
Привет Хабр.
После публикации рейтинга статей за 2017 и 2018 год, следующая идея была очевидна — собрать обобщенный рейтинг за все годы. Но просто собрать ссылки было бы банально (хотя и тоже полезно), поэтому было решено расширить обработку данных и собрать еще немного полезной информации.

Рейтинги, статистика и немного исходного кода на Python под катом.
Те, кого сразу интересуют результаты, эту главу могут пропустить. А мы пока выясним, как это работает.
В качестве исходных данных имеется csv-файл примерно такого вида:
Индекс всех статей в таком виде занимает 42Мб, а для его сбора понадобилось примерно 10 дней работы скрипта на Raspberry Pi (закачка шла в один поток с паузами, чтобы не перегружать сервер). Теперь посмотрим, какие данные из всего этого можно извлечь.
Начнем с относительно простого — оценим аудиторию сайта за все годы. Для примерной оценки можно использовать количество комментариев к статьям. Загрузим данные и выведем график числа комментариев.
Данные выглядят примерно так:

Результат интересен — оказывается, с 2009 года активная аудитория сайта (те, кто оставляют к статьям комментарии) практически не растет. Хотя может все ИТ-шники просто уже здесь?
Раз уж речь зашла про аудиторию, интересно вспомнить последнее нововведение Хабра — добавление англоязычной версии сайта. Выведем статьи, имеющие "/en/" внутри ссылки.
Результат тоже интересный (масштаб по вертикали специально оставлен тем же):

Всплеск количества публикаций начался с 15 января 2019, когда был опубликован анонс Hello world! Or Habr in English, однако за несколько месяцев до этого 3 статьи уже были опубликованы: 1, 2 и 3. Вероятно, это было бета-тестирование?
Следующий интересный момент, которого мы не касались в предыдущих частях — это сопоставление идентификаторов статей и дат публикации. Каждая статья имеет ссылку вида habr.com/ru/post/N, нумерация статей сквозная, первая статья имеет идентификатор 1, а та которую вы читаете, 441740. Кажется, все просто. Но не совсем. Проверим соответствие дат и идентификаторов.
Загрузим файл в Pandas Dataframe, выделим даты и id, и построим их график:
Результат удивляет — идентификаторы берутся не всегда подряд, как предполагалось изначально, имеются заметные «выбросы».
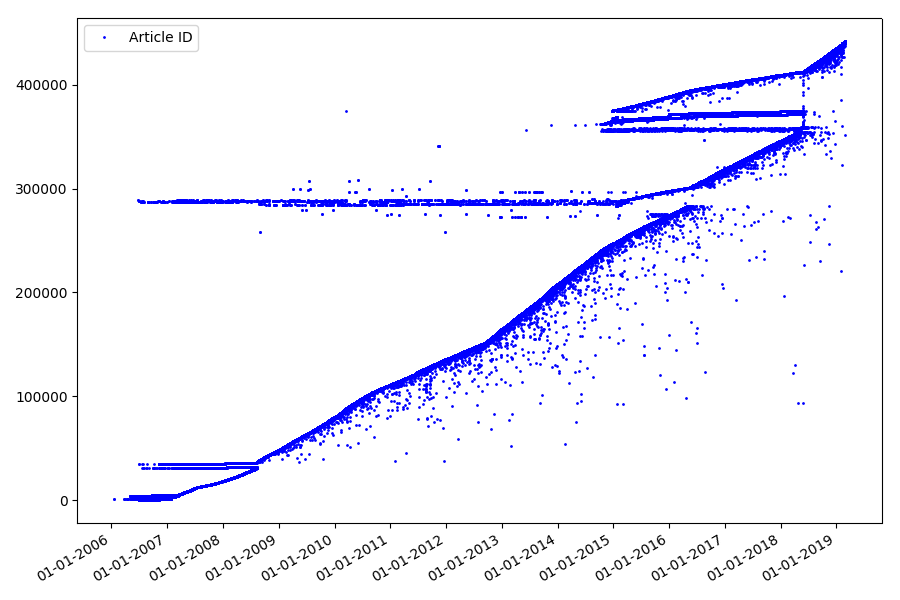
Отчасти именно из-за них у аудитории были вопросы к рейтингам за 2017 и 2018 годы — такие статьи с «неправильным» ID не учитывались парсером. Почему так, сказать сложно, да и не так важно.
Что может быть интересного в идентификаторах? Есть гипотеза, которую я не могу доказать формально, но которая кажется очевидной. Идентификатор присваивается в момент создания черновика статьи, а дата публикации очевидно, наступает позже. Кто-то выкладывает статью в тот же день, кто-то публикует материал позже. К чему все это? Расположим на оси Х идентификаторы, а по вертикали даты, и посмотрим фрагмент графика более подробно:
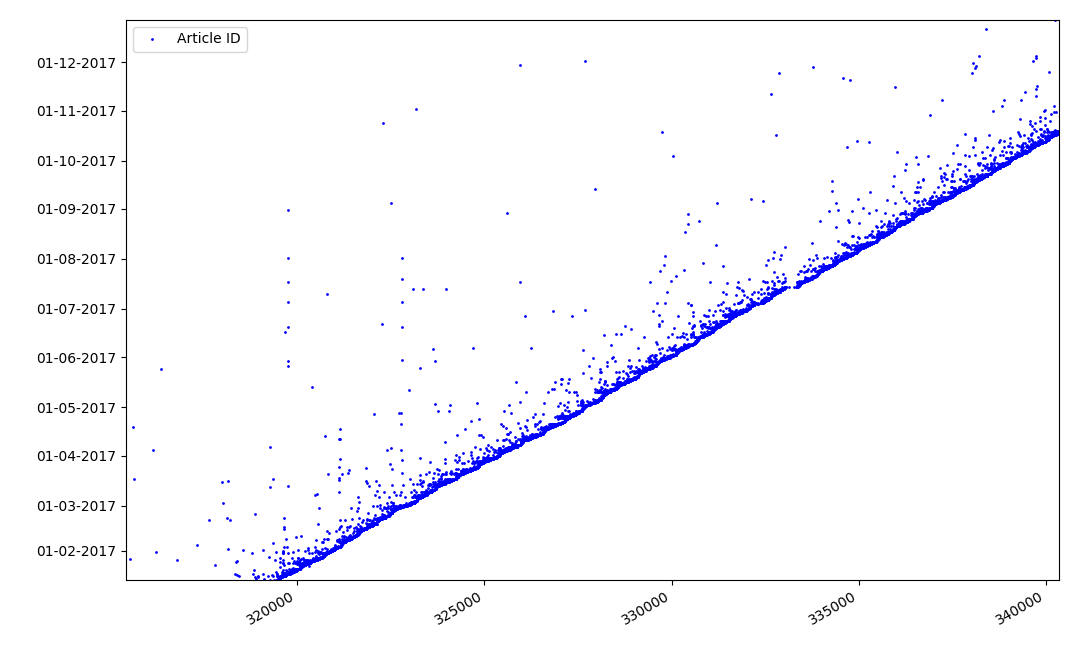
Результат — мы видим облако точек над сплошной линией, которое показывает нам распределение времени продолжительности создания статей. Как нетрудно видеть, максимум приходится на интервал до 1-2 недели. Почти вся масса статей создается не более чем за месяц, хотя некоторые статьи публикуются и через несколько месяцев после создания черновика (разумеется, это не гарантирует нам что автор работал над статьей несколько месяцев ежедневно, но результат все же вполне интересный).
Интересный, хотя и интуитивно понятный момент — время публикации статей.
Выведем статистику по рабочим дням:
Зависимость количества статей от времени публикации в будние дни:
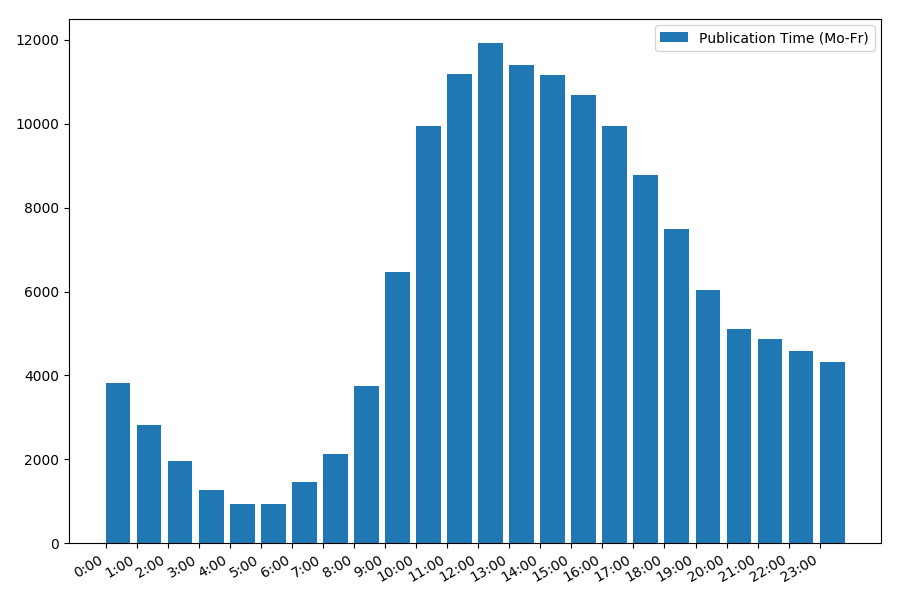
Картинка интересна, большинство публикаций приходится на рабочее время. Все же интересно, для большинства авторов написание статей это основная работа, или они просто занимаются этим в рабочее время? ;) А вот график распределения в выходные дни дает другую картину:
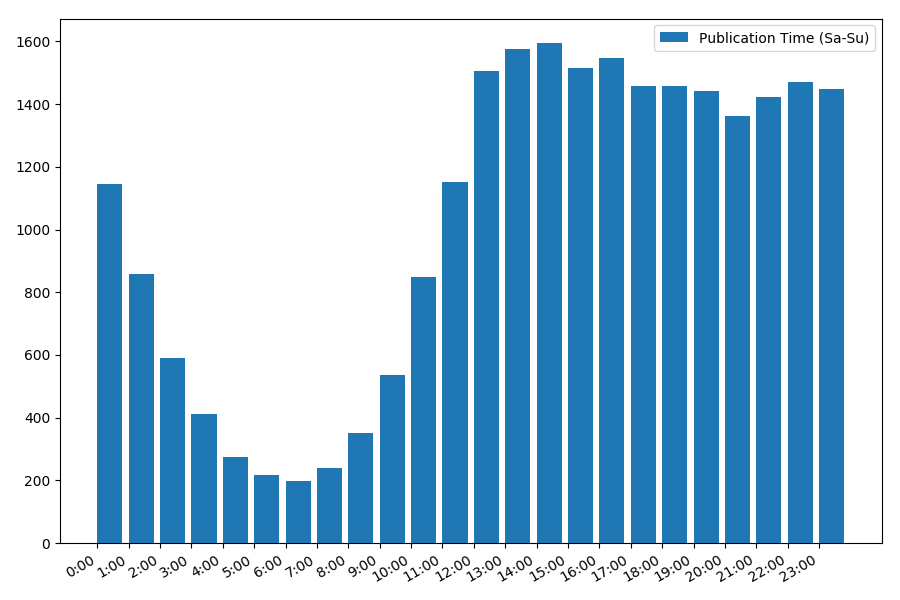
Раз уж речь зашла о дате и времени, посмотрим среднее значение просмотров и количество статей по дням недели.
Результат интересен:
Как можно видеть, в выходные публикуется заметно меньше статей. Но зато каждая статья набирает больше просмотров, так что публиковать статьи в выходные кажется довольно-таки целесообразным (как было выяснено еще в первой части, активный жизненный цикл статьи не более 3-4х дней, так что первые пара дней являются вполне критичными).
Статья пожалуй, получается слишком длинной. Окончание во второй части.
После публикации рейтинга статей за 2017 и 2018 год, следующая идея была очевидна — собрать обобщенный рейтинг за все годы. Но просто собрать ссылки было бы банально (хотя и тоже полезно), поэтому было решено расширить обработку данных и собрать еще немного полезной информации.
Рейтинги, статистика и немного исходного кода на Python под катом.
Обработка данных
Те, кого сразу интересуют результаты, эту главу могут пропустить. А мы пока выясним, как это работает.
В качестве исходных данных имеется csv-файл примерно такого вида:
datetime,link,title,votes,up,down,bookmarks,views,comments
2006-07-13T14:23Z,https://habr.com/ru/post/1/,"Wiki-FAQ для Хабрахабра",votes:1,votesplus:1,votesmin:0,bookmarks:8,views:28300,comments:56
2006-07-13T20:45Z,https://habr.com/ru/post/2/,"Мы знаем много недоделок на сайте… но!",votes:1,votesplus:1,votesmin:0,bookmarks:1,views:14600,comments:37
...
2019-01-25T03:47Z,https://habr.com/ru/post/435118/,"Save File Me — бесплатный сервис бэкапов с шифрованием на стороне клиента",votes:5,votesplus:5,votesmin:0,bookmarks:26,views:1800,comments:6
2019-01-08T03:09Z,https://habr.com/ru/post/435120/,"Lambda-функции в SQL… дайте подумать",votes:9,votesplus:13,votesmin:4,bookmarks:63,views:5700,comments:30
Индекс всех статей в таком виде занимает 42Мб, а для его сбора понадобилось примерно 10 дней работы скрипта на Raspberry Pi (закачка шла в один поток с паузами, чтобы не перегружать сервер). Теперь посмотрим, какие данные из всего этого можно извлечь.
Аудитория сайта
Начнем с относительно простого — оценим аудиторию сайта за все годы. Для примерной оценки можно использовать количество комментариев к статьям. Загрузим данные и выведем график числа комментариев.
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv(log_path, sep=',', encoding='utf-8', error_bad_lines=True, quotechar='"', comment='#')
def to_int(s):
# "bookmarks:22" => 22
num = ''.join(i for i in s if i.isdigit())
return int(num)
dates = pd.to_datetime(df['datetime'], format='%Y-%m-%dT%H:%MZ')
dates += datetime.timedelta(hours=3)
comments = df["comments"].map(to_int, na_action=None)
plt.rcParams["figure.figsize"] = (9, 6)
fig, ax = plt.subplots()
plt.plot(dates, comments, 'go', markersize=1, label='Comments')
ax.xaxis.set_major_locator(mdates.YearLocator())
plt.ylim(bottom=0, top=1000)
plt.legend(loc='best')
fig.autofmt_xdate()
plt.tight_layout()
plt.show()
Данные выглядят примерно так:
Результат интересен — оказывается, с 2009 года активная аудитория сайта (те, кто оставляют к статьям комментарии) практически не растет. Хотя может все ИТ-шники просто уже здесь?
Раз уж речь зашла про аудиторию, интересно вспомнить последнее нововведение Хабра — добавление англоязычной версии сайта. Выведем статьи, имеющие "/en/" внутри ссылки.
df = df[df['link'].str.contains("/en/")]Результат тоже интересный (масштаб по вертикали специально оставлен тем же):
Всплеск количества публикаций начался с 15 января 2019, когда был опубликован анонс Hello world! Or Habr in English, однако за несколько месяцев до этого 3 статьи уже были опубликованы: 1, 2 и 3. Вероятно, это было бета-тестирование?
Идентификаторы
Следующий интересный момент, которого мы не касались в предыдущих частях — это сопоставление идентификаторов статей и дат публикации. Каждая статья имеет ссылку вида habr.com/ru/post/N, нумерация статей сквозная, первая статья имеет идентификатор 1, а та которую вы читаете, 441740. Кажется, все просто. Но не совсем. Проверим соответствие дат и идентификаторов.
Загрузим файл в Pandas Dataframe, выделим даты и id, и построим их график:
df = pd.read_csv(log_path, header=None, names=['datetime', 'votes', 'bookmarks', 'views', 'comments'])
dates = pd.to_datetime(df['datetime'], format='%Y-%m-%dT%H:%M:%S.%f')
dates += datetime.timedelta(hours=3)
df['datetime'] = dates
def link2id(link):
# https://habr.com/ru/post/345936/ => 345936
if link[-1] == '/': link = link[0:-1]
return int(link.split('/')[-1])
df['id'] = df["link"].map(link2id, na_action=None)
plt.rcParams["figure.figsize"] = (9, 6)
fig, ax = plt.subplots()
plt.plot(df_ids['id'], df_ids['datetime'], 'bo', markersize=1, label='Article ID')
ax.yaxis.set_major_formatter(mdates.DateFormatter("%d-%m-%Y"))
ax.yaxis.set_major_locator(mdates.MonthLocator())
plt.legend(loc='best')
fig.autofmt_xdate()
plt.tight_layout()
plt.show()
Результат удивляет — идентификаторы берутся не всегда подряд, как предполагалось изначально, имеются заметные «выбросы».
Отчасти именно из-за них у аудитории были вопросы к рейтингам за 2017 и 2018 годы — такие статьи с «неправильным» ID не учитывались парсером. Почему так, сказать сложно, да и не так важно.
Что может быть интересного в идентификаторах? Есть гипотеза, которую я не могу доказать формально, но которая кажется очевидной. Идентификатор присваивается в момент создания черновика статьи, а дата публикации очевидно, наступает позже. Кто-то выкладывает статью в тот же день, кто-то публикует материал позже. К чему все это? Расположим на оси Х идентификаторы, а по вертикали даты, и посмотрим фрагмент графика более подробно:
Результат — мы видим облако точек над сплошной линией, которое показывает нам распределение времени продолжительности создания статей. Как нетрудно видеть, максимум приходится на интервал до 1-2 недели. Почти вся масса статей создается не более чем за месяц, хотя некоторые статьи публикуются и через несколько месяцев после создания черновика (разумеется, это не гарантирует нам что автор работал над статьей несколько месяцев ежедневно, но результат все же вполне интересный).
Дата и время публикации
Интересный, хотя и интуитивно понятный момент — время публикации статей.
Выведем статистику по рабочим дням:
print("Group by hour (average, working days):")
df_workdays = df[(df['day'] < 5)]
g = df_workdays.groupby(['hour'])
hour_count = g.size().reset_index(name='counts')
grouped = g.median().reset_index()
grouped['counts'] = hour_count['counts']
print(grouped[['hour', 'counts', 'views', 'comments', 'votes', 'votesperview']])
print()
view_hours = grouped['hour'].values
view_hours_avg = grouped['counts'].values
fig, ax = plt.subplots()
plt.bar(view_hours, view_hours_avg, align='edge', label='Publication Time (Mo-Fr)')
ax.set_xticks(range(24))
ax.xaxis.set_major_formatter(FormatStrFormatter('%d:00'))
plt.legend(loc='best')
fig.autofmt_xdate()
plt.tight_layout()
plt.show()
Зависимость количества статей от времени публикации в будние дни:
Картинка интересна, большинство публикаций приходится на рабочее время. Все же интересно, для большинства авторов написание статей это основная работа, или они просто занимаются этим в рабочее время? ;) А вот график распределения в выходные дни дает другую картину:
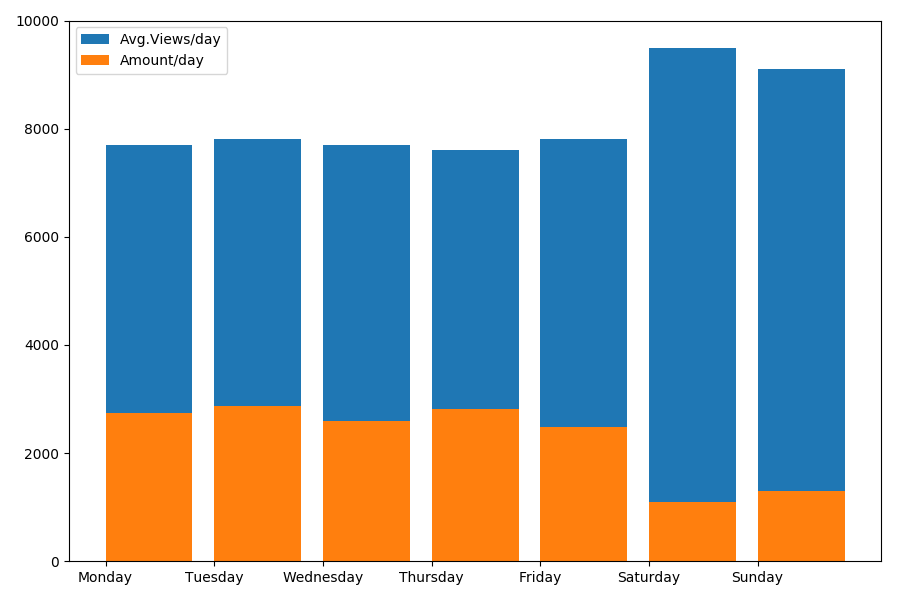
Раз уж речь зашла о дате и времени, посмотрим среднее значение просмотров и количество статей по дням недели.
g = df.groupby(['day', 'dayofweek'])
dayofweek_count = g.size().reset_index(name='counts')
grouped = g.median().reset_index()
grouped['counts'] = dayofweek_count['counts']
grouped.sort_values('day', ascending=False)
print(grouped[['day', 'dayofweek', 'counts', 'views', 'comments', 'votes', 'votesperview']])
print()
view_days = grouped['day'].values
view_per_day = grouped['views'].values
counts_per_day = grouped['counts'].values
days_of_week = grouped['dayofweek'].values
plt.bar(view_days, view_per_day, align='edge', label='Avg.Views/day')
plt.bar(view_days, counts_per_day, align='edge', label='Amount/day')
plt.xticks(view_days, days_of_week)
plt.ylim(bottom=0, top=10000)
plt.show()
Результат интересен:
Как можно видеть, в выходные публикуется заметно меньше статей. Но зато каждая статья набирает больше просмотров, так что публиковать статьи в выходные кажется довольно-таки целесообразным (как было выяснено еще в первой части, активный жизненный цикл статьи не более 3-4х дней, так что первые пара дней являются вполне критичными).
Статья пожалуй, получается слишком длинной. Окончание во второй части.
Slavik_Kenny
Мне кажется не совсем корректно учитывать время без привязки к часовому поясу пользователя. То что попадает в рабочее время по мнению хабра для многих таковым уже не является.
Хотя вот вам еще идея для интересного пункта статистики — показать на карте географию расположения авторов, так скажем оценить самые продуктивные регионы :)
DmitrySpb79 Автор
Сервер отдает время публикации в GMT, +3 добавлялось для удобства просмотра.
Как раз, четкий пик с 10 до 17 говорит о том, что большинство авторов находятся в московском часовом поясе :) Хотя кто-то и ночью выкладывает, да.
Координаты авторов в статьях не хранятся, хотя вывести было бы интересно, да.
Slavik_Kenny
Или большинство авторов имеет часовой пояс GMT, +4 и больше и выкладывает статьи после работы — нельзя ни одно из наших утверждений считать правильным, т.к. никто не проверяет часовой пояс авторов, но большая часть страны живет не по московскому времени все-таки, логичней предположить что время чаще отличается.
Это не придирка, просто указание на возможность неверных выводов.
Но у многих город указан в профиле, заодно и статистика по заполненности этого параметра будет :)
sanmon1985
бОльшая часть по населению все же живет по московскому времени
smind
Нужно иметь ввиду что основная часть обитателей Рунета расположена всё-таки более менее компактно в европейской части Евразии, хотя Россия и огромная страна и есть крупные города за Уралом но это скорее проценты чем десятки процентов аудитории.
Slavik_Kenny
не десятки процентов а только проценты? Слишком категоричное утверждение по меньшей мере…
smind
Вы попробуйте к каждому часовому поясу добавить количество жителей этого пояса.
Slavik_Kenny
Для того чтобы ваше высказывание было правдой в часовом поясе Москвы должен проживать 91% населения России, что по любым источникам не соответствует действительности, так что авторов, у которых часовой пояс отличается от GMT+3 намного больше чем «проценты». При этом не стоит забывать, что не все авторы проживают на территории России, а значит часовых поясов намного больше различных.
tyomitch
Для того, чтобы высказывание smind было правдой, в часовом поясе Москвы должны проживать 91% посетителей Хабра. То, что плотность российских айтишников распределена ещё более неравномерно, чем плотность россиян вообще — ни для кого не секрет.
Slavik_Kenny
А что-бы совсем было верно, то должны проживать 91% авторов Хабра :)
smind
Эт прям Вы меня заставили покапаться в данных. Итак, за Уралом живет примерно 29млн это примерно 20% от населения России.
Это если не учитывать Украину и Белоруссию.
Slavik_Kenny
А почему вы так упорно цепляетесь к территории «за Уралом»? Сам Урал это уже другой часовой пояс, причем не на один час разница даже, а на два, так что и некоторые территории до Урала уже отличаются по времени от Москвы.
В любом случае спор не о чем, т.к. не все заполняют эту информацию в профиле, да и вообще никто не будет это проверять :)
smind
я с Вами и не спорю, прокомментировал Вашу фразу
и что на выкладки топикстартера никак не повлияет учет разных часовых поясов, т.к. это лишь проценты от общей массы постов, далее я на реальных цифрах показал что это действительно так.
Quarc
Карта слегка устарела, т.к. точно знаю, что время в Новосибирске, Томске и Горно-Алтайске совпадает с Красноярском, вероятно то же верно и для Барнаула с Кемеровом, т.е. желтого пятна более нету.
Slavik_Kenny
в любом случае время отличается от МСК, а речь об этом.
tyomitch
Не только «жёлтого пятна» больше нету — успел поменяться пояс чуть ли не в половине всех субъектов РФ:
