
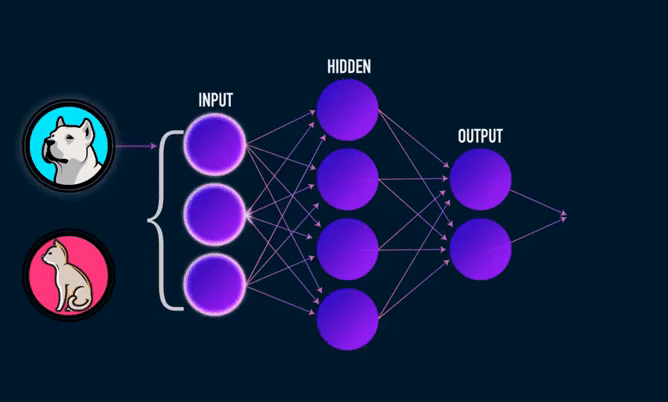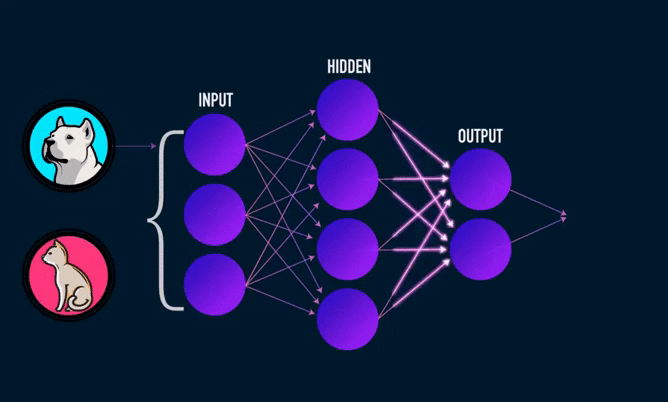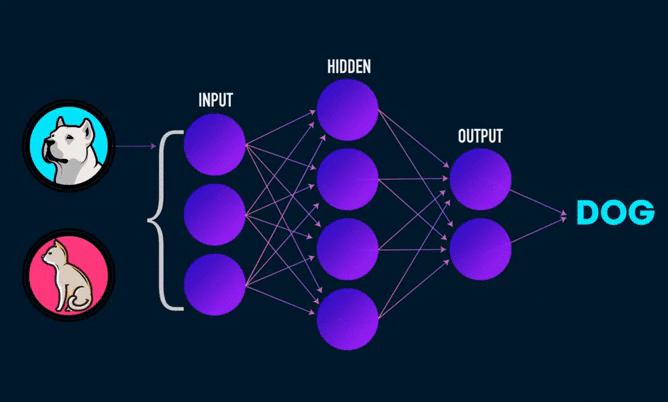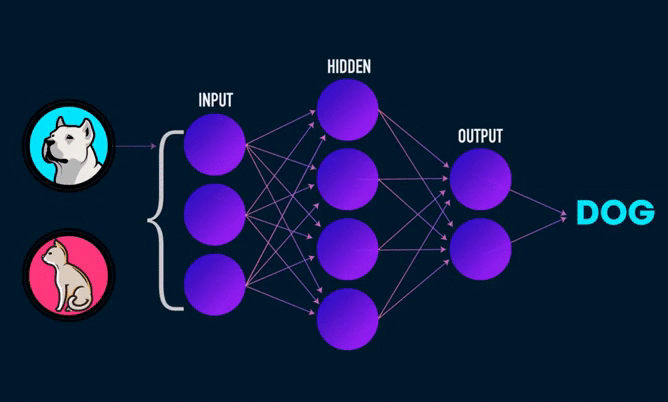
Всем привет! На повестке дня интересная тема — будем создавать с нуля собственную нейронную сеть на Python. В ее основе обойдемся без сложных библиотек (TensorFlow и Keras).
Основное, о чем нужно знать — искусственная нейронная сеть может быть представлена в виде блоков/кружков (искусственных нейронов), имеющие между собой, в определенном направлении, связи. В работе биологической нейронной сети от входов сети к выходам передается электрический сигнал (в процессе прохода он может изменяться).
Электрические сигналы в связях искусственной нейронной сети — это числа. Ко входам нашей искусственной нейронной сети мы будем подавать рандомные числа (которые бы символизировали величины электрического сигнала, если бы он был). Эти числа, продвигаясь по сети будут неким образом меняться. На выходе мы получим ответ нашей сети в виде какого-то числа.

Искусственный нейрон
Для того, чтобы нам понять как работает нейронная сеть изнутри — внимательно изучим модель искусственного нейрона:

Поступающие на вход рандомные числа умножаются на свои веса. Сигнал первого входа ?? умножается на соответствующий этому входу вес ??. В итоге получаем ?. И так до ??-ого входа. В итоге на последнем входе получаем ?.
После этого все произведения передаются в сумматор, который суммирует все входные числа, умноженные на соответствующие веса:
Справка по Сигме.Итогом работы сумматора является число, называемое взвешенной суммой:
Отмечу, что просто так подавать взвешенную сумму на выход бессмысленно. Нейрон должен обработать ее и получить адекватный выходной сигнал. Для этих целей используют функцию активации (мы будем использовать Sigmoid).
Функция активации (Activation function) — функция, принимающая взвешенную сумму как аргумент. Значение этой функции и является выходом нейрона .
Обучение нейронной сети
Обучение нейронной сети представляет собой процесс тонкой настройки весов и смещений из входных данных. Конечно, правильные значения для весов и смещений определяют точность предсказаний.
Выход у двухслойной нейронной сети будет выглядеть следующим образом:
— входной слой;
— выходной слой;
— набор весов;
— набор смещений;
— выбор функции активации для каждого скрытого слоя.
Как мы видим веса и смещения являются единственными переменными, которые влияют на выход .
Для информации, результат повторного применения обучающего процесса состоит из 2-х шагов:
- Вычисление прогнозируемого выхода ;
- Обновление весов и смещений.
Опишем все это в коде:
class NeuralNetwork:
def __init__(self, x, y):
self.input = x
self.weights1 = np.random.rand(self.input.shape[1],4)
self.weights2 = np.random.rand(4,1)
self.y = y
self.output = np.zeros(self.y.shape)
def feedforward(self):
self.layer1 = sigmoid(np.dot(self.input, self.weights1))
self.output = sigmoid(np.dot(self.layer1, self.weights2))
Оценивать качество наших результатов (набор весов и смещений, который минимизирует функцию потери) мы будем вместе с суммой квадратов ошибок (среднее значение разницы между каждым прогнозируемым и фактическим значением):
Далее, после измерения ошибки нашего прогноза, нам нужно найти способ распространения ошибки обратно и обновить наши веса и смещения. В этом нам поможет градиентный спуск.
Здесь мы не сможем вычислить функции потерь по отношению к весам и смещениям, так как её уравнение не содержит весов и смещений.
Ура! Мы получили то, что нам нужно?—?производную функции потерь по отношению к весам. Теперь мы сможем регулировать веса.
Добавим функцию backpropagation в наш код:
class NeuralNetwork:
def __init__(self, x, y):
self.input = x
self.weights1 = np.random.rand(self.input.shape[1],4)
self.weights2 = np.random.rand(4,1)
self.y = y
self.output = np.zeros(self.y.shape)
def feedforward(self):
self.layer1 = sigmoid(np.dot(self.input, self.weights1))
self.output = sigmoid(np.dot(self.layer1, self.weights2))
def backprop(self):
d_weights2 = np.dot(self.layer1.T, (2*(self.y - self.output) * sigmoid_derivative(self.output)))
d_weights1 = np.dot(self.input.T, (np.dot(2*(self.y - self.output) * sigmoid_derivative(self.output), self.weights2.T) * sigmoid_derivative(self.layer1)))
self.weights1 += d_weights1
self.weights2 += d_weights2
На этом наша сеть готова. Выводы по качеству нейронной сети предлагаю каждому сделать самостоятельно.
Всем знаний!
Прогноз/Факт
0.023/0
0.979/1
0.975/1
0.025/0
Подписывайтесь на мой телеграм-канал (@dataisopen), чтобы не пропустить интересные статьи из мира искусственных нейронных сетей!
Комментарии (27)


GokenTanmay
29.04.2019 10:37На Python есть отличная библиотека TensorFlow — которая умеет считать NN на видеокартах NVidia (> CUDA 3.0). Причем конфигурация сетки описывается до безобразия просто и удобно.
Для информации: Видеокарта NVidia 660 GTX считает сетку на TensorFlow приблизительно быстрее в 40 раз, чем та же сетка считается на i5 2500k.
Проблема не закодировать сетку — проблема очень сильно ее оптимизировать что бы быстро подобрать веса.
lair
29.04.2019 11:19+1> На Python есть отличная библиотека TensorFlow
Правильнее сказать, в Python есть биндинги для отличного фреймворка TensorFlow.GokenTanmay
29.04.2019 13:39Спасибо за подсказку. Я не программист — поэтому в нюансах терминологии могу быть некорректен. Просто отложилось, что если «это» ставится через pip или setuptools, то это скорее всего библиотека.
Но что меня реально поразило несколько лет назад, то это с какой легкостью можно запускать код на GPU, это было очень круто и очень эффектно.
lair
29.04.2019 11:19+1> Здесь мы не сможем вычислить функции потерь по отношению к весам и смещениям, так как её уравнение не содержит весов и смещений.
> Ура! Мы получили то, что нам нужно?—?производную функции потерь по отношению к весам. Теперь мы сможем регулировать веса.
Гм. «Теперь нарисуйте остальную сову»?
И это еще не вдаваясь в то, что feed-forward all-dense — это далеко не единственный вариант сети. И совершенно не понятно, где после вашего упрощения, собственно, смысл.Psychopompe
29.04.2019 18:04Тот «редкий медицинский случай», когда чтение комментариев может быть полезнее самой статьи.
M00nL1ght
29.04.2019 11:31+2В ее основе обойдемся без сложных библиотек (TensorFlow и Keras).
А чем отличается перемножение матриц с помощью numpy:
self.layer1 = sigmoid(np.dot(self.input, self.weights1)) self.output = sigmoid(np.dot(self.layer1, self.weights2))
От того же самого но в tensorflow?
output = tf.matmul(X, W) + b
что такое sigmoid в вашем коде? где она определена?
Просто прочитав начало статьи я ожидал увидеть полностью реализованный процесс построения сети с описанием и без помощи сторонних библиотек, а увидел замену tf.matmul на np.dot, которые по факту ничем не отличаются. Ну да бэк проп описали в коде (при чем не описали словами и математически), опять же с помощью numpy. Но мне кажется этого как то маловато и не понятно почему именно так умножаются матрицы, а не иначе, что за теория за этим стоит.
Да и вообще чем tensorflow сложнее numpy? Сейчас создать простую нейронку на tf намного легче чем на np, да и эффективней, так как, уже упоминалось выше, можно использовать gpu, про keras я вообще молчу.TiesP
29.04.2019 12:03Для использования tensorflow порог вхождения, всё-таки, повыше, чем для numpy. Код для tf так просто не запускается, как здесь. Там нужны дополнительные телодвижения — инициализация переменных, открытие/закрытие сессии, доп.запуск расчета и т.д.
M00nL1ght
29.04.2019 12:17Если для человека порог вхождения выше из за того, что надо переменные инициализировать, то я даже не знаю, что и посоветовать.
Numpy более общая либа для работы с матрицами и выполнения операций с ними, tensorflow в основе своей это тоже работа с матрицами (тк нейронки это матрицы по сути) + добавлены специфические возможности для упрощения построения и реализации нейроных сетей, темплейты нейронок и тд и тп.
Насчет сессий: tensorflow 2.0 грядет. Да и pytorch никто не отменял)TiesP
29.04.2019 12:26под «переменные инициализировать» я имел в виду дополнительные телодвижения, типа
tf.initialize_all_variables().run()
кроме обычных инициализаций типа
w = tf.Variable([0., 0., 0.], name="w", trainable=True)
… понятно, что после нескольких повторений человек привыкает)M00nL1ght
29.04.2019 12:36+1Это все исходит из концепции сессий, которые в скором времени должны кануть в лету.
Но тем не менее, эти телодвижения можно и потерпеть ради возможности запускать вычисления на GPU. И от такого порог вхождения не должен повышаться. Вас же не заставляют писать cudaMalloc, cudaMemcpy, cudaFree и прочее.
А так есть еще pytorch без телодвижений)
UDP: Все таки tf предназначен для построения сетей, поэтому его легче и лучше использовать чем numpy. Да согласен там есть свои заморочки но куда ж без них)
В данной статье не понятен смысл замены tensorflow/pytorch и прочее на numpyTiesP
29.04.2019 13:10В общем да, я тоже для себя решил, что лучше изучить tf. Ещё мне нравится в нем, что он довольно универсальный, и можно обученную сеть даже на Android использовать (встроив её в программу).
Akon32
29.04.2019 13:07А чем отличается перемножение матриц с помощью numpy… от того же самого но в tensorflow?
TF автоматически добавляет связи для графа вычислений и автоматически вычисляет производные. Да, для всех 20 слоёв. Имхо, обучать нейронные сети без такой технологии — неверный путь.

D1abloRUS
29.04.2019 12:08Оставлю тут, мало кому понадобится uber.github.io/ludwig, в целом без порогов вхождения

na9ort
29.04.2019 12:26Я что-то не понял, а где нейронная сеть то? Начало статьи многообещающее: будем учить сеть определять животное по картинке. На деле же пару определений, несколько формул, тяп ляп и статья готова. Серьёзно?

iroln
29.04.2019 13:18Здесь мы не сможем вычислить функции потерь по отношению к весам и смещениям, так как её уравнение не содержит весов и смещений.
Ура! Мы получили то, что нам нужно?—?производную функции потерь по отношению к весам. Теперь мы сможем регулировать веса.Какой полёт мысли, какой элегантный и логичный переход в рассуждениях, всё всем стало кристально ясно, ведь это тривиальные вещи! :)
А где код функций sigmoid и sigmoid_derivative? Я что-то не вижу.
Зачем писать такие "статьи", не понимаю. Уверен, что любой, кто не в теме ничего не поймёт из вашей "статьи" и даже код запустить не сможет, потому что он не работает в том виде, в каком вы его показали.
Akon32
29.04.2019 13:25Очередная из десятков бесполезных статей про то, как сделать никому не нужный перцептрон
и бросить изучение нейросетей. В то время как tensorflow/keras содержит учебные примеры распознавания картинок от рукописных цифр до котиков.

Wundarshular
29.04.2019 15:37Ещё один способ написать нейронную сеть, особо не вникая в устройство, и КДПВ? Всё?

PurpleTentacle
30.04.2019 09:22Интересная статья, спасибо. Только если вы используете русскую терминологию всюду, почему числа «рандомные», а не случайные? Это дорога к дигитальному тиви и чилдринятам в скуле. :-)

koldoon
30.04.2019 10:18Как-то началось все очень бодро, но после трети статьи ритм повествования улетел куда-то в космос и от начального посыла «объяснить все последовательно на пальцах» ничего не осталось.: ( Как будто «Обучение нейронной сети» писал не тот же самый человек, что и первый раздел.

dark_ruby
30.04.2019 14:58а может кто-то нормальную статью на эту тему посоветовать, чтоб именно с нуля и доходчивым обьяснением всех формул и не обязательно на питоне. Особенно я не понимаю как бекпропагейшн работает.
lair
30.04.2019 16:36Я пользовался известным курсом от Andrew Ng. Backprop рассказывают в пятой неделе.

DrAndyHunter
> Создадим для этого правило цепи помощи в вычислении:
Вы не дописали что-то?
Вообще статья больше похожа на рекламу вашего канала в Телеграм
Syurmakov Автор
Спасибо, что поправили. Ошибки при редактировании, уже исправил/заменил.
Телеграм-канал это не реклама, а осведомленность :)
ivanych
Кажется, всё-равно что-то не дописано, какой-то обрывок предложения: