
Здравствуйте, уважаемые читатели Хабра. Меня зовут Рустем и я главный разработчик в казахстанской ИТ-компании DAR. В этой статье я расскажу, что нужно знать перед тем, как переходить на шаблоны Event Sourcing и CQRS с помощью Akka toolkit.
Примерно с 2015 года мы начали проектировать свою экосистему. После анализа и опираясь на опыт работы со Scala и Akka, решили остановиться на Akka toolkit. У нас были и удачные реализации шаблонов Event Sourcing c CQRS и не очень. Накопилась экспертиза в этой области, которой я хочу поделиться с читателями. Мы рассмотрим, как Akka реализует эти паттерны, а также какие инструменты доступны и поговорим о подводных камнях Akka. Надеюсь, что после прочтения этой статьи, у вас будет больше понимания рисков перехода на Akka toolkit.
На темы CQRS и Event Sourcing было написано много статей на Хабре и на других ресурсах. Данная статья предназначена для читателей, которые уже понимают, что такое CQRS и Event Sourcing. В статье я хочу сконцентрироваться на Аkka.
Domain-Driven Design
Про Domain-Driven Design (DDD) писали много материалов. Есть как противники, так и сторонники такого подхода. От себя хочу добавить, что если вы решили перейти на Event Sourcing и CQRS, то будет не лишним изучить DDD. К тому же, философия DDD чувствуется во всех инструментах Аkkа.
На самом деле, Event Sourcing и CQRS — это только маленькая часть большой картины под названием Domain-Driven Design. При проектировании и разработке, у вас могут возникнуть много вопросов о том, как правильно реализовать эти шаблоны и интегрировать в экосистему, а знание DDD облегчить вам жизнь.
В данной статье, термин сущность (entity по DDD), будет обозначать Persistence Actor который имеет уникальный идентификатор.
Почему Scala?
У нас часто спрашивают, почему Scala, а не Java. Одна из причин — это Akka. Сам фреймворк, написан на языке Scala c поддержкой языка Java. Здесь нужно сказать, что так же есть реализация на .NET, но это уже другая тема. Чтобы не вызывать дискуссию, я не буду писать, чем Scala лучше или хуже, чем Java. Я лишь рассказу пару примеров, которые, по-моему мнению, у Scala есть преимущество перед Java при работе с Akka:
- Неизменяемые объекты. В Java нужно писать неизменяемые объекты самому. Поверьте, это не легко и не совсем удобно постоянно писать финальные параметры. В Scala
case classуже неизменяемый со встроенной функциейcopy - Стиль написания кода. При реализации на Java, вы все равно будете писать в стиле Scala, то есть, функционально.
Вот пример реализации actor на Scala и Java:
Scala:
object DemoActor {
def props(magicNumber: Int): Props = Props(new DemoActor(magicNumber))
}
class DemoActor(magicNumber: Int) extends Actor {
def receive = {
case x: Int => sender() ! (x + magicNumber)
}
}
class SomeOtherActor extends Actor {
context.actorOf(DemoActor.props(42), "demo")
// ...
}Java:
static class DemoActor extends AbstractActor {
static Props props(Integer magicNumber) {
return Props.create(DemoActor.class, () -> new DemoActor(magicNumber));
}
private final Integer magicNumber;
public DemoActor(Integer magicNumber) {
this.magicNumber = magicNumber;
}
@Override
public Receive createReceive() {
return receiveBuilder()
.match(
Integer.class,
i -> {
getSender().tell(i + magicNumber, getSelf());
})
.build();
}
}
static class SomeOtherActor extends AbstractActor {
ActorRef demoActor = getContext().actorOf(DemoActor.props(42), "demo");
// ...
}(Пример взят с отсюда)
Обратите внимание на реализацию метода createReceive() на примере языка Java. Внутри, через фабрику ReceiveBuilder, реализуется pattern-matching. receiveBuilder() — метод от Akka для поддержки лямбда-выражений, а именно pattern-matching в Java. В Scala это реализуется нативно. Согласитесь, код в Scala короче и легче читаем.
- Документация и примеры. Несмотря на то, что в официальной документации есть примеры на Java, на просторах интернета почти все примеры на Scala. Так же, вам будет легче ориентироваться в исходниках библиотеки Akka.
По части производительности, разницы между Scala и Java не будет, так как все крутится в JVM.
Хранилище
До реализации Event Sourcing с помощью Akka Persistence, рекомендую заранее выбрать базу для постоянного хранения данных. Выбор базы зависит от требований к системе, от ваших желаний и предпочтений. Данные можно хранить как в NoSQL и RDBMS, так и в файловой системе, например LevelDB от Google.
Важно отметить, что Akka Persistence не отвечает за запись и чтение данных из базы, а делает это через плагин, который должен реализовать Akka Persistence API.
После выбора инструмента для хранения данных, нужно выбрать плагин из списка, либо написать его самому. Второй вариант я не рекомендую, зачем изобретать велосипед.
Для постоянного хранения данных, мы решили остановиться на Cassandra. Дело в том, что нам нужна была надежная, быстрая и распределенная база. К тому же, Typesafe сами сопровождают плагин, который полностью реализует Akka Persistence API. Он постоянно обновляется и в сравнение с другими, у плагина Cassandra написана более полная документация.
Стоит оговориться, что у плагина также есть несколько проблем. Например, все еще нет стабильной версии (на момент написания этой статьи, последняя версия 0.97). Для нас самой большой неприятностью, с которой мы встретились при использовании данного плагина, была потеря событий при считывании Persistent Query для некоторых сущностей. Для полной картины, ниже приведена схема CQRS:
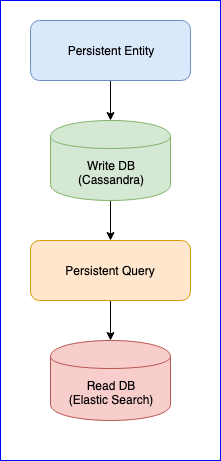
Persistent Entity распределяет события сущностей на тэги по алгоритму consistent hash (например на 10 шардов):
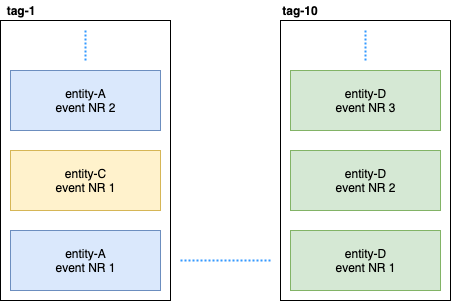
Затем, Persistent Query подписывается на эти тэги и запускает поток, который складывает данные в Elastic Search. Так как Cassandra в кластере, события будут разбросаны по нодам. Некоторые ноды могут проседать и будут отвечать медленнее остальных. Нет гарантии, что вы получите события в строгом порядке. Для решения этой проблемы, плагин реализован так, что если он получит неупорядоченное событие, например entity-A event NR 2, то он определенное время ждет первоначальное событие и если его не получит, то просто проигнорирует все события данной сущности. Даже по этому поводу были дискуссии в Gitter. Если кому интересно, можно прочитать переписку между @kotdv и разработчиками плагина: Gitter
Как можно решить это недоразумение:
- Нужно обновить плагин до последней версии. В последних версиях разработчики Typesafe решили много проблем, связанных с Eventual Consistency. Но, мы все еще ждем стабильной версии
- Были добавлены более точные настройки компонента, который отвечает за получение событий. Можно попробовать увеличить время ожидания неупорядоченных событий для более надежной работы плагина: c
assandra-query-journal.events-by-tag.eventual-consistency.delay=10s - Настроить Cassandra согласно рекомендациям DataStax. Поставить garbage collector G1 и выделить как можно больше памяти для Cassandra.
В конце концов, проблему с недостающими событиями мы решили, но теперь есть стабильная задержка данных на стороне Persistence Query (от пяти до десяти секунд). Было решено оставить подход для данных, которые используются для аналитики, а там, где важна скорость, мы вручную публикуем события на шину. Главное выбрать подходящий механизм обработки или публикации данных: at-least-once или at-most-once. Хорошее описание от Akka можно почитать здесь. Для нас было важно соблюдать консистенцию данных и поэтому, после успешной записи данных в базу, мы ввели переходное состояние, которое контролирует успешную публикацию данных в шине. Ниже приведен пример кода:
object SomeEntity {
sealed trait Event {
def uuid: String
}
/**
* Событие, которое отправляется на сохранение.
*/
case class DidSomething(uuid: String) extends Event
/**
* Индикатор, который указывает что последнее событие было опубликовано.
*/
case class LastEventPublished(uuid: String) extends Event
/**
* Контейнер, который хранит текущее состояние сущности.
* @param unpublishedEvents – хранит события, которые не опубликовались.
*/
case class State(unpublishedEvents: Seq[Event])
object State {
def updated(event: Event): State = event match {
case evt: DidSomething =>
copy(
unpublishedEvents = unpublishedEvents :+ evt
)
case evt: LastEventPublished =>
copy(
unpublishedEvents = unpublishedEvents.filter(_.uuid != evt.uuid)
)
}
}
}
class SomeEntity extends PersistentActor {
…
persist(newEvent) { evt =>
updateState(evt)
publishToEventBus(evt)
}
…
}Если по каким-либо причинам не удалось опубликовать событие, то при следующем старте SomeEntity, он будет знать, что событие DidSomething не дошел до шины и повторит попытку повторно опубликовать данные.
Сериализатор
Сериализация — это не менее важный пункт в использовании Akka. У него есть внутренний модуль — Akka Serialization. Этот модуль используется для сериализации сообщений при обмене ими между актерами и при хранении их через Persistence API. По умолчанию используется Java serializer, но рекомендуется использовать другой. Проблема в том, что Java Serializer медленный и занимает много места. Есть два популярных решения- это JSON и Protobuf. JSON, хоть и медленный, но его проще реализовать и поддерживать. Если нужно минимизировать расходы на сериализацию и хранение данных, то можно остановиться на Protobuf, но тогда процесс разработки пойдет медленнее. Помимо Domain Model, придется писать еще Data Model. Не стоит забывать про версионность данных. Будьте готовы постоянно писать маппинг между Domain Model и Data Model.
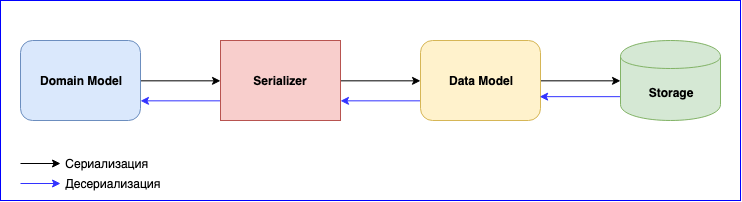
Добавили новое событие — пишите маппинг. Изменили структуру данных — пишите новую версию Data Model и измените функцию маппинга. Не забывайте еще про тесты для сериализаторов. В общем, работы будет не мало, но в итоге получите слабосвязанные компоненты.
Выводы
- Тщательно изучите и выберите подходящую для себя базу и плагин. Рекомендую выбирать плагин, который хорошо сопровождается и не остановится в разработке. Область относительно новая, есть еще куча недоработок, которые только предстоит решить
- Если выберите распределенное хранилище, то придется решать проблему с задержкой до 10 секунд самому, либо смириться с этим
- Сложность сериализации. Вы можете пожертвовать скоростью и остановиться на JSON, либо выбрать Protobuf и писать множество адаптеров и поддерживать их.
- Есть и плюсы этого шаблона, это слабо связанные компоненты и независимые команды разработчиков, которые строят одну большую систему.
vba
Будьте так любезны, ссылочку на оригинал. Спасибо
rustem_sagimbekov Автор
Данная статья не является переводом и основана на моем личном опыте.
vba
Вас понял, спасибо