

Знакома ли вам ситуация, когда на выбор фильма вы тратите гигантское количество времени, сопоставимое со временем самого просмотра? Для пользователей онлайн-кинотеатров это частая проблема, а для самих кинотеатров — упущенная прибыль.
К счастью, у нас есть Rekko — система персональных рекомендаций, которая уже год успешно помогает пользователям Okko выбирать фильмы и сериалы из более чем десяти тысяч единиц контента. В статье я расскажу вам как она устроена с алгоритмической и технической точек зрения, как мы подходим к её разработке и как оцениваем результаты. Ну и про сами результаты годового A/B теста тоже расскажу.
Для начала немного истории. Okko начал своё существование в 2011 году как часть Йоты, запустившись под именем Yota Play.
Yota Play был уникальным для своего времени сервисом: он тесно интегрировался с социальными сетями и использовал информацию о просмотренных и оценённых друзьями фильмах во многих частях сервиса, в том числе и в рекомендациях.

В 2012 социальные рекомендации было решено дополнить алгоритмическими. Так появился «Оракул» — первая рекомендательная система онлайн-кинотеатра Okko. Вот несколько выдержек из его дизайн-документа:
Аналогичный подход использован и в реализованной системе персональных рекомендаций. Используется шкала уровней от “ничто” (пустота, отсутствие) до “всё” (полностью, максимально). В диапазоне [127..+127] 0 – является серединой или “нормой”. По такой шкале оценивается и степень симпатии к главному герою и субъективная цена товара и степень “красного” цвета. Например, размер вселенной оценивается значением +127 (по шкале габаритов), а темнота значением — 127 (по шкале интенсивности освещенности).
При выработке рекомендаций, важным является не только предыстория, но и характер конкретного пользователя. Персональный профиль также содержит 4-ре шкалы типов характеров (по К. Леонгарду – демонстративный, педантичный, застревающий, возбудимый).
Физиологические лимиты мозга не зависят от свойств характера человека и от того, насколько он дружелюбен и общителен. По мнению профессора, ограничения существуют в неокортексе, отделе, отвечающем за сознательные мысли и речь. Данное ограничение также учитывается в реализованной системе, особенно при выработке рекомендаций для педантичного типа характера и при формировании выборки подобных пользователей среди социальных связей.

Как вы уже поняли, времена тогда были дикие, физиологические лимиты мозга ничем не ограничивались, а разогнанный неокортекс и сам мог генерировать персональные рекомендации со скоростью света. Поэтому модель было решено сразу же катить в продакшен.
Насколько можно судить из сохранившихся артефактов древней цивилизации, «Оракул» представлял из себя дикую смесь алгоритмов коллаборативной фильтрации, щедро приправленную бизнес-правилами.

К середине 2013 года всех начало понемногу отпускать и было наконец-то решено проверить качество рекомендательной машины. Для этого специально обученный редактор заполнил основные разделы приложения и был запущен A/B тест: половина пользователей видела выдачу алгоритма, половина — выбор редактора.
Это сейчас мы с вами читаем статьи об очередных победах искуственного интеллекта и с ужасом представляем себе день, когда тот лишит нас работы. Тогда, в 2013, ситуация обстояла иначе: человек героически победил машину, создав ещё больше рабочих мест в отделе контента. «Оракул» выключили и больше никогда не включали. Вскоре исчезли и все социальные фишки, а Yota Play превратился в Okko.
Период с 2013 по 2016 год ознаменовался «зимой» искуственного интеллекта и тоталитарным правлением контентного отдела: персональных рекомендаций в сервисе не существовало.
К середине 2017 года стало понятно что так жить дальше нельзя. Успехи Netflix были на слуху у каждого и вся индустрия бурными темпами двигалась в сторону персонализации. Пользователей перестали интересовать «тупые» статичные сервисы, они уже начинали привыкать к «умным» интерфейсам, понимающим их с полуслова и предугадывающим все их желания.
В качестве первой итерации решили проинтегрироваться с двумя крупными российскими поставщиками рекомендаций. Раз в день оба сервиса забирали из Okko необходимые данные, шуршали своими чёрными коробочками на далёких серверах и выгружали результаты.
По итогам полугодового A/B теста никаких статистически значимых отличий в контрольной и тестовых группах выявлено не было.

Как раз к концу этого A/B теста я и пришёл в Okko, чтобы вместе с главой аналитики Михаилом Алексеевым (malekseev) начать делать сервис по-настоящему персональным. Менее чем через год к нам присоединился Данил Казаков (xaph), окончательно сформировав текущую команду.
Общие соображения
Когда перед тобой возникает давно изученная мировым сообществом бизнес-задача, которую, к тому же, необходимо решить быстро, велик соблазн взять первое попавшееся популярное глубокое нейросетевое решение, запихать в него данные лопатой, утрамбовать и выкинуть в прод.

Главное этому соблазну не поддаваться. Задача научного сообщества — добиться максимального скора на протухших и синтетических датасетах — зачастую не совпадает с задачей бизнеса — заработать побольше денег, затратив при этом поменьше ресурсов.

Нет, это не значит что вам не нужны рекуррентные сети и можно загребать миллиарды методом k ближайших соседей. Просто может так оказаться, что на ваших данных классическое матричное разложение позволит зарабатывать дополнительные условные 100 миллионов в год, а рекуррентные сети — 105 миллионов в год. При этом содержание стойки серверов с видеокартами для этих самых сетей обойдётся в 10 миллионов в год и потребует нескольких лишних месяцев на разработку и внедрение, а простая интеграция уже готового матричного разложения в другой раздел сервиса и почтовую рассылку потребует месяца доработок и даст ещё 100 условных миллионов в год.
Поэтому важно начать с основ — проверенных базовых методов — и двигаться в сторону всё более современных подходов, обязательно замеряя и предсказывая, какой эффект каждый новый метод окажет на бизнес, сколько он будет стоить и сколько позволит заработать.
Мерять в Okko умеют отлично. Буквально каждая новая фича, каждое нововведение у нас проходит через A/B тест, рассматривается в разрезе самых разных групп пользователей, эффекты проверяются на статистическую значимость и лишь после этого выносится решение о принятии или отклонении новой функциональности.

Текущий дашборд Rekko, например, сравнивает контрольную и тестовую группу по более чем 50 метрикам, среди которых есть выручка, время пребывания в сервисе, время выбора фильма, количество просмотров по подписке, конверсия в покупку и автопродление и многие другие. И да, мы всё ещё храним небольшую группу пользователей, которые никогда не получали персональные рекомендации (простите).

О рекомендательных системах
Для начала небольшое введение в рекомендательные системы.
Задача рекомендательной системы состоит в том, чтобы для каждого пользователя по его истории взаимодействия с элементами построить отношение порядка на множестве всех элементов. Означает это вот что: какие бы два произвольных элемента мы не взяли, мы всегда сможем сказать, какой из них является более предпочтительным для пользователя, а какой менее.
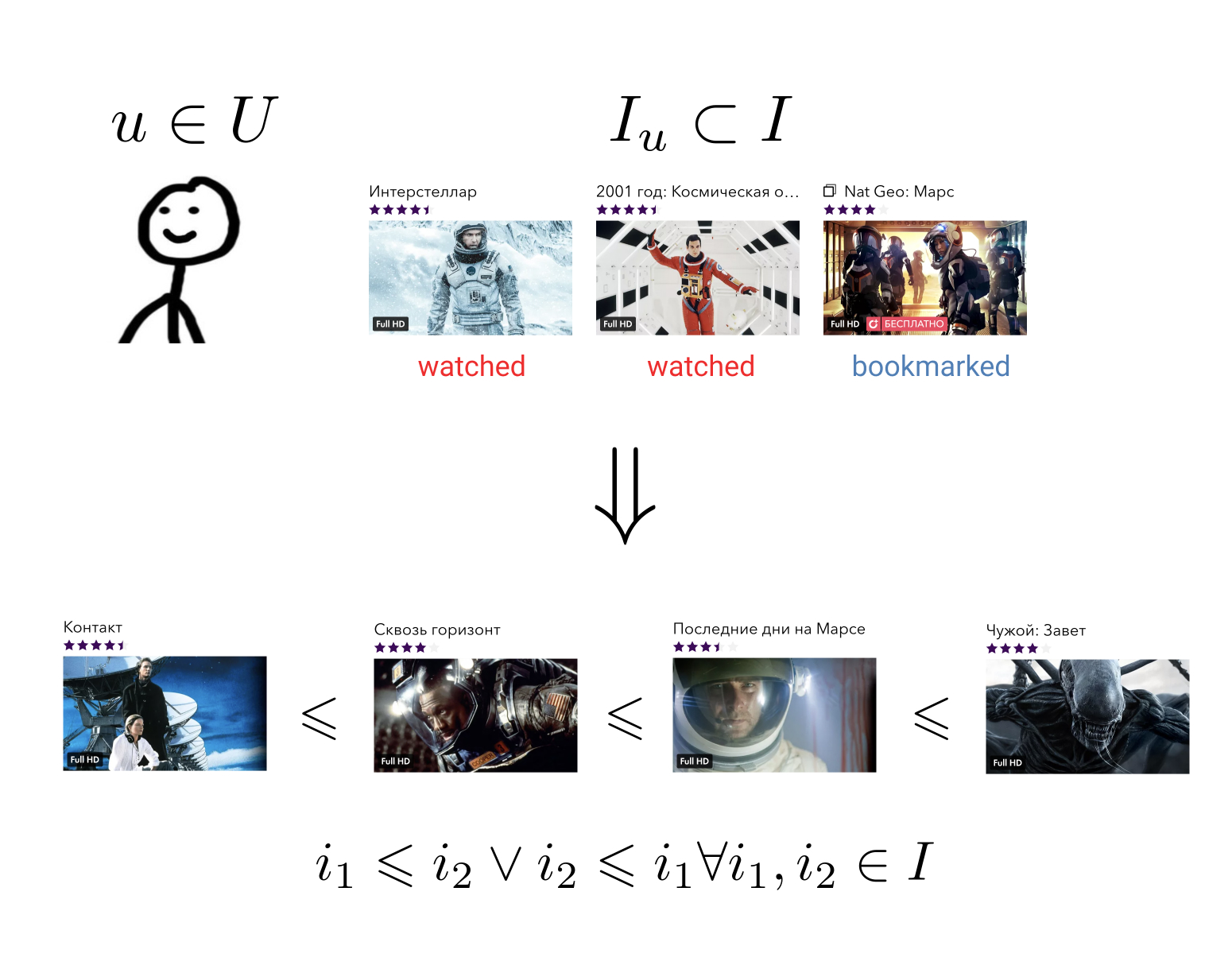
Эту достаточно общую задачу можно свести к более простой: отобразить элементы на множество, на котором уже задано отношение порядка. Например, на множество вещественных чисел. В этом случае необходимо для каждого пользователя и каждого элемента уметь предсказывать некоторую величину — насколько данный пользователь предпочитает данный элемент.

Имея отношение порядка на наших элементах, мы способны решить множество бизнес-задач, например, выбрать из всех элементов N наиболее релевантных для пользователя или отсортировать результаты поиска в соответствии с его предпочтениями.
В идеальном случае нам потребуется целое семейство отношений порядка, зависящих от контекста. Если пользователь зашёл в коллекцию «Боевики», он скорее всего предпочтёт фильм «Разрушитель» фильму «Оскар», но в коллекции «Фильмы с Сильвестром Сталлоне» предпочтение вполне может быть обратным. Аналогичные примеры можно привести для дня недели, времени дня или устройства, с которого пользователь зашёл в сервис.

Традиционно все методы построения персональных рекомендаций делятся на три большие группы: коллаборативная фильтрация (collaborative filtering, CF), контентные модели (content models, CM) и гибридные модели, объединяющие первые два подхода.
Методы коллаборативной фильтрации используют информацию о взаимодействиях всех пользователей и всех элементов. Такая информация, как правило, представляется в виде разреженной матрицы, где строки соответствуют пользователям, столбцы элементам, а на паресечении пользователя и элемента стоит величина, характеризующая взаимодействие между ними, либо пропуск, если этого взаимодействия не было. Задача построения отношения порядка здесь сводится к задаче заполнения пропущенных элементов матрицы.
Эти методы, как правило, просты для понимания и реализации, быстры, но показывают не самый лучший результат.
Контентные модели — произвольные методы машинного обучения для решения задач классификации или регрессии, параметризованные некоторым набором параметров . На вход они принимают признаки пользователя и признаки элемента, а выходом служит степень релевантности данного элемента данному пользователю. Обучаются такие модели не на взаимодействиях всех пользователей и всех элементов, как методы коллаборативной фильтрации, а лишь на отдельных прецедентах.

Такие модели, как правило, гораздо более точны, чем методы коллаборативной фильтрации, но сильно проигрывают им в скорости. Представьте, если у нас есть функция некоторого общего вида, принимающая на вход признаки пользователей и элементов, то её необходимо вызвать для каждой пары . В случае с тысячью пользователей и десятью тысячами элементов это уже миллион вызовов.
Гибридные модели объединяют достоинства обоих подходов, предлагая качественные рекомендации за приемлемое время.
Самый популярный гибридный подход на сегодняшний день представляет из себя двухуровневую архитектуру, где модель коллаборативной фильтрации из всех возможных элементов отбирает небольшое число (100 — 1000) кандидатов, которые затем ранжирует гораздо более мощная контентная модель. Иногда таких ступеней отбора кандидатов может быть несколько и на каждом новом уровне используется всё более сложная модель.

Такая архитектура имеет множество плюсов:
- Коллаборативная и контентная части не связаны между собой и могут обучаться отдельно с разной частотой;
- Качество всегда лучше, чем у коллаборативной модели отдельно;
- Скорость гораздо выше, чем у контентной модели отдельно;
- «Бесплатно» получаем вектора из коллаборативной модели, которые затем можно использовать для решения смежных задач.
Если говорить о конкретных технологиях, то возможных комбинаций здесь очень много.
В качестве коллаборативной части можно брать пользовательские подписки, популярный контент, популярный контент среди друзей пользователя, можно применить матричную или тензорную факторизацию, обучить DSSM или любой другой метод с достаточно быстрым предсказанием.
В качестве контентной модели можно использовать вообще любой подход, от линейной регрессии до глубоких сеток.
Мы в Okko в данный момент остановились на комбинации матричной факторизации с WARP loss и градиентного бустинга над деревьями, о чём я сейчас подробно и расскажу.
Первый этап: отбор кандидатов
Думаю не совру, если скажу, что алгоритмы матричной факторизации являются на сегодняшний день самыми популярными методами коллаборативной фильтрации. Суть метода понятна из названия: мы пытаемся представить уже упоминавшуюся матрицу взаимодействий пользователя с контентом произведением двух матриц меньшего ранга, одна из которых будет представлять собой «матрицу пользователей», а другая — «матрицу элементов». Имея такое разложение мы сможем восстановить исходную матрицу вместе со всеми пропущенными значениями.

При этом, естественно, мы свободны в выборе критерия схожести имеющейся и восстанавливаемой матриц. Самый простой критерий — среднеквадратическое отклонение.
Пусть — строка матрицы пользователей, соответствующая пользователю , а — столбец матрицы элементов, соответствующий элементу . Тогда при перемножении матриц их произведение будет означать величину предполагаемого взаимодействия между данным пользователем и элементом. Посчитав теперь среднеквадратическое отклонение между этой величиной и априорно известным значением взаимодействия для всех пар взаимодействовавших пользователей и элементов , получим функцию потерь, которую можно минимизировать.
Как правило, к ней ещё добавляют регуляризацию.
Такая задача не выпукла и NP-сложна. Однако легко заметить, что при фиксировании одной из матриц задача превращается в линейную регрессию относительно второй матрицы, а значит, мы можем искать решение итеративно, попеременно замораживая то матрицу пользователей, то матрицу элементов. Такой подход называется Alternating Least Squares (ALS).

Главный плюс ALS — скорость и возможность лёгкого распараллеливания. За это его так любят в Яндекс.Дзене и Вконтакте, где и пользователи и элементы исчисляются десятками миллионов.
Однако если мы говорим об объёме данных, помещающимся на одной машине, ALS не выдерживает никакой критики. Главная его проблема — он оптимизирует не ту функцию потерь. Вспомните формулировку задачи построения рекомендательной системы. Мы хотим получить отношение порядка на множестве, а вместо этого оптимизируем среднеквадратическое отклонение.
Легко привести пример матрицы, для которой среднеквадратическое отклонение будет минимальным, но порядок элементов при этом безнадёжно разрушен.
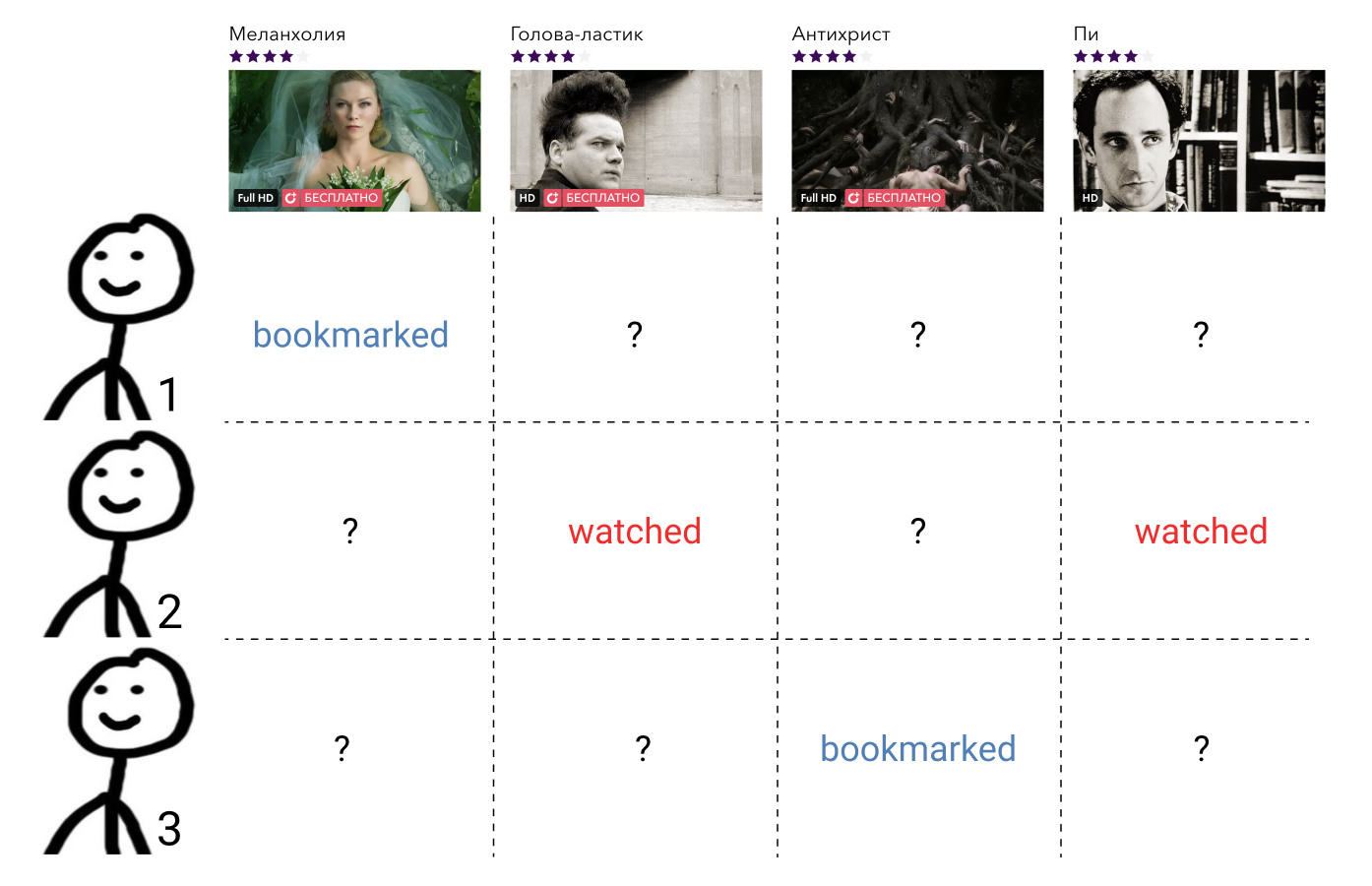
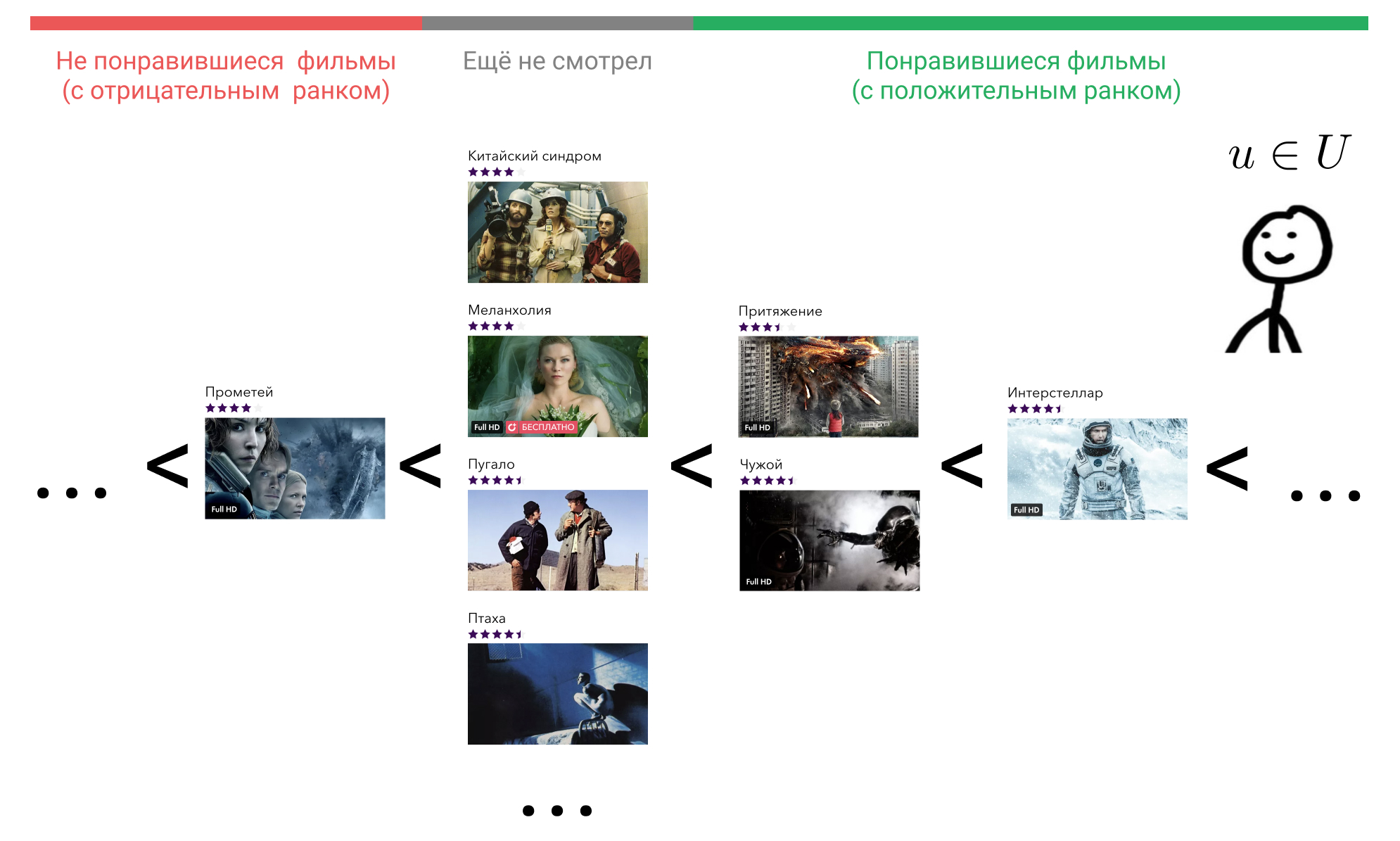
Давайте посмотрим, что мы можем с этим сделать. В голове у пользователя все элементы, с которыми он провзаимодействовал, расположены в некотором порядке. Например, он точно знает, что «Интерстеллар» лучше, чем «Притяжение», «Притяжение» и «Чужой» одинаково хорошие фильмы, и все они чуть хуже, чем «Терминатор». При этом к фильмам, которые пользователь ещё не смотрел, он тоже испытывает некоторое отношение, причём ко всем одинаковое. Он может считать, что такие фильмы априори хуже тех фильмов, что он посмотрел. Или он может считать, что, например, «Прометей» — плохой фильм, и любой фильм, который он ещё не смотрел, будет лучше него.
Представим, что по некоторым признакам поведения пользователя в сервисе мы умеем восстанавливать этот порядок, отображая элемент, с которым он провзаимодействовал, в целое число с помощью функции . Множество всех фильмов, с которыми пользователь провзаимодействовал, обозначим как . Условимся, что , если пользователь не взаимодействовал с фильмом , то есть . Таким образом, если пользователь посчитал фильм плохим, то , а если хорошим, то .

Теперь мы можем ввести ранк .
здесь обозначает индикаторную функцию и равна единице, если верно и нулю иначе.
Давайте остановимся на минуту и подумаем, что такой ранк означает.
Зафиксируем пользователя , это — какой-то конкретный пользователь, какой именно — нас не интересует. Соответственно и его вектор окажется фиксированным.
Возьмём теперь любой фильм, который он посмотрел, например «Интерстеллар». В формуле это . Далее найдём фильм, который пользователь считает хуже, чем «Интерстеллар». Мы можем выбирать из «Притяжение», «Чужой», «Прометей», либо любого фильма, который он ещё не смотрел.

Возьмём «Притяжение». В формуле это . Теперь проверим, если взять вектор «Интерстеллар» и домножить на вектор пользователя, будет ли результат больше, чем результат умножения вектора «Притяжение» на тот же самый вектор пользователя. Для надёжности учтём зазор в единицу. Теперь сделаем это для «Чужого», для «Прометея» и для всех фильмов, которые пользователь ещё не посмотрел и просуммируем.
Получим количество фильмов, которые наша модель матричного разложения ошибочно ставит выше, чем «Интерстеллар». В идеальной модели будет равно нулю для кадого пользователя и каждого элемента, с которым он провзаимодействовал.
Теперь достаточно легко записать общую ошибку модели.
— некоторая функция, переводящая натуральный ранк в вещественное число. От её выбора зависит то, какую часть верхушки списка элементов мы хотим оптимизировать. Хорошим выбором может служить функция, описанная ниже, однако в реальных вычислениях ради скорости её можно аппроксимировать логарифмом.
С функцией потерь разобрались. Как теперь всё это применить на практике? Можно, конечно, оптимизировать приведённую функцию напрямую с помощью градиентного спуска, но честное вычисление ранка для всех элементов и всех пользователей займёт гигантское количество времени, ведь нам необходимо будет производить суммирование вообще по всем доступным элементам.
Здесь нам поможет небольшой трюк: вместо честного ранка будем считать его аппроксимацию. Для этого из элементов таких, что будем выбирать случайные и проверять, не нарушается ли отношение . Если отношение не нарушалось раз и нарушилось на шаге , то примем в качестве ранка элемента
где — общее число элементов.
Имея ранк примера, нарушающего отношение порядка, мы легко можем сделать шаг градиентного спуска в сторону, исправляющую это недоразумение.
Такая функция потерь называется WARP и впервые она была описана в статье WSABIE: Scaling Up To Large Vocabulary Image Annotation. Мы её видоизменили, добавив произвольные целочисленные ранки и понятие нейтрального ранка для элементов, с которыми пользователь не взаимодействовал. На нашей задаче это дало прирост метрик примерно в 10%.
Открытым остаётся вопрос выбора . В Okko пользователь может провзаимодействовать с контентом следующим образом:
- Купить навсегда;
- Взять в аренду;
- Посмотреть по подписке (или бесплатно);
- Добавить в закладки;
- Поставить рейтинг от 0 до 10.
Покупку мы считаем самым ценным действием, так как она требует от пользователя вложений не только времени, но и денег. Если пользователь готов потратить на новинку 399 рублей, скорее всего, он её ценит. Взятие в аренду находится на втором месте, просмотр по подписке на третьем. Добавление в закладки обрабатывается отдельными бизнес-правилами, поэтому на данном этапе мы это действие игнорируем.
Рейтинг — особое действие. В отличие от покупки или просмотра, это explicit действие: пользователь забивает на все наши эмпирические правила и чётко говорит нам какой фильм ему нравится, а какой нет. Поэтому рейтинг, если он поставлен, перекрывает все implicit предположения.
В итоге, в качестве мы используем степенную функцию, зависящую от относительного времени просмотра. Степень определяется типом потребления. Ниже приведены примеры графиков для различных типов потребления, построенные с некоторыми случайными гиперпараметрами.
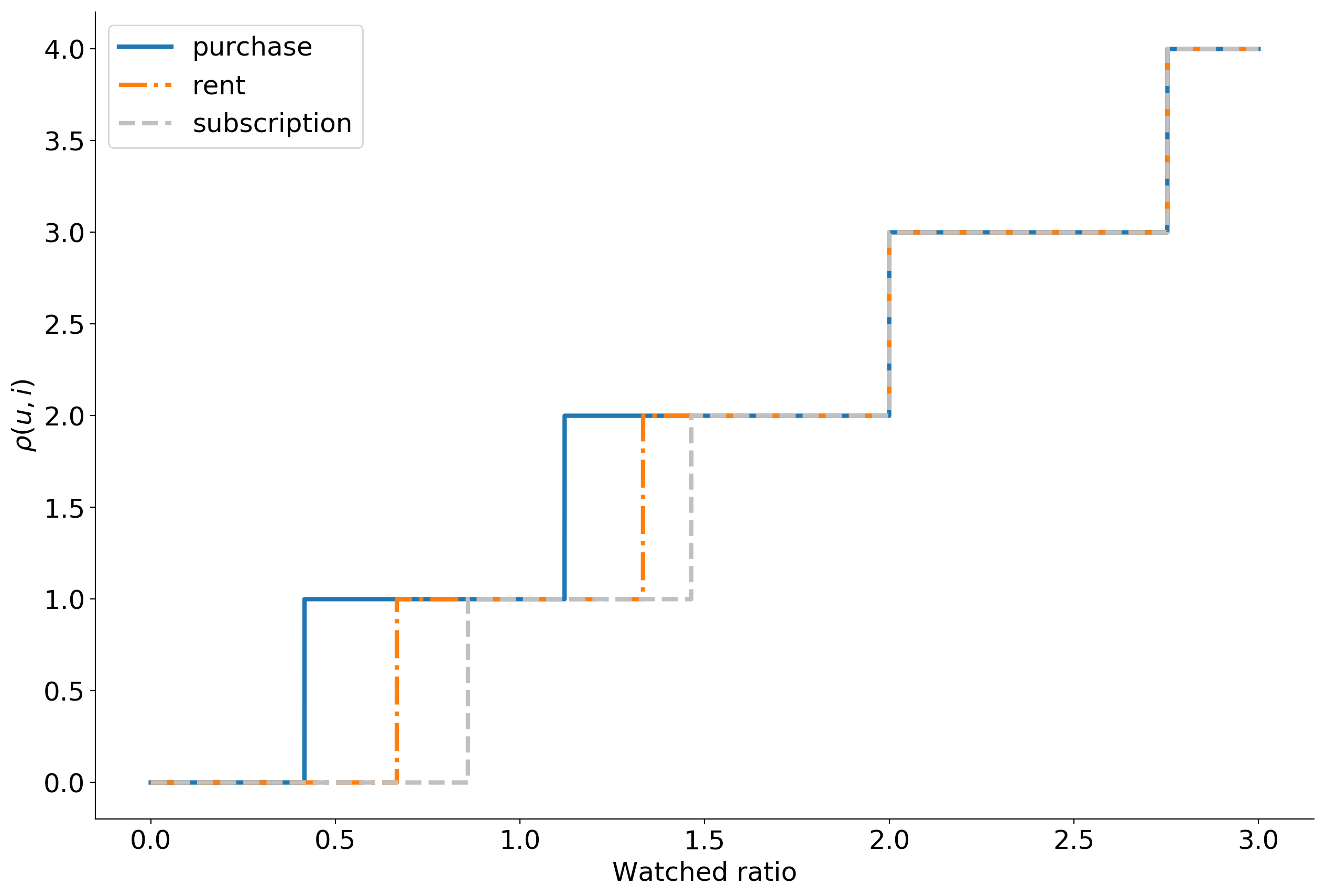
При этом , если пользователь оценил фильм ниже своей средней оценки и , если выше.
Если говорить о технической реализации, то мы используем самописную библиотеку на Cython, унаследовав немного кода из LightFM.
Второй этап: ранжирование

Имея матрицы пользователей и элементов, легко посчитать top-N рекомендаций для пользователя: достаточно умножить его вектор на матрицу элементов и отсортировать результат по убыванию. Если элементов слишком много, можно воспользоваться подходом из статьи Approximate nearest neighbor algorithm based on navigable small world graphs и делать это за логарифмическое время вместо линейного.
К сожалению, рекомендации, полученные из матричной факторизации, не дают приемлемого качества, каким бы крутым методом мы её не учили. Дело в том, что мы никак не используем доступную мета-информацию об элементах, пользователях и контексте. Также мы теряем всю временную информацию: какой элемент был потреблён первым, а какой последним.
Этих проблем позволяют избежать контентные модели. Они мощные, выразительные и в них можно засунуть любые признаки, но они крайне медленные. Решение — прогонять контентную модель не на всех элементах, а на кандидатах, полученных из матричного разложения. Кандидатов может быть столько, сколько вы успеваете обрабатывать, но желательно хотя бы в два раза больше, чем вы показываете пользователям. В нашем случае для 100 рекомендованных фильмов лучшим решением оказалось использовать 400 кандидатов.

Признаки, которые мы подаём в контентную модель, можно разделить на три группы: признаки пользователя, признаки элемента и признаки взаимодействия. Всего получается около 50 признаков.
В качестве признаков пользователей мы используем агрегированную статистику их поведения в сервисе, например:
- процент смотрения по подписке,
- распределение устройств, с которых пользователь заходит в приложение,
- время жизни в сервисе,
- и т. д.
Для фильмов мы используем практически всю доступную мета-информацию: жанр, год выхода, страна, актёр, режиссёр, ограничение по возрасту и т. п. Также хорошо помогают агрегированные бизнес-метрики: процент заходов на карточку, количество просмотров, добавлений в избранное, распределение по способам смотрения, по устройствам и т. д.
Признаки взаимодействия включают в себя скоры из этапа отбора кандидатов и агрегированную статистику по всем предыдущим взаимодействиям пользователя и фильмов с участием тех же актёров, режиссёров, сценаристов, что и у рассматриваемого фильма.
Самый частый вопрос, возникающий, когда речь заходит о ранжировании кандидатов моделью второго уровня, заключается в том, как же эту модель обучать. В случае с одной только матричной факторизацией нам требовалось два множества, разделённых по времени — обучающее и тестовое. В случае с двухступенчатой системой нам их понадобится три — два тренировочных и одно тестовое.
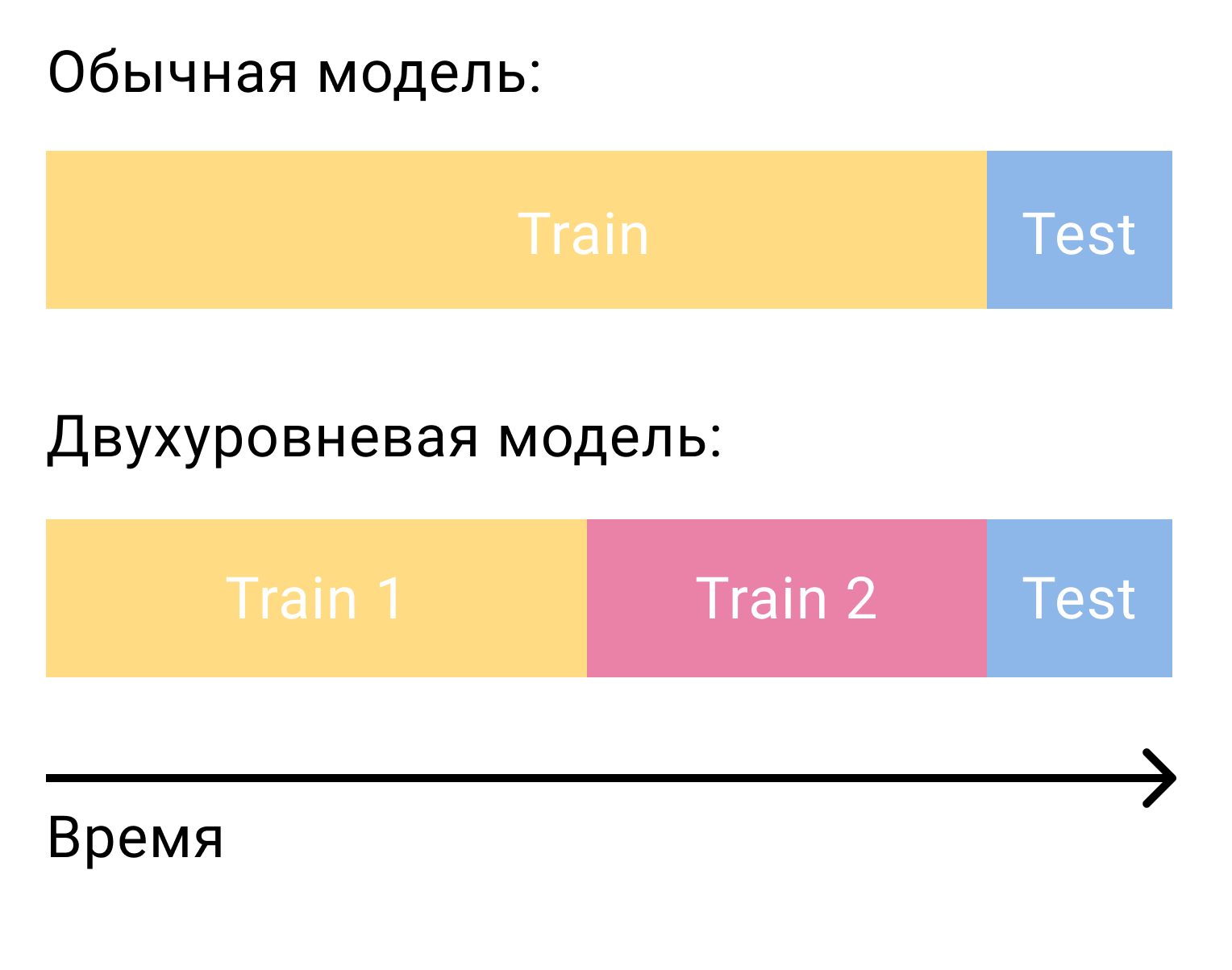
На первом тренировочном множестве мы обучим модель первого уровня и построим кандидатов. Из кандидатов важно исключить те элементы, с которыми пользователь взаимодействовал в этом множестве. Затем мы посмотрим, с какими из кандидатов пользователь взаимодействовал во втором тренировочном множестве. Назовём их positives, а остальных кандидатов negatives. Это и будет нашим обучающим множеством для контентной модели.
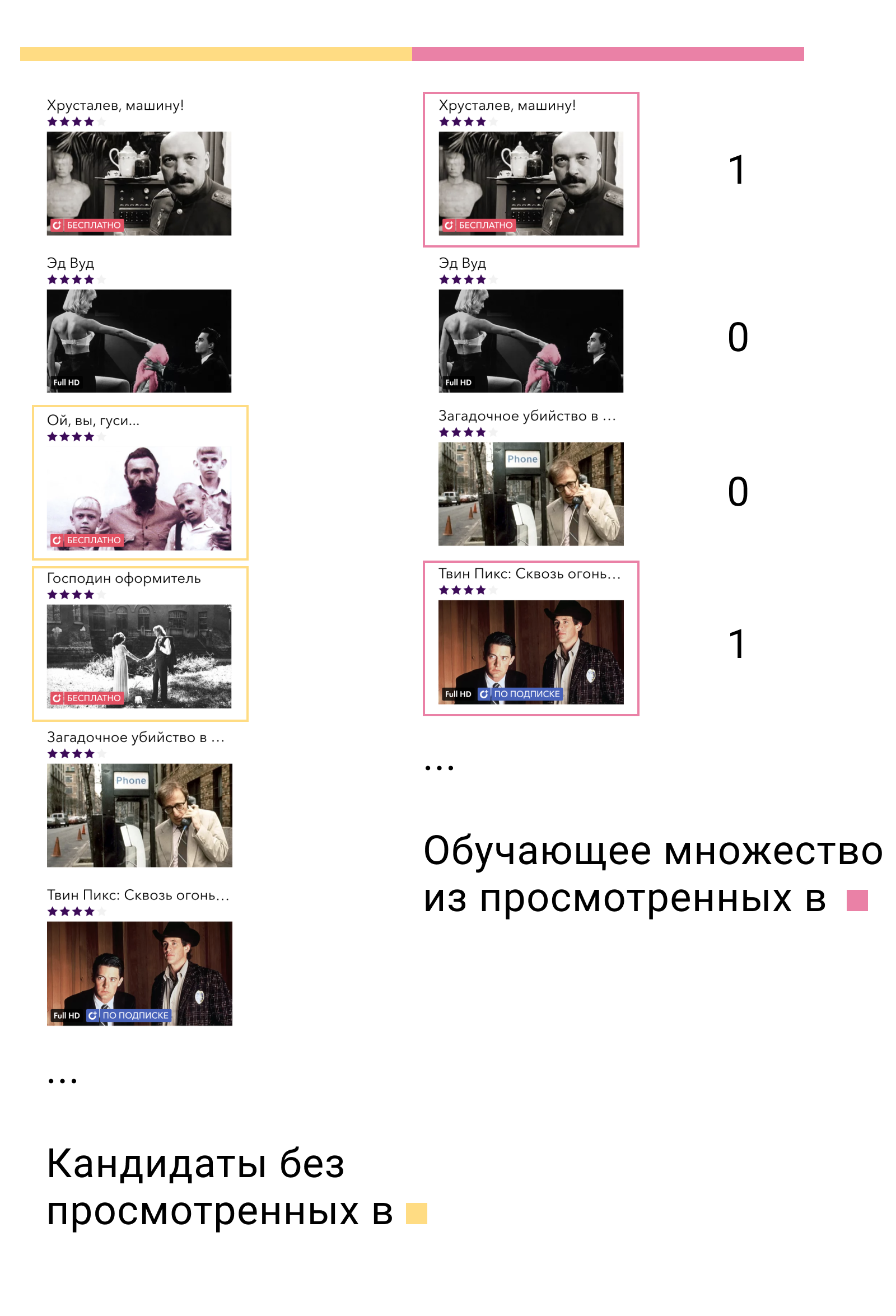
Почему это работает? Во-первых, мы обучаем модель ровно на тех данных, на которых она и будет использоваться — выходе модели первого уровня. Во-вторых, среди всех возможных отрицательных примеров мы берём самые сложные — те, которые модель первого уровня называет релевантными для пользователя, но они таковыми не являются.
Что дальше? Самое простое и очевидное решение — решить задачу бинарной классификации и затем отсортировать элементы по убыванию вероятности быть положительным примером. Но можно снова вспомнить постановку задачи построения рекомендательной системы, понять, что бинарная классификация — не та задача, которую мы решаем, и опять перейти к задаче ранжирования.
В XGBoost и LightGBM основной функцией потерь для задач ранжирования является LambdaMART. Если не вдаваться в детали, интуиция за ней достаточно проста. Если — выход модели для примера , то вероятность того, что элемент будет иметь ранк выше чем элемент , будет равна
Функция потерь тогда может быть записана следующим образом.
здесь — истинная вероятность ранжирования. Мы определим её как 1 если , 0 если и 0.5 в случае .
Двухуровневая модель даёт прирост метрик на 50% по сравнению с одноуровневой. Функция потерь ранжирования добавляет ещё 10%.
Бонус: похожие фильмы
Помните, в плюсах используемого нами подхода я упоминал о «бесплатных» векторах из матричной факторизации, которые можно использовать для решения смежных задач? Так вот, одну из таких задач — поиск похожих фильмов — мы решили.
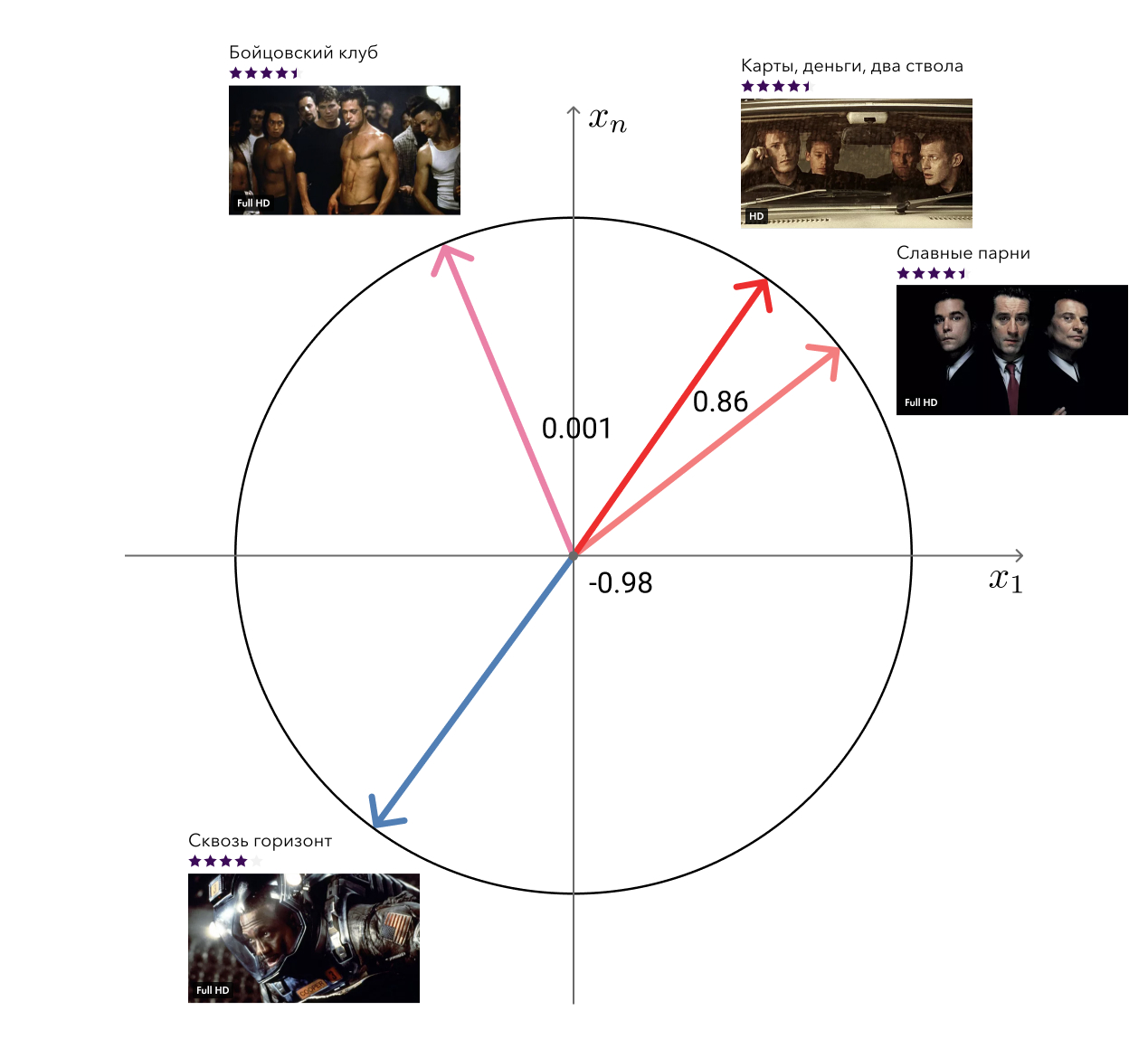
Решение до безобразия простое: для каждого фильма мы берём его вектор и ищем к нему ближайшие по косинусной дистанции. На глаз выглядит вполне адекватно. Следующий уровень — добавить мета-информацию и использовать алгоритмы на графах.

Техническая реализация
Помимо алгоритмической части хочется рассказать немного и о реализации. Rekko состоит из трёх компонентов: lynch, rekko-tasks и rekko-service.
Lynch работает на одной мощной машине, периодически просыпается, подготавливает данные для микросервиса и складывает их в S3.
Микросервисы rekko-tasks и rekko-service находятся в продуктовой среде Okko рядом со всеми остальными микросервисами и базами данных. Первый из них постоянно мониторит S3 на предмет изменений, при наличии таковых скачивает их и складывает в продуктовые базы. Второй микросервис использует эти предпосчитанные результаты для того, чтобы в реальном времени отвечать на запросы пользователей и рассчитывать их рекомендации.

Микросервисы написаны на Python с использованием falcon, gunicorn и gevent и не представляют собой ничего интересного за исключением бизнес-логики. Как и все остальные микросервисы продуктовой среды Okko, они закрыты балансировщиком.
Lynch же гораздо интереснее.
Что нужно сделать, чтобы посчитать очередную порцию рекомендаций для пользователей? Как минимум:
- Загрузить новые данные, появившиеся с момента последнего пересчёта;
- Обработать их;
- Обучить матричную факторизацию;
- Построить кандидатов;
- Переранжировать кандидатов;
- Применить бизнес-правила;
- Выгрузить.
Вроде звучит не страшно, можно вынести каждую часть в отдельную функцию и просто вызвать их по очереди:
data = extract_data()
data = transform_data(data)
mf_model = train_mf_model(data)
candidates = build_candidates(mf_model)
predictions = build_predictions(content_model, candidates)
upload_predictions(predictions)Ну всё, отлично поработали, расходимся? Не совсем. А что, если вся эта простыня где-то упадёт? Ну например из-за нехватки памяти. Придётся перезапускать всё заново, даже если мы уже потратили пару часов на то, чтобы обучить модель и построить кандидатов.
Хорошо, давайте тогда сохранять все промежуточные результаты в файлы, а после падения проверять какие из них уже существуют, восстанавливать состояние и запускать вычисления уже только с нужного момента. На самом деле эта идея ещё хуже чем предыдущая. Программа может прерваться посередине записи в файл и он, хоть и будет существовать, будет в неверном состоянии. В лучшем случае всё вычисление упадёт, в худшем — завершится с неверным результатом.
Хорошо, давайте сделаем запись в файл атомарной. А каждую функцию вообще вынесем в отдельную сущность и укажем зависимости между ними. Получится цепочка вычислений, каждый элемент которой может быть либо выполнен, либо нет.

Уже неплохо. Но в реальности все необходимые вычисления едва ли будут описываться списком. Обучение матричной факторизации потребует не только данных о транзакциях, но ещё и об оценках пользователей, построение кандидатов потребует списка запомненных фильмов, чтобы исключить их, вычисление похожих фильмов потребует обученной матричной факторизации и мета-информации из каталога и так далее. Наши задачи выстраиваются уже не в односвязный список, а в ориентированный граф без циклов (Directed Acyclic Graph, DAG).

DAG — крайне популярная структура для организации вычислений. Существуют два основных фреймворка для построения DAG: Airflow и Luigi. Мы в Okko остановились на последнем. Luigi разработан в Spotify, активно развивается, полностью написан на питоне, легко расширяется и позволяет очень гибко организовывать вычисления.
Задача в Luigi определяется классом, наследуемым от luigi.Task и реализующим три обязательных метода: requires, output и run. Вот так выглядит типичная задача:
# RekkoTask расширяет luigi.Task дополнительной функциональностью
class DoSomething(RekkoTask):
# Параметры задачи
date: datetime.datetime = luigi.DateSecondParameter()
# Потребляемые ресурсы
resources = {
'cores': 4,
'aws': 1,
'memory': 8
}
# Namespace задачи для удобной группировки
task_namespace = 'Transform'
def requires(self):
# Задачи, от которых данная зависит и чьи результаты ей требуются
return {
'data': DownloadData(date=self.date),
'element_mapping': MakeElementMapping(date=self.date)
}
def output(self):
# Куда данная задача запишет результат
# Это может быть не только локальный файл, но и база данных и файл на s3
return luigi.LocalTarget(
os.path.join(self.data_root, f'some_output_{self.date}.msg'),
format=luigi.format.Nop
)
def run(self):
# Основной метод, где происходит вся работа
# Загрузка данных из зависимых задач
with self.input()['data'].open('r') as f:
data = pd.read_csv(f)
with self.input()['element_mapping'].open('r') as f:
element_mapping = json.load(f)
# Обрабатываем входные данные и считаем результат
result = ...
# Можем записать логи для отправки их затем в Splunk
self.log(
n_results=len(result)
)
# Атомарно записываем результат
with self.output().open('w') as f:
result.to_msgpack(f)Luigi сам проследит за тем, чтобы задачи выполнились в нужном порядке без превышения потребления доступных ресурсов. Если задачи могут выполняться параллельно, он запустит их параллельно, максимизируя утилизацию CPU и минимизируя общее время исполнения. Если какая-то задача завершится с ошибкой, он перезапустит её некоторое количество раз и в случае неудачи сообщит нам. При этом все задачи, которые могут быть выполнены, будут выполнены. Это означает, например, что ошибка в задаче ранжирования кандидатов не помешает посчитать и выгрузить список похожих фильмов.
В данный момент Lynch состоит из 47 уникальных задач, производящих около 100 своих экземпляров. Часть из них занята непосредственной работой, часть — подсчётом метрик и отправкой их в наш BI инструмент Splunk. Основные статистики и отчёты о своей работе Lynch также периодически присылает нам в телеграмм. Об ошибках тоже пишет, но уже в личку.

Мониторинг, сплиты и результаты

Первое правило Data Science: никому не рассказывать о зарплатах в Data Science. Второе правило Data Science: то, что нельзя измерить, нельзя улучшить.
Мы стараемся следить за всем. В первую очередь это, конечно же, метрики ранжирования на исторических данных. Они помогают ещё на этапе исследований выбрать лучшую модель из нескольких и подобрать для неё гиперпараметры.
Для работающих в продакшене моделей мы тоже считаем метрики, но уже подневные. Такие метрики достаточно волатильны, но по ним можно будет сказать, если модель вдруг по какой-то причине деградирует. При выводе в прод новой модели можно оставить её на неделю работать «вхолостую» и следить, чтобы метрики не проседали. После этого можно включить её для части пользователей, запустить A/B тест и следить уже за бизнес-метриками.
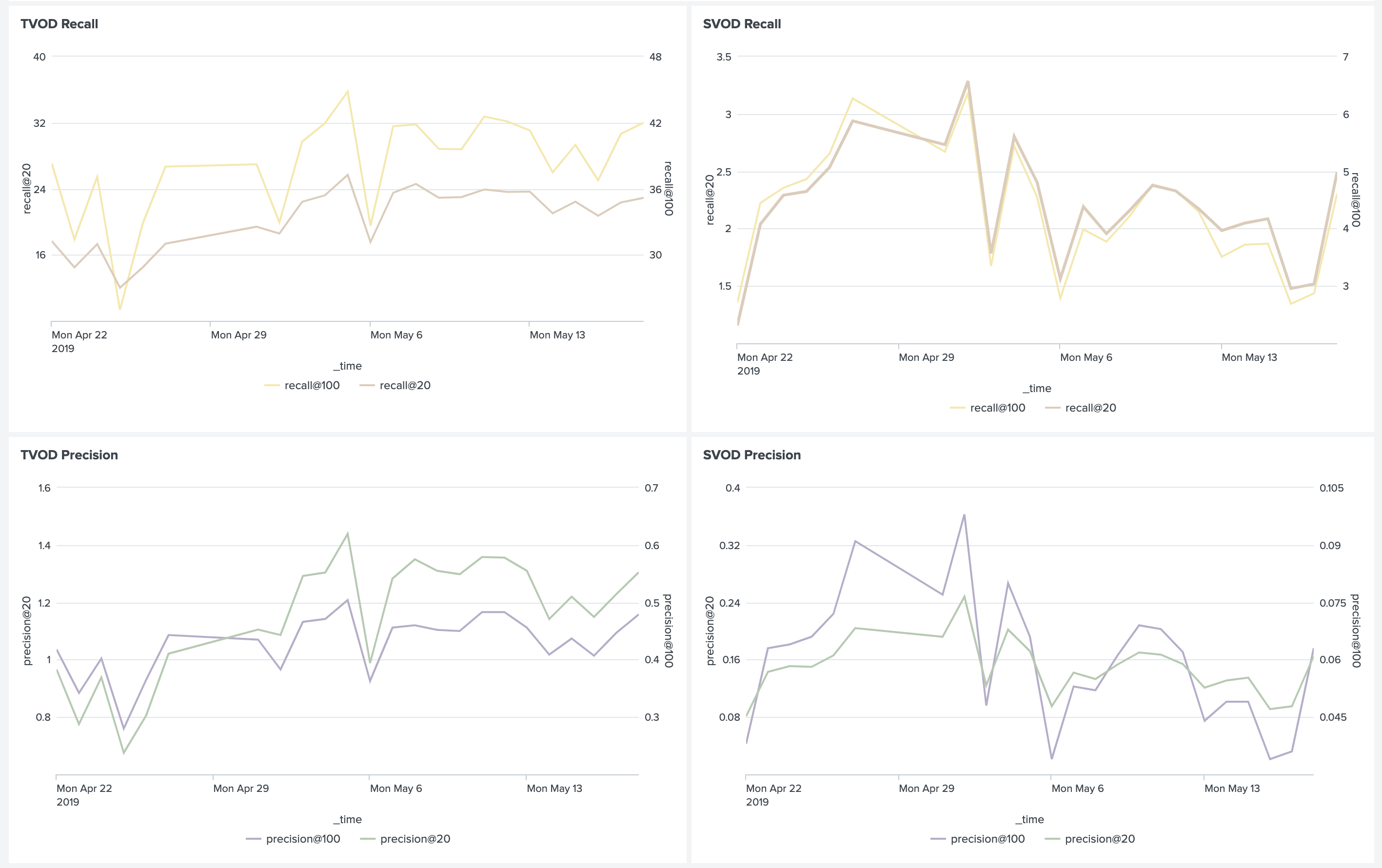
Кроме того, мы считаем распределения рекомендаций по жанру, стране, году, типу и т. п. Это позволяет понимать текущий характер предпочтений пользователей, сравнивать его с реальными данными смотрения и ловить ошибки в бизнес-правилах.
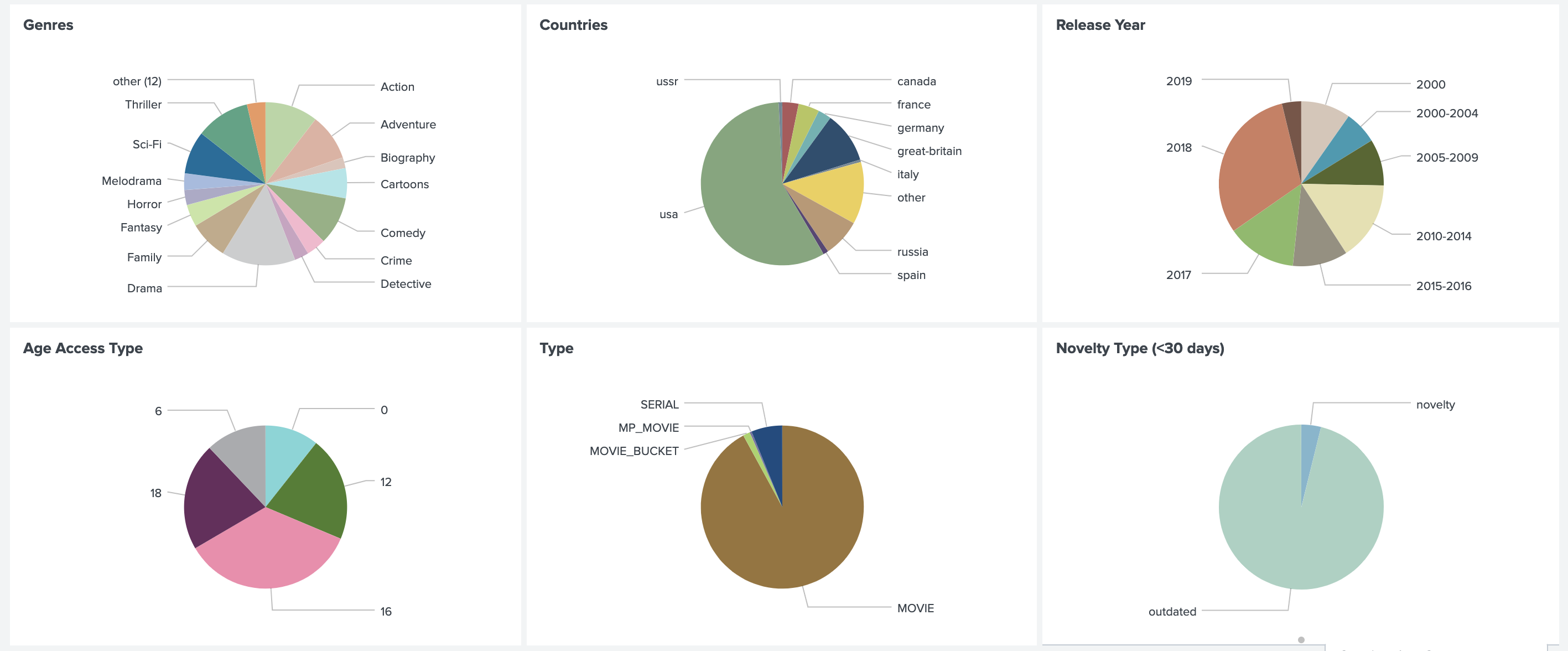
Очень важно также следить за распределениями всех используемых признаков. Резкое изменение в них может быть вызвано ошибкой в источнике данных и привести к непредсказуемым результатам.
Но, конечно, самое главное, что требует пристального внимания — бизнес-метрики. В рамках рекомендательной системы главными бизнес-метриками для нас являются:
- Выручка по транзакционной и подписной моделям потребления (TVOD / SVOD revenue);
- Средняя выручка на посетителя (average revenue per visitor, ARPV);
- Средний чек (average price per purchase, APPP);
- Среднее число покупок на пользователя (average purchases per user, APPU);
- Конверсия в покупку (CR to purchase);
- Конверсия в просмотр по подписке (CR to watch);
- Конверсия в пробный период (CR to trial).
При этом мы смотрим отдельно на метрики из раздела «Рекомендации» и «Похожие» и метрики всего сервиса в целом, чтобы учесть эффект перераспределения и рассмотреть ситуацию под разными углами.
Вот так может выглядеть дашборд сравнения нескольких моделей:

Кроме мгновенных значений метрик полезно также смотреть на дельты и аккумулятивные дельты между ними.
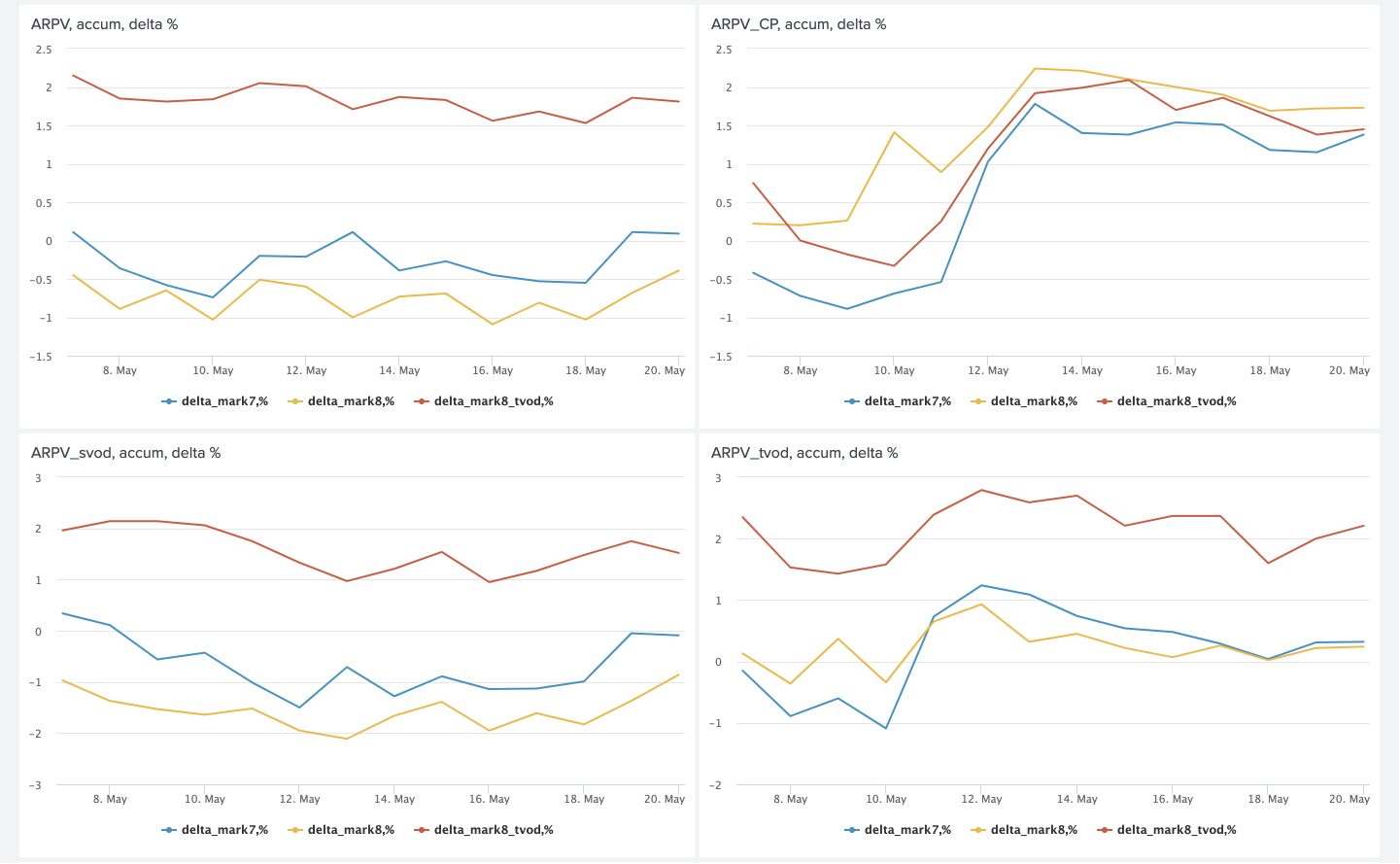
Как я уже говорил в начале, мы сравниваем не только модели между собой, но и группу пользователей с рекомендациями против группы пользователей без рекомендаций. Это позволяет нам оценивать чистый эффект от внедрения Rekko и понимать, где мы в данный момент находимся и какой запас для усовершенствования ещё остаётся. Согласно этому A/B тесту на данный момент мы имеем:
- ARPV +3.5%
- ARPV с учётом маржинальности +5%
- APPU +4.3%
- CR to trial +2.6%
- CR to watch +2.5%
- APPP -1%
Фильмы в онлайн-кинотеатре условно можно разделить на две группы: новинки и старый контент. Новинки мы уже умеем хорошо продавать. Основное предназначение персональных рекомендаций — достать из каталога релевантный пользователям старый контент. Это ведёт к увеличению числа покупок и проседанию среднего чека, так как такой контент, естественно, дешевле. Но у такого контента ещё и высокая маржинальность, что компенсирует проседание чека и даёт прирост в выручке в пять процентов.
Более релевантный подписной контент привёл к увеличению конверсии в пробный период и смотрению по подписке.

Rekko Challenge
С 18 февраля по 18 апреля 2019 года мы совместно с платформой Boosters провели соревнование Rekko Challenge, где предложили участникам построить рекомендательную систему на основе анонимизированных продуктовых данных.

Ожидаемо в топе оказались участники, построившие двухуровневую систему, похожую на нашу. Победители, занявшие первое и третье места, сумели добавить к ансамблю RNN. А участник с восьмого места сумел забраться на него с помощью лишь моделей коллаборативной фильтрации.
Евгений Смирнов, занявший в соревновании второе место, написал статью, где рассказал о своём решении.
В данный момент соревнование доступно в виде песочницы, так что каждый, кто интересуется рекомендательными системами, может попробовать в нём свои силы и получить полезный опыт.
Заключение
Данной статьёй я хотел показать вам, что рекомендательные системы в продакшене — это совсем не сложно, а весело и прибыльно. Главное — думать о целях, а не средствах их достижения и постоянно всё измерять.
В будущих статьях мы расскажем вам ещё больше о внутренней кухне Okko, поэтому не забывайте подписываться и ставить лайки.
Spaceoddity
Всё, с сегодняшнего дня запустили рекламную кампанию на полную?
Куча умных диаграмм и графиков, рассуждения о том, что надо последовательно развивать сервисы, а не гнаться за сию минутным эффектом.
И тут же сегодня мы узнаём цену на трансляции матчей АПЛ. Которую ничем иным, кроме как «надо бы сразу по максимуму маржу снять» не объяснить. Народ уже вовсю ругается, что урежь цену в 2 раза — профита было бы куда больше. Что 200р. в день (или 500 в месяц) — это сильно завышенная цена за такую специфику. Что нет наконец возможности подключить пакет с матчами одной любимый команды (хотя в статье очень много расписано про машинное обучение рекомендательных систем...).
Не, не взлетит…
devpony Автор
Странно думать, что эта статья была написана ради рекламной кампании АПЛ. То что дата публикации совпала с анонсом цен – совпадение.
По поводу ценообразования могу лишь напомнить классическую диаграмму:
smarthomeblog
Есть масса примеров, когда дешево — очень качественно. И, что не маловажно, остутсвутют любые ограничения по локации. А так статья очень познавательная.
Spaceoddity
А то, что пост появился в «лучшем» с нулём комментариев — тоже совпадение?
devpony Автор
"Лучшее" – это просто лента постов за день, отсортированная по рейтингу. Утром постов мало и даже новый пост с небольшим рейтингом может там оказаться.
Если честно, я был бы только рад заплатить хабру за трафик и промоутинг, но такой возможности, к сожалению, нет.
v2kxyz
А вы пробовали объяснить? По информации отсюда:
Права стоят 7 млн. евро, что примерно 511 млн. рублей. Аудитория около 175000. Сезон идет 10 месяцев, поэтому если все будут брать подписку по почти самому невыгодному варианту 549 месяц получаем доход — 960 млн. рублей. Расходы на железные и людские ресурсы мне неизвестны. Но я уверен, что многие купят подписку заранее по 3000 рублей, тогда доход составит вообще 525 млн. рублей, а прибыль за счет неизвестных издержек будет отрицательной. Поэтому негодование по поводу цен мне совершенно непонятно. Да и 500р — это один раз в кино сходить, что-то бунтов по поводу цен не наблюдается.
P.S. Мне вот придется покупать и их и МатчТВ, ибо еврокубки.
Spaceoddity
500р — это один раз в кино не сходить, один раз пива не попить, один раз не пообедать и т.д.
Всякий раз когда тебе пытаются втюхать какой-то сервис (обычно из медиа-индустрии) ссылаются на этот «один раз». Проблема в том, что в итоге этих «разов» набирается столько… Хотя многие люди и не против заплатить, но только за всю пачку контента, а не по каждому чиху бежать доплачивать ещё 500р, обмазываться всякими платформами и т.п.
Ну и основная моя претензия что пока известно только о том, что куплены права и главным назначили Стогниенко. Всё. Ни форматов, ни технических подробностей. Непонятно вообще насколько всё это будет смотрибельно. Зато ценники уже развесили.
v2kxyz
Считайте тогда лучше не в разах, в рублях в час за развлечение. Поход в кино 500р за 2 часа, покупка трансляций АПЛ — 2+ часа, лично для меня часов 6(3 игры) минимум.
По фильмам у Okko неплохой сервис в плане качества, поэтому не думаю, что футбол они в 360p будут показывать. Главное, чтобы приложения в телевизоре это умело…
P.S. Но это все оффтопик, я статью никак не осилю, с телефона не удобно ее читать было.
tsukasa_mixer
А теперь, представим что пользователь это не индивид, а множество…
Вся рекомендательная система сразу же ломается в хлам.
devpony Автор
Аккаунты, которыми пользуются сразу несколько человек, – один из главных пунктов нашего плана развития. Самое правильное решение здесь – перед началом сеанса спрашивать кто сейчас смотрит.
algotrader2013
Вряд ли кто ответит честно — и так всем надо чрезмерно много неочевидно зачем нужных данных, и людей это выбешивает. Скорее перспективно угадывать по устройству, времени и дню недели, таймингам между нажатиями… но вот как подготовить датасет для обучения, не зная таки, кто именно смотрел?
Или всё же полученная сейчас модель и так дает нечто среднее, взвешенное по активности между всеми членами семьи, и все ок? Не пробовали ради интереса смешивать два случайных акка, и смотреть после этого на точность?
devpony Автор
Нет, далеко не всё ок. Есть известные кейсы, когда вся семья пользуется Okko и в рекомендациях полно мультиков, т.к. ребёнок, естественно, смотрит больше всех. Для родителей такие рекомендации не релевантны и они туда не заглядывают. Хотя там и может быть ~20% релевантного родителям контента, но они не будут выискивать его среди кучи не релевантного.
Ну, если пользователь хочет получать релевантные персональные рекомендации и понимает, что без выбора своего профиля их не получить, то выбора у него не будет.
Это ОЧЕНЬ сложная задача, которая совершенно точно не может быть решена с идеальной точностью. Соответственно, всегда будут ошибки и всегда будут недовольные пользователи. Спрашивать пользователя – вполне нормальная практика. Так делает, например, Netflix, а опыта в UI/UX у них полно.
tsukasa_mixer
Самое простое предположение, по времени.
это банальная характеристика которую криво учитывают.
Например:
итого 2 индивида по хорошему порождают минимум 4 поведенческих набора предпочтений.
всякие переключения профилей, это из категории "не решать задачу"
и давайте будем честны, это скрип зубов менеджеров, т.к. теперь мы знаем, что пользуясь 1 аккаунтом, на самом деле нас "орда семейная" .
korzhik
Не знаю почему вас заминусовали. Видимо это одинокие бездетные строители рекомендательных сетей.
Tarson
Следующий шаг — чтобы кто-нибудь за меня этот фильм и посмотрел…
nlog
А Терминатора 2 нет.
devpony Автор
?\_(?)_/?lnkov
Спасибо за подробную статью!
Один комментарий.
Если использовать эту группу несколько раз в качестве контрольной, то начиная со второго аб-теста результаты могут сильно поехать из-за смещения, образованного эффектом «памяти» пользователей.
emkh
Отличная статья, спасибо!
Deeplerg
Ничего не понятно, но очень интересно
Fandorin
Сервис неудобный, за каждый чих — плати. Пользуюсь нетфликсом, очень удобно, нет проблем с переключением аккаунтов, одна подписка, полный доступ. Здесь же куча каких-то граблей.
devpony Автор
На Netflix гораздо меньше библиотека, если не считать их оригинального контента. Например, там никогда не будет новинок, потому что студии не открывают подписные права на новинку ни для одного игрока рынка. У нас же новинки будут доступны для покупки.
Fandorin
Вы сконцентрируйтесь на юзабилити и на понятных подписках. Чтобы у вас начать смотреть фильм у меня ушло минут 15 с «втыканием» куда жать и почему я подписку оформил, а за фильм, который я хочу посмотреть, мне надо доплачивать. Я понимаю, что у вас там модель монетизации какая-то, но блин для пользователей это вообще неочевидно! Должно быть 3 клика и 30 секунд потраченного времени в идеале. на Нетфликсе все интуитивно понятно. Я бы посоветовал сначала сделать сервис «Для людей», а потом думать о монетизации. зато вы пишете про алгоритмы рекомендаций) да они никому не будут нужны))
aleks_raiden
это справедливо. И нетфликс также это понимает, поэтому некоторая часть новинок уже собственного производства )
4knowledge
Спасибо за статью, насколько решения с хакатона были сильны по сравнению с вашим решением? (если конечно же честно обучаться на тех же данных)
devpony Автор
Скор первого места – 0.048, скор нашей системы на тех же данных – 0.061. Но тут нужно принимать во внимание смещение, вызванное работой продуктовой системы во время сбора данных.
xPomaHx
У меня сейчас оценено около 2000 фильмов, мультов и сериалов, и могу сказать, что никакая система рекомендаций тут уже не поможет, потому, что я просто всё хорошие фильмы или те что по моему вкусу я уже посмотрел.
Kyrie1965
Хорошая статья. Половину после первого прочтения не понял (буду вникать по второму разу), но сама тема формирования рекомендаций очень значимая для операторов VoD-контента. Для спортивного интереса и оценки своего видения поучаствую в песочнице на Boosters.
Для себя сделал некоторые выводы:
И когда вы в Okko добавите поддержку автофреймрейта (preferredDisplayModeId) в версии для Android TV? (в последний раз, когда смотрел вашу программу, поддержки не было)
devpony Автор
Передал пожелание в отдел разработки.
mkvmaks
Все хорошо и сервис на самом деле нравиться, но не нравятся цены. А самое обидное, что покупаешь фильм, а там редкостное г***о и деньги зря потрачены. В кино хожу редко, т.к. там давно смотреть нечего. А вот стоила бы подписка руб. 300 в месяц на все фильмы и в качестве бонуса фильм 2019 года в подарок — я бы заплатил и не жаловался. )