

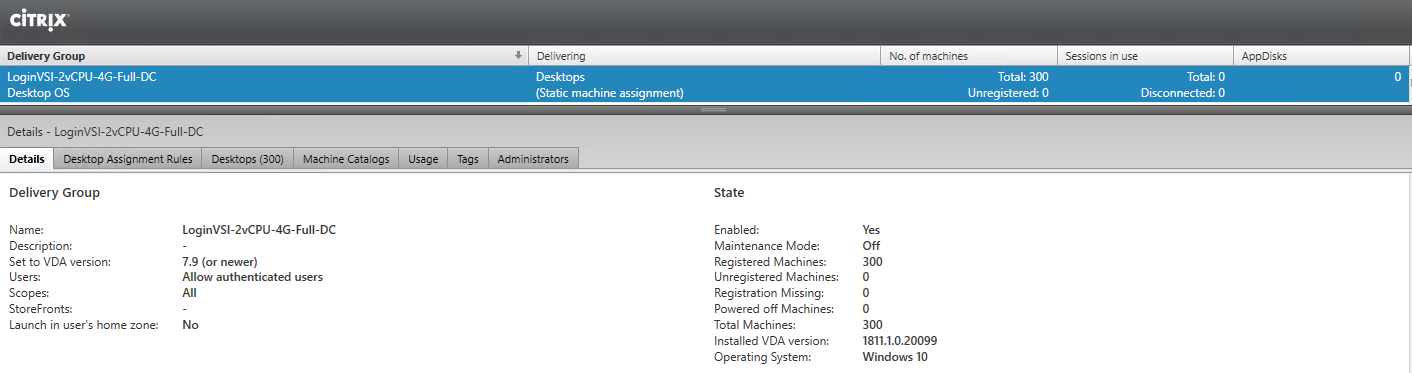
Заказчик захотел VDI. Очень присматривался к связке SimpliVity + VDI Citrix Virtual Desktop. Для всех операторов, сотрудников офисов по городам и так далее. Там пять тысяч пользователей только в первой волне миграции, и поэтому они настояли на нагрузочном тестировании. VDI может начать тормозить, может спокойно прилечь — и не всегда это случается из-за проблем с каналом. Мы купили очень мощный пакет тестирования специально для VDI и грузили инфраструктуру, пока она не легла по дискам и по процессору.
Итак, нам понадобятся пластиковая бутылка, софт LoginVSI для навороченных тестов VDI. У нас он с лицензиями на 300 юзеров. Потом взяли железо HPE SimpliVity 380 в набивке, подходящей для задачи максимальной плотности пользователей на один сервер, нарезали виртуальных машин с хорошей переподпиской, поставили на них офисный софт на Win10 и начали тестить.
Поехали!
Система
Два узла (сервера) HPE SimpliVity 380 Gen10. На каждой:
- 2 x Intel Xeon Platinum 8170 26c 2.1Ghz.
- Оперативная память: 768GB, 12 x 64GB LRDIMMs DDR4 2666MHz.
- Основной дисковый контроллер: HPE Smart Array P816i-a SR Gen10.
- Жесткие диски: 9 x 1.92 TB SATA 6Gb/s SSD (в конфигурации RAID6 7+2, т. е. это модель Medium в терминах HPE SimpliVity).
- Сетевые карты: 4 x 1Gb Eth (данные пользователей), 2 x 10Gb Eth (бэкэнд SimpliVity и vMotion).
- Специальные встроенные FPGA-карты в каждом узле для дедупликации/компрессии.
Узлы подключены между собой интерконнектом 10Gb Ethernet напрямую без внешнего коммутатора, который используется как бэкэнд SimpliVity и для передачи данных виртуальных машин по NFS. Данные виртуальных машин в кластере всегда зеркалируются между двумя узлами.
Узлы объединены в кластер Vmware vSphere под управлением vCenter.
Для проведения тестирования развёрнуты контроллер домена и брокер подключений Citrix. Контроллер домена, брокер и vCenter вынесены на отдельный кластер.


В качестве тестовой инфраструктуры развёрнуты 300 виртуальных рабочих столов в конфигурации Dedicated – Full Copy, т. е. каждый рабочий стол представляет собой полную копию оригинального образа виртуальной машины и сохраняет все изменения, сделанные пользователями.
Каждая виртуальная машина имеет 2vCPU и 4GB RAM:
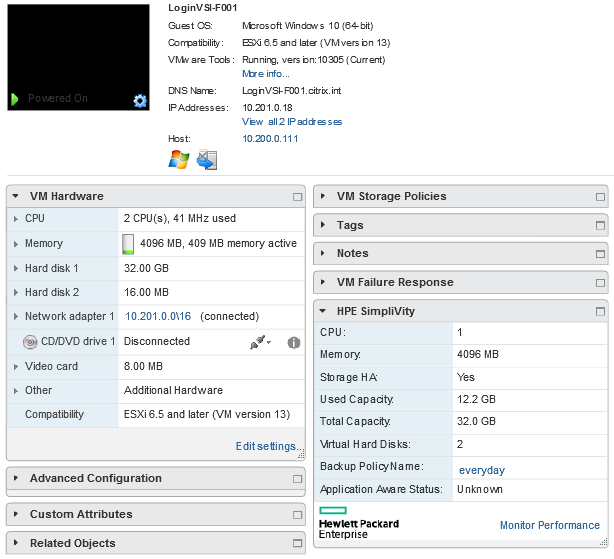
На виртуальные машины было установлено следующее ПО, требуемое для проведения тестирования:
- Windows 10 (64-bit), версия 1809.
- Adobe Reader XI.
- Citrix Virtual Delivery Agent 1811.1.
- Doro PDF 1.82.
- Java 7 Update 13.
- Microsoft Office Professional Plus 2016.
Между узлами — синхронная репликация. У каждого блока данных в кластере — две копии. То есть сейчас полный набор данных на каждом из узлов. При кластере в три и больше узлов — копии блоков в двух разных местах. При создании новой ВМ создаётся дополнительная копия на одном из узлов кластера. При выходе из строя одного узла все ВМ, ранее запущенные на нём, автоматически перезапускаются на других узлах, где у них есть реплики. Если узел вышел из строя надолго, то начинается постепенное восстановление избыточности, и кластер снова возвращается к резервированию N+1.
Балансировка и хранение данных происходят на уровне программного хранилища самого SimpliVity.
Виртуальные машины запускают кластер виртуализации, он же располагает их на программном хранилище. Сами рабочие столы брали по типовому шаблону: на тест заехали столы финансистов и операционистов (это два разных шаблона).
Тестирование
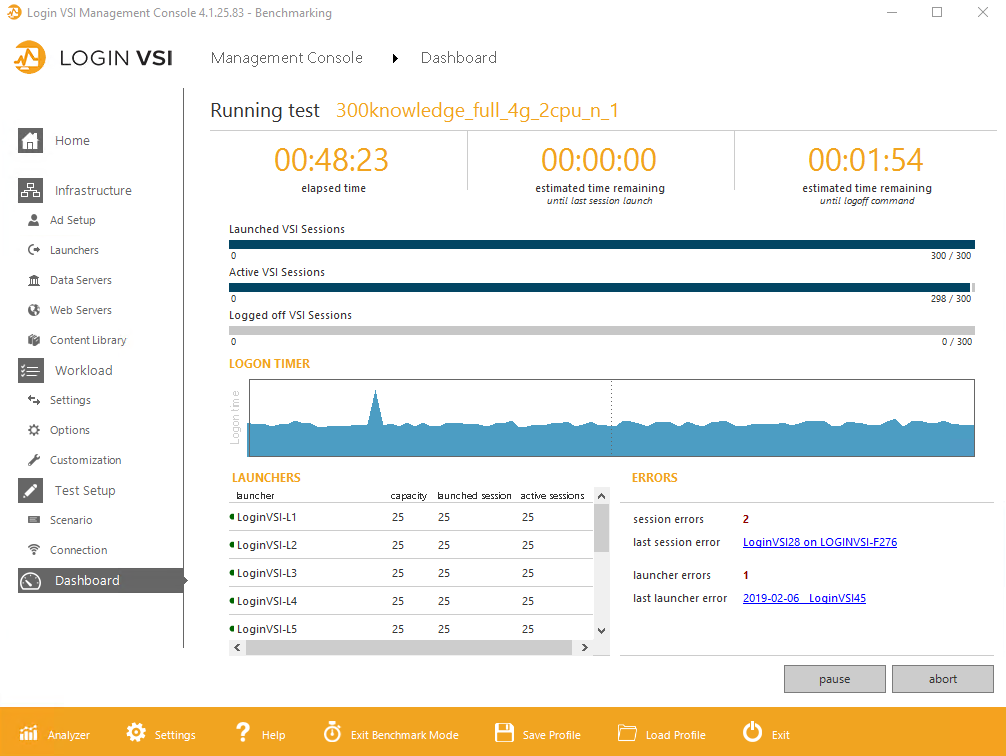
Для проведения тестирования использовался тестовый комплекс ПО LoginVSI 4.1. Комплекс LoginVSI в составе управляющего сервера и 12 машин для тестовых подключений были развёрнуты на отдельном физическом хосте.
Тестирование проводилось в трёх режимах:
Режим Benchmark — варианты нагрузки 300 Knowledge workers и 300 Storage workers.
Стандартный режим — вариант нагрузки 300 Power workers.
Для возможности работы Power workers и повышения разнообразия нагрузки в комплекс LoginVSI была добавлена библиотека дополнительных файлов Power Library. Для обеспечения повторяемости результатов все настройки тестового стенда были оставлены Default.
Тесты Knowledge и Power workers имитируют реальную нагрузку пользователей, работающих на виртуальных рабочих станциях.
Тест Storage workers создан специально для тестирования систем хранения данных, далёк от реальных нагрузок и большей частью состоит в работе пользователя с большим количеством файлов разных размеров.
В процессе тестирования пользователи заходят на рабочие станции в течение 48 минут примерно по одному пользователю каждые 10 секунд.
Результаты
Основным результатом тестирования LoginVSI является метрика VSImax, которая составляется из времени выполнения различных заданий, запускаемых пользователем. Например: время открытия файла в блокноте, время сжатия файла в 7-Zip и т. д.
Подробное описание подсчета метрик доступно в официальной документации по ссылке.
Другими словами, LoginVSI повторяет типовой шаблон нагрузки, симулируя действия пользователя в офисном пакете, при чтении PDF и так далее, и измеряет различные задержки. Есть критический уровень задержек «всё тормозит, работать невозможно»), до достижения которого считается, что максимум юзеров не набран. Если время отклика на 1 000 мс быстрее, чем это состояние «всё тормозит», то считается, что система работает нормально, и можно добавлять ещё пользователей.
Вот основные метрики:
| Метрика |
Производимые действия |
Подробное описание |
Нагружаемые компоненты |
| NSLD |
Время открытия текстового |
Запускается блокнот и |
CPU и I/O |
| NFO |
Время открытия диалогового |
Открытие файла VSI-Notepad [Ctrl+O] |
CPU, RAM и I/O
|
| ZHC* |
Время создания Zip-файла с сильным сжатием |
Сжатие локального |
CPU и I/O |
| ZLC* |
Время создания Zip-файла со слабым сжатием |
Сжатие локального |
I/O
|
| CPU |
Вычисление большого |
Создание большого массива |
CPU |
При выполнении тестирования изначально подсчитывается базовая метрика VSIbase, которая показывает скорость выполнения заданий без нагрузки на систему. На ее основе определяется VSImax Threshold, который равен VSIbase + 1 000мс.
Выводы о производительности системы делаются на основе двух метрик: VSIbase, определяющей скорость работы системы, и VSImax threshold, определяющей максимальное количество пользователей, которое выдержит система без существенной деградации.
300 Knowledge workers benchmark
Knowledge workers — это юзеры, которые регулярно нагружают память, процессор и IO разными мелкими пиками. Софт эмулирует нагрузку с требовательных офисных пользователей, как будто они постоянно что-то тыкают (PDF, Java, офисный пакет, просмотр фото, 7-Zip). По мере добавления пользователей с нуля до 300 задержка у каждого плавно растёт.
Данные статистики VSImax:
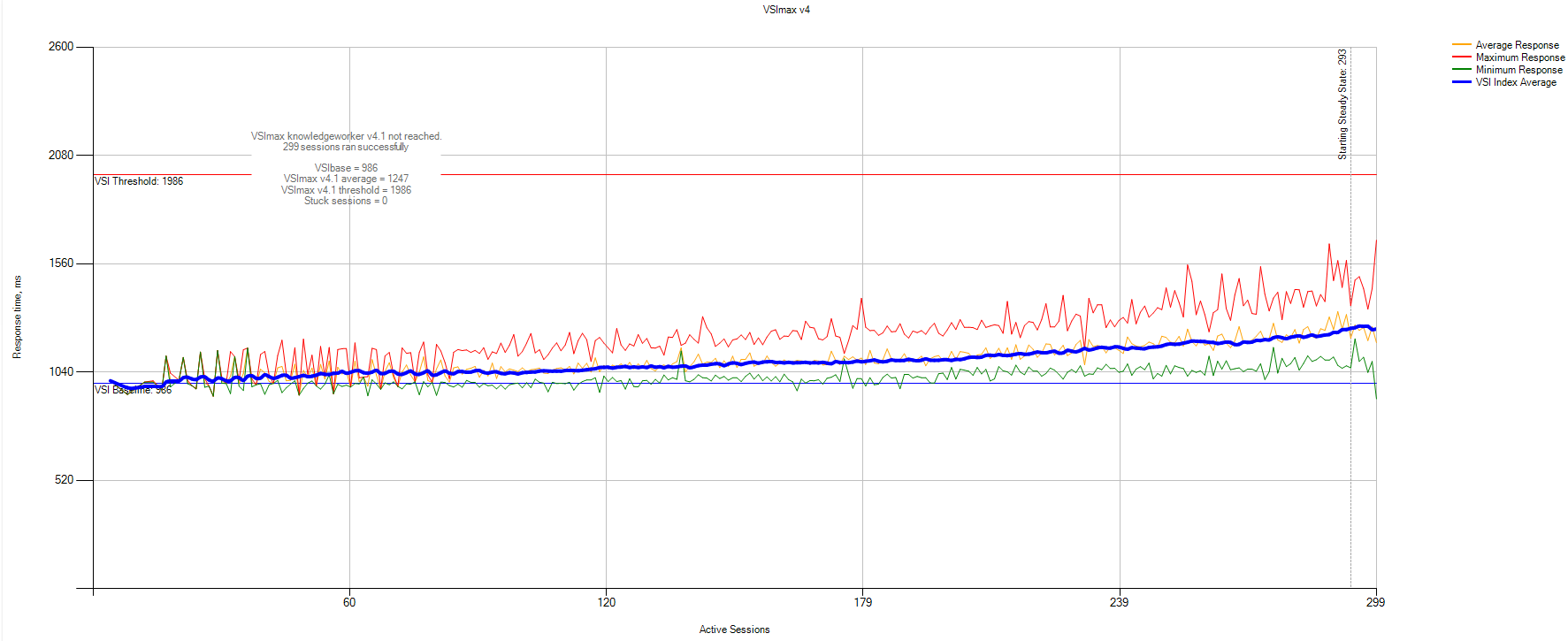
VSIbase = 986мс, VSI Threshold достигнут не был.
Статистика нагрузки на систему хранения из мониторинга SimpliVity:
При данном типе нагрузки система выдерживает повышение нагрузки практически без деградации производительности. Время выполнения заданий пользователей растёт плавно, время отклика системы не изменяется в течение тестирования и составляет до 3 мс на запись и до 1 мс — на чтение.
Вывод: 300 knowledge юзеров без каких-либо проблем работают на текущем кластере и не мешают друг другу, достигая переподписки pCPU/vCPU 1 к 6. Общие задержки при возрастании нагрузки равномерно растут, но обсусловленный предел достигнут не был.
300 Storage workers benchmark
Это пользователи, которые постоянно пишут и читают в пропорции 30 к 70 соответственно. Этот тест был проведён скорее ради эксперимента. Данные статистики VSImax:
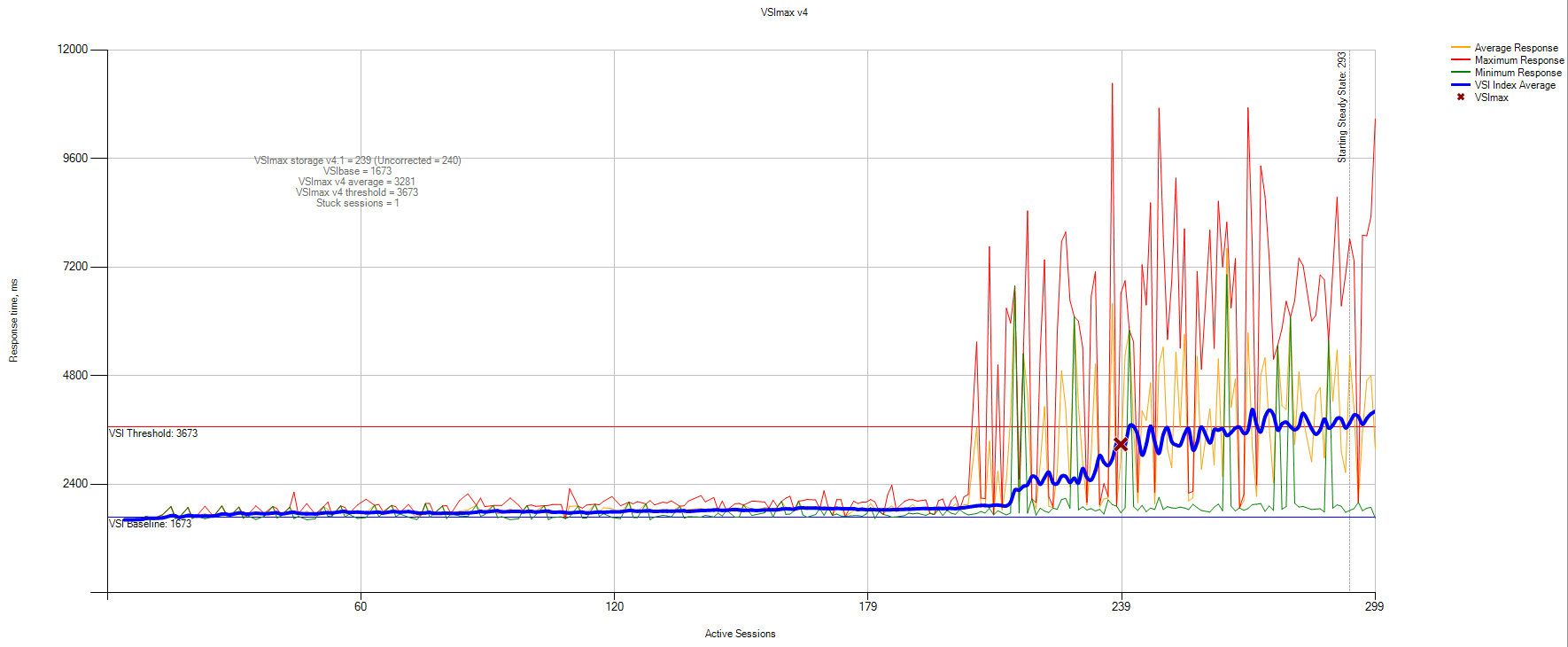
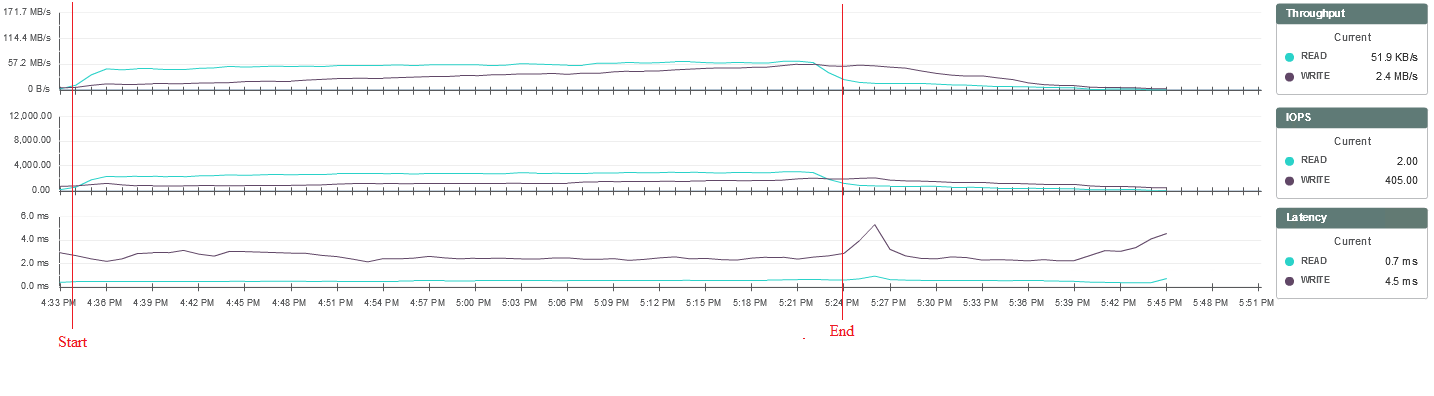
VSIbase = 1673, VSI Threshold достигнут на 240 пользователях.
Статистика нагрузки на систему хранения из мониторинга SimpliVity:
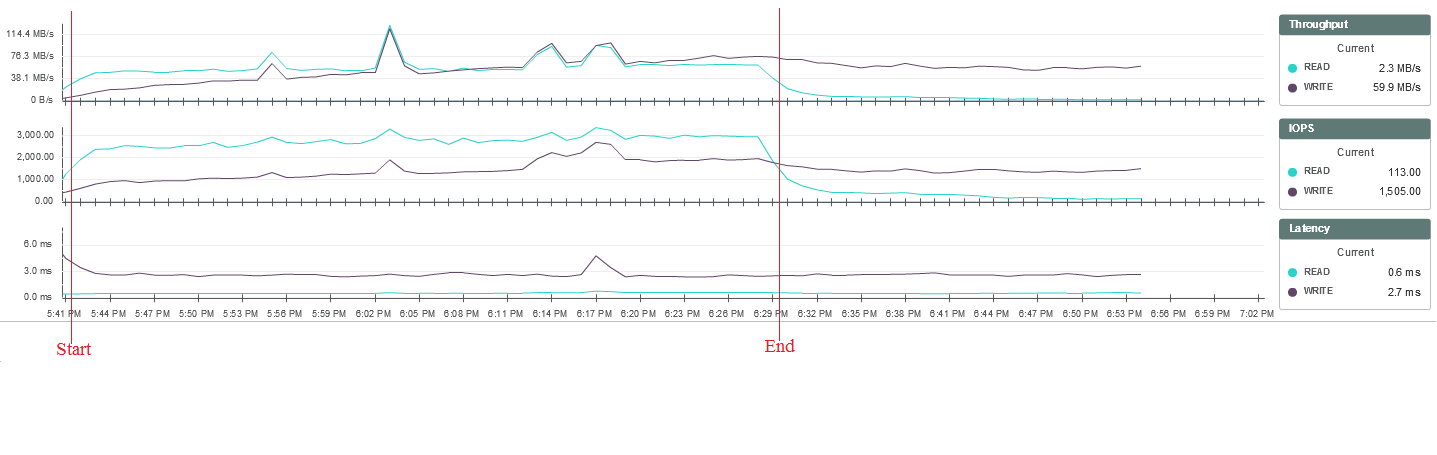
Такой тип нагрузки, по сути, — стресс-тест системы хранения. При его выполнении каждый пользователь записывает на диск множество случайных файлов разных размеров. В этом случае видно, что при превышении некоторого порога нагрузки у части пользователей повышается время выполнения задач на запись файлов. При этом нагрузка на систему хранения, процессор и память хостов существенно не изменяется, поэтому точно определить, с чем связаны задержки, на данный момент нельзя.
Выводы о производительности системы с помощью этого теста можно делать только в сравнении с результатами теста на других системах, так как такие нагрузки — синтетические, нереалистичные. Тем не менее, в целом тест прошёл неплохо. До 210 сессий всё шло хорошо, а затем начались непонятные отклики, которые при этом нигде, кроме Login VSI, не отслеживались.
300 Power workers
Это пользователи, которые любят процессор, память и высокие IO. Эти «продвинутые пользователи» регулярно запускают сложные задачи с долгими пиками вроде установки нового ПО и распаковки больших архивов. Данные статистики VSImax:
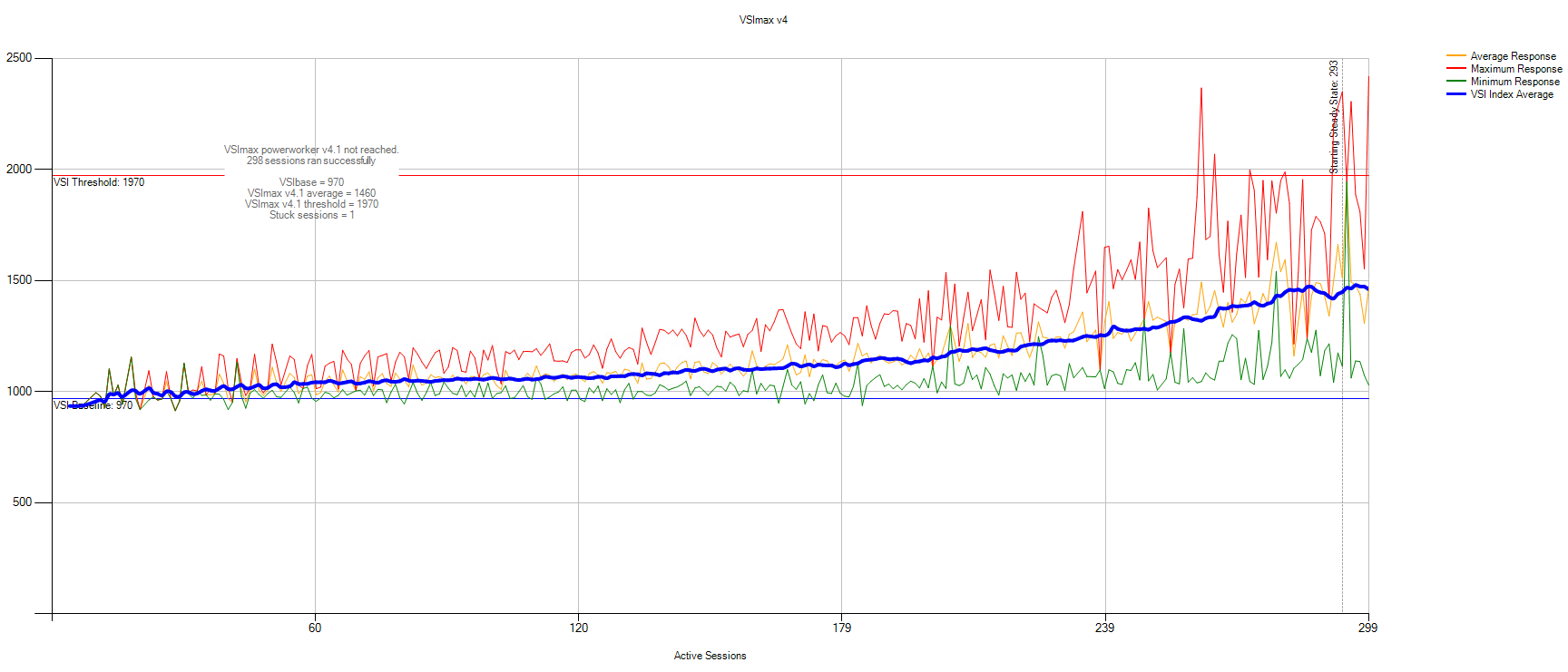
VSIbase = 970, VSI Threshold достигнут не был.
Статистика нагрузки на систему хранения из мониторинга SimpliVity:
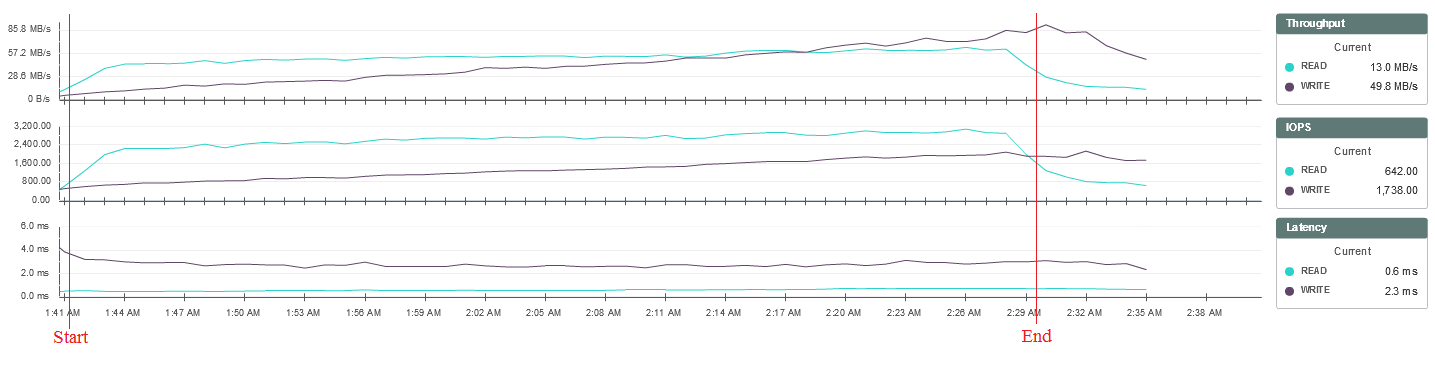
При тестировании был достигнут порог нагрузки процессоров на одном из узлов системы, но это не оказало существенного влияния на её работу:

В этом случае система выдерживает повышение нагрузки также без существенной деградации производительности. Время выполнения заданий пользователей растёт плавно, время отклика системы не изменяется в течение тестирования и составляет до 3 мс на запись и до 1 мс — на чтение.
Обычных тестов заказчику было недостаточно, и мы пошли дальше: повысили характеристики ВМ (количество vCPU, чтобы оценить повышение переподписки и размер диска) и добавили допнагрузку.
При проведении дополнительных тестов была использована следующая конфигурация стенда:
Развёрнуто 300 виртуальных рабочих столов в конфигурации 4vCPU, 4GB RAM, 80GB HDD.
Конфигурация одной из тестовых машин:
Машины развёрнуты в варианте Dedicated – Full Copy:

300 Knowledge workers benchmark с переподпиской 12
Данные статистики VSImax:

VSIbase = 921 мс, VSI Threshold достигнут не был.
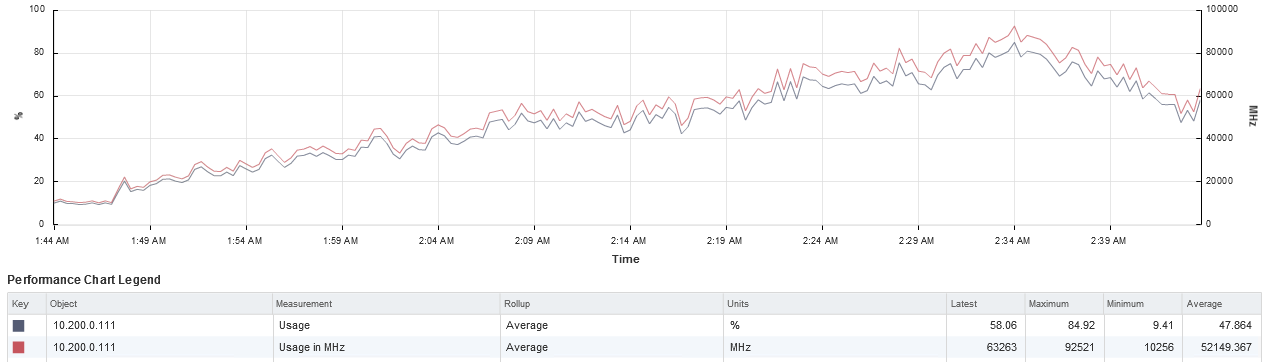
Статистика нагрузки на систему хранения из мониторинга SimpliVity:
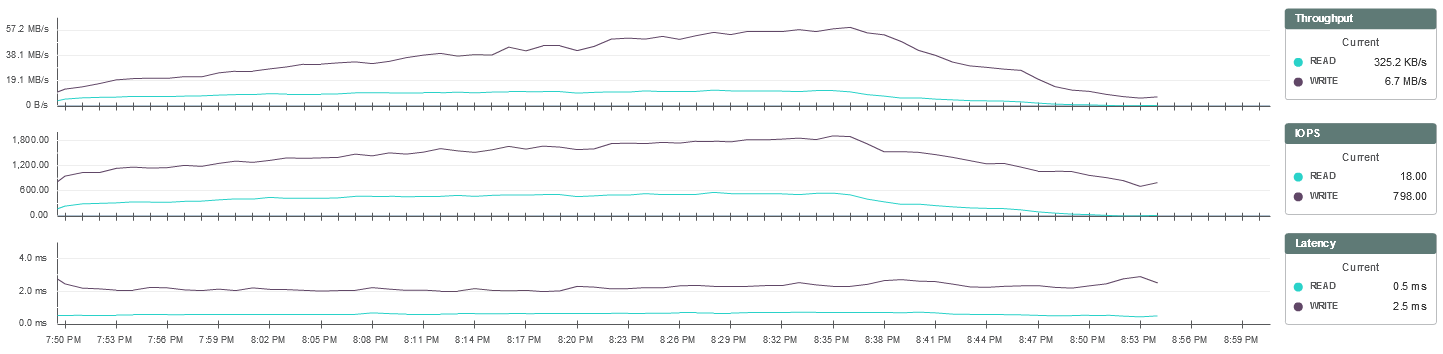
Полученные результаты аналогичны тестированию предыдущей конфигурации ВМ.
300 Power workers с переподпиской 12
Данные статистики VSImax:
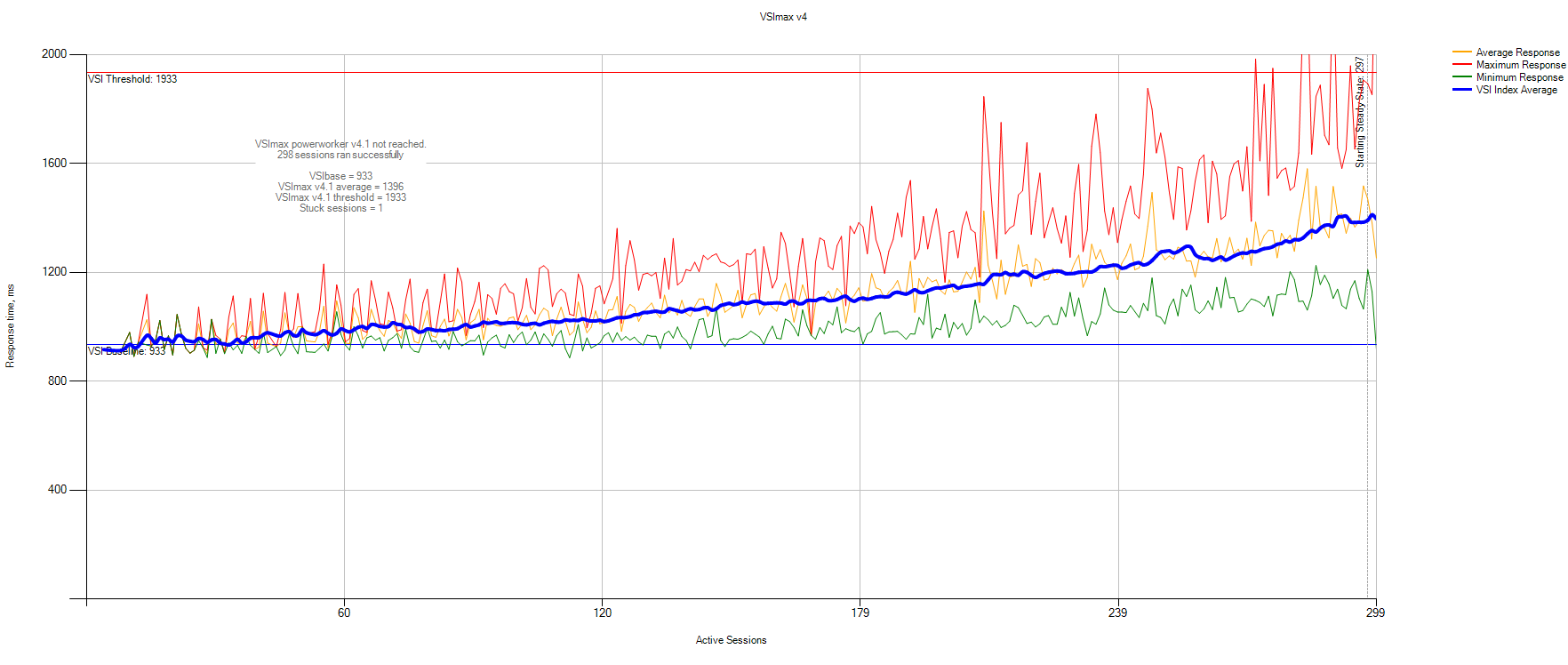
VSIbase = 933, VSI Threshold достигнут не был.
Статистика нагрузки на систему хранения из мониторинга SimpliVity:

При данном тестировании также был достигнут порог нагрузки процессоров, но это не оказало существенного влияния на производительность:


Полученные результаты аналогичны тестированию предыдущей конфигурации.
Что будет, если запустить нагрузку на 10 часов?
Теперь смотрим, будет ли «эффект накопления», и пускаем тесты на 10 часов подряд.
Длительные тесты и описание раздела должны быть нацелены на то, что мы хотели проверить, будут ли возникать какие-то проблемы с фермой при длительной нагрузке на неё.
300 Knowledge workers benchmark + 10 hours
Дополнительно было проведено тестирование варианта нагрузки 300 knowledge workers с последующей работой пользователей в течение 10 часов.
Данные статистики VSImax:
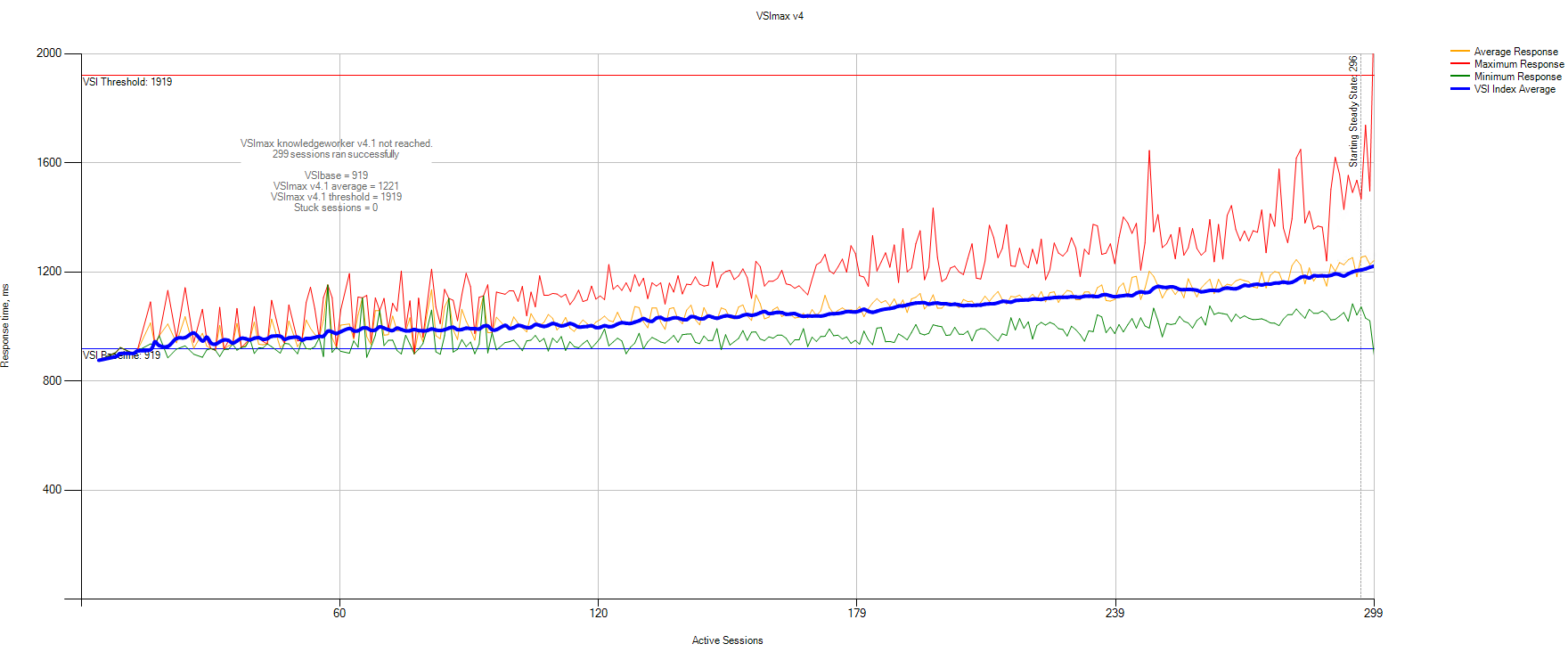
VSIbase = 919 мс, VSI Threshold достигнут не был.
Данные статистики VSImax Detailed:
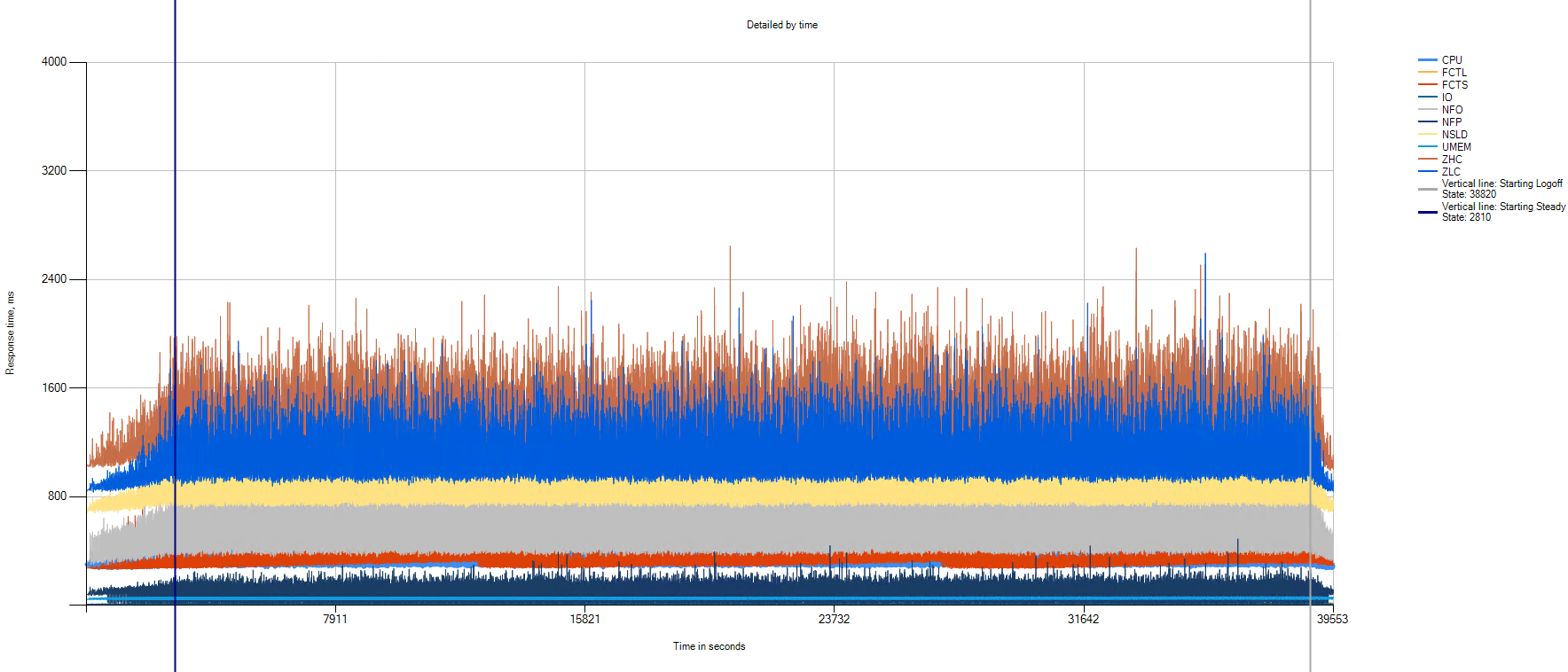
По графику видно, что в течение всего теста не наблюдается какой-либо деградации производительности.
Статистика нагрузки на систему хранения из мониторинга SimpliVity:

Производительность системы хранения остаётся на одном уровне на протяжении всего теста.
Дополнительное тестирование с добавлением синтетической нагрузки
Заказчик попросил добавить дикой нагрузки на диск. Для этого на систему хранения в каждую из виртуальных машин пользователей было добавлено задание на запуск синтетической нагрузки на диск при входе пользователя в систему. Нагрузка обеспечивалась утилитой fio, позволяющей ограничивать нагрузку на диск по количеству IOPS. В каждой машине запускалось задание на запуск дополнительной нагрузки в количестве 22 IOPS 70 %/30 % Random Read/Write.
300 Knowledge workers benchmark + 22 IOPS per user
При первоначальном тестировании было обнаружено, что fio создаёт значительную дополнительную нагрузку на процессор виртуальных машин. Это привело к быстрой перегрузке хостов по CPU и сильно повлияло на работу системы в целом.
Нагрузка на CPU хостов:


Задержки системы хранения при этом также закономерно увеличились:
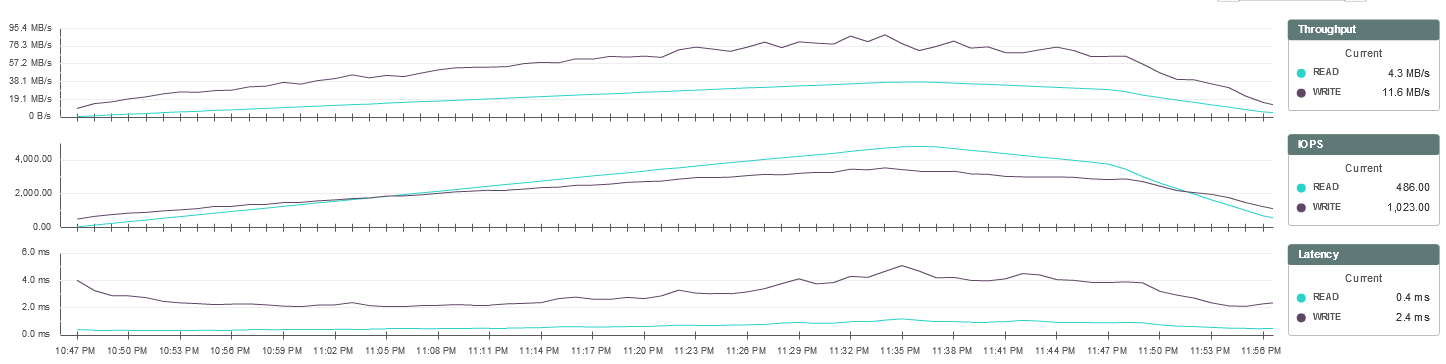
Недостаток вычислительной мощности стал критичным примерно к 240 пользователям:
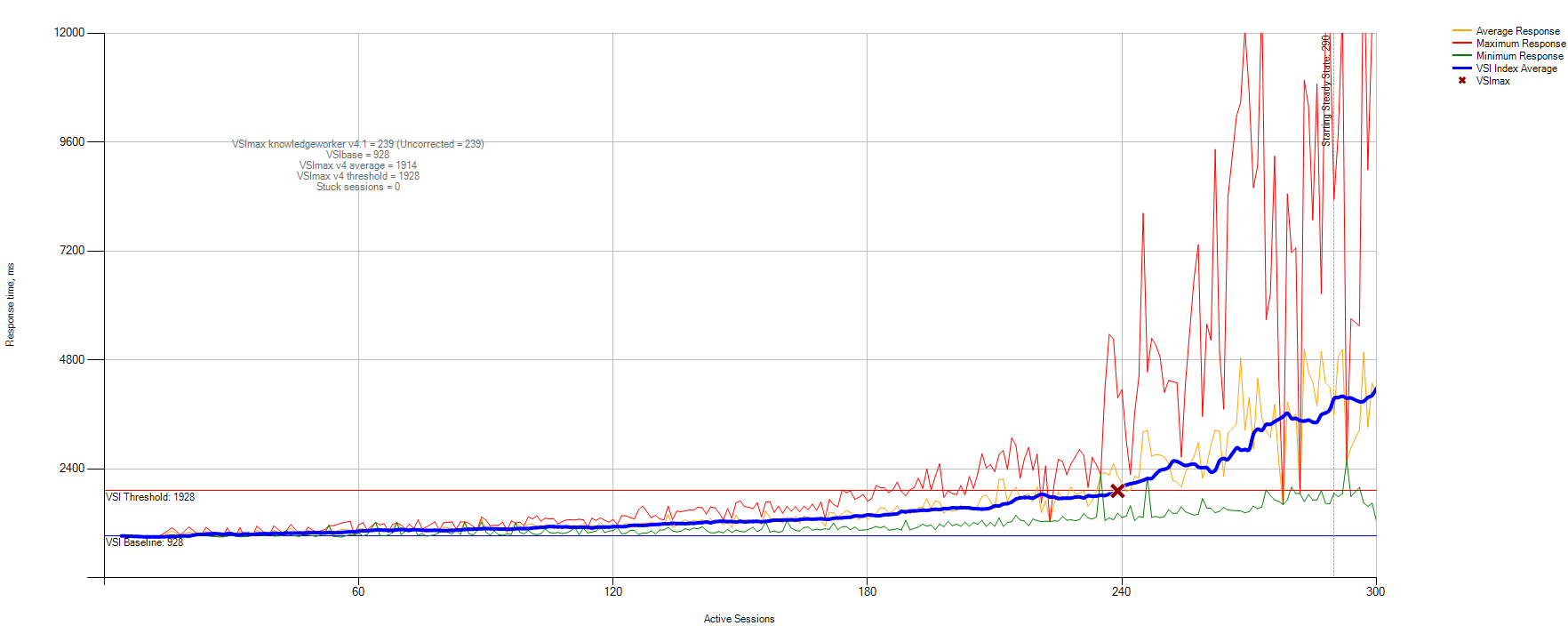
Вследствие полученных результатов было решено провести тестирование, менее нагружающее CPU.
230 Office workers benchmark + 22 IOPS per user
Для снижения нагрузки на CPU был выбран тип нагрузки Office workers, на каждую сессию также было добавлено по 22 IOPS синтетической нагрузки.
Тест был ограничен 230 сессиями для того, чтобы не превысить максимальную нагрузку на CPU.
Тест был запущен с последующей работой пользователей в течение 10 часов для проверки стабильности системы при длительной работе на нагрузке, близкой к максимальной.
Данные статистики VSImax:
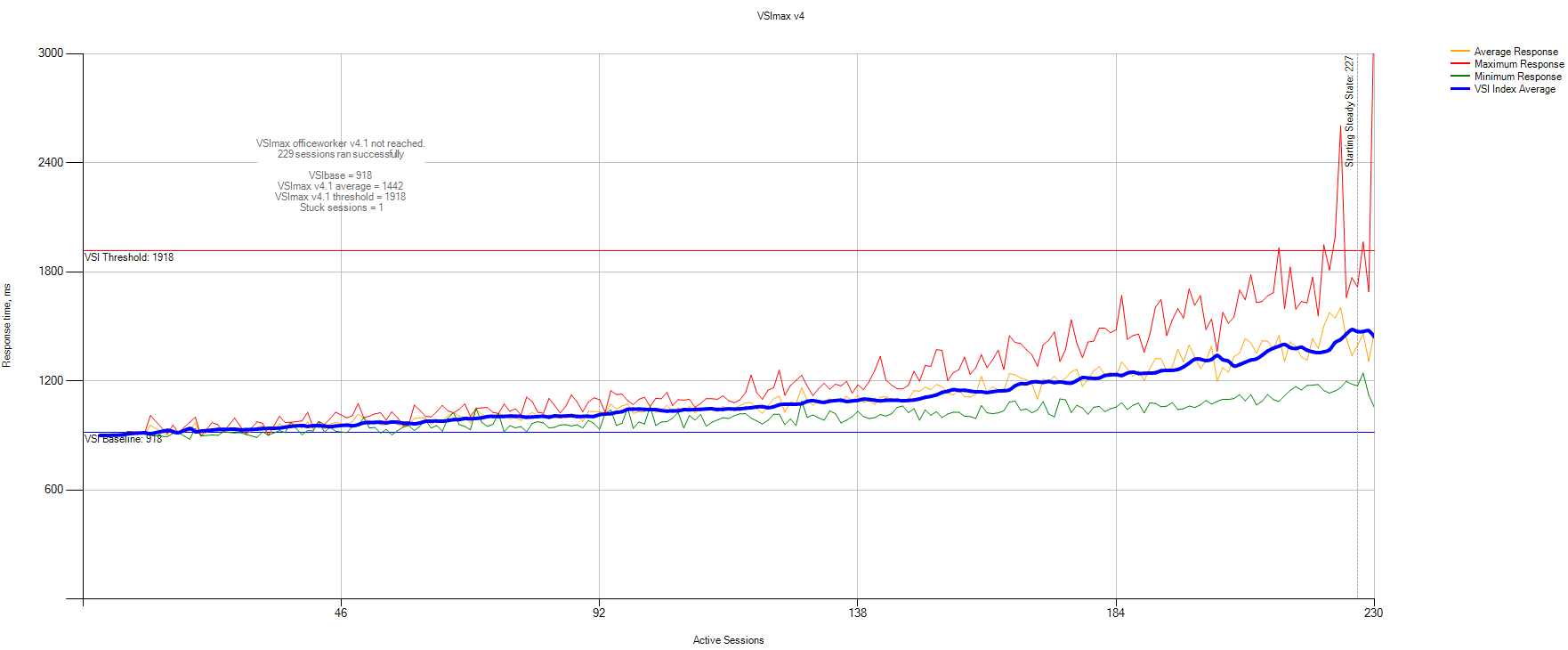
VSIbase = 918 мс, VSI Threshold достигнут не был.
Данные статистики VSImax Detailed:
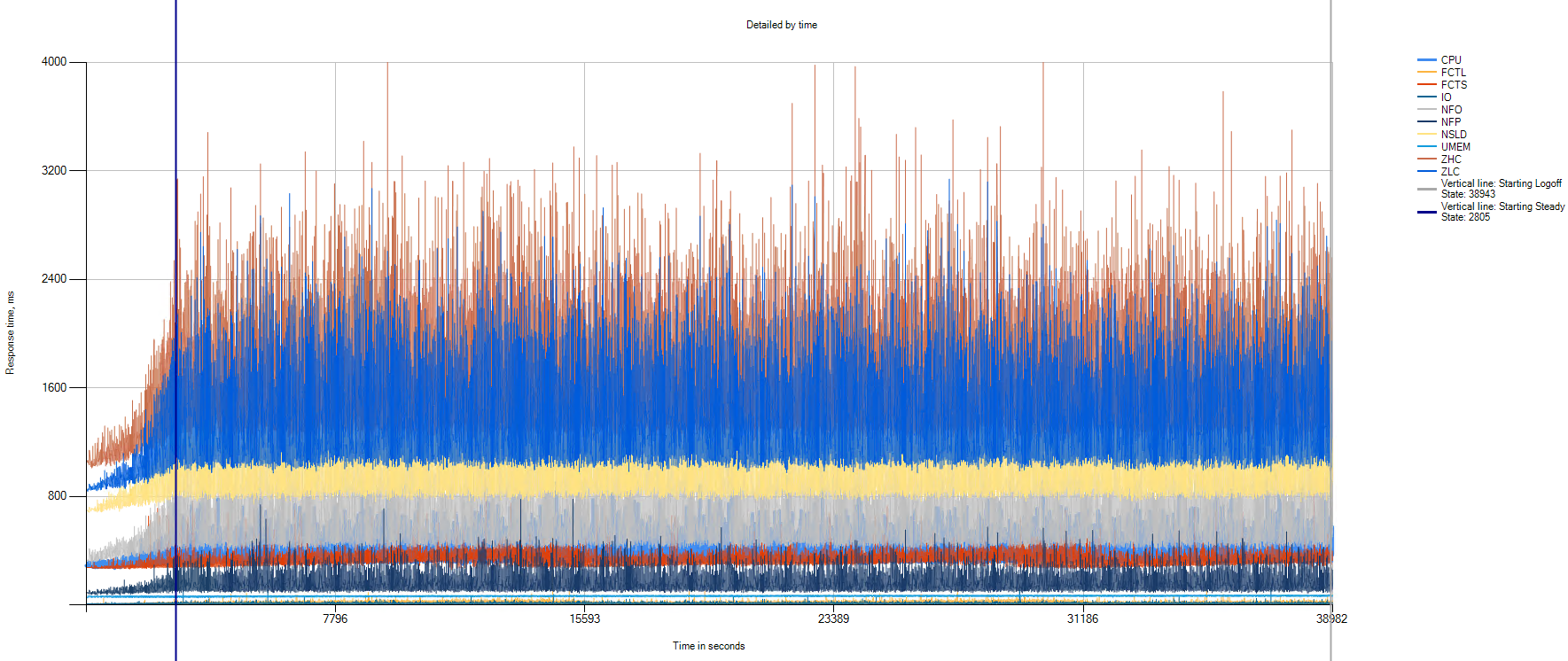
По графику видно, что в течение всего теста не наблюдается какой-либо деградации производительности.
Данные статистики по нагрузке на CPU:
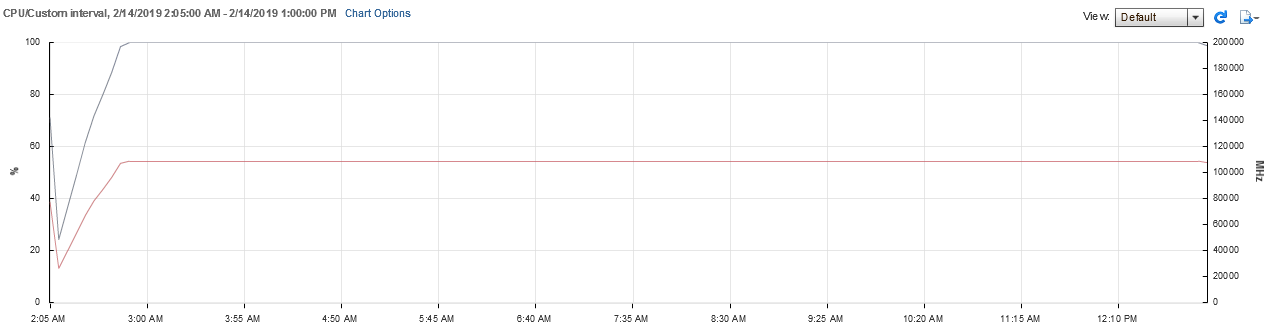
При выполнении данного теста нагрузка на CPU хостов была практически максимальной.
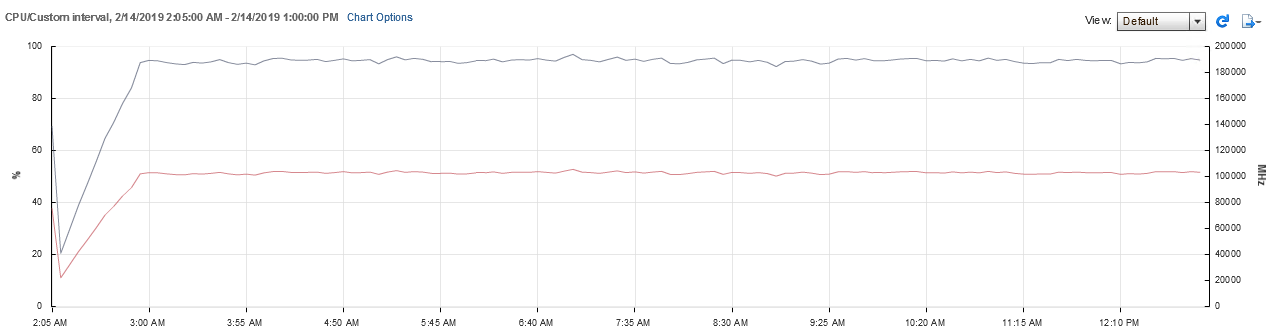
Статистика нагрузки на систему хранения из мониторинга SimpliVity:

Производительность системы хранения остаётся на одном уровне на протяжении всего теста.
Нагрузка на систему хранения в течение теста составила примерно 6 500 IOPS в соотношении 60/40 (3 900 IOPS — на чтение, 2 600 IOPS — на запись), что составляет примерно 28 IOPS на одну рабочую станцию.
Время отклика в среднем составляло 3 мс на запись и до 1 мс — на чтение.
Итог
При моделировании реальных нагрузок на инфраструктуру HPE SimpliVity были получены результаты, подтверждающие способность системы обеспечивать работу виртуальных рабочих столов в количестве не менее 300 Full Clone-машин на паре узлов SimpliVity. При этом время отклика системы хранения сохранялось на оптимальном уровне на протяжении всего тестирования.
Нам очень импонирует подход про длительные тесты и сравнение решений до внедрения. Мы можем протестировать производительность и для ваших нагрузок, если хотите. В том числе на других гиперконвергентных решениях. Упомянутый заказчик сейчас заканчивает тесты на другом решении в параллель. Его текущая инфраструктура — просто парк ПК, домен и софт на каждом рабочем месте. Переезжать на VDI без тестов, конечно, довольно сложно. Конкретно сложно понимать реальные возможности фермы VDI, не смигрировав на неё реальных пользователей. А эти тесты позволяют быстро оценить реальные возможности той или иной системы без необходимости привлечения обычных пользователей. Отсюда и возникло такое исследование.
Второй важный подход — заказчик сразу заложился на правильное масштабирование. Тут можно докупать сервер и добавлять ферму, например, на 100 пользователей, всё предсказуемо по цене пользователя. Например, когда им понадобится добавить ещё 300 пользователей, они будут знать, что нужны два сервера в уже определённой конфигурации, а не пересматривать возможности модернизации своей инфраструктуры в целом.
Интересны возможности федерации HPE SimpliVity. Бизнес — географически разделённый, поэтому в дальний офис имеет смысл ставить свою отдельную VDI-железку. В федерации SimpliVity каждая виртуалка реплицируется по расписанию с возможностью делать между географически удалёнными кластерами очень быстро и без нагрузки на канал — это встроенный бекап очень хорошего уровня. При репликации ВМ между площадками канал задействуется настолько минимально, насколько это возможно, и это даёт возможности строить очень интересные архитектуры DR при наличии единого центра управления и кучи децентрализованных площадок хранения.
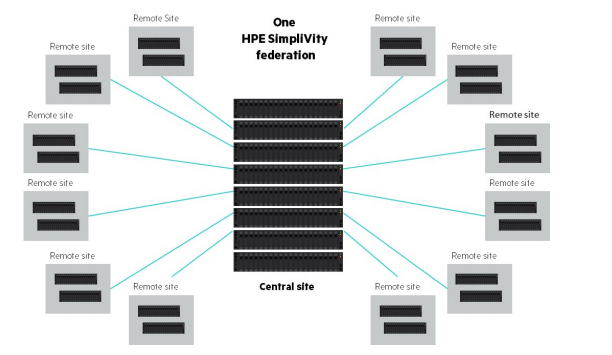
Федерация
Всё это в совокупности даёт возможность оценить и финансовую сторону очень детально, и наложить затраты на VDI на планы роста компании, и понять, как быстро окупится решение и как оно будет работать. Потому что любой VDI — это решение, которое в итоге экономит массу ресурсов, но при этом, скорее всего, без экономически выгодной возможности поменять его в течение 5–7 лет использования.
В общем, если остались вопросы не для комментариев, — пишите мне на почту mk@croc.ru.
Комментарии (22)

ILya63
24.04.2019 11:12Лет 10 назад использовали Autoit и ни какого специального софта для тестирования VDI не требовалось.
algotrader2013
24.04.2019 12:16Выглядит странным использование 2 x Intel Xeon Platinum 8170 26c 2.1Ghz и SATA SSD
Действительно ли целесообразно использовать платинумы, в которых серьезный процент от цены идет за возможность строить 8-ми сокетную систему без костылей, в двухпроцессорных системах? Выглядит, как неудачный костыль (у нас есть 2х сокетная система, надо бы по максимумуму в нее засунуть ядер, и все равно на цена/перфоманс).
Все таки, $7500 за 1 камень с позорной частотой в 2.1. А ведь за $3000 ведь можно купить Gold 6248, где 20 ядер с частотой 2.5, и они становятся вчетвером в один недорогой 2u корпус типа такого . И такая система на 80 2.5 ГГц ядер будет в разы производительнее купленной.
Да и при готовности платить 30К только за камни (и еще хз сколько за лицензии), странно зажимание денег на NVMe диски. Ну сэкономите за счет SSD, потом пользователи будут ходить утром кофе пить, пока их софт прогревается. Оно того стоит?Tigger
24.04.2019 12:49Насколько я понял тут речь не о купленном решении, а о том, которое тестировали. Что было доступно на тест из многоядерных процессоров — то и протестировали.
MikeKostsov Автор
24.04.2019 13:11Использование 8170 особенность тестирования, где действительно целью было получить побольше ядер в одном узле.
В реальных проектах, как правильно заметили, чаще всего используем 6148 (новые 6248 только вышли, так что будем в и их закладывать). 4-сокетные серверы ставить не всегда целесообразно, т.к. в итоге получается большой домен отказа, а экономия только в занимаемом пространстве (если сравнивать именно 2U серверы).
Про NVMe диски немного не в тему. В SimpliVity они на данный момент не используются. Да и такого заметного влияния для пользователей они не дадут. А для БД, мегакритичных к задержкам – да.
shapa
24.04.2019 13:19-2Про дико устаревший (около 10 лет ему) проприетарный адаптер дедупликации и компрессии коллеги из Крока или сами не в курсе (?), или предпочитают не рассказывать на публику детали.
Дело в том, что этот адаптер «держит» только блоки данных размером 8 килобайт, в итоге все что больше (а почти во всех случаях на сегодня оптимальнее использовать блоки ФС большего размера) — сначала разбивается на блоки по 8, затем обратно «сшивается».
По сути, этот адаптер кардинально замедляет работу подсистемы ввода-вывода, отсюда настолько низкие результаты при тестировании.
p.s. Пример BestPractices от Microsoft для SQL сервера — «Operating System Best Practice Configurations for SQL Server:
»Hence, on a SQL Server machine the NTFS Allocation unit size hosting SQL database files (Including tempdb files) should be 64K.""
maxsl78
24.04.2019 15:59Вопрос вопросов для HCI решения, что лучше? Неоптимально так? или на CPU? Тем более для Windows десктопа стандартный блок 4K
shapa
24.04.2019 16:17Для HCI уже доказано двумя лидирующими вендорами на этом рынке (Dell EMC Vmware и Nutanix) — лучше делать чисто программно.
В современные процессоры (Intel, IBM, AMD) встроены все нужные аппаратные инструкции — как для сжатия, так и дедупликации и криптования (например аппаратная калькуляция хэшей SHA256)
p.s. 4k для Симпливити тоже не оптимально ;)
maxsl78
24.04.2019 15:48Лучше бы поделились опытом реальной эксплуатации подобных систем. Синтетика она такая синтетика, на малом масштабе можно сильно пролететь с сайзингом. Например у нас VDI на 120 «power users» использующих в работе СЭД, Почта-офис, UC, CRM «пробивает» в активные часы > 60к write iops avg. В масштабе 300 десктопов 22 iops на арм выглядят далекими от реальных нагрузок.
shapa
24.04.2019 16:1922 IOPS на рабочее место — это дико низкий результат, отчего вся статья выглядит забавно.
В реалиях должно быть намного выше. 60k на 300 пользователей — вполне верю, это как раз примерно 30% нагрузки на базовый кластер Nutanix из трех узлов (около 180k IOPS random write 4k блоки) (N+1 — два узла и один в запасе).vesper-bot
24.04.2019 17:15Это что же за нутаникс-кластер, который 180к иопс тянет на три ноды? All flash там, что ли? У него оверхэд на запись минимум четырехкратный (разве что хранилище RF1 делать).
shapa
24.04.2019 17:30Где начитались про «оверхеды»? ;) Сказки от конкурентов?
Гибриды, гибриды.
Запись (кроме последовательной) идет всегда на флеш уровень, далее (когда данные остывают) мигрирует на холодный (для гибридных систем).
Нутаникс ОС умеет делать все оптимизации данных (компрессия, дедупликация и прочее) для любого варианта — All Flash (включая NVMe + SSD), Hybrid и т.д.
All Flash цифры намного выше — можно на 4-х узлах легко 600+ тысяч IOPS получить.vesper-bot
25.04.2019 13:23Ладно, дальше в приват. Что-то мне подсказывает, что мы слегка о разных нутаниксах говорим. :)
MikeKostsov Автор
24.04.2019 17:42120 пользователь VDI выдаёт 60000 IOPS на запись – это что-то уникальное. Удалось вычислить что действительно создаёт столько нагрузки?
22 IOPS на АРМ в описанных тестах – это дополнительная нагрузка, создаваемая иометром, помимо тех, что создают и другие описанные задачи.
В среднем мы видим по проектам, на дисковую подсистему каждый пользователь генерит по 15-25 IOPS 60/40% R/W. От проекта к проекту цифры естественно разные, но держатся около этих показателей.
Вот для примера скриншоты с реальной системы SimpliVity, расположенной у заказчика под VDI, где создано 216 вм и около 80% из них в среднем активно:


maxsl78
25.04.2019 01:51Да ничего особо уникального, основные потребители браузер, приложение для видеоконференций (видеомост), CRM система (отчеты передаются на клиента в виде .xls), swap — конфигурация vm 4vcpu 8gb ram Win10 Ent LTSC (1809).
ustas33
26.04.2019 17:56Велосипеды с костылями.
Был бы нормальный рынок, заказчик бы купил себе подписку на Windows Virtual Desktop в Azure azure.microsoft.com/en-us/pricing/details/virtual-desktop
и спокойно жил.
awsswa59
28.04.2019 09:30Azure нужен для внешних клиентов.
а VDI как правило используют на 99% времени внутри своей сети.
awsswa59
Я надеюсь вы предупредили заказчика что SimpliVity морально устарела как уже года 3-4 назад. А деградация SSD на SimpliVity просто бешеная.
Раз у вас с бюджетом все хорошо, почему не использовали карты от TERADICHI? У вас провал по процам, а карты снимают 20-25% общей нагрузки.
Тесты с PCI Intel optine — делали?
shapa
Это в стиле Крок :) Продолжать упорно продавливать устаревшие технологии, не информируя клиента о том что есть существенно более грамотные, выгодные и надежные решения.
Проблем технических масса — помимо упомянутой тобой деградации SSD — они еще и лимитируют (резко) скорость записи на SSD, чтобы те не умерли в гарантийный срок.
Это — вопиющий технический косяк.
" Both platforms provide the same capacity and burst performance, but a feature called Media Lifecycle Manager can throttle write performance to ensure a full three years of life on the SSDs in the 4000 series nodes."
h20195.www2.hpe.com/v2/getpdf.aspx/a00019351enw.pdf
TERADICHI как раз смысла на правильных протоколах типа Blast смысла использовать абослютно нет, проблема в жестком перерасходе ресурсов самой Simplivity (RAM в особенности).
В целом даже сами HPE уже все поняли.
https://www.hpe.com/us/en/newsroom/press-release/2019/04/hpe-and-nutanix-sign-global-agreement-to-deliver-hybrid-cloud-as-a-service.html
MikeKostsov Автор
Вопиющий технический косяк» — на самом деле разумное ограничение, т. к. ноды 4000-й серии содержат в себе Read-Intensive диски.
Если изначально понятно, что ожидается постоянная активная запись 24х7, никто не мешает взять ноды 6000-й серии с Write Intensive дисками, где ничего не лимитируется.
shapa
Цены на это чудо (с 6000-й серией) видел? :D
и VSAN (который намного лучше Симпливити технически) и уж тем более NTNX будут намного выгоднее, не говоря о тотальном техническом превосходстве.
MikeKostsov Автор
Видел, но для каждого заказчика и сравнения — это сугубо индивидуальный вопрос.
MikeKostsov Автор
По моральному устареванию и деградации — вопрос спорный. Тем более в первую очередь важно решение бизнес-задач и обеспечение для них отказоустойчивой, гибкой и производительной платформы, чему это решение полностью соответствует.
Карты Teradici предназначены для оффлоада нагрузки протокола PCoIP. Здесь же при тестировании да и в целом в проектах мы используем HDX для Citrix и Blast для VMware.
Intel Optane в рамках самого SimpliVity не используется. Отдельных тестов под это не проводили, да и большого смысла под VDI в этом не видим.