
Для тех, кто не читал дайджест за октябрь, можете прочесть его здесь.
Итак, а теперь дайджест за ноябрь:
1. MIT разработал новый тип робота, который может расти как растение когда ему требуется дополнительная досягаемость.

2. Компания Disney представила систему для быстрой и надежной передачи предметов, а также исследование влияния скорости робота и времени реакции на воспринимаемое качество взаимодействия.
3. Под микроскопом: лаборатория Top Pathology Lab объединяет источники данных для разработки ИИ, обнаруживающего рак.
4. Команда исследователей из Google и Berkeley AI Research недавно разработала новый подход, который объединяет RL с обучением путем имитации. Он может быть использован для обучения ИИ решать многоэтапные и долгосрочные задачи — манипулирования объектами, занимающие длительный период времени.

5. Модель AlphaStar от DeepMind обучилась играть в StarCraft II на уровне Грандмастера. В общем рейтинге модель обошла 99.8 % активных игроков. Уровень Грандмастера был достигнут для всех трех типов игроков: Protoss, Terran и Zerg. В начале года AlphaStar соревновалась против двоих лучших игроков в StarCraft II.
6. Исследователи из USI выделили основные проблемы, с которыми сталкиваются разработчики при обучении нейросетей. Выборка состояла из 1059 проблем и коммитов ML-репозиториев на GitHub, которые были вручную проанализированы.
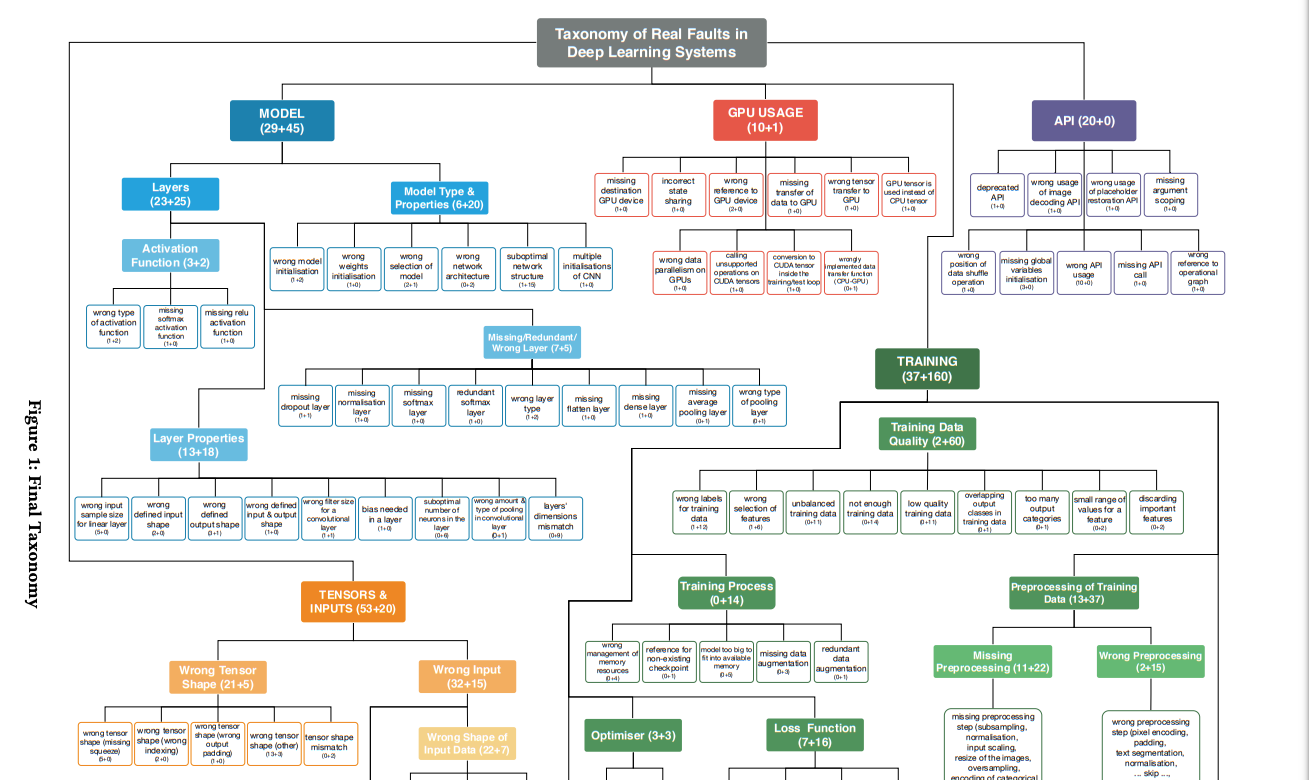
7. Китайские и американские исследователи разработали новый метод обучения нейросетей для распознавания речи по губам, позволивший добиться лучших результатов, чем удавалось аналогичным алгоритмам.
8. Искусственный интеллект может использоваться для предсказания молекулярных волновых функций и электронных свойств молекул. Этот инновационный метод искусственного интеллекта, разработанный группой исследователей из Университета Уорика, Технического университета Берлина и Университета Люксембурга, может быть использован для ускорения разработки молекул лекарств или новых материалов.

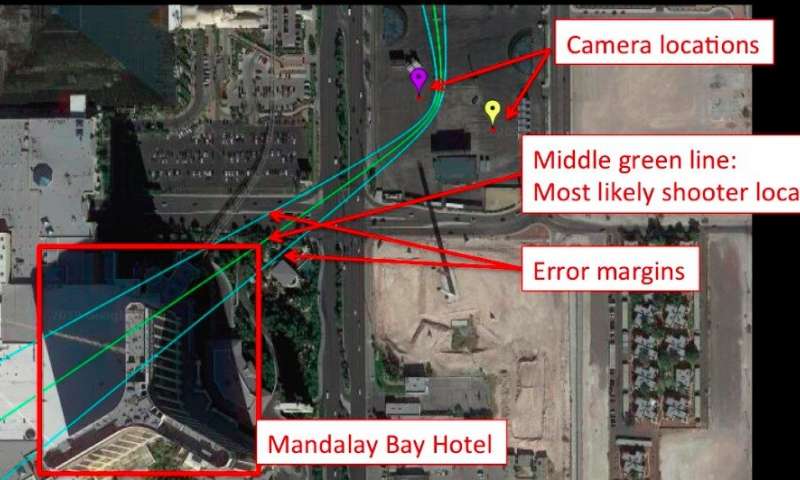
9. Исследователи из Университета Карнеги-Меллона разработали систему, которая может точно определять местонахождение киллера на основе видеозаписей всего с трех смартфонов.
10. Исследователи Массачусетского технологического института разработали бота, оснащенного искусственным интеллектом, который может побеждать игроков-людей в хитрых многопользовательских онлайн-играх, где роли и мотивы игроков держатся в секрете.

11. «Роботы-оригами» — это современные мягкие и гибкие роботы, которые тестируются для использования в различных сферах, включая доставку лекарств в человеческие тела, поисково-спасательные операции в условиях стихийных бедствий и роботизированное оружие-гуманоид.
12. Google представила Night Sight, который расширяет границы съемки при слабом освещении с помощью телефонных камер. Позволяя выдержке до 4 минут делать четкие снимки звезд на ночном небе или ночных пейзажей без какого-либо искусственного освещения.

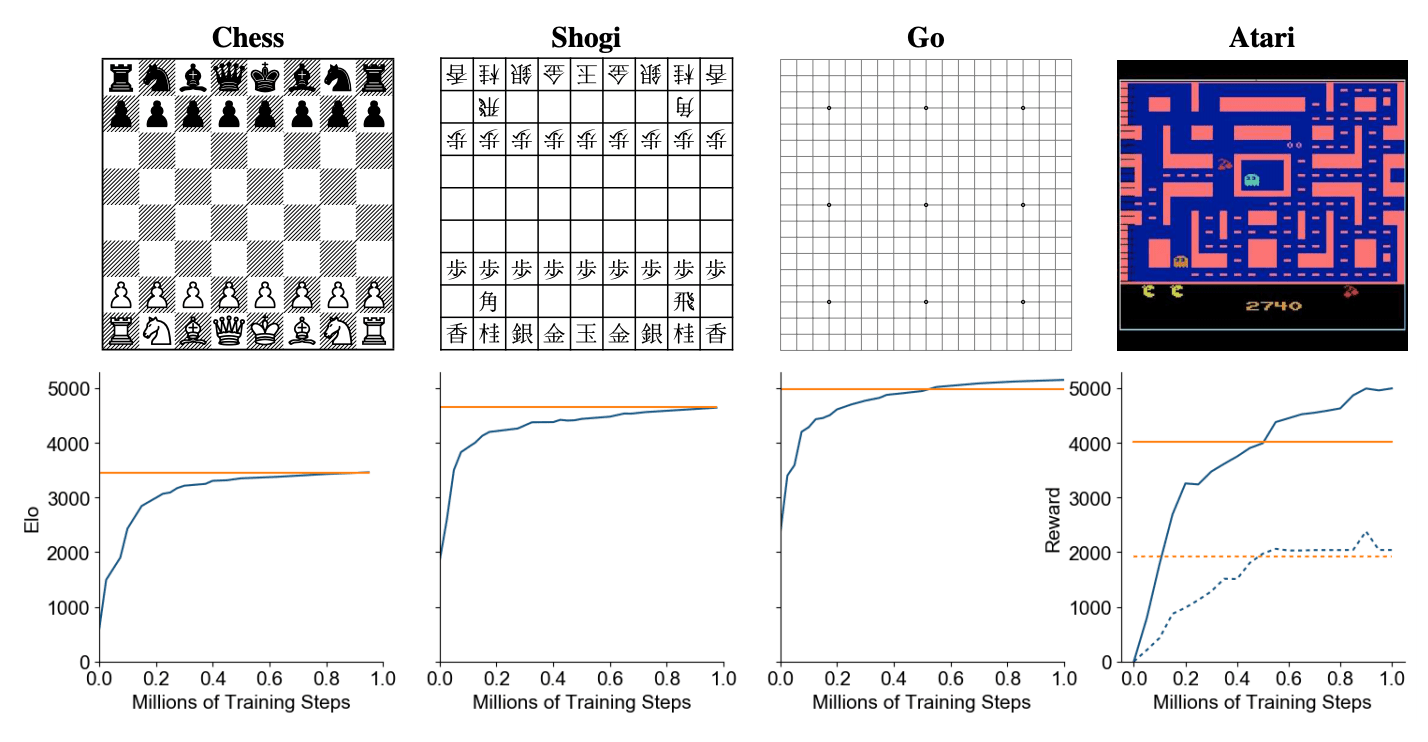
13. Модель от DeepMind учится играть одновременно в шахматы, Atari, Go и Shogi. Разработкой алгоритма занимались исследователи из DeepMind. MuZero выдает state-of-the-art результаты для игры Atari 2600 и обходит людей в таких играх, как шахматы, сеги и го. Алгоритм расширяет AlphaZero на большее количество сред, среди которых среды с одним игроком.
14. Нейросеть распознает позу робота по одному изображению. Определение позы внешне установленной камеры — фундаментальная проблема для задачи управления роботом. Такой навык необходим роботу, чтобы уметь брать предметы, взаимодействовать с людьми и обходить препятствия.

15. Исследователи из University of Edinburgh обучили нейросетевую модель анимировать игровых персонажей. Нейросеть предсказывает, как персонаж должен взаимодействовать со средой, чтобы выполнить какое-то действие.
16. Нейросеть разделяет аудиозапись на вокал и инструментальную часть. Deezer опубликовали библиотеку на Python Spleeter. Spleeter состоит из предобученных нейросетевых моделей, которые разделяют музыкальную запись на 2, 4 или 5 дорожек. Модели в библиотеке реализованы на TensorFlow.

17. Ученые создали анимированную 3D-голограмму, которую можно потрогать и услышать.
18. Британец Ричард Браунинг пролетел над Брайтонским пирсом около 500 метров, разогнавшись до 136 км/час.
19. В США использовали технологии украинского стартапа Respeecher, который научился копировать голос любого человека.
Бонус!
20. Долголетие связано с белками, которые успокаивают перевозбужденные нейроны. Новое исследование устанавливает молекулярную связь между мозгом и старением и показывает, что сверхактивные нейроны могут сократить продолжительность жизни.

21. Рецепторы вкуса и запаха в некоторых органах контролируют состояние естественного микробного здоровья организма и вызывают тревогу по поводу вторжения паразитов.
22. Новые исследования помогают объяснить, как микробы в кишечнике могут формировать реакции хозяина на страх.

На этом наш короткий дайджест подошел к концу. Не пропускать статьи и новостные дайджесты вам поможет подписка на мой Telegram-канал Нейрон, а также подписка на мой аккаунт на Хабре, не пропускайте следующих дайджестов.
Всем знаний!
Комментарии (5)

ua30
11.12.2019 13:425. Модель AlphaStar от DeepMind обучилась играть в StarCraft II на уровне Грандмастера.
С удовольствием с подобным противником в Civilization играл бы. Давно уже хочется подобного. В пошаговых играх все еще интересней в плане ИИ.
Нормальную катку собирать надо только со своими. А это как минимум 3-5 часов на партию надо выделить, и ждать пока люди соберутся. Так бы часик вечерком с ИИ погонял, засейвился, и продолжил как удобно будет. Ляпота!red75prim
11.12.2019 14:46ИИ придётся учить красиво проигрывать. Если учить его выигрывать, то недообученный будет делать неприятные ляпы, а с хорошо обученным не будет возможности выиграть.
ua30
11.12.2019 15:46Насколько я понимаю, такие ИИ учатся наблюдая за игрой людей. Разбираются все составляющие действия. По итогам одной игры ничего конкретного о них сказать нельзя будет. Но изучив миллионы партий (и учитывая их исходы), можно выстроить определенные закономерности и предрасположенности. ИИ будет сопоставлять ситуацию в которой находится, и получать на основе изученного материала список дальнейших вариантов действий с оценкой их положительного влияния на победу.
Цивилизация у встроенного «ИИ» имеет 9 уровней сложности. Так что ничего даже переделывать не придется. На простых уровнях ИИ будет чаще отдавать предпочтение менее выгодным для себя вариантам. Это решит проблему «хорошо обученного ИИ». Кроме того, не стоит забывать, что ИИ, основанный лишь на таких обучениях, по сути, все еще существенно ограничен в своих возможностях по сравнению с хорошими игроками. Именно поэтому все еще имеем 99,8%. Нет, это круто. Но пройти оставшиеся 0,2% вряд ли будет проще, чем дойти до 99,8%. Все дело в том, что такой ИИ ограничен собственными знаниями. А человек — нет.
А вот что касается красиво проигрывать — тут действительно на первый взгляд загвоздка. Как правило, люди (даже топовые игроки) предлагают скрапать, как только понимают что дальше продолжать уже бессмысленно, все решено. А если и можно теоретически что то сделать — это будет долго и нудно. Ни кто не хочет. В любом случае, интерес пропал. Но! Вы тут забываете, что ИИ не имеет алгоритма. Он не будет рассматривать текущую ситуацию как определенный этап игры. Мол вот все, конец — что мне дальше делать не знаю. Для него каждая итерация — это сопоставление ситуации с базой его знаний и выбор решения действия. Поэтому, я не думаю что он не сможет естественным образом красиво проигрывать и этому надо будет как-то дополнительно обучать. Т.к. его действия в целом будут адекватными. Конечно, могут быть нюансы (типа бросить все силы на последнюю попытку), но это нюансы. ИМХО.
xander27
У Alex007 (русскоязычный комментатор) возникли сомнения в правильности подсчета этого рейтинга, так что там не все так однозначно. Подробности можно посмотреть тут.
Fromych
Там вроде не только у него одного