
Если использовать БД временных рядов (timeseries db, wiki) как основное хранилище для сайта со статистикой, то вместо решения задачи можно получить много головной боли. Я работаю над проектом, где используется такая база, и иногда InfluxDB, о которой пойдет речь, преподносила вообще неожиданные сюрпризы.
Disclaimer: приведенные проблемы относятся к версии InfluxDB 1.7.4.
Почему time series?
Проект заключается в отслеживании транзакций в различных блокчейнах и отображении статистики. Конкретно — смотрим эмиссию и сжигание стэйбл-коинов (wiki). На основе этих транзакций нужно строить графики и показывать сводные таблицы.
При анализе транзакций пришла идея: использовать базу данных временных рядов InfluxDB как основное хранилище. Транзакции являются точками во времени и в модель временного ряда они хорошо вписываются.
Еще функции агрегации выглядели весьма удобно — для обработки графиков с большим периодом идеально подходят. Пользователю нужен график за год, а в базе лежит набор данных с таймфреймом в пять минут. Все сто тысяч точек ему отправлять бессмысленно — кроме долгой обработки, они и на экране не поместятся. Можно написать свою реализацию увеличения таймфрейма, либо воспользоваться встроенными в Influx функциями агрегации. С их помощью можно сгруппировать данные по дням и отправить нужные 365 точек.
Немного смущало то, что обычно такие базы используют с целью сбора метрик. Мониторинг серверов, iot-устройства, все, с чего «льются» миллионы точек вида: [<время> — <значение метрики>]. Но если база хорошо работает с большим потоком данных, то почему маленький объем должен вызывать проблемы? С этой мыслью взяли InfluxDB в работу.
Что еще удобного в InfluxDB
Кроме упомянутых функций агрегации есть еще одна замечательная вещь — continuous queries (doc). Это встроенный в БД планировщик, который может обрабатывать данные по расписанию. Например, можно каждые 24 часа группировать все записи за день, считать среднее и записывать одну новую точку в другую таблицу без написания собственных велосипедов.
Также есть retention policies (doc) — настройка удаления данных после какого-то периода. Полезно, когда например, нужно хранить нагрузку на CPU за неделю с измерениями раз в секунду, а на дистанции в пару месяцев такая точность не нужна. В такой ситуации можно сделать так:
- создать continuous query для агрегации данных в другую таблицу;
- для первой таблицы определить политику удаления метрик, которые старше той самой недели.
И Influx будет самостоятельно уменьшать размер данных и удалять ненужное.
О хранимых данных
Данных хранится не много: около 70 тысяч транзакций и еще один миллион точек с рыночной информацией. Добавление новых записей — не более 3000 точек в сутки. Также есть метрики по сайту, но там данных мало и по retention policy они хранятся не больше месяца.
Проблемы
В процессе разработки и последующего тестирования сервиса возникали все более и более критичные проблемы при эксплуатации InfluxDB.
1. Удаление данных
Есть серия данных с транзакциями:
SELECT time, amount, block, symbol FROM transactions WHERE symbol='USDT'Результат:
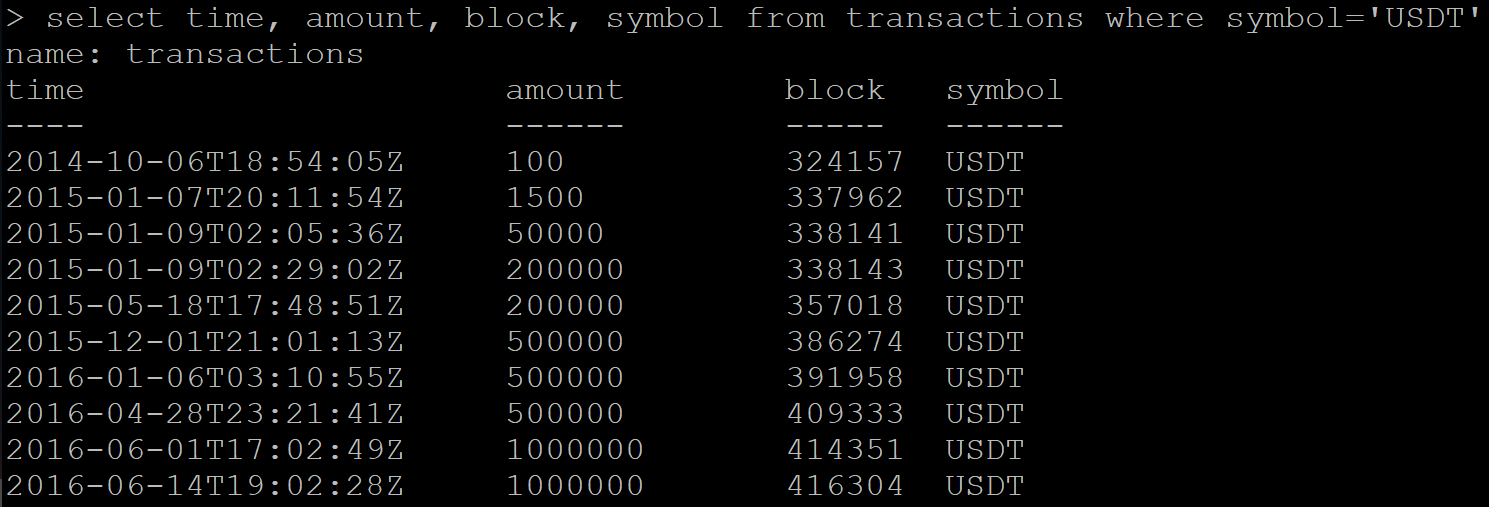
Посылаю команду на удаление данных:
DELETE FROM transactions WHERE symbol=’USDT’Далее делаю запрос на получение уже удаленных данных. И Influx вместо пустого ответа возвращает часть данных, которые должны быть удалены.
Пробую удалить таблицу целиком:
DROP MEASUREMENT transactionsПроверяю удаление таблицы:
SHOW MEASUREMENTSТаблицу в списке не наблюдаю, но новый запрос данных все еще возвращает тот же набор транзакций.
Проблема возникла у меня лишь один раз, так как кейс с удалением — единичный случай. Но такое поведение базы явно не вписывается в рамки «корректной» работы. Позже на github нашел открытый тикет почти годовой давности на эту тему.
В результате, помогло удаление и последующее восстановление всей базы.
2. Числа с плавающей точкой
Математические вычисления при использовании встроенных в InfluxDB функций дают ошибки точности. Не то, чтобы это было чем-то необычным, но неприятно.
В моем случае данные имеют финансовую составляющую и обрабатывать их хотелось бы с высокой точностью. Из-за этого в планах отказаться от continuous queries.
3. Continuous queries нельзя адаптировать к разным временным зонам
На сервисе есть таблица с дневной статистикой по транзакциям. Для каждого дня нужно сгруппировать все транзакции за эти сутки. Но день у каждого пользователя будет начинаться в разное время, следовательно и набор транзакций разный. По UTC есть 37 вариантов сдвига, для которых нужно агрегировать данные.
В InfluxDB при группировке по времени можно дополнительно указать сдвиг, например для московского времени (UTC+3):
SELECT MEAN("supply") FROM transactions GROUP BY symbol, time(1d, 3h) fill(previous)Но результат запроса будет некорректным. По какой-то причине сгруппированные по дням данные будут начинаться аж в 1677 году (InfluxDB официально поддерживает временной промежуток от этого года):
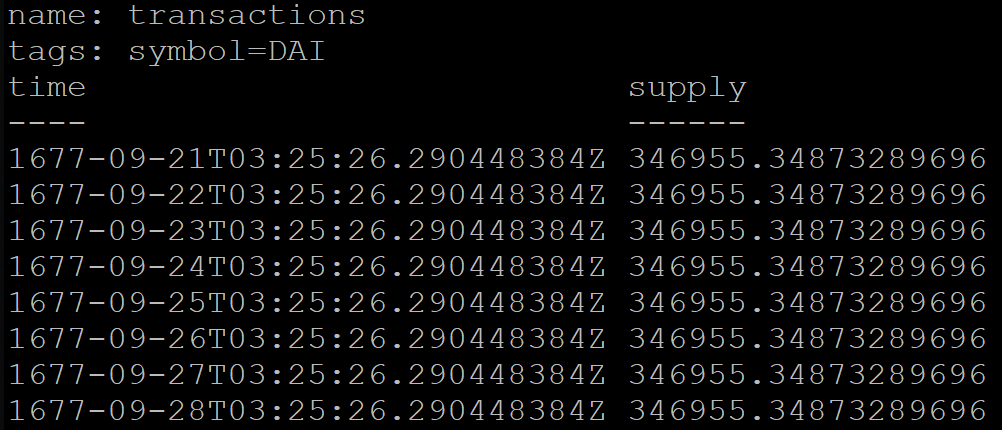
Для обхода этой проблемы временно перевели сервис на UTC+0.
4. Производительность
В интернете есть много бенчмарков со сравнениями InfluxDB и других БД. При первом ознакомлении они выглядели маркетинговыми материалами, но сейчас считаю, что доля правды в них есть.
Расскажу свой кейс.
Сервис предоставляет метод API, который возвращает статистику за последние сутки. При расчетах метод запрашивает базу трижды с такими запросами:
SELECT * FROM coins_info WHERE time <= NOW() GROUP BY symbol ORDER BY time DESC LIMIT 1SELECT * FROM dominance_info ORDER BY time DESC LIMIT 1SELECT * FROM transactions WHERE time >= NOW() - 24h ORDER BY time DESCОбъяснение:
- В первом запросе получаем последние точки для каждой монеты с данными по рынку. Восемь точек для восьми монет в моем случае.
- Второй запрос получает одну самую новую точку.
- Третий запрашивает список транзакций за последние сутки, их может быть несколько сотен.
Уточню, что в InfluxDB по тэгам и по времени автоматически строится индекс, который ускоряет запросы. В первом запросе symbol — это тэг.
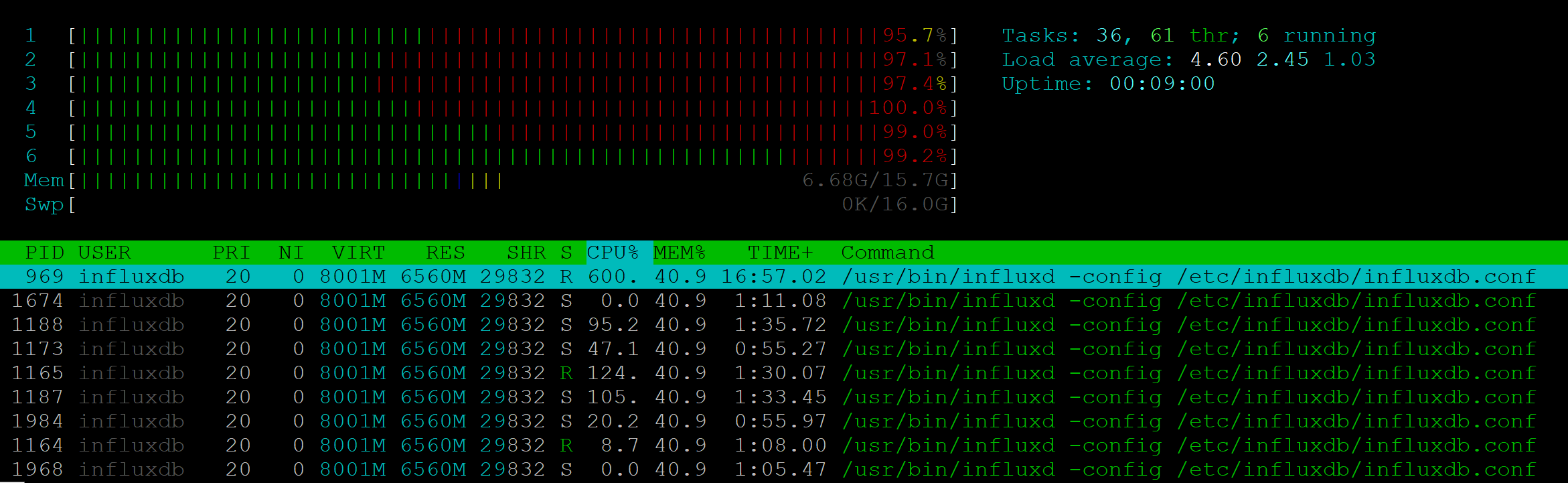
Я провел стресс-тест для этого метода API. Для 25 RPS сервер демонстрировал полную загрузку шести CPU:
При этом процесс NodeJs совсем не давал нагрузки.
Скорость выполнения деградировала уже на 7-10 RPS: если один клиент мог получить ответ за 200 мс, то 10 клиентов должны были ждать по секунде. 25 RPS — граница, с которой страдала стабильность, клиентам возвращались 500 ошибки.
С такой производительностью использовать Influx в нашем проекте невозможно. Более того: в проекте, где мониторинг нужно демонстрировать множеству клиентов — могут появиться схожие проблемы и сервер метрик будет перегружен.
Вывод
Самый главный вывод из полученного опыта — нельзя брать в проект неизвестную технологию без достаточного анализа. Простой скрининг открытых тикетов на github мог дать информацию, чтобы не брать InfluxDB в качестве основного хранилища данных.
InfluxDB должна была хорошо подойти под задачи моего проекта, но как показала практика, эта БД не отвечает потребностям и много косячит.
В репозитории проекта уже можно найти версию 2.0.0-beta, остается надеяться, что во второй версии будут значимые улучшения. А я пока пойду изучать документацию TimescaleDB.
Комментарии (34)

KonstantinSpb
22.04.2019 18:12+2Clickhouse еще можно посмотреть
www.altinity.com/blog/clickhouse-for-time-series

amarao
22.04.2019 18:18+2Это вы ещё мясцо не потрогали. А мясцо звучит так: комбинаторный взрыв в continious queries. Если вы используете их для классического rrd, то записи вида (из документации):
CREATE CONTINUOUS QUERY "cq_basic_br" ON "transportation" BEGIN SELECT mean(*) INTO "downsampled_transportation"."autogen".:MEASUREMENT FROM /.*/ GROUP BY time(30m),* END
то вас ждёт Ньютон со своим биномом и Декарт со своим произведением. Вам перемножат всех fields у всех measurement на все значения tags в базе. Если у вас десять measurement, в каждой из которых 5 полей и 3 тега с 100 значениями у каждого, то вас ждёт...
3*100*5*10 = 1500пустых групп для каждого отсчёта. После чего пустое выкинут и оставшееся запишут. Если у вас хотя бы миллион точек, то ваши 1.5ккк групп за минуту может и переварят. А вот когда вам кто-то подпихнёт ещё одну measurement с десятком полей и тегом с десятком значений, то получившееся 150 миллиардов — не переварят никогда. И вам уронят influx oom'ом. А потом systemd его перезапустит и influx продолжит работать. И он у вас будет падать, терять данные, флапать мониторингом (если тот будет успевать режим "упал-отжался"), и вы будете недоумевать, что происходит.
А происходит феерическая архитектурная фигня (ФАФ), бороться с которыми можно только с помощью костылей и подпорок.

gecube
22.04.2019 21:38Решение какое? Использовать всё-таки инфлакс? Или забить на него, как на неудачное решение? Или ограничиться подмножеством его функций?
jekatigr Автор
22.04.2019 22:16Так как производительность influx на чтение совсем никуда не годится, для основных данных попробую использовать Timescale. Агрегация по временному промежутку там есть, а continuous queries заменяются на запуск запросов SELECT INTO по cron.
Метрики пока останутся в influx, чтение нужно только для администратора.
morozovsk
23.04.2019 02:38+1Timescale будет занимать до 30 раз больше места на диске чем influxdb.
Они там со сжатием походу совсем не заморачивались, автор в комментах просто рекомендует использовать специальную файловую систему, которая всё будет сжимать сама. В общем не рекомендую.
Рекомендую посмотреть в сторону clickhouse.
Я настрадался с influx так, что уже даже серверные метрики теперь храню в кликхаусе.
Простой udp-сервер в 100 строк кода притворяется influxdb, ловит метрики от telegraf и сохраняет их в кликхаус. Работать с ним приятней, данные на диске занимают меньше.
Это я вдохновился приложением коллег, которое притворяется elasticsearch, принимает по http json-запрос и сохраняет все данные в кликхаус. Там тоже можно в 100 строк кода уложиться.jekatigr Автор
23.04.2019 02:57Спасибо.
По поводу размера БД: в моем случае это не критично, данных не много, рост полностью предсказуем. Cardinality на текущий момент — 66 и не думаю, что в будущем значительно изменится. Да и Postgresql — хороший фундамент, как мне кажется.
Выше уже предлагали присмотреться к clickhouse, немного полистал доку. В глаза бросилось то, что она изначально позиционируется как бд для аналитических запросов и редкого чтения. В моем случае это критично, хоть и указанные характеристики гораздо лучше influx.
Вполне возможно, что я просто ем кактус с tsdb и нужно вернуться к велосипедам и реляционным бд.
gecube
23.04.2019 08:34Вероятно, что КХ лучше подходит для bulk записей. В этом основной камень преткновения.
Чисто реляционные — не лучший выбор, т.к. у вас постоянно идет прореживание записей, т.е. заранее можно примерно оценить сколько «слотов» нужно и аллоцировать под них место и структуры. Именно поэтому tsdb и появились — более оптимальная работа именно с определенными структурами.
gecube
23.04.2019 08:32Простой udp-сервер в 100 строк кода притворяется influxdb, ловит метрики от telegraf и сохраняет их в кликхаус. Работать с ним приятней, данные на диске занимают меньше.
а зачем, если можно поднять графит? А телеграф в него умеет напрямую?morozovsk
23.04.2019 11:41Зачем мне графит если кликхаус не просто современнее и навороченнее, а сильно эффективнее.
gecube
23.04.2019 13:19Я говорю графит — и подразумеваю стек от lomik (не graphite-python over whisper, а graphite @CH и пускай запись данных будет головной болью графита, а не моего прокси или агента мониторинга).
morozovsk
23.04.2019 14:02В указанной мною статье в графите от ломика не было тегов. Авторы статьи очень сильно надеялись, что их поддержка появится в ближайшее время. Прошёл год и они появились.
Уж лучше моей головной болью будет 100 строк моего кода, чем годы ожиданий пока сделают, то что мне нужно.
К тому же мне не нравится структура бд в графите от ломика. Эта гибкость дорого обходится. Она не имеет смысла для серверных метрик (где структура может быть сгенерирована за первых пару минут анализа метрик). Гораздо эффективнее создать один раз нужную колонку (конечно автоматически, а не в ручную) и складировать метрики в неё, тогда сжатие на уровне колонки будет гораздо эффективнее, чем создать две колонки ключ и значение и пихать в них всё подряд.
Можно сравнить "универсальную схему" и мою схему, которая создаётся динамически по мере надобности.
При запросе на cpu у меня будут доставаться с диска данные только по cpu, а не все данные, а потом отфильтровываться cpu.
Для моего кейса мне не нужен графит, мне достаточно кликхауса и 100 строк кода, которые автоматически добавляют новые колонки.gecube
23.04.2019 15:15Спаибсо за комментарии.
Немного замечаний.
1. А чего сразу телеграфом не слать в КХ? Достаточно output plugin написать. Понимаю, что форк, все дела, но возможно, что и примут патч с этим output plugin'ом в апстрим в одной из следующих версий (вообще ребята из телеграф показались достаточно адекватными в этом плане).
2. а чем смотреть метрики? В графане визуализируете?
3. преимущество стека от ломика в том, что туда мойру можно прикрутить и получить нормальный алертинг. А как Вы предлагаете алертинг делать? Через стороннее решение? Графана? Фу-фу-фу.
4. повторюсь, что насколько я помню, что КХ хорош только для батчевых записей. Телеграф же шлет можно сказать — единичные метрики. Насколько хорошо это будет работать? Насколько я помню, стек от ломика оптимизирует записи в памяти и шлет их пачками в КХ, что обеспечивает эффективность на запись.
5. Касательно тезиса, что схема лучше динамическая, чем универсальная — ну, мы же понимаем, что есть несколько нюансов с метриками. Первая — что обычно они только добавляются (т.е. типов метрик становится больше). Вторая — что обычно количество наблюдаемых объектов (узлов, сервисов и т.п.) тоже увеличивается. Третья — старые метрики обычно нужны с ретеншеном и разрежением частоты с агрегацией. Если ретеншен, положим, можно сделать откидываем партиций в КХ, то как разрежение делать? Эффективно? Или речь про достаточно маленькое хранилище, для которого эта проблема в принципе не проявится? Четверое — сжатие при использовании унивесарльной схемы для каждой из таблиц (т.е. НЕ УНИВЕРСАЛЬНОЙ схемы для ВСЕХ метрик) — будет больше, при не очень большой потере скорости. С другой стороны, метрики обычно нужны только для оперативного мониторинга, а скорость доступа к историческим данным нужна ± постоянная (но можно, что не слишком высокая), в не зависимости от их датировки. Как-то так.
Ну, и как Вы заметили — метрики бывают разные. Вы про «Она не имеет смысла для серверных метрик». А бизнес метрики? Метрики приложений (которые вроде бы еще системные, но не совсем)?morozovsk
23.04.2019 16:111. думал об этом, но там input plugin от моего коллеги висит в пуллреквестах больше года. Просить его написать в долгий ящик ещё и output plugin у меня пока совести не хватает.
2. графана
3. графана
4. конечно шлю пачками, а не поштучно
5. для мониторинга серверов новые типы метрик добавляются раз в полгода.
Бизнес метрики и метрики приложений я сразу пишу в кликхаус. Не вижу смысла в 2019 году для новых сервисов писать данные в графит, а потом страдать, что подсев на графит очень сложно переезжать на кликхаус, и что сторонняя прослойка, подменяющая графит на кликхаус работает не очень оптимально зато гибко.
В общем напишу ещё раз, что для моих задач это решение работает как надо, и я не претендую на всеобщую универсальность.
Мой посыл первого комментария был в том, что написать приложение, которое будет заменять ваш текущий «инструмент с хранилищем» и сохранять всё в кликхаус — это вовсе не «рокет сайнс», всё самое тяжёлое на себя берёт кликхаус.
amarao
23.04.2019 15:22Одна из причин жизни с TICK'ом — очень хороший язык для графаны. У clickhouse'а, например, non_negative_derivative написать можно в запросе?
amarao
23.04.2019 15:20Текущее решение (решающее проблему комбинаторного взрыва) — использовать per measurement CQ. Никаких звёзд. Дополнительно, надо проявлять гигену в телеграфе и дропать ненужные теги, а так же не собирать что попало (например, отключать per-cpu для cpu, которое добавляет тысячи к комбинаторному множетелю из-за количества cpu на современных системах).
Второе: добавить в мониторинг проверку NRestarts для influxdb.service. Это число увеличивается каждый раз, когда systemd делает «упал-отжался» для сервиса.morozovsk
23.04.2019 16:29>отключать per-cpu для cpu
Спасибо, очень ценное замечание, обратил внимание на это, когда стал писать метрики телеграфа в кликхаус, но не знал, что это отключается в конфиге.
Теперь нужно будет ещё раз хорошенько посмотреть таблицы кликхауса и конфиги телеграфа на наличие мусора.
Stanislavvv
25.04.2019 15:36Сразу перейти на clickhouse. У меня на работе пришлось перейти с influxdb, когда 16Гб памяти перестало хватать для работы с данными всего-навсего за неделю. Требовалось — за пару месяцев минимум, а лучше — за полгода. Сейчас — clickhouse, у которого поставили уже потом 32Гб на всякий случай и таки да, полгода неагрегированных данных.
Но да, есть и свои нюансы, там не совсем тот SQL, к которому все привыкли…
P.S. часть метрик показывается через графану (для которых это имеет смысл), часть — используется для автоматики.
a1ien_n3t
23.04.2019 02:15Кстати кто юзает influx незабудьте обновиться до 1.7.5 или прописать shared_secret отличный от пустого. А то ваша база открыта для всех желающийх под любым логином.
gecube
23.04.2019 08:35Для системы мониторинга это не самый большой грех… А вот если финансовые данные хранить — да, косямба.

trolley813
23.04.2019 08:55> В моем случае данные имеют финансовую составляющую и обрабатывать их хотелось бы с высокой точностью.
«Уж сколько раз твердили миру», что для финансовых данных числа с плавающей точкой не годятся — а поскольку чего-то по типу decimal в influxdb нет, то лучшим выбором пока остаются целые числа.
P.S. Конечно, это не значит, что проблемы с точностью нет.ELazin
24.04.2019 11:49+2что для финансовых данных числа с плавающей точкой не годятся
Это одна из тех фраз, которые слышишь(видишь) в каждой второй статье или книге и которые не имеют никакого отношения к действительности. Финансовые расчеты как правило выполняются с использованием double (binary64 в терминах IEEE 754). Совершенно бессмысленно использовать decimal (decimal64) для всех вычислений. Вы все равно будете получать результат, который будет требовать округления (пример, я хочу посчитать сколько индийских рупий я могу купить на 1000 рублей, курс RUB/INR — 0.91 и результат 1098,901098901 рупий, binary64 и decimal64 могут представить это значение без потери точности, при этом мне придется округлить до 1098,90). При этом операции над decimal64 — дороже чем над binary64, т.к. реализуются программно. Бухгалтерия — другое дело, там использование decimal имеет какой-то смысл.trolley813
25.04.2019 08:47Тут нужны не decimal, а int (по факту, числа с фиксированной точкой) — т.е. данные хранятся в самых мелких единицах (копейках, центах и т.п.). Так и об округлении не нужно думать, как правило
ELazin
25.04.2019 10:17Об округлении, в случае double и decimal, придется подумать один раз. С fixed point об округлении приходится думать намного чаще, т.к. у промежуточные значения не представимы однозначно как fixed point.

shushu
23.04.2019 17:22Как вы себе представляете хранение агрегированных данных для каждой тайм зоны? Знаете ли вы про параметр запроса tz('Europe/Berlin') к примеру? То что вы называете «сдвигом», я не думаю что вы применяете это корректно, ещё и удивляетесь что получается что то не то.
По поводу производительности, то как правильно сказали выше, вы зря используете select *, вам и вправду нужны все точки? Если так — то даже реляционная база даст выше производительность.
Попробуйте select mean(«value»)… Where time > now() — 24h group by time(10m)
В этом случае вернётся среднее value для каждого интервала в 10 минут за последние сутки, это будет 144 точки, если надо меньше — увеличьте group by период.
SELECT * FROM coins_info WHERE time <= NOW()
Вообще то, по факту, этот запрос возвращает абсолютно все что есть, а не за последние сутки.
В любом случае, попробуйте запрос что я дал выше, отрабатывает ли он быстрее?

Brain_Overload
23.04.2019 18:04Influx узали для мониторинга, это наверное самая прожорливая TSDB что я видел, при этом упать может в любой момент без сохранения данных. да и вообще косяков много, которые как-то плохо лечат.
Spartak13
24.04.2019 18:31А что сейчас используете?
Influx пробовали пристроитьта стек в 2016 году для хранения сырых временных рядов. Привлекли continues queries для построения равномерно разреженных рядов. От идеи пришлось отказаться из-за «краевых эффектов». Плюс в то время в инете нашлось много issues на тему просадки производительности influx при росте базы. Решили не рисковать и остаться на проприетарным хранилище трендовBrain_Overload
24.04.2019 18:37Для метрик Прометей, у нас нет потребности хранить стрижки более пары-тройки спринтов. Инфлюкс пока оставили, но чисто как долговременное хранилище прикрученное к Прометею.
Sovigod
Вывод у вас полностью верный.
От себя могу добавить — при работе с любой tsdb забудьте про запросы SELECT * FROM. Всегда используйте агрегирующие функции. Если вам нужны все данные по всем точкам с сортировкой не по времени — то вам не tsdb.
Еще лучше всегда указывать нужный промежуток времени в запросе — у инфлюкса ряды партиционируются по времени.
trolley813
Тем не менее, у инфлюкса есть и преимущества (перед тем же кликхаусом, например) — опыт показал, что при хранении большого количества (несколько сотен на таблицу) метрик InfluxDB выигрывает благодаря двум основным причинам:
<время> - <название метрики> - <значение метрики>, причем заранее может быть неизвестно, сколько всего метрик и как они называются (и какой у них тип данных). В Clickhouse в таких случаях нужно каждый раз создавать строку и заполнять все отсутствующие значения NULL-ами (а они там появились только сравнительно недавно), не говоря уже о том, что приходится лишний раз проходить по набору данных (хорошо еще, если они исторические, а не в реальном времени приходят), чтобы определить набор колонок и их типы.Sovigod
1. Полностью согласен. Очень удобно для timeseries
2. Вы чуть лукавите. В Кликхаусе NULL при инсерте не обязательны. Но вручную поддерживать схему нужно и это очень муторно. Автоматические ALTER TABLE что бы добавить столбец или изменить индекс (((( — в инфлюксе схема очень гибкая.
Лично мое мнение influxdb — не production-ready для важных данных. Уже больше года использую как хранилище точек мониторинга. В нем только те данные которые можно потерять без особых проблем.