
Предисловие
Довольно часто пользователи, разработчики и администраторы СУБД MS SQL Server сталкиваются с проблемами производительности БД или СУБД в целом, поэтому весьма актуальным является мониторинг MS SQL Server.
Данная статья является дополнением к статье Использование Zabbix для слежения за базой данных MS SQL Server и в ней будут разобраны некоторые аспекты мониторинга MS SQL Server, в частности: как быстро определить, каких ресурсов не хватает, а также рекомендации по настройке флагов трассировки.
Для работы следующих приведенных скриптов, необходимо создать схему inf в нужной базе данных следующим образом:
use <имя_БД>;
go
create schema inf;Метод выявления нехватки оперативной памяти
Первым показателем нехватки оперативной памяти является тот случай, когда экземпляр MS SQL Server съедает всю выделенную ему ОЗУ.
Для этого создадим следующее представление inf.vRAM:
CREATE view [inf].[vRAM] as
select a.[TotalAvailOSRam_Mb] --сколько свободно ОЗУ на сервере в МБ
, a.[RAM_Avail_Percent] --процент свободного ОЗУ на сервере
, a.[Server_physical_memory_Mb] --сколько всего ОЗУ на сервере в МБ
, a.[SQL_server_committed_target_Mb] --сколько всего ОЗУ выделено под MS SQL Server в МБ
, a.[SQL_server_physical_memory_in_use_Mb] --сколько всего ОЗУ потребляет MS SQL Server в данный момент времени в МБ
, a.[SQL_RAM_Avail_Percent] --поцент свободного ОЗУ для MS SQL Server относительно всего выделенного ОЗУ для MS SQL Server
, a.[StateMemorySQL] --достаточно ли ОЗУ для MS SQL Server
, a.[SQL_RAM_Reserve_Percent] --процент выделенной ОЗУ для MS SQL Server относительно всего ОЗУ сервера
--достаточно ли ОЗУ для сервера
, (case when a.[RAM_Avail_Percent]<10 and a.[RAM_Avail_Percent]>5 and a.[TotalAvailOSRam_Mb]<8192 then 'Warning' when a.[RAM_Avail_Percent]<=5 and a.[TotalAvailOSRam_Mb]<2048 then 'Danger' else 'Normal' end) as [StateMemoryServer]
from
(
select cast(a0.available_physical_memory_kb/1024.0 as int) as TotalAvailOSRam_Mb
, cast((a0.available_physical_memory_kb/casT(a0.total_physical_memory_kb as float))*100 as numeric(5,2)) as [RAM_Avail_Percent]
, a0.system_low_memory_signal_state
, ceiling(b.physical_memory_kb/1024.0) as [Server_physical_memory_Mb]
, ceiling(b.committed_target_kb/1024.0) as [SQL_server_committed_target_Mb]
, ceiling(a.physical_memory_in_use_kb/1024.0) as [SQL_server_physical_memory_in_use_Mb]
, cast(((b.committed_target_kb-a.physical_memory_in_use_kb)/casT(b.committed_target_kb as float))*100 as numeric(5,2)) as [SQL_RAM_Avail_Percent]
, cast((b.committed_target_kb/casT(a0.total_physical_memory_kb as float))*100 as numeric(5,2)) as [SQL_RAM_Reserve_Percent]
, (case when (ceiling(b.committed_target_kb/1024.0)-1024)<ceiling(a.physical_memory_in_use_kb/1024.0) then 'Warning' else 'Normal' end) as [StateMemorySQL]
from sys.dm_os_sys_memory as a0
cross join sys.dm_os_process_memory as a
cross join sys.dm_os_sys_info as b
cross join sys.dm_os_sys_memory as v
) as a;
Тогда определить то, что экземпляр MS SQL Server потребляет всю выделенную ему память можно следующим запросом:
select SQL_server_physical_memory_in_use_Mb, SQL_server_committed_target_Mb
from [inf].[vRAM];
Если показатель SQL_server_physical_memory_in_use_Mb постоянно не меньше SQL_server_committed_target_Mb, то необходимо проверить статистику ожиданий.
Для определения нехватки оперативной памяти через статистику ожиданий создадим представление inf.vWaits:
CREATE view [inf].[vWaits] as
WITH [Waits] AS
(SELECT
[wait_type], --имя типа ожидания
[wait_time_ms] / 1000.0 AS [WaitS],--Общее время ожидания данного типа в миллисекундах. Это время включает signal_wait_time_ms
([wait_time_ms] - [signal_wait_time_ms]) / 1000.0 AS [ResourceS],--Общее время ожидания данного типа в миллисекундах без signal_wait_time_ms
[signal_wait_time_ms] / 1000.0 AS [SignalS],--Разница между временем сигнализации ожидающего потока и временем начала его выполнения
[waiting_tasks_count] AS [WaitCount],--Число ожиданий данного типа. Этот счетчик наращивается каждый раз при начале ожидания
100.0 * [wait_time_ms] / SUM ([wait_time_ms]) OVER() AS [Percentage],
ROW_NUMBER() OVER(ORDER BY [wait_time_ms] DESC) AS [RowNum]
FROM sys.dm_os_wait_stats
WHERE [waiting_tasks_count]>0
and [wait_type] NOT IN (
N'BROKER_EVENTHANDLER', N'BROKER_RECEIVE_WAITFOR',
N'BROKER_TASK_STOP', N'BROKER_TO_FLUSH',
N'BROKER_TRANSMITTER', N'CHECKPOINT_QUEUE',
N'CHKPT', N'CLR_AUTO_EVENT',
N'CLR_MANUAL_EVENT', N'CLR_SEMAPHORE',
N'DBMIRROR_DBM_EVENT', N'DBMIRROR_EVENTS_QUEUE',
N'DBMIRROR_WORKER_QUEUE', N'DBMIRRORING_CMD',
N'DIRTY_PAGE_POLL', N'DISPATCHER_QUEUE_SEMAPHORE',
N'EXECSYNC', N'FSAGENT',
N'FT_IFTS_SCHEDULER_IDLE_WAIT', N'FT_IFTSHC_MUTEX',
N'HADR_CLUSAPI_CALL', N'HADR_FILESTREAM_IOMGR_IOCOMPLETION',
N'HADR_LOGCAPTURE_WAIT', N'HADR_NOTIFICATION_DEQUEUE',
N'HADR_TIMER_TASK', N'HADR_WORK_QUEUE',
N'KSOURCE_WAKEUP', N'LAZYWRITER_SLEEP',
N'LOGMGR_QUEUE', N'ONDEMAND_TASK_QUEUE',
N'PWAIT_ALL_COMPONENTS_INITIALIZED',
N'QDS_PERSIST_TASK_MAIN_LOOP_SLEEP',
N'QDS_CLEANUP_STALE_QUERIES_TASK_MAIN_LOOP_SLEEP',
N'REQUEST_FOR_DEADLOCK_SEARCH', N'RESOURCE_QUEUE',
N'SERVER_IDLE_CHECK', N'SLEEP_BPOOL_FLUSH',
N'SLEEP_DBSTARTUP', N'SLEEP_DCOMSTARTUP',
N'SLEEP_MASTERDBREADY', N'SLEEP_MASTERMDREADY',
N'SLEEP_MASTERUPGRADED', N'SLEEP_MSDBSTARTUP',
N'SLEEP_SYSTEMTASK', N'SLEEP_TASK',
N'SLEEP_TEMPDBSTARTUP', N'SNI_HTTP_ACCEPT',
N'SP_SERVER_DIAGNOSTICS_SLEEP', N'SQLTRACE_BUFFER_FLUSH',
N'SQLTRACE_INCREMENTAL_FLUSH_SLEEP',
N'SQLTRACE_WAIT_ENTRIES', N'WAIT_FOR_RESULTS',
N'WAITFOR', N'WAITFOR_TASKSHUTDOWN',
N'WAIT_XTP_HOST_WAIT', N'WAIT_XTP_OFFLINE_CKPT_NEW_LOG',
N'WAIT_XTP_CKPT_CLOSE', N'XE_DISPATCHER_JOIN',
N'XE_DISPATCHER_WAIT', N'XE_TIMER_EVENT')
)
, ress as (
SELECT
[W1].[wait_type] AS [WaitType],
CAST ([W1].[WaitS] AS DECIMAL (16, 2)) AS [Wait_S],--Общее время ожидания данного типа в миллисекундах. Это время включает signal_wait_time_ms
CAST ([W1].[ResourceS] AS DECIMAL (16, 2)) AS [Resource_S],--Общее время ожидания данного типа в миллисекундах без signal_wait_time_ms
CAST ([W1].[SignalS] AS DECIMAL (16, 2)) AS [Signal_S],--Разница между временем сигнализации ожидающего потока и временем начала его выполнения
[W1].[WaitCount] AS [WaitCount],--Число ожиданий данного типа. Этот счетчик наращивается каждый раз при начале ожидания
CAST ([W1].[Percentage] AS DECIMAL (5, 2)) AS [Percentage],
CAST (([W1].[WaitS] / [W1].[WaitCount]) AS DECIMAL (16, 4)) AS [AvgWait_S],
CAST (([W1].[ResourceS] / [W1].[WaitCount]) AS DECIMAL (16, 4)) AS [AvgRes_S],
CAST (([W1].[SignalS] / [W1].[WaitCount]) AS DECIMAL (16, 4)) AS [AvgSig_S]
FROM [Waits] AS [W1]
INNER JOIN [Waits] AS [W2]
ON [W2].[RowNum] <= [W1].[RowNum]
GROUP BY [W1].[RowNum], [W1].[wait_type], [W1].[WaitS],
[W1].[ResourceS], [W1].[SignalS], [W1].[WaitCount], [W1].[Percentage]
HAVING SUM ([W2].[Percentage]) - [W1].[Percentage] < 95 -- percentage threshold
)
SELECT [WaitType]
,MAX([Wait_S]) as [Wait_S]
,MAX([Resource_S]) as [Resource_S]
,MAX([Signal_S]) as [Signal_S]
,MAX([WaitCount]) as [WaitCount]
,MAX([Percentage]) as [Percentage]
,MAX([AvgWait_S]) as [AvgWait_S]
,MAX([AvgRes_S]) as [AvgRes_S]
,MAX([AvgSig_S]) as [AvgSig_S]
FROM ress
group by [WaitType];
В этом случае определить нехватку оперативной памяти можно следующим запросом:
SELECT [Percentage]
,[AvgWait_S]
FROM [inf].[vWaits]
where [WaitType] in (
'PAGEIOLATCH_XX',
'RESOURCE_SEMAPHORE',
'RESOURCE_SEMAPHORE_QUERY_COMPILE'
);
Здесь нужно обратить внимание на показатели Percentage и AvgWait_S. Если они существенны по своей совокупности, то есть очень большая вероятность того, что оперативной памяти не хватает экземпляру MS SQL Server. Существенные значения определяются индивидуально для каждой системы. Однако, можно начинать со следующего показателя: Percentage>=1 и AvgWait_S>=0.005.
Для вывода показателей в систему мониторинга (например, Zabbix) можно создать следующие два запроса:
- сколько в процентах занимают типы ожиданий по ОЗУ (сумма по всем таким типам ожиданий):
select coalesce(sum([Percentage]), 0.00) as [Percentage] from [inf].[vWaits] where [WaitType] in ( 'PAGEIOLATCH_XX', 'RESOURCE_SEMAPHORE', 'RESOURCE_SEMAPHORE_QUERY_COMPILE' ); - сколько в миллисекундах занимают типы ожиданий по ОЗУ (максимальное значение из всех средних задержек по всем таким типам ожиданий):
select coalesce(max([AvgWait_S])*1000, 0.00) as [AvgWait_MS] from [inf].[vWaits] where [WaitType] in ( 'PAGEIOLATCH_XX', 'RESOURCE_SEMAPHORE', 'RESOURCE_SEMAPHORE_QUERY_COMPILE' );
Исходя из динамики полученных значений по этим двум показателям, можно сделать вывод достаточно ли ОЗУ для экземпляра MS SQL Server.
Метод выявления чрезмерной нагрузки на ЦПУ
Для выявления нехватки процессорного времени достаточно воспользоваться системным представлением sys.dm_os_schedulers. Здесь, если показатель runnable_tasks_count постоянно больше 1, то существует большая вероятность того, что количество ядер не хватает экземпляру MS SQL Server.
Для вывода показателя в систему мониторинга (например, Zabbix) можно создать следующий запрос:
select max([runnable_tasks_count]) as [runnable_tasks_count]
from sys.dm_os_schedulers
where scheduler_id<255;
Исходя из динамики полученных значений по данному показателю, можно сделать вывод достаточно ли процессорного времени (количества ядер ЦПУ) для экземпляра MS SQL Server.
Однако, важно помнить о том факте, что сами запросы могут запрашивать сразу несколько потоков. И порой оптимизатор не может верно оценить сложность самого запроса. Тогда запросу могут быть выделено слишком много потоков, которые в данный момент времени не могут быть обработаны одновременно. И это тоже вызывает тип ожидания, связанный с нехваткой процессорного времени, и разрастания очереди на планировщики, которые используют конкретные ядра ЦПУ, т е показатель runnable_tasks_count в таких условиях будет расти.
В таком случае перед тем как увеличивать количество ядер ЦПУ, необходимо правильно настроить свойства параллелизма самого экземпляра MS SQL Server, а с 2016 версии-правильно настроить свойства параллелизма нужных баз данных:

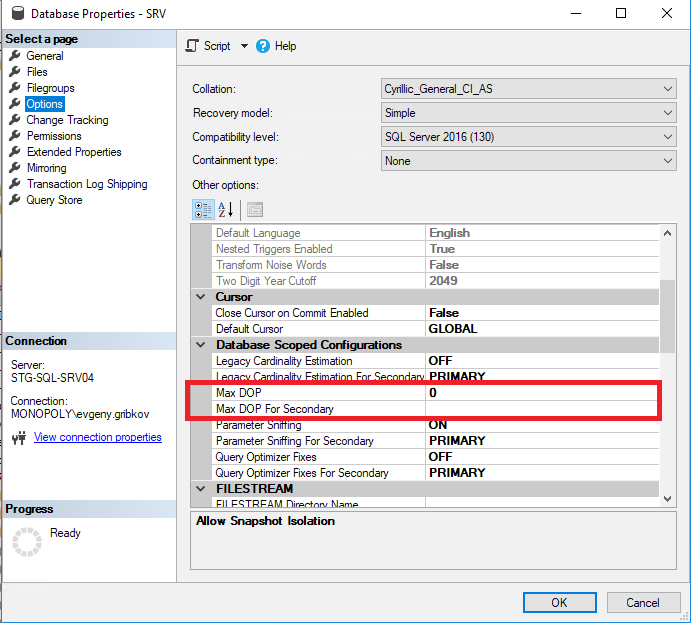
Здесь стоит обратить внимания на следующие параметры:
- Max Degree of Parallelism-задает максимальное количество потоков, которые могут быть выделены каждому запросу (по умолчанию стоит 0-ограничение только самой операционной системой и редакцией MS SQL Server)
- Cost Threshold for Parallelism-оценочная стоимость параллелизма (по умолчанию стоит 5)
- Max DOP-задает максимальное количество потоков, которые могут быть выделены каждому запросу на уровне базы данных (но не более, чем значение свойства «Max Degree of Parallelism») (по умолчанию стоит 0-ограничение только самой операционной системой и редакцией MS SQL Server, а также ограничение по свойству «Max Degree of Parallelism» всего экземпляра MS SQL Server)
Здесь невозможно дать одинаково хороший рецепт для всех случаев, т е нужно анализировать тяжелые запросы.
По собственному опыту рекомендую следующий алгоритм действий для OLTP-систем для настройки свойств параллелизма:
- сначала запретить параллелизм, выставив на уровне всего экземпляра Max Degree of Parallelism в 1
- проанализировать самые тяжелые запросы и подобрать для них оптимальное количество потоков
- выставить Max Degree of Parallelism в подобранное оптимальное количество потоков, полученное из п.2, а также для конкретных баз данных выставить Max DOP значение, полученное из п.2 для каждой базы данных
- проанализировать самые тяжелые запросы и выявить негативный эффект от многопоточности. Если он есть, то повышать Cost Threshold for Parallelism.
Для таких систем как 1С, Microsoft CRM и Microsoft NAV в большинстве случаев подойдет запрет многопоточности
Также если стоит редакция Standard, то в большинстве случаев подойдет запрет многопоточности в виду того факта, что данная редакция ограничена по количеству ядер ЦПУ.
Для OLAP-систем описанный выше алгоритм не подходит.
По собственному опыту рекомендую следующий алгоритм действий для OLAP-систем для настройки свойств параллелизма:
- проанализировать самые тяжелые запросы и подобрать для них оптимальное количество потоков
- выставить Max Degree of Parallelism в подобранное оптимальное количество потоков, полученное из п.1, а также для конкретных баз данных выставить Max DOP значение, полученное из п.1 для каждой базы данных
- проанализировать самые тяжелые запросы и выявить негативный эффект от ограничения параллелизма. Если он есть, то либо понижать значение Cost Threshold for Parallelism, либо повторить шаги 1-2 данного алгоритма
Т е для OLTP-систем идем от однопоточности к многопоточности, а для OLAP-систем наоборот-идем от многопоточности к однопоточности. Таким образом можно подобрать оптимальные настройки параллелизма как для конкретной базы данных, так и для всего экземпляра MS SQL Server.
Также важно понимать, что настройки свойств параллелизма со временем нужно менять, исходя из результатов мониторинга производительности MS SQL Server.
Рекомендации по настройке флагов трассировки
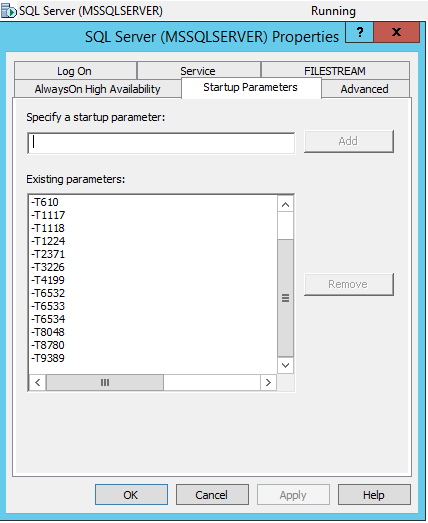
Из собственного опыта и опыта моих коллег для оптимальной работы рекомендую выставлять на уровне запуска службы MS SQL Server для 2008-2016 версий следующие флаги трассировки:
- 610 — Уменьшение протоколирования вставок в индексированные таблицы. Может помочь со вставками в таблицы с большим количеством записей и множеством транзакций, при частых долгих ожиданиях WRITELOG по изменению в индексах
- 1117 — Если файл в файловой группе удовлетворяет требованиям порога автоматического увеличения, все файлы в файловой группе увеличиваются
- 1118 — Заставляет все объекты располагаться в разных экстентах (запрет на смешанные экстенты), что сводит к минимуму необходимость сканирования страницы SGAM, которая и используется для отслеживания смешанных экстентов
- 1224 — Отключает укрупнение блокировок на основе количества блокировок. Однако слишком активное использование памяти может включить укрупнение блокировок
- 2371 — Изменяет порог фиксированного автоматического обновления статистики на порог динамического автоматического обновления статистики. Важно для обновления планов запросов касательно больших таблиц, где неправильно определение числа записей приводит к ошибочным планам выполнения
- 3226 — Подавляет сообщения об успешном выполнении резервного копирования в журнале ошибок
- 4199 — Включает изменения в оптимизаторе запросов, выпущенные в накопительных пакетах обновления и пакетах обновления SQL Server
- 6532-6534 — Включает улучшение производительности операций запросов с пространственными типами данных
- 8048 — Преобразует объекты памяти, секционированные по NUMA, в секционированные по ЦП
- 8780 — Включает дополнительное выделение времени для составления плана запроса. Некоторые запросы без этого флага могут быть отклонены, так как у них нет плана запроса (очень редкая ошибка)
- 9389 — Включает дополнительный динамический временно предоставляемый буфер памяти для операторов пакетного режима, что дает возможность оператору пакетного режима запросить дополнительную память и избежать переноса данных в tempdb, если дополнительная память доступна
Также до 2016 версии полезно включать флаг трассировки 2301, который включает оптимизацию расширенной поддержки принятия решений и тем самым помогает в выборе более правильных планов запросов. Однако, начиная с версии 2016, он часто оказывает негативный эффект в достаточно длительном общем времени выполнения запросов.
Также для систем, в которых очень много индексов (например, для баз данных 1С), рекомендую включать флаг трассировки 2330, который отключает сбор об использовании индексов, что в целом положительно сказывается на системе.
Более подробно о флагах трассировки можно узнать здесь.
По приведенной выше ссылке важно также учитывать версии и сборки MS SQL Server, т. к. для более новых версий некоторые флаги трассировки включены по умолчанию или не дают никакого эффекта.
Включить и выключить флаг трассировки можно с помощью команд DBCC TRACEON и DBCC TRACEOFF соответственно. Более подробно смотрите здесь.
Получить состояние флагов трассировки можно с помощью команды DBCC TRACESTATUS: подробнее.
Чтобы флаги трассировки были включены в автозапуск службы MS SQL Server, необходимо зайти в SQL Server Configuration Manager и в свойствах службы добавить данные флаги трассировки через -T:
Итоги
В данной статье были разобраны некоторые аспекты мониторинга MS SQL Server, с помощью которых можно оперативно выявить нехватку ОЗУ и свободного времени ЦПУ, а также ряд других менее очевидных проблем. Были рассмотрены наиболее часто используемые флаги трассировки.
Источники
» Статистика ожидания SQL Server
» Статистика ожиданий SQL Server'а или пожалуйста, скажите мне, где болит
» Системное представление sys.dm_os_schedulers
» Использование Zabbix для слежения за базой данных MS SQL Server
» Стиль жизни SQL
» Флаги трассировки
» sql.ru
Комментарии (23)

Kant8
14.04.2019 23:11+11224 — Отключает укрупнение блокировок на основе количества блокировок.
Контролирует ли этот флаг выбор между блокировками строк и страниц?
Периодически ловим дедлоки, где 3-5 не связанных друг с другом логически процессов по кругу лочатся из-за обновления строк в одной и той же таблице, находящихся похоже на одной странице. И непонятно как их побороть.
Или может какой-нибудь другой флаг или настройка могут помочь. В попадающейся в отчете дедлока хранимке уже давно написан rowlock, но он похоже игнорируется, плюс его нет в сотнях других запросов, которые приходят через ормку из приложения.
jobgemws Автор
14.04.2019 23:18Т к деталей нет, то в общем рекомендую рассмотреть следующие варианты:
1) включить версионирование (самое простое)
2) воспользоваться секционированием, чтобы данные находились в разных секциях (среднее по сложности)
3) с помощью шардинга отправлять запросы на разные узлы (самое сложное)Kant8
14.04.2019 23:36+1Из деталей могу сказать, что это ПО для небольшого банка, там секционированием и шардированием заниматься на текущий момент избыточно, дедлоки вылетают нечасто, и скорее всего когда из-за сбоев в статистике некоторые планы становятся параллельными со сканами там, где не нужно, и висят такие в кэше, пока мы не замечаем проблемы.
Ну и из того, что я не понимаю, в репортах таких круговых дедлоков всегда присутствуют типы ожиданий e_waitPortOpen и e_waitPipeGetRow. И если второй это из параллелизма, то откуда первый не совсем понятно.
Сейчас вот подумываю может попробовать поиграться с параллелизмом как описано в статье, но немного страшновато :)
А изоляция уже давно на снепшотах, если вы про это.jobgemws Автор
14.04.2019 23:53Да, я про изоляцию имел в виду.
Про параллелизм-начните с самого запроса, ограничив ему потоки от 1 и далее, сравните планы и время выполнения. Лучше сначала проверить на нагрузочной тестовой среде, а потом на проде
jobgemws Автор
14.04.2019 23:54Так по сканам-индексов не хватает или может они сильно фрагментированы, или статистика устаревшая

uaggster
15.04.2019 08:57А чего страшно то?
Максимум, что вы получите — деградацию производительности в N раз (причем, думаю, N не будет больше 1,5-2 раз, максимум 3).
Вообще, Max Degree Parallelism в 0 оставляют только самоубийцы.
Это имеет смысл делать только в случае, если сервер используется как однопользовательская система для построения каких либо отчетов.
Другое дело, что в 1 его тоже стоит устанавливать не всегда.
Опять же, только в том случае, только когда вы имеете OLTP с тысячами одновременных коннектов и элементарными запросами, дергающими по 1 записи в таблице, без какой-либо сложно логики.
У меня, например — небольшие, 100 — 200 Гб базы, и небольшая, интенсивность обращения к ним, не более 100 запросов в секунду. Я установил степень параллелизма равной 1/4 количества «железных» ядер процессора, и, в общем, забыл об этой проблеме.
Наверное, можно сделать лучше, но зачем? :-)
Пользователи ж не кричат «висит», а только «подтормаживает».
:-)jobgemws Автор
15.04.2019 09:17+1Лучше каждый запрос отдельно проверить, а то порой даже деградация в 5% будет стоить компании многоциферными потерями прибыли, а уж в разы-может стать причиной в ближайшем будущем вынужденного сокращения целых отделов

uaggster
15.04.2019 07:53Первым показателем нехватки оперативной памяти является тот случай, когда экземпляр MS SQL Server съедает всю выделенную ему ОЗУ.
А экземпляр MS SQL SERVER всегда съедает всю выделенную ему ОЗУ.
:-)jobgemws Автор
15.04.2019 07:57Часто, но невсегда.
В статье изложено как понять, что именно ОЗУ ему не хватает, а не случай, когда СУБД что-то в памяти держитuaggster
15.04.2019 08:25Часто, но невсегда.
Всегда, всегда. :-)
Хотя, конечно, если у вас памяти — ведро, а база — считанные мегабайты, тогда да.
Но вопрос в другом.
А почему б, в качестве первого шага по анализу «чего в супе не хватает» не воспользоваться более штатными средствами?
Штатным отчетом Memory Consumption, отчетами из серии Performance — Top Queries by ХХХХ или Activity Monitor (дада!) в SSMS?
Их, правда, нужно научиться читать.jobgemws Автор
15.04.2019 08:34+1Если Вы для мониторинга пользуетесь Activity Monitor, то тогда Вы будете заблуждаться, когда скулю нужно еще памяти, а когда он просто ее сьел (последнее не означает нехватку ОЗУ).
Activity Monitor перестал пользоваться лет 5 назад, т к есть более гибкие и точные способы получить что нужно (например про нехватку памяти описано выше).
Про встроенные отчеты я вообще молчу-когда начинаешь разбирать как это все собирается, то понимаешь, что лучше более точные запросы написать, оформить их в пользовательские счетчики и вывести их в Zabbix и Spotlight.
Наверно Вы никогда не сталкивались, когда из-за Activity Monitor и особенно из-за Сборщика Данных (а он нужен для тех красивых отчетов) высоконагруженная СУБД теряла в своей ппоизводительности более 5%, что недопустимо, где каждые 5 мсек стоят больших денег.
Для справки-работаю с разными БД от 100 МБ до 100+ ГБ с интенсивностью использования одновременных запросов от 10 до 10 000
kolu4iy
15.04.2019 10:12+1Даже если база считанные мегабайты, но нагрузка в 1000+ пользователей — съест.
Artemis86
15.04.2019 08:37+1Не совсем так насколько я знаю. Просто по дефолту стоит настройка использовать всё ОЗУ, но после установки можно выставить лимиты.
jobgemws Автор
15.04.2019 08:41Да, имелось в виду, что сверху и снизу обьем ОЗУ ограничили в настройках.
И часто скуль осваивает выделенный ему максимальный обьем. Но сколько он сьел и мало ли ему обьемов ОЗУ-это разные вещи.
Также не стоит забывать, что версия и редакция могут накладывать максимально воспринимаемый обьем ОЗУ и ядер ЦПУ.

Tzimie
16.04.2019 16:54+1Вот не знаю стоит ли вставлять в PROD столько флагов. Если что при поддержке Майкрософт не может сказать айяйяй? Я в данном случае консервантор, не ставь флаг пока не доказано, что есть проблема, которую он решает
jobgemws Автор
16.04.2019 17:24Да, Вы правы-это рекомендация из личного моего опыта и опыта моих коллег, а не Microsoft.
Однако, эти флаги проверены временем на разных системах и разных сборках, редакциях, версий и условий.
Но все всегда нужно перепроверять как и информацию из книг, msdn и любых статей тоже нужно перепроверять
virtualsys
Если память не изменяет, то в 2016 флаги 1118 и 4199 уже отжили свое, в них нет необходимости.
А у вас нет опыта в использование типовых флагов в синхронном режиме AlwaysOn? И с регламентными работами? А то некоторые там чуть ли не шаманят.
jobgemws Автор
Потому я и указал, что важно учитывать версию MS SQL Server.
Обычно используют асинхронный режим AlwaysOn. Типовые регламентные работы и флаги такие же
virtualsys
В асинхронном автоматически не переключится на реплику без потери данных. Если это не важно, то, понятное дело, асинхронный оптимальнее с точки зрения требований.
Про 2016 я уточнил только потому что Вы в конце отдельно приводили флаги не актуальные для новых версий. А так, конечно, надо внимательно перечитывать нюансы под конкретный релиз.
jobgemws Автор
Для асинхронного обычно также принимают ряд мер для минимизации потери данных от T-SQL до специальных утилит