

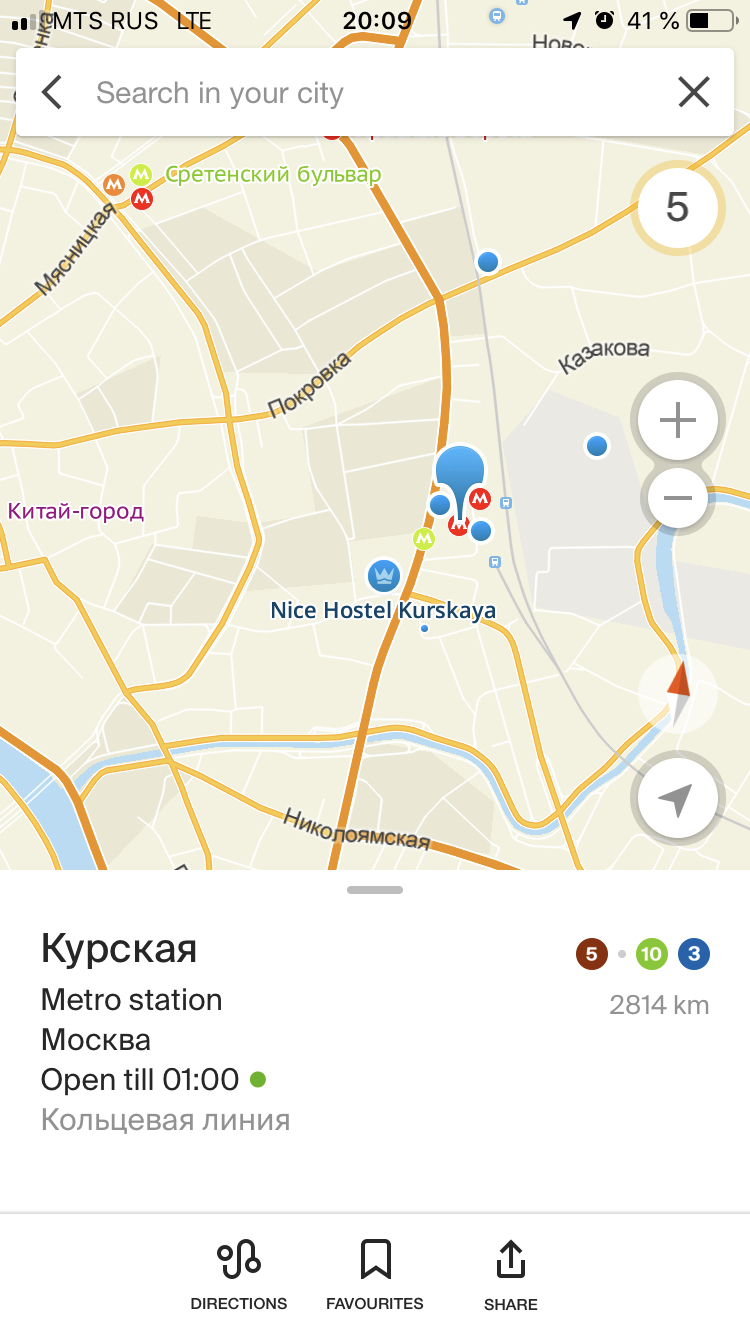
Представьте ваш первый день на новой работе. Офис находится в районе совершенно незнакомой вам станции метро Курская. Приближается время обеда. Вы открываете поисковое приложение, пишете «поесть на Курской» и получаете подборку вариантов, где можно отобедать.
Что стоит за запросом «поесть на Курской» и как он обрабатывается, чтобы найти именно то, что нужно вам? В статье я расскажу, как команда Поиска 2ГИС делает всё возможное для того, чтобы жизнь в городах была удобнее и комфортнее для пользователей.
Важно понимать, что текст поискового запроса — лишь верхушка айсберга, малая часть того, с чем непосредственно взаимодействует пользователь. Сам поисковый запрос, помимо текста, содержит множество других данных. В них входит персонализированная информация о местоположении пользователя, участке карты, который он видит, набор записей из его избранного и информация о режимах поиска. Например, поиск по карте или в здании, а может и поиск проезда. Данные — залог успеха хорошего поискового функционала.
Мы уделяем большое внимание нашим данным и их структуре. Более того, сам алгоритм поиска в 2ГИС мы называем структурным поиском, потому что он заточен под эффективный и быстрый поиск в наших структурированных данных. Мы особым образом подготавливаем поисковый индекс и данные, из которых он строится. Не буду углубляться в детали, скажу лишь, что данные организованы так, чтобы быть достаточно простыми в обработке, хорошо сжимались, а главное позволяют нам быстро их обрабатывать даже на мобильных устройствах.
Более того, поиск умеет работать офлайн, а потому предъявляет особые требования к быстродействию и объёму поискового индекса. Этой особенности мы уделяем большое внимание — постоянно сжимаем поисковый индекс, оцениваем быстродействие на всевозможных платформах и ускоряем функционал там, где специфичные поисковые кейсы превышают установленный лимит времени. К слову, можем похвастаться тем, что рядовой поисковый запрос в 2ГИС на мобильном устройстве выполняется быстрее, чем приложение рисует выпадающий список по результатам.
Ниже я приоткрою завесу тайны, покрывающей магию нашего поиска. В качестве примера возьмём упомянутый запрос «поесть на Курской». Рассмотрим этапы его обработки и что происходит на каждом из них. Итак, поехали!
Этап 1. Парсинг
Входные параметры: запрос «поесть на Курской»
Прежде всего, нам необходимо провести парсинг текста запроса. Это важно, потому что после парсинга мы сможем работать не с текстом запроса, а с набором токенов, из которых он состоит. Токены — это отдельные слова запроса. В нашем случае мы получим набор из трёх токенов: «поесть», «на», «курской». Казалось бы, всё просто, но дьявол в мелочах. И порой всё бывает не так очевидно: например, в запросах «wi-fi» или «2-я» мы должны понимать, что обрабатывать такие сочетания следует целиком.
Сами по себе токены содержат информацию о тексте слова, о позиции в запросе, о наличии разделителя следующего за словом и некоторую характеристику слова — регистр его символов, представляет ли слово собой число, порядковое числительное, номер телефона, адрес или другие данные.
Этап 2. Словарный поиск
Входные параметры: токены «поесть», «на», «курской»

С готовым списком токенов запроса мы приступаем к этапу словарного поиска, то есть к этапу, на котором для каждого токена находим список словоформ из наших данных. Словоформа — это закодированная информация о корне слова и его окончании.
Словарный поиск мы представляем как алгоритм анализа словаря, представленного в виде графа. Узлы в нём — это буквы, а точнее — символы. Граф состоит из узлов-символов и переходов между этими узлами. Результатом обхода нашего графа-словаря является множество словоформ, которые мы можем получить на основе переданных токенов из предыдущего этапа. Так мы пробуем найти в нашем словаре последовательность символов, которая совпадает с очередным токеном из запроса. При этом, как мы все с вами знаем, пользователи допускают опечатки, пропускают буквы или даже ошибаются в раскладке клавиатуры. Поэтому при обходе словаря мы применяем некоторые манипуляции с тем, чтобы учесть возможный человеческий фактор или попробовать угадать, что человек набирает прямо сейчас. В ход идут различные преобразования цепочки символов: вставки, замены, дописывание символов и тому подобное.
В результате для каждого токена запроса из графа мы извлекаем набор словоформ с информацией о корне и окончании слова, информацию о числе символов в словоформе и оценку найденности. Оценка найденности — оценка, характеризующая словарное расстояние найденной последовательности символов к искомой последовательности. Оценка характеризует насколько сильно отличается найденная цепочка символов от токена запроса.
Так для токенов найдём словоформы:
- 13 форм для «поесть»: «поест», «поесть», «paese», «payot», …
- 3 формы для «на»: «na», «nu», «на»
- 48 форм для «курской»: «курской», «курская», «курски», «курское», «курако», …
Далее найденные словоформы фильтруются в зависимости от их оценки. Лучшие из них, то есть максимально близкие к словам из запроса, попадают в список терминов. Под термином будем понимать словоформу и оценку найденности. Плюс к тому, помимо найденных словоформ в список добавляются термины, полученные с помощью правил морфологии. Важный этап обработки морфологии — добавление морфологической оценки. Дело в том, что в нашем поиске используется сильный механизм обработки морфологии, который позволяет нам не просто находить похожие слова из словаря, но и согласно правилам естественного языка правильнее находить что именно интересует пользователя по смыслу, а не только по похожести слов.
Так для токенов будут созданы термины:
- «поесть»: «поедим», «поели», «поем», «поест», «поесть»
- «на»: «на», «na», «nu»
- «курской»: «курская», «курский», «курского», «курское», «курской»
На этом этап словарного поиска заканчивается. Мы провели обработку запроса и имеем для каждого токена список терминов, которые уходят в дальнейшую обработку. Эти термины содержат всю информацию о слове, которое они представляют, и имеют оценку того, как каждый из них был найден.
Этап 3. Поиск вхождений в данные
Вход: набор терминов для каждой части запроса
- «поесть»: «поедим», «поели», «поем», «поест», «поесть»
- «на»: «на», «na», «nu»
- «курской»: «курская», «курский», «курского», «курское», «курской»
Получив из предыдущего этапа набор терминов для каждой из частей запроса, мы приступаем к их поиску по нашему индексу. Каждый документ в данных имеет множество заголовков и записывается в обратный индекс так, чтобы мы могли легко находить все упоминания нужного термина в конкретных документах, представляющих организации, адреса или любые другие.
Для каждой из частей запроса и для каждого из терминов этих частей мы ищем документы, содержащие слова, закодированные в терминах. Так, для частей запроса по всем терминам будут найдены вхождения:
- «поесть»: 18 вхождений
- «на»: 4304 вхождений
- «курской»: 79 вхождений
Очевидно, что предлог «на» встречается очень много раз и потому попадает в множество заголовков документов — «кофе на вынос», «поиграть на приставке», «постановка на учёт машины». «Поесть» и «курской» тоже используются неоднократно. Второе слово с его терминами встречается в наших данных значительно чаще, чем первое.

Попаданием мы считаем соответствие слова из поискового запроса слову из конкретного документа. Эти попадания сохраняются в список, который будет анализироваться на следующем этапе. При добавлении попадания мы не только копируем из термина данные о слове в документе, но и вычисляем лучшую оценку того, как слово могло быть найдено. Иными словами, выбираем морфологическую оценку термина, либо оценку того, как термин был найден в словаре, в зависимости от того, какая из оценок ближе к токену запроса.
Этот этап — прелюдия к старту самого поиска. Мы подготовили набор попаданий в конкретные документы, на основе которых следующий алгоритм будет отбирать и оценивать, что нужно отдать пользователю в качестве результата.
Этап 4. Сердце поиска
Вход: список попаданий
- «поесть»: 18 вхождений
- «на»: 4304 вхождений
- «курской»: 79 вхождений
На самом деле список попаданий в нашей реализации — это достаточно хитрый контейнер. Важно понять, что при добавлении попаданий в него создаются специальные узлы, куда записываются сами попадания, и ссылка на документ, в который пришлись эти попадания.
Поэтому правильнее будет отобразить входные данные следующим образом:
Вход: контейнер узлов-документов
- документ1: { попадания, … }
- документ2: { попадания, … }
- документ3: { попадания, … }
- документ4: { попадания, … }
- ...
Первым делом поиск начинает обход дерева документов и каждый узел отдаёт в анализатор, который оценивает пригоден ли документ из этого узла быть результатом для попадания в выдачу. Чтобы понимать, с какими объёмами приходится работать анализатору, скажу, что на старте контейнер содержит более 3000 узлов! А ведь узлы могут добавляться в процессе обхода, поэтому реально обрабатывается ещё больше. Не будет преувеличением сказать, что анализ — самая затратная часть поиска и в то же время одна из самых сложных и больших функций проекта. И тем не менее она выполняется крайне быстро даже на мобильных устройствах.
Этап 5. Анализ
Вход: Узел документ: { попадания, … }
Начинается анализ с получения списка тайтлов из узла. Тайтл представляет собой заголовок и список попаданий, пришедшихся в этот заголовок документа. Эти заголовки и будем оценивать на первом этапе. Нам важно узнать полезность каждого тайтла. Полезность может быть хорошей, слабой и мусорной.
Для каждого из тайтлов отбираются лучшие из цепочки попаданий — лучшие по длине и словарной оценке, составленной из похожести попаданий. На основе лучшей цепочки и будет проведена оценка полезности тайтла. Чтобы определить полезность цепочки, мы в том числе используем механизм на основе частотности слов в документах. Грубо говоря, чем чаще слово встречается в документе, тем оно важнее (TF-IDF). Так, если цепочка содержит попадание в важное слово из заголовка документа без сильных морфологических отличий, например отличное число или род — считаем тайтл полезным. Тайтл также может быть полезным, если его попадания полностью покрывают слова из заголовка документа.
С помощью полезности все тайтлы образуют маску полезности для узла. Эта маска даёт нам представление о токенах запроса, покрываемых анализируемым узлом. И с её помощью мы во многом определяем, следует ли дальше анализировать узел.
В качестве результата мы имеем не просто один документ из индекса, а набор структурных данных, представляющих потенциальный результат с информацией о том, как она может быть найдена.
Этап 6. Оценка
Вход: Узел документ: { попадания, … }

В зависимости от маски полезности, мы либо будем обрабатывать узел, либо сразу перейдём к следующему. Из множества обработанных узлов мы накапливаем различную информацию об их совокупности. Например, множество тайтлов узлов, отношения узлов между собой и некоторые другие данные.
Дальше начинается анализ тайтлов узлов, взаимосвязанных друг с другом. По факту множество узлов объединяются в граф узлов, который мы оцениваем.
Из тайтлов узлов графа получаем список отранжированных тайтлов. Говоря проще, из множества узлов мы составляем единый список тайтлов, в котором для каждого элемента также добавляется оценка и совокупность факторов из попаданий тайтлов всех участвующих узлов.
Оценка — структура с информацией о числе задействованных в тайтле слов из запроса и множество других факторов о том, как слово было найдено и обработано — начиная с этапа словарного поиска. Важно, что эти оценки из ранжированного тайтла будут участвовать в отборе лучших оценок. Некоторые из них будут помечены как выбранные и внесут свой вклад в конечную оценку того результата, который увидит пользователь.
Общая оценка наделяет результат информацией, которая будет крайне важна при сортировке всей выдачи. Она содержит такие факторы, как, например, пропуски слов из запроса. Эта мера характеризует число слов, которые не были покрыты узлом с его структурной информацией.
На основе информации о полезности тайтлов определяется ясность результата. Ясность может быть хорошей, слабой и плохой. И вычисляется она с участием всех выбранных тайтлов для обрабатываемого узла. Все эти данные оказывают драматическое влияние на дальнейшую судьбу результатов и порядок их выдачи.
Постепенно мы приближаемся к окончанию анализа узла. Прежде чем узел окончательно покинет пределы анализатора и станет потенциальным результатом, мы проводим ещё несколько уточняющих манипуляций. Например, на совместимость выбранных заголовков документов.
Узел, прошедший все круги анализатора, образует результат, содержащий в себе информацию о выбранных заголовках и документ. Результат, дающий хорошее покрытие поискового запроса, отправляется в постобработку.
Этап 7. Постобработка
Вход: результат, сконструированный из узла

Анализатор отсеивает множество записей из индекса, прежде чем те станут результатами. Однако в ходе анализа может быть оценено и отправлено на обработку множество потенциальных результатов. Чтобы показать пользователю только самые полезные из них в порядке релевантности, нам нужно отсечь худшие варианты, найденные анализатором.
На предыдущем шаге упоминалась общая оценка результата. Общая оценка позволяет нам на этапе постобработки отсечь худшие результаты. Градация следующая. Результаты, не покрывшие какие-либо токены запроса, очевидно, хуже тех результатов, которые полностью покрывают запрос пользователя. Результаты с худшей ясностью, очевидно, менее желательны, чем результаты с хорошей ясностью. Постобработчик накапливает сведения о поступающих результатах и отсеивает те, что заведомо хуже. Остальные добавляет в список.
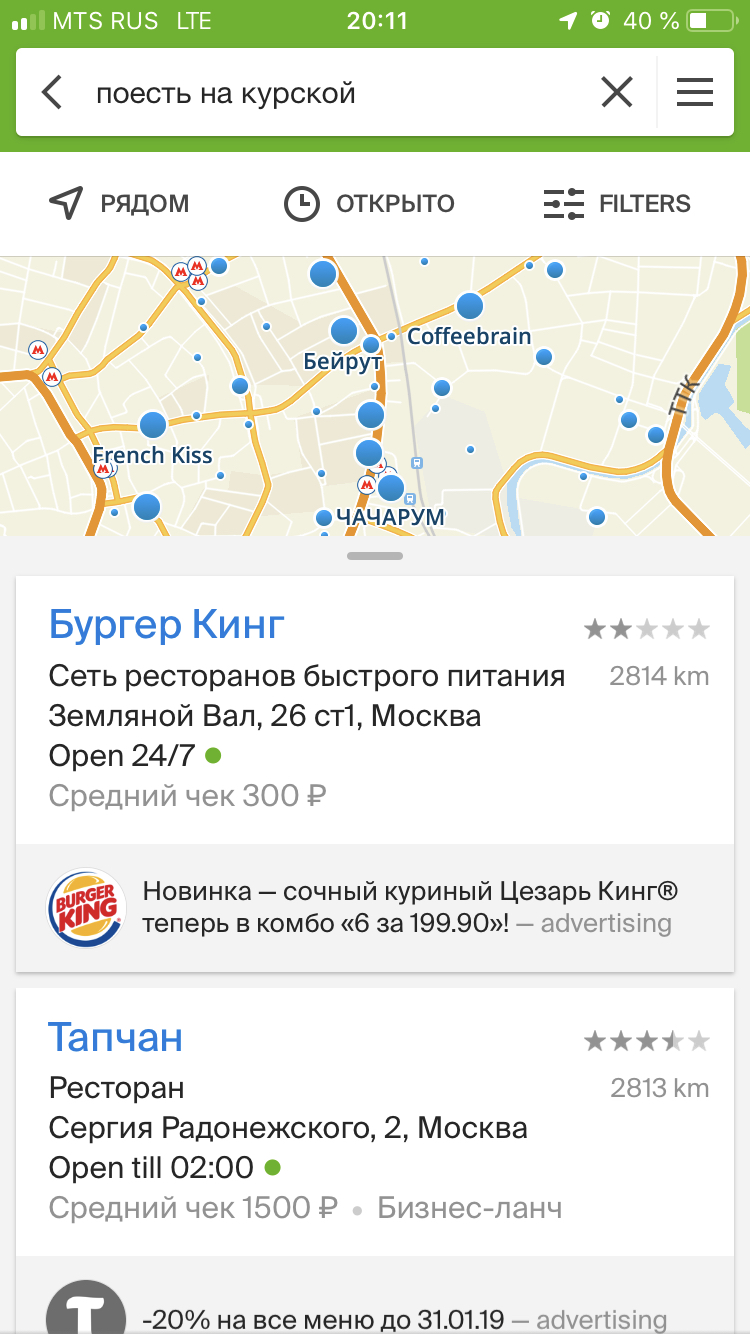
Перед тем, как отдать голодному пользователю информацию о кафе, мы проводим завершающую обработку — сортируем по релевантности. В сортировке участвует множество факторов, рассчитанных и агрегированных на разных этапах поиска. И в конечном итоге поисковая выдача по запросу «поесть на Курской» составляет более 500 результатов. Многие из них были найдены одинаковым путём, а потому имеют одинаковую оценку. Они будут отсортированы по степени популярности у пользователей.
Вывод
Мы получили выдачу с множеством кафе и ресторанов и, радостные, отправляемся обедать. Все результаты мы получили за доли секунд. И при этом нам даже не нужно интернет-соединение.
Приложение хранит поисковые индексы на устройстве. Такая схема обеспечивает нас нетривиальными задачами по оптимизации сжатия данных и скорости их обработки — ведь поиск должен быстро работать на самых разных мобильных устройствах! Впрочем, это уже совсем другая история.
Сегодня же я постарался приоткрыть капот нашего поискового движка и показать, как мы помогаем пользователям находить в городе то, что им нужно, причём делать это быстро и удобно. Надеюсь, было познавательно.
Комментарии (23)

EgorZanuda
20.12.2018 10:32Отсутствие полнотекстового поиска даже в режиме онлайн, привело к результату «Нет данных».
Немного не в тему, грамотность постановки примера имеет значение. Если в примере заменить нового сотрудника на путешественника с личным авто тогда поменяется психологический портрет примера. Разъясняю мысль, новый сотрудник боится или стесняется спросить у коллег где можно поесть. Здесь явно что-то не то с новым сотрудником. Да и цифровой поиск выдаст только адреса, а коллеги явно подскажут тонкости кухни конкретного заведения.Moximko Автор
20.12.2018 11:36Можно выбрать героя, который больше по душе — путешественник или просто человек, оказавшийся по делам в незнакомой части города и хочет поесть.
questor
20.12.2018 10:36-3Тут недавно была статья о проблемах Америки с доставкой посылок, где в комментариях много обсуждали надуманность проблемы (комикс_проблемы_первого_мира.jpg), так вот я скажу вот что.
До сих пор гораздо проще спросить новых коллег в офисе «где тут у вас обедают» и получить гораздо более подробный и точный ответ.
И только в случае если вы редкостно замкнутый человек, забегались на новой работе настолько, что не у кого спросить — все вышли, только тогда я бы обратился к поиску.Moximko Автор
20.12.2018 11:36+1Согласен, можно спросить коллег, однако, в мире ИТ интроверты не редкость и кто-то может любить обедать в одиночестве, например. А ещё поиск в справочнике может помочь найти новые места даже если вы знаете все кафе в округе.
Nalivai
20.12.2018 21:46+2Да хрен там валялся. Устроился я тут на работу, вполне себе экстравертно несколько раз спросил разных людей, с разными сходил в разные столовки, и ничего не понравилось. Полез гуглить, оказалось что прям в соседнем бц кафе без вывески про которое никто не знал, а через дом бургерная в подвале, в которую никто не ходит потому что «бургеры не еда».
В общем, нафиг их, эти офисные легенды и пересказы пересказов.
teifo
20.12.2018 11:59Не подскажите, почему на Бете, когда ищешь какую-то компанию, то на половину монитора теперь два экрана -результаты поиска и экран компании? Разве так удобнее?
Sanch_ru
20.12.2018 13:41Да, это эксперимент с новой механикой интерфейса – в сценарии выбора компаний можно одновременно видеть выдачу слева и открытую карточку справа, что позволяет быстро просматривать несколько карточек компаний
dab512
20.12.2018 12:11Наберите в поиске «игрушки для ребёнка» и попробуйте найти ближайшие к вам магазины где реально можно купить машинку.
Больше половины точек на карте будут нерелевантны.Moximko Автор
20.12.2018 12:30Интересный кейс, могу лишь сказать, что в наступающем году мы будем работать над этим и, надеюсь, порадуем вас.

crazylh
20.12.2018 16:10На Курской найти поесть наверно не самая большая проблема в отличии от спальных районов...
mSnus
21.12.2018 15:28Странно это всё. А где морфологический анализ, быстро сводящий "поесть" к другим синонимам? А где анализ кейсов, быстро отличающий "кофе на вынос" от "кофе на Курской" и"Китайскую кухню" от "Белорусских кухонь"? Что-то подобное есть, или вы проблему понимания что механическими методами?
Moximko Автор
22.12.2018 06:32Вкратце я упомянул морфологический анализ и разумеется у нас есть механизм, чтобы отличать китайскую и белорусскую кухни, однако это темы, достойные отдельных статей, поэтому здесь упомянуты лишь вскользь.
mSnus
22.12.2018 12:57У вас написано, что морфологический анализ ведёт к созданию токенов
[quot]
Так для токенов будут созданы термины:
«поесть»: «поедим», «поели», «поем», «поест», «поесть»
«на»: «на», «na», «nu»
«курской»: «курская», «курский», «курского», «курское», «курской»
[/quot]
То есть просто находятся разные формы слова (кстати, почему nu?), но не находится общий ключ "еда"?
Какая стадия тогда сужает контекст до
"Поесть = (действие, еда)
Курская = (геометка, м. Курская, Москва)"? Или такого нет?
gubber
Спасибо. Можно пару вопросов?
Сколько же весят ваши индексы на устройствах?
Привязаны ли они к георгафии пользователя?
Moximko Автор
Конечно можно!
Наши индексы привязаны к конкретным городам-проектам, например есть индексы Москвы, Новосибирска и другие.
Соответсвенно размер индексов разный для каждого города, его можно узнать в списке городов в приложении, например размер индекса Москвы около 300мб, а Омска около 45мб.
Un1oR
Ну только это размер не только поискового индекса, а вообще всех данных города, включая карту, дорожный граф и т.д. Отдельно индекс гораздо меньше занимает.
А цифра в списке городов несколько меньше размера данных на диске, т.к. это размер данных, передаваемых по сети при загрузке, а они пожаты lzma и распаковываются в процессе обновления на устройстве. Плюс часть файлов может шариться между несколькими городами, это тоже очевидным образом может влиять на цифру в списке городов.
Woodroof
Ну только в разы меньше :) Индекс поиска Москвы в распакованном виде занимает чуть более 62 МиБ.
Moximko Автор
Да, это верно, именно поисковый индекс значительно меньше, спасибо за уточнение.