
В статье пойдет речь о том, какую пользу оказывает логирование. Расскажу о логах по PSR. Добавлю немного личных рекомендаций по работе с уровнем, сообщением и контекстом логируемого события. Будет приведен пример, как можно организовать логирование и мониторинг с помощью ELK в приложении, написанном на Laravel и запущенном через Docker на нескольких инстансах. Распишу важное правило системы оповещения. Приведу пример скрипта, который поднимает одной командой весь стек мониторинга.
Польза логирования
Хорошо организованное логирование позволяет, как минимум, следующее:
- Знать о том, что что-то идёт не так, как задумано (есть ошибки)
- Знать подробности ошибки, которые помогут сказать, с кем и где произошла ошибка, и не допустить повтора
- Знать о том, что всё идёт как задумано (access.log, debug-, info-уровни)
Сама по себе запись в лог вам всего этого не скажет, но с помощью логов будет возможность самостоятельно узнать подробности событий, либо настроить систему мониторинга логов, которая будет иметь возможность оповещать о проблемах. Если сообщения в логах сопровождаются достаточным объемом контекста, то это значительно упрощает отладку, потому что вам будет доступно больше данных о ситуации, в которой произошло событие.
Чем писать и что писать
Частью php-сообщества разработаны рекомендации по некоторым задачам написания кода. Одна из таких рекомендаций PSR-3 Logger Interface. Она как раз описывает то, чем нужно логировать. Для этого разработан интерфейс Psr\Log\LoggerInterface пакета "psr/log". При его использовании нужно знать о трёх составляющих события:
- Уровень — важность события
- Сообщение — текст, описывающий событие
- Контекст — массив дополнительной информации о событии
Уровни события по PSR-3
Уровни заимствованы из RFC 5424 — The Syslog Protocol, примерное описание их следующее:
- debug — Подробная информация для отладки
- info — Интересные события
- notice — Существенные события, но не ошибки
- warning — Исключительные случаи, но не ошибки
- error — Ошибки исполнения, не требующие сиюминутного вмешательства
- critical — Критические состояния (компонент системы недоступен, неожиданное исключение)
- alert — Действие требует безотлагательного вмешательства
- emergency — Система не работает
Описание есть, но следовать им не всегда получается легко, из-за сложности определения важности некоторых событий. Например, в контексте одного запроса не удалось выполнить обращение к подключаемому ресурсу. При записи этого события мы не знаем, один ли такой запрос завершился неудачей, а может только у одного пользователя такие запросы завершаются неудачей. От этого зависит, требуется безотлагательное вмешательство или это редкий случай, может подождать или даже его можно проигнорировать. Такие вопросы решаются в рамках мониторинга логов. Но уровень определить всё равно надо. Поэтому об уровнях логирования в команде можно договориться. Пример:
- emergency — это уровень для внешних систем, которые могут посмотреть на вашу систему и точно определить, что она полностью не работает, либо не работает её самодиагностика.
- alert — система сама может продиагностировать своё состояние, например, задачей по расписанию, и в результате записать событие с этим уровнем. Это могут быть проверки подключаемых ресурсов или что-то конкретное, например, баланс на счету используемого внешнего ресурса.
- critical — событие, когда сбой даёт компонент системы, который очень важен и всегда должен работать. Это уже сильно зависит от того, чем занимается система. Подходит для событий, о которых важно оперативно узнать, даже если оно произошло всего раз.
- error — произошло событие о, котором при скором повторении нужно сообщить. Не удалось выполнить действие, которое обязательно должно быть выполнено, но при этом такое действие не попадает под описание critical. Например, не удалось сохранить аватарку пользователя по его запросу, но при этом система не является сервисом аватарок, а является чат-системой.
- warning — события, для немедленного уведомления о которых нужно набрать значительное их количество за период времени. Не удалось выполнить действие, невыполнение которого ничего серьезного не ломает. Это всё ещё ошибки, но исправление которых может ждать рабочего расписания. Например, не удалось сохранить аватарку пользователя, а система — интернет-магазин. Уведомление о них нужно (при высокой частоте), чтобы узнать о внезапных аномалиях, потому что они могут быть симптомами более серьезных проблем.
- notice — это события, которые сообщают о предусмотренных системой отклонениях, которые являются частью нормального функционирования системы. Например, пользователь указал неправильный пароль при входе, пользователь не заполнил отчество, но оно и не обязательно, пользователь купил заказ за 0 рублей, но у вас такое предусмотрено в редких случаях. Уведомление по ним при высокой частоте тоже нужно, так как резкий рост числа отклонений может быть результатом допущенной ошибки, которую срочно нужно исправить.
- info — события, возникновение которых сообщает о нормальном функционировании системы. Например, пользователь зарегистрировался, пользователь приобрел товар, пользователь оставил отзыв. Уведомление по таким событиями нужно настраивать в обратном виде: если за период времени произошло недостаточное количество таких событий, то нужно уведомить, потому что их снижение могло быть вызвано в результате допущенной ошибки.
- debug — события для отладки какого-либо процесса в системе. При добавлении достаточного количества данных в контекст события можно произвести диагностику проблемы, либо заключить об исправном функционировании процесса в системе. Например, пользователь открыл страницу с товаром и получил список рекомендаций. Значительно увеличивает количество отправляемых событий, поэтому допустимо убирать логирование таких событий через некоторое время. Как результат, количество таких событий в нормальном функционировании будет переменным, тогда и мониторинг для уведомления по ним можно не подключать.
Сообщение события
По PSR-3 сообщение должно быть либо строкой, либо объектом с методом __toString(). Кроме того, по PSR-3 строка сообщения может содержать плейсхолдеры вида ”User {username} created”, которые могут быть заменены значениями из массива контекста. При использовании Elasticsearch и Kibana для мониторинга я рекомендую не использовать плейсхолдеры, а писать фиксированные строки, потому что это упростит фильтрацию событий, а контекст всегда будет рядом. Кроме того, предлагаю обратить внимание на дополнительные требования к сообщению:
- Текст должен быть коротким, но значимым. Это то, что будет приходить в алертах, и что будет в списках произошедших событий.
- Тексту лучше быть уникальным для разных частей программы. Это позволит из алерта, не заглядывая в контекст, понять, в какой части произошло событие.
Контекст события
Контекст события по PSR-3 это массив (можно вложенный) значений переменных, например, ID сущностей. Контекст можно оставить пустым, если по сообщению всё понятно о событии. В случае логирования исключения следует передавать всё исключение, а не только getMessage(). При использовании Monolog через NormalizerFormatter из исключения будут автоматически извлечены полезные данные и добавлены в контекст события, в том числе и стектрейс. То есть нужно вместо
[
'exception' => $exception->getMessage(),
]использовать
[
'exception' => $exception,
]В Laravel можно для событий автоматически вписывать в контекст данные. Это можно сделать через Global Log Context (только для непойманных исключений или через report()), либо через LogFormatter (для всех событий). Обычно, добавляется информация с id текущего пользователя, request URI, IP, request UUID и подобное.
При использовании Elasticsearch в качестве хранилища логов следует помнить, что в нём используются фиксированные типы данных. То есть, если вы передавали в контексте customer_id числом, то при попытке сохранить событие с другим типом, например строкой (uuid), то такое сообщение не запишется. Типы в индексе фиксируются при первом получении значения. Если индексы создаются каждый день, то новый тип запишется только на следующий день. Но даже это не избавит от всех проблем, потому что для Kibana типы будут смешанными и часть операций, привязанных к типу, будет недоступна пока будут смешанные индексы.
Для предотвращения этой проблемы рекомендую придерживаться правил:
- Не использовать слишком общие имена ключей, которые могут быть разного типа
- Делать явное приведение к типу значений, если нет уверенности в его типе
Пример: вместо
[
'response' => $response->all(),
'customer_id' => $id,
'value' => $someValue,
]использовать
[
'smsc_response_data' => json_encode($response->all()),
'customer_id' => (string) $customer_id,
'smsc_request_some_value' => (string) $someValue,
]Вызов логгера из кода
Для быстрой записи события в лог можно придумать несколько вариантов. Рассмотрим некоторые из них.
- Объявить глобальную функцию
log()и вызывать её из разных частей программы. У такого подхода много недостатков. Например, в классах, где мы обращаемся к этой функции, образуется неявная зависимость. Этого следует избегать. Кроме этого такой логгер сложно настраивать, когда в системе нужно иметь несколько разных. Другой недостаток, если мы говорим о работе с Laravel, то, что мы не используем возможности, предоставляемые фреймворком для решения этой проблемы. - Использовать Laravel фасад \Log. С таким подходом части системы, которые обращаются к этому фасаду, начинают зависеть от фреймворка. В частях системы, которые мы не собираемся выносить из-под фреймворка, такое решение вполне подойдет. Например, писать из некоторых экземпляров консольной команды, фоновой задачи, контроллера. Или когда уже есть запутанная структура сервисов, и прокинуть экземпляр логгера в них не так просто.
- Резолвить зависимость логгера через хелперы фреймворка
app()иresolve(). Подход имеет те же недостатки, что и использование фасада, но при этом нужно чуть больше писать кода. - Указывать зависимость от логгера в конструкторе класса, который этот логгер будет использовать. При этом в качестве типа следует указывать тот самый
LoggerInterface, чтобы соблюсти DIP. Благодаря autowiring фреймворков, зависимости автоматически разрешатся в реализации по их объявленным абстракциям. В Laravel в некоторые классы зависимости можно указать в отдельном методе, вместо того, чтобы указывать в конструкторе всего класса.
Где в коде вызывать логгер
При организации кода в проекте может возникнуть вопрос, в каком классе мне следует писать в лог. Должен ли это быть сервис? Или это нужно делать там, откуда сервис вызываем: контроллер, фоновая задача, консольная команда? Или каждое исключение само должно решать, что ему писать в лог с помощью его метода report (Laravel)? Простого ответа сразу на все вопросы нет.
Рассмотрим возможность, данную Laravel, делегировать классу исключения задачу логировать себя. Исключение не может знать, насколько оно критично для системы, чтобы определить уровень события. Кроме того, у исключения нет доступа к контексту, если его специально не добавлять при вызове этого исключения. Чтобы вызов метода render на исключении произошел, нужно либо не поймать исключение (будет использован глобальный ErrorHandler), либо поймать и использовать глобальный хелпер report(). Такой способ позволяет не вызывать PSR-3 логгер каждый раз, где мы это исключение можем поймать. Но не думаю, что ради этого стоит давать исключению такую ответственность.
Может показаться, что мы всегда можем логировать только в сервисах. Действительно, в некоторых сервисах можно сделать логирование. Но рассмотрим сервис, который не зависит от проекта и, вообще, мы планируем вынести его в отдельный пакет. Тогда этот сервис не знает о своей важности в проекте, а, значит, не сможет определить уровень логирования. Например, сервис интеграции с конкретным SMS-шлюзом. Если мы получили сетевую ошибку, то это ещё не значит, что она достаточно серьезная. Возможно, в системе есть сервис интеграции с другим SMS-шлюзом, через который будет вторая попытка отправки, тогда ошибку от первого можно репортить как warning, а ошибку второго как error. Только вот все эти интеграции должны быть вызваны из другого сервиса, который как раз и будет логировать. Получается, что ошибка в одном сервисе, а логируем в другом. Но иногда у нас нет сервиса-обёртки над другим сервисом — мы вызываем сразу из контроллера. В этом случае я считаю допустимым писать в лог в контроллере вместо того, чтобы писать сервис-декоратор для логирования.
Пример, показывающий использование зависимости и передачу контекста:
<?php
namespace App\Console\Commands;
use App\Services\ExampleService;
use Illuminate\Console\Command;
use Psr\Log\LoggerInterface;
class Example extends Command
{
protected $signature = 'example';
public function handle(ExampleService $service, LoggerInterface $logger)
{
try {
$service->example();
} catch (\Exception $exception) {
$logger->critical('Example error', [
'exception' => $exception,
]);
}
}
}
Куда писать
Рассмотрим следующие варианты.
- Согласно 12 факторному приложению и некоторым другим рекомендациям, писать нужно в stdout, stderr среды выполнения приложения. Для этого можно указать в config логгера
php://stdout*. - Игнорировать 12-factor, docker-way и писать в файлы. Laravel (Monolog) позволяют даже настроить ротацию логов. Далее сообщения из файлов можно собрать с помощью Filebeat и отправить в Logstash для разбора.
- Отправлять логи из приложения напрямую дальше, например, по UDP для увеличения производительности.
- Комбинировать решения. Писать в файлы, которые с помощью Filebeat будут собраны и отправлены в Logstash. Писать в stderr контейнера, чтобы получить возможность использовать команды
docker logsи быть готовым к удобному сбору логов из среды оркестрации контейнеров. При этом можно некоторые каналы писать только локально, некоторые отправлять по сети.
* В php-fpm 7.2 при записи логов в stdout получаем "WARNING: [pool www] child X said into stdout...", и длинные сообщения обрезаются. Одно из решений этой проблемы здесь. В php-fpm 7.3 такой проблемы нет.
Варианты формата записи:
- Человекочитаемый (переносы строк, отступы и прочее)
- Машиночитаемый (обычно, json)
- Оба формата одновременно: машиночитаемый в stdout для дальнейшей маршрутизации, человекочитаемый на случай внезапных проблем с маршрутизацией и быстрого дебага
Любой из вариантов предполагает, что логи подвергаются маршрутизации — как минимум, отправке в единую систему обработки (хранения) логов по следующим причинам:
- Долгосрочное хранение и архивация
- Построение крупномасштабных графиков трендов
- Гибкая система оповещения о событиях
У докера есть возможность указать диспетчер логов. По умолчанию — json-file, то есть, докер складывает вывод из контейнера в json-file на хосте. Если мы выбираем диспетчер логов, который будет отправлять записи куда-то по сети, то мы больше не сможем использовать команду docker logs. Если stdout/stderr контейнера был выбран единственным местом для записи логов приложения, то в случае сетевых проблем или проблем у единого хранилища, быстро извлечь записи для дебага может не получиться.
Мы можем использовать json-file докера и Filebeat. Получим и локальные логи и дальнейшую маршрутизацию. Стоит заметить здесь ещё одну особенность докера. При записи события длиной больше 16KB докер разбивает запись символом \n, что путает многие сборщики логов. Об этом есть issue. Проблему со сторону докера решить не удалось, поэтому её решили со стороны сборщиков. С некоторой версии Filebeat поддерживает такое поведение докера и корректно объединяет события.
Какую комбинацию всех возможностей мест назначений и форматов записи выбрать вы можете решить для вашего проекта самостоятельно.
Использование Filebeat + ELK + Elastalert
Кратко роль каждого сервиса можно описать так:
- Filebeat — собирает события из файлов и отправляет
- Logstash — парсит события и отправляет
- Elasticsearch — хранит структурированные события
- Kibana — выводит события (графики, агрегации и т.п.)
- Elastalert — отправляет алерты на основе запросов
Дополнительно можно: zabbix, metricbeat, grafana и прочее.
Теперь подробнее о каждом.
Filebeat
Можно запускать как отдельной службой на хосте, можно отдельным докер-контейнером. Для работы с потоком событий из docker использует путь хоста /var/lib/docker/containers/*/*.log. Filebeat имеет широкий набор опций, которыми можно задать поведение в различных ситуациях (файл переименован, файл удалён и тому подобное). Filebeat может сам парсить json внутри события, но в события может попасть и не json, что приведет к ошибке. Всю обработку событий лучше произвести в одном месте.
filebeat.inputs:
- type: docker
containers:
ids:
- "*"
processors:
- add_docker_metadata: ~
Logstash
Умеет принимать события от многих источников, но здесь мы рассматриваем Filebeat.
В каждом событии кроме самого события из stdout/stderr есть метаданные (хост, контейнер и т. п.). Много встроенных фильтров обработки: парсить по регуляркам, разбирать json, изменять, добавлять, удалять поля и т. п. Подходит для парсинга как логов приложения, так и nginx access.log в произвольном формате. Умеет передавать данные в разные хранилища, но здесь рассматриваем Elasticsearch.
if [status] {
date {
match => ["timestamp_nginx_access", "dd/MMM/yyyy:HH:mm:ss Z"]
target => "timestamp_nginx"
remove_field => ["timestamp_nginx_access"]
}
mutate {
convert => {
"bytes_sent" => "integer"
"body_bytes_sent" => "integer"
"request_length" => "integer"
"request_time" => "float"
"upstream_response_time" => "float"
"upstream_connect_time" => "float"
"upstream_header_time" => "float"
"status" => "integer"
"upstream_status" => "integer"
}
remove_field => [ "message" ]
rename => {
"@timestamp" => "event_timestamp"
"timestamp_nginx" => "@timestamp"
}
}
}Elasticsearch
Elasticsearch очень мощный инструмент для большого спектра задач, но с целью мониторинга логов его можно использовать зная лишь некоторый минимум.
Сохраненные события — это документ, документы хранятся в индексах.
Каждый индекс — это схема, в которой определен тип для каждого поля документа. Нельзя сохранить событие в индексе, если хотя бы у одного поля неподходящий тип.
Разные типы позволяют делать разные операции над группой документов (для чисел — sum, min, max, avg и т. п., для строк — нечеткий поиск и так далее).
Для логов руководства обычно рекомендуют использовать дневные индексы — каждый день новый индекс.
Обеспечение стабильной работы Elasticsearch с ростом объема данных — задача, требующая более глубоких знаний об этом инструменте. Но быстрым решением проблемы стабильности можно выбрать автоматическое удаление устаревших данных. Для этого я предлагаю разбивать в logstash уровни событий по разным индексам. Это позволит дольше хранить редкие, но более важные события.
output {
if [fields][log_type] == "app_log" {
if [level] in ["DEBUG", "INFO", "NOTICE"] {
elasticsearch {
hosts => "${ES_HOST}"
index => "logstash-app-log-debug-%{+YYYY.MM.dd}"
}
} else {
elasticsearch {
hosts => "${ES_HOST}"
index => "logstash-app-log-error-%{+YYYY.MM.dd}"
}
}
}
}Для автоматического удаления устаревших индексов предлагаю использовать программу от Elastic Curator. Запуск программы добавляется в расписание Cron, сама конфигурация может храниться в отдельном файле.
action: delete_indices
description: logstash-app-log-error
options:
ignore_empty_list: True
filters:
- filtertype: pattern
kind: prefix
value: logstash-app-log-error-
- filtertype: age
source: name
direction: older
timestring: '%Y.%m.%d'
unit: months
unit_count: 6Для долговечного хранения событий предлагаю использовать альтернативные системы хранения, которые могут быть подключены как сервисы приёма от Filebeat или Logstash, либо полностью отдельно. В недавних версиях Elasticsearch ввели разбиение на горячие-теплые-холодные индексы, возможно, их следует вам рассмотреть.
Kibana
Kibana здесь используется как инструмент для чтения журнала событий. Это веб-приложение, которое выполняет запросы к Elasticsearch. Позволяет строить дашборды с разными визуализациями показателей.
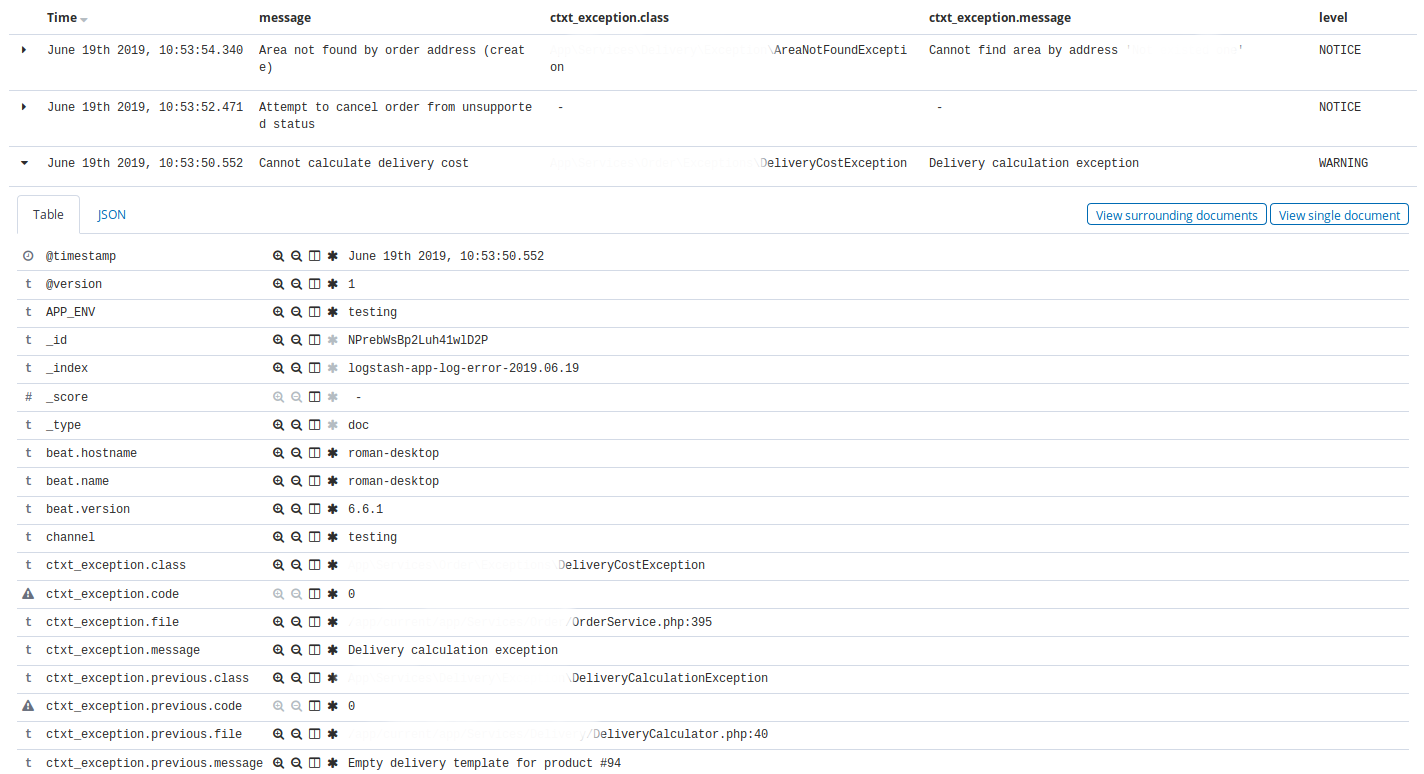
Типичное использование Kibana — это ежедневный просмотр списка недавних событий в разделе Discovery с некоторыми фильтрами. Например, отдельная страница Discovery с отображением списка недавних событий из app с уровнем warning и выше, где выводятся столбцы time, message, exception class, host, client_id.
Другой пример, страница Discovery с отображением списка недавних событий из nginx, у которых неуспешные статусы и не 404 с отображением столбцов time, message, request, status.
Кроме того Kibana используется для дебага, так как в ней можно быстро отфильтровать события: по сообщению, по уровню, по любому значению из контекста. Например, выбрать все события по конкретному клиенту (делается в один клик по одному событию нужного клиента).
Elastalert
Elastalert используется для выполнения запросов к Elasticsearch и оповещению на основе их результатов. Другими словами, алертинг. Есть широкий набор типов правил, с помощью которых можно построить эффективную систему оповещения об отклонениях.
Для каждого правила можно указать расписание запуска, интервал для повторной отправки по тому же условию (реалерт), список сервисов для оповещения и многое другое.
Некоторые примеры правил:
- Не должно быть событий с уровнем ALERT, EMERGENCY. Реалерт — 10 минут
- Не должно быть событий с уровнем CRITICAL. Реалерт — 30 минут
- Не должно быть больше, чем N событий уровня X за M минут
- Должны быть минимум 10 INFO за 3 часа
- Процент ответов nginx с кодом 200, 201, 304 должен быть не ниже 75% за час, если было хотя бы 50 событий
name: Blacklist ALERT, EMERGENCY
type: blacklist
index: logstash-app-*
compare_key: "level"
blacklist:
- "ALERT"
- "EMERGENCY"
realert:
minutes: 5
alert:
- "slack"
При подключении автоматических оповещений о событиях следует не допустить очень серьезную ошибку — слишком частое оповещение. Я рекомендую настраивать автоматическое оповещение таким образом, чтобы уведомления шли только по событиям, требующим безотлагательного вмешательства. Всё остальное нужно привыкать смотреть самостоятельно используя Kibana.
Если вы настроили правило, например, что успешных http-кодов должно быть не менее 75% за час, затем получили оповещение об отклонении, проверили и обнаружили, что ничего страшного не произошло, то правило нужно менять. Если какое-то правило постоянно срабатывает, но ничего критичного не происходит, и уже нечего менять в правиле, то лучше его отключить совсем.
Если ваша система постоянно дает сбой неделю за неделей, то, скорее всего, вы и сами уже знаете, чего ждать в списке событий в Kibana, поэтому отключите автоматические уведомления и проверяйте состояние вручную.
Рекомендую границу в 5 уведомлений в неделю в среднем. Если их получается больше, значит, это уже не внезапные отклонения, а ожидаемые, а значит, уведомления по ним не нужны.
Я уделил особое внимание частоте оповещений, потому что нарушение этого правила приводит к полному игнорированию оповещений. Это сводит пользу автоматических уведомлений на нет.
При получении оповещения хорошей привычкой может стать обзор ситуации через просмотр Kibana по всем недавним событиям. Это позволит точнее оценить ситуацию и корректно расставить приоритеты при решении проблемы.
Всё вместе
Всё описанное можно запускать в docker-контейнерах. Причём всё конфигурируется таким образом, что всем стеком можно пользоваться как локально при разработке, так и в staging- и production-окружениях, где переменными остаются только переменные окружения.
Все описанные сервисы, за исключением Elastalert, позволяют использовать переменные окружения в конфигурациях. Проблему Elastalert удалось разрешить, используя команду вида
envsubst < /opt/elastalert/config.dist.yaml > /opt/elastalert/config.yaml в entrypoint-скрипте и доустановкой зависимостей, чтобы это работало.
Конфигурации каких сервисов стека оставлять в репозитории проекта, а какие выносить в отдельный репозиторий мониторинга, зависит от наличия других проектов и того, как они будут переиспользовать стек.
build:
docker build -t some-registry/elasticsearch elasticsearch
docker build -t some-registry/logstash logstash
docker build -t some-registry/kibana kibana
docker build -t some-registry/nginx nginx
docker build -t some-registry/curator curator
docker build -t some-registry/elastalert elastalert
push:
docker push some-registry/elasticsearch
docker push some-registry/logstash
docker push some-registry/kibana
docker push some-registry/nginx
docker push some-registry/curator
docker push some-registry/elastalert
pull:
docker pull some-registry/elasticsearch
docker pull some-registry/logstash
docker pull some-registry/kibana
docker pull some-registry/nginx
docker pull some-registry/curator
docker pull some-registry/elastalert
prepare:
docker network create -d bridge elk-network || echo "ok"
stop:
docker rm -f kibana || true
docker rm -f logstash || true
docker rm -f elasticsearch || true
docker rm -f nginx || true
docker rm -f elastalert || true
run-logstash:
docker rm -f logstash || echo "ok"
docker run -d --restart=always --network=elk-network --name=logstash -p 127.0.0.1:5001:5001 -e "LS_JAVA_OPTS=-Xms256m -Xmx256m" -e "ES_HOST=elasticsearch:9200" some-registry/logstash
run-kibana:
docker rm -f kibana || echo "ok"
docker run -d --restart=always --network=elk-network --name=kibana -p 127.0.0.1:5601:5601 --mount source=elk-kibana,target=/usr/share/kibana/optimize some-registry/kibana
run-elasticsearch:
docker rm -f elasticsearch || echo "ok"
docker run -d --restart=always --network=elk-network --name=elasticsearch -e "ES_JAVA_OPTS=-Xms1g -Xmx1g" --mount source=elk-esdata,target=/usr/share/elasticsearch/data some-registry/elasticsearch
run-nginx:
docker rm -f nginx || echo "ok"
docker run -d --restart=always --network=elk-network --name=nginx -p 80:80 -v /root/elk/.htpasswd:/etc/nginx/.htpasswd some-registry/nginx
run-elastalert:
docker rm -f elastalert || echo "ok"
docker run -d --restart=always --network=elk-network --name=elastalert --env-file=./elastalert/.env some-registry/elastalert
run: prepare run-elasticsearch run-kibana run-logstash run-elastalert
delete-old-indices:
docker run --rm --network=elk-network -e "ES_HOST=elasticsearch:9200" some-registry/curator curator --config /curator/curator.yml /curator/actions.ymlТакой вариант стека имеет следующие преимущества:
- Снаружи доступен только 80 порт nginx, который проксирует запросы по basic auth к Kibana
- Порт Logstash тоже закрыт. Доступ к нему производится с помощью ssh-туннеля
- Одной командой поднимается весь стек кроме nginx
- Отдельными командами можно пересобирать, перезапускать docker-образы
- Отдельными командами можно произвести переразвертывание новой версии одного из образов
- Сервисы автоматически запускаются при перезагрузке сервера или внутреннем сбое
- Разворачивается одинаково в локальном и боевом окружении, отличаясь .env-файлом алертинга и файлом nginx-паролем
- Параметры *_JAVA_OPTS подобраны таким образом, чтобы весь стек стабильно работал на одном инстансе с 4GB RAM (зависит от потока событий и длительности хранения в ES).
Стоит заметить, что в данном подходе не используется ни один из xpack-плагинов.
Допустим вариант использования docker-compose. Главное, что основная конфигурация, состоящая из Dockerfile-ов, конфига Filebeat, конфигов Logstash, правил оповещения, правил автоудаления индексов, находится под системой контроля версий, получая возможность быстрого переразвертывания, хранения истории изменений и всех других преимуществ VCS.
Важно уделять внимание автоматической проверки работоспособности стека. Я предлагаю организовать проверку следующим образом. В самом приложении создается задача, исполняемая по расписанию (в Laravel для этого есть scheduler), скажем, раз в неделю за 5 минут до дейлимитинга. Сама задача вызывает логгер и записывает сообщение с уровнем ALERT. Если весь стек функционирует нормально, то вы получите оповещение. Если такого оповещения нет, а вы к нему привыкли, то это станет сигналом для разбирательств.
Заключение
Я описал, какую пользу можно извлечь из логирования, рассказал о некоторых вариантах, которые можно выбирать на каждом шаге построения стека логирования и мониторинга. Привёл пример стека с описанием каждого компонента. Надеюсь, вы нашли что-то полезное для себя в этом материале. Данные мной рекомендации были опробованы на нескольких проектах и хорошо себя показали в бою. Но следует помнить, что всегда есть, что улучшить.
Комментарии (14)

mmasiukevich
19.06.2019 12:49но из-за особенности php-fpm в официальном образе docker получаем в docker logs
7.3 спешит на помощь, не?
getId Автор
19.06.2019 13:14Всё верно, в 7.3 такой особенности больше нет. Содержимое поста немного устарело.
mmasiukevich
19.06.2019 14:33а зачем оно тогда в статье?
getId Автор
19.06.2019 14:39Я уже сделал пометку в статье о том, для какой версии это было актуально. Оставил, чтобы показать, с какими трудностями раньше приходилось сталкиваться и как их можно было решить.

Nashev
21.06.2019 15:11Я не очень уловил границу описания былых трудностей. Может, их оформить как-то более заметно? Типа врезки в журнале?
getId Автор
21.06.2019 15:35+1Переписал начало раздела «Куда писать». Вынес описание проблемы о php-fpm 7.2 в сноску со звездочкой. Врезка цитатой выглядит здесь слишком яркой для такой отсылки.
ZurgInq
19.06.2019 13:09Согласно 12 факторному приложению, писать нужно в stdout, stderr среды выполнения приложения.
Люди бездумно продолжают ссылаться на правила конфигурирования приложений для облачной платформы heroku как на эталон. Если вы разворачиваете приложение не на heroku, то не стоит пытаться следовать всем этим злополучным «12 factor».
Почему heroku говорит, что надо отправлять логи исключительно в stdout? У heroku просто нет другого нормального способа сохранить логи, так как файловая система при любом перезапуске может сбросится в чистое состояние. Если вы разворачиваете приложение на одной единственной машине, то можете писать логи куда вам удобно, не оглядываясь, как это надо делать на heroku.getId Автор
19.06.2019 13:32Писать логи в stdout/stderr — это рекомендация не только Heroku. Упоминания этой практики в отношении контейнеров можно найти и в других источниках, например, cloud.google.com/solutions/best-practices-for-operating-containers
О том, что можно писать в файлы и собирать их, я тоже упомянул.
gecube
19.06.2019 17:04С файлами вообще очень интересно. Сейчас мода на то, чтобы все засовывать в докер. Так вот. При прочих равных файл внутри контейнера всегда пишется в эфемерную файловую систему суть есть последний слой запущенного контейнера докера (который можно превратить в образ путем docker commit). Так вот. В одной из дискуссий обратили внимание, что вообще желательно все файлы, которые генерирует приложение ЛИБО класть в tmpfs, ЛИБО в VOLUME (заранее определенный в Dockerfile, либо ключами -v/--mount при запуске контейнера) — они тогда, во-первых, персистируют между перезапусками контейнера (tmpfs же чистится) и, во-вторых, это дешевле по iops и нагрузке на cpu, чем писать в эфемерную ФС (внезапно, ога?).
Поэтому писать в stdout/stderr — вполне норм рекомендация, тем более, что тот же systemd по умолчанию логи тоже в таком же виде ждет от приложения (можете сами проверить).
В общем, мойте руки перед едой.
p.s. с stdout/stderr есть другие нюансы, о которых мне указали мои коллеги, но которые выходят за обсужденные выше моменты.
getId Автор
20.06.2019 05:29Очень любопытно. Поделитесь, пожалуйста, другими нюансами.
gecube
20.06.2019 07:19getId https://habr.com/ru/post/450098/#comment_20105786
Например, это
Ну, и, вообще, добро пожаловать в профильную группу по логам в Телеграм: @ru_logsgetId Автор
20.06.2019 07:28Спасибо. Я правильно понял позицию по ссылке, что приложение должно само сразу писать во внешний приёмник логов по сети?
gecube
20.06.2019 07:50+1Мое мнение, что это отстой. Но сколько людей — столько мнений.
У записи в удаленное хранилище логов приложением есть свои плюсы. Например, можно более удобно контролировать, что должно попасть в логи. Можно сразу писать структурированные логи (json), не боясь, что по дороге кто-то их порежет или криво сконвертирует. В минусах — это не решает проблему гарантированной доставки. Если шлете в условный эластик, а он "прилёг", то Ваше приложение легко может заблокироваться на записи в него. Но здесь больше играют более системные вопросы — а допустимо ли, чтобы логи иногда терялись. ИБшники, например, скорее будут топить за целостность системы, а не за ее доступность (оно и понятно — мало ли в логах что интересное будет, а по закону Мерфи именно их и пролюбили). Ops'ы же будут, напротив, за доступность и отказоустойчивость. Для них логи — это очень приятное дополнение для расследования проблем и мониторинга отказов
gecube
Добавлю. В docker-ce таких драйверов два: json-file и journald. Рекомендую присмотреться ко второму, т.к. он не отменяет использование docker logs, но зато позволяет пользоваться всеми прелестями journalctl (включая автоматический тротлинг, если место кончилось, и ротацию логов). Дополнительно в docker-ee можно использовать команду docker logs и для остальных драйверов:
https://docs.docker.com/config/containers/logging/configure/