

Какое-то время назад, приключилась со мной неприятная история, которая послужила триггером для небольшого проекта на гитхабе и вылилась в эту статью.
Обычный день, обычный релиз: все задачи вдоль и поперек проверены нашим QA-инженером, поэтому со спокойствием священной коровы «закатываем» на stage. Приложение ведет себя хорошо, в логах — тишина. Принимаем решение делать switch (stage <-> prod). Переключаем, смотрим на приборы…
Проходит пару минут, полет стабильный. QA-инженер делает smoke-тест, замечает, что приложение как-то неестественно подтормаживает. Списываем на прогрев кешей.
Проходит еще пару минут, первая жалоба из первой линии: у клиентов очень долго загружаются данные, приложение тормозит, долго отвечает и т.д. Начинаем беспокоиться… смотрим логи, ищем возможные причины.
Проходит еще пару минут, прилетает письмо от DB-админов. Пишут, что время выполнения запросов к базе данных (далее БД) пробило все возможные границы и стремится в бесконечность.
Открываю мониторинг (использую JavaMelody), нахожу эти запросы. Запускаю PGAdmin, воспроизвожу. Действительно долго. Добавляю «explain», смотрю execution plan… так и есть, мы забыли про индексы.
Почему code review недостаточно?
Тот случай меня многому научил. Да, я «потушил пожар» в течение часа, создав прямо на проде нужный индекс как-то так (не забывайте про опцию CONCURRENTLY):
CREATE INDEX CONCURRENTLY IF NOT EXISTS ix_pets_name
ON pets_table (name_column);Согласитесь, это было равносильно деплою с downtime. Для приложения, над которым работаю, это недопустимо.
Я сделал выводы и добавил в checklist для code review специальный жирный пункт: если я вижу, что в процессе разработки был добавлен/изменен один из классов Repository — проверяю sql-миграции на наличие там скрипта, создающего, изменяющего индекс. Если его там нет, пишу автору вопрос: уверен ли он, что здесь не нужен индекс?
Вполне вероятно, что индекс не нужен, если данных немного, но если мы работаем с таблицей, в которой количество строк считаются в миллионах, ошибка индекса может стать фатальной и привести к истории, изложенной в начале статьи.
В таком случае, я прошу автора pull request (далее PR) на 100% убедиться, что запрос, который он написал на HQL, хотябы частично покрывается индексом (используется Index Scan). Для этого разработчик:
- запускает приложение
- ищет преобразованный (HQL -> SQL) запрос в логах
- открывает PGAdmin или другой инструмент администрирования БД
- генерирует в локальной БД, чтобы никому не мешать своими экспериментами, приемлемое для тестов количество данных (минимум 10К — 20К записей)
- выполняет запрос
- запрашивает execution plan
- внимательно изучает его и делает соответствующие выводы
- добавляет/изменяет индекс, добиваясь, чтобы план выполнения его устраивал
- отписывается в PR, что покрытие запроса проверил
- экспертно оценивая риски и серьезность запроса, я могу перепроверить его действия
Очень много рутинных действий и человеческого фактора, но какое-то время меня устраивало, и я с этим жил.
По дороге домой
Говорят, очень полезно хотя бы иногда ходить с работы, не слушая музыку/подкасты по пути. В это время, просто подумав о жизни, можно прийти к интересным умозаключениям и идеям.
В один из дней я шел домой и думал о том, что было в тот день. Было несколько review, каждый я сверял с чеклистом и проделывал ряд действий, описанных выше. Я так утомился в тот раз, что подумал, какого черта? Разве нельзя это сделать автоматически?.. я ускорил шаг, желая поскорее «запилить» эту идею.
Постановка задачи
Что же самое важное для разработчика в execution plan?
Конечно, seq scan на больших объемах данных, вызванный отсутствием индекса.
Таким образом, нужно было сделать тест, который:
- Выполняется на БД с конфигурацией, аналогичной продовской
- Перехватывает запрос к БД, производимый JPA репозиторием (Hibernate)
- Получает его Execution Plan
- Парсит Execution Plan, раскладывая его в удобную для проверок структуру данных
- Используя удобный набор Assert методов, проверяет ожидания. Например, что не используется seq scan.
Нужно было скорее проверить эту гипотезу, сделав прототип.
Архитектура решения
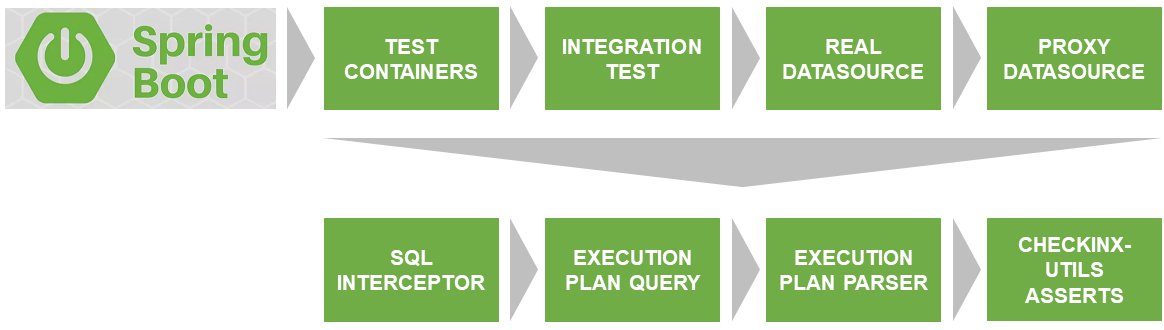
Первая проблема, которую предстояло решить — запуск теста на реальной БД, совпадающей по версии и настройкам с той, которая используется на проде.
Спасибо Docker & TestContainers, они решают эту проблему.
SqlInterceptor, ExecutionPlanQuery, ExecutionPlanParse и AssertService — это интерфейсы, которые в настоящее время я реализовал для Postgres. В планах — реализовать для других БД. Если есть желание поучаствовать — welcome. Код написан на Kotlin.
Все это вместе я разместил на GitHub и назвал checkinx-utils. Вам это повторять не нужно, достаточно подключить dependency на checkinx в maven/gradle и пользоваться удобными asserts. Как это сделать, подробнее опишу далее.
Описание взаимодействия компонентов CheckInx
ProxyDataSource
Первую проблему, которую предстояло решить — перехват готовых к выполнению запросов к БД. Уже с установленными параметрами, без вопросиков и т.д.
Для этого реальный dataSource нужно обернуть в некий Proxy, который позволял бы встроиться в конвейер выполнения запросов и, соответственно, перехватить их.
Такие ProxyDataSource уже реализовывали многие. Я воспользовался готовым решением ttddyy, который позволяет установить свой Listener перехватывающий нужный мне запрос.
Исходный DataSource подменяю, используя класс DataSourceWrapper (BeanPostProcessor).
SqlInterceptor
По сути его метод start() устанавливает в proxyDataSource свой Listener и начинает перехват запросов, сохраняя их во внутреннем списке statements. Метод stop(), соответственно, удаляет установленный Listener.
ExecutionPlanQuery
Здесь исходный запрос трансформируется в запрос на получение execution plan. В случае с Postgres это добавление к запросу ключевого слова «EXPLAIN».
Далее, этот запрос исполняется на той же БД из testcontainders и возвращается «сырой» execution plan (список строк).
ExecutionPlanParser
C «сырым» планом выполнения работать неудобно. Поэтому, я его парсю в дерево состоящее из нод (PlanNode).
Разберем поля PlanNode на примере реального ExecutionPlan:
Index Scan using ix_pets_age on pets (cost=0.29..8.77 rows=1 width=36)
Index Cond: (age < 10)
Filter: ((name)::text = 'Jack'::text)| Свойство | Пример | Описание |
|---|---|---|
| raw: String | Index Scan using ix_pets_age on pets (cost=0.29..8.77 rows=1 width=36) | исходная строка |
| table: String? | pets |
название таблицы |
| target: String? | ix_pets_age | название индекса |
| coverage: String? | Index Scan | покрытие |
| coverageLevel | HALF | абстракция над покрытием (ZERO, HALF, FULL) |
| children: MutableList<PlanNode> | - | дочерние ноды |
| properties: MutableList<Pair<String, String>> | key: Index Cond, value: (age < 10); key: Filter, value: ((name)::text = 'Jack'::text) |
свойства |
| others: MutableList<String> | - | Все что не удалось распознать в текущей версии checkinx |
AssertService
Со структурой данных возвращаемой парсером уже можно нормально работать. CheckInxAssertService представляет собой набор проверок дерева PlanNode описанного выше. Он позволяет задавать собственные лямбды проверок или использовать предзаданные, с мой точки зрения, наиболее востребованные. Например, чтобы в вашем запросе не было Seq Scan, либо вы хотите убедится, что используется / не используется конкретный индекс.
CoverageLevel
Очень важный Enum, опишу его отдельно:
| Значение | Описание |
|---|---|
| NOT_USING |
проверяет что конкретный target (индекс) не используется |
| ZERO |
индекс не используется (Seq Scan) |
| HALF |
частичное покрытие запроса индексом (Index Scan). Например, поиск осуществляется по индексу, но за результирующими данными обращается к таблице |
| FULL |
полное покрытие запроса индексом (Index Only Scan) |
| UNKNOWN |
неизвестное покрытие. По какой-то причине не удалось его установить |
Далее разберем несколько примеров использования.
Примеры тестов с использованием CheckInx
Я сделал отдельный проект на GitHub checkinx-demo, где реализовал JPA repository к таблице pets и тесты к этому репозиторию проверяющие покрытие, индексы и т.д. Полезно будет туда глянуть в качестве отправной точки.
У вас может быть такой тест:
@Test
fun testFindByLocation() {
// ARRANGE
val location = "Moscow"
// Генерируем тестовые данные, их должно быть достаточно много 10К-20К.
// Лучше использовать TestNG и вынести этот код в @BeforeClass
IntRange(1, 10000).forEach {
val pet = Pet()
pet.id = UUID.randomUUID()
pet.age = it
pet.location = "Saint Petersburg"
pet.name = "Jack-$it"
repository.save(pet)
}
// ACT
// Начинаем перехват запросов
sqlInterceptor.startInterception()
// Тестируемый метод
val pets = repository.findByLocation(location)
// Заканчиваем перехват
sqlInterceptor.stopInterception()
// ASSERT
// Здесь можно проверить сколько запросов было исполнено
assertEquals(1, sqlInterceptor.statements.size.toLong())
// Убеждаемся, что используется индекс ix_pets_location с частичным покрытием (Index Scan)
checkInxAssertService.assertCoverage(CoverageLevel.HALF, "ix_pets_location", sqlInterceptor.statements[0])
// Если нам все равно какой индекс будет использоваться, но важно чтобы не было Seq Scan, мы можем проверить минимальный уровень покрытия
checkInxAssertService.assertCoverage(CoverageLevel.HALF, sqlInterceptor.statements[0])
// ... тоже самое, но используя свою лямбду
checkInxAssertService.assertPlan(plan) {
it.coverageLevel.level < CoverageLevel.FULL.level
}
}План выполнения мог быть следующим:
Index Scan using ix_pets_location on pets pet0_ (cost=0.29..4.30 rows=1 width=46)
Index Cond: ((location)::text = 'Moscow'::text)… или вот таким, если мы забыли бы про индекс (тесты покраснеют):
Seq Scan on pets pet0_ (cost=0.00..19.00 rows=4 width=84)
Filter: ((location)::text = 'Moscow'::text)В своем проекте, я больше всего использую самый простой assert, говорящий о том, что в плане выполнения отсутствует Seq Scan:
checkInxAssertService.assertCoverage(CoverageLevel.HALF, sqlInterceptor.statements[0])Наличие такого теста говорит о том, что я, как минимум, изучил план выполнения.
Также это делает ведение проекта более явным, а документируемость и предсказуемость кода увеличивается.
@Test
fun testFindByLocation() {
// ARRANGE
val location = "Moscow"
// ACT
// Начинаем перехват запросов
sqlInterceptor.startInterception()
// Тестируемый метод
val pets = repository.findByLocation(location)
// Заканчиваем перехват
sqlInterceptor.stopInterception()
// ASSERT
// Получаем "сырой" план выполнения
val executionPlan = executionPlanQuery.execute(sqlInterceptor.statements[0])
// Получаем распарсенный план - дерево
val plan = executionPlanParser.parse(executionPlan)
assertNotNull(plan)
// ... сами делаем обход
val rootNode = plan.rootPlanNode
assertEquals("Index Scan", rootNode.coverage)
assertEquals("ix_pets_location", rootNode.target)
assertEquals("pets pet0_", rootNode.table)
}Подключение к проекту
В своем проекте я выделил такие тесты в отдельную группу, назвав ее Intensive Integration Tests.
Подключить и начать использовать checkinx-utils достаточно легко. Начнем с build скрипта.
Вначале подключите репозиторий. Когда-нибудь я загружу checkinx в maven, но сейчас выкачать artifact можно только с GitHub через jitpack.
repositories {
// ...
maven { url 'https://jitpack.io' }
}Далее, добавляем зависимость:
dependencies {
// ...
implementation 'com.github.dsemyriazhko:checkinx-utils:0.2.0'
}Завершаем подключение добавлением конфигурации. Сейчас поддерживается только Postgres.
@Profile("test")
@ImportAutoConfiguration(classes = [PostgresConfig::class])
@Configuration
open class CheckInxConfigОбратите внимание на профиль test. Иначе вы обнаружите ProxyDataSource у себя в проде.
PostgresConfig подключает несколько бинов:
- DataSourceWrapper
- PostgresInterceptor
- PostgresExecutionPlanParser
- PostgresExecutionPlanQuery
- CheckInxAssertServiceImpl
Если вам нужна какая-то кастомизация, которую не предоставляет текущий API, вы всегда можете подменить один из bean своей реализацией.
Известные проблемы
Иногда у DataSourceWrapper не получается подменить исходный dataSource из-за Spring CGLIB proxy. В BeanPostProcessor в таком случае приходит не DataSource, а ScopedProxyFactoryBean и возникают проблемы с проверкой типов.
Самым простым решением будет создать для тестов HikariDataSource вручную. Тогда ваша конфигурация будет следующей:
@Profile("test")
@ImportAutoConfiguration(classes = [PostgresConfig::class])
@Configuration
open class CheckInxConfig {
@Primary
@Bean
@ConfigurationProperties("spring.datasource")
open fun dataSource(): DataSource {
return DataSourceBuilder.create()
.type(HikariDataSource::class.<i>java</i>)
.build()
}
@Bean
@ConfigurationProperties("spring.datasource.configuration")
open fun dataSource(properties: DataSourceProperties): HikariDataSource {
return properties.initializeDataSourceBuilder()
.type(HikariDataSource::class.<i>java</i>)
.build()
}
}Планы по развитию
- Хотелось бы понять, нужно ли это кому-то кроме меня? Для этого, создам опрос. Буду рад честному ответу.
- Посмотреть, что реально нужно и расширить стандартный список assert методов.
- Написать реализации для других БД.
- Конструкция sqlInterceptor.statements[0] выглядит не очень очевидной, хочется улучшить.
Буду рад, если кто-нибудь захочет присоединиться и законтрибьютить, поупражнявшись в Kotlin.
Заключение
Уверен, что будут комментарии: невозможно предсказать как планировщик запроса поведет себя на проде, все зависит от собранной статистики.
Действительно, планировщик. воспользовавшись собранной ранее статистикой, может построить отличный от тестируемого план. Смысл немного в другом.
Задача планировщика улучшить, а не ухудшить запрос. Поэтому, без ЯВНОЙ причины, он не станет вдруг использовать Seq Scan, а вот вы неосознанно можете.
CheckInx вам нужен, чтобы написав тест, не забыть про изучение плана выполнения запроса и рассмотреть возможность создания индекса, либо наоборот, тестом явно показать, что никакие индексы здесь не нужны и вас устраивает Seq Scan. Это избавило бы вас от лишних вопросов на code review.
Ссылки
Комментарии (25)

BlessYourHeart
30.05.2019 05:42ищет преобразованный (HQL -> SQL) запрос в логах
Неужели HQL настолько проще (поддерживать/управлять) чем SQL, что лучше выучить HQL и героически побеждять всю эту HQL -> SQL и писать отдельные модули для проверки и потом модули для проверки проверок…VolCh
30.05.2019 06:16Он и подобные QL не то, что проще или сложнее — они, при внешней схожести на SQL, другие семантически: они, по сути, работают не со строками таблиц, а с хранилищами объектов. Ну и в среднестатистических проектах вообще редко используются напрямую, просто внутренняя деталь реализации ORM.
dsemyriazhko Автор
30.05.2019 09:59Все верно, но даже с nativeQuery бывает непросто воспроизвести все параметры и т.д. С конкретным тестом все становится проще.
mad_nazgul
30.05.2019 12:44spring data jpa.
Программист напишет в data jpa repository что то типа findByNameAndAge, а потом это «превратиться» в запрос.
Ну а если использовать Spring Data Jpa, там и до Query не далеко.
И только самые стойкие доходят до @ Query(nativeQuery=true)
VolCh
30.05.2019 06:18Интересный подход. А о более низком уровне не думали? Чтоб не зависеть от основного языка проекта?
dsemyriazhko Автор
30.05.2019 09:44До текущего момента не думал), я ведь этим решал свою проблему. Нужно подумать, но кроме портации, например, на .net ничего в голову не приходит.

IvanVakhrushev
30.05.2019 11:06+2Чтобы это действительно работало и имело смысл, вам для тестирования нужна копия\обезличенная копия production базы. Распределение данных и статистика имеют здесь ключевое значение.
Анализировать производительность и план исполнения запросов на вручную сгенерированной БД — это лукавство, которое в один прекрасный момент выйдет вам боком.dsemyriazhko Автор
30.05.2019 11:52в целом ничего не мешает поднять копию продакшин БД и прогонять эти тесты на ней. Результаты, конечно, точнее будут.
но даже в таком виде какие то явные косяки (например, забыл что-то) мне помогло устранить.sshikov
30.05.2019 20:28Это вам может и не мешает. А мне допустим никто не даст скопировать прод базу, не говоря уже о том, что никто не выделит столько терабайт места для данных. Так что планы вполне могут измениться радикально, потому что размеры мягко говоря разные.
И кстати… не совсем понял, что у вас за база (видимо PostgreSQL), но скажем в оракле есть очевидные случаи, когда создание лишнего индекса не того типа как раз тормозит запросы на пару-тройку порядков.
dsemyriazhko Автор
30.05.2019 18:56Если я, например, добиваюсь идеального плана выполнения в тесте, например на 10К-20К записей. Потом на проде планировщик за счет статистики, по моему опыту, может сделать запрос только лучше, но я не припомню, чтобы он его прибил в ноль.
Например, если планировщик увидит, что в результате фильтрации позвращается больше определенного процента записей, он может посчитать, что использовать seq scan оправданно. При этом время запроса только улучшится (в большенстве случаев).
Мне же как разработчику важно изначально «подстелить соломку» и провести некую работу над запросом, убедившись, что планировщик вообще в состоянии его выполнить оптимально.
Может я, конечно, не встречался еще с такими кейсами. Буду рад примеру.
angel_zar
30.05.2019 12:34А так ли нужно на каждый чих создавать индекс?
Следующая проблема медленные DML и тут нужно будет искать не используемые индексы.dsemyriazhko Автор
30.05.2019 12:57100% на каждый чих этого делать не нужно. В разработке вообще все нужно делать осознанно, такая у нас профессия). Но я бы проверял все «чихи» (изменение запроса, добавление нового), если в таблице записи исчисляются в миллионах.
mayorovp
30.05.2019 14:21Всё-таки лучше создать лишний индекс чем не создать нужного.
Когда в таблице десяток индексов, очередной индекс замедлит DML всего на 10%, а вот отсутствие нужного индекса способно замедлить выборку в пару миллионов раз...

valery1707
30.05.2019 14:34Лишний индекс будет тормозить
INSERT/UPDATEникак не участвуя вSELECT.
Сильно ли это лучше чем отсутствие индекса — по мне так тоже зависит от ситуации.mayorovp
30.05.2019 17:10К ситуации вида "Проходит еще пару минут, прилетает письмо от DB-админов. Пишут, что время выполнения запросов к базе данных (далее БД) пробило все возможные границы и стремится в бесконечность" легко прийти пропустив всего один важный индекс, но её тяжело достичь добавлением ненужного индекса. Нужна целая куча ненужных индексов, чтобы начались заметные лаги.
sshikov
30.05.2019 20:30Берете оракл. Создаете реверсивный индекс. Пишете запрос с between, имеете тормоза, примерно эквивалентные фулл скану. На SELECT, ясное дело.
valery1707
31.05.2019 12:17В вашем варианте новый индекс, как я понимаю, используется в запросе — потому он его и тормозит.
Я же говорил про случай когда индекс вообще в запросе не участвует и я не знаю БД в которой такой индекс бы мешалSELECT-ам.
Но вообще я отвечал на другой комментарий в котором говорили что "лучше создать лишний индекс чем не создать нужный" и я отвечал в контексте того что "лишний индекс тоже мешать будет".sshikov
31.05.2019 12:31Ну, я просто привел пример, что индекс (лишний) вполне может мешать селектам. Используется ли он в запросе? Конечно да, но проблема в том, что для автора запроса это может быть не вполне очевидно.
Ну и да, ради объективности, реверсивные индексы — они все-таки не совсем «стандартные», и в какой-то степени настроены на то, чтобы оптимизировать как раз вставки — и частично именно поэтому влияют и на селект.

fuggy
30.05.2019 22:20К чему устраивать парсинг explain, если он может отдавать через EXPLAIN (FORMAT XML/JSON/YAML) в нужном формате на выбор.
Я думаю что, если запросы требуют быстрого ответа для пользователя, то лучше ориентироваться не на наличие или отсутствие Seq Scan, а оценивать Total Cost по какому-то порогу. К тому же есть определённый класс запросов для которых выборка через Seq Scan будет быстрее, чем использовать Index Scan.dsemyriazhko Автор
30.05.2019 22:27Парсинг все равно нужен, чтобы разложить в объектную модель и дальше удобно с ней работать, делая проверки.
Вы правы, распарсить JSON намного проще, чем TEXT)). Я как-то это упустил. Спасибо за подсказку! Добавлю в план написать другую реализацию query & parser.
vpasechnik
31.05.2019 13:30В Oracle DB можно экспортнуть статистику с прода, и импортнуть локально (не уверен можно ли так сделать в Postgres). После чего можно просто проверять косты запросов обычным трешхолдом. (например тест зеленый если кост меньше 100).
Иногда full table access (seq scan) не является самым плохим вариантом плана.
krupt
31.05.2019 14:48Спасибо за статью и библиотеку, но есть предложение. Не хочется при assert завязываться на имя индекса — лучше завязаться на поля таблиц, которые используются в запросе и проверять наличие этих полей в используемом индексе. Типо, assertIsColumnExistsInIndexIntoExecutionPlan :-)
pserega
31.05.2019 15:34-1Если используете JPA репозиторием (Hibernate), за чем перехватчики запросов использовать и думать, какая база используется.
public class QueryUtils<T> { private static final Logger log = LoggerFactory.getLogger(QueryUtils.class); @Autowired EntityManagerFactory entityManagerFactory; @Autowired EntityManager em; private final Class<T> type; public QueryUtils() { this.type = (Class<T>) ((ParameterizedType) getClass().getGenericSuperclass()).getActualTypeArguments()[0]; } public String getQueryString(Filter<T> filter) { CriteriaBuilder builder = em.getCriteriaBuilder(); CriteriaQuery<T> query = builder.createQuery(type); Root<T> root = query.from(type); Predicate predicate = filter.toSpecification().toPredicate(root, query, builder); if (predicate != null) { query.where(predicate); } QueryImpl queryI = em.createQuery(query).unwrap(QueryImpl.class); Map<String, TypedValue> paramMap = queryI.getQueryParameters() .getNamedParameters(); log.debug("map param : "+ paramMap); String hql = queryI.getQueryString().replace("fetch",""); QueryTranslatorFactory ast = new ASTQueryTranslatorFactory(); QueryTranslator queryTranslator = ast.createQueryTranslator( hql,hql, Collections.EMPTY_MAP,(SessionFactoryImplementor) entityManagerFactory.unwrap(SessionFactory.class),null); queryTranslator.compile(Collections.EMPTY_MAP, true ); log.debug("Table Sql : "+ queryTranslator.getQuerySpaces()); String nativeSql = queryTranslator.getSQLString(); for (TypedValue value : paramMap.values()) { nativeSql = nativeSql.replaceFirst("\\?", "'"+value.getValue().toString()+"'"); } log.debug("hql : "+ queryTranslator.getQueryString()); log.debug("NativeSql : "+ nativeSql); return nativeSql; } }
Можно получить запрос, не вызывая его.
За статью спасибо.
Peter03
Похоже данный подход не работает с stored procedures или вы их не используете?
dsemyriazhko Автор
Не исключаю, что где то они необходимы, но я успешно избегаю их использование уже на протяжении нескольких лет). На сколько мне известно, EXPLAIN не работает с инструкцией CALL, поэтому текущий ExecutionPlanQuery не сможет получить план.
Я стараюсь всю логику держать в приложении, а БД использовать только в качестве хранилища. Так легче масштабироваться: накидал пару дополнительных нод и готово. С БД все не так просто, реплики и тд гораздо сложнее. Прибегаю к этому в последнюю очередь имхо.