

Первым комментарием к замечательной статье Субъективное видение идеального языка программирования оказалась ссылка на язык программирования Zig. Естественно, стало интересно, что же это такое за язык, который претендует на нишу C++, D и Rust. Посмотрел — язык показался симпатичным и в чем-то интересным. Приятный си-подобный синтаксис, оригинальный подход к обработке ошибок, встроенные сопрограммы. Данная статья является кратким обзором официальной документации с вкраплениями собственных мыслей и впечатлений от запуска примеров кода.
Начинаем
Установка компилятора достаточно простая, для Windows- просто распаковать дистрибутив в какую-то папку. Делаем в той же папке текстовый файл hello.zig, вставляем туда код из документарции и сохраняем. Сборка выполняется командой
zig build-exe hello.zigпосле чего в той же директории оказывается hello.exe.
Кроме сборки, доступен режим юнит-тестирования, для этого в коде используются блоки test, а сборка и запуск тестов осуществляется командой
zig test hello.zigПервые странности
Компилятор не поддерживает виндовские переносы строк (\r\n). Конечно, сам факт того, что переносы строк в каждой системе (Win,Nix,Mac) какие-то свои — это дикость и пережиток прошлого. Но тут уж ничего не поделаешь, так что просто выбираем например в Notepad++ желаемый для компилятора формат.
Вторая странность, на которую я наткнулся случайно — в коде не поддерживаются табуляции! Только пробелы. Бывает же такое :)
Впрочем, об этом честно написано в документации — правда уже в самом конце.
Комментарии
Еще одна странность — Zig не поддерживает многострочные комментарии. Помнится, в древнем турбо паскале было сделано все верно — поддерживались вложенные многострочные комментарии. Видимо, с тех пор ни один разработчик языка не осилил такую несложную штуку:)
Зато есть документирующие комментарии. Начинаются с ///. Должны находиться в определенных местах — перед соответствующими объектами (переменными, функциями, классами...). Если они где-то в другом месте — ошибка компиляции. Неплохо.
Объявление переменных
Выполнено в модном сейчас (и идеологически верном) стиле, когда сначала пишется ключевое слово (const или var), затем имя, затем опционально тип, и затем начальное значение. Т.е. автоматический вывод типов имеется. Переменные должны быть инициализированы — если не указать начальное значение, будет ошибка компиляции. Впрочем, предусмотрено специальное значение undefined, которое можно явно использовать для задания неинициализированных переменных.
var i:i32 = undefined;Вывод на консоль
Для экспериментов нам понадобится вывод на консоль — во всех примерах используется такой вот способ. В области подключаемых модулей прописывается
const warn = std.debug.warn;а в коде пишется вот так:
warn("{}\n{}\n", false, "hi");В компиляторе есть некие баги, о чем он честно сообщает при попытке вывести таким способом целое число или число с плавающей точкой:
error: compiler bug: integer and float literals in var args function must be casted. github.com/ziglang/zig/issues/557
Типы данных
Примитивные типы
Имена типов взяты по всей видимости из Rust (i8, u8,… i128, u128), также есть специальные типы для двоичной совместимости с Си, 4 вида типов с плавающей точкой (f16, f32, f64, f128). Есть тип bool. Есть тип нулевой длины void и специальный noreturn, о котором расскажу далее.
А еще можно конструировать целочисленные типы любой длины в битах от 1 до 65535. Имя типа начинается с буквы i или u, а затем пишется длина в битах.
// оно компилируется!
var j:i65535 = 0x0123456789ABCDEF0123456789ABCDEF0123456789ABCDEF0123456789ABCDEF;Впрочем, вывести на консоль это значение у меня не получилось — в процессе компиляции вывалилась ошибка в LLVM.
Вообще это интересное решение, хотя и неоднозначное (ИМХО: поддержка именно длинных числовых литералов на уровне компилятора это правильно, а вот именование типов таким образом — не очень, лучше сделать честно через шаблонный тип). И почему ограничение 65535? Библиотеки типа GMP вроде бы таких ограничений не накладывают?
Строковые литералы
Это массивы символов (без завершающего нуля в конце). Для литералов с завершающим нулем применяется префикс 'c'.
const normal_bytes = "hello";
const null_terminated_bytes = c"hello";Аналогично большинству языков, Zig поддерживает стандартные escape-последовательности и вставку Unicode-символов через их коды (\uNNNN, \UNNNNNN где N — шестнадцатеричная цифра).
Многострочные литералы формируются с использованием двух обратных слэшей в начале каждой строки. При этом кавычки не требуются. То есть некоторая попытка сделать raw-строки, но ИМХО неудачная — преимущество raw-строк в том, что можно вставить в код любой кусок текста откуда угодно — и в идеале ничего не менять, а здесь придется в начале каждой строки добавлять \\.
const multiline =
\\#include <stdio.h>
\ \\int main(int argc, char **argv) {
\\ printf("hello world\n");
\\ return 0;
\\}
;Целочисленные литералы
Все как в си-подобных языках. Очень порадовало, что для восьмеричных литералов применяется префикс 0o, а не просто ноль как в Си. Также поддерживаются двоичные литералы с префиксом 0b. Литералы с плавающей точкой могут быть шестнадцатеричными (как это сделано в расширении GCC).
Операции
Конечно же присутствуют стандартные арифметические, логические и битовые операции Си. Поддерживаются сокращенные операции (+= и т.д.). Вместо && и || используются ключевые слова and и or. Интересный момент — дополнительно поддерживаются операции с гарантированной семантикой переполнения (wraparound semantics). Выглядят они вот так:
a +% b
a +%= bПри этом обычные арифметические операции не гарантируют переполнения и их результаты при переполнении считаются неопределенными (а для констант выдаются ошибки компиляции). ИМХО это немного странно, но судя по всему сделано из каких-то глубоких соображений совместимости с семантикой языка Си.
Массивы
Литералы массивов выглядят так:
const msg = []u8{ 'h', 'e', 'l', 'l', 'o' };
const arr = []i32{ 1, 2, 3, 4 };Строки являются массивами символов, как и в Си. Индексация классическая квадратными скобками. Предусмотрены операции сложения (конкатенации) и умножения массивов. Очень интересная штука, и если с конкатенацией все понятно, то умножение — я все ждал пока кто-то это реализует, и вот дождался:) В Ассемблере(!) есть такая операция dup, которая позволяет формировать повторяющиеся данные. Теперь и в Zig:
const one = []i32{ 1, 2, 3, 4 };
const two = []i32{ 5, 6, 7, 8 };
const c = one ++ two; // { 1,2,3,4,5,6,7,8 }
const pattern = "ab" ** 3; // "ababab"Указатели
Синтаксис похож на Си.
var x: i32 = 1234; // объект
const x_ptr = &x; // взятие адресаДля разыменования (взятия значения по указателю) используется непривычная постфиксная операция:
x_ptr.* == 5678;
x_ptr.* += 1;Тип указателя явно задается установкой звездочки перед именем типа
const x_ptr : *i32 = &x;Срезы (слайсы)
Встроенная в язык структура данных, позволяющая ссылаться на массив или его часть. Содержит указатель на первый элемент и количество элементов. Выглядит вот так:
var array = []i32{ 1, 2, 3, 4 };
const slice = array[0..array.len];Вроде бы это взято из Go, не уверен. И также я не уверен, стоило ли это встраивать в язык, при том что реализация в любом ООП-языке такой штуки весьма элементарна.
Структуры
Интересный способ объявления структуры: объявляется константа, тип которой автоматически выводится как «тИповый» (type), и именно она используется как имя структуры. А сама структура (struct) «безымянная».
const Point = struct {
x: f32,
y: f32,
};Привычным в си-подобных языках способом имя задать нельзя, однако компилятор выводит имя типа по определенным правилам — в частности, в рассмотренном выше случае оно будет совпадать с именем «тИповой» константы.
В общем случае язык не дает гарантий о порядке полей и их выравнивании в памяти. Если гарантии нужны — то следует использовать «упакованные» структуры
const Point2 = packed struct {
x: f32,
y: f32,
};Инициализация — в стиле сишных десигнаторов:
const p = Point {
.x = 0.12,
.y = 0.34,
};Структуры могут иметь методы. Однако размещение метода в структуре — это просто использование структуры как пространства имен; в отличие от С++, никаких неявных параметров this не передается.
Перечисления
В общем такие же как в С/С++. Есть некоторые удобные встроенные средства доступа к метаинформации, например к количеству полей и их именам, реализованные встроенными в язык синтаксическими макросами (которые в документации называются builtin functions).
Для «двоичной совместимсости с Си» предусмотрены некие extern enums.
Для указания типа, который должен лежать в основе перечисления, применяется конструкция вида
packed enum(u8)где u8 — базовый тип.
Перечисления могут иметь методы, подобно структурам (т.е. использовать имя перечисления как пространство имен).
Объединения (unions)
Насколько я понял, объединение в Zig является алгебраическим типом-суммой, т.е. содержит скрытое теговое поле, определяющее какое из полей объединения «активно». «Активация» другого поля производится полным переприсваиванием всего объединения. Пример из документации
const assert = @import("std").debug.assert;
const mem = @import("std").mem;
const Payload = union {
Int: i64,
Float: f64,
Bool: bool,
};
test "simple union" {
var payload = Payload {.Int = 1234};
// payload.Float = 12.34; // ОШИБКА! поле не активно
assert(payload.Int == 1234);
// переприсваиваем целиком для изменения активного поля
payload = Payload {.Float = 12.34};
assert(payload.Float == 12.34);
}Также объединения могут явно использовать перечисления для тега.
// Unions can be given an enum tag type:
const ComplexTypeTag = enum { Ok, NotOk };
const ComplexType = union(ComplexTypeTag) {
Ok: u8,
NotOk: void,
};Объединения, аналогично перечислениям и структурам, также могут предоставлять свое пространство имен для методов.
Опциональные типы
Zig имеет встроенную поддержку опционалов. Перед именем типа добавляется знак вопроса:
const normal_int: i32 = 1234; // normal integer
const optional_int: ?i32 = 5678; // optional integerИнтересно то, что в Zig реализована одна штука, о возможности которой я подозревал, но не был уверен, правильно ли это или нет. Указатели сделаны совместимыми с опционалами без добавления дополнительного скрытого поля («тега»), в котором хранится признак действительности значения; а в качестве недействительного значения используется null. Таким образом, ссылочные типы, представленные в Zig указателями, даже не требуют дополнительной памяти для «опциональности». При этом присваивание обычным указателям значения null запрещено.
Типы-ошибки
Подобны опциональным типам, но вместо булевского тега («действительно-недействительно») используется элемент перечисления, соответствующий коду ошибки. Синтаксис похож на опционалы, вместо вопросительного знака добавляется восклицательный. Таким образом, эти типы можно использовать например для возврата из функций: возвращается или объект-результат успешной работы функции, или ошибка с соответствующим кодом. Типы-ошибки являются важной частью системы обработки ошибок языка Zig, подробнее в разделе «Обработка ошибок».
Тип void
В Zig возможны переменные типа void и операции с ними
var x: void = {};
var y: void = {};
x = y;никакого кода для таких операций не генерируется; этот тип полезен главным образом для метапрограммирования.
Также имеется тип c_void для совмесимости с Си.
Управляющие операторы и фукнции
К ним относятся: блоки, switch, while, for, if, else, break, continue. Для группировки кода используются стандартные фигурные скобки. Просто блоки как и в С/С++ используются для ограничения области видимости переменных. Блоки могут рассматриваться как выражения. В языке нет goto, но есть метки, которые можно использовать с операторами break и continue. По умолчанию эти операторы работают с циклами, однако если у блока есть метка — то можно использовать ее.
var y: i32 = 123;
const x = blk: {
y += 1;
break :blk y; // прерывания блока blk и возврат y
};Оператор switch отличается от сишного тем, что в нем нет «fallthrough», т.е. исполняется только одно условие (case) и осуществляется выход из switch. Синтаксис более компактный: вместо case используется стрелка "=>". Switch также может рассматриваться как выражение.
Операторы while и if в целом такие же как во всех си-подобных языках. Оператор for больше похож на foreach. Все они могут рассматриваться как выражения. Из новых возможностей — while и for, также как и if, могут иметь блок else, который выполняется если не было ни одной итерации цикла.
И вот здесь пришло время рассказать об одной общей фиче для switch, while, которая в некотором роде позаимствована из концепции циклов foreach — «захвате» переменных. Выглядит это так:
while (eventuallyNullSequence()) |value| {
sum1 += value;
}
if (opt_arg) |value| {
assert(value == 0);
}
for (items[0..1]) |value| {
sum += value;
}
Здесь аргументом while является некий «источник» данных, который может быть опционалом, для for — массивом или срезом, а в переменной, находящейся между двух вертикальных линий оказывается «развернутое» значение — т.е. текущий элемент массива или среза (или указатель на него), внутреннее значение опционального типа (или указатель на него).
Операторы defer и errdefer
Оператор отложенного выполнения, позаимствованный из Go. Работает так же — аргумент этого оператора выполняется при выходе из области видимости, в которой использован оператор. Дополнительно предусмотрен оператор errdefer, который срабатывает в том случае, если из функции возвращается тип-ошибка с активным кодом ошибки. Это является частью оригинальной системы обработки ошибок в Zig.
Оператор unreachable
Элемент контрактного программирования. Специальное ключевое слово, которое ставится там, куда управление придти не должно ни при каких обстоятельствах. Если оно таки приходит туда, то в режимах Debug и ReleaseSafe генерируется паника, а в ReleaseFast оптимизатор выкидывает эти ветки полностью.
noreturn
Технически является типом, совместимым в выражениях с любым другим типом. Это возможно за счет того, что возврата объекта этого типа никогда не будет. Поскольку в Zig операторы являются выражениями, то нужен специальный тип для выражений, которые никогда не будут вычислены. Это происходит, когда правая часть выражения безвозвратно передает управление куда-то вовне. К таким операторам break, continue, return, unreachable, бесконечные циклы и функции, никогда не возвращающие управления. Для сравнения — вызов обычной функции (возвращающей управление) не является noreturn-оператором, потому что управление хоть и передается вовне, но рано или поздно будет возвращено в точку вызова.
Таким образом, становятся возможны такие выражения:
fn foo(condition: bool, b: u32) void {
const a = if (condition) b else return;
@panic("do something with a");
}Переменная a получает значение, возвращаемое оператором if/else. Для этого части (и if и else) должны возвращать выражение одного типа. Часть if возвращает bool, часть else — тип noreturn, который технически совместим с любым типом, в результате код компилируется без ошибок.
Функции
Синтаксис классический для языков подобного типа:
fn add(a: i8, b: i8) i8 {
return a + b;
}В целом функции выглядят довольно стандартно. Пока я не заметил признаков first-class functions, но мое знакомство с языком очень поверхностное, могу и ошибаться. Хотя возможно это пока не сделано.
Еще интересная особенность — в Zig игнорировать возвращаемые значения можно только явно с помощью подчеркивания _
_ = foo();Предусмотрена рефлексия, позволяющая получить различную информацию о функции
const assert = @import("std").debug.assert;
test "fn reflection" {
assert(@typeOf(assert).ReturnType == void); // тип возвращаемого значения
assert(@typeOf(assert).is_var_args == false); // переменное число аргументов
}Исполнение кода во время компиляции
В Zig предусмотрена мощнейшая возможность — выполнение кода, написанного на zig, во время компиляции. Для того чтобы код выполнился во время компиляции, достаточно заключить его в блок с ключевым словом comptime. Одну и ту же функцию можно вызывать как во время компиляции, так и во время выполнения, что позволяет писать универсальный код. Разумеется, есть некоторые ограничения, связанные с разными контекстами работы кода. Например, в документации во множестве примеров comptime используется для проверок времени компиляции:
// array literal
const message = []u8{ 'h', 'e', 'l', 'l', 'o' };
// get the size of an array
comptime {
assert(message.len == 5);
}Но конечно мощь этого оператора здесь раскрывается далеко не полностью. Так, в описании языка приведен классический пример эффективного применения синтаксических макросов — реализация функции аналогичной printf, но разбирающей форматную строку и проводящей все необходимые проверки типов аргументов на этапе компиляции.
Также слово comptime используется для указания параметров функций времени компиляции, что похоже на шаблонные функции С++.
параметры времени компиляции
fn max(comptime T: type, a: T, b: T) T {
return if (a > b) a else b;
}Обработка ошибок
В Zig придумана оригинальная, не похожая на другие языки система обработки ошибок. Это можно назвать «явными исключениями» (в этом языке явность вообще является одной из идиом). Это также похоже на коды возврата в Go, но устроено все иначе.
В основе системы обработки ошибок Zig лежат специальные перечисления для реализации собственных кодов ошибок (error) и построенные на их основе «типы-ошибки» (алгебраический тип-сумма, объединяющий возвращаемый тип функции и код ошибки).
Перечисления ошибок объявляюстся аналогично обычным перечислениям:
const FileOpenError = error {
AccessDenied,
OutOfMemory,
FileNotFound,
};
const AllocationError = error {
OutOfMemory,
};Однако, все коды ошибок получают значения больше нуля; также, если объявить в двух перечислениях код с одним и тем же именем, он получит одно и то же значение. Однако неявные преобразования между разными перечислениями ошибок запрещены.
Ключевое слово anyerror означает перечисление, включающее в себя все коды ошибок.
Подобно опциональным типам, язык поддерживает формирование типов-ошибок с помощью специального синтаксиса. Тип !u64 — это сокращенная форма anyerror!u64, которая в свою очередь означает объединение (вариант), включающее в себя тип u64 и тип anyerror (как я понимаю, код 0 зарезервирован для обозначения отсутствия ошибки и действительности поля данных, остальные коды — это собственно коды ошибок).
Ключевое слово catch позволяет перехватить ошибку и превращать ее в значение по умолчанию:
const number = parseU64(str, 10) catch 13;Так, если в функции parseU64, возвращающей тип !u64, возникнет ошибка, то catch «перехватит» ее и возвратит значение по умолчанию 13.
Ключевое слово try позволяет «пробрасывать» ошибку на верхний уровень (т.е. на уровень вызывающей функции). Код вида
fn doAThing(str: []u8) !void {
const number = try parseU64(str, 10);
// ...
}эквивалентен вот такому:
fn doAThing(str: []u8) !void {
const number = parseU64(str, 10) catch |err| return err;
// ...
}Здесь происходит следующее: вызывается parseU64, если из нее возвращается ошибка — она перехватывается оператором catch, в котором с помощью синтаксиса «захвата» извлекается код ошибки, помещается в переменную err, которая возвращается через !void в вызывающую функцию.
Также к обработке ошибок относится описанный ранее оператор errdefer. Код, являющийся аргуметом errdefer, выполняется только в том случае, если функция возвращает ошибку.
Еще некоторые возможности. С помощью оператора || можно сливать наборы ошибок
const A = error{
NotDir,
PathNotFound,
};
const B = error{
OutOfMemory,
PathNotFound,
};
const C = A || B;Еще Zig предоставляет такую возможность, как трассировка ошибок. Это нечто похожее на stack trace, но содержащая подробную информацию о том, какая ошибка возникла и как она распространялась по цепочке try от места возникновения до главной функции программы.
Таким образом, система обработки ошибок в Zig представляет собой весьма оригинальное решение, не похожее ни на исключения в C++, ни на коды возврата в Go. Можно сказать, что у такого решения есть определенная цена — дополнительные 4 байта, которые приходится возвращать вместе с каждым возвращаемым значением; очевидные преимущества — абсолютная явность и прозрачность. В отличие от С++, здесь функция не может выкинуть неизвестное исключение откуда-то из глубины цепочки вызовов. Все что возвращает функция — она возвращает явно и только явно.
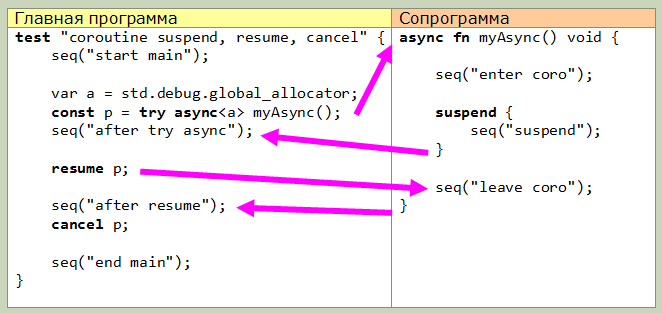
Сопрограммы
В Zig имеются встроенные сопрограммы. Это функции, которые создаются с ключевым словом async, с помощью которого передаются функции аллокатора и деаллокатора (как я понимаю, для дополнительного стека).
test "create a coroutine and cancel it" {
const p = try async<std.debug.global_allocator> simpleAsyncFn();
comptime assert(@typeOf(p) == promise->void);
cancel p;
assert(x == 2);
}
async<*std.mem.Allocator> fn simpleAsyncFn() void {
x += 1;
}async возвращает специальный объект типа promise->T (где T — возвращаемый тип функции). С помощью этого объекта можно управлять сопрограммой.
Наиболее низкий уровень предусматривает ключевых слова suspend, resume и cancel. С помощью suspend выполнение сопрограммы приостанавливается и передается в вызывающую программу. Возможен синтаксис блока suspend, все что внутри блока выполняется до фактической приостановки сопрограммы.
resume принимает аргумент типа promise->T и возобновляет выполнение сопрограммы с того места, на котором она была приостановлена.
cancel освобождает память сопрограммы.
На данной картинке показана передача управления между основной программой (в виде теста) и сопрограммой. Все достаточно просто:
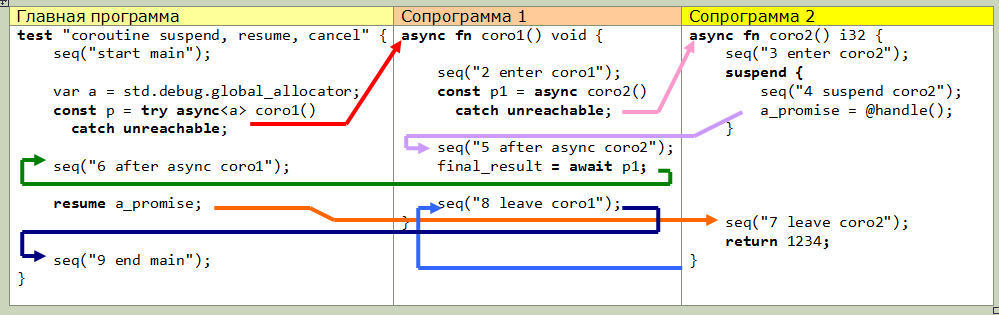
Вторая (более высокоуровневая) возможность — использование await. Это единственная вещь, с которой я, честно говоря, не разобрался (увы, документация пока весьма скудная). Вот фактическая диаграмма передачи управления немного модифицированного примера из документации, возможно вам это что нибудь объяснит:
Встроенные функции
builtin functions — достаточно большой набор функций, встроенных в язык и не требующих подключения каких либо модулей. Возможно, правильнее называть некоторые из них «встроенными синтаксическими макросами», потому что возможности многих выходят далеко за пределы функций. builtin'ы предоставляют доступ к средствам рефлексии (sizeOf, tagName, TagType, typeInfo, typeName, typeOf), с их помощью подкючаются модули (import). Другие больше похожи на классические builtin'ы C/C++ — они реализуют низкоуровневые преобразования типов, различные операции такие как sqrt, popCount, slhExact и т.п. Весьма вероятно, что перечень встроенных функций будет меняться по мере развития языка.
В завершение
Очень приятно что такие проекты появляются и развиваются. Язык Си хоть и является удобным, лаконичным и привычным для многих, все же устарел и по архитектурным причинам не может поддерживать многие современные концепции программирования. С++ развивается, но объективно переусложнен, с каждой новой версией становится все сложнее, и по тем же самым архитектурным причинам и из-за необходимости обратной совместимости с этим ничего нельзя поделать. Rust интересен, но с весьма высоким порогом вхождения, что не всегда оправдано. D — хорошая попытка, но довольно много мелких недочетов, складывается впечатление что изначально язык создавался скорее под впечатлением Java, а последующие фичи вводились уже как-то не так как следовало бы. Очевидно что Zig — еще одна такая попытка. Язык интересный, и интересно посмотреть что из него в итоге получится.
Комментарии (23)

worldmind
14.01.2019 20:10Все эти быстрые пороги вхождения уже проходили, раст хоть заявляется что решает проблемы с памятью, а тут больших киллер-фич не видать.
greabock
14.01.2019 21:51Так что там по киллер-фичам? Go — просто как топор, в Rust потокобезопасная концепция владения, и copiler-driven-development. Ну типа незнаю… должно же быть хоть что-то типа «гляди как могу!». )
MaM
14.01.2019 22:10+1Дженерик компаил тайм, это большая киллер фитча. Не знаю, есть ли тут бинды к аст, что бы еше код в компаил тайм генерить, если есть, то язык стоит внимания.
Tarik02
15.01.2019 10:29Компилятор пока что написан на C++, хотелось бы чтобы портировали на Zig. Тогда дальнейшее развитие будет легче идти.
DollaR84
14.01.2019 22:2265535 — это ограничение 16 бит, возможно отсюда.
А насчет срезов. Не знаю есть ли они в GO, но они точно есть в Python.
Возможно оттуда и взято.
А вообще интересно конечно, спасибо за обзор :)NeoCode
14.01.2019 23:26Именно 65535 бит. Почти 8К (без одного бита). Тут интересно почему не 65536, куда бит дели:)
DollaR84
15.01.2019 02:07Не, все правильно.
16 бит — это 65536 значений.
А эти значения в диапазоне:
от 0 до 65535.
А 65535 — это именно максимальное значение, которое можно представить в 16-битном целом числе.
Ну а число с 0 бит — то странное число было бы :)
nikbond
15.01.2019 10:06В Python использование синтаксиса слайсов на самом деле не создает слайс, а создает «настоящий» новый list.
Срез — это невладеющая структура данных, отображение настоящего массива. Т.е. изменения элементов среза также должно изменять оригинальный массив. В именно го так, а в Python не так.DollaR84
15.01.2019 14:53да, согласен с вами, не обратил внимание что влияние идет на исходный массив.

rafuck
15.01.2019 00:15Корутины, судя по вашему описанию, fullstack. Во второй диаграмме с ними подразумеваются некие глобальные переменные (a_promise)? Использование final_result вообще не видно. Она тоже глобальная?
Union в такой реализации вообще какие-то бесполезные получаются.
Понравилось перечисление как пространство имен. Но все равно хочется для переменной A типа enum вызвать A.isSomething(). В D это решается передачей A в качестве параметра в функцию isSomething насколько я помню.
Понравился подход к обработке ошибок.
P.S. А почему «идеологически верно» писать тип переменной после ее имени?DollaR84
15.01.2019 02:27P.S. А почему «идеологически верно» писать тип переменной после ее имени?
Мне вот тоже интересно.
С давних времен привык что везде тип переменной перед ее именем, и как-то совсем не понял почему перевернули наоборот.Sirikid
15.01.2019 03:27С давних пор так было только в Си, а «идеологически верно» потому что так парсить и читать проще.
rafuck
15.01.2019 05:13Парсить проще потому что двоеточие после идентификатора есть что ли?

NeoCode Автор
15.01.2019 12:21Как я понимаю современные тенденции, удобнее парсить когда в начале известное, а за ним новое имя. В c++ на это напоролись и пришлось вводить typename перед именами типов в некоторых случаях в шаблонах. Во всех языках последнего поколения пишут обычно
var x: type = value
Здесь var/let/const — всегда известное ключевое слово, дальше имя, а тип опционален ибо в тренде автоматический вывод типов.
DollaR84
15.01.2019 14:27Ну кроме C, также идет в:
C++, Objective C, Java.
Ну а насчет того что так читается проще — довольно субъективное утверждение, дело привычки, возможно и так наверно.

domix32
15.01.2019 12:22Идиоматически верно, потому что в большинстве случаев можно написать что-то вроде
const a = 3илиlet a = vec.map(Impl::doStuff).collect()и иже с ними и тип будет выведен компилятором автоматически.
NeoCode Автор
15.01.2019 21:19На картинке только часть кода, непосредственно относящаяся к корутинам. Переменные a_promise и final_result глобальные, функция seq выводит строку на экран, в отличие от оригинального примера, где она заполняет массив буквами, соответствующими точками вызова.
beeruser
15.01.2019 10:50Да он практически идеальный для миграции с С++. Ну всё, теперь можно валить :)
uvelichitel
Тоже заинтересовался и почитал документацию (которая, на мой взгляд, не вполне еще доработана). Нигде не нашел о типическом полиморфизме. Классы, подтипы, интерфейсы или конракты, такого рода концепции не предусмотрены? Как предпологается структурировать большие базы кода?