
Разные помощники в написании классного кода нас просто окружают, линтеры, тайпчекеры, утилиты для поиска уязвимостей, всё с нами. Мы привыкли и используем не вдаваясь в детали, как «черный ящик». Например, мало кто разбирается в принципах работы Pylint — одного из таких незаменимых инструментов для оптимизации и улучшения кода на Python.
А вот Максим Мазаев знает, насколько важно понимать свои инструменты, и нам рассказал на Moscow Python Conf++. На реальных примерах показал, как знание внутреннего устройства Pylint и его плагинов помогло уменьшить время code review, улучшить качество кода и вообще повысить эффективность разработки. Ниже расшифровка-инструкция.

Зачем нам Pylint?
Если вы его уже используете, то может возникнуть вопрос: «Зачем знать, что внутри у Pylint, чем эти знания могут помочь?»
Обычно разработчики пишут код, запускают линтер, получают сообщения о том, что улучшить, как сделать код более красивым, и вносят предложенные изменения. Теперь код удобнее читать и не стыдно показать коллегам.
Долгое время и в ЦИАН именно так работали с Pylint, с небольшими дополнениями: меняли конфигурации, убирали лишние правила, увеличили максимальную длину строки.
Но в какой-то момент столкнулись с проблемой, для решения которой, пришлось копнуть глубоко внутрь Pylint и разобраться, как он работает. Что это за проблема и как ее решили, читайте дальше.
О спикере: Максим Мазаев (backslash), 5 лет в разработке, работает в ЦИАН. Глубоко изучает Python, асинхронность и функциональное программирование.
О ЦИАН
Большинство считает, что ЦИАН — это агентство недвижимости с риелторами и очень удивляются, когда узнают, что вместо риэлторов у нас работают программисты.
Мы — техническая компания, в которой нет риелторов, зато очень много программистов.
Каждый день в продакшн выезжают сотни и тысячи строк нового кода. Требования для кода довольно просты:
Чтобы этого добиться, конечно, нужен code review.
Code review
Code review в ЦИАН проходит в два этапа:
Pull request может не пройти code review из-за:
Какие могут быть проблемы со стилем, если линтер проверяет код?
Все кто пишет на Python знают, что существует руководство по написанию кода РЕР-8. Как любой стандарт, PEP-8 довольно общий и нам, как разработчикам, этого недостаточно. Стандарт хочется в одних местах конкретизировать, а в других расширить.
Поэтому мы придумали свои внутренние договоренности о том, как код должен выглядеть и работать, и назвали их «Decline Cian Proposals».
«Decline Cian Proposals» — набор правил, сейчас их примерно 15. Каждое из этих правил — основание, чтобы pull request был отклонен и отправлен на доработку.
Что мешает продуктивному code review?
Создается проблема и для разработчика и для проверяющих. В результате критически снижается скорость code review. Вместо того, чтобы анализировать логику кода, проверяющие начинают анализировать визуальный стиль, то есть выполняют работу линтера: сканируют код по строчкам и ищут несоответствия в отступах, в формате импортов.
От этой проблемы нам бы хотелось избавиться.
А не написать ли нам свой линтер?
Кажется, что проблему решит инструмент, который будет знать про все внутренние договоренности и сможет проверять код на их выполнение. Получается нам нужен свой линтер?
На самом деле нет. Идея дурацкая, потому что у нас уже используется Pylint. Это удобный линтер, нравится разработчикам и встроен во все процессы: запускается в Jenkins, генерирует красивые отчеты, которые полностью устраивают и в виде комментариев приезжают в pull request. Все отлично, второй линтер не нужен.
Так как решить проблему, если свой линтер мы писать не хотим?
Написать плагин для Pylint
Для Pylint можно написать плагины, они называются чекерами. Под каждое внутреннее правило можно написать свой чекер, который будет его проверять.
Рассмотрим два примера подобных чекеров.
Пример № 1
В какой-то момент обнаружилось, что в коде много комментариев вида «TODO» — обещаний отрефакторить, удалить ненужный код или переписать его красиво, но не сейчас, а позже. С подобными комментариями есть проблема — они совершенно ни к чему не обязывают.
Проблема
Разработчик написал обещание, выдохнул и пошел со спокойной душой заниматься следующей задачей.
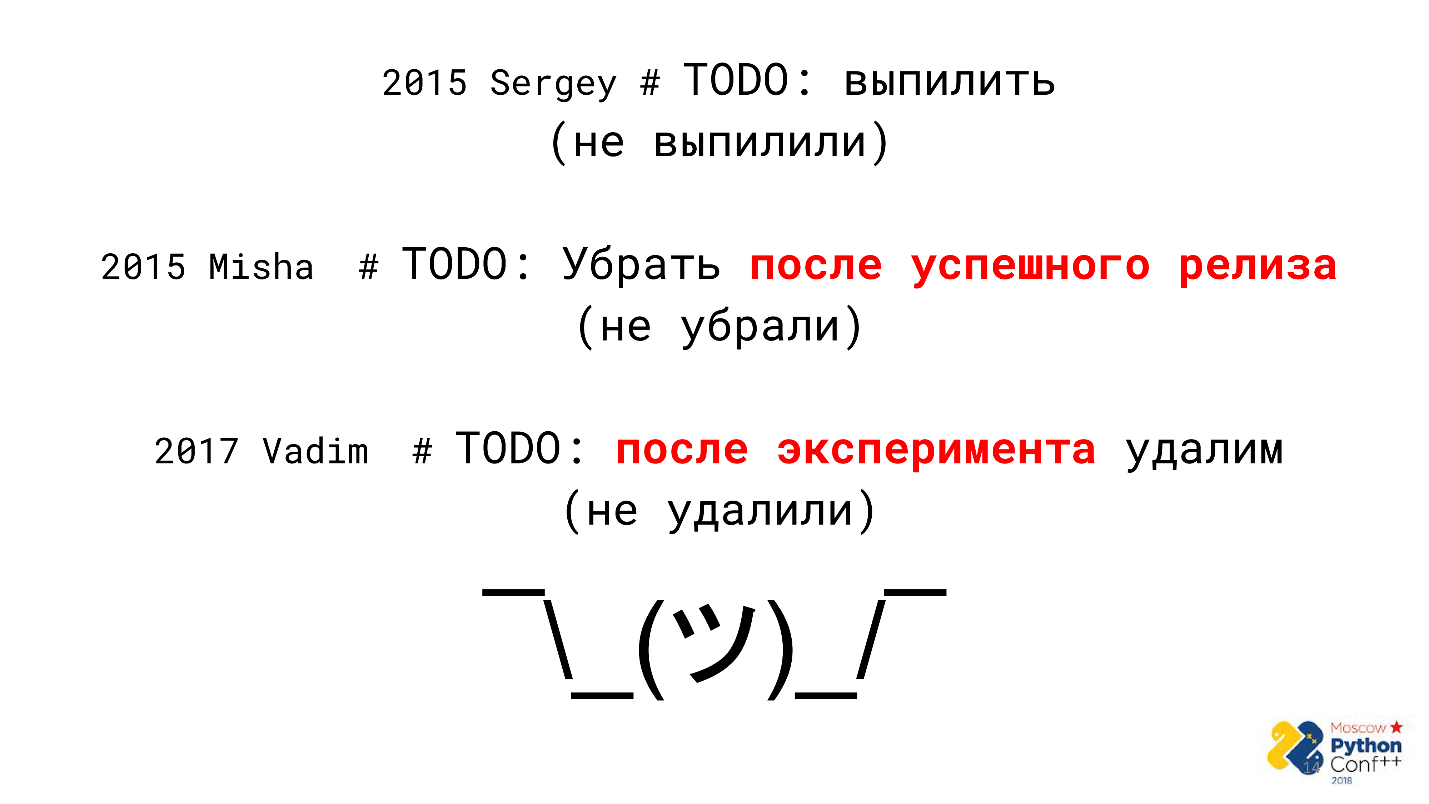
В итоге:
Например, разработчик 3 года назад обещал что-то убрать после успешного релиза, а случился ли релиз за 3 года? Возможно, что да. Удалить ли код в этом случае? Это большой вопрос, но, скорее всего, нет.
Решение: пишем свой чекер для Pylint
Нельзя запретить разработчикам писать подобные комментарии, но можно заставить сделать дополнительную работу: создать в трекере задачу на доработку обещания. Тогда мы точно про нее не забудем.
Нам нужно найти все комментарии вида TODO и убедиться, что в каждом из них есть ссылка на задачу в Jira. Давайте писать.
Что такое чекер с точки зрения Pylint? Это класс, который наследуется от базового класса чекера и имплементирует некий интерфейс.
В нашем случае это IRawChecker — так называемый «сырой» чекер.
«Сырой» чекер итерируется по строкам файла и над строкой может выполнить определенное действие. В нашем случае в каждой строке чекер будет искать нечто похожее на комментарий и ссылку на задачу.
Для чекера нужно определить список сообщений, которые он будет выдавать:
В сообщении есть:
Код сообщения имеет вид «С1234», в котором:
Код нужен, чтобы отключить проверку, если она станет не нужна. Можно написать Pylint: disable и короткий буквенно-цифровой код или мнемоническое название:
Авторы Pylint рекомендуют отказаться от буквенно-цифрового кода и использовать мнемонический, он более наглядный.
Следующий шаг — определить метод, который называется process_module.

Название очень важно. Метод должен называться именно так, потому что Pylint потом будет его вызывать.
В модуль передается параметр node. В данном случае неважно, что это такое и какого он типа, важно только помнить, что у node есть метод stream, который возвращает файл построчно.
По файлу можно пройтись и для каждой строчки проверить наличие комментариев и ссылки на задачу. Если комментарий есть, а ссылки нет, то выбросить предупреждение вида ’issue-code-in-todo’ с кодом чекера и номером строки. Алгоритм достаточно простой.
Регистрируем чекер, чтобы Pylint о нем знал. Это делается функцией register:
Важный, момент: модуль чекера должен лежать в PYTHONPATH, чтобы Pylint мог потом его импортировать.
Зарегистрированный чекер проверяется тестовым файлом с комментариями без ссылок на задачи.
Для теста запускаем Pylint, передаем в него модуль, с помощью параметра load-plugins передаем чекер, и внутри линтера запускаем две фазы.
Фаза 1. Инициализация плагинов
Фаза 2. Разбираем пул чекеров
После фазы 1 остается целый список чекеров разных типов:

Из списка выделяем те, что относятся к интерфейсу «сырого» чекера: смотрим какие чекеры имплементируют интерфейс IRawChecker и берем их себе.
Для каждого отобранного чекера вызываем метод checker.process_module(module), и запускаем проверку.
Результат
Снова запускаем чекер на тестовом файле:
Появится сообщение о том, что есть комментарий с TODO и нет ссылки на задачу.
Проблема решена и теперь в процессе code review разработчикам не нужно сканировать код глазами, находить комментарии, писать автору кода напоминание, что есть договоренность и желательно оставить ссылку. Всё происходит автоматизировано и code review проходит чуть быстрее.
Пример № 2. keyword-arguments
Есть функции, которые принимают позиционные аргументы. Если аргументов достаточно много, то при их вызове функции не очень понятно, где какой аргумент и зачем он нужен.
Проблема
Например, у нас есть функция:
В коде есть sale и True и непонятно, что они означают. Гораздо удобнее, когда функции, в которых много аргументов, вызывались бы только с именованными аргументами:
Это хороший код, в котором сразу понятно, где какой параметр и мы не перепутаем их последовательность. Попробуем написать чекер, который проверяет подобные кейсы.
«Сырой» чекер, использовавшийся в предыдущем примере, для такого случая написать очень сложно. Можно добавить супер-сложные регулярные выражения, но такой код тяжело читать. Хорошо, что Pylint дает возможность написать другой тип чекера на основе абстрактного синтаксического дерева AST, его и будем использовать.
Лирическое отступление про AST
AST или абстрактное синтаксическое дерево — это представление кода в виде дерева, где вершина — операнды, а листья — операторы.
Например, вызов функции, где есть один позиционный аргумент и два именованных, трансформируется в абстрактное дерево:

Здесь есть вершина с типом Call и она имеет:
Задача в данном случае:
С точки зрения Pylint, чекер на основе AST — это класс, который наследуется от класса базового чекера и имплементирует интерфейс IAstroidChecker:
Как и в первом примере, в списке сообщений указывается описание чекера, код сообщения, короткое мнемоническое название:
Следующий шаг — определяется метод visit_call:
Метод не обязательно должен так называться. Самое главное в нем — префикс visit_, а дальше идет имя вершины, которая нас интересует, с маленькой буквы.
В данном примере метод visit_call получит на вход ноду с типом Call и посмотрит, есть ли у нее больше двух аргументов и присутствуют ли позиционные аргументы, чтобы выбросить предупреждение и передать туда код и саму ноду.
Регистрируем чекер, как в предыдущем примере: передаем экземпляр Pylint, вызываем register_checker, передавая сам чекер и запускаем.
Это пример вызова тестовой функции, где есть 3 аргумента и только один из них именованный:
Это функция, которая потенциально вызывается неправильно с нашей точки зрения. Запускаем Pylint.
Фаза 1 инициализации плагинов полностью повторяется, как и в предыдущем примере.
Фаза 2. Разбор модуля на AST
Код разбирается в AST-дерево. Разбор выполняет библиотека Astroid.
Почему Astroid, а не AST (stdlib)
Astroid внутри себя использует не стандартный модуль Python AST, а типизированный AST-парсер typed_ast, отличающийся тем, что поддерживает тайпхинты из РЕР 484. Typed_ast — это ответвление AST, форк, который развивается параллельно. Что интересно, там присутствуют те же баги, что в AST, и чинятся параллельно.
Раньше Astroid использовал стандартный AST-модуль, в котором можно было столкнуться с проблемой использования тайпхинтов, определенных в комментариях, которые используются во втором Python. Если проверить такой код через Pylint, то до определенного момента он ругался на неиспользованный импорт, потому что импортированный класс Entity присутствует только в комментарии.
Работа закипела! Прошло 2 года, этой весной Pylint уже перешел на типизированный AST-парсер и перестал ругаться на такие вещи. Импорты для тайпхинтов больше не помечаются как неиспользуемые.
Astroid использует AST-парсер, чтобы разобрать код на дерево, а потом при сборке делает некоторые интересные вещи. Например, если вы используете import *, то он импортирует все, что по звездочке, и добавит в locals, чтобы предотвратить ошибки с неиспользованными импортами.
Transform plugins используются в случаях, когда есть какие-то сложные модели, основанные на мета-классах, когда все атрибуты генерируются динамически. В этом случае Astroid очень сложно понять, что подразумевается. При проверке Pylint будет ругаться, что в моделях нет такого атрибута, когда к нему обращаются, а с помощью Transform plugins можно решить проблему:
Характерный пример — pylint-django. При работе со сложными django-моделями линтер часто ругается на неизвестные атрибуты. Pylint-django как раз решает эту проблему.
Фаза 3. Разбираем пул чекеров
Возвращаемся к чекеру. У нас снова есть список чекеров, из которых мы находим те, что имплементируют интерфейс AST checker.
Фаза 4. Разбираем чекеры по типам нод
Дальше у каждого чекера находим методы, они могут быть двух типов:
Было бы неплохо во время хождения по дереву знать, для какой ноды какие чекеры нужно вызвать. Поэтому они разбираются в словарь, где ключ — это имя ноды, значение — это список тех чекеров, которым важен факт захода на эту ноду.
То же самое с leave-методами: ключ в виде имени ноды, список чекеров, которым интересен факт выхода с этой ноды.
Запускаем Pylint. Он показывает предупреждение, что у нас есть функция, где больше двух аргументов и в ней присутствует позиционный аргумент:
Проблема решена. Теперь программистам на code review не нужно считать аргументы у функции, за них это сделает линтер. Мы сэкономили свое время, время на code review и задачи быстрее проходят в продакшн.
А тесты написать?
Pylint позволяет провести юнит-тестирование чекеров и это очень просто. С точки зрения линтера, тест-чекер выглядит как класс, который наследуется от абстрактного CheckerTestCase. В нем необходимо указать тот чекер, который проверяем.
Шаг 1. Создаем тестовую AST-ноду из той части кода, что проверяем.
Шаг 2. Проверяем, что чекер, заходя на ноду, либо бросит, либо не бросит соответствующее сообщение:
TokenChecker
Есть еще один тип чекера, который называется TokenChecker. Он работает по принципу лексического анализатора. В Python есть модуль tokenize, который выполняет работу лексического сканера и разбивает код на список токенов. Это может выглядеть примерно так:

Названия переменных, функций и ключевые слова становятся токенами с типом NAME, а разделители, скобочки, двоеточия — токенами с типом OP. Кроме этого есть отдельные токены для индентации, перевода строки и обратного перевода.
Как Pylint работает с TokenChecker:
Мы не нашли применения TokenChecker, но есть такие примеры, которые использует сам Pylint:
Выводы
У нас была проблема с code review. Разработчики выполняли работу линтера, тратили свое время на бессмысленное сканирование кода и информирование автора об ошибках. С Pylint мы:
Простой чекер пишется за полчаса, а сложный за несколько часов. Чекер экономит гораздо больше времени, чем забирает на написание и отбивается за несколько неотклонённых pull request.
Подробнее узнать про Pylint и то, как писать для него чекеры, можно в официальной документации, но в плане написания чекеров она достаточно бедная. Например, про TokenChecker там присутствует только упоминание, что он есть, но нет про то, как написать сам чекер. Больше информации есть в исходниках Pylint на GitHub. Можно посмотреть, какие есть чекеры в стандартной поставке и вдохновиться на написание своего.
Знание внутреннего устройства Pylint экономит человеко-часы, упрощает
работу и улучшает код. Экономьте свое время, пишите хороший код и
пользуйтесь линтерами.
А вот Максим Мазаев знает, насколько важно понимать свои инструменты, и нам рассказал на Moscow Python Conf++. На реальных примерах показал, как знание внутреннего устройства Pylint и его плагинов помогло уменьшить время code review, улучшить качество кода и вообще повысить эффективность разработки. Ниже расшифровка-инструкция.
Зачем нам Pylint?
Если вы его уже используете, то может возникнуть вопрос: «Зачем знать, что внутри у Pylint, чем эти знания могут помочь?»
Обычно разработчики пишут код, запускают линтер, получают сообщения о том, что улучшить, как сделать код более красивым, и вносят предложенные изменения. Теперь код удобнее читать и не стыдно показать коллегам.
Долгое время и в ЦИАН именно так работали с Pylint, с небольшими дополнениями: меняли конфигурации, убирали лишние правила, увеличили максимальную длину строки.
Но в какой-то момент столкнулись с проблемой, для решения которой, пришлось копнуть глубоко внутрь Pylint и разобраться, как он работает. Что это за проблема и как ее решили, читайте дальше.
О спикере: Максим Мазаев (backslash), 5 лет в разработке, работает в ЦИАН. Глубоко изучает Python, асинхронность и функциональное программирование.
О ЦИАН
Большинство считает, что ЦИАН — это агентство недвижимости с риелторами и очень удивляются, когда узнают, что вместо риэлторов у нас работают программисты.
Мы — техническая компания, в которой нет риелторов, зато очень много программистов.
- 1 млн. уникальных пользователей в сутки.
- Самая крупная доска объявлений о продаже и аренде недвижимости в Москве и Санкт-Петербурге. В 2018 году вышли на федеральный уровень и работаем по всей России.
- Почти 100 человек в команде разработки, из которых 30 ежедневно пишут код на Python.
Каждый день в продакшн выезжают сотни и тысячи строк нового кода. Требования для кода довольно просты:
- Код достойного качества.
- Стилистическая однородность. Все разработчики должны писать примерно похожий код, без «винегрета» в репозиториях.
Чтобы этого добиться, конечно, нужен code review.
Code review
Code review в ЦИАН проходит в два этапа:
- Первый этап — автоматизированный. Робот в Jenkins запускает тесты, прогоняет Pylint и проверяет согласованность API между микросервисами, так как мы используем микросервисы. Если на этом этапе тесты падают или линтер показывает что-то странное, то это повод для того, чтобы отклонить pull request и отправить код на доработку.
- Если первый этап прошел удачно, то наступает второй — одобрение от двух разработчиков. Они могут оценить, насколько код хорош в плане бизнес-логики, одобрить pull request или вернуть код на доработку.
Проблемы code review
Pull request может не пройти code review из-за:
- ошибок в бизнес-логике, когда разработчик неэффективно или неправильно решил задачу;
- проблем со стилем кода.
Какие могут быть проблемы со стилем, если линтер проверяет код?
Все кто пишет на Python знают, что существует руководство по написанию кода РЕР-8. Как любой стандарт, PEP-8 довольно общий и нам, как разработчикам, этого недостаточно. Стандарт хочется в одних местах конкретизировать, а в других расширить.
Поэтому мы придумали свои внутренние договоренности о том, как код должен выглядеть и работать, и назвали их «Decline Cian Proposals».
«Decline Cian Proposals» — набор правил, сейчас их примерно 15. Каждое из этих правил — основание, чтобы pull request был отклонен и отправлен на доработку.
Что мешает продуктивному code review?
С нашими внутренними правилами есть одна проблема — линтер не знает про них, и было бы странно, если бы знал — они же внутренние.Разработчику, который выполняет задачу, нужно всегда помнить и держать правила в голове. Если он забудет одно из правил, то в процессе code review проверяющие укажут на проблему, задача отправится на доработку и время релиза задачи увеличится. После доработки и исправления ошибок, проверяющим нужно вспомнить, что же было в задаче, переключать контекст.
Создается проблема и для разработчика и для проверяющих. В результате критически снижается скорость code review. Вместо того, чтобы анализировать логику кода, проверяющие начинают анализировать визуальный стиль, то есть выполняют работу линтера: сканируют код по строчкам и ищут несоответствия в отступах, в формате импортов.
От этой проблемы нам бы хотелось избавиться.
А не написать ли нам свой линтер?
Кажется, что проблему решит инструмент, который будет знать про все внутренние договоренности и сможет проверять код на их выполнение. Получается нам нужен свой линтер?
На самом деле нет. Идея дурацкая, потому что у нас уже используется Pylint. Это удобный линтер, нравится разработчикам и встроен во все процессы: запускается в Jenkins, генерирует красивые отчеты, которые полностью устраивают и в виде комментариев приезжают в pull request. Все отлично, второй линтер не нужен.
Так как решить проблему, если свой линтер мы писать не хотим?
Написать плагин для Pylint
Для Pylint можно написать плагины, они называются чекерами. Под каждое внутреннее правило можно написать свой чекер, который будет его проверять.
Рассмотрим два примера подобных чекеров.
Пример № 1
В какой-то момент обнаружилось, что в коде много комментариев вида «TODO» — обещаний отрефакторить, удалить ненужный код или переписать его красиво, но не сейчас, а позже. С подобными комментариями есть проблема — они совершенно ни к чему не обязывают.
Проблема
Разработчик написал обещание, выдохнул и пошел со спокойной душой заниматься следующей задачей.
В итоге:
- комментарии с обещаниями висят годами и не выполняются;
- замусоривается код;
- технический долг копится годами.
Например, разработчик 3 года назад обещал что-то убрать после успешного релиза, а случился ли релиз за 3 года? Возможно, что да. Удалить ли код в этом случае? Это большой вопрос, но, скорее всего, нет.
Решение: пишем свой чекер для Pylint
Нельзя запретить разработчикам писать подобные комментарии, но можно заставить сделать дополнительную работу: создать в трекере задачу на доработку обещания. Тогда мы точно про нее не забудем.
Нам нужно найти все комментарии вида TODO и убедиться, что в каждом из них есть ссылка на задачу в Jira. Давайте писать.
Что такое чекер с точки зрения Pylint? Это класс, который наследуется от базового класса чекера и имплементирует некий интерфейс.
class TodoIssueChecker(BaseChecker):
_ _implements_ _ = IRawChecker
В нашем случае это IRawChecker — так называемый «сырой» чекер.
«Сырой» чекер итерируется по строкам файла и над строкой может выполнить определенное действие. В нашем случае в каждой строке чекер будет искать нечто похожее на комментарий и ссылку на задачу.
Для чекера нужно определить список сообщений, которые он будет выдавать:
msgs = {
'С9999': ('Комментарии с TODO без ссылки на задачу',
issue-code-in-todo',
'Длинное описание')}
В сообщении есть:
- описание короткое и длинное;
- код чекера и короткое мнемоническое название, которое определяет, что это за сообщение.
Код сообщения имеет вид «С1234», в котором:
- Первая буква четко стандартизирована по разным типам сообщений: [C]onvention; [W]arning; [Е]ггог; [F]atal; [R] efactoring. Благодаря букве, в отчете сразу видно, что происходит: напоминание о договоренностях или фатальные проблемы, которые нужно срочно решать.
- 4 произвольные цифры, уникальные в рамках Pylint.
Код нужен, чтобы отключить проверку, если она станет не нужна. Можно написать Pylint: disable и короткий буквенно-цифровой код или мнемоническое название:
# Pylint: disable=C9999
# Pylint: disable=issue-code-in-todo
Авторы Pylint рекомендуют отказаться от буквенно-цифрового кода и использовать мнемонический, он более наглядный.
Следующий шаг — определить метод, который называется process_module.
Название очень важно. Метод должен называться именно так, потому что Pylint потом будет его вызывать.
В модуль передается параметр node. В данном случае неважно, что это такое и какого он типа, важно только помнить, что у node есть метод stream, который возвращает файл построчно.
По файлу можно пройтись и для каждой строчки проверить наличие комментариев и ссылки на задачу. Если комментарий есть, а ссылки нет, то выбросить предупреждение вида ’issue-code-in-todo’ с кодом чекера и номером строки. Алгоритм достаточно простой.
Регистрируем чекер, чтобы Pylint о нем знал. Это делается функцией register:
def register(linter: Pylinter) -> None:
linter. register_checker (
TodoIssueChecker(linter)
)
- В функцию приходит экземпляр Pylint.
- В нём вызывается метод register_checker.
- В метод передаем сам чекер.
Важный, момент: модуль чекера должен лежать в PYTHONPATH, чтобы Pylint мог потом его импортировать.
Зарегистрированный чекер проверяется тестовым файлом с комментариями без ссылок на задачи.
$ cat work.ру
# T0D0: Удалю через неделю, честно-честно!
$ pylint work.ру --load-plugins todo_checker
…
Для теста запускаем Pylint, передаем в него модуль, с помощью параметра load-plugins передаем чекер, и внутри линтера запускаем две фазы.
Фаза 1. Инициализация плагинов
- Импортируются все модули, где есть плагины. В Pylint есть внутренние чекеры и внешние. Все они собираются вместе и импортируются.
- Регистрируем — module.register(self). Для каждого чекера вызывается функция register, куда передается экземпляр Pylint.
- Выполняются проверки: на валидность параметров, на присутствие сообщений, опций и отчетов в правильном формате.
Фаза 2. Разбираем пул чекеров
После фазы 1 остается целый список чекеров разных типов:
- AST checker;
- Raw checker;
- Token checker.
Из списка выделяем те, что относятся к интерфейсу «сырого» чекера: смотрим какие чекеры имплементируют интерфейс IRawChecker и берем их себе.
Для каждого отобранного чекера вызываем метод checker.process_module(module), и запускаем проверку.
Результат
Снова запускаем чекер на тестовом файле:
$ cat work.ру
# T0D0: Удалю через неделю, честно-честно!
$ pylint work, ру --load-plugins todo_checker
С: 0,0: Комментарий с T0D0 без ссылки на задачу
(issue-code-in-todo)
Появится сообщение о том, что есть комментарий с TODO и нет ссылки на задачу.
Проблема решена и теперь в процессе code review разработчикам не нужно сканировать код глазами, находить комментарии, писать автору кода напоминание, что есть договоренность и желательно оставить ссылку. Всё происходит автоматизировано и code review проходит чуть быстрее.
Пример № 2. keyword-arguments
Есть функции, которые принимают позиционные аргументы. Если аргументов достаточно много, то при их вызове функции не очень понятно, где какой аргумент и зачем он нужен.
Проблема
Например, у нас есть функция:
get_offer_by_cian_id(
"sale",
Тrue,
859483,
)
В коде есть sale и True и непонятно, что они означают. Гораздо удобнее, когда функции, в которых много аргументов, вызывались бы только с именованными аргументами:
get_offer_by_cian_id(
deal_type="sale",
truncate=True,
cian_id=859483,
)
Это хороший код, в котором сразу понятно, где какой параметр и мы не перепутаем их последовательность. Попробуем написать чекер, который проверяет подобные кейсы.
«Сырой» чекер, использовавшийся в предыдущем примере, для такого случая написать очень сложно. Можно добавить супер-сложные регулярные выражения, но такой код тяжело читать. Хорошо, что Pylint дает возможность написать другой тип чекера на основе абстрактного синтаксического дерева AST, его и будем использовать.
Лирическое отступление про AST
AST или абстрактное синтаксическое дерево — это представление кода в виде дерева, где вершина — операнды, а листья — операторы.
Например, вызов функции, где есть один позиционный аргумент и два именованных, трансформируется в абстрактное дерево:
Здесь есть вершина с типом Call и она имеет:
- атрибуты функции с названием func;
- список позиционных аргументов args, где есть нода с типом Const и значением 112;
- список именованных аргументов Keywords.
Задача в данном случае:
- Найти в модуле все ноды с типом Call (вызов функции).
- Посчитать общее количество аргументов, которые принимает функция.
- Если аргументов больше 2, то убедиться, что в ноде отсутствуют позиционные аргументы.
- Если есть позиционные аргументы, то показать предупреждение.
Саll(
func=Name(name='get_offer'),
args=[Const(value=1298880)],
keywords=[
…
]))]
С точки зрения Pylint, чекер на основе AST — это класс, который наследуется от класса базового чекера и имплементирует интерфейс IAstroidChecker:
class NonKeywordArgsChecker(BaseChecker):
-_ _implements_ _ = IAstroidChecker
Как и в первом примере, в списке сообщений указывается описание чекера, код сообщения, короткое мнемоническое название:
msgs = {
'С9191': ('Краткое описание',
keyword-only-args',
'Длинное описание')}
Следующий шаг — определяется метод visit_call:
def visit_call(self, node: Call)
…
Метод не обязательно должен так называться. Самое главное в нем — префикс visit_, а дальше идет имя вершины, которая нас интересует, с маленькой буквы.
- AST-парсер ходит по дереву и для каждой вершины смотрит, определены ли у чекера интерфейс visit_<Имя>.
- Если да, то вызывает его.
- Рекурсивно проходит по всем ее детям.
- При уходе с ноды вызывает метод lеаvе_<Имя>.
В данном примере метод visit_call получит на вход ноду с типом Call и посмотрит, есть ли у нее больше двух аргументов и присутствуют ли позиционные аргументы, чтобы выбросить предупреждение и передать туда код и саму ноду.
def visit_call(self, n):
if node.args and len(node.args + node.keywords) > 2:
self.add_message(
'keyword-only-args',
node=node
)
Регистрируем чекер, как в предыдущем примере: передаем экземпляр Pylint, вызываем register_checker, передавая сам чекер и запускаем.
def register(linter: Pylinter) -> None:
linter.register_checker(
TodoIssueChecker(linter)
)
Это пример вызова тестовой функции, где есть 3 аргумента и только один из них именованный:
$ cat work.ру
get_offers(1, True, deal_type="sale")
$ Pylint work.py --load-plugins non_kwargs_checker
…
Это функция, которая потенциально вызывается неправильно с нашей точки зрения. Запускаем Pylint.
Фаза 1 инициализации плагинов полностью повторяется, как и в предыдущем примере.
Фаза 2. Разбор модуля на AST
Код разбирается в AST-дерево. Разбор выполняет библиотека Astroid.
Почему Astroid, а не AST (stdlib)
Astroid внутри себя использует не стандартный модуль Python AST, а типизированный AST-парсер typed_ast, отличающийся тем, что поддерживает тайпхинты из РЕР 484. Typed_ast — это ответвление AST, форк, который развивается параллельно. Что интересно, там присутствуют те же баги, что в AST, и чинятся параллельно.
from module import Entity
def foo(bar):
# type: (Entity) -> None
return
Раньше Astroid использовал стандартный AST-модуль, в котором можно было столкнуться с проблемой использования тайпхинтов, определенных в комментариях, которые используются во втором Python. Если проверить такой код через Pylint, то до определенного момента он ругался на неиспользованный импорт, потому что импортированный класс Entity присутствует только в комментарии.
В какой-то момент на GitHub к Astroid пришел Гвидо Ван Россум и сказал: «Ребята, у вас есть Pylint, который ругается на такие кейсы, а у нас есть типизированный AST-парсер, который поддерживает это все. Давайте дружить!»
Работа закипела! Прошло 2 года, этой весной Pylint уже перешел на типизированный AST-парсер и перестал ругаться на такие вещи. Импорты для тайпхинтов больше не помечаются как неиспользуемые.
Astroid использует AST-парсер, чтобы разобрать код на дерево, а потом при сборке делает некоторые интересные вещи. Например, если вы используете import *, то он импортирует все, что по звездочке, и добавит в locals, чтобы предотвратить ошибки с неиспользованными импортами.
Transform plugins используются в случаях, когда есть какие-то сложные модели, основанные на мета-классах, когда все атрибуты генерируются динамически. В этом случае Astroid очень сложно понять, что подразумевается. При проверке Pylint будет ругаться, что в моделях нет такого атрибута, когда к нему обращаются, а с помощью Transform plugins можно решить проблему:
- Помочь Astroid модифицировать абстрактное дерево и разобраться в динамической природе Python.
- Дополнить AST полезной информацией.
Характерный пример — pylint-django. При работе со сложными django-моделями линтер часто ругается на неизвестные атрибуты. Pylint-django как раз решает эту проблему.
Фаза 3. Разбираем пул чекеров
Возвращаемся к чекеру. У нас снова есть список чекеров, из которых мы находим те, что имплементируют интерфейс AST checker.
Фаза 4. Разбираем чекеры по типам нод
Дальше у каждого чекера находим методы, они могут быть двух типов:
- visit_<Имя ноды>
- lеаvе_<Имя ноды>.
Было бы неплохо во время хождения по дереву знать, для какой ноды какие чекеры нужно вызвать. Поэтому они разбираются в словарь, где ключ — это имя ноды, значение — это список тех чекеров, которым важен факт захода на эту ноду.
_visit_methods = dict(
<Имя ноды> : [checker1, checker2 ... checkerN]
)
То же самое с leave-методами: ключ в виде имени ноды, список чекеров, которым интересен факт выхода с этой ноды.
_leave_methods = dict(
<Имя ноды>: [checker1, checker2 ... checkerN]
)
Запускаем Pylint. Он показывает предупреждение, что у нас есть функция, где больше двух аргументов и в ней присутствует позиционный аргумент:
$ cat work.ру
get_offers(1, True, deal_type="sale")
$ Pylint work.py --load-plugins non_kwargs_checker
C: 0, 0: Функция c >2 аргументами вызывается с позиционными аргументами (keyword-only-args)
Проблема решена. Теперь программистам на code review не нужно считать аргументы у функции, за них это сделает линтер. Мы сэкономили свое время, время на code review и задачи быстрее проходят в продакшн.
А тесты написать?
Pylint позволяет провести юнит-тестирование чекеров и это очень просто. С точки зрения линтера, тест-чекер выглядит как класс, который наследуется от абстрактного CheckerTestCase. В нем необходимо указать тот чекер, который проверяем.
class TestNonKwArgsChecker(CheckerTestCase):
CHECKER_CLASS = NonKeywordArgsChecker
Шаг 1. Создаем тестовую AST-ноду из той части кода, что проверяем.
node = astroid.extract_node(
"get_offers(3, 'magic', 'args')"
)
Шаг 2. Проверяем, что чекер, заходя на ноду, либо бросит, либо не бросит соответствующее сообщение:
with self.assertAddsMessages(message):
self.checker.visit_call(node)
TokenChecker
Есть еще один тип чекера, который называется TokenChecker. Он работает по принципу лексического анализатора. В Python есть модуль tokenize, который выполняет работу лексического сканера и разбивает код на список токенов. Это может выглядеть примерно так:
Названия переменных, функций и ключевые слова становятся токенами с типом NAME, а разделители, скобочки, двоеточия — токенами с типом OP. Кроме этого есть отдельные токены для индентации, перевода строки и обратного перевода.
Как Pylint работает с TokenChecker:
- Проверяемый модуль токенизируется.
- Огромный список токенов передается всем чекерам, которые имплементируют ITokenChecker и вызывается метод рrocess_tokens (tokens).
Мы не нашли применения TokenChecker, но есть такие примеры, которые использует сам Pylint:
- Проверка правописания. Например, можно взять все токены с типом text и посмотреть на лексическую грамотность, проверить слова из списков стоп-слов и т.д.
- Проверка отступов, пробелов.
- Работа со строками. Например, можно проверить, что в Python 3 не используются юникод-литералы или убедиться, что в байтовой строке присутствуют только ASCI-символы.
Выводы
У нас была проблема с code review. Разработчики выполняли работу линтера, тратили свое время на бессмысленное сканирование кода и информирование автора об ошибках. С Pylint мы:
- Переложили рутинные проверки на линтер, имплементировали внутренние соглашения в нем.
- Увеличили скорость и качество code review.
- Сократили количество отклоненных pull request, а время прохождения задач в продакшн стало меньше.
Простой чекер пишется за полчаса, а сложный за несколько часов. Чекер экономит гораздо больше времени, чем забирает на написание и отбивается за несколько неотклонённых pull request.
Подробнее узнать про Pylint и то, как писать для него чекеры, можно в официальной документации, но в плане написания чекеров она достаточно бедная. Например, про TokenChecker там присутствует только упоминание, что он есть, но нет про то, как написать сам чекер. Больше информации есть в исходниках Pylint на GitHub. Можно посмотреть, какие есть чекеры в стандартной поставке и вдохновиться на написание своего.
Знание внутреннего устройства Pylint экономит человеко-часы, упрощает
работу и улучшает код. Экономьте свое время, пишите хороший код и
пользуйтесь линтерами.
Следующая конференция Moscow Python Conf ++ состоится 5 апреля 2019 г. и уже сейчас можно забронировать early birf билет. А еще лучше будет собраться с мыслями и подать заявку на доклад, тогда посещение будет бесплатным, а бонусом пойдут приятные плюшки, включая коучинг по изготовлению доклада.
Наша конференция — площадка для встречи с единомышленниками, двигателями индустрии, для общения и обсуждения любимых Python-разработчиками вещей: backend и web, сбор и обработка данных, AI/ML, тестирование, IoT. Как она прошла осенью посмотрите в видеоотчете на нашем канале Python Channel и подпишитесь на канал — скоро выложим лучшие доклады с конференции в свободный доступ.
sobolevn
Спасибо за видео и статью! К сожалению, не смог посетить доклад лично.
Задам вопрос пост-фактум.
> Есть функции, которые принимают позиционные аргументы. Если аргументов достаточно много, то при их вызове функции не очень понятно, где какой аргумент и зачем он нужен.
У меня была похожая идея для своего линтера: github.com/wemake-services/wemake-python-styleguide/issues/340
Но она разбилась о факт наличия `*args` в языке. Как вы решаете проблему того, что некоторые функции могут и должны принимать много позиционных аргументов by design?