
Давайте начнем серию статей по безопасности веб-приложений с объяснением того, что делают браузеры и как именно они это делают. Поскольку большинство ваших клиентов будут взаимодействовать с вашим веб-приложением через браузеры, необходимо понимать основы функционирования этих замечательных программ.
Chrome и lynx
Браузер — это движок рендеринга. Его работа заключается в том, чтобы загрузить веб-страницу и представить её в понятном для человека виде.
Хоть это и почти преступное упрощение, но пока это все, что нам нужно знать на данный момент.
Возможно, вы привыкли работать с одним из самых популярных браузеров, таких как Chrome, Firefox, Edge или Safari, но это не значит, что в мире нет других браузеров.
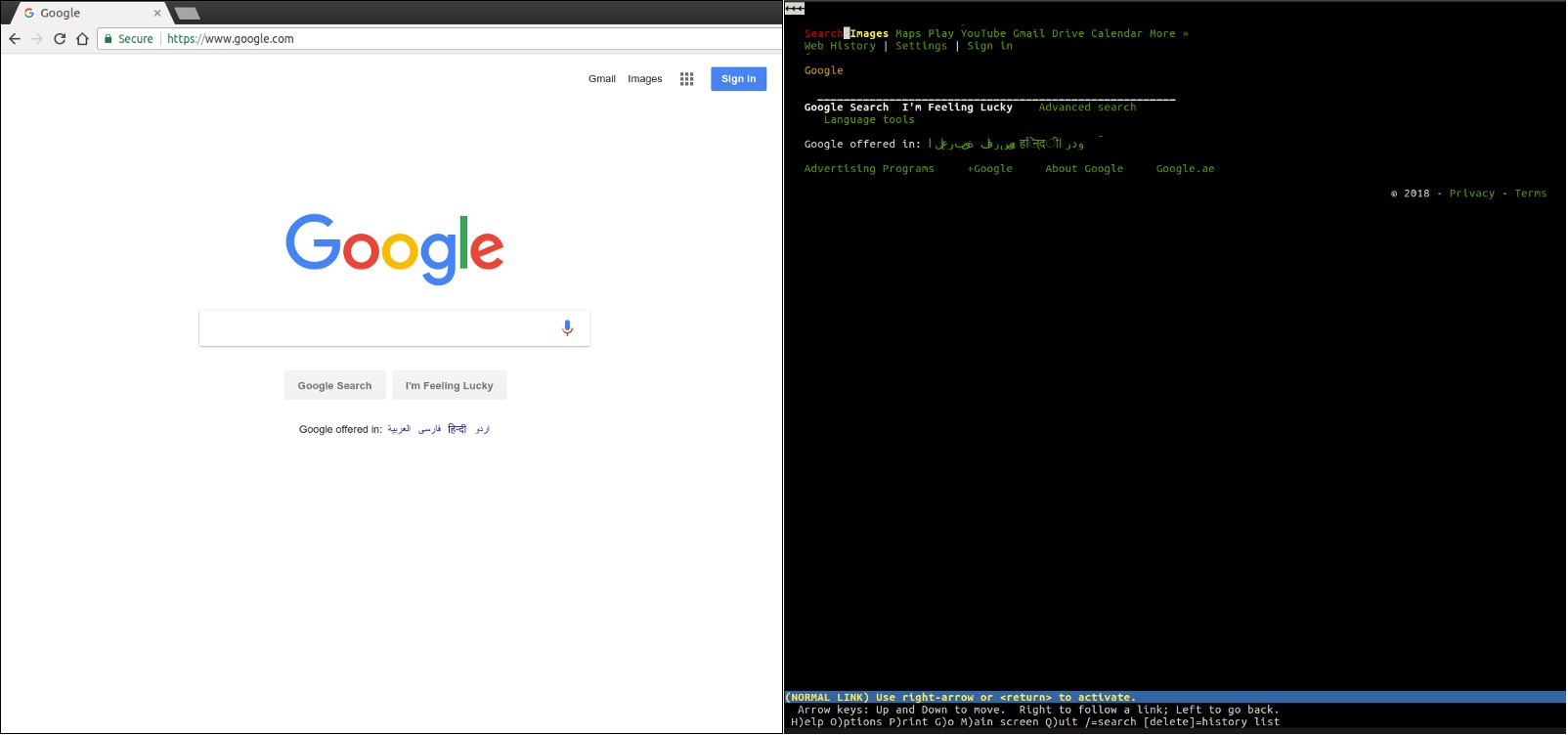
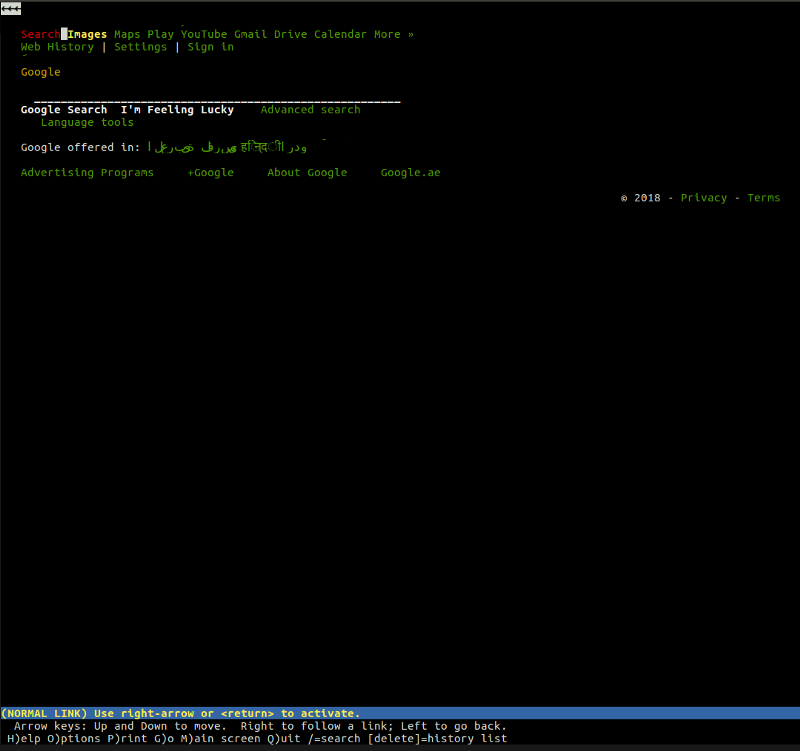
Например, lynx — это легкий текстовый браузер, работающий из командной строки. В основе lynx лежат те же самые принципы, которые вы найдете в любых других «мейнстримных» браузерах. Пользователь вводит веб-адрес (URL), браузер скачивает документ и отображает его — единственное отличие состоит в том, что lynx использует не движок графического рендеринга, а текстовый интерфейс, благодаря которому такие сайты, как Google, выглядят так:
Мы в целом имеем представление, что делает браузер, но давайте подробнее рассмотрим действия, которые эти гениальные приложения выполняют для нас.
Короче говоря, работа браузера в основном состоит из
Этот процесс помогает браузеру узнать, к какому серверу он должен подключиться, когда пользователь вводит URL. Браузер связывается с DNS-сервером и обнаруживает, что google.com соответствует набору цифр 216.58.207.110 — IP-адресу, к которому может подключиться браузер.
Как только браузер определит, какой сервер будет обслуживать наш запрос, он установит с ним TCP-соединение и начнет HTTP-обмен. Это не что иное, как способ общения браузера с нужным ему сервером, а для сервера — способ отвечать на запросы браузера.
HTTP — это просто название самого популярного протокола для общения в сети, и браузеры в основном выбирают HTTP при общении с серверами. HTTP-обмен подразумевает, что клиент (наш браузер) отправляет запрос, а сервер присылает ответ.
Например, после того, как браузер успешно подключится к серверу, обслуживающему google.com, он отправит запрос, который выглядит следующим образом
Давайте разберем запрос построчно:
После того, как браузер, выступающий в роли клиента, завершит выполнение своего запроса, сервер отправит ответ. Вот как выглядит ответ:
Воу, на этот раз довольно много информации, которую нужно переварить. Сервер сообщает нам, что запрос был выполнен успешно (200 OK) и добавляет к ответу несколько заголовков, из которых например, можно узнать, какой именно сервер обработал наш запрос (Server: gws), какова политика X-XSS-Protection этого ответа и так далее и тому подобное.
Прямо сейчас вам не нужно понимать каждую строку в ответе. Позже в этой серии публикации мы подробнее расскажем о протоколе HTTP, его заголовках и т. д.
На данный момент все, что вам нужно знать — это то, что клиент и сервер обмениваются информацией и что они делают это через HTTP-протокол.
Последним по счёту, но не последним по значению идет процесс рендеринга. Насколько хорош браузер, если единственное, что он покажет пользователю, это список забавных символов?
В теле ответа сервер включает представление запрашиваемого документа в соответствии с заголовком Content-Type. В нашем случае тип содержимого был установлен на text/html, поэтому мы ожидаем HTML-разметку в ответе — и именно ее мы и находим в теле документа.
Это как раз тот момент, где браузер действительно проявляет свои способности. Он считывает и анализирует HTML-код, загружает дополнительные ресурсы, включенные в разметку (например, там могут быть указаны для подгрузки JavaScript-файлы или CSS-документы) и представляет их пользователю как можно скорее.
Еще раз, конечным результатом должно стать то, что доступно для восприятия среднестатистического Васи.
Если вам нужно более детально объяснение того, что действительно происходит, когда мы нажимаем клавишу ввода в адресной строке браузера, я бы предложил прочитать статью «Что происходит, когда…», очень дотошную попытку объяснить механизмы, лежащие в основе этого процесса.
Поскольку это серия посвящена безопасности, я собираюсь дать подсказку о том, что мы только что узнали: злоумышленники легко зарабатывают на жизнь уязвимостями в части HTTP-обмена и рендеринга. Уязвимости, злонамеренные пользователи и прочие фантастические твари встречаются и в других местах, но более эффективный подход к обеспечению защиты именно на упомянутых уровнях уже позволяет вам добиваться успехов в улучшении вашего состояния безопасности.
4 самых популярных браузера принадлежат разным вендорам:
Помимо борьбы друг с другом, чтобы увеличить свое проникновение на рынок, поставщики также взаимодействуют друг с другом, чтобы улучшить веб-стандарты, которые являются своего рода «минимальными требованиями» для браузеров.
W3C является краеугольным камнем разработки стандартов, но браузеры нередко разрабатывают свои собственные функции, которые в конечном итоге превращаются в веб-стандарты, и безопасность тут не является исключением.
Например, в Chrome 51 были введены файлы cookie SameSite — функция, которая позволила веб-приложениям избавиться от определенного типа уязвимости, известной как CSRF (подробнее об этом позже). Другие производители решили, что это хорошая идея, и последовали ее примеру, что привело к тому, что подход SameSite стал веб-стандартом: на данный момент Safari является единственным крупным браузером без поддержки файлов cookie SameSite.

Это говорит нам о двух вещах:
Первый пункт — это выстрел в Safari (как я уже говорил, шучу!), а второй пункт действительно важен. При разработке веб-приложений нам нужно не только убедиться, что они выглядят одинаково в разных браузерах, но и обеспечить одинаковую защиту наших пользователей на разных платформах.
Ваша стратегия обеспечения безопасности в сети должна варьироваться в зависимости от того, какие возможности нам предоставляет вендор-поставщик браузера. В настоящее время большинство браузеров поддерживают один и тот же набор функций и редко отклоняются от своего общей дорожной карты, но случаи, подобные приведенному выше, все еще случаются, и это то, что мы должны учитывать при определении нашей стратегии безопасности.
В нашем случае, если мы решим, что будем нейтрализовывать атаки CSRF только с помощью файлов cookie SameSite, мы должны знать, что мы подвергаем риску наших пользователей Safari. И наши пользователи тоже должны это знать.
И последнее, но не менее важное: вы должны помнить, что вы можете решить, поддерживать ли версию браузера или нет: поддержка каждой версии браузера будет непрактичной (вспомните хпро Internet Explorer 6). Несмотря на это, уверенная поддержка нескольких последних версий основных браузеров — как правило, хорошее решение. Однако, если вы не планируете предоставлять защиту на какой-то определенной платформе, очень желательно, чтобы ваши пользователи об этом знали.
Тот факт, что обычный пользователь обращается к нашему приложению благодаря помощи стороннего клиентского программного обеспечения (браузера), добавляет еще один уровень, усложняющий путь к удобному и безопасному просмотру веб-страниц: сам браузер может быть источником уязвимости безопасности.
Вендоры, как правило, предоставляют вознаграждения (также известные как баг-баунти) исследователям безопасности, которые могут искать уязвимость в самом браузере. Эти ошибки связаны не с вашим веб-приложением, а с тем, как браузер самостоятельно управляет безопасностью.
Например, программа поощрений Chrome позволяет исследователям безопасности обращаться к команде безопасности Chrome, чтобы сообщить об обнаруженных ими уязвимостях. Если факт наличия уязвимости подтвердится, будет выпущено исправление и, как правило, опубликовано уведомление о безопасности, а исследователь получит (обычно финансовое) вознаграждение от программы.
Такие компании, как Google, инвестируют достаточно солидный капитал в свои программы Bug Bounty, поскольку это позволяет компаниям привлекать множество исследователей, обещая им финансовую выгоду в случае обнаружения ими каких-либо проблем с тестируемым программным обеспечением.
В программе Bug Bounty выигрывают все: поставщику удается повысить безопасность своего программного обеспечения, а исследователям платят за их находки. Мы обсудим эти программы позже, так как я считаю, что инициативы Bug Bounty заслуживают отдельного раздела в ландшафте аспектов безопасности.
К настоящему времени мы должны были понять очень простую, но довольно важную концепцию: браузеры — это всего лишь HTTP-клиенты, созданные для «усредненного» интернет-пользователя.
Браузеры определенно более мощны, чем простой HTTP-клиент для какой-либо платформы (например, вспомните, что у NodeJS есть зависимость от 'http'), но, в конце концов, они «просто» продукт естественной эволюции более простых HTTP-клиентов.
Что до разработчиков, нашим HTTP-клиентом, вероятно, является cURL от Daniel Stenberg, одна из самых популярных программ, которую веб-разработчики используют ежедневно. Она позволяет нам осуществлять HTTP-обмен на лету, отправляя HTTP-запрос из нашей командной строки:
В приведенном выше примере мы запросили документ по адресу localhost:8080/, и локальный сервер успешно на него ответил.
Вместо того, чтобы выгружать тело ответа в командную строку, мы использовали флаг -I, который сообщает cURL, что нас интересуют только заголовки ответа. Сделав еще шаг вперед, мы можем дать команду cURL выдавать немного больше информации, включая фактический запрос, который он выполняет, чтобы мы могли лучше изучить весь этот HTTP-обмен. Опция, которую мы должны использовать: -v (verbose, подробнее):
Примерно та же информация доступна в популярных браузерах посредством их DevTools.
Как мы уже видели, браузеры представляют собой не более чем сложные HTTP-клиенты. Конечно, они добавляют огромное количество функций (например, управление учетными данными, создание закладок, история и т. Д.), Но правда в том, что они были рождены как HTTP-клиенты для людей. Это важно, так как в большинстве случаев вам не нужен браузер для проверки безопасности вашего веб-приложения, когда вы можете просто «закурлить его» и посмотреть на ответ.
И последнее, что я хотел бы отметить: браузером может быть все, что угодно. Если у вас есть мобильное приложение, которое использует API-интерфейсы по протоколу HTTP, то такое приложение является вашим браузером — оно просто настроено вами по индивидуальному заказу, которое распознает только определенный тип HTTP-ответов (из вашего собственного API).
Как мы уже упоминали, что собираемся наиболее подробно осветить фазы HTTP-обмена и рендеринга, поскольку именно они предоставляют наибольшее количество векторов атак для злоумышленников.
В следующей статье мы более подробно рассмотрим протокол HTTP и попытаемся понять, какие меры мы должны предпринять для обеспечения безопасности HTTP-обмена.
Перевод выполнен при поддержке компании EDISON Software, которая профессионально занимается разработкой веб-сайтов для крупных заказчиков, а так же веб-разработкой на C# и .NET.
Chrome и lynx
Браузер — это движок рендеринга. Его работа заключается в том, чтобы загрузить веб-страницу и представить её в понятном для человека виде.
Хоть это и почти преступное упрощение, но пока это все, что нам нужно знать на данный момент.
- Пользователь вводит адрес в строке ввода браузера.
- Браузер загружает «документ» по этому URL и отображает его.
Возможно, вы привыкли работать с одним из самых популярных браузеров, таких как Chrome, Firefox, Edge или Safari, но это не значит, что в мире нет других браузеров.
Например, lynx — это легкий текстовый браузер, работающий из командной строки. В основе lynx лежат те же самые принципы, которые вы найдете в любых других «мейнстримных» браузерах. Пользователь вводит веб-адрес (URL), браузер скачивает документ и отображает его — единственное отличие состоит в том, что lynx использует не движок графического рендеринга, а текстовый интерфейс, благодаря которому такие сайты, как Google, выглядят так:
Мы в целом имеем представление, что делает браузер, но давайте подробнее рассмотрим действия, которые эти гениальные приложения выполняют для нас.
Что делает браузер?
Короче говоря, работа браузера в основном состоит из
- Разрешение DNS
- HTTP-обмен
- Рендеринг
- Сброс и повтор
Разрешение DNS
Этот процесс помогает браузеру узнать, к какому серверу он должен подключиться, когда пользователь вводит URL. Браузер связывается с DNS-сервером и обнаруживает, что google.com соответствует набору цифр 216.58.207.110 — IP-адресу, к которому может подключиться браузер.
HTTP-обмен
Как только браузер определит, какой сервер будет обслуживать наш запрос, он установит с ним TCP-соединение и начнет HTTP-обмен. Это не что иное, как способ общения браузера с нужным ему сервером, а для сервера — способ отвечать на запросы браузера.
HTTP — это просто название самого популярного протокола для общения в сети, и браузеры в основном выбирают HTTP при общении с серверами. HTTP-обмен подразумевает, что клиент (наш браузер) отправляет запрос, а сервер присылает ответ.
Например, после того, как браузер успешно подключится к серверу, обслуживающему google.com, он отправит запрос, который выглядит следующим образом
GET / HTTP/1.1
Host: google.com
AcceptДавайте разберем запрос построчно:
- GET / HTTP/1.1: этой первой строкой браузер просит сервер извлечь документ из месторасположения /, добавляя затем, что остальная часть запроса будет происходить по протоколу HTTP/1.1 (а можно так же использовать версию 1.0 или 2)
- Host: google.com: это единственный HTTP-заголовок, обязательный для протокола HTTP/1.1. Поскольку сервер может обслуживать несколько доменов (google.com, google.co.uk и т. д.), Клиент здесь упоминает, что запрос был для этого конкретного хоста.
- Accept: */*: необязательный заголовок, в котором браузер сообщает серверу, что он примет любой ответ. Сервер может иметь ресурс, доступный в форматах JSON, XML или HTML, поэтому он может выбирать любой формат, который предпочитает
После того, как браузер, выступающий в роли клиента, завершит выполнение своего запроса, сервер отправит ответ. Вот как выглядит ответ:
HTTP/1.1 200 OK
Cache-Control: private, max-age=0
Content-Type: text/html; charset=ISO-8859-1
Server: gws
X-XSS-Protection: 1; mode=block
X-Frame-Options: SAMEORIGIN
Set-Cookie: NID=1234; expires=Fri, 18-Jan-2019 18:25:04 GMT; path=/; domain=.google.com; HttpOnly
<!doctype html><html">
...
...
</html>Воу, на этот раз довольно много информации, которую нужно переварить. Сервер сообщает нам, что запрос был выполнен успешно (200 OK) и добавляет к ответу несколько заголовков, из которых например, можно узнать, какой именно сервер обработал наш запрос (Server: gws), какова политика X-XSS-Protection этого ответа и так далее и тому подобное.
Прямо сейчас вам не нужно понимать каждую строку в ответе. Позже в этой серии публикации мы подробнее расскажем о протоколе HTTP, его заголовках и т. д.
На данный момент все, что вам нужно знать — это то, что клиент и сервер обмениваются информацией и что они делают это через HTTP-протокол.
Рендеринг
Последним по счёту, но не последним по значению идет процесс рендеринга. Насколько хорош браузер, если единственное, что он покажет пользователю, это список забавных символов?
<!doctype html><html">
...
...
</html>В теле ответа сервер включает представление запрашиваемого документа в соответствии с заголовком Content-Type. В нашем случае тип содержимого был установлен на text/html, поэтому мы ожидаем HTML-разметку в ответе — и именно ее мы и находим в теле документа.
Это как раз тот момент, где браузер действительно проявляет свои способности. Он считывает и анализирует HTML-код, загружает дополнительные ресурсы, включенные в разметку (например, там могут быть указаны для подгрузки JavaScript-файлы или CSS-документы) и представляет их пользователю как можно скорее.
Еще раз, конечным результатом должно стать то, что доступно для восприятия среднестатистического Васи.
Если вам нужно более детально объяснение того, что действительно происходит, когда мы нажимаем клавишу ввода в адресной строке браузера, я бы предложил прочитать статью «Что происходит, когда…», очень дотошную попытку объяснить механизмы, лежащие в основе этого процесса.
Поскольку это серия посвящена безопасности, я собираюсь дать подсказку о том, что мы только что узнали: злоумышленники легко зарабатывают на жизнь уязвимостями в части HTTP-обмена и рендеринга. Уязвимости, злонамеренные пользователи и прочие фантастические твари встречаются и в других местах, но более эффективный подход к обеспечению защиты именно на упомянутых уровнях уже позволяет вам добиваться успехов в улучшении вашего состояния безопасности.
Вендоры
4 самых популярных браузера принадлежат разным вендорам:
- Chrome от Google
- Firefox от Mozilla
- Сафари от Apple
- Edge от Microsoft
Помимо борьбы друг с другом, чтобы увеличить свое проникновение на рынок, поставщики также взаимодействуют друг с другом, чтобы улучшить веб-стандарты, которые являются своего рода «минимальными требованиями» для браузеров.
W3C является краеугольным камнем разработки стандартов, но браузеры нередко разрабатывают свои собственные функции, которые в конечном итоге превращаются в веб-стандарты, и безопасность тут не является исключением.
Например, в Chrome 51 были введены файлы cookie SameSite — функция, которая позволила веб-приложениям избавиться от определенного типа уязвимости, известной как CSRF (подробнее об этом позже). Другие производители решили, что это хорошая идея, и последовали ее примеру, что привело к тому, что подход SameSite стал веб-стандартом: на данный момент Safari является единственным крупным браузером без поддержки файлов cookie SameSite.
Это говорит нам о двух вещах:
- Похоже, что Safari недостаточно заботится о безопасности своих пользователей (шучу: файлы cookie SameSite будут доступны в Safari 12, который, возможно, уже был выпущен к моменту прочтения этой статьи)
- исправление уязвимости в одном браузере не означает, что все ваши пользователи в безопасности
Первый пункт — это выстрел в Safari (как я уже говорил, шучу!), а второй пункт действительно важен. При разработке веб-приложений нам нужно не только убедиться, что они выглядят одинаково в разных браузерах, но и обеспечить одинаковую защиту наших пользователей на разных платформах.
Ваша стратегия обеспечения безопасности в сети должна варьироваться в зависимости от того, какие возможности нам предоставляет вендор-поставщик браузера. В настоящее время большинство браузеров поддерживают один и тот же набор функций и редко отклоняются от своего общей дорожной карты, но случаи, подобные приведенному выше, все еще случаются, и это то, что мы должны учитывать при определении нашей стратегии безопасности.
В нашем случае, если мы решим, что будем нейтрализовывать атаки CSRF только с помощью файлов cookie SameSite, мы должны знать, что мы подвергаем риску наших пользователей Safari. И наши пользователи тоже должны это знать.
И последнее, но не менее важное: вы должны помнить, что вы можете решить, поддерживать ли версию браузера или нет: поддержка каждой версии браузера будет непрактичной (вспомните хпро Internet Explorer 6). Несмотря на это, уверенная поддержка нескольких последних версий основных браузеров — как правило, хорошее решение. Однако, если вы не планируете предоставлять защиту на какой-то определенной платформе, очень желательно, чтобы ваши пользователи об этом знали.
Совет для профи: вы никогда не должны поощрять своих пользователей использовать устаревшие браузеры или активно поддерживать их. Даже если вы приняли все необходимые меры предосторожности, другие веб-разработчики этого не сделали. Поощряйте пользователей использовать последнюю поддерживаемую версию одного из основных браузеров.
Вендор или стандартный баг?
Тот факт, что обычный пользователь обращается к нашему приложению благодаря помощи стороннего клиентского программного обеспечения (браузера), добавляет еще один уровень, усложняющий путь к удобному и безопасному просмотру веб-страниц: сам браузер может быть источником уязвимости безопасности.
Вендоры, как правило, предоставляют вознаграждения (также известные как баг-баунти) исследователям безопасности, которые могут искать уязвимость в самом браузере. Эти ошибки связаны не с вашим веб-приложением, а с тем, как браузер самостоятельно управляет безопасностью.
Например, программа поощрений Chrome позволяет исследователям безопасности обращаться к команде безопасности Chrome, чтобы сообщить об обнаруженных ими уязвимостях. Если факт наличия уязвимости подтвердится, будет выпущено исправление и, как правило, опубликовано уведомление о безопасности, а исследователь получит (обычно финансовое) вознаграждение от программы.
Такие компании, как Google, инвестируют достаточно солидный капитал в свои программы Bug Bounty, поскольку это позволяет компаниям привлекать множество исследователей, обещая им финансовую выгоду в случае обнаружения ими каких-либо проблем с тестируемым программным обеспечением.
В программе Bug Bounty выигрывают все: поставщику удается повысить безопасность своего программного обеспечения, а исследователям платят за их находки. Мы обсудим эти программы позже, так как я считаю, что инициативы Bug Bounty заслуживают отдельного раздела в ландшафте аспектов безопасности.
Джейк Арчибальд (Jake Archibald) — разработчик-"адвокат" в Google, который обнаружил уязвимость, затрагивающую несколько браузеров. Он задокументировал свои усилия по ее обнаружению, процесс обращения к различным вендорам, затронутым уязвимостью, и реакцию представителей вендоров в интересном блог-посте, который я рекомендую вам прочитать.
Браузер для разработчиков
К настоящему времени мы должны были понять очень простую, но довольно важную концепцию: браузеры — это всего лишь HTTP-клиенты, созданные для «усредненного» интернет-пользователя.
Браузеры определенно более мощны, чем простой HTTP-клиент для какой-либо платформы (например, вспомните, что у NodeJS есть зависимость от 'http'), но, в конце концов, они «просто» продукт естественной эволюции более простых HTTP-клиентов.
Что до разработчиков, нашим HTTP-клиентом, вероятно, является cURL от Daniel Stenberg, одна из самых популярных программ, которую веб-разработчики используют ежедневно. Она позволяет нам осуществлять HTTP-обмен на лету, отправляя HTTP-запрос из нашей командной строки:
$ curl -I localhost:8080
HTTP/1.1 200 OK
server: ecstatic-2.2.1
Content-Type: text/html
etag: "23724049-4096-"2018-07-20T11:20:35.526Z""
last-modified: Fri, 20 Jul 2018 11:20:35 GMT
cache-control: max-age=3600
Date: Fri, 20 Jul 2018 11:21:02 GMT
Connection: keep-aliveВ приведенном выше примере мы запросили документ по адресу localhost:8080/, и локальный сервер успешно на него ответил.
Вместо того, чтобы выгружать тело ответа в командную строку, мы использовали флаг -I, который сообщает cURL, что нас интересуют только заголовки ответа. Сделав еще шаг вперед, мы можем дать команду cURL выдавать немного больше информации, включая фактический запрос, который он выполняет, чтобы мы могли лучше изучить весь этот HTTP-обмен. Опция, которую мы должны использовать: -v (verbose, подробнее):
$ curl -I -v localhost:8080
* Rebuilt URL to: localhost:8080/
* Trying 127.0.0.1...
* Connected to localhost (127.0.0.1) port 8080 (#0)
> HEAD / HTTP/1.1
> Host: localhost:8080
> User-Agent: curl/7.47.0
> Accept: */*
>
< HTTP/1.1 200 OK
HTTP/1.1 200 OK
< server: ecstatic-2.2.1
server: ecstatic-2.2.1
< Content-Type: text/html
Content-Type: text/html
< etag: "23724049-4096-"2018-07-20T11:20:35.526Z""
etag: "23724049-4096-"2018-07-20T11:20:35.526Z""
< last-modified: Fri, 20 Jul 2018 11:20:35 GMT
last-modified: Fri, 20 Jul 2018 11:20:35 GMT
< cache-control: max-age=3600
cache-control: max-age=3600
< Date: Fri, 20 Jul 2018 11:25:55 GMT
Date: Fri, 20 Jul 2018 11:25:55 GMT
< Connection: keep-alive
Connection: keep-alive
<
* Connection #0 to host localhost left intactПримерно та же информация доступна в популярных браузерах посредством их DevTools.
Как мы уже видели, браузеры представляют собой не более чем сложные HTTP-клиенты. Конечно, они добавляют огромное количество функций (например, управление учетными данными, создание закладок, история и т. Д.), Но правда в том, что они были рождены как HTTP-клиенты для людей. Это важно, так как в большинстве случаев вам не нужен браузер для проверки безопасности вашего веб-приложения, когда вы можете просто «закурлить его» и посмотреть на ответ.
И последнее, что я хотел бы отметить: браузером может быть все, что угодно. Если у вас есть мобильное приложение, которое использует API-интерфейсы по протоколу HTTP, то такое приложение является вашим браузером — оно просто настроено вами по индивидуальному заказу, которое распознает только определенный тип HTTP-ответов (из вашего собственного API).
Погружение в протокол HTTP
Как мы уже упоминали, что собираемся наиболее подробно осветить фазы HTTP-обмена и рендеринга, поскольку именно они предоставляют наибольшее количество векторов атак для злоумышленников.
В следующей статье мы более подробно рассмотрим протокол HTTP и попытаемся понять, какие меры мы должны предпринять для обеспечения безопасности HTTP-обмена.
Перевод выполнен при поддержке компании EDISON Software, которая профессионально занимается разработкой веб-сайтов для крупных заказчиков, а так же веб-разработкой на C# и .NET.
Germanjon
Это не совсем задача браузера. Браузер вполне может открывать сайты и страницы вида 192.168.1.2/homepage.html
PastorGL
А вот разработчики Firefox с вами по данному вопросу не согласятся, и прилагают в комплекте своего браузера несколько вариантов резолверов DNS. Безопасность, и всё такое.