
Описание общей потребности в синхронизации изменений
При работе с базами данных часто приходится решать проблему синхронизации изменений.
Если в компании используется всего одна промышленная среда, то в дополнение к ней требуется как минимум еще одна дополнительная среда для тестирования внесенных изменений. В этом случае возникает необходимость переноса изменений из тестовой среды в промышленную.
С ростом компании может увеличиваться количество необходимых серверов и виртуальных сред, а также может расти количество экземпляров систем управления базами данных, тогда возникает необходимость в более сложной синхронизации.
Как правило, разработку баз данных ведут в специально выделенной среде. Затем изменения переносят в среду тестирования для проведения различных проверок (юнит-тесты, автотесты, нагрузочные тесты и т д). И только после всех этапов разработки и проверок осуществляют перенос изменений в промышленную среду.
При достаточно большой инфраструктуре появляется необходимость переносить изменения сразу в несколько промышленных сред. Кроме этого, разработка баз данных может быть разделена на разные среды по функционалу, и тогда необходимо периодически осуществлять перенос изменений между данными средами.
Встречаются случаи, когда изменения были применены вне среды для разработки и их необходимо в нее перенести. Но такие ситуации нужно минимизировать, чтобы не возникала угроза для корректной работы системы.
В общем случае, последовательность переноса изменений можно представить следующим образом:
- Между средами для разработки.
- Из сред для разработки в среды для тестирования.
- Между средами для тестирования. В случае внесения изменений, пришедших не из среды разработки в любую из сред для тестирования, такие изменения также переносятся в среду для разработки. Как правило, все изменения должны идти из среды разработки в среду для тестирования, но не наоборот.
- Из среды тестирования в предпромышленные среды, где производится сбор изменений для каждой конкретной промышленной среды, проводятся последние интеграционные тесты, а также тесты по откату изменений при заранее указанных инсценированных сбоях.
- Из предпромышленной среды в промышленную среду с возможностью быстрого отката внесенных изменений.
Существуют различные инструменты для синхронизации изменений между средами, например:
- Visual Studio Comparer
- SQL Server Integration Services
- dbForge Comparer от компании Devart
- ApexSQL от компании Quest Software
- Решения от компании RedGate
Обычно с MS SQL Server работают решения, написанные на .NET (например, написанные на C#).
В данной статье будет рассматриваться пример переноса изменений базы данных MS SQL Server с одного сервера на другой с помощью инструментов от компаний Devart, Quest Software и RedGate. В конце будет сделано сравнение данных инструментов.
В данной статье для примеров будем рассматривать базу данных SRV, которая предназначена для обслуживания СУБД MS SQL Server. Скачать ее исходники можно здесь.
Данная база данных SRV распространяется свободно для любых целей.
Решения от компании Devart
Решения от компании Devart для синхронизации баз данных MS SQL Server называются DbForge Data Comparer, DbForge Schema Comparer и dbForge Compare Bundle for SQL Server. Первые два встраиваются в DbForge Studio for MS SQL Server, а третий-непосредственно в SSMS.
Синхронизация схем баз данных
После открытия студии, перейдите на вкладку «Database Sync» и создайте новое подключение, нажав по кнопке «New Connection»:
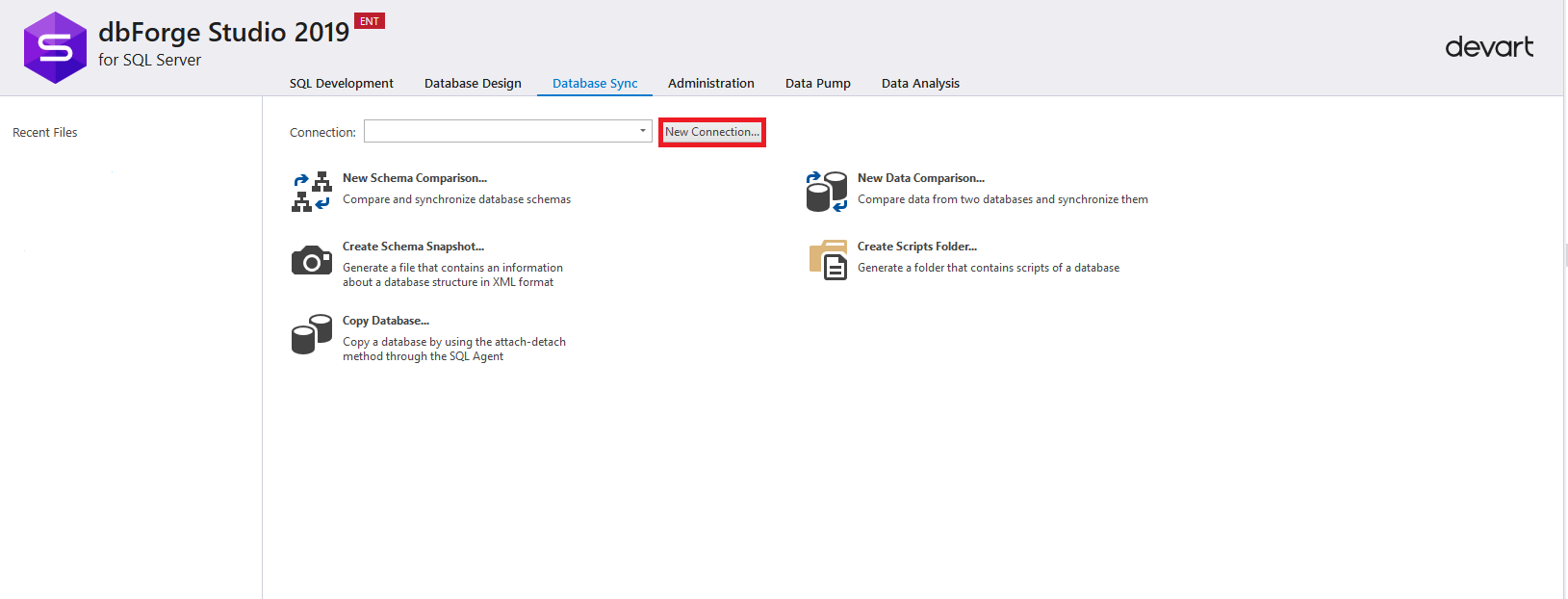
В открывшемся окне настроек подключения необходимо ввести необходимые данные для подключения к экземпляру MS SQL Server (серверу-источнику). Обратите внимание, что помимо аутентификации MS SQL Server, Windows, Active Directory, появилась возможность аутентификации через MFA. После заполнения всех необходимых полей, нажмите на кнопку «Test Connection» для проверки соединения:
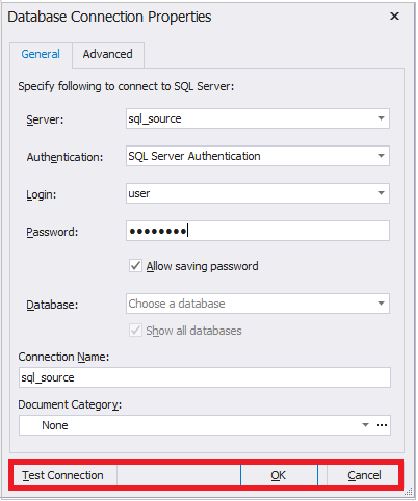
После установки соединения будет выведено следующее диалоговое окно:
Далее нажмите на кнопку «ОК» в диалоговом окне и на такую же кнопку в окне настроек подключения.
Теперь появилось новое подключение:

Аналогичным образом необходимо подключить все нужные экземпляры MS SQL Server (в данном примере нужно создать подключение для сервера-приемника).
После этого необходимо нажать на «New Schema Comparison» для настройки процесса сравнения схем базы данных на сервере-источнике и базы данных на сервере-приемнике:
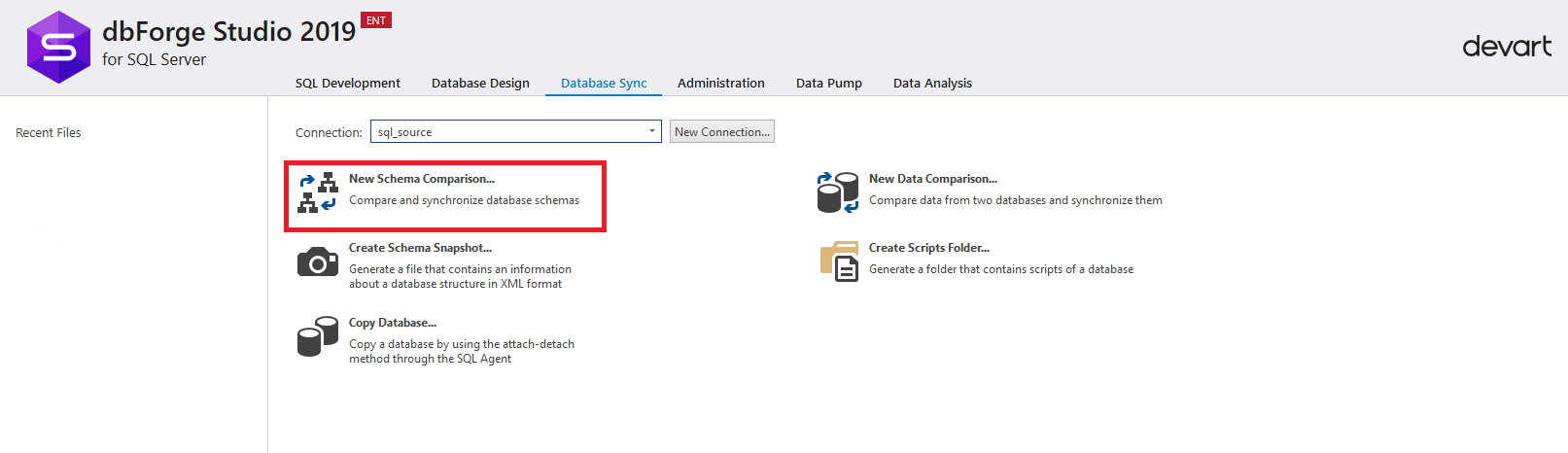
Появится окно настроек для сравнения схем.
На вкладке «Source and Target» слева в панели Source необходимо выбрать:
- тип
- подключение
- базу данных источника
Справа в панели Target необходимо выбрать:
- тип
- подключение
- базу данных приемника
Обратите внимание, что в типе можно выбрать не только базу данных, но также каталог скриптов, снимок, контроль версий и резервную копию. В нашем случае выбираем в типе «база данных».
После выбора всех настроек необходимо нажать на кнопку «Next» для продолжения настройки синхронизации схем баз данных.
Если сравниваются две изначально одинаковые базы данных, то можно сразу приступать к сравнению схем, нажав на кнопку «Compare».
При необходимости можно перейти к любой вкладке настроек, кликнув на соответствующий элемент слева окна.
На любом этапе можно сохранить настройки в виде bat-файла, нажав на кнопку «Save Command Line» слева внизу окна.
В большинстве случаев при накатывании изменений между изначально одинаковыми базами данных, достаточно сразу нажать на кнопку «Compare». Но для исследования функционала необходимо нажать «Next»:
Во вкладке «Options» можно выставить различные настройки или оставить их по умолчанию:
Во вкладке «Schema Mapping» можно настроить сопоставление схем по имени:
Во вкладке «Table Mapping» можно настроить сопоставление таблиц и столбцов:

Во вкладке «Object Filter» можно задать объекты для сравнения.
После этого, при необходимости можно вернуться к предыдущим шагам.
В конце необходимо нажать на кнопку «Compare» для запуска процесса сравнения схем заданных баз данных:
Окно настроек сравнения схем баз данных исчезнет, и появится окно с индикатором процесса выполнения сравнения:

В конце процесса обратите внимание на окно. Можно изменить настройки сравнения, нажав на кнопку «Edit Comparison» в левом верхнем углу окна. Справа от этой кнопки располагается круг со стрелкой — это кнопка обновления, которая запускает вновь процесс сравнения схем. Также чуть ниже располагаются все зарегистрированные ранее сервера:
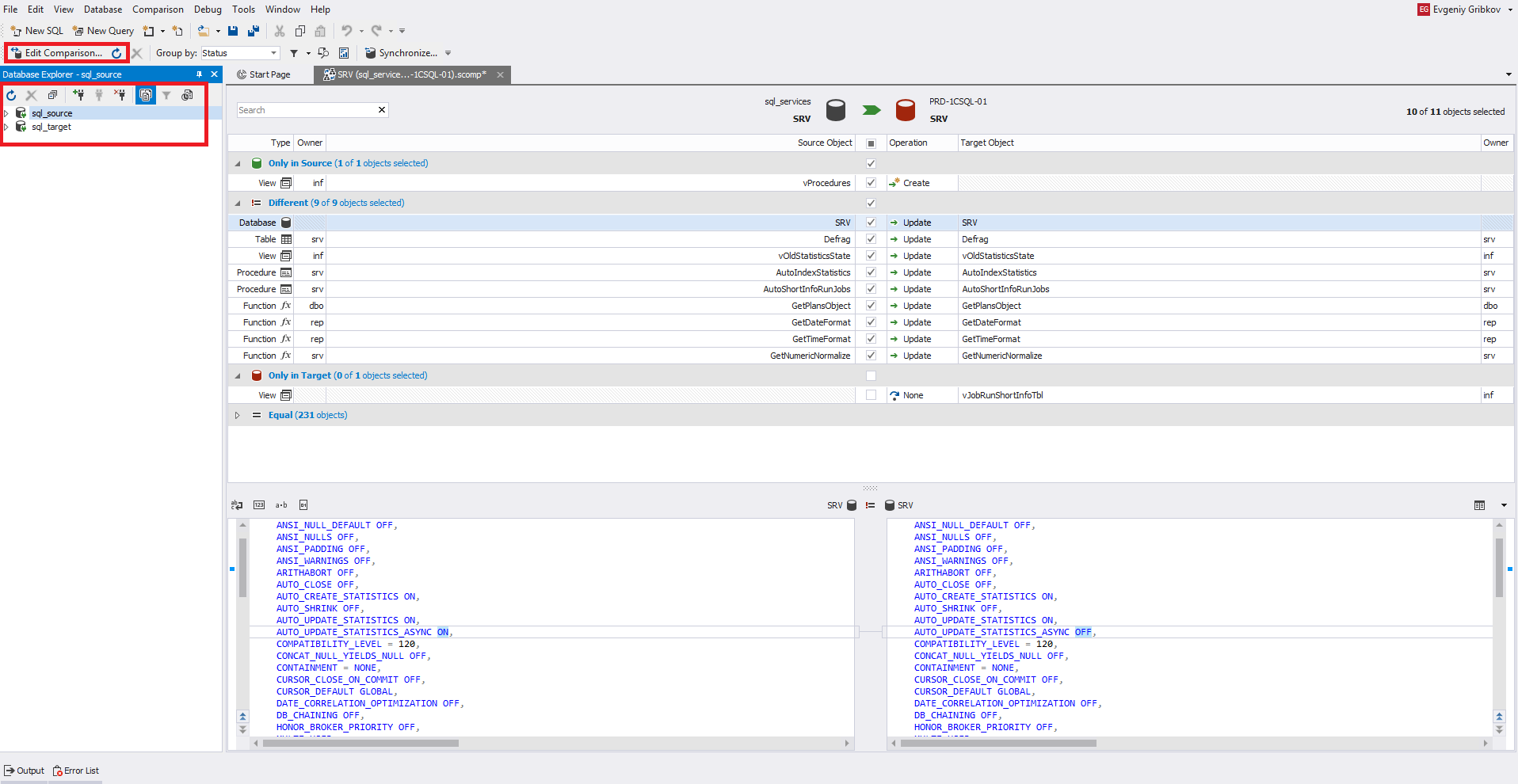
Через главное меню в File можно сохранить настройки сравнения схем в виде файла с расширением scomp.
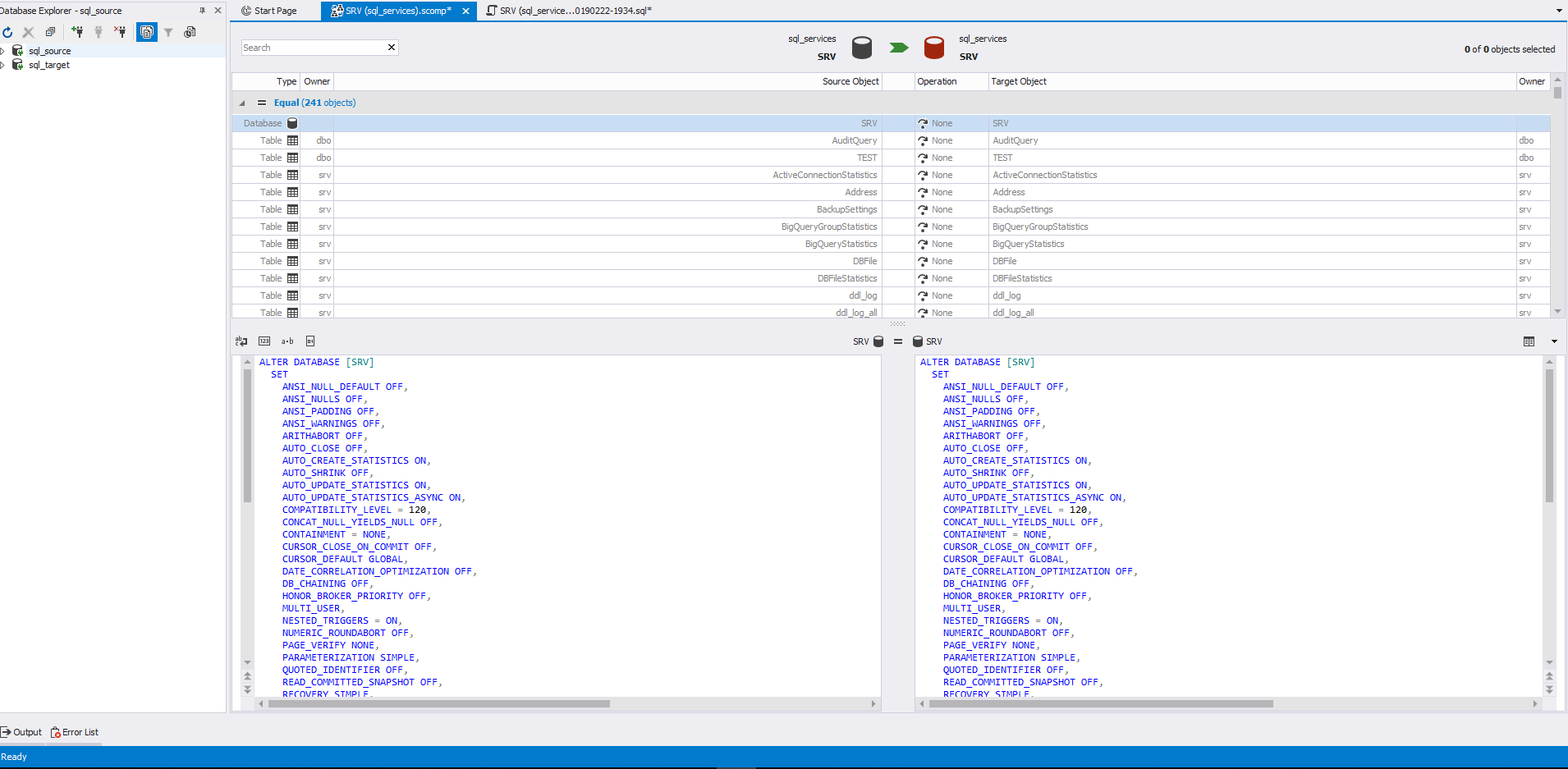
Теперь обратим внимание на центральную часть окна. Здесь галочками нужно выбрать необходимые объекты для синхронизации. Слева располагаются объекты источника, а справа-приемника. Внизу аналогичным образом располагается код определения объектов. Объекты для сравнения разделены на 4 секции с подсчетом количества этих объектов в каждой секции.
Здесь выбрана для просмотра кода определения таблица, которая есть и в источнике, и в приемнике. Поэтому данный объект находится в секции «Different»:

При выборе данного объекта, его код определения слева будет перенесен вправо при синхронизации схем баз данных для приемника.
Здесь для просмотра кода определения выбрано представление, которое есть только в источнике. Поэтому данный объект находится в секции «Only in source» и справа для него нет кода определения:
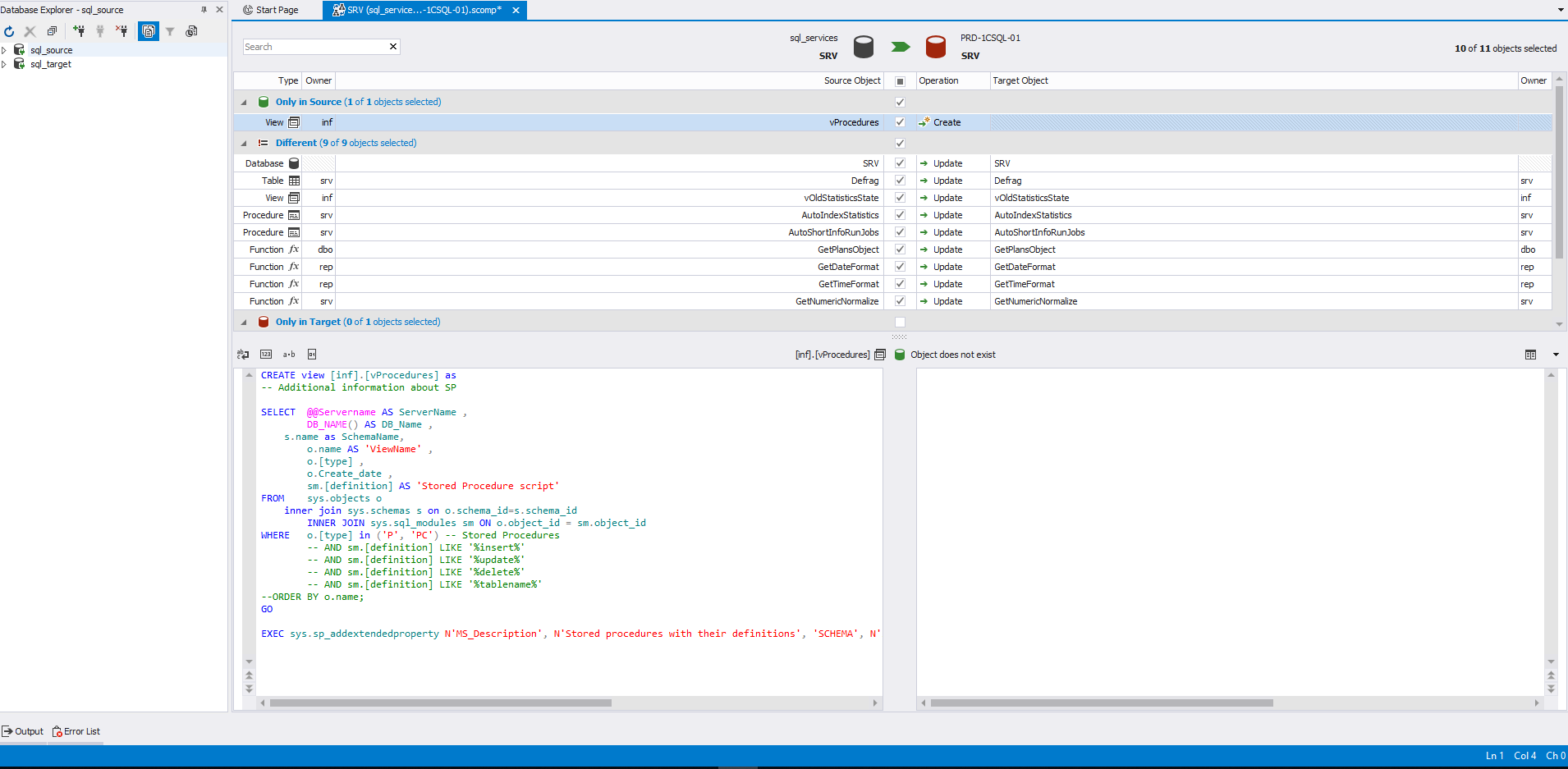
При выборе такого объекта, его код создания будет сгенерирован для приемника.
Здесь для просмотра кода определения выбрано представление, которое есть только в приемнике. Поэтому данный объект находится в секции «Only in target» и слева для него нет кода определения:
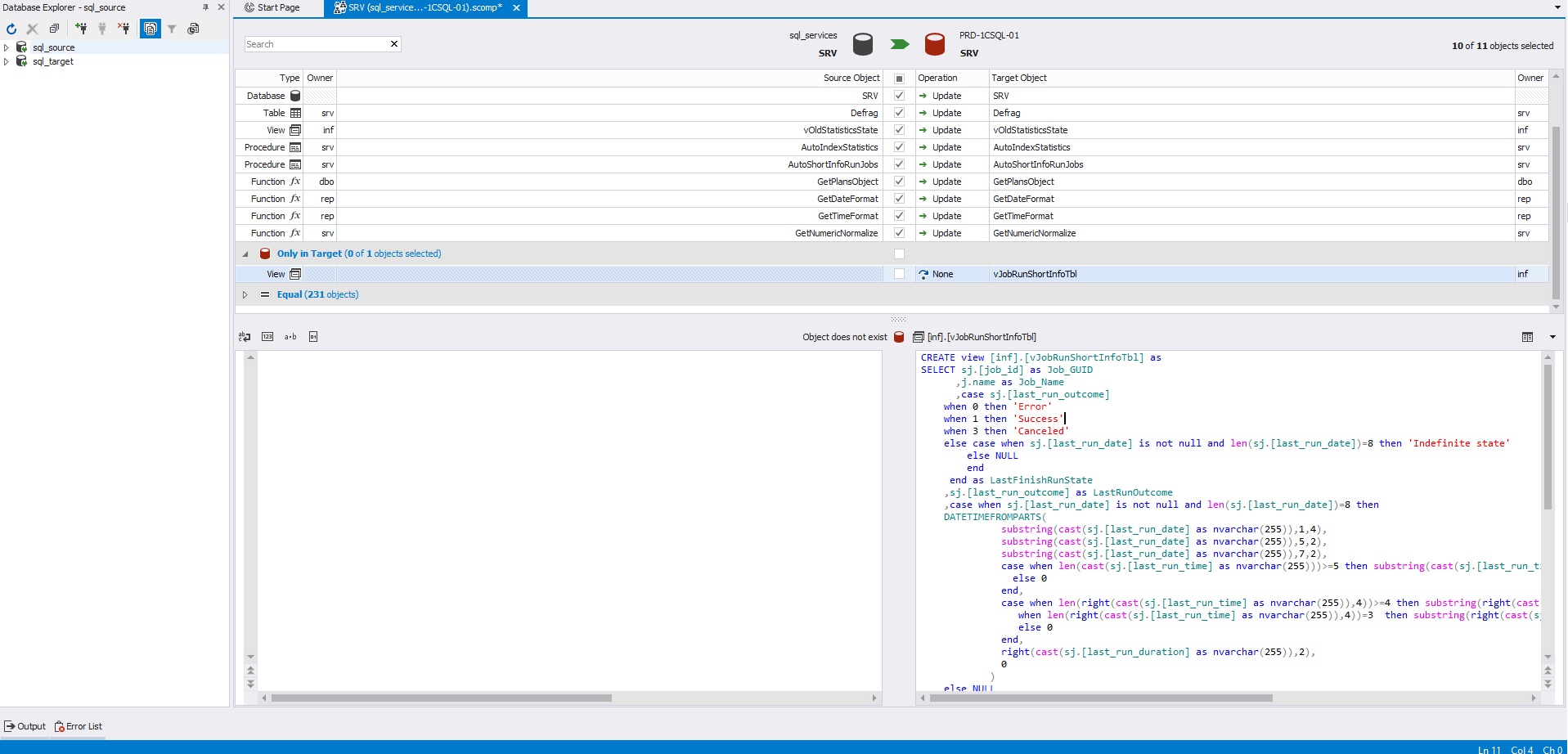
При выборе такого объекта, его код удаления будет сгенерирован для приемника.
Далее, для запуска самого процесса синхронизации схем баз данных необходимо нажать на одну из кнопок, выделенных красным на картинке:
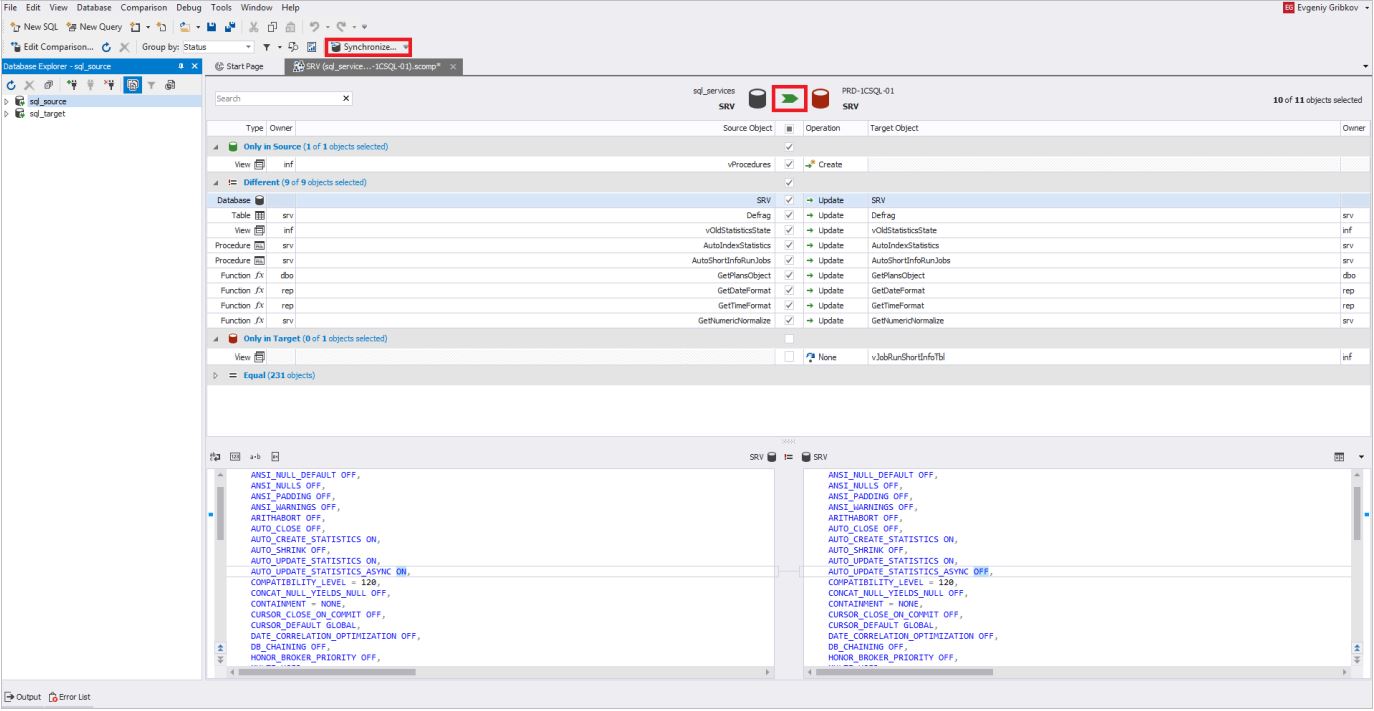
Во вкладке «Output» необходимо указать, как будет происходить процесс синхронизации. Обычно выбирается генерация скрипта в студию или в файл. В нашем случае выберем первый вариант. Рекомендуется внимательно проходить последовательность всех вкладок по настройке процесса синхронизации:
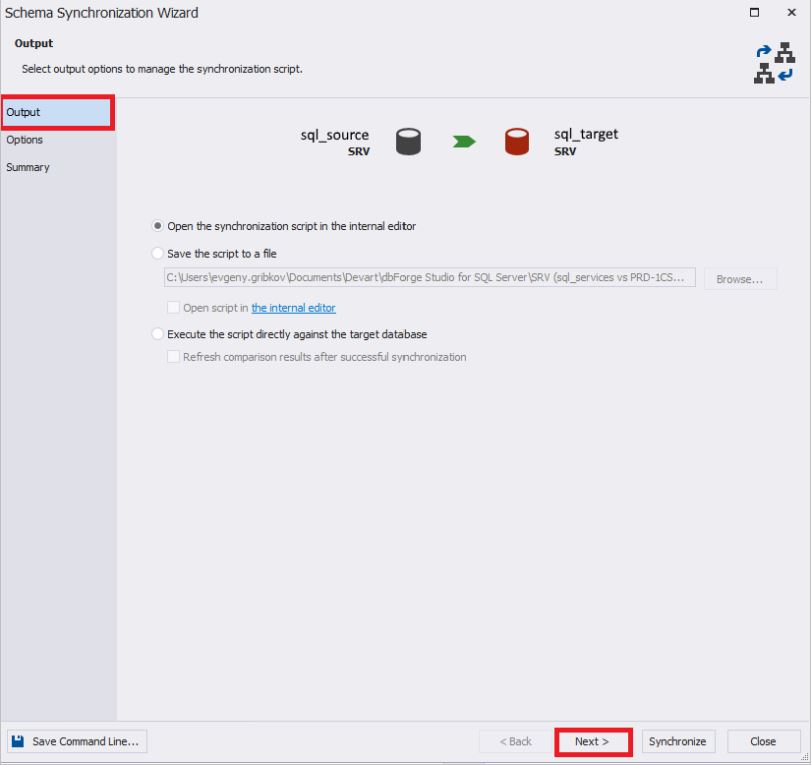
Во вкладке «Options» можно задать различные настройки для синхронизации схем баз данных.
Обычно убираются все настройки из группы «Database backup».
По умолчанию в группе настроек «Transactions» выставлено «Use a single transaction» и «Set transaction isolation level to SERIALIZABLE», что предотвращает ситуации, в которых могут быть применены только части изменений – т.е. изменения будут применяться полностью либо не применяться вовсе:
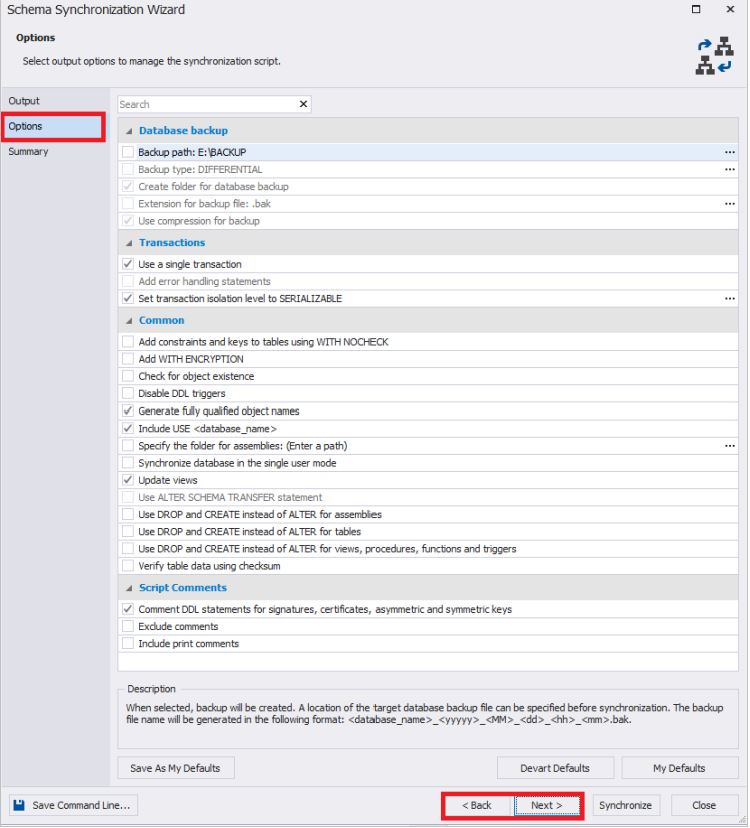
Во вкладке «Summary» отображаются итоги выбора настроек синхронизации. При необходимости можно вернуться к предыдущим пунктам.
Обратите внимание, что настройки по синхронизации схем баз данных также можно сохранить в bat-файл, нажав на кнопку «Save Command Line» слева внизу окна.
В конце необходимо нажать на кнопку «Synchronize» для начала процесса генерации скрипта синхронизации схем баз данных:
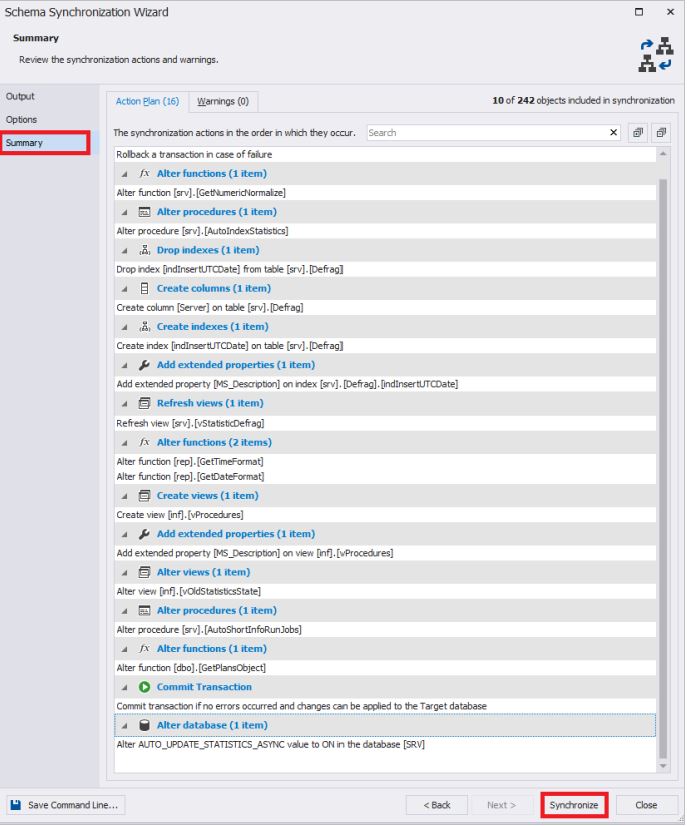
По завершению, будет сгенерирован скрипт в новое окно:
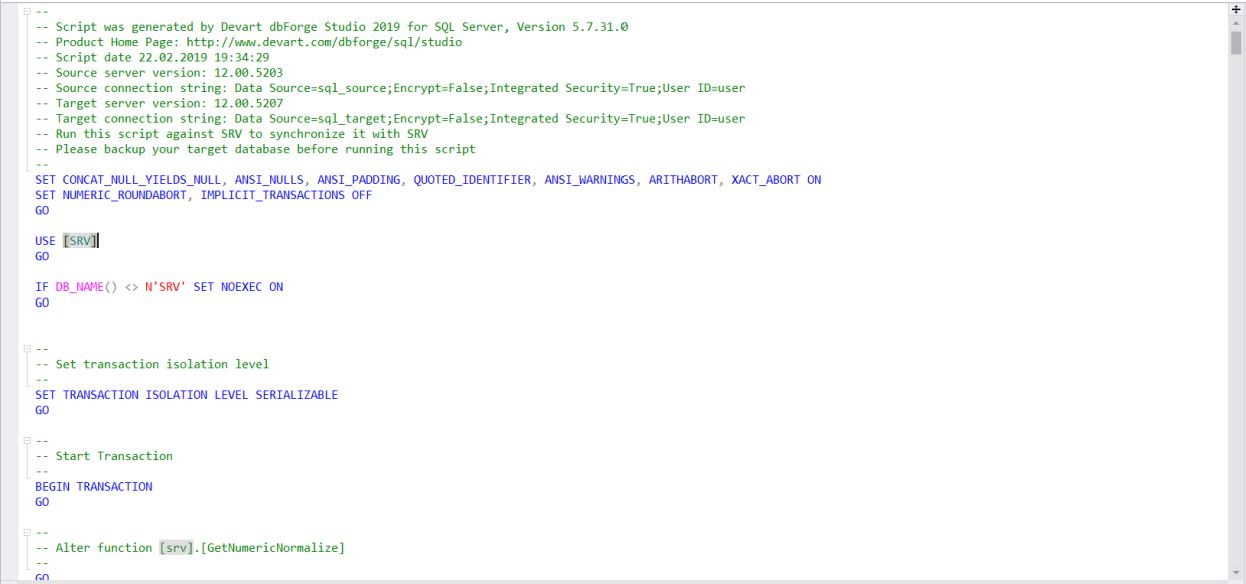
Данный скрипт и есть код для переноса изменений схемы базы данных с источника на приемник. Его можно применить на сервере-приемнике или сохранить в файл для последующего применения на сервере-приемнике. Как правило, в любом случае данный скрипт сохраняют, чтобы после всех проверок применить его сразу на нескольких серверах для одной и той же базы данных. Сделать это можно с помощью групп зарегистрированных серверов в SSMS, отправив получившийся скрипт сразу на всю нужную группу серверов:
После синхронизации, выбранные ранее объекты, должны исчезнуть из окна сравнения схем:
Синхронизация данных баз данных
Предполагается, что были созданы нужные подключения как описывалось выше в «Синхронизация схем баз данных».
После этого необходимо нажать «New Data Comparison» для настройки процесса сравнения данных базы данных на сервере — источнике и базы данных на сервере — приемнике:
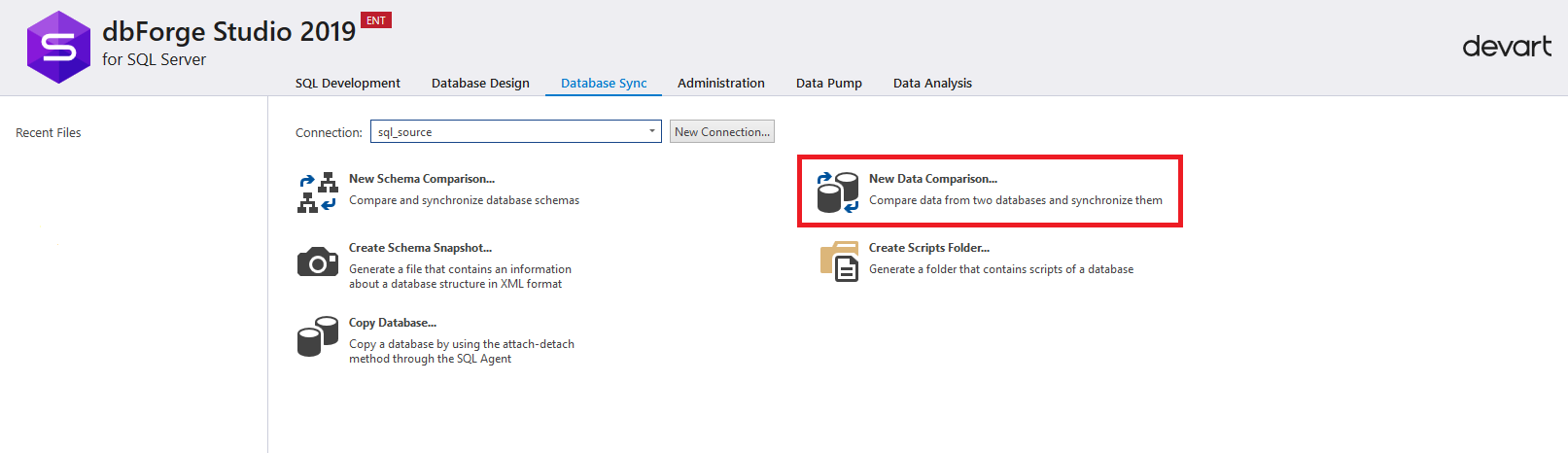
Появится окно настроек для сравнения данных.
На вкладке «Source and Target» слева в панели Source необходимо выбрать:
- тип
- подключение
- базу данных источника
Справа в панели Target необходимо выбрать:
- тип
- подключение
- базу данных приемника
Обратите внимание, что в типе можно выбрать не только базу данных, но также каталог скриптов и резервную копию. В нашем случае выбираем в типе «база данных».
После выбора всех настроек необходимо нажать «Next» для продолжения настройки синхронизации данных баз данных.
В отличие от сравнения схем, при сравнении данных рекомендуется пройти все шаги настроек последовательно.
При необходимости можно перейти к любой вкладке настроек, кликнув на соответствующий элемент окна слева.
На любом этапе можно сохранить настройки в виде bat — файла, нажав «Save Command Line» слева внизу окна.
После настройки вкладки “Source and Target” необходимо нажать «Next»:
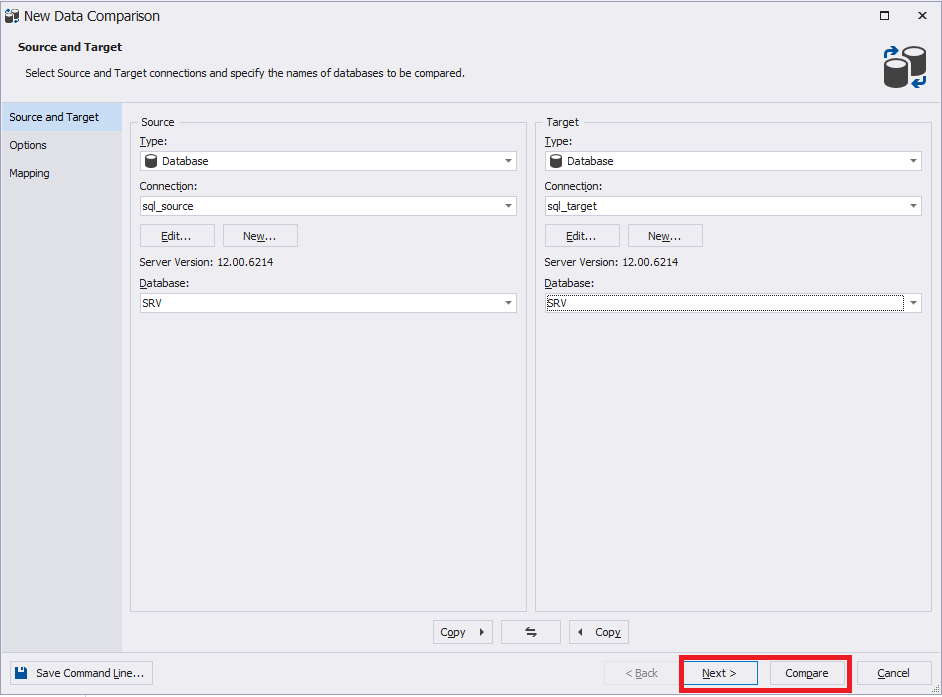
Во вкладке «Options» можно выставить различные настройки или оставить их по умолчанию:
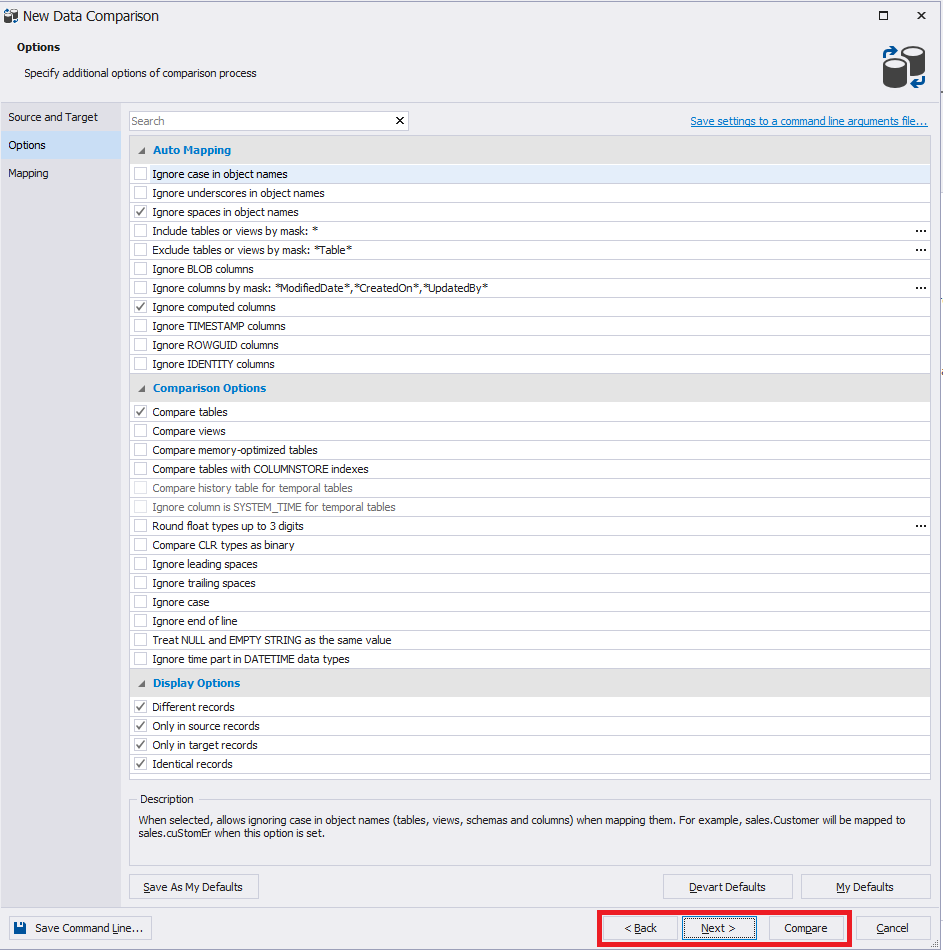
Во вкладке «Mapping» дается список таблиц для синхронизации данных. Восклицательными знаками отмечены те таблицы, в которых нет первичного ключа. Для таких таблиц сопоставление нужно делать вручную. Для этого выберите нужную строку (таблицу) и справа нажмите на многоточие:
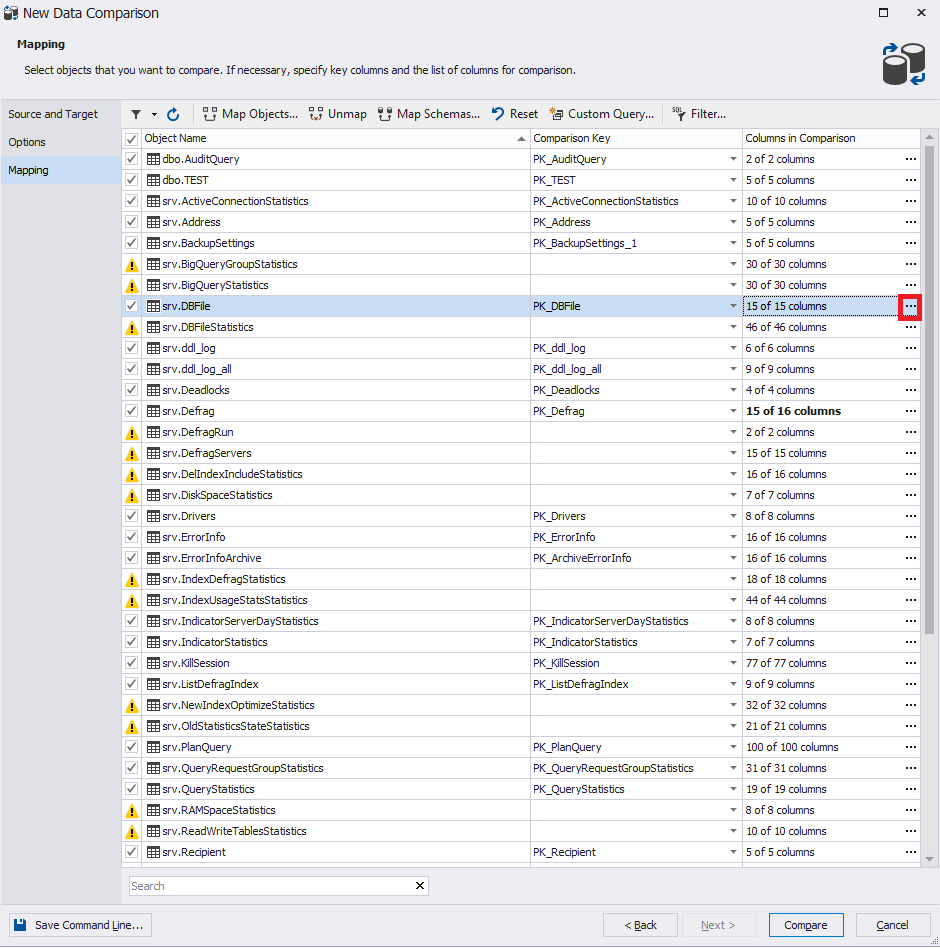
Появится окно сопоставления:

После этого при необходимости можно вернуться к предыдущим шагам.
В конце необходимо нажать «Compare» для запуска процесса сравнения данных заданных баз данных:
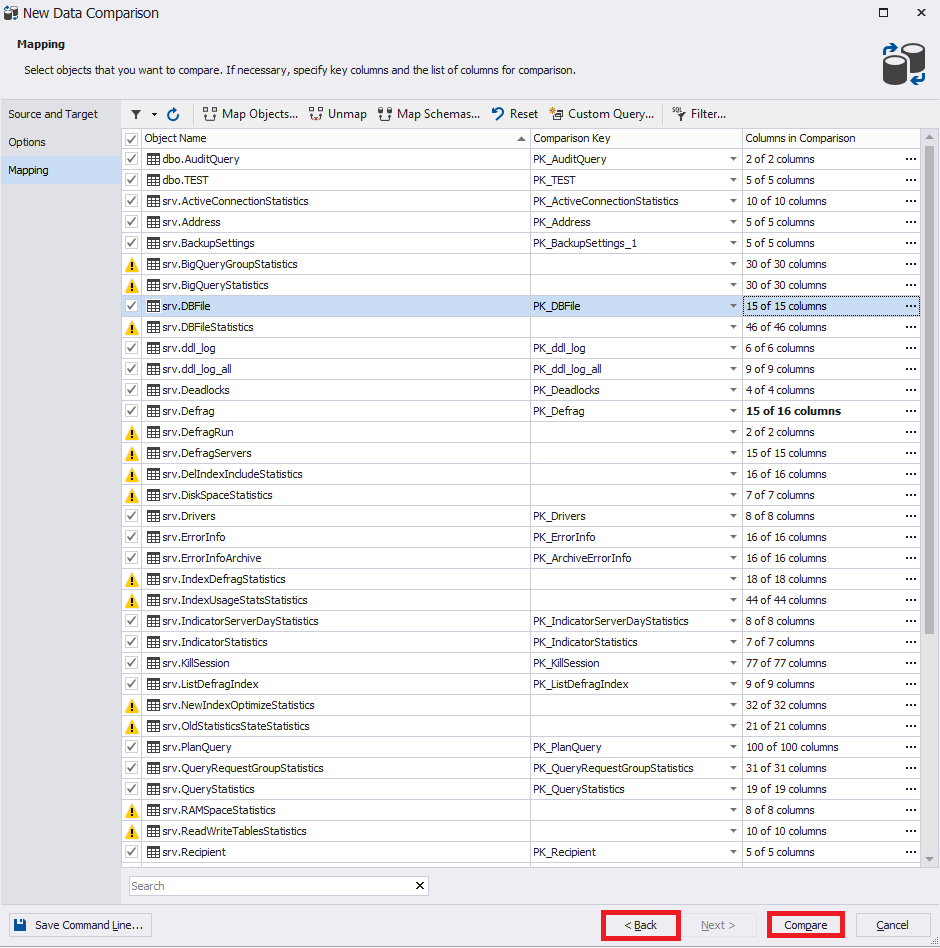
Окно настроек сравнения данных баз данных исчезнет и появится окно с индикатором процесса выполнения сравнения:
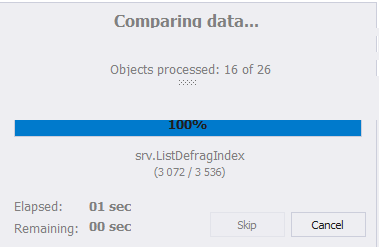
В конце процесса обратите внимание на окно. Можно изменить настройки сравнения, нажав «Edit Comparison» в левом верхнем углу окна. Справа от этой кнопки располагается круг со стрелкой — это кнопка обновления, которая запускает процесс сравнения данных вновь. Также чуть ниже располагаются все зарегистрированные ранее сервера:

Через главное меню в File можно сохранить настройки сравнения схем в виде файла с расширением dcomp.
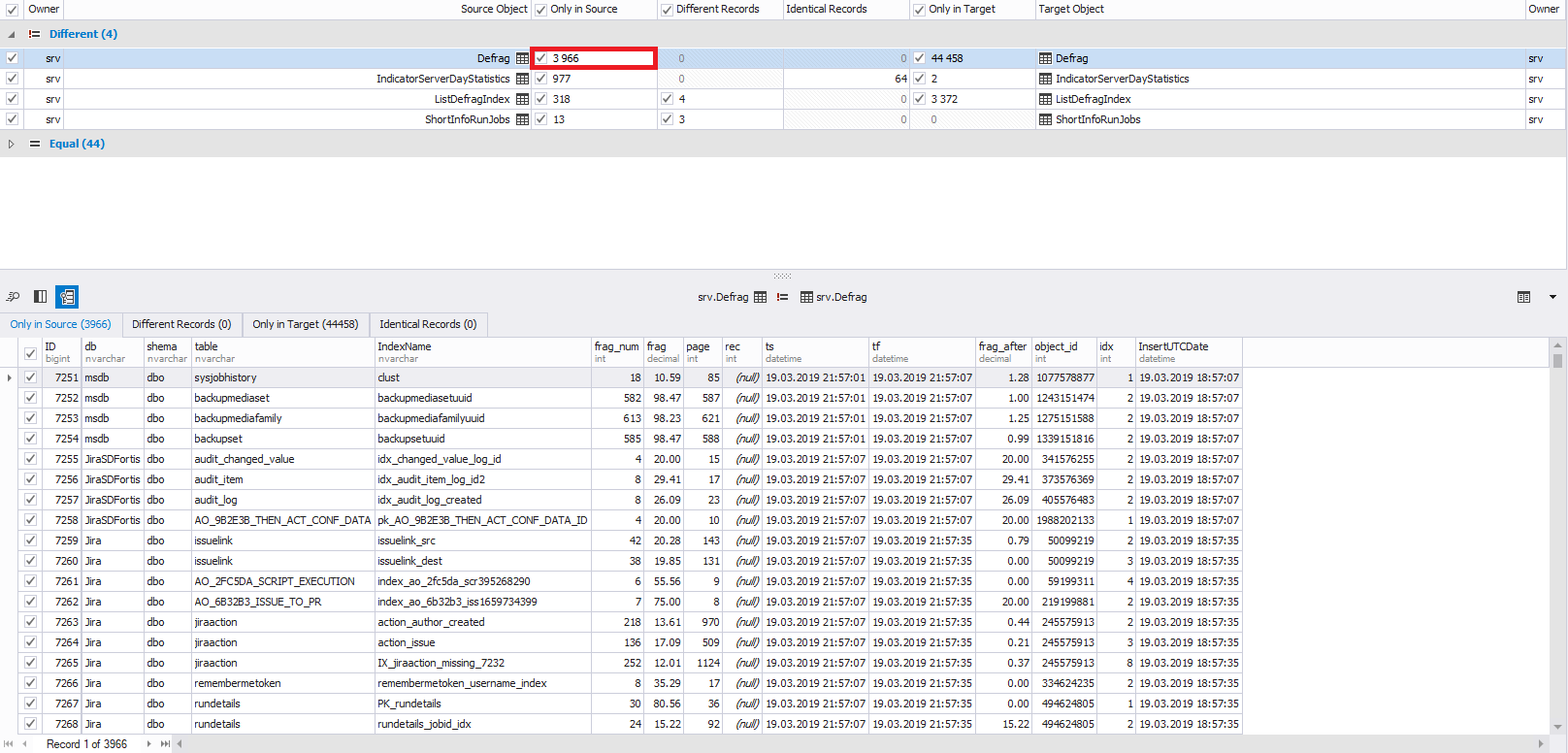
Теперь обратим внимание на центральную часть окна. Здесь галочками нужно выбрать необходимые объекты для синхронизации. Слева располагаются объекты источника, а справа — приемника:

Внизу отображается следующая информация:
- для вставляемых строк — данные вставляемых строк:
- для изменяемых строк — сравнение строк:

- для удаляемых строк — данные удаляемых строк:
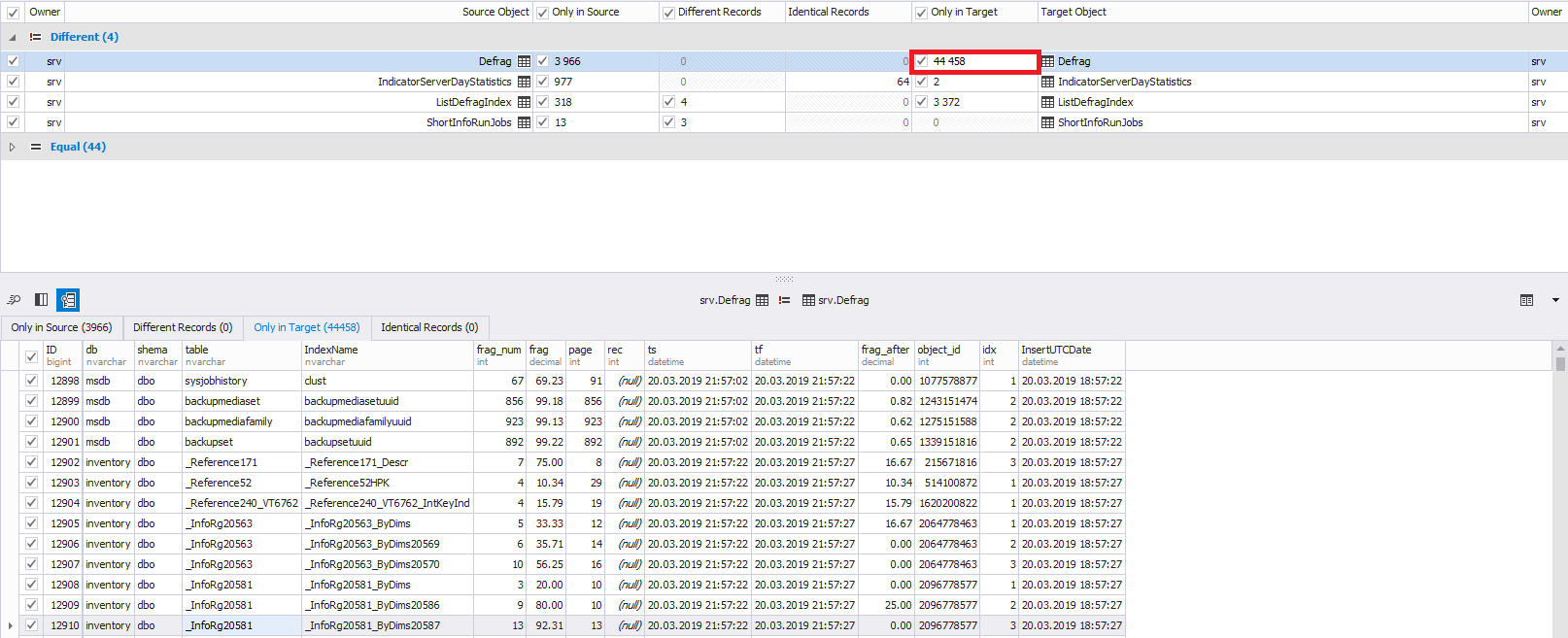
Внизу слева при необходимости можно выбрать не все строки для изменений, а нужные. По умолчанию выбираются все строки:
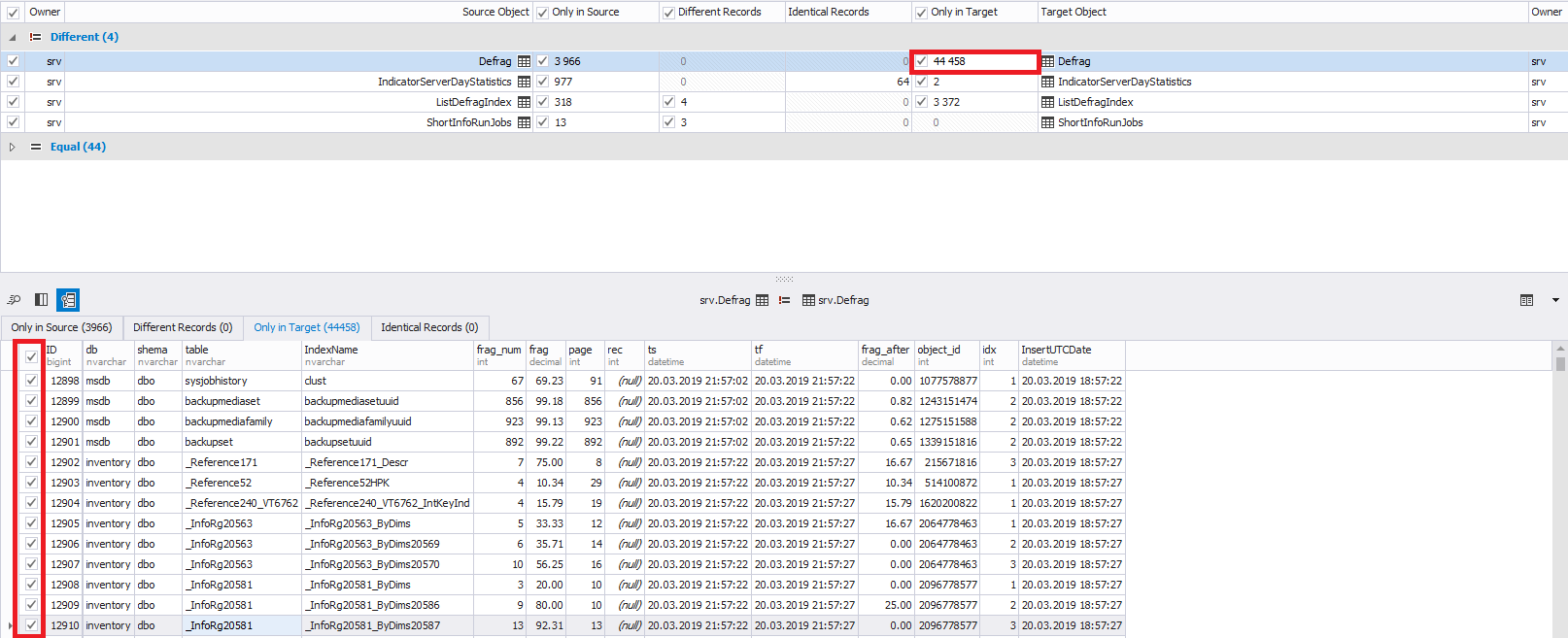
Также можно переходить между добавляемыми, изменяемыми и удаляемыми строками с помощью вкладок над самой таблицей данных:
Для управления видимостью нужных столбцов (полей) есть необходимый функционал:
По умолчанию выбраны все столбцы.
Далее для запуска самого процесса синхронизации данных баз данных необходимо нажать на одну из кнопок, выделенных красным на картинке:

Во вкладке «Output» необходимо указать, как будет происходить процесс синхронизации. Обычно выбирается генерация скрипта в студию или в файл. В нашем случае выберем первый вариант. Рекомендуется внимательно проходить последовательность всех вкладок по настройке процесса синхронизации:
Во вкладке «Options» можно задать различные настройки для синхронизации.
Обычно убираются все настройки из группы «Database backup».
По умолчанию в группе настроек «Transactions» выставлено «Use a single transaction» и «Set transaction isolation level to SERIALIZABLE», что предотвращает ситуации, в которых могут быть применены только части изменений – т.е. изменения будут применяться полностью либо не применяться вовсе:
Во вкладке «Summary» отображаются итоги выбора настроек синхронизации. При необходимости можно вернуться к предыдущим пунктам.
Обратите внимание, что настройки по синхронизации схем баз данных также можно сохранить в bat — файл, нажав «Save Command Line» слева внизу окна.
В конце необходимо нажать «Synchronize» для начала процесса генерации скрипта синхронизации:
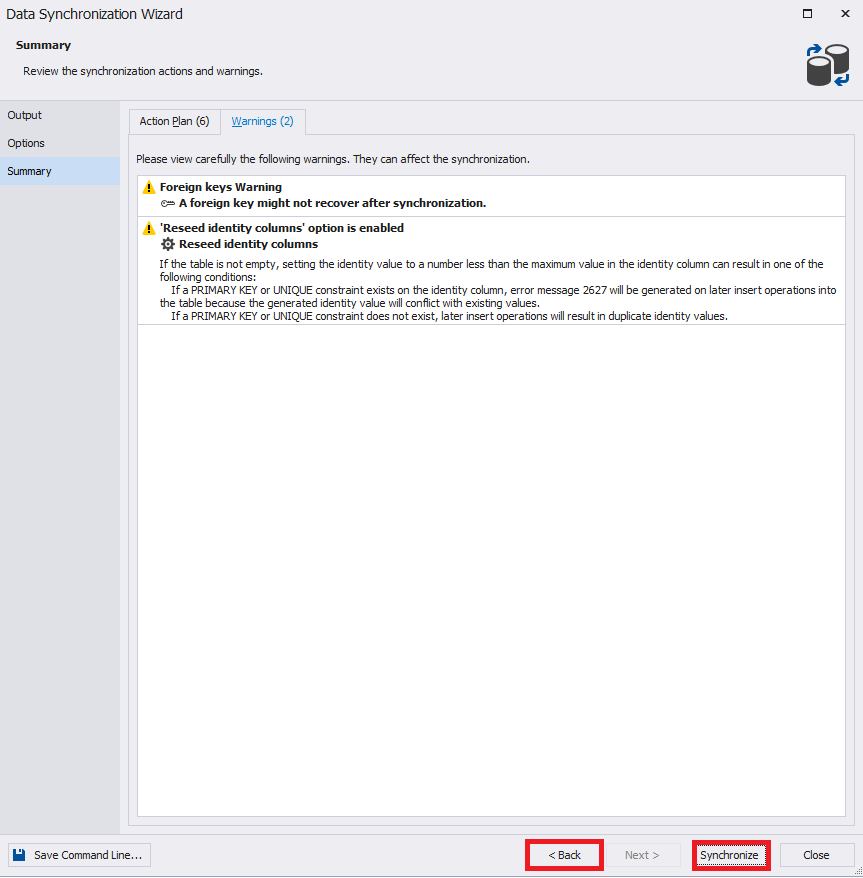
По завершении будет сгенерирован скрипт в новое окно:
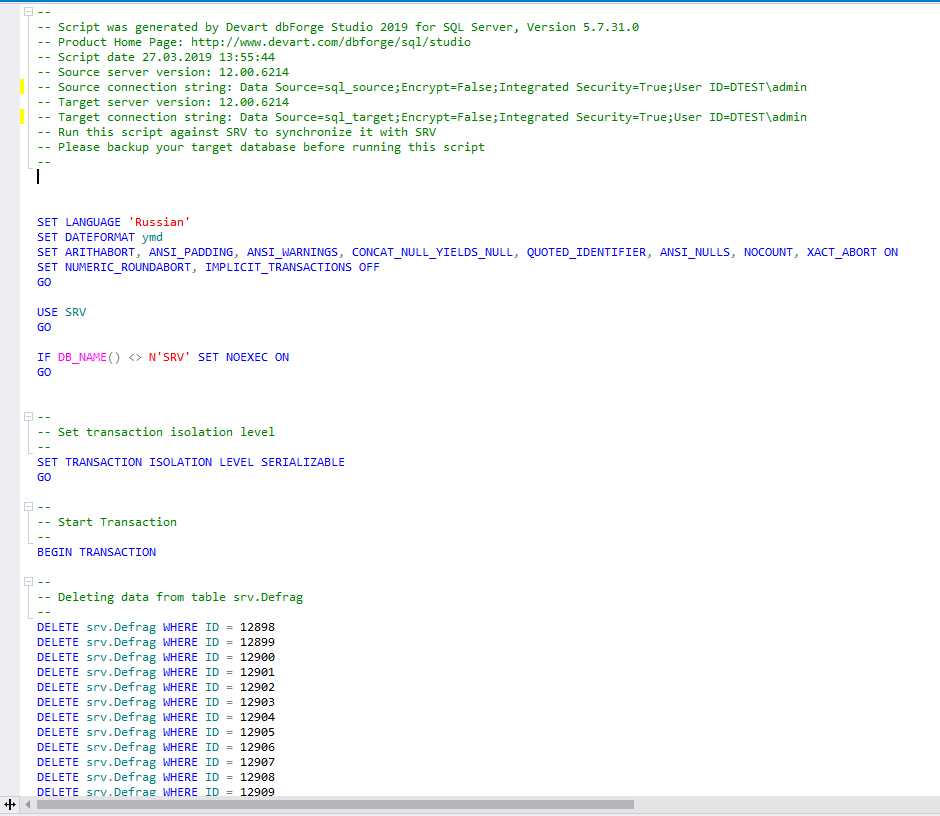
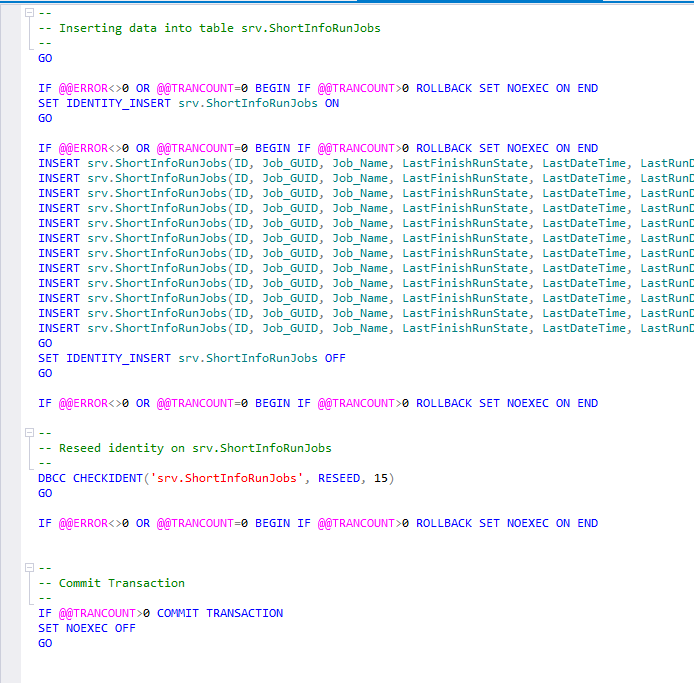
Данный скрипт и есть код для переноса изменений данных с источника на приемник. Его можно применить на сервере — приемнике или сохранить в файл для последующего применения на сервере — приемнике.
После синхронизации выбранные ранее объекты должны исчезнуть из окна сравнения данных.
Краткий обзор инструмента dbForge Compare Bundle for SQL Server
Помимо самой dbForge Studio for SQL Server для сравнения данных и схем баз данных можно использовать инструмент dbForge Compare Bungle for SQL Server от компании Devart, который встраивается в SQL Server Management Studio (SSMS). Рассмотрим пример использования данного инструмента в SSMS:
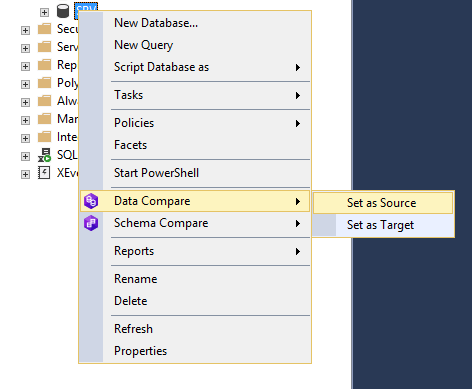
Здесь нужно нажать правой кнопкой мыши на нужную базу данных и выбрать необходимое действие: сравнение данных или сравнение схемы. После этого установить выбранную базу данных как источник или как приемник. Аналогичным образом выбрать вторую базу данных как приемник или как источник.
После установки источника и приемника для начала настройки синхронизации данных или схемы баз данных необходимо нажать на зеленую стрелку посередине экрана:
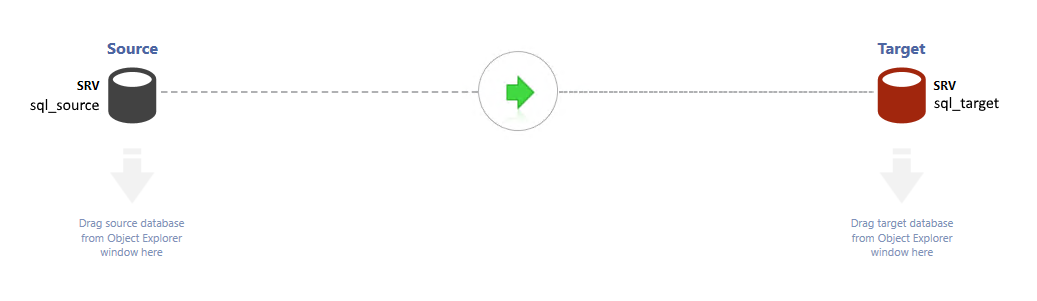
После этого появится привычное окно настроек синхронизации данных или схем баз данных в зависимости от того, что было выбрано ранее.
Решения от компании Quest Software
Инструменты ApexSQL Diff и ApexData Diff от компании Quest Software встраиваются в SSMS.
Также данные инструменты могут работать самостоятельно и без SSMS.
Синхронизация схем баз данных
В главном меню для запуска тулзы достаточно выбрать ApexSQL\ApexSQL Diff\Launch:
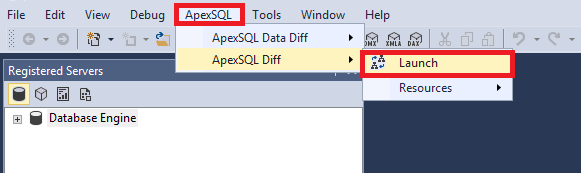
В появившемся окне нажмите внизу на кнопку “New”:

Откроется окно параметров сравнения схем баз данных. Теперь необходимо заполнить нужные поля на вкладке «Data sources»:
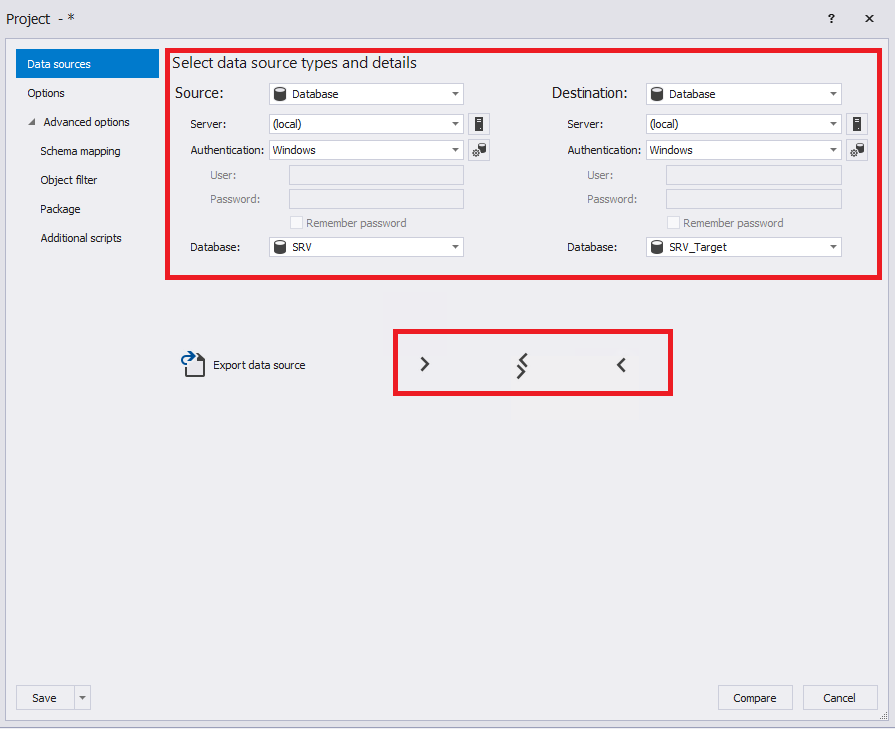
Обратите внимание на стрелки внизу. Они позволяют менять местами настройки слева направо и справа налево, а также копировать настройки слева направо и справа налево. Далее нажмите на вкладку «Options» и выберите необходимые настройки сравнения схем баз данных (можно ничего не менять):
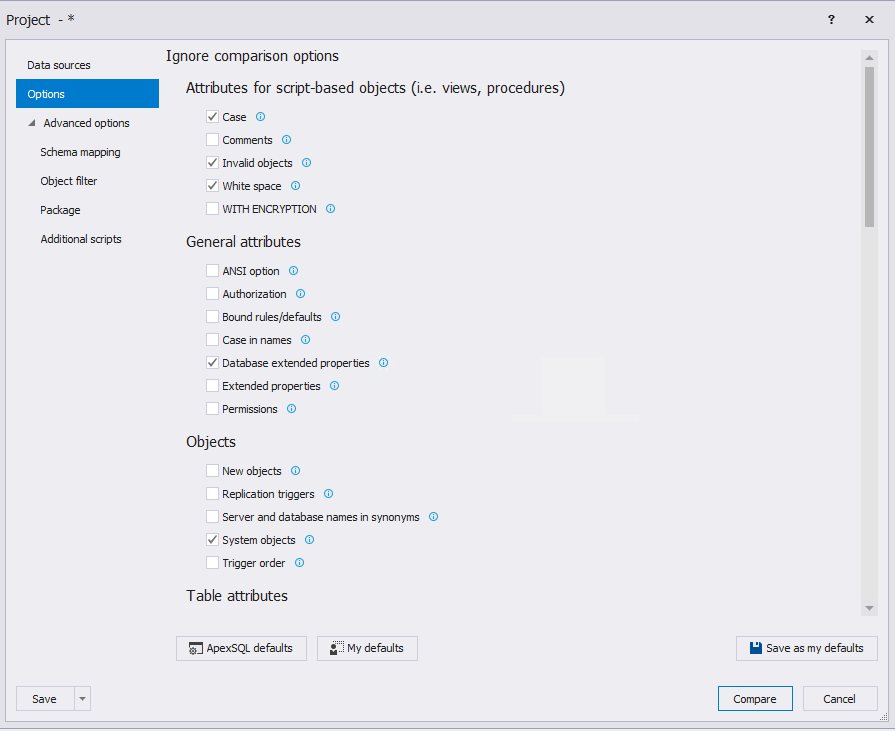
Теперь необходимо перейти на вкладку «Advanced options» и просмотреть расширенные настройки, которые при необходимости можно изменить. Вкладка «Schema mapping» содержит сопоставление схем для сравнения:
Также есть и ряд других расширенных настроек:
- расширенные настройки вкладки «Object Filter»:
- расширенные настройки вкладки «Package»:

- расширенные настройки вкладки «Additional scripts»:
В конце необходимо нажать на кнопку «Compare», чтобы запустить процесс сравнения схем баз данных. В конце появится окно, где слева будут располагаться объекты схемы базы данных источника, а справа — объекты базы данных приемника:
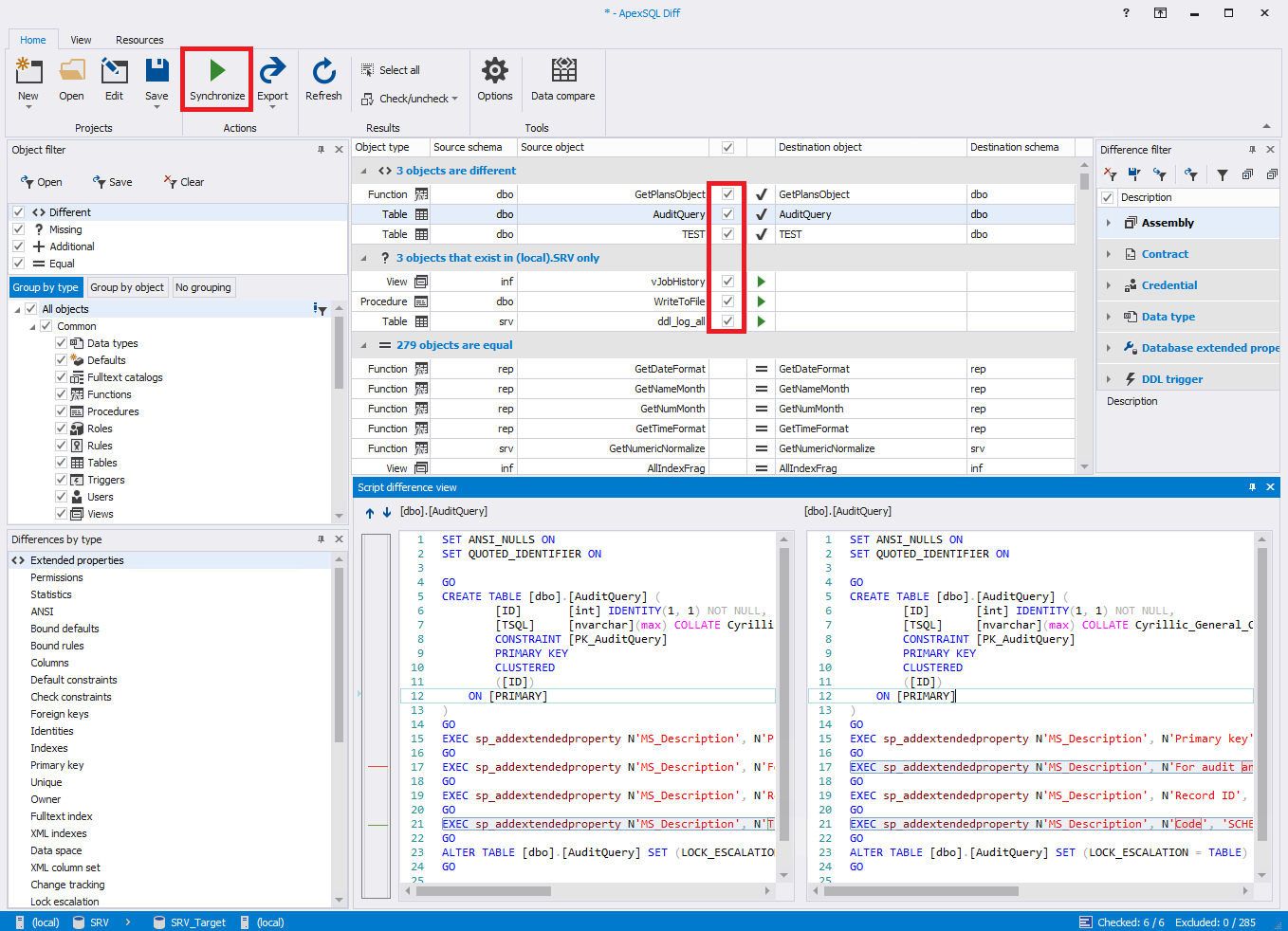
Внизу окна располагается код определения выбранного объекта, а также подсвечиваются различия в кодах определения одного и того же объекта в разных базах данных.
Здесь необходимо выбрать нужные объекты для синхронизации схем баз данных.
После этого необходимо нажать на кнопку с изображением зеленой стрелки «Synchronize».
Откроется окно настроек непосредственно самой синхронизации баз данных.
На вкладке «Synchronization direction» задается направление синхронизации.
Далее, необходимо нажать на кнопку «Next»:

На вкладке «Dependencies» показываются зависимости:
На вкладке «Output options» указываем, что необходимо сгенерировать скрипт синхронизации:
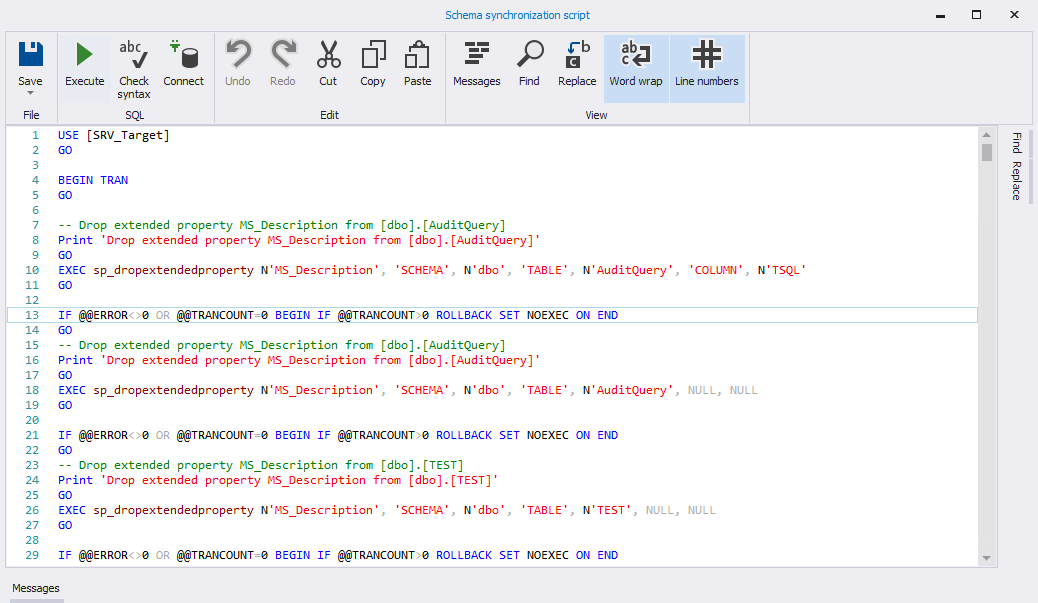
На вкладке «Summary and warnings» отображается итоговая информация по выбранным настройкам синхронизации. Для начала создания скрипта синхронизации необходимо нажать на кнопку «Create script»:

В конце будет выведен скрипт:
Теперь рассмотрим по подробнее верхнюю панель проекта синхронизации схем баз данных:

Вкладка «View» содержит различные настройки по отображению компонентов окна.
Вкладка «Resources» содержит информацию о продукте, а также ссылки на документацию и центр поддержки пользователей. Теперь разберем вкладку «Home». Само сравнение схем можно выполнить в виде SSIS-пакета:

Сохранить проект можно в виде автоматизированного скрипта:

Также есть возможность сформировать отчеты о сравнении в разных форматах:

Синхронизация данных баз данных
В главном меню для запуска утилиты достаточно выбрать ApexSQL\ApexSQL Data Diff\Launch:
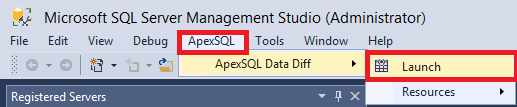
В появившемся окне нажмите внизу на кнопку “New”:

Откроется окно параметров сравнения данных баз данных. Теперь необходимо заполнить нужные поля на вкладке «Data sources»:
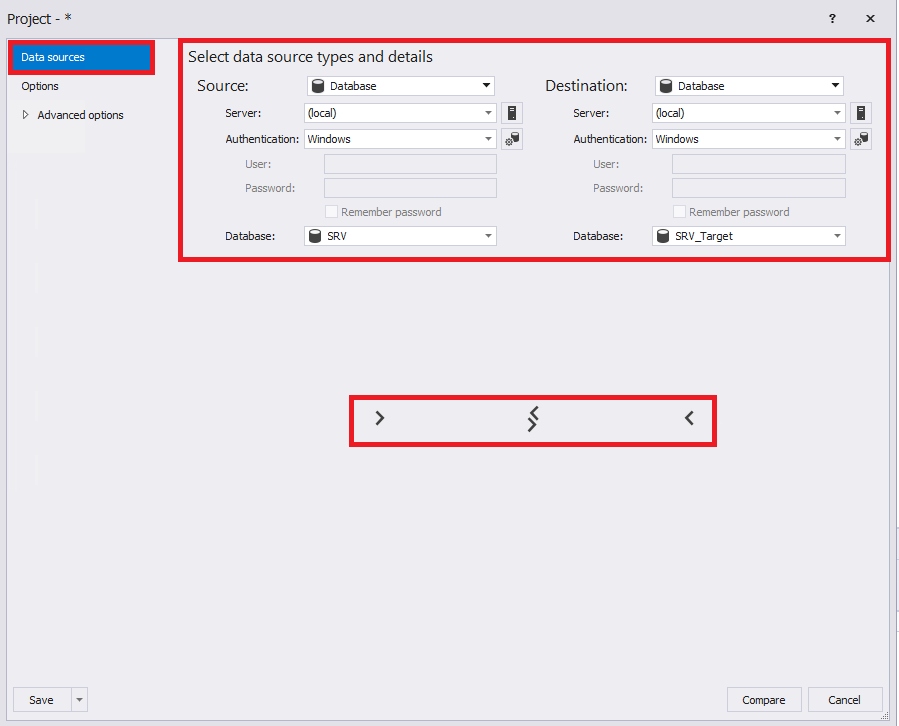
Обратите внимание на стрелки внизу. Они позволяют менять местами настройки слева направо и справа налево, а также копировать настройки слева направо и справа налево.
Далее нажмите на вкладку «Options» и выберите необходимые настройки сравнения данных баз данных (можно ничего не менять):
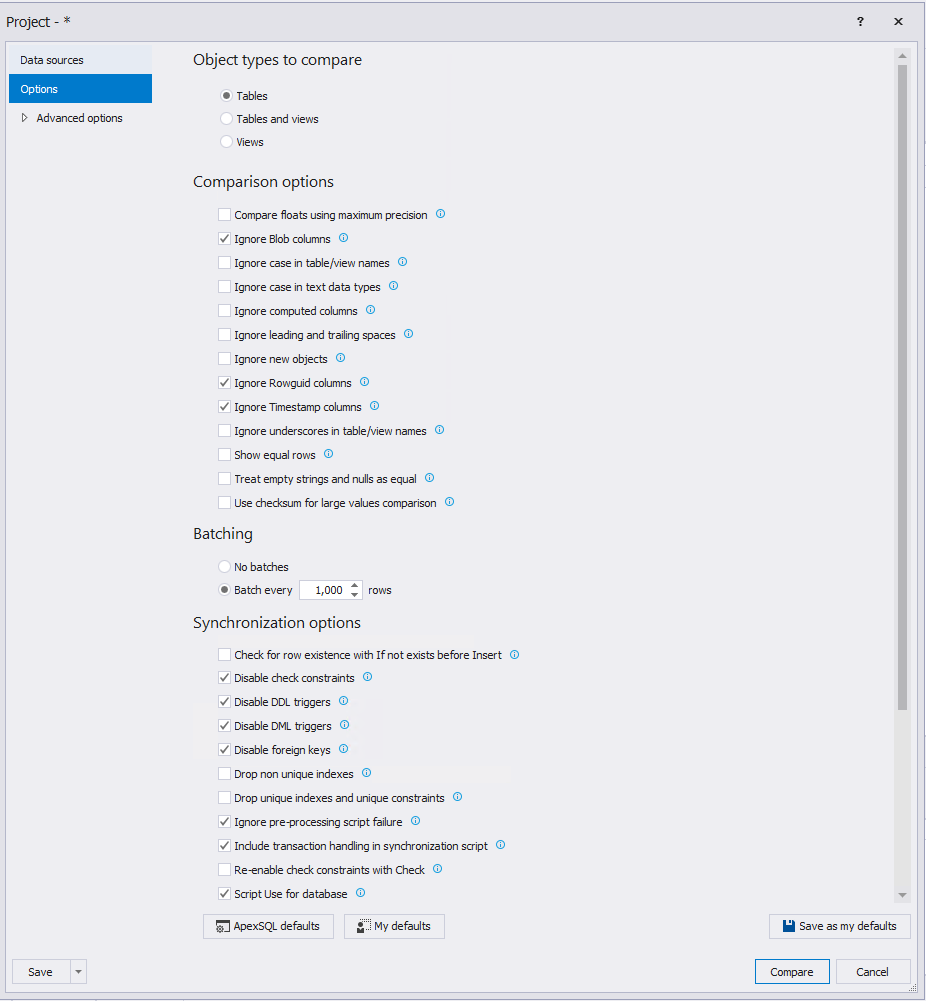
Во вкладке «Advanced options» можно просмотреть расширенные настройки, которые при необходимости можно изменить. Они аналогичные тем, что были приведены выше для сравнения схем баз данных. Добавляется только еще одна вкладка «Object mapping»:
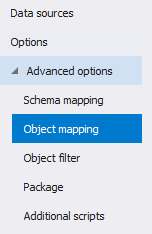
На этой вкладке сопоставляются для сравнения данных таблицы, колонки и их содержимое.
После всех настроек необходимо нажать на кнопку «Compare» для запуска процесса сравнения данных баз данных:
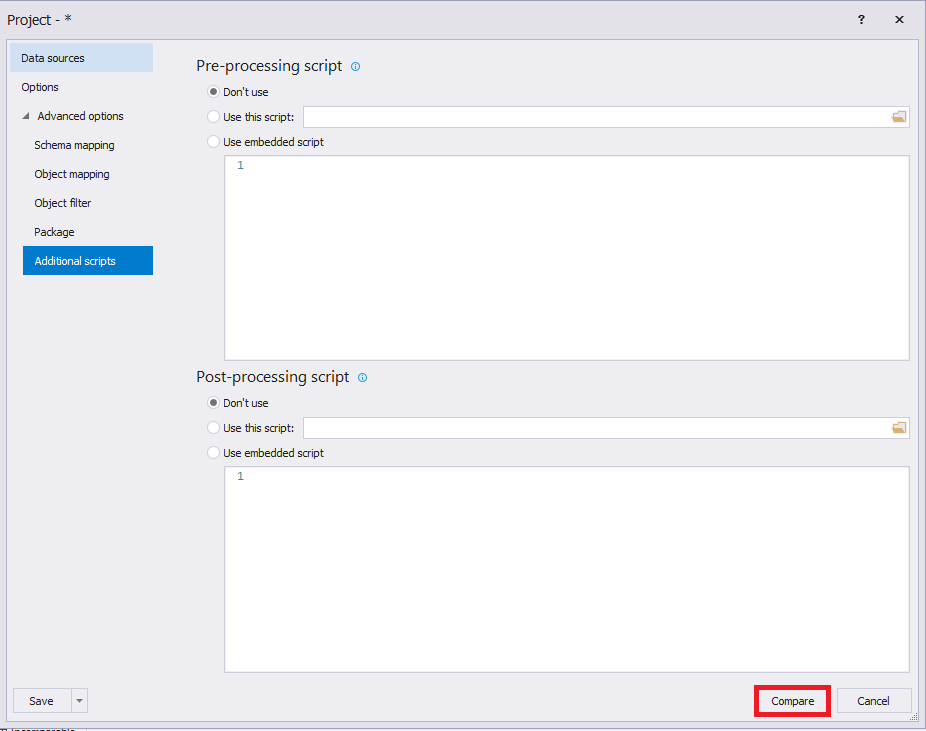
По окончании процесса сравнения данных баз данных выведется окно разности в данных:
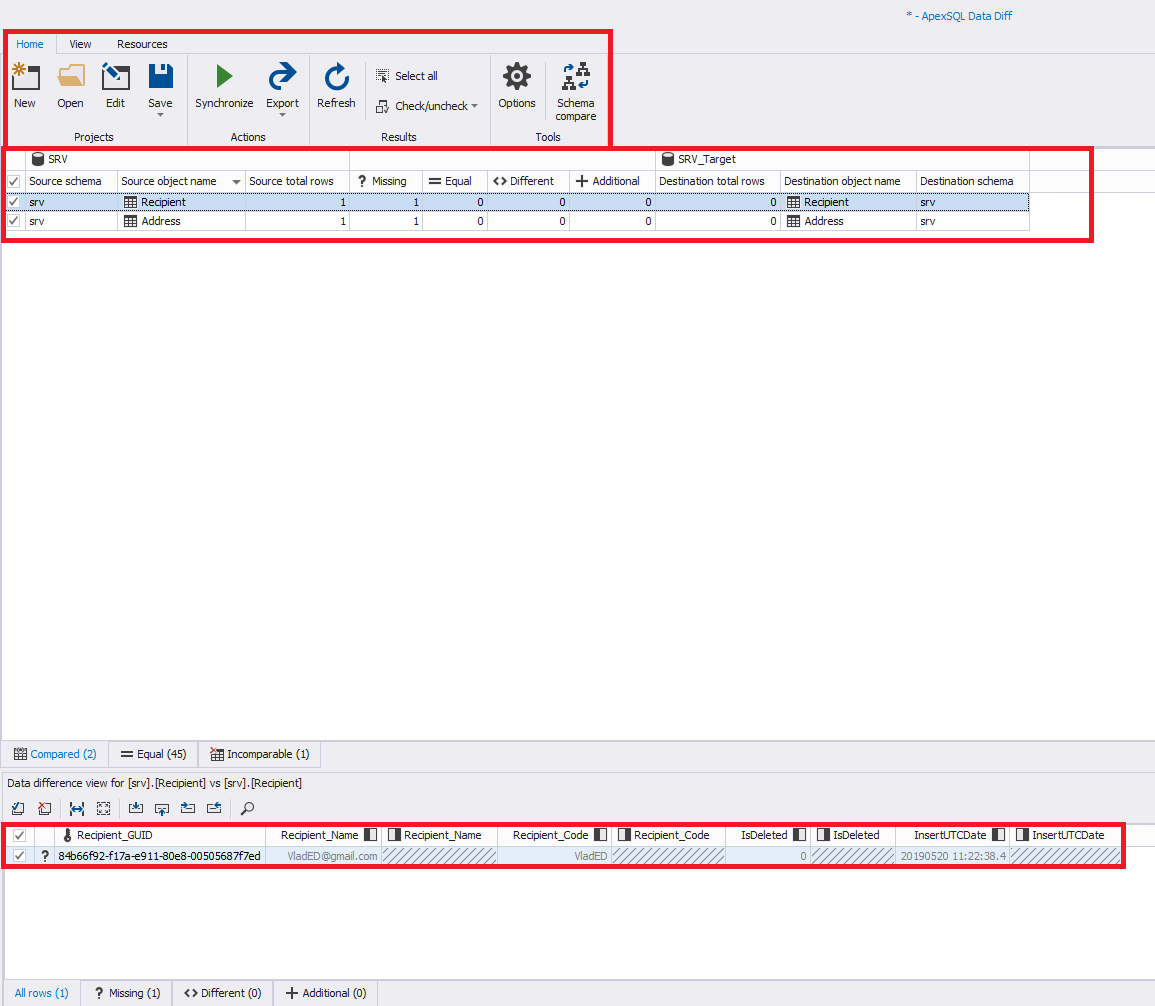
По середине окна располагается список таблиц, в которых находятся отличающиеся записи, а внизу отображаются эти различия для выбранной таблицы. Слева отображаются данные, которые присутствуют на источнике, а справа — на получателе.
К главному окну вернемся ниже, а сейчас необходимо выбрать галочками слева какие таблицы и строки будем синхронизировать. После чего в главном меню нужно нажать на кнопку с изображением зеленой стрелки «Synchronize».
Откроется окно настроек непосредственно самой синхронизации баз данных.
На вкладке «Synchronization direction» задается направление синхронизации.
Далее, необходимо нажать на кнопку «Next»:

На вкладке «Output options» указываем, что необходимо сгенерировать скрипт синхронизации:
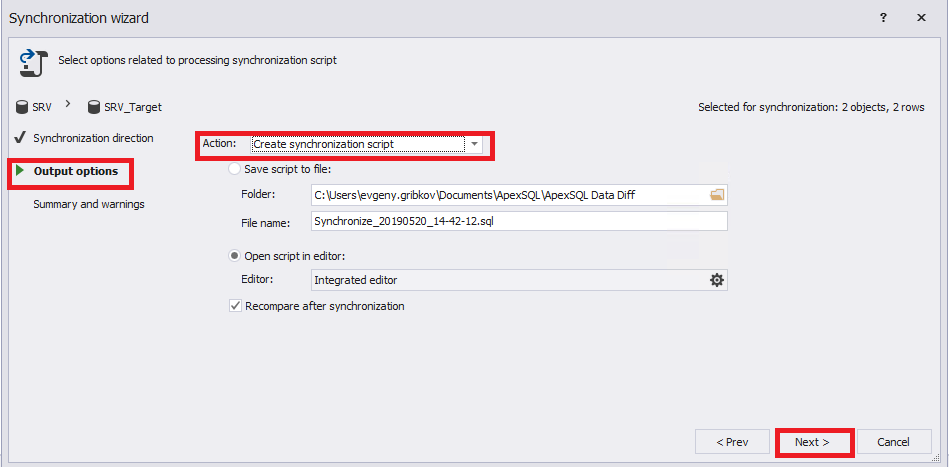
На вкладке «Summary and warnings» отображается итоговая информация по выбранным настройкам синхронизации. Для начала создания скрипта синхронизации необходимо нажать на кнопку «Create script»:
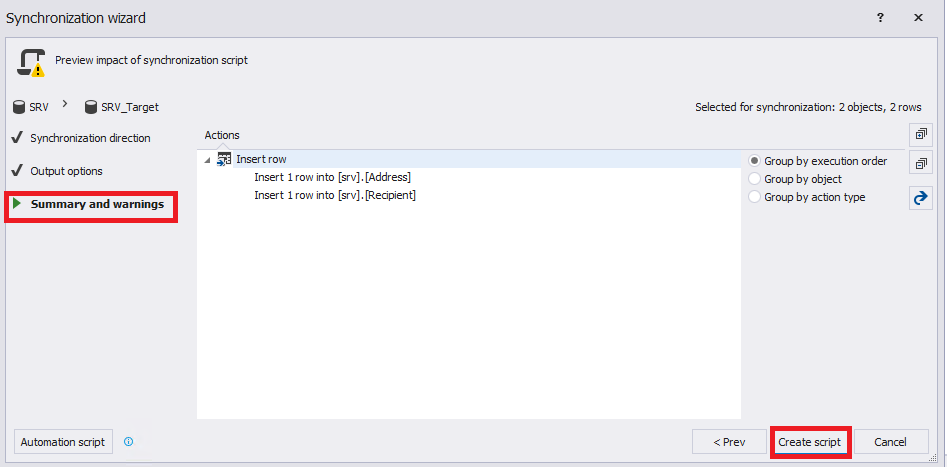
В конце будет выведен скрипт:

Теперь рассмотрим по подробнее верхнюю панель проекта синхронизации данных баз данных, а именно само главное меню:

Вкладка «View» содержит различные настройки по отображению компонентов окна.
Вкладка «Resources» содержит информацию о продукте, а также ссылки на документацию и центр поддержки пользователей.
Теперь разберем вкладку «Home».
Сохранить проект можно в виде автоматизированного скрипта:
Также можно сделать экспорт проекта в различные форматы:
Решения от компании RedGate
Теперь рассмотрим инструменты SQL Compare и SQL Data Compare от компании RedGate.
Синхронизация схем баз данных
Инструмент SQL Compare от компании RedGate поставляется как отдельная утилита. Потому после его установки необходимо просто открыть новое приложение и на вкладке «Data sources» выбрать синхронизацию баз данных с обеих сторон:
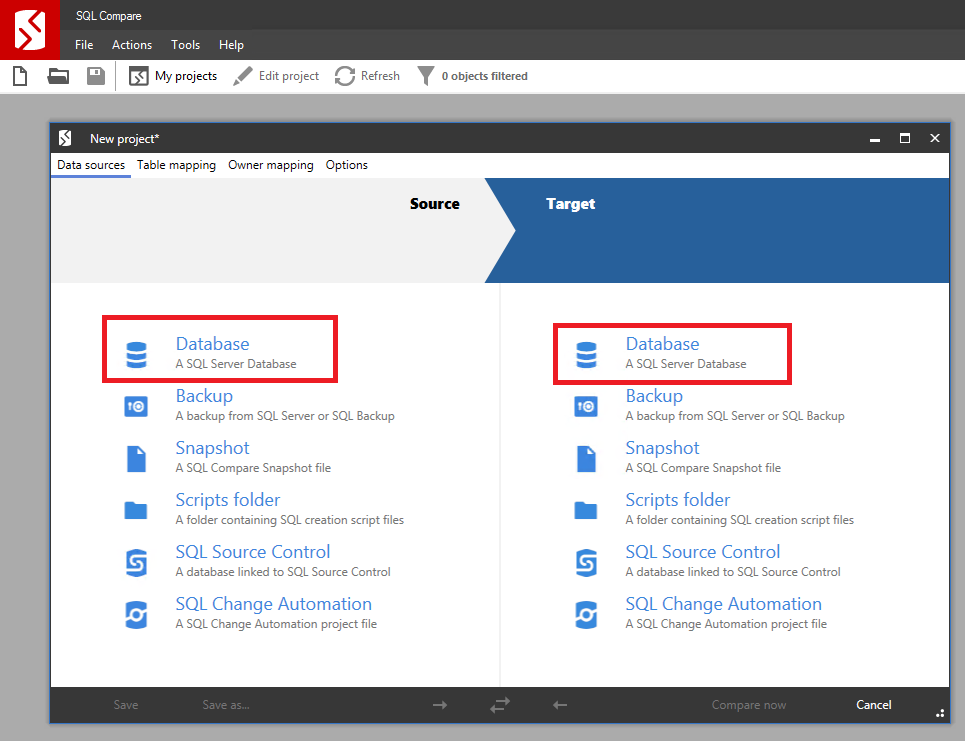
Здесь и далее, как и в тех тулзах, которые были рассмотрены ранее, слева располагается источник, а справа-приемник. Далее необходимо заполнить необходимые поля как на картинке:

На вкладке «Table mapping» отображаются соответствующие друг другу таблицы:

Здесь также можно нажать на «Full» необходимой таблицы и там просмотреть, а потом при необходимости и изменить, сопоставление колонок выбранной таблицы:

На вкладке «Owner mapping» настраивается сопоставление схем:
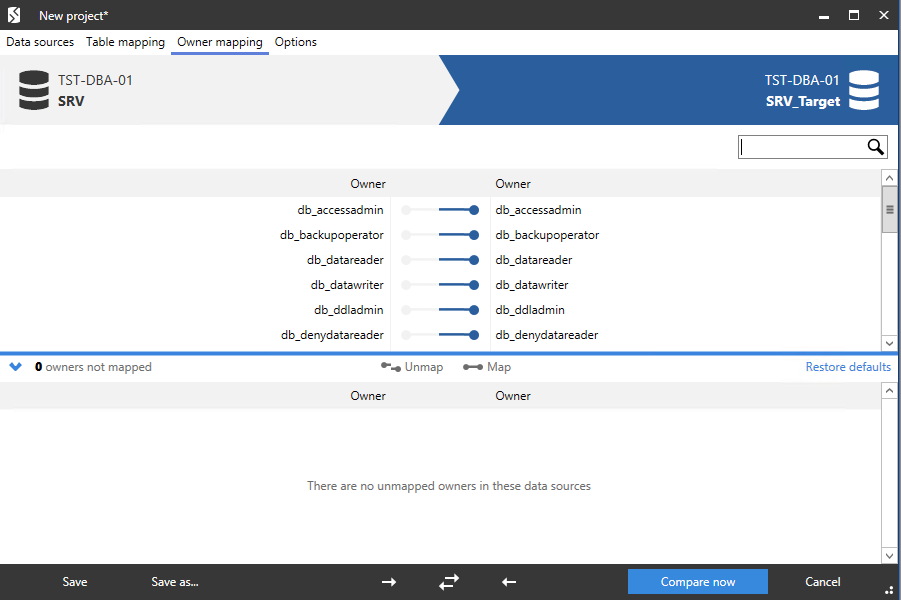
На вкладке «Options» можно просмотреть и настроить дополнительные настройки сравнения схем баз данных:
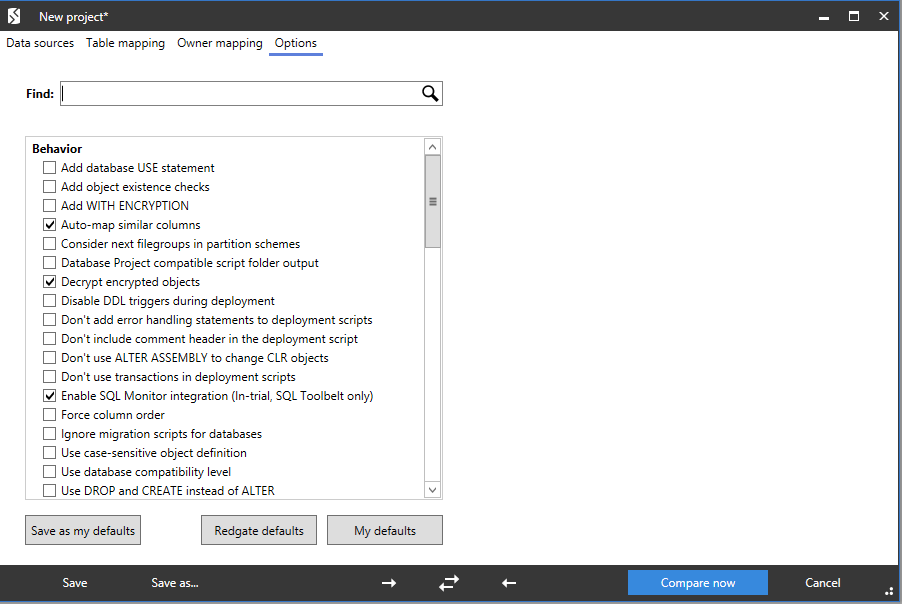
Теперь необходимо нажать внизу на синюю кнопку «Compare now» для запуска процесса сравнения схем баз данных. В конце процесс необходимо нажать внизу на синюю кнопку «OK»:

Будет выведено окно, в котором (подобно ApexSQL Diff) отображается список различий, а внизу код определения выбранного объекта с подсветкой этих различий:
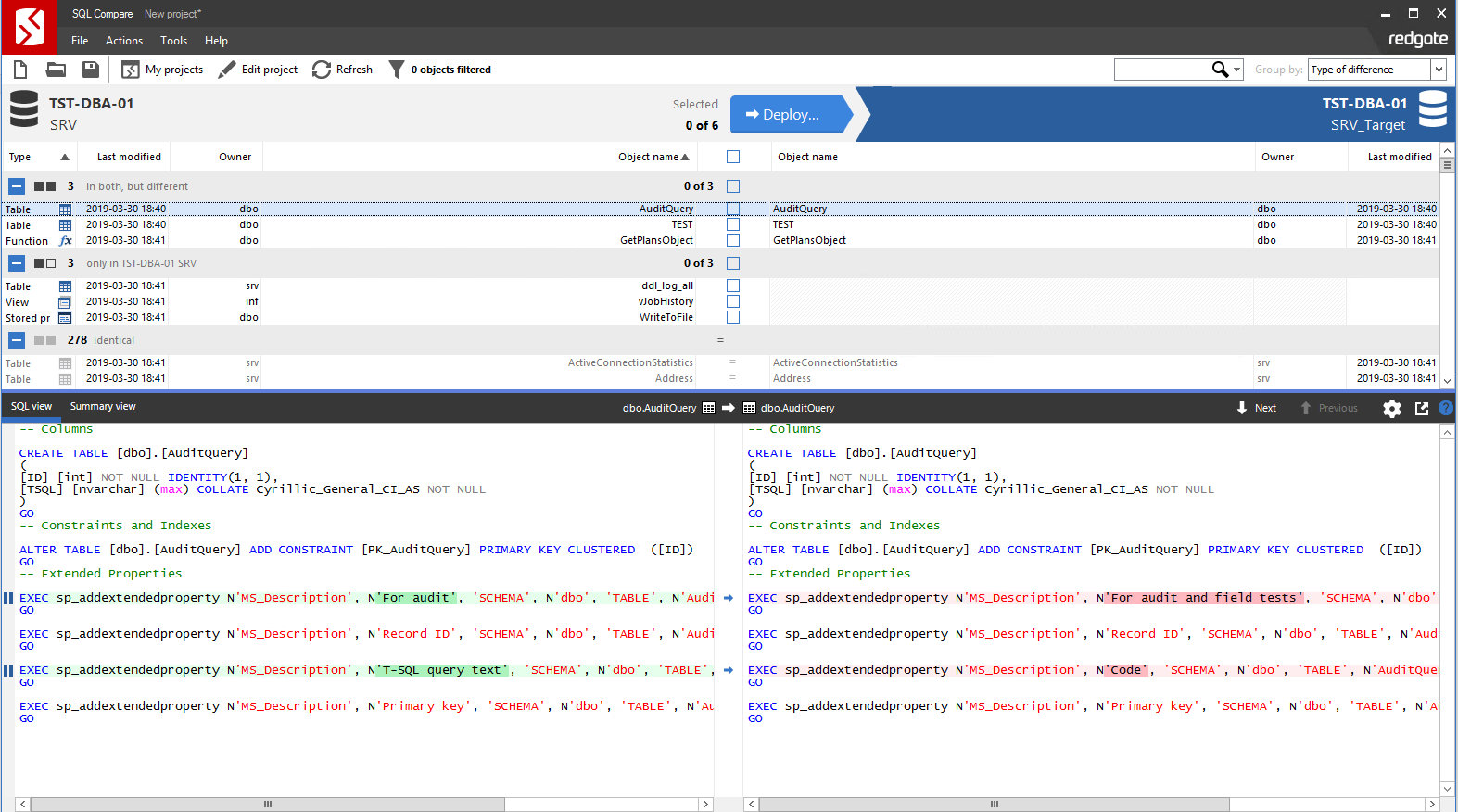
Как и раньше, необходимо выбрать галочками нужные объекты для синхронизации и нажать на большую синюю кнопу «Deploy»:
од определения выбранного объекта с подсветкой этих различий:

После этого откроется окно настроек самой синхронизации схем баз данных.
На вкладке «Deployment method» можно выбрать метод синхронизации схем.
Здесь просто можно нажать на кнопку «Next»:
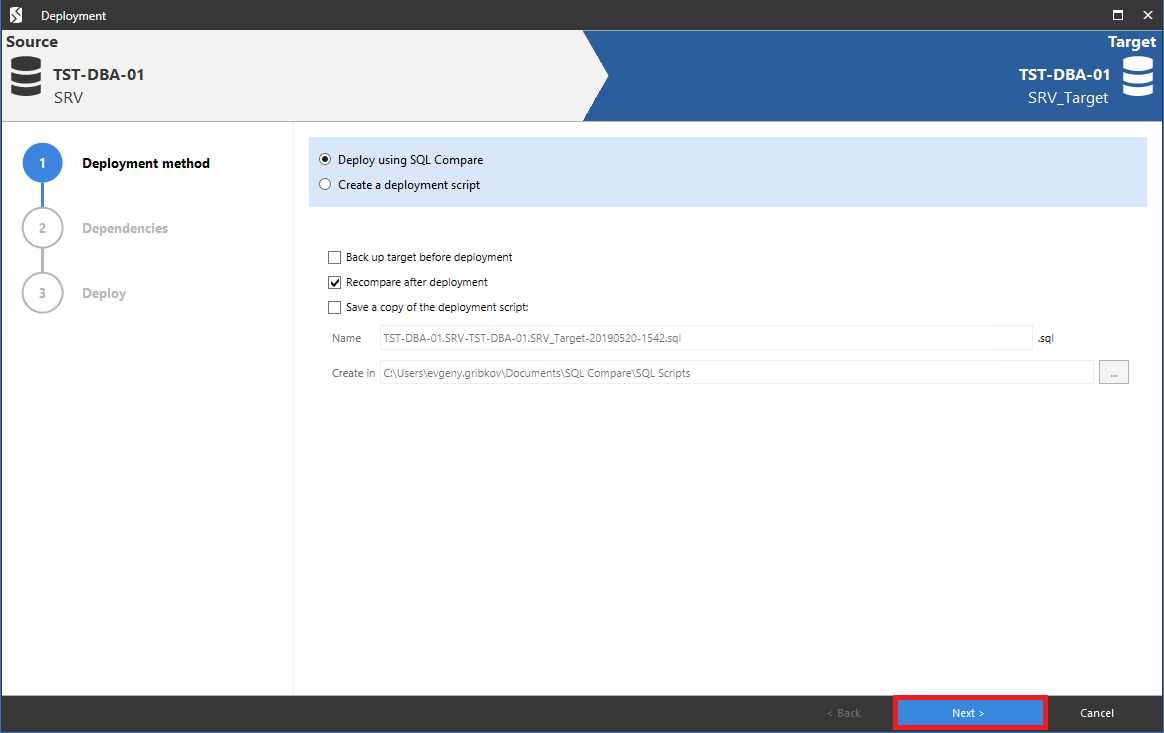
Таким образом получим готовый скрипт синхронизации схем между выбранными базами данных, который можно применить в нужных базах данных:
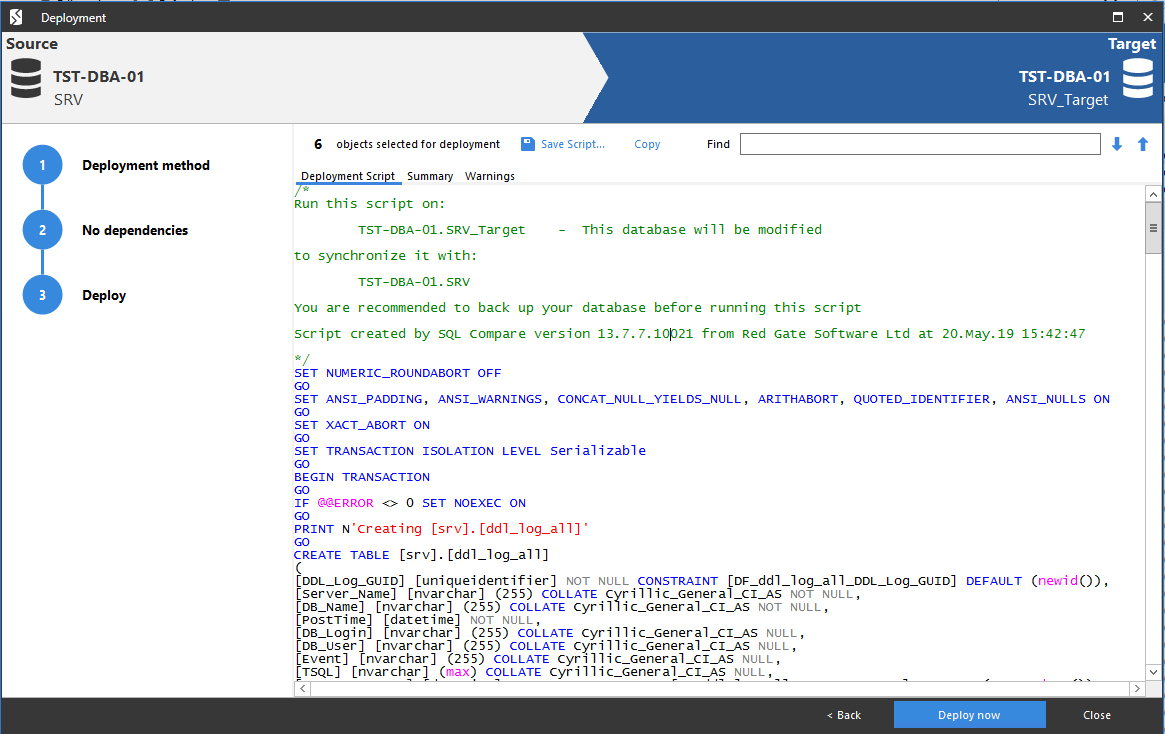
Синхронизация данных баз данных
Инструмент SQL Data Compare от компании RedGate поставляется как отдельная утилита. Потому после его установки необходимо просто открыть новое приложение и на вкладке «Data sources» выбрать синхронизацию баз данных с обеих сторон:
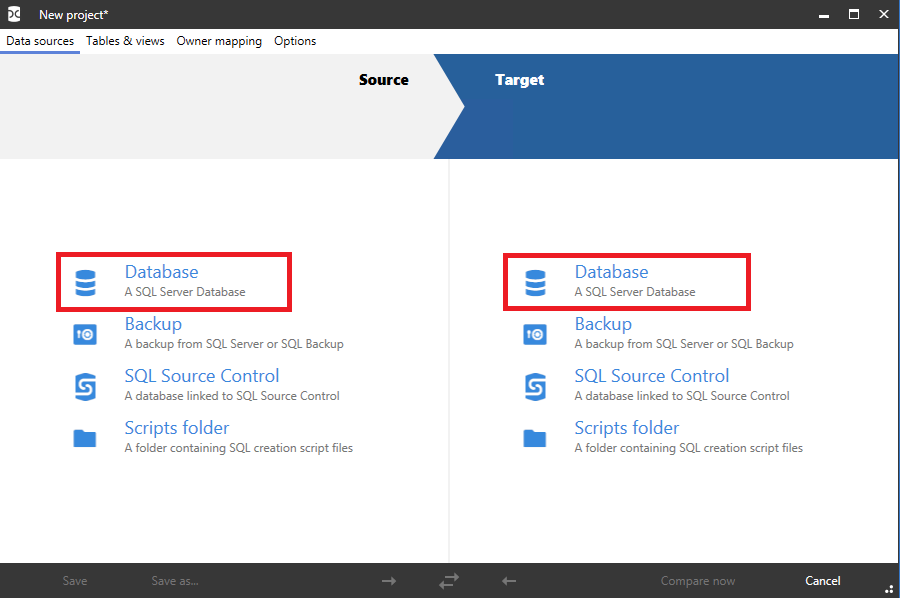
Здесь и далее, как и в тех тулзах, которые были рассмотрены ранее, слева располагается источник, а справа-приемник.
Далее необходимо заполнить необходимые поля как на картинке:

На вкладке «Table & views» отображаются соответствующие друг другу таблицы и представления:
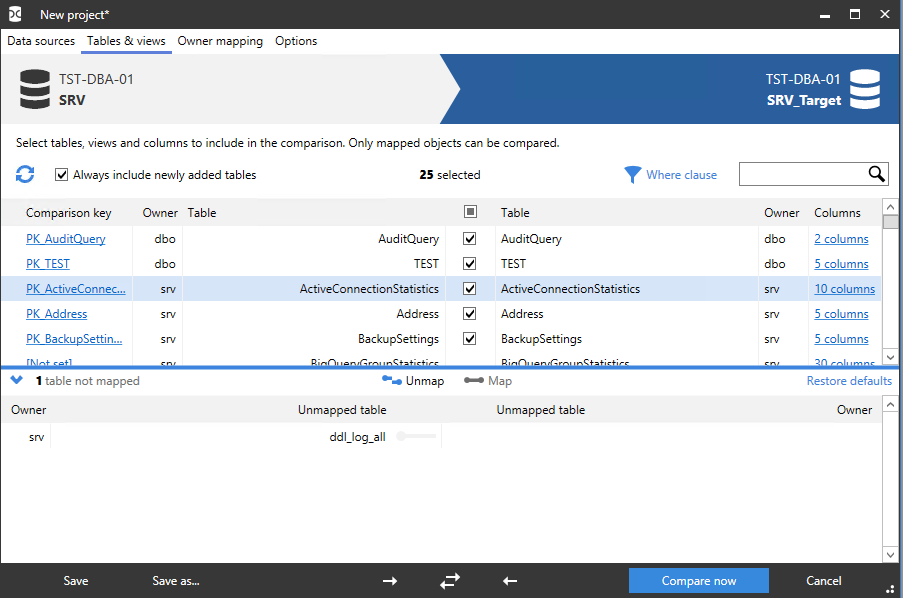
Здесь также можно нажать на «columns» необходимой таблицы или представления и там просмотреть, а потом при необходимости и изменить, сопоставление колонок выбранной таблицы или представления:

На вкладке «Owner mapping» настраивается сопоставление схем объектов баз данных:
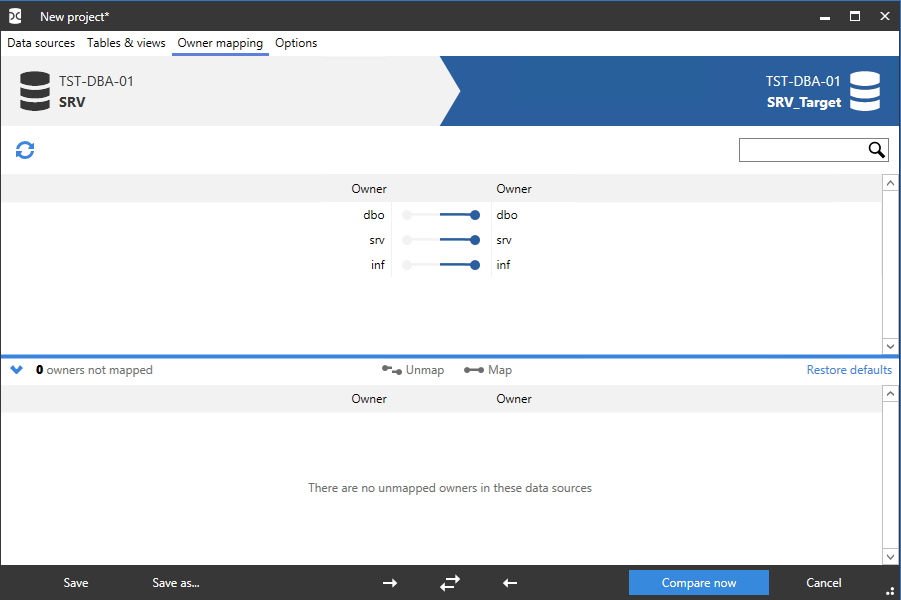
На вкладке «Options» можно просмотреть и настроить дополнительные настройки сравнения данных баз данных:

Теперь необходимо нажать внизу на синюю кнопку «Compare now» для запуска процесса сравнения данных баз данных. В конце процесс необходимо нажать внизу на синюю кнопку «OK»:
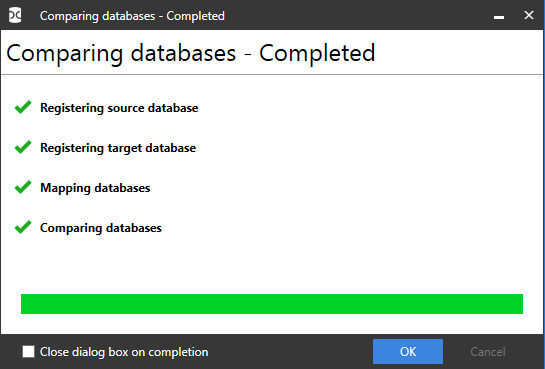
Будет выведено окно, в котором (подобно ApexSQL Data Diff) отображается список различий, а внизу чем отличаются строки выбранной таблицы или представления с подсветкой этих различий:
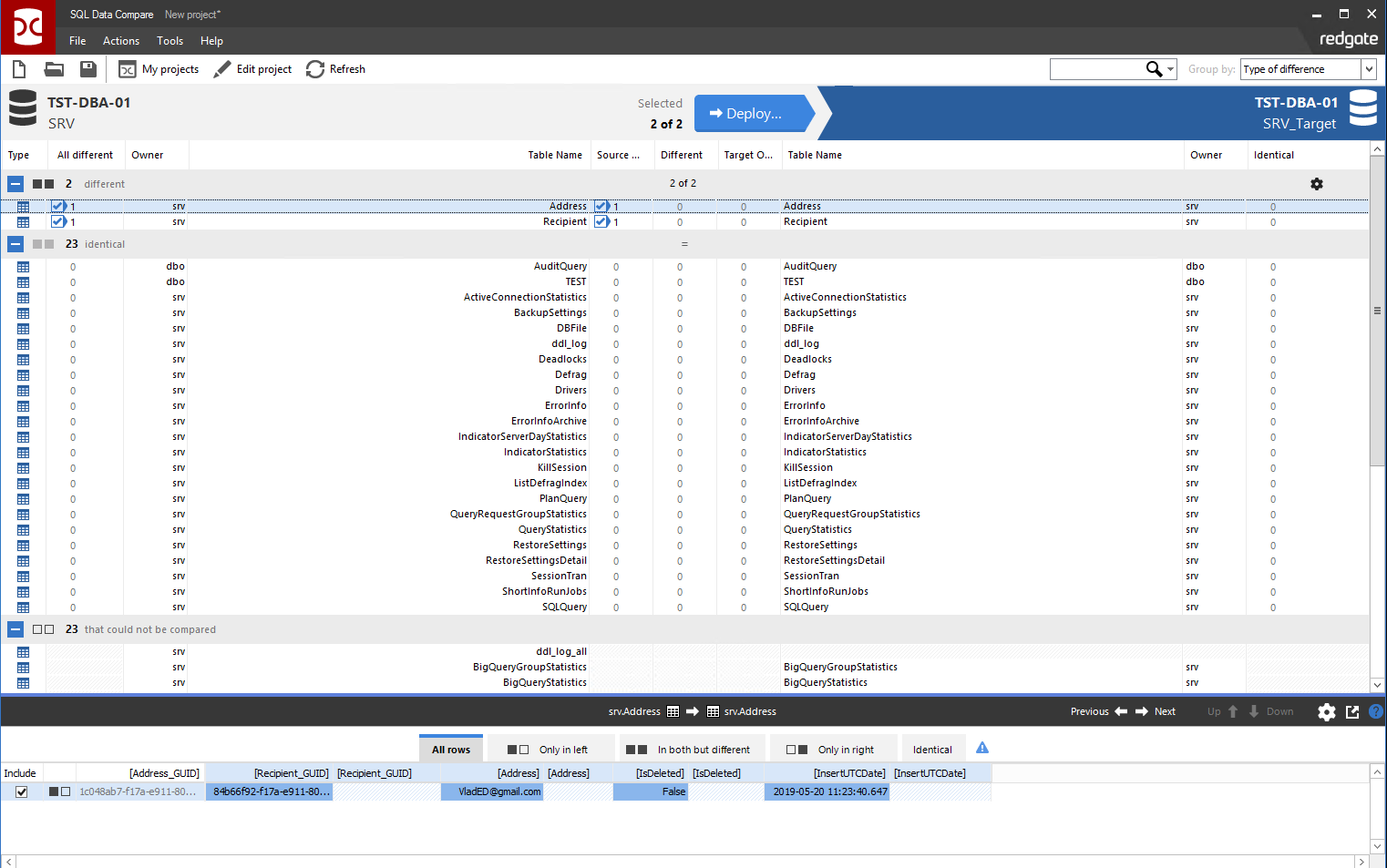
Как и раньше, необходимо выбрать галочками нужные объекты для синхронизации и нажать на большую синюю кнопу «Deploy»:
После этого откроется окно настроек самой синхронизации данных баз данных.
На вкладке «Deployment method» можно выбрать метод синхронизации данных.
Здесь просто можно нажать на кнопку «Next»:
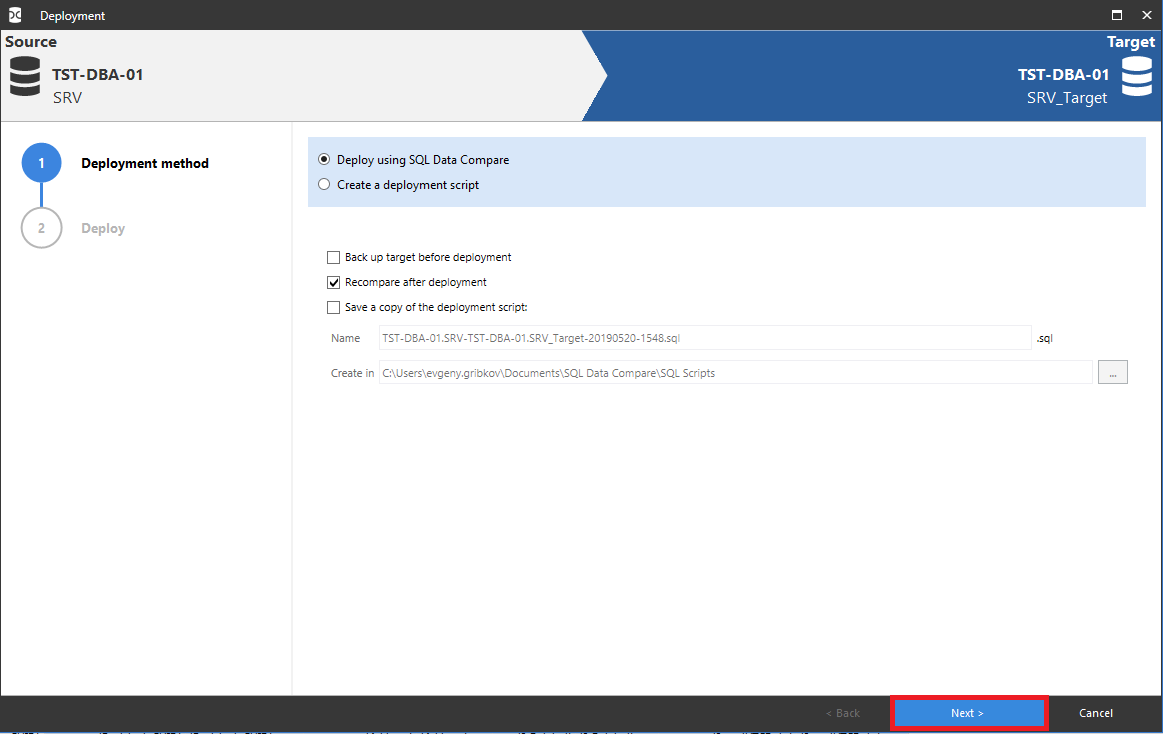
Таким образом получим готовый скрипт синхронизации данных между выбранными базами данных, который можно применить в нужных базах данных:
Сравнение цены и функционала
| Продукт | 1 лицензия | ||
|---|---|---|---|
| ApexSQL Diff | 599$ | 359$ | |
| 599$ | 359$ | ||
| SQL Compare | 785$ | 785$ | |
| SQL Data Compare | 785$ | 785$ | |
| 300$ | 300$ | ||
| 300$ | 300$ |
Стоит также отметить, следующие функциональные возможности рассмотренных выше инструментов:
- источником для сравнения может служить:
- база данных
- снимок
- папка со скриптами
- резервная копия
- система управления версиями
- с данными инструментами можно работать через командную строку
- синхронизацию можно выполнить напрямую или сохранить скрипт синхронизации для последующего выполнения. Также можно сохранить в виде bat-файла
На официальном сайте тулзы ApexSQL Diff приводится сравнение данной программы с тулзой SQL Compare.
Аналогично, и для тулзы ApexSQL Data Diff приводится сравнение с тулзой SQL Data Compare.
По приведенным сравнениям легко видеть, что что-то есть в ApexSQL, чего нет в Compare, а что-то наоборот есть в Compare, но нет в ApexSQL. Но все рассмотренные утилиты обладают необходимым набором основного функционала для сравнения как схем, так и самих данных баз данных.
По функционалу и цене, с учетом скидок и рассмотренного материала выше, продукты ApexSQL Diff и ApexSQL Data Diff являются оптимальным выбором.
Заключение
Были рассмотрены популярные утилиты для синхронизации схем и данных баз данных:
- dbForge Schema Compare for SQL Server компании Devart
- dbForge Data Compare for SQL Server компании Devart
- ApexSQL Diff компании Quest Software
- ApexSQL Data Diff компании Quest Software
- SQL Compare компании RedGate
- SQL Data Compare компании RedGate
Также было проведено краткое сравнение по цене и функционалу этих продуктов.
Итогом рассмотрения стал вывод о том, что оптимальным выбором по цене и функционалу являются продукты ApexSQL Diff и ApexSQL Data Diff компании Quest Software. Однако, основной необходимый функционал в достаточной степени есть и в продуктах компании Devart: dbForge Schema Compare for SQL Server и dbForge Data Compare for SQL Server. Эти продукты можно купить существенно дешевле, чем их аналоги ApexSQL Diff и ApexSQL Data Diff от компании Quest Software.
Аналогичные решения есть и для СУБД Oracle.
А какие компараторы помогают вам и для каких СУБД для сравнения схем и данных баз данных?
После дискуссий
Также коллеги в комментариях и в переписках рекомендовали следующие интересные компараторы:
- для сравнения схем и данных баз данных разных СУБД
- для перехода с MS SQL Server на PostgreSQL:
- для сравнения схем и данных баз данных СУБД MS SQL Server
- для перехода с одной СУБД в другую СУБД и для сравнения схем и данных баз данных разных СУБД
- для переноса БД Jira из СУБД MS SQL Server в СУБД PostgreSQL
Источники
Комментарии (37)

Silnur
02.09.2019 14:49+2Microsoft SQL Server Data Tools для этих целей не достаточно?

jobgemws Автор
02.09.2019 14:53+1Вполне достаточно, но рассматривались сторонние утилиты для быстрой настройки.
Про SSDT также сказано вначале (но не расписывалось сильно): Visual Studio Comparer+SSIS (сюда и SSDT входит)aleyush
03.09.2019 20:29Поясните, пожалуйста: что важное умеют рассмотренные утилиты, чего не делает бесплатный SSDT?
Пользуюсь им, навскидку всё то же самое. Хочу понять, что я упускаю.jobgemws Автор
03.09.2019 20:35Меньше нужно писать кода, кликать мышкой и более быстро получить результат.
А также значительно малый порог вхождения.
SSDT сам пользовался пока баз и экземпляров скулей не перевалило за сотни.
Тогда даже каждый лишний клик и каждая лишняя секунда значительно увеличивает время работы.

dude_sam
02.09.2019 15:24Что-то не увидел раздела с откатом изменений? Или под «откатом» имелось в виду «запуск скрипта миграции внутри транзакции»?
jobgemws Автор
02.09.2019 15:35В данном случает внутри транзакции
Код тоже готовится в транзакции
Также код можно поместить и в другую транзакцию или придумать иной способ отката, зная что именно меняется по коду

anshev0
02.09.2019 15:27+1Спасибо за труд по сравнению. Используем RedGate, редко в проектах dbForge. Давно сравнивали и Apex, но на тот момент не показался лучшим. Большая часть — это автоматические скрипты для сравнения структур, которые синхронизируют, что нужно. Ценники кусачие и растут, но приходится покупать, так реально экономят время и деньги, а проекты не в России.
jobgemws Автор
02.09.2019 15:37+1Но ведь решения от RedGate очень дорогие. Чем не подошел Apex? И чем не подошел DbForge?
Я использую в основном DbForge и иногда Apex.anshev0
02.09.2019 16:17+1Да, RedGate не дёшев, но обычно выбивали скидки под количество лицензий с несколькими программами, когда цена значительно меньше. Ещё используем Prompt (подсказчик), SQL Monitor (мониторинг), Search. Возможно, к RedGate торрены давно находились просто, поэтому у нас ещё исторически их пробовал народ. ) Учту Ваш вывод в статье, проверит кто-нибудь инструменты на сегодня. VisualStudio — тоже улучшилась в плане БД, некоторые любят руками сравнивать в нём. От Apex-а обычно ApexLog — аудитор лога пользуем. Так что со всеми участниками знакомы.
akhkmed
02.09.2019 17:06+1Подскажите, пожалуйста, не рассматривали «примитивные» средства ведения кода и структуры баз данных, когда все объекты БД выгружаются в текстовые файлы в фиксированной древовидной структуре?
Из плюсов: это условно бесплатно, удобно сравнивать окружения, можно использовать традиционные системы версионного контроля со всеми вытекающими для командной работы.
Из минусов: все миграции необходимо описывать руками в скриптах, что трудоёмко, но даёт больше контроля над происходящим.jobgemws Автор
02.09.2019 17:21Да, давно как-то так и делал
В принципе такой же подход но улучшенный есть и в VS, когда создаете проект БД.
Следующее развитие- это SSIS (SSDT).
И потом уже эти и подобные тулы.

k-semenenkov
02.09.2019 17:13Пользуюсь своим MssqlMerge (сорри за рекламу).
Я сам не дибигай, и мне как правило нужно обозреть изменения или проверить менялось ли что-то конкретное, сравнить, и в редких случаях точечно смержить или сгенеить скрипт, продукт пока развивается больше исходя из собственных нужд.jobgemws Автор
02.09.2019 17:13+1Можете ли выложить проект в гитхаб и дать ссылку?
k-semenenkov
02.09.2019 17:30Выложить в гитхаб — нет, не могу. Пока у меня еще есть к нему небольшой корыстный интерес :). Я думаю что упомянутые в статье компании тоже не стали бы.
И да — хотел, но не смог отредактировать мой предыдущий камент — спасибо большое за обзор!jobgemws Автор
02.09.2019 18:12Ок, но хотя бы можете выложить ссылку на описание продукта?
Если такого нет, то в ближайшем будущем плиз дайте.
P.S.: Рад всегда делиться и помогать)k-semenenkov
02.09.2019 18:35+1Ссылку на описание — конечно! (сперва подумал что ссылка интересна только после выкладывания на гитхаб)
www.db-merge-tools.net/mssqlmerge
Есть еще видео-презентация на 7 минут — youtu.be/JClUOQ1J9HE, старенькая правда, но принципиально с тех пор не сильно что поменялось, добавилось больше поддерживаемых типов объектов и стало чуток красивей.jobgemws Автор
02.09.2019 19:53Благодарю за инфу, а на чем написана тулза и какие библиотеки использует?
Какие технические требования к ПО?k-semenenkov
02.09.2019 21:57На c#/WPF, библиотеки — DiffPlex для сравнения текста и Microsoft.SqlServer.Types для работы с некоторыми типами данных. В платной версии есть эксель экспорт — он к сожалению сейчас требует наличия самого экселя на машине, наследие более ранней утилиты для Аксесса которая предполагала наличие полного офиса.
Тех требования — Windows XP и выше, наличие .net framework 4 client profile или выше, по железу каких либо специфических требований нет. Для активации триала желателен интернет (но не обязателен), для бесплатной версии или при наличии ключа — не требуется.jobgemws Автор
02.09.2019 22:38Благодарю за ответ.
А есть ли что-то подобное для PostgreSQL, а также для сравнения схем и данных между MS SQL Server и PostgreSQL?k-semenenkov
02.09.2019 22:47Для PostgreSQL — нет, пока только желание в очень далеком будущем, я с ним еще не работал.
MS SQL Server и PostgreSQL — тоже нет, сравнивать разные разные СУБД пока даже не планирую вообще, слишком много других хотелок по развитию того что уже есть.jobgemws Автор
02.09.2019 23:05Компаратор для разных СУБД очень актуален в силу перехода с одной СУБД на другую СУБД.
Например, в РФ и ее соседей тренд переходить с платной СУБД на СУБД PostgreSQL.
jobgemws Автор
03.09.2019 09:44Пока выявлены следующие пути по синхронизации баз разных СУБД:
1) http://www.dbbalance.com/database_comparison.htm
2) для перехода со скуля на постгрес: https://severalnines.com/blog/migrating-mssql-postgresql-what-you-should-know
3) используя ORM (например, EF) перенести схему и данные с одной СУБД на другую СУБДLordNaradius
03.09.2019 12:21+1В личных целях использовал средство Full Convert для переноса с MS SQL в PostgreSQL. Возможно, Вам пригодится эта информация.
Telhcar
02.09.2019 18:13+1У нас, на небольшой бд в примерно 5000 объектов, продукты apex ну очень медленно работают. Dbforge справляется гораздо бодрее.
Насколько мне известно, dbforge имеет очень лояльную политику к индивидуальным разработчикам из Россииjobgemws Автор
02.09.2019 18:15По компараторам компании Devart Вы правы-они сделали ряд улучшений и если верить интернету, то скоро выпустят еще обновление (правда не знаю что там именно улучшено, но на официальном сайте наверняка напишут). Плюс они очень лояльно относятся к клиентам, т е получить скидку при покупке нескольких решений и существенную можно. Плюс у них и цены самые маленькие.
Но я по своему субъективному мнению сужу по удобству.
Не примите как за рекламу.

jakobz
03.09.2019 06:27+1Как правило, все в гит скрипты кладут, и при деплое накатывают автоматом. И имеют все бд одинаковые на всех инстах, с поправкой на версию. Ну типа вон статья blog.codinghorror.com/get-your-database-under-version-control — больше 10 лет уже ей, я думал все уже так делают. Зачем руками-то?
jobgemws Автор
03.09.2019 07:24Здесь имелось в виду сравнение двух баз, а не миграция изменений.
Контроль версий-это другое, а именно история изменений одной базы.jakobz
03.09.2019 07:34А как вообще получается что они разные? Они же по построению либо идентичные, либо отличаются на несколько скриптов миграции, которые можно посмотреть в гите.
jobgemws Автор
03.09.2019 07:39Разными они могут быть по нескольким причинам. Например:
1) совершенно разные БД и нужно перенести только часть объектов с одной БД в другую
2) БД действительно должны быть идентичны, но по каким-то причинам одна из них не привязана к единому репозиторию
3) во время эксплуатации в РСУБД на одном из экземпляров БД появились странные данные и нужно проанализировать чем данные там отличаются от остальных
4) какие данные не попали с центрального сервера на подчиненный и наоборот
5) аналогично и по схемам в п.3-4
И т д
somurzakov
03.09.2019 07:26+1а как насчет CI/CD для базы? например, используя SSDT и azure devops pipelines
devblogs.microsoft.com/ssdt/sqldb-cicd-introjobgemws Автор
03.09.2019 07:27Да, это тоже используем.
Но часто бывают моменты сравнить именно две базы, а это совсем другая задача.
jobgemws Автор
04.09.2019 18:29Подумал и решил расписать ответ.
Смотрите, всё те же компании ApexSQL, RedGate, Devart предлагают свои решения для автоматизации CI/CD, которые они называют DevOps решениями:
AlanDenton
Спасибо за обозр. А касательно скорости работы? Багам? Например ApexSQL я бы сказал что сильно бажливый.
jobgemws Автор
По тем сценариям, что удалось прогнать, багов не было выявлено ни у одной тулзы.
Однако, не могу сказать, что их нет вообще.
База сама по себе содержала таблицы, ограничения в виде PK, FK, уникальных индексов, представления, функции (табличные и скалярные) и хранимые процедуры.
С переносом, изменением и т д и т п в синхронизации схем и синхронизации данных все было ок.