

Это вторая часть серии по веб-безопасности: первая часть была «Как работают браузеры».
Как мы видели в предыдущей статье, браузеры взаимодействуют с веб-приложениями по протоколу HTTP, и это главная причина, по которой мы углубляемся в эту тему. Если пользователи введут данные своей кредитной карты на веб-сайте, а злоумышленник сможет перехватить данные до того, как они попадут на сервер, у нас наверняка будут проблемы.
Понимание того, как работает HTTP, как мы можем защитить связь между клиентами и серверами и какие функции, связанные с безопасностью, предлагает протокол, является первым шагом на пути к улучшению нашей безопасности.
При обсуждении HTTP, тем не менее, мы всегда должны различать семантику и техническую реализацию, поскольку это два совершенно разных аспекта работы HTTP.
Ключевое различие между ними можно объяснить очень простой аналогией: 20 лет назад люди заботились о своих родственниках так же, как и сейчас, даже при том, что способ их взаимодействия существенно изменился. Наши родители, вероятно, возьмут свою машину и поедут к сестре, чтобы наверстать упущенное и провести некоторое время вместе с семьей.
Вместо этого в наши дни чаще всего отправляют сообщения в WhatsApp, звонят по телефону или используют группу в Facebook, что раньше было невозможно. Это не значит, что люди общаются или заботятся больше или меньше, а просто то, что их взаимодействие изменилось.
HTTP ничем не отличается: семантика протокола не сильно изменилась, в то время как техническая реализация взаимодействия клиентов и серверов с годами была оптимизирована. Если вы посмотрите на HTTP-запрос 1996 года, он будет очень похож на те, что мы видели в предыдущей статье, хотя способ прохождения этих пакетов через сеть сильно отличается.
Обзор
Как мы уже видели, HTTP следует модели запроса/ответа, когда клиент, подключенный к серверу, отправляет запрос, а сервер отвечает на него.
HTTP-сообщение (запрос или ответ) состоит из нескольких частей:
- «first line» (первая строка)
- headers (заголовки запроса)
- body (тело запроса)
В запросе первая строка указывает метод, используемый клиентом, путь к ресурсу, который он хочет, а также версию протокола, который он собирается использовать:
GET /players/lebron-james HTTP/1.1В этом случае клиент пытается получить ресурс (
GET) по адресу /Players/Lebron-James через версию протокола 1.1 — ничего сложного для понимания.После первой строки HTTP позволяет нам добавлять метаданные к сообщению через заголовки, которые принимают форму ключ-значение, разделенных двоеточием:
GET /players/lebron-james HTTP/1.1
Host: nba.com
Accept: */*
Coolness: 9000Например, в этом запросе клиент добавил к запросу 3 дополнительных заголовка:
Host, Accept и Coolness.Подожди,
Coolness?!?!Заголовки не должны использовать определенные, зарезервированные имена, но обычно рекомендуется полагаться на те, которые стандартизированы в спецификации HTTP: чем больше вы отклоняетесь от стандартов, тем меньше вас поймет другой участник обмена.
Cache-Control — это, например, заголовок, используемый для определения того, является ли (и каким образом) ответ кешируемым: большинство прокси и обратных прокси понимают его, следуя спецификации HTTP до буквы. Если бы вам пришлось переименовать заголовок Cache-Control в Awesome-Cache-Control, прокси не имели бы представления о том, как кэшировать ответ, так как они не созданы для соответствия спецификации, которую вы только что придумали.Однако иногда имеет смысл включить в сообщение «пользовательский» заголовок, так как вы можете добавить метаданные, которые на самом деле не являются частью спецификации HTTP: сервер может решить включить техническую информацию в свой ответ, чтобы клиент мог одновременно выполнять запросы и получать важную информацию о состоянии сервера, который возвращает ответ:
...
X-Cpu-Usage: 40%
X-Memory-Available: 1%
...При использовании пользовательских заголовков всегда предпочтительно ставить перед ними префикс с ключом, чтобы они не конфликтовали с другими заголовками, которые могут стать стандартом в будущем: исторически это работало хорошо, пока все не начали использовать «нестандартные» префиксы
X что, в свою очередь, стало нормой. Заголовки X-Forwarded-For и X-Forwarded-Proto являются примерами пользовательских заголовков, которые широко используются и понимаются балансировщиками нагрузки и прокси-серверами, даже если они не являются частью стандарта HTTP.Если вам нужно добавить собственный настраиваемый заголовок, в настоящее время обычно лучше использовать фирменный префикс, такой как
Acme-Custom-Header или A-Custom-Header.После заголовков запрос может содержать тело, которое отделено от заголовков пустой строкой:
POST /players/lebron-james/comments HTTP/1.1
Host: nba.com
Accept: */*
Coolness: 9000
Best Player Ever
Наш запрос завершен: первая строка (информация о местоположении и протоколе), заголовки и тело. Обратите внимание, что тело является полностью необязательным и, в большинстве случаев, оно используется только тогда, когда мы хотим отправить данные на сервер, поэтому в приведенном выше примере используется метод
POST.Ответ сильно не имеет различий:
HTTP/1.1 200 OK
Content-Type: application/json
Cache-Control: private, max-age=3600
{"name": "Lebron James", "birthplace": "Akron, Ohio", ...}Первая информация, которая присылается в ответе, — это версия протокола, которую он использует, вместе со статусом этого ответа. Далее следуют заголовки и, если требуется, разрыв строки, за которым следует тело.
Как уже упоминалось, протокол подвергся многочисленным пересмотрам и со временем добавились новые функции (новые заголовки, коды состояния и т. д.), Но основная структура не сильно изменилась (первая строка, заголовки и тело). Что действительно изменилось, так это то, как клиенты и серверы обмениваются этими сообщениями — давайте рассмотрим это подробнее.
HTTP vs HTTPS vs H2
В HTTP произошли 2 значительных семантических изменения:
HTTP / 1.0 и HTTP / 1.1.«Где HTTPS и HTTP2?», Спросите вы.
HTTPS и HTTP2 (сокращенно H2) — это больше технических изменений, поскольку они представили новые способы доставки сообщений через Интернет, без существенного влияния на семантику протокола.
HTTPS является «безопасным» расширением HTTP и включает установление общего секретного ключа между клиентом и сервером, гарантируя, что мы общаемся с нужной стороной, и шифруем сообщения, которые обмениваются общим секретным ключом (подробнее об этом позже). Пока HTTPS был нацелен на повышение безопасности протокола HTTP, H2 был нацелен на обеспечение высокой скорости.
H2 использует двоичные, а не текстовые сообщения, поддерживает мультиплексирование, использует алгоритм HPACK для сжатия заголовков…… Короче говоря, H2 повышает производительность по HTTP/1.1.
Владельцы веб-сайтов неохотно переходили на HTTPS, так как это включало дополнительные обходы между клиентом и сервером (как уже упоминалось, необходимо установить общий секретный ключ между двумя сторонами), тем самым замедляя работу пользователя: с H2, который шифруется по умолчанию оправданий больше нет, так как такие функции, как мультиплексирование и server push, делают его лучше, чем простой HTTP/1.1.
HTTPS
HTTPS (HTTP Secure) позволяет клиентам и серверам безопасно общаться через TLS (Transport Layer Security), преемник SSL (Secure Socket Layer).
Проблема, на которую ориентирован TLS, довольно проста и может быть проиллюстрирована одной простой метафорой: ваша вторая половинка звонит вам в середине дня, когда вы находитесь на собрании, и просит вас сообщить им пароль учетной записи вашего онлайн-банкинга, поскольку она должна выполнить банковский перевод, чтобы обеспечить своевременную оплату за обучение вашего сына. Очень важно, чтобы вы сообщили об этом прямо сейчас, иначе вы столкнетесь с вероятностью того, что вашего ребенка отчислят из школы на следующее утро.
Теперь вы столкнулись с двумя проблемами:
- аутентификация (authentication) того, что вы действительно разговариваете со своей второй половинкой, поскольку это может быть кто-то, притворяющийся ей
- шифрование (encryption): передача пароля так, чтобы ваши коллеги не смогли его понять и записать
Что вы будете делать? Это именно та проблема, которую HTTPS пытается решить.
Чтобы проверить, с кем вы разговариваете, HTTPS использует Public Key Certificates(сертификаты открытых ключей), которые представляют собой не что иное, как сертификаты, указывающие личность конкретного сервера: когда вы подключаетесь через HTTPS к IP-адресу, сервер за этим адресом представляет вам его сертификат для вас, чтобы подтвердить свою личность. Возвращаясь к нашей аналогии, вы можете просто попросить свою вторую половинку сказать ваш номер социального страхования. Как только вы убедитесь, что номер правильный, вы получаете дополнительный уровень доверия.
Это, однако, не мешает «злоумышленникам» узнать номер социального страхования жертвы, украсть смартфон вашей второй половинки и позвонить вам. Как мы проверим личность звонящего?
Вместо того, чтобы прямо попросить свою вторую половинку написать свой номер социального страхования, вместо этого вы звоните своей маме (которая живет по соседству) и просите ее пойти в вашу квартиру и удостовериться, что именно ваша вторая половина говорит номер социального страхования. Это добавляет дополнительный уровень доверия, так как вы не считаете свою маму угрозой и полагаетесь на нее для проверки личности звонящего.
В терминах HTTPS ваша мама называется CA, сокращение от Certificate Authority: работа CA заключается в проверке личности конкретного сервера и выдаче сертификата с собственной цифровой подписью: это означает, что при подключении к определенному домену я получу не сертификат, сгенерированный владельцем домена (так называемый самоподписанный сертификат), а CA.
Задача CA состоит в том, что они проверяют подлинность домена и выдают сертификат соответствующим образом: когда вы «заказываете» сертификат (обычно называемый SSL-сертификатом, хотя в настоящее время вместо него используется TLS — названия действительно прилипают!), CA могут позвонить вам или попросить изменить настройку DNS, чтобы убедиться, что вы контролируете данный домен. После завершения процесса проверки он выдаст сертификат, который затем можно установить на веб-серверы.
Затем клиенты, такие как браузеры, будут подключаться к вашим серверам и получать этот сертификат, чтобы они могли проверить его подлинность: браузеры имеют своего рода «отношения» с CA, в том смысле, что они отслеживают список доверенных доменов в CA чтобы убедиться, что сертификат действительно заслуживает доверия. Если сертификат не подписан доверенным органом, браузер отобразит большое информационное предупреждение для пользователей:
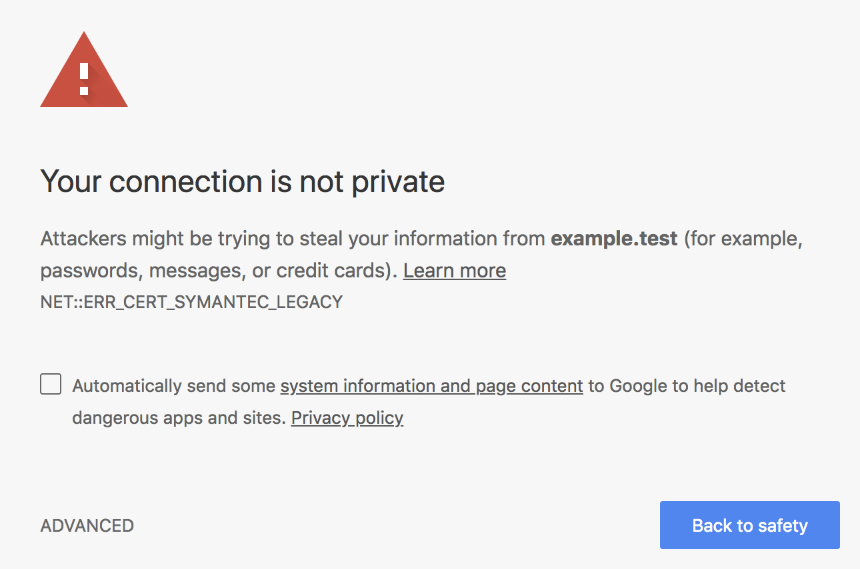
Мы на полпути к обеспечению связи между вами и вашей второй половиной: теперь, когда мы прошли аутентификацию (проверку личности вызывающего абонента), нам нужно убедиться, что мы можем общаться безопасно, без вмешательства других в процесс. Как я уже упоминал, вы находитесь прямо посреди собрания и вам нужно записать свой пароль для онлайн-банкинга. Вам нужно найти способ зашифровать ваше общение, чтобы только вы и ваша родственная душа могли понять ваш разговор.
Вы можете сделать это, установив общий секретный ключ между вами двумя и зашифровать сообщения с помощью этого ключа: например, вы можете использовать вариант шифра Цезаря, основанный на дате вашей свадьбы.

Это будет хорошо работать, если у обеих сторон есть установленные отношения, как у вас и вашей второй половинки, поскольку они могут создать ключ, основанный на общей памяти, о которой никто не знает. Браузеры и серверы, тем не менее, не могут использовать такой же механизм, поскольку они не знают друг друга заранее.
Вместо этого используются вариации протокола обмена ключами Диффи-Хеллмана, которые гарантируют, что стороны без предварительного знания устанавливают общий секретный ключ, и никто другой не сможет его «украсть». Это включает в себя использование математики.
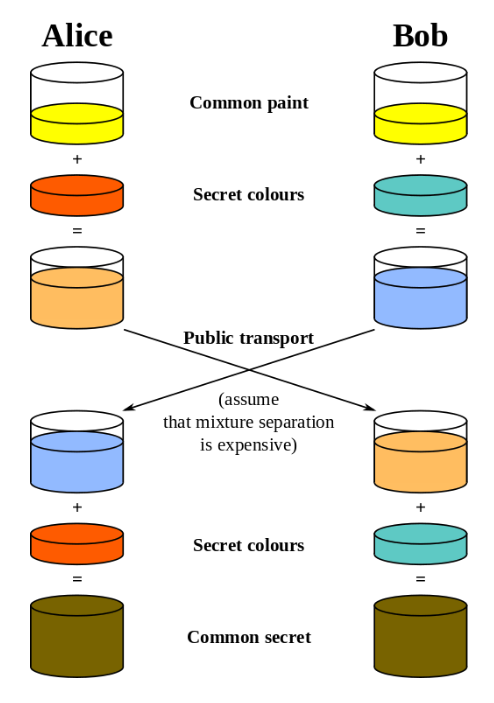
Как только секретный ключ установлен, клиент и сервер могут общаться, не опасаясь, что кто-то может перехватить их сообщения. Даже если злоумышленники сделают это, у них не будет общего секретного ключа, необходимого для расшифровки сообщений.
Для получения дополнительной информации о HTTPS и Diffie-Hellman я бы порекомендовал прочитать «Как HTTPS защищает соединения» Хартли Броди и «Как HTTPS на самом деле работает?» Роберта Хитона. Кроме того, в «Девяти алгоритмах, которые изменили будущее» есть удивительная глава, в которой объясняется шифрование с открытым ключом, и я горячо рекомендую его фанатам компьютерных наук, интересующимся оригинальными алгоритмами.
HTTPS везде
Все еще решаете, должны ли вы поддерживать HTTPS на вашем сайте? У меня для вас плохие новости: браузеры начали защищать пользователей от веб-сайтов, не поддерживающих HTTPS, для того, чтобы «заставить» веб-разработчиков предоставлять полностью зашифрованные возможности просмотра.
За девизом «HTTPS везде» браузеры начали выступать против незашифрованных соединений — Google был первым поставщиком браузеров, который дал веб-разработчикам крайний срок, объявив, что начиная с Chrome 68 (июль 2018 года) он будет отмечать веб-сайты HTTP как «небезопасные»:
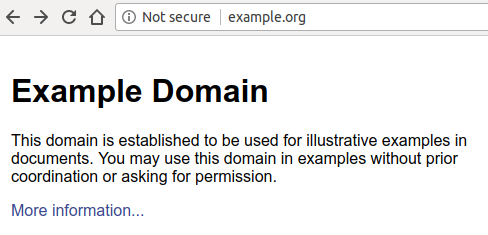
Еще более тревожным для веб-сайтов, не использующих преимущества HTTPS, является тот факт, что, как только пользователь вводит что-либо на веб-странице, метка «Небезопасно» становится красной — этот шаг должен побудить пользователей дважды подумать, прежде чем обмениваться данными с веб-сайтами, которые не поддерживает HTTPS.
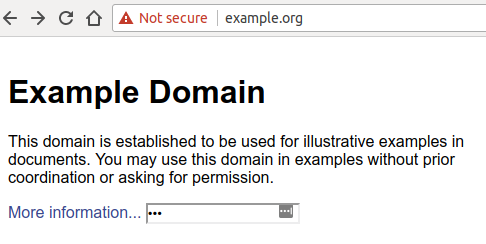
Сравните это с тем, как выглядит сайт, работающий по HTTPS и имеющий действующий сертификат:

Теоретически, веб-сайт не должен быть безопасным, но на практике это отпугивает пользователей — и это справедливо. В те времена, когда H2 не было реальностью, имело бы смысл придерживаться незашифрованного, простого HTTP-трафика. В настоящее время практически нет причин для этого. Присоединяйтесь к движению “HTTPS везде” и помогите сделать Интернет более безопасным местом для серфинга.
GET vs POST
Как мы видели ранее, HTTP-запрос начинается со своеобразной “первой строки”:
Прежде всего, клиент сообщает серверу, какие методы он использует для выполнения запроса: базовые HTTP-методы включают
GET, POST, PUT и DELETE, но список можно продолжить с менее распространенными (но все еще стандартными) методами, такими как TRACE, OPTIONS, или HEAD.Теоретически, ни один метод не безопаснее других; на практике все не так просто.
GET-запросы обычно не содержат тела, поэтому параметры включаются в URL (например,
www.example.com/articles?article_id=1), тогда как POST-запросы обычно используются для отправки («публикации») данных, которые включены в тело. Другое отличие заключается в побочных эффектах, которые несут эти методы: GET — идемпотентный метод, означающий, что независимо от того, сколько запросов вы отправите, вы не будете изменять состояние веб-сервера. Вместо этого POST не является идемпотентным: для каждого отправляемого вами запроса вы можете изменять состояние сервера (подумайте, например, о размещении нового платежа — теперь вы, вероятно, понимаете, почему сайты просят вас не обновлять страницу при выполнении сделки).Чтобы проиллюстрировать важное различие между этими методами, нам нужно взглянуть на журналы веб-серверов, с которыми вы, возможно, уже знакомы:
192.168.99.1 - [192.168.99.1] - - [29/Jul/2018:00:39:47 +0000] "GET /?token=1234 HTTP/1.1" 200 525 "-" "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36" 404 0.002 [example-local] 172.17.0.8:9090 525 0.002 200
192.168.99.1 - [192.168.99.1] - - [29/Jul/2018:00:40:47 +0000] "GET / HTTP/1.1" 200 525 "-" "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36" 393 0.004 [example-local] 172.17.0.8:9090 525 0.004 200
192.168.99.1 - [192.168.99.1] - - [29/Jul/2018:00:41:34 +0000] "PUT /users HTTP/1.1" 201 23 "http://example.local/" "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36" 4878 0.016 [example-local] 172.17.0.8:9090 23 0.016 201Как вы видите, веб-серверы регистрируют путь запроса: это означает, что, если вы включите конфиденциальные данные в свой URL-адрес, они будут пропущены веб-сервером и сохранены где-то в ваших журналах — ваши конфиденциальные данные будут где-то в открытом тексте, чего нам нужно полностью избежать. Представьте, что злоумышленник сможет получить доступ к одному из ваших старых файлов-журналов, который может содержать информацию о кредитной карте, токены доступа для ваших приватных сервисов и т. д., это будет полной катастрофой.
Веб-серверы не журнализируют HTTP-заголовки и тела, так как сохраняемые данные будут слишком объемными — именно поэтому отправка информации через тело запроса, а не по URL-адресу, как правило, безопаснее. Отсюда мы можем вывести, что
POST (и аналогичные неидемпотентные методы) безопаснее, чем GET, даже если это больше зависит от того, как данные отправляются при использовании определенного метода, а не от того, что конкретный метод по сути более безопасен, чем другие: если бы вы включили конфиденциальную информацию в тело запроса GET, то у вас не возникло бы больше проблем, чем при использовании POST, даже если такой подход был бы сочтен необычным.Мы верим в заголовки HTTP
В этой статье мы рассмотрели HTTP, его развитие и то, как его безопасное расширение объединяет аутентификацию и шифрование, чтобы позволить клиентам и серверам обмениваться данными через безопасный канал: это не все, что HTTP может предложить с точки зрения безопасности.
Перевод выполнен при поддержке компании EDISON Software, которая профессионально занимается безопасностью, а так же разрабатывает системы электронной медицинской проверки.
Комментарии (9)

funca
16.12.2018 21:53+1В http каждый запрос идеоматически не зависит от других. Это полезное во многих отношениях архитектурное свойство создает массу проблем при попытке отследить активности пользователей.
Время установки https соединения «на холодную» порядка 200ms, т.к. процесс обмена ключами не быстрый… Это довольно долго, по сравнению с http. Для того, чтобы уменьшить это время в ssl и tls был добавлен механизм сессионных ключей. Сайт.эффект в том, что теперь на сервере можно связвывать серию запросов гарантируя, что они пришли от одного клиента. h2 это способ решить ту же самую задачу, другим способом — завернуть всю сессию в одно соединение. На практике оба способа можно использовать вместе. Делает-ли это интернет более безопасным? Смотря для кого.
shpaker
16.12.2018 22:00+1GET — идемпотентный метод, означающий, что независимо от того, сколько запросов вы отправите, вы не будете изменять состояние веб-сервера
Вы серьёзно?
funca
16.12.2018 22:11На самом деле все примерно так и есть tools.ietf.org/html/rfc7231#section-4.2.2. Если сильно хочется можно придираться в цитируемой фразе к состоянию сервера. Так бывает, когда люди объясняют своими словами. Но на мой взгляд это больше похоже на придирку к словам.
shpaker
17.12.2018 12:26Конечно, я докопался до «состояния» сервера и именно поэтому эту фразу и процитировал в своём комментарии. Нет, про состояние и идемпотентность всё ок, меня скорее зацепило, что это в абзаце про GET. В реальной жизни GET не более идемпотентный, чем тот же POST, и выкатывать в статье такие перлы обозначает сразу рассказывать людям определенную «полуправду». Оно то вроде и да… но нет. И кстати, это перевод и соответственно про «объясняют своими словами» здесь не уместно. Посмотрел в ориганале, там также. Просто надо такие моменты раскрывать шире, а не провозюкивать вилами по воде в статье про «безопасность» для самых маленьких. И да, основы HTTP настолько заезжены в этом мире, что я не понимаю зачем стоило брать и тащить на хабр вот эту статью, а не взять бы и не написать что-то свое с меньшим количеством воды и с большим количеством деталей и с разбором потенциальных инцендентов.
funca
17.12.2018 22:05На заре карьеры сделал в админке удаление методом GET по ссылке ?action=delete. Мне казалось это решение безопасным. Через некоторое время клиент обнаружил отсутствие данных. Выяснилось, что какой то плагин браузера ходил по всем ссылкам, которые мог найти на странице. Поведение плагина было корректным. Так я открыл для себя удивительный мир архитектур http и rest. Рекомендую. Встречаются какие-то частные случаи, когда имплементация GET нарушает соглашения. Но это исключения, которые не заслуживают обобщений. В подавляющем большинстве случаев соглашения поддерживаются. Благодаря этому www продолжает функционировать.
shpaker
18.12.2018 09:52Спасибо за рекомендации, но боюсь, что без них как-нибудь проживу. Давайте не размазывать тему и если идёт обсуждения протокола не переходить на частные случаи. HTTP это не архитектура, это протокол. В RFC про то, что он должен быть идемпотентным скорее указано в качестве рекомендации, потому что технически ограничить его использование по сабжу невозможно. Кроме страничек по HTTP в своременном мире отдают и различные API и встречаются даже публичные сервисы которые позволяют (в подавляющем большинстве) по GET менять состояние сервиса. Например, у меня сейчас открыта вкладка с бот-API Телеграма и в нём все действия можно осуществлять как POST'ом, так и (о боже!) GET'ом — как яркий пример — отправка сообщения. И даже если отправлять сообщения в Телеграме через POST, то это никак не повлияет на безопасность, так как в URL-секции указывается приватный TOKEN. И тут мы можем наблюдать, что и URL тоже может содержать приватные данные, да и вообще безопасность сервиса от выбора HTTP-метода никак не зависит. И я уж не буду упоминать всякие интернал-сервисы и всякие штуки, которые можно встретить в энтерпрайзных системах в которых то что не обязатольно, то точно не обязательно и все рекомендации отправляются лесом…
То, что вы описали про плагин это не атака и не недостаток GET'а, а скорее две столкнувшиеся беды — криворукая реализация и кривой плагин. То есть эта та ситуация где ты сам себе злой буратино и это скорее подтерждает мои слова, что фраза в этой статье некорректна и GET чего только не может. Про REST тут не имеет смысла ничего писать, потому что он не имеет отношения к статье и о его недостатках можно говорить не меньше чем о его достоинствах. Я ещё раз уточню раз вам не понятно, о том, что мне не понравилось в посте. Там написано описание метода протокола, а не рекомендации по его использованию и указано, что GET всегда идемпотентен, что не правда и это даже вы сами подтвердили своим опытом со страницей с delete-ссылками. И это не недостаток данного перевода, а недостаток статьи оригинала. И всё бы ничего, если бы не было указано в заголовке статьи слов «Web Security». А security как раз заканчивается там, где под её соусом подают недостоверную информацию и у людей появляется иллюзия её наличия. И если начинающий разработчик-домохазяйка начнёт юзать GET'ы, думая что они не могут менять состояния сервиса, прочитав информацию в данной статье-руководстве, то последствия могут быть самыми разными.
saipr
И на ГОСТ-ах тоже.