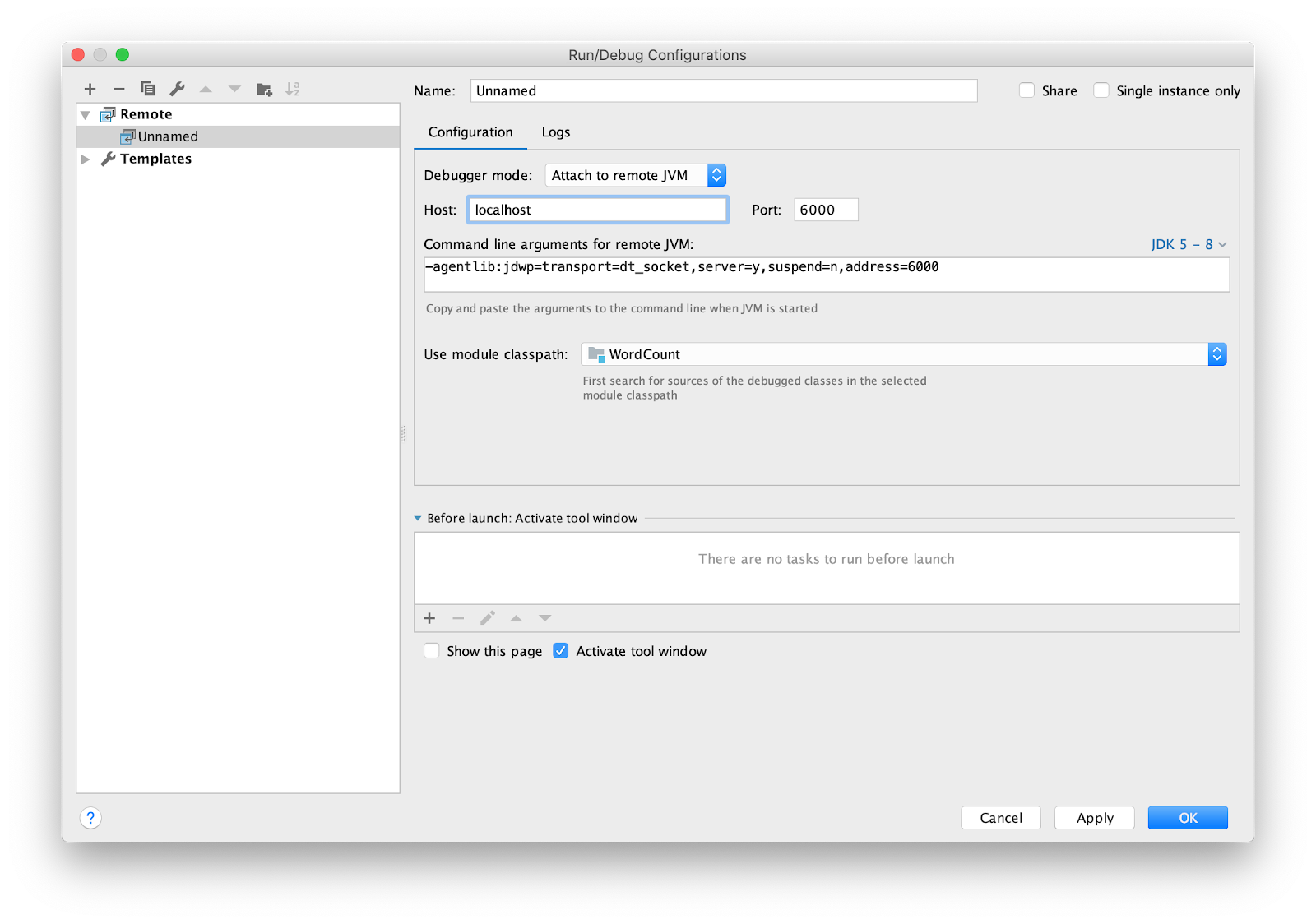
Поставим breakpoint в main и запустим.
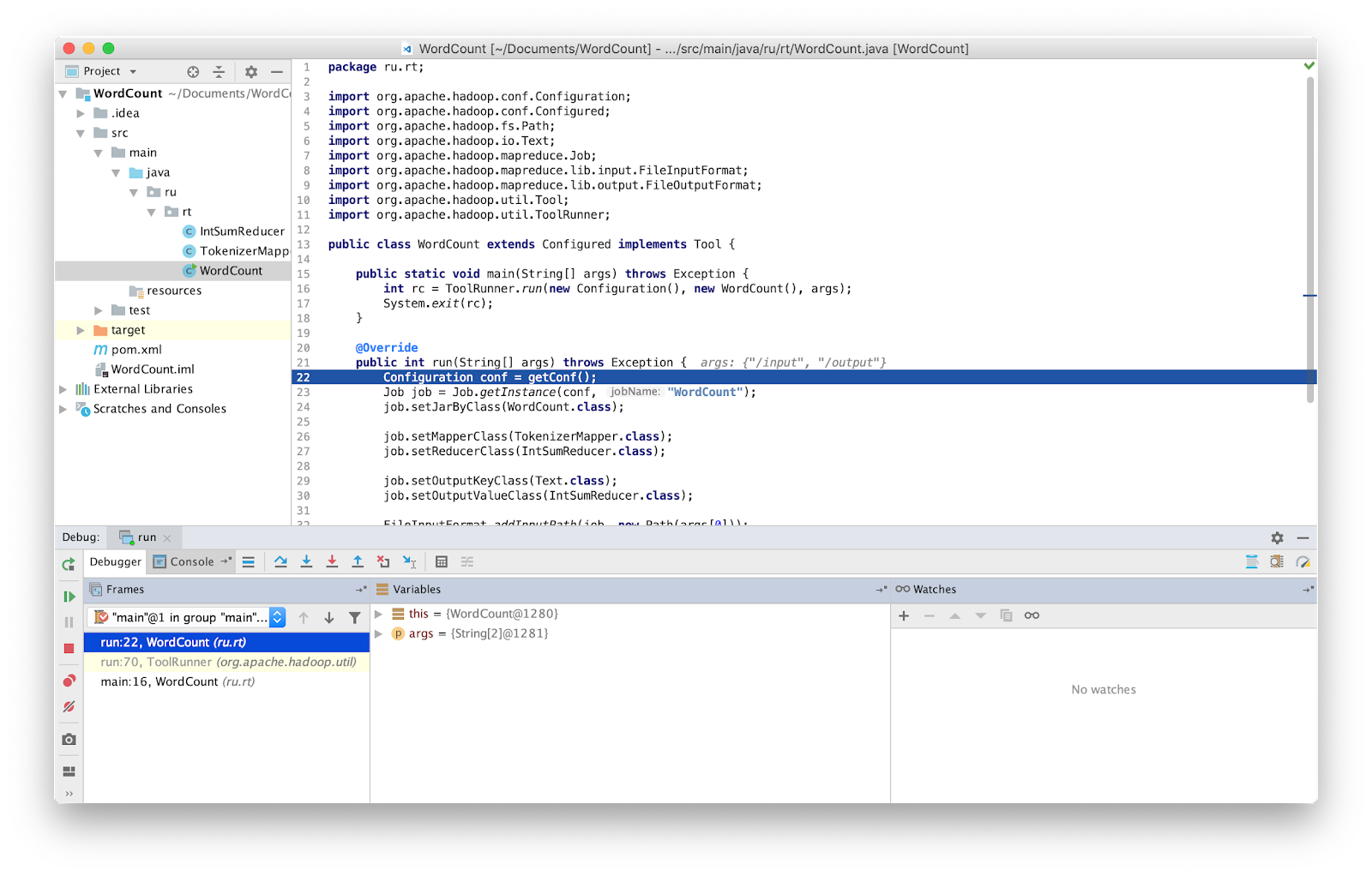
Все, теперь мы можем отлаживать программу как обычно.
В ранних версиях Hadoop поставлялся специальный класс, который позволял повторно запустить сбойное задание — isolationRunner. Данные, вызвавшие сбой, сохранялись на диск по адресу, указанному в переменной окружения Hadoop mapred.local.dir. К сожалению, в последних версиях Hadoop такой класс больше не поставляется.
Standalone — это стандартный режим, в котором работает Hadoop. Он подходит для отладки там, где не используется HDFS. При такой отладке можно использовать ввод и вывод через локальную файловую систему. Standalone-режим обычно является самым быстрым режимом Hadoop, так как он использует локальную файловую систему для всех входных и выходных данных.
Как упоминалось ранее, можно внедрить в код средство отладки, например, счетчики. Счетчики определяются перечислением (enum) Java. Имя перечисления определяет имя группы, а поля перечисления определяют имена счетчиков. Счетчик может пригодиться для оценки проблемы,
и может использоваться как дополнение к отладочному выводу.
Объявление и использование счетчика:
Для инкремента счетчика нужно использовать метод
После успешного завершения MapReduce задача в конце выводит значения счетчиков.
Ошибочные данные можно выводить в stderr или в stdout, или писать выходные данные в hdfs, используя класс
В Hadoop есть библиотека MRUnit, которая используется совместно с фреймворками тестирования (например, JUnit). При написании модульных тестов мы проверяем, что на выходе функция выдает ожидаемый результат. Мы используем класс MapDriver из пакета MRUnit, в свойствах которого устанавливаем тестируемый класс. Для этого используется метод
Вот наш тест.
Как следует из названия, это режим, в котором используется вся мощность Hadoop. Запущенная программа MapReduce может работать на 1000 серверов. Всегда сложно отлаживать программу MapReduce, так как у вас есть Mappers, работающие на разных машинах с разными входными данными.
Как оказалось, тестирование MapReduce не такая простая задача как кажется на первый взгляд.
Чтобы сэкономить время в поисках ошибки в MapReduce, я использовал все перечисленные методы и советую всем тоже их применять. Это особенно полезно в случае с большими инсталляциями, подобных таким, какие работают в «Ростелекоме».
При выполнении заданий в кластере запуск отладчика усложняется тем, что мы не знаем, какой узел будет обрабатывать ту или иную часть входных данных, и не можем заранее настроить свой отладчик.
Можно использовать проверенный временем
System.out.println("message"). Но как проанализировать вывод System.out.println("message") разбросанных по этим узлам?Мы можем выводить сообщения в стандартный поток ошибок. Все, что пишется в stdout или stderr,
направляется в соответствующий файл журнала, который можно найти на веб-странице расширенной информации о задаче или в журнальных файлах.
Мы также можем включить в код средство отладки, обновлять сообщения о состоянии задачи и использовать пользовательские счетчики, которые помогут нам понять масштаб бедствия.
Приложение Hadoop MapReduce можно отлаживать во всех трех режимах, в которых может работать Hadoop:
- standalone
- pseudo-distributed mode
- fully distributed
Более подробно мы остановимся на первых двух.
Pseudo-distributed mode (псевдораспределенный режим)
Псевдораспределенный режим используется для имитации реального кластера. И может использоваться для тестирования в среде, максимально приближенной к продуктивной. В данном режиме все демоны Hadoop будут работать на одном узле!
Если у вас есть dev-сервер или другая песочница (например, Virtual Machine с настроенной средой разработки, такой как Hortonworks Sanbox с HDP), то можно отладить управляющую программу, используя средства удаленной отладки (remote debugging).
Для запуска отладки нужно задать значение переменной окружения:
YARN_OPTS. Ниже приведен пример. Для удобства можно создать файл startWordCount.sh и добавить в него необходимые параметры для запуска приложения.#!/bin/bash
source /etc/hadoop/conf/yarn-env.sh
export YARN_OPTS='-agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=6000 ${YARN_OPTS}'
yarn jar wordcount-0.0.1.jar ru.rtc.example.WordCount /input /output
Теперь, запустив скрипт
`./startWordCount.sh`, мы увидим сообщениеListening for transport dt_socket at address: 6000
Осталось настроить IDE для удаленной отладки (remote debugging). Я использую intellij IDEA. Перейдем в меню Run -> Edit Configurations… Добавим новую конфигурацию
Remote.Поставим breakpoint в main и запустим.
Все, теперь мы можем отлаживать программу как обычно.
ВНИМАНИЕ. Вы должны убедиться, что работаете с последней версией исходного кода. Если нет, то у вас могут быть различия в строках, в которых отладчик выполняет остановку.
В ранних версиях Hadoop поставлялся специальный класс, который позволял повторно запустить сбойное задание — isolationRunner. Данные, вызвавшие сбой, сохранялись на диск по адресу, указанному в переменной окружения Hadoop mapred.local.dir. К сожалению, в последних версиях Hadoop такой класс больше не поставляется.
Standalone (локальный запуск)
Standalone — это стандартный режим, в котором работает Hadoop. Он подходит для отладки там, где не используется HDFS. При такой отладке можно использовать ввод и вывод через локальную файловую систему. Standalone-режим обычно является самым быстрым режимом Hadoop, так как он использует локальную файловую систему для всех входных и выходных данных.
Как упоминалось ранее, можно внедрить в код средство отладки, например, счетчики. Счетчики определяются перечислением (enum) Java. Имя перечисления определяет имя группы, а поля перечисления определяют имена счетчиков. Счетчик может пригодиться для оценки проблемы,
и может использоваться как дополнение к отладочному выводу.
Объявление и использование счетчика:
package ru.rt.example;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class Map extends Mapper<LongWritable, Text, Text, IntWritable> {
private Text word = new Text();
enum Word {
TOTAL_WORD_COUNT,
}
@Override
public void map(LongWritable key, Text value, Context context) {
String[] stringArr = value.toString().split("\\s+");
for (String str : stringArr) {
word.set(str);
context.getCounter(Word.TOTAL_WORD_COUNT).increment(1);
}
}
}
}
Для инкремента счетчика нужно использовать метод
increment(1)....
context.getCounter(Word.TOTAL_WORD_COUNT).increment(1);
...
После успешного завершения MapReduce задача в конце выводит значения счетчиков.
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
ru.rt.example.Map$Word
TOTAL_WORD_COUNT=655
Ошибочные данные можно выводить в stderr или в stdout, или писать выходные данные в hdfs, используя класс
MultipleOutputs для дальнейшего анализа. Полученные данные можно передавать на вход приложению в standalone режиме или при написании unit-тестов.В Hadoop есть библиотека MRUnit, которая используется совместно с фреймворками тестирования (например, JUnit). При написании модульных тестов мы проверяем, что на выходе функция выдает ожидаемый результат. Мы используем класс MapDriver из пакета MRUnit, в свойствах которого устанавливаем тестируемый класс. Для этого используется метод
withMapper(), входные значения withInputValue() и ожидаемый результат withOutput() или withMultiOutput(), если используется множественный вывод.Вот наш тест.
package ru.rt.example;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mrunit.mapreduce.MapDriver;
import org.apache.hadoop.mrunit.types.Pair;
import org.junit.Before;
import org.junit.Test;
import java.io.IOException;
public class TestWordCount {
private MapDriver<Object, Text, Text, IntWritable> mapDriver;
@Before
public void setUp() {
Map mapper = new Map();
mapDriver.setMapper(mapper)
}
@Test
public void mapperTest() throws IOException {
mapDriver.withInput(new LongWritable(0), new Text("msg1"));
mapDriver.withOutput(new Pair<Text, IntWritable>(new Text("msg1"), new IntWritable(1)));
mapDriver.runTest();
}
}
Fully distributed mode (полностью распределенный режим)
Как следует из названия, это режим, в котором используется вся мощность Hadoop. Запущенная программа MapReduce может работать на 1000 серверов. Всегда сложно отлаживать программу MapReduce, так как у вас есть Mappers, работающие на разных машинах с разными входными данными.
Заключение
Как оказалось, тестирование MapReduce не такая простая задача как кажется на первый взгляд.
Чтобы сэкономить время в поисках ошибки в MapReduce, я использовал все перечисленные методы и советую всем тоже их применять. Это особенно полезно в случае с большими инсталляциями, подобных таким, какие работают в «Ростелекоме».
Комментарии (5)

strongmonkey Автор
12.12.2018 20:49Я давно подумываю о том, чтобы научиться доставать это как-то через Yarn.
Было-бы интересно почитать про порты. Так то обычно я использую порт который мне дал администратор: )
sshikov
>с большими инсталляциями, подобных таким, какие работают в «Ростелекоме».
Из чистого любопытства — большими это сколько?
>suspend=y,address=6000
Я-я (нем). С большой вероятностью просто не запустится, скажет что порт занят. Или у вас недостаточно большой и нагруженный кластер ;) Например, Spark UI по умолчанию стартует с портом 4040, и если он занят — увеличивает номер порта на единицу. Так вот, у нас запуск на портах типа 4059 — совсем не редкость.
Я бы сказал, что для упрощения отладки MapReduce надо для начала перестать писать на MapReduce. И перейти на что-то более пригодное для целей тестирования, где маппер — это чистая функция, без примесей Hadoop API, которую можно протестировать автономно.
Apache Crunch тот же — намного удобнее уже, особенно с учетом того, что есть локальный режим запуска — один из трех штатных (включая Yarn и еще Spark), в котором как раз можно подцепиться отладчиком (конечно же, со всеми ограничениями такого режима). Ну и сам спарк в общем-то, в режиме --master local.
strongmonkey Автор
В конкретном примере я использовал sandbox на виртуальной машине и у меня был настроен порт 6000, на живом кластере это будет скорее всего другой порт.
Что на ваш взгляд более пригодное для тестирования?
Сменить вектор направления в большой копании не так просто, есть старый код который требует поддержки а переписовать на что то новое порой не хватает времени.
Хотя мысли попробовать spark посещают.
sshikov
>на живом кластере это будет скорее всего другой порт.
И к сожалению, возможно занятый. Так что выбор свободного порта (и способ донести знание о нем до отладчика) — это отдельная интересная тема. Я давно подумываю о том, чтобы научиться доставать это как-то через Yarn.
>Что на ваш взгляд более пригодное для тестирования?
Если вы хотите похожее на MapReduce? Я думаю что все-таки Crunch тут максимально близок. Spark — это уже более сильное изменение.
Но по сути… в общем-то там и там вы просто меняете класс mapper на экземпляр объекта, реализующий интерфейс типа mapper с одним методом T map(S source). Самое главное что в итоге вы эти экземпляры можете создавать и тестировать без фреймворка, потому что они к нему уже не привязаны совсем (максимум — будут Writable). В Spark в этой же роли например UDF, которые от Spark API тоже отвязаны, и тестируемы.
apanasenko
На много более простой способ написания больший и сложных job: github.com/twitter/scalding