
Сегодня я хочу рассказать читателям Хабра об очередях сообщений вообще и о Yandex Message Queue в частности. Сначала я хочу объяснить, что такое «распределённая персистентная очередь сообщений» и зачем она нужна. Показать её практическую ценность, механику работы с сообщениями, поговорить про API и удобство использования. Во второй половине материала мы посмотрим на техническую сторону: как в наших очередях используется Yandex Database (это надежный фундамент нашего сервиса), как выглядят наивный и улучшенный подход к построению архитектуры, какие проблемы вызывает распределённость и как их можно решить.

Что такое распределённая персистентная очередь сообщений?
Википедия определяет очередь сообщений как «программно-инженерный компонент, используемый для межпроцессного или межпотокового взаимодействия внутри одного процесса». На самом деле, это понятие несколько шире: процессы, взаимодействующие при помощи очереди, могут находиться на разных серверах и даже в разных дата-центрах.
Мы немного уточним термины.
Очередь сообщений – это хранилище, которое обеспечивает размещение и чтение данных в определённом порядке.
С очередью обычно взаимодействуют два типа сущностей:
- писатели (producers) – отправляют сообщения в очередь;
- читатели (consumers) – получают (читают) сообщения из очереди.
При использовании очереди читатели и писатели не зависят друг от друга. Они могут работать с разной производительностью, надёжностью, доступностью и даже могут быть написаны на разных языках программирования.
Основной сценарий для очереди: надёжно и быстро передавать сообщения от писателя к читателю. В отличие от базы данных очередь не предназначена для длительного хранения сообщений. Во многих популярных реализациях существует соответствующий параметр – «Срок хранения сообщений». Он определяет, сколько времени хранится сообщение до момента безвозвратного удаления.
Мы разобрались с понятием очереди, переходим к «распределённости» и «персистентности».
- Распределённость в нашем случае означает наличие кластера, который хранит и обрабатывает данные и метаданные очередей, объединяя все свои узлы в единое целое с помощью вычислительной сети.
- Персистентность подразумевает, что все сообщения в очереди записываются на диск, а писатель получает подтверждение отправки только после успешной записи.
Распределённость и персистентность не влияют на основную функциональность очереди, они обеспечивают отказоустойчивость и надёжность хранения данных. Какие виды отказов могут случиться в нашей системе, мы рассмотрим чуть позже. Однако не могу отказать в себе в удовольствии и немного раскрою карты: за всю историю существования сервиса мы не потеряли ни одного сохранённого сообщения клиента.
Для чего нужна очередь сообщений
Очередь позволяет отделять логически независимые части сервисов друг от друга, то есть обеспечивает decoupling, который так востребован в популярных сейчас микросервисах. Это повышает масштабируемость и надёжность: всегда можно увеличить поток записи в очередь и добавить больше читателей – обработчиков сообщений, при этом отказ читателей никак не сказывается на работе писателей.
Очереди сглаживают пики нагрузок: они исполняют роль буфера для читателей. Если для мгновенной обработки всех поступающих сообщений текущих мощностей читателей недостаточно, помещённые в очередь сообщения будут обработаны позже, когда нагрузка уменьшится. Буферизация полезна для сервисов с нестабильной нагрузкой, где не нужна моментальная обработка входящих событий.
Давайте посмотрим, как это работает, на примере поискового робота (всё-таки Яндекс начинался с поиска!), который скачивает, обрабатывает и помещает веб-страницы в базу данных. Возьмём вот такую архитектуру.
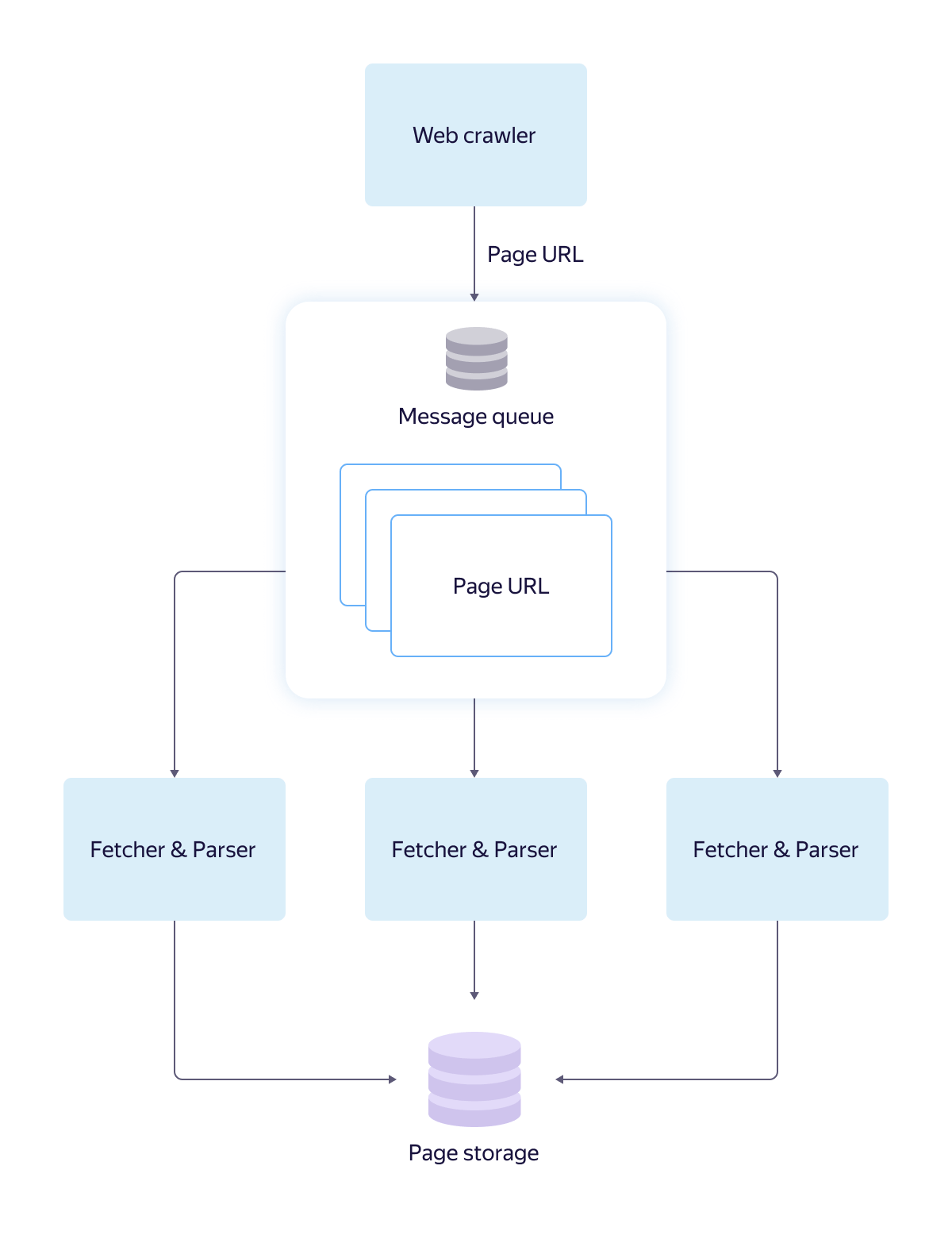
Очередь сообщений решает здесь следующие проблемы:
- Робот работает намного быстрее воркеров, которые отвечают за парсинг и загрузку страниц в базу. Без очереди ссылки стали бы накапливаться и заполнять доступную память или диск. То же самое произошло бы, если бы воркеры оказались временно недоступны.
- Без очереди роботу необходимо «знать» рабочий интерфейс воркеров, чтобы назначать им задания. Интерфейс может меняться по мере развития продукта.
- У отдельного воркера достаточно низкая надёжность, поэтому нет гарантии, что переданная ссылка будет обработана им полностью.
Очередь обеспечивает надежное хранение данных с масштабированием, позволяет отложить обработку ссылки. Если один воркер выйдет из строя, необработанная ссылка через определенный промежуток времени будет возвращена в очередь для обработки другим воркером. У очереди есть собственный интерфейс, который протестирован и описан в документации, так что системы поискового робота и воркеров могут разрабатывать разные команды, на разных языках программирования. Это не повлияет на общую работоспособность.
Как Yandex Message Queue работает с сообщениями
Здесь можно выделить три основных этапа:
- запись сообщения в очередь;
- чтение сообщения из очереди;
- удаление сообщения из очереди.
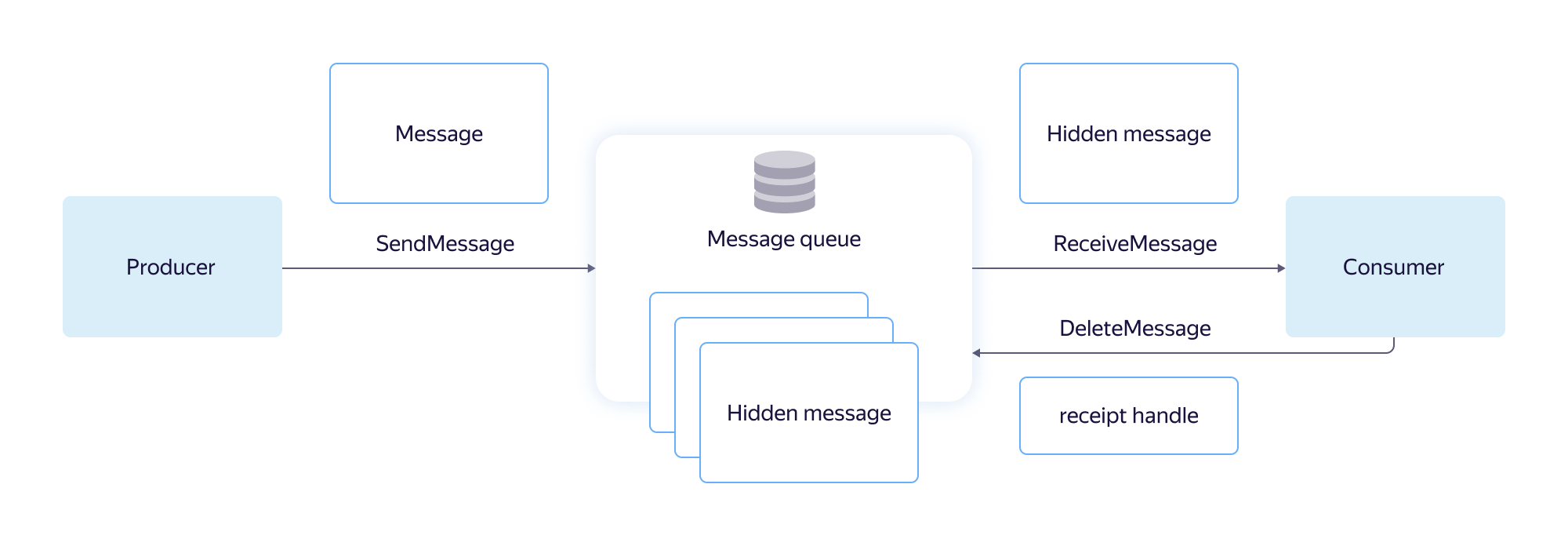
Запись считается успешной, если сообщение было надёжно сохранено и в скором времени станет доступно читателям. Возможна запись с дедупликацией: когда повторная попытка записи отправленного сообщения игнорируется.
В момент прочтения сообщение скрывается из очереди на период времени, который называется таймаутом видимости (Visibility Timeout), и становится недоступным для других читателей. Если таймаут видимости истекает, сообщение возвращается в очередь и снова становится доступным для обработки. Порядок прочтения сообщений определяется очередью, а не читателем.
Сам читатель и сетевое соединение с ним потенциально ненадёжны. Таймаут видимости необходим, чтобы иметь возможность вернуть в очередь сообщение при аварийном завершении работы читателя или обрыве соединения. В противном случае возникает вероятность, что отдельное сообщение никогда не будет корректно обработано.
После успешного прочтения сообщение передаётся клиенту вместе с идентификатором ReceiptHandle. Идентификатор указывает на конкретные данные, которые должны быть удалены из очереди сообщений.
Типы очередей в Yandex Message Queue
Первый и наиболее часто используемый тип – стандартная очередь (Standard Queue). Она отличается высокой пропускной способностью (тысячи сообщений в секунду), отличной производительностью и малым временем исполнения основных операций. Стандартные очереди состоят из логических шардов и поддерживают практически линейное масштабирование пропускной способности.
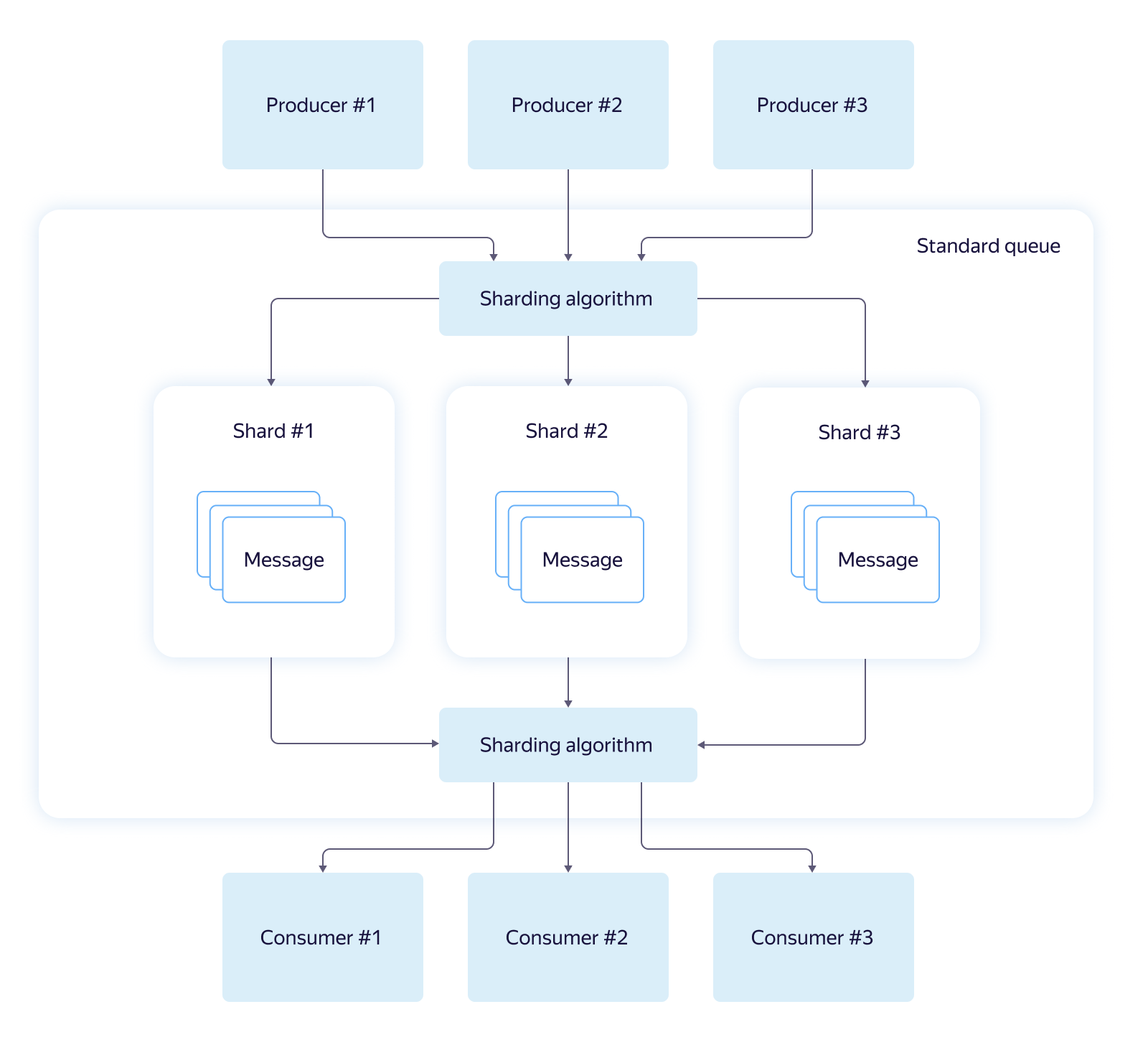
Стандартные очереди не поддерживают дедупликацию сообщений при записи в очередь и не гарантируют порядок прочтения. Из-за использования шардинга запрос на чтение может не вернуть ни одного сообщения, даже если они есть в очереди. Чаще всего это случается в режиме short polling, когда чтение идёт из одного случайно выбранного шарда.
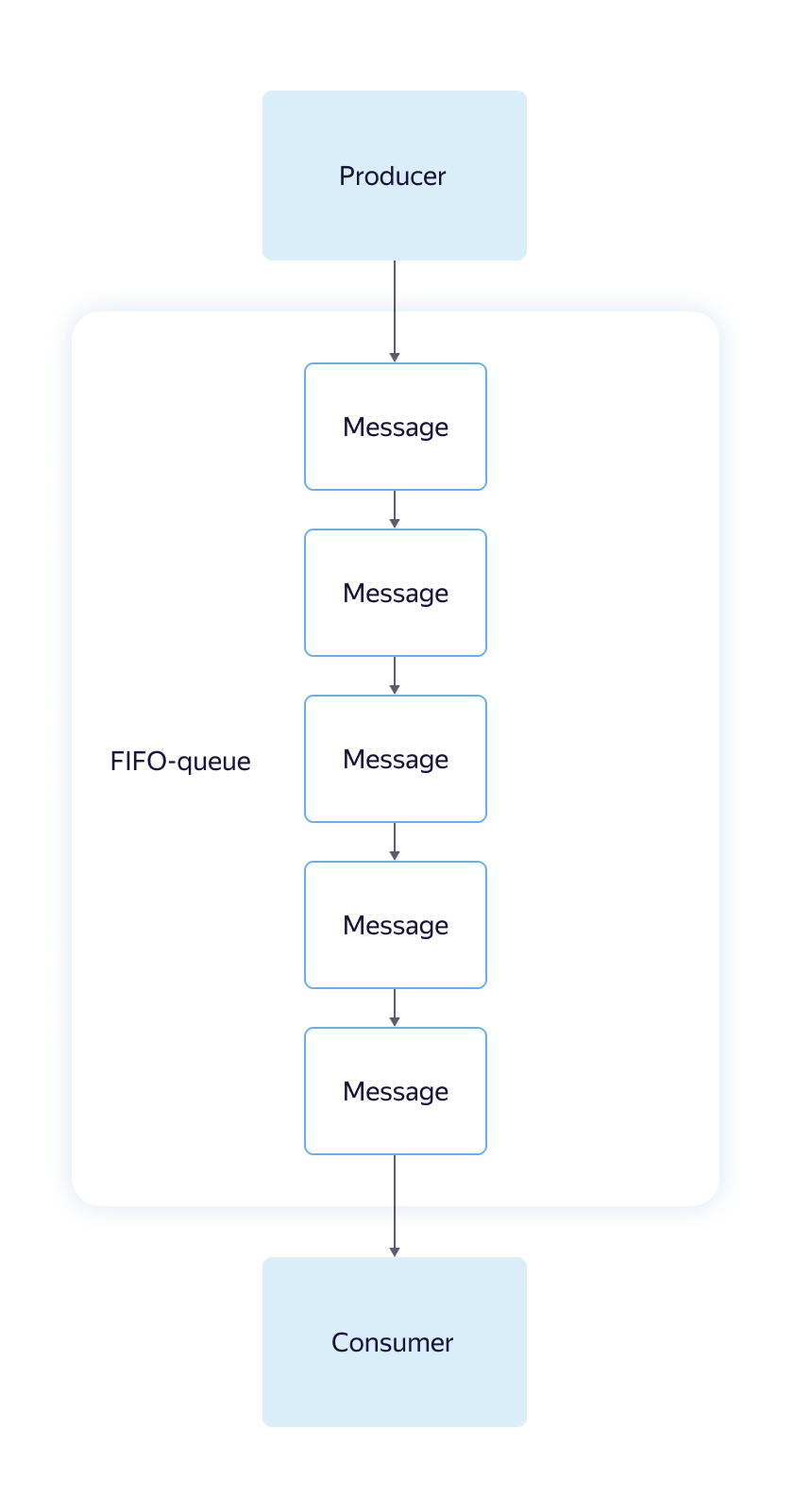
Второй тип – FIFO – противоположность стандартной очереди. Обеспечивает строгий порядок чтения, поддерживает дедупликацию при записи и повторные попытки прочтения сообщений. Производительность и масштабируемость ниже, чем у стандартной. Производительность FIFO-очереди ограничена 30 запросами в секунду. FIFO рекомендуется использовать, когда нужно постараться обеспечить семантику доставки “exactly once”. Обычно под словом «очередь» подразумевается именно FIFO.
Yandex Message Queue API
API – крайне важная составляющая любого продукта. Хороший программный интерфейс должен быть простым и понятным, требовать минимального ознакомления с документацией для эффективного применения. Должен не позволять делать странные или ненужные действия и защищать от глупых ошибок, вовремя сообщая о нарушении «контракта».
Если у системы есть такой API, она быстро получает лояльных пользователей и обрастает удобными «обёртками» для разных платформ и языков программирования.
Amazon Simple Queue Service API (AWS SQS API) – пример такого интерфейса, проверенного временем и огромным количеством клиентов. Поэтому мы решили не изобретать уникальный интерфейс для Yandex Message Queue, а реализовали поддержку AWS SQS API, причём очень тщательно.
В большинстве случаев пользователю SQS достаточно сменить endpoint (адрес сервиса), регион (в данный момент у нас используется только «ru-central1») и получить новые реквизиты доступа (credentials) в пределах Яндекс.Облака. Всё остальное, например, скрипт с использованием командной строки AWS, код с использованием AWS SDK или готовый сервис на Celery или boto, скорее всего, трогать не придётся. Логика и функциональность сервиса очередей останутся прежними.
Подробное описание методов Yandex Message Queue API есть в документации сервиса.
Немного об удобстве
Yandex Message Queue – управляемый (managed) сервис, то есть за работоспособность серверов и программного обеспечения отвечает Яндекс.Облако. Команда сервиса следит за здоровьем очередей, оперативно заменяет вышедшие из строя диски, устраняет разрывы сети и выкатывает обновления. Обновление происходит без остановки сервиса: пока мы устанавливаем новую версию YMQ на одну группу серверов, балансировщик нагрузки старательно перенаправляет трафик на другие. Так что пользователи ничего не замечают.
Чтобы вам было удобнее контролировать работу очередей, мы добавили в YMQ большое количество наглядных графиков, здесь показана только небольшая их часть. Графики находятся в консоли Яндекс.Облака, в разделе «Статистика».

Мы расскажем про четыре самых полезных на наш взгляд графика:
- График «Сообщений в очереди» помогает следить за накоплением данных в очереди. Рост графика может означать, что обработчики не справляются с нагрузкой или обработка остановилась.
- График «Возраст самого старого сообщения в очереди»: большие значения сигнализируют о проблемах с обработкой сообщений. Если все работает правильно, сообщения не должны долго находиться в очереди.
- График «Количество попыток чтения сообщения» показывает, когда сообщения начинают вычитываться несколько раз. Это может значить, что обработчики аварийно завершают работу при получении каких-то сообщений.
- График «Время пребывания в очереди» говорит, сколько времени проходит с момента отправки сообщения в очередь до получения обработчиком.
Графики помогают моментально оценить динамику работы очереди и наличие сбоев без необходимости просмотра логов.
Мы обсудили более-менее общие моменты, теперь перейдём к деталям.
Как в Yandex Message Queue используется Yandex Database
Сервис Yandex Message Queue построен поверх геораспределённой отказоустойчивой базы данных Yandex Database (YDB), которая обеспечивает строгую консистентность и поддержку ACID-транзакций. Мы не будем сейчас разбирать её устройство и характеристики, ограничимся общей схемой.
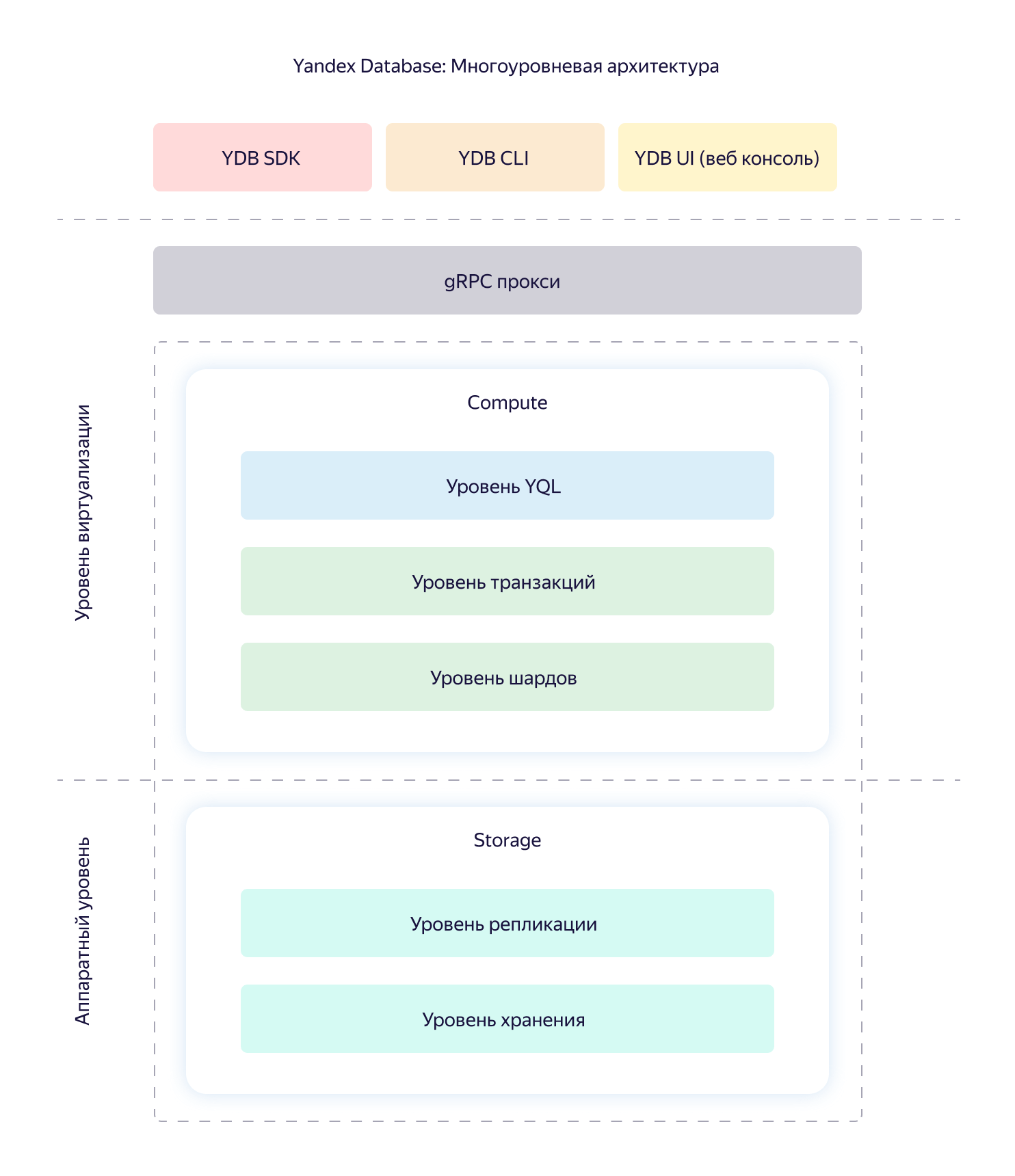
Очередь в YMQ состоит из логических шардов, представленных неким фиксированным набором таблиц YDB. Каждая таблица хранит свою часть информации. Например, есть таблица общего состояния под названием State, которая хранит offset'ы и реальное количество сообщений. Есть таблица с данными и метаданными сообщений. Есть таблица со связанными атрибутами.
Все основные операции с очередью — работа с сообщениями, изменение атрибутов, создание и удаление — это работа с иерархией таблиц и директорий YDB, либо транзакционные запросы к одной или нескольким таблицам очереди. Данные внутри таблиц очереди – источник абсолютной истины. Поэтому помимо корректной и стабильной работы БД нужно обеспечивать надёжное хранение и высокую доступность данных.
У нас информация хранится в нескольких репликах: по одной копии в каждом из трёх дата-центров Яндекса. В случае недоступности одного из дата-центров количество реплик в оставшихся удваивается. Таким образом восстанавливается требуемый уровень надежности. Даже если выйдет из строя целый дата-центр и одна стойка сервиса в другом, данные будут полностью доступны.
Первый вариант архитектуры Yandex Message Queue
Первый вариант архитектуры YMQ, который мы сами назвали наивным, выглядел вот так.
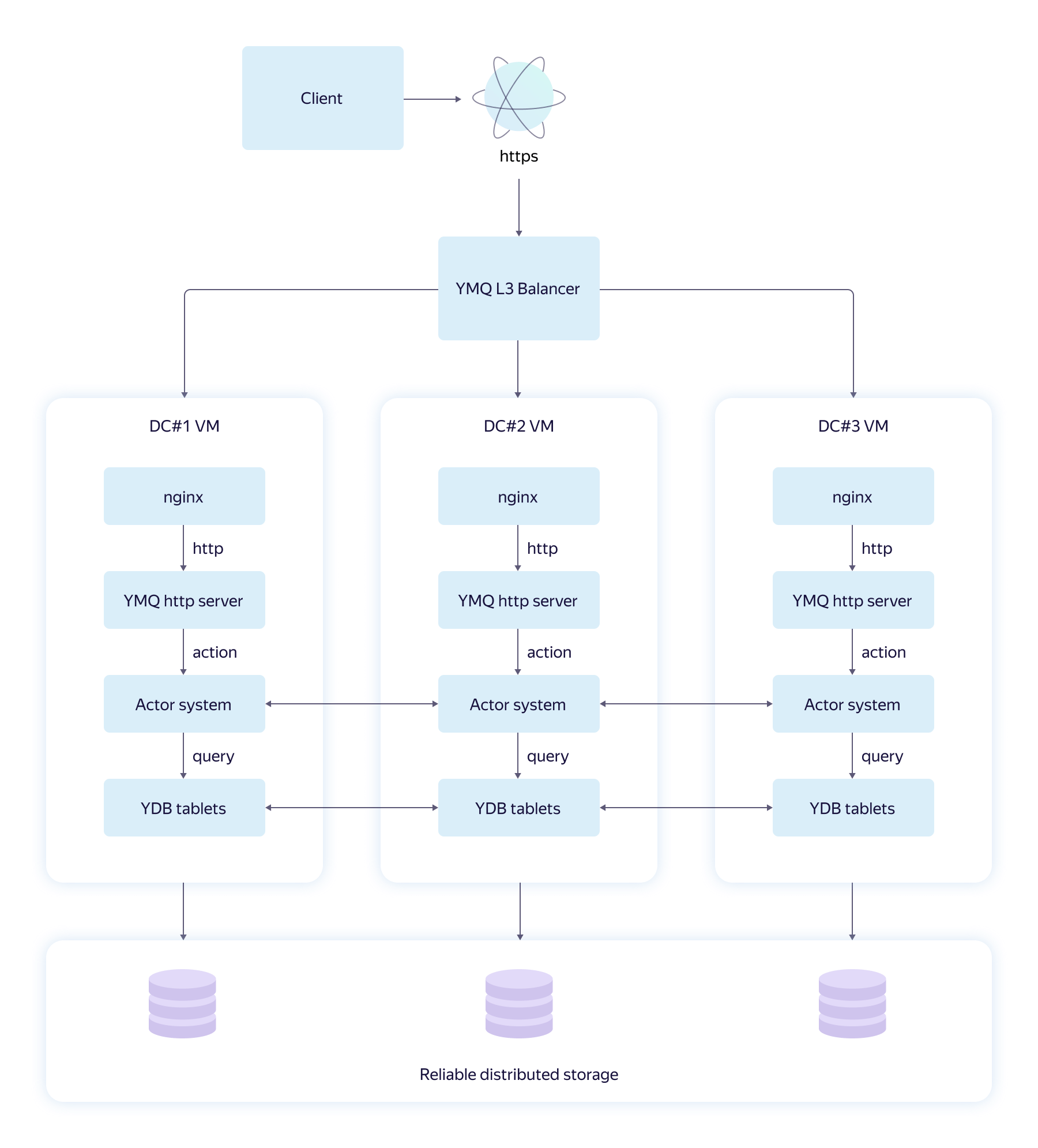
Схема показывает путь HTTPS-запроса от клиента YMQ до хранилища YDB. Посмотрим на основные компоненты:
- L3-балансер направляет запрос в ближайший к пользователю дата-центр Яндекса. Так уменьшаются сетевые задержки, хотя нагрузка распределяется неравномерно.
- Nginx на виртуальной машине Яндекс.Облака терминирует HTTPS-соединения, обеспечивает защиту от сетевых атак и проксирует запрос дальше, на сервер YMQ, уже в HTTP.
- HTTP-сервер YMQ реализует логику SQS HTTP API, проводит валидацию и переводит запрос в строго типизированный формат protobuf.
- YMQ Actor system – акторная система. В ней одновременно запущены тысячи различных акторов, обменивающихся информацией. Акторная система каждого хоста — это часть кластера. Все акторы кластера живут и действуют как единое целое. Бизнес-логика YMQ реализована в различных акторах, осуществляющих запросы-транзакции к YDB.
- YDB tablets («таблетки») – часть ядра YDB, которая отвечает за работу с таблицами в запросах и транзакциях. Сами таблетки не хранят данные. Это управляющие структуры в памяти, которые способны восстанавливать состояние в случае отказа оборудования.
- Storage – надёжное, распределённое, отказоустойчивое хранилище.
У такой архитектуры есть недостаток: все серверы в кластере независимо работают с таблицами одной и той же очереди. Это негативно влияет на производительность и мешает организовывать достоверные кэши скрытых и доступных для чтения сообщений. Сложно ограничивать поток запросов, а это очень важно для любого высоконагруженного сервиса.
Архитектура Yandex Message Queue с мастерами очередей
Нагрузочные стрельбы показали, что первый вариант архитектуры выдерживает около 450 сообщений в секунду на очередь с одним шардом. Это было очень мало.
Основной проблемой стал contention запросов. Большое количество логически конфликтующих транзакций быстро приводило кэши скрытых сообщений в несогласованное состояние. Для решения проблемы мы ввели особую сущность – мастер очередей (queue master).

Мастер очереди – актор, который в обычных условиях существует в кластере в единственном экземпляре и пропускает через себя все запросы, связанные с конкретной очередью. Если запрос к очереди приходит на сервер, где нужный мастер отсутствует, специальный прокси-актор перенаправляет запрос, а затем транслирует обратно полученный от мастера ответ.
При использовании мастера очередей правильный кэш незаблокированных сообщений снижает contention при работе с таблицами. Упрощается реализация ограничения потока запросов, например, через Leaky bucket. Доступны быстрые и точные метрики очереди: количество сообщений, общий трафик и тому подобное. Можно группировать однотипные запросы.
В теории у такой архитектуры есть определенные недостатки, связанные с централизацией:
- Снижение отказоустойчивости: если из строя выходит виртуальная машина с мастером, все очереди с мастерами на ней будут недоступны. Однако специальные механизмы YDB позволяют поднимать новые мастера внутри кластера буквально за несколько секунд. Это во многом решает проблему.
- Ограниченная масштабируемость: все запросы проходят через один хост. Недостаток нивелируют таблетки YDB. Именно они выполняют всю тяжелую работу с данными. А мастер асинхронно отправляет запросы и обрабатывает полученные результаты. Это делает его «лёгкой» сущностью, которая не создаёт эффект «бутылочного горлышка» при нагрузочном тестировании.
Батчинг запросов в мастерах очередей
Распределенные транзакции с таблицами базы данных ведут к определенным дополнительным расходам, поэтому идея уменьшить количество запросов казалась нам логичной. Сто транзакций на запись сообщений по одному лучше превратить в одну транзакцию на запись ста сообщений сразу. С мастерами очередей внедрить такую пакетную обработку (батчинг, batching) намного проще.

Батчинг несколько увеличивает задержки (latency) при выполнении операций. Взамен значительно увеличивается пропускная способность. С батчингом одношардовая очередь может обработать до 30 000 запросов в секунду.
Вообще загрузка у очередей бывает очень разной: и тысячи сообщений в секунду, и несколько сообщений в день. Нам нужно было оптимизировать работу с очередями с помощью гибкого алгоритма. Лобовые варианты с накоплением сообщений в буфере до порогового количества или сбросом по таймеру нас не устраивали. Поэтому мы разработали для YMQ алгоритм адаптивного батчинга, который хорошо работает в обоих случаях. Его работа показана в формате временной диаграммы.
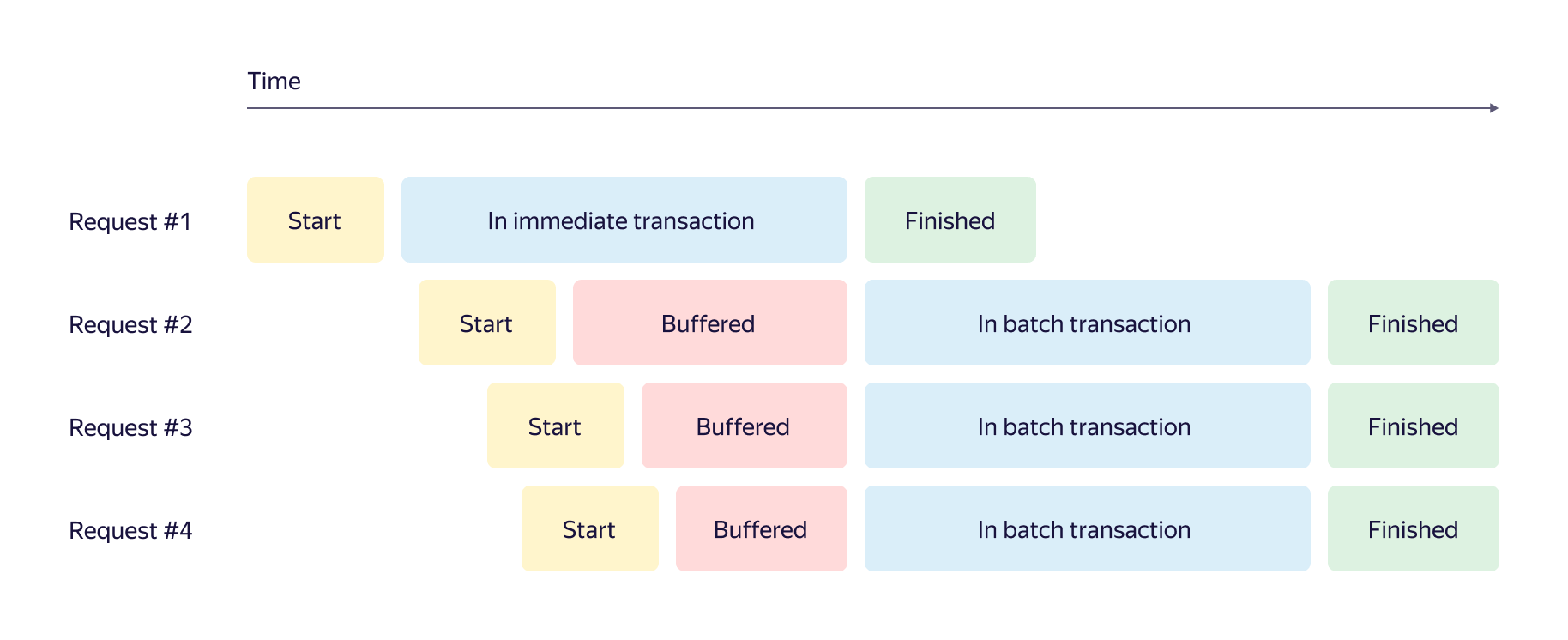
Здесь при поступлении нового сообщения возможен один из трёх сценариев:
- Транзакция запускается мгновенно, если нет других запущенных транзакций подобного типа.
- Если запущенные транзакции есть, сообщение добавляется в буфер и ждет завершения транзакций.
- Если размер буфера превысил пороговое значение, запускается еще одна параллельная транзакция. Количество параллельно выполняющихся транзакций ограничено.
Идея адаптивного батчинга напоминает алгоритм Нейгла для TCP/IP. И вот что интересно: по результатам нагрузочных тестов мы выяснили, что адаптивный батчинг немного уменьшает latency операций. Снижается количество одновременных транзакций, а вместе с ним и нагрузка на таблицы. По сумме факторов решение с адаптивным батчингом превзошло первое наивное решение во всех вариантах сценариев.
Что происходит с мастерами при возникновении проблем
В Yandex Message Queue, как и в любой распределённой системе, могут возникать чрезвычайные ситуации. Отказывают серверы, тормозят диски, рвётся сеть внутри и между дата-центрами.
В подобных случаях YDB в течение нескольких секунд автоматически переносит затронутые сбоем таблетки на более подходящие серверы внутри кластера. Мастера очередей YMQ переносятся вместе со своими таблетками.
Не во всех случаях возможно достоверно определить статус сервера по сети, поэтому бывают ситуации, когда новый мастер уже запущен, а старый ещё не прекратил работу.
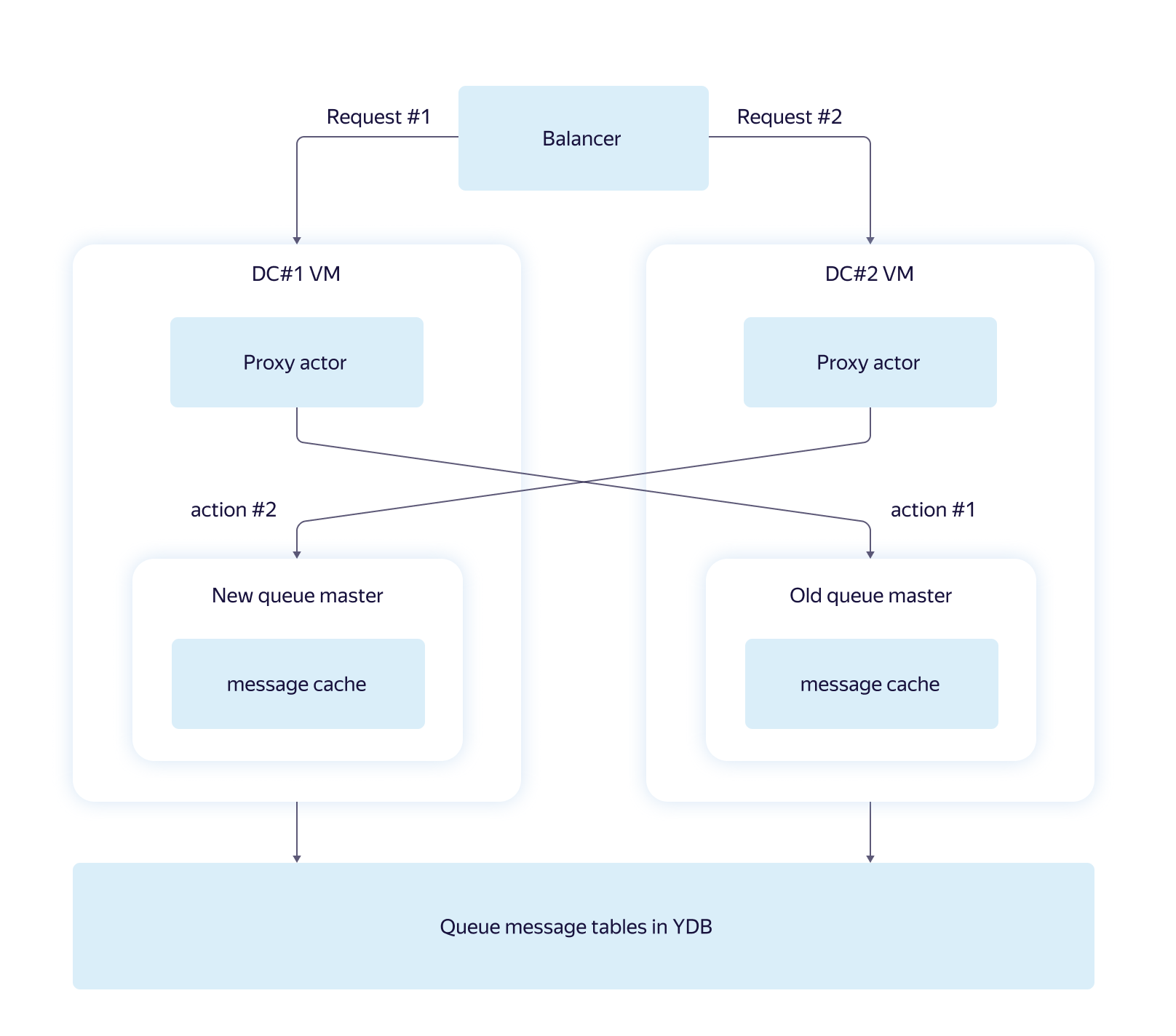
Для YMQ это не проблема. Запросы в базу не делают предположений о верности кэша видимых сообщений и проверяют каждое из них заново в процессе скрытия. Поэтому существование «лишних» мастеров приводит только к небольшому временному снижению производительности.
Как мы добились отказоустойчивости при создании очереди
В YDB невозможно создать несколько таблиц и модифицировать данные в рамках одной транзакции. Для нас это означало, что очередь, которая физически является набором таблиц, нельзя создать «транзакционно». При гонке в параллельных запросах или при отказах машин можно получить неконсистентное состояние, из которого невозможно выбраться без постороннего вмешательства. Мы подумали и разработали вот такую схему для решения проблемы.
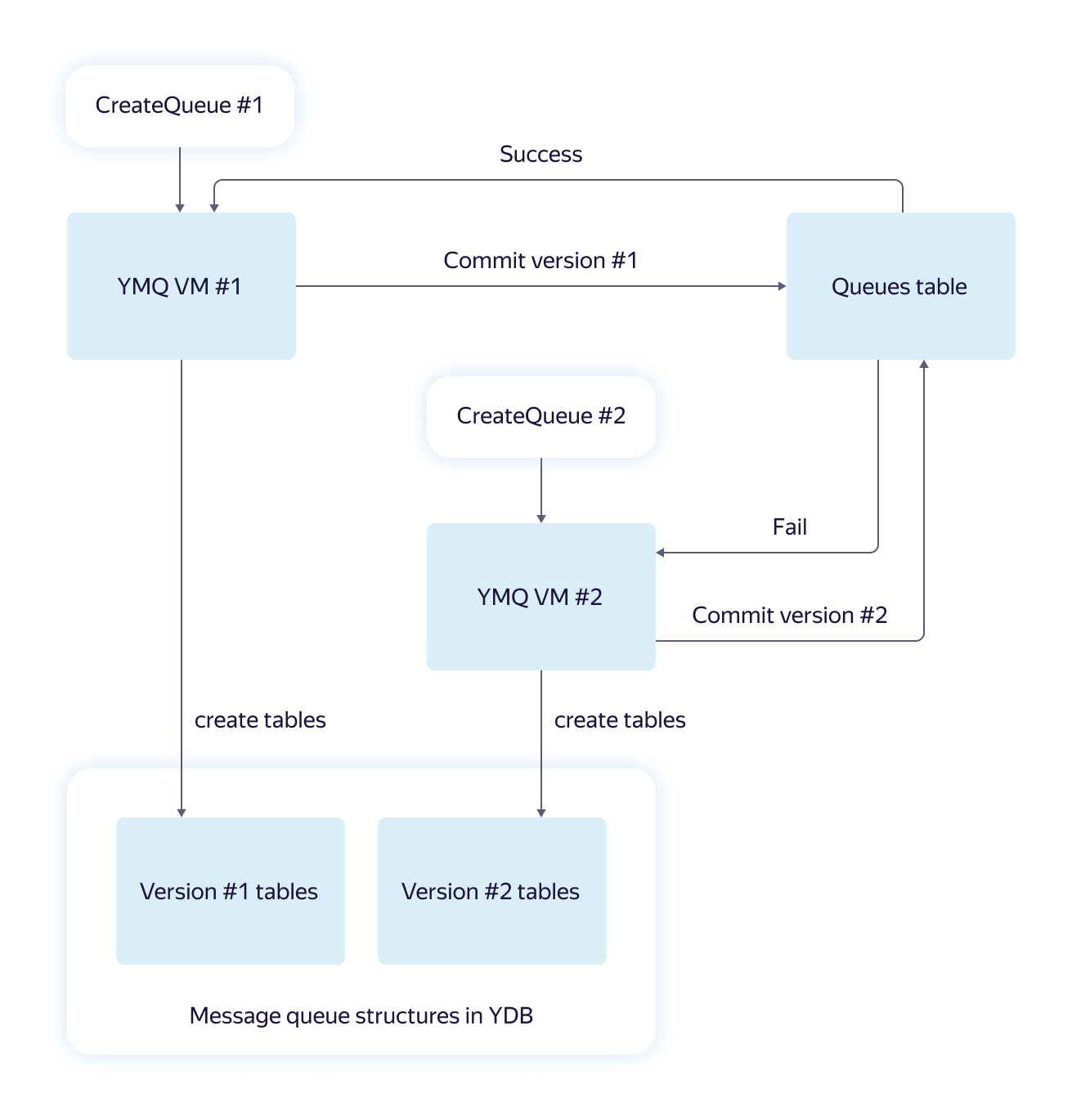
Основная идея такова: для каждого запроса на создание очереди необходимые структуры данных очереди создаются параллельно и независимо. Таким образом создаются версии, которые в конце «коммитятся» в виде строки в специальную таблицу. Выбирается версия-победитель, а все «проигравшие» запросы понимают, какая версия «победила», и возвращают корректную ссылку.
Такой алгоритм в парадигме «всё или ничего» устойчив к отказам по причине независимости создаваемых структур и наличия финальной транзакции с коммитом версии. Если коммит завершился успешно, можно считать, что запрашиваемая очередь создана правильно.
Как в Yandex Message Queue организованы тестирование и мониторинг
Yandex Message Queue – сложный программно-аппаратный комплекс. У него много возможных точек отказа. Мы должны быть уверены в качестве сервиса, который предоставляем. Поэтому мы регулярно его тестируем.
- Юнит-тесты проверяют корректность парсинга запросов, валидацию параметров, атрибутов и прочее. Эти тесты максимально быстрые и узконаправленные.
- Функциональные тесты позволяют удостовериться в полной работоспособности реализованного API в разных ситуациях, обычных и не очень. Достаточно длительные, обязательно прогоняются после каждого изменения кода в репозитории.
- Системные тесты занимаются тем, чем занимался бы реальный пользователь: создают и удаляют очереди, настраивают нужные параметры и затем прогоняют через них некоторое количество сообщений. Проверяют, что ничего не потерялось и не изменилось. Также проверяют граничные значения параметров и правильность обработки некорректного поведения. Реализованы с использованием библиотеки boto, работают в режиме 24/7, в том числе на продакшн-кластере под видом отдельного пользователя.
- Нагрузочные тесты используют тот же код, что и системные, но работают с повышенной частотой запросов и количеством сообщений. Неоднократно помогали нам находить узкие места в архитектуре.
Помимо прогона тестов важно следить за состоянием продакшна. Для этого у нас есть различные онлайн-проверки и графики с установленными пороговыми значениями и настроенными оповещениями. Оповещения приходят дежурным. В ежедневных дежурствах участвует вся наша команда.
В первую очередь мы отслеживаем:
- количество ошибок с кодом 5хх, которых в идеале вообще не должно быть;
- количество неуспешных транзакций YDB;
- загруженность процессоров, дисков, сети, акторной системы кластера;
- корректность и производительность работы модельной нагрузки, имитирующей действия реального пользователя;
- работоспособность виртуальных машин Яндекс.Облака с нашим сервисом и всего связанного оборудования.
Всё это помогает нам обеспечивать высокую надёжность и доступность сервиса усилиями небольшой команды и концентрироваться на развитии продукта.
В заключение
Задача инфраструктурных команд в Яндексе – создавать и поддерживать надёжные, масштабируемые и производительные решения, на основе которых можно быстро и успешно запускать новые продукты, улучшающие жизнь конечных пользователей. Внутри компании наш сервис очередей давно доказал свою полезность и стал частью архитектуры Яндекс.Видео, Яндекс.Маркета, Яндекс.Образования, Яндекс.Такси и других служб.
Теперь он доступен в экосистеме Яндекс.Облака и его можно использовать для построения сервисов внутри и вне самого Облака. Сейчас новые пользователи при регистрации получают денежный грант на ознакомление, так что попробовать Yandex Message Queue можно бесплатно.
Комментарии (21)

Peter03
11.06.2019 18:33Что может продвинуть использование подобных сервисов — это наличие reference clients для топ-10 языков.
Типа copy&paste код в свой проект и почти сразу можно пользоваться.
Еще можно было бы реализовать библиотеки которые мимикрируют под сервисы с подобной функциональностью. т.е. подключаешь библиотеку которая использует те-же namespace и имена классов/методов/функций что и конкурент. Позволит потестировать его практически без переделки приложения.andreystl
11.06.2019 19:26Как правильно отмечает librarian, так как интерфейс такой же, как у AWS SQS, можно использовать готовые AWS SDK для всех языков. Чуть позже мы и в нашу документацию добавим сэмплы кода для разных языков.
Вообще API YMQ настолько тривиален, что можно и так сразу пользоваться. :) Настраивать ничего не нужно, очередь создал и вперёд.
Что касается мимикрирования под другие сервисы — это интересная и правильная мысль, но тут зачастую просто реализацией клиента не обойдёшься, у других очередей другой набор функций, просто так не полетит. Либо надо на недостающие функции бросать исключения — и тогда далеко не все приложения протестируешь, либо доделывать недостающее в самом сервисе — а это уже дополнительное время на разработку. Но мы думаем в этом направлении.Peter03
11.06.2019 19:56так как интерфейс такой же, как у AWS SQS, можно использовать готовые AWS SDK для всех языков.
Я не про то что много примеров, а про то что иметь страничку, придя куда и выбрав свой язык и ответив на пару наводящих вопросов — получишь результат готовый к употреблению. Ключевой момент — в одном месте. Не искать по гитхабам и т.п., а взять у провайдера сервиса, без заморочек. Если будет такой dev-friendly подход, то многие по крайней мере попробуют. Новый продукт не хотят использовать в основном когда не желают инвестировать время и ресурсы в «чёрную лошадку», а если свести это к минимуму, то будет приятно отличать вас от конкурентов. Ну и конечно наличие бесплатного плана, чтобы свои пет-проекты на полторы калеки можно было поюзать без смс и регистрации.
но тут зачастую просто реализацией клиента не обойдёшься
По крайней мере можно сделать для тех где обойдёшься. А для многих других — можно не реализовывать методы которые не поддерживаешь. Если кто-то пользует крутой сервис с 80 фичами, но в реальности использует только две, то у него всё скомпилируется ок. А у того, у кого реально хитрые функции используются, у него просто не получится скомпилировать проект.Paskin
11.06.2019 22:29Если язык компилируемый — то проект собрать не получится в любом случае. А если понаставить заглушек «чтобы компилятор не ругался» — гарантированы лучи поноса от будущих пользователей.

mechatroner
12.06.2019 06:02Прикольно, респект разработчикам! Наверно, предполагается, что в будущем очередью можно будет управлять не только с помощью утилиты «aws», но и с помощью «yc»? А то сейчас как-то не логично, YCC управляется с yc, а YMQ с aws.
andreystl
12.06.2019 09:44Да, в будущем мы планируем добавить поддержку Облачного API и работы через
yc.

anshev0
12.06.2019 13:28+2Спасибо за статью.
Интересно, а какие Вы приведёте аргументы, чтобы сподвигнуть пользоваться YandexMQ вместо того же RabbitMQ или других облачных очередей?
На стороне RabbitMQ, что он open source, кроссплатформенный, бесплатный, проверенный годами, горизонтально масштабируемый, с плагинами для мониторинга, имеющий готовые библиотеки для множества языков, отлично работает на хостах в разных частях мира и т.д.
Например Яндекс.Облака — не бесплатные, поэтому стоит указать, что стоимость 30-38 р/млн. сообщений. Наверняка стоимость ниже чем у AWS или Azure. Посмотрел, что Azure даже 0.4$/mln без VAT, но как обычно в облачках дьявол кроется в деталях. )
Честно хочется узнать, может ещё кому будет интересно.andreystl
12.06.2019 16:07Отличный вопрос.
RabbitMQ — это действительно один из самых популярных и известных сервисов опенсорсных очередей. Поэтому и внутри Яндекса разные сервисы в своё время стали его использовать. Однако опыт реальной промышленной эксплуатации RabbitMQ нашими сервисами показывает, что не так всё хорошо:
— разворачивать и поддерживать кролика команде каждого сервиса нужно самостоятельно;
— он не всегда стабильно работает;
— если ломается, то надо чинить, иногда руками и это не всегда легко;
— в режиме high availability не обеспечивается надёжность сообщений — при отказах серверов кластера и переезде мастера очереди возможна потеря сообщений.
Из-за необходимости ручной работы бесплатность RabbitMQ достаточно условна, да и за серверы тоже нужно заплатить.
А у YMQ:
— сервис полностью управляемый (managed), то есть Облако всю поддержку осуществляет самостоятельно. Пришёл в UI/API, создал очередь — дальше работаешь с endpoint'ом, про поддержку сервиса не думаешь;
— вся архитектура как YMQ, так и Yandex Database построена таким образом, чтобы не терять данные даже при значительных сбоях — потерях дисков, серверов целиком, стоек серверов или даже датацентров. Если вы сделали SendMessage, и сервер ответил HTTP 200 OK, значит, сообщение надёжно записано и будет доступно для прочтения (мы не рассматриваем мегакатастрофы вроде метеоритов, уничтожающих одновременно все ДЦ Яндекса — если вы что-то знаете и планируете быть к такому готовыми, напишите в нам в техподдержку и мне в личку, желательно как можно скорее);
— YMQ гораздо более отказоустойчив, чем кролик, сообщение при записи синхронно пишется в три реплики в три датацентра (у кролика же репликация по WAN не рекомендуется). YMQ спокойно, без каких-либо потерь сообщений переживает не то что выход из строя сервера — датацентр целиком может выйти из строя и YMQ продолжит работать;
— графиков больше и они более информативные — очень часто, если проблема на стороне пользователя, то её причину можно установить прямо по графикам на дашборде, не нужно лезть в логи. Некоторые крайне полезные графики есть вообще только у нас — например, количество вычиток сообщений (сразу видно, если клиентское приложение сбоит и не с первого раза обрабатывает сообщения);
— с библиотеками тоже всё хорошо вследствие поддержки SQS API — можно брать AWS SDK для любого языка и пользоваться;
— в будущем Яндекс.Мониторинг обязательно позволит навешивать алерты на очереди YMQ.
И всё это всего лишь за 30,48 руб. за миллион (!) запросов.
Конечно, у RabbitMQ функциональность побогаче, и поддерживается больше протоколов, но мы обнаружили, что существующих в YMQ функций уже сейчас достаточно для реализации подавляющего большинства пользовательских сценариев. Если у вас есть сценарий, который не получается реализовать на нашем сервисе — напишите, это будет очень ценно.ya-radix Автор
12.06.2019 17:23Я ещё добавлю про важный момент: чтобы пользоваться нашими очередями, в Яндекс.Облаке свой сервис держать вовсе необязательно: endpoint сервиса доступен и снаружи. Правда при работе с сервисом из облачных VM вы не платите за трафик, только за запросы, что, конечно, выгоднее.
Shpall
12.06.2019 13:28+2Прошу прощения, мне показалось что ваше решение чем-то очень напоминает Apache Kafka. Вполне возможно, я многое путаю. Не могли бы рассказать, чем ваше решение принципиально отличается от той же самой кафки? Спасибо!
ya-radix Автор
12.06.2019 15:53Ну, и то, и другое — очереди сообщений :)
В остальном есть куча различий. Kafka больше про упорядоченные потоки данных (per partition) и exactly-once семантику (при определённых усилиях со стороны потребителя, конечно). Она хорошо масштабируется и позволяет прокачивать огромные объёмы данных. Но в то же время её API становится неудобным, если порядок неважен, а хочется обрабатывать сообщения в очереди независимо. С Kafka не получится так же легко построить очередь задач, как на основе YMQ. Например, в Celery она не поддерживается по этой причине — зато есть RabbitMQ, AWS SQS (а значит и YMQ) и другие.

blind_oracle
12.06.2019 14:36+1Производительность FIFO-очереди ограничена 30 запросами в секунду
Как-то все очень грустно по сравнению с той же Kafka которая дает примерно те же гарантии (fifo, exactly-once)andreystl
12.06.2019 16:05Всё верно, Kafka для сценария FIFO является одной из самых производительных очередей, но, как правильно пишет ya-radix в соседнем комментарии, FIFO в некоторых сценариях использования только мешает — если порядок не важен. Поэтому YMQ — это, в первую очередь, стандартные очереди c at least once и отсутствием порядка, а FIFO — дополнительная, нишевая функциональность для тех случаев, когда нужен FIFO, не нужна высокая нагрузка и не хочется использовать две разных системы.
В любом случае, это место мы тоже будем оптимизировать, если будет спрос на это. 30 RPS только выглядит скромно — это достаточно много, зачастую сервису нужно хорошо постараться, чтобы генерировать такой RPS, в большинстве случаев сервисам хватает единиц RPS.blind_oracle
12.06.2019 16:42+1FIFO в некоторых сценариях использования только мешает — если порядок не важен
Что-то мне сложно представить случаи когда он именно мешает. Не нужен — да, много случаев, но чтобы мешал…
30 RPS только выглядит скромно — это достаточно много, зачастую сервису нужно хорошо постараться, чтобы генерировать такой RPS, в большинстве случаев сервисам хватает единиц RPS.
Эээ… ну я даже не знаю что сказать. Наверное типовым клиентам Я и хватает 30 RPS, но городить очереди и прочее ради 30 RPS как-то смысла не вижу. Наверное проще очередь в табличке в MySQL держать :) Шутка, конечно, но в каждой шутке…
Я всё к тому что есть продукт №1 — Кафка. Она предоставляет fifo+exactly once с производительностью в десятки-сотни тысяч RPS на одной ноде в зависимости от.
И есть сабж, который с теми же гарантиями дает 30… или тысячу-другую без гарантий. Я всё понимаю, но разница уж очень большая.
В любом случае, начинание хорошее. Особенно в свете того что тот же Амазон часто берет какой-нибудь опенсурс продукт и начинает продавать его как сервис, что многим очень не нравится. Тут хотя бы своё :)andreystl
12.06.2019 17:19Что-то мне сложно представить случаи когда он именно мешает. Не нужен — да, много случаев, но чтобы мешал…
Например, если передаются сообщения, разброс времени обработки которых очень большой и сама обработка дорогая. Воркер обрабатывает «тяжёлое» сообщение минуту, за это время обрабатывается большое количество других сообщений. Если на обработке «тяжёлого» воркер падает, то все остальные успешно сообщения тоже надо заново переобрабатывать — прочтённые сообщения в партиции коммитятся по порядку, если какое-то ранее не закоммитили и упали, незакоммиченными будут и все следующие за ним.
Или другой пример — есть 100 партиций и 80 воркеров. Поровну не поделить, некоторые воркеры получат по две партиции. Если партиции «тяжёлые», воркеры с двумя партициями могут и не справляться. Нужно либо подгонять количество воркеров к количеству партиций — что может быть дорого и/или неудобно, либо количество партиций к воркерам — что та ещё задача, особенно если число воркеров меняется динамически. Здесь мешает не столько FIFO, сколько partition level parallelism, но это вещи связанные — порядок появляется как раз на потоке сообщений. Если бы был message level parallelism (и, соответственно, не было бы порядка), количество воркеров и партиций никак не были бы связаны.
Эээ… ну я даже не знаю что сказать. Наверное типовым клиентам Я и хватает 30 RPS, но городить очереди и прочее ради 30 RPS как-то смысла не вижу. Наверное проще очередь в табличке в MySQL держать :) Шутка, конечно, но в каждой шутке…
В БД в любом случае держать не надо, при росте нагрузки там неминуемо будут проблемы и придётся куда-то мигрировать. Поэтому даже при небольших RPS в тех местах, где нужна очередь, лучше сразу использовать очередь — это асинхронные взаимодействия, постановка задач, пересылка сообщений без необходимости получения ответа и т.п. Жить и развиваться будет сильно проще. Тем более что очередь использовать очень просто, это как раз таблички в БД нужно «городить» — придумывать схему, как-то её поддерживать и развивать, мигрировать, делать какую-то библиотеку для работы с этими табличками, наступать примерно на все грабли разработчиков очередей (в статье как раз раскрываются некоторые примеры таких граблей), потом упереться в то, как это всё добро на MySQL тормозит, полгода оптимизировать и понять, что написали своё подобие сервиса очередей. Кому всё это нужно в 2019 году — непонятно.
А в YMQ три основных вызова — SendMessage, ReceiveMessage и DeleteMessage. Предельно просто и понятно, подставляешь endpoint и реквизиты для доступа и вперёд.
Я всё к тому что есть продукт №1 — Кафка. Она предоставляет fifo+exactly once с производительностью в десятки-сотни тысяч RPS на одной ноде в зависимости от.
И есть сабж, который с теми же гарантиями дает 30… или тысячу-другую без гарантий. Я всё понимаю, но разница уж очень большая.
Сравнивать FIFO-очередь и Kafka бессмысленно, FIFO-очереди YMQ не ставят себе задачу заменить Kafka, в сценариях, где нужно передавать эти десятки тысяч RPS упорядоченных данных, нужно использовать заточенные под это инструменты — так, внутри Яндекса мы для передачи упорядоченных потоков тоже не используем FIFO-очереди YMQ, а используем Logbroker — наша собственная разработка система передачи данных, тоже поверх Yandex Database, и горизонтально масштабируется на огромные значения RPS и MB/s.
Даже стандартные очереди YMQ (которые уже сейчас при необходимости поддерживают те же десятки тысяч RPS в одну очередь, и это не предел оптимизаций) не стоит сравнивать с Kafka — функции и задачи у этих систем немного разные.
В простых сценариях, где сообщения не упорядочены и не требуется поддержка exactly once, нужно просто брать YMQ и не морочиться с нумерацией сообщений, количеством партиций и т.п.
В будущем, возможно, мы как раз будем предоставлять Logbroker в Яндекс.Облаке в том или ином виде, вот тогда можно будет вернуться к сравнению с Kafka.
gridem
13.06.2019 07:49Сравнивать FIFO-очередь и Kafka бессмысленно, FIFO-очереди YMQ не ставят себе задачу заменить Kafka
Сравнивать имеет смысл, т.к. решается одна и та же задача. А то, что у команды не было задачи конкурировать с Kafka — это вопросы, относящиеся к политической области, а не технической.
На мой взгляд, сравнение более, чем уместное: при одинаковых гарантиях Kafka выдает на многие порядки большую производительность. Тут возникает масса вопросов про эффективность.
Даже стандартные очереди YMQ (которые уже сейчас при необходимости поддерживают те же десятки тысяч RPS в одну очередь, и это не предел оптимизаций) не стоит сравнивать с Kafka — функции и задачи у этих систем немного разные.
Можно тут прояснить, в чем разница задач для очередей? Какие задачи выполняют распределенные очереди кроме той, чтобы хранить последовательность сообщений, добавлять и извлекать?
andreystl
13.06.2019 17:26Kafka передаёт данные с сохранением порядка, а стандартные очереди YMQ — без. Как я показал выше, есть сценарии, на которых это различие принципиально.
gridem
13.06.2019 17:43Тут я не очень понял. Можно сказать, что то, что Kafka сохраняет порядок — приятный бонус. Можно им не пользоваться, и тогда задачи становятся одинаковыми. А значит можно снова сравнивать, верно?
Получается, что у Kafka производительность выше во всех сценариях работы. Более того, Kafka предоставляет больше гарантий и возможностей. Думаю, вот в таком аспекте и можно сравнить.
timon_aeg
sdk нет?
andreystl
Есть, мы об этом пишем в разделе «Yandex Message Queue API» — так как YMQ поддерживает AWS SQS API, то для работы можно использовать широкий набор AWS SDK, предлагаемых для самых разных языков.
А также YMQ можно использовать в фреймворках и библиотеках, которые поддерживают SQS как транспорт — например, в Celery, Laravel и т.п.