
За последний год мы перенесли внушительную часть настроек DirectCRM в базу данных. Множество элементов промо-кампаний, которые мы до этого описывали исключительно кодом, теперь создаются и настраиваются менеджером через админку. При этом получилась очень сложная структура БД, насчитывающая десятки таблиц.
Однако, за перенос настроек в базу данных пришлось расплачиваться. Об архитектуре, позволяющий кэшировать редко меняющиеся Linq to SQL сущности, смотрите под катом.
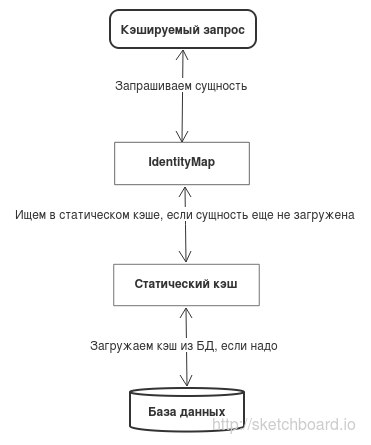
Основным агрегатом настроек системы является промо-кампания. В промо-кампанию входит множество элементов: триггерные рассылки, призы и операции, которые потребитель может совершить на сайте. У каждого элемента есть множество настроек, которые ссылаются на другие сущности в базе. В итоге получается дерево с большой вложенностью. Чтобы вытащить это дерево, необходимо совершить десятки запросов к БД, которые негативно сказываются на производительности.
Изначально было понятно, что придется приписывать кэширование кампаний, но мы строго следовали первому правилу оптимизации — не оптимизировать, пока производительность системы нас удовлетворяет. Но, конечно же, в итоге настал момент когда без кэширования уже жить было нельзя.
Вопросов, в какой момент должен сбрасывать кэш, не было — его нужно обновлять при любом изменении кампании или ее элемента (так как кампания является агрегатом, никаких сложностей в реализации такой логики не возникает). А вот над вопросом, где этот кэш хранить и каким образом его сбрасывать, пришлось немного задуматься. Были рассмотрены следующие варианты:
Вариант с использованием Redis привлекателен, так как позволяет держать только одну копию кэша для всех WEB-серверов, а не загружать его для каждого сервера, но по факту — это экономия на спичках: кампании после окончания настройки меняются редко и не важно, будет ли кэш загружен четыре раза в день или шестнадцать. Так как никаких распределенных транзакций между Redis и БД нет, сложно гарантировать, что при изменении кампании будет сброшен кэш, поэтому первый вариант отпадает.
У третьего варианта есть следующие преимущества перед вторым:
В общем, проблема и общий подход к решению ясны. Дальше пойдут технические подробности.
Для того, чтобы полноценно использовать в рамках текущего DataContext сущности загруженные в другом DataContext, их необходимо клонировать и зааттачить. При аттаче сущность добавляется в IdentityMap текущего DataContext. Зааттачить одну и ту же сущность к двум разным DataContext нельзя (поэтому каждый клон может использоваться только в одном DataContext, т. е. в одной бизнес транзакции). MemberwiseClone для клонирования использовать нельзя, так как при этом в клоне будут ссылки на сущности, зааттаченные к DataContext, в котором сущность была загружена, а не к текущем DataContext.
В итоге для того, чтобы можно было использовать сущности из статического кэша, в базовом классе репозитория был написан следующий код, использующий Linq MetaModel и немного Reflection:
Чтобы при клонировании, при проходе по EntityRef и EntitySet, не выгрузить половину БД, клонируются только те, которые помечены специальным атрибутом CacheableAssociationAttribute.
Так как кэш загружается в отдельном DataContext, и клонирование происходит уже после его Dispose, нам пришлось написать метод, который подгружает все кэшируемые ассоциации у загружаемой сущности:
Конечно же, если использовать DataLoadOptions, то понадобится меньше запросов для загрузки EntityRef. Но мы даже не думали заниматься динамическим построением DataLoadOptions, потому что в Linq to SQL есть баг, из-за которого при использовании DataLoadOptions для загрузки EntitySet некорректно загружается тип сущности (дискриминатор типа игнорируется и вместо дочернего типа загружается родительский).
Так как доступ к записям в БД у нас происходит через репозитории, обращения к кэшу я также вынес туда. При попытке получить кампанию или элемент кампании происходит следующее:
При таком подходе мы аттачим только те кампании, которые нам нужны и проверяем актуальность кэша (дату изменения кампании) только один раз за транзакцию (один раз за время жизни DataContext). Так как в репозиториях есть множество методов для получения элементов кампаний (по Id, по кампании, по уникальному строковому идентификатору) структура данных кэша получилась сложной, но с этим можно жить.
Новая архитектура кэширования прошла все интеграционные тесты и была успешно выложена на Production одного из проектов. Все стабильно работало и ничто не предвещало беды.
После выкладки кэша на очередной проект, массово повалились ошибки: «DuplicateKeyException: cannot add an entity with a key that is already in use» при аттаче кампании к текущему DataContext. Первая мысль: «Мы ошиблись где-то в своем рекурсивном коде клонирования и аттачим одну и ту же сущность два раза.» — оказалась неверной. Ошибка была более концептуальной.
Виноват оказался код в конечном проекте, обращавшийся к кампании без использования кэша перед тем, как происходил аттач этой же кампании из кэша. Как я писал выше, при аттаче сущность добавляется в IdentityMap, но если перед этим сущность уже была загружена из БД, то она уже есть в IdentiyMap и попытка добавить сущность с тем же ключом вызывает ошибку. Linq to SQL не позволяет проверить есть ли сущность в IdentityMap перед аттачем. А если отлавливать и игнорировать ошибки при аттаче, кэширование получилось бы неполноценным.
Была идея убрать у репозиториев, работающих с кэшем, возможность обращаться к базе минуя кэш. Кроме того, что это далеко непростая задача, это не решило бы проблему полностью, так как у многих некэшируемых сущностей имеются EntityRef на кэшируемые сущности, а при обращении к EntityRef запрос идет минуя репозиторий.
Есть два варианта решения этой проблемы:
Первый вариант потребовал бы переписать половину кода. При этом получившийся код был бы более громоздким, так как везде, где было обращение к EntityRef, пришлось бы использовать методы репозиториев. Так что пришлось остановиться на втором варианте.
Так как мы аттачим сущности при создании DataContext, а не при обращении к конкретным сущностям, нам придется в начале транзакции явно указывать какие сущности из кэша нам понадобятся (загружать весь кэш каждый раз было бы явно излишним). То есть выбранный подход — это не универсальное кэширование; он всего лишь позволяет тонко настраивать использование кэша для отдельных транзакций.
В некоторых наших репозиториях результаты запросов по Id к сущностям кэшировались на время транзакции в Dictionary. По факту этот кэш транзакции можно считать нашим IdentityMap, используемым поверх IdentityMap Linq to SQL. Нам оставалось только перенести кэш транзакции в базовый репозиторий и добавить в него методы доступа не только по Id, но и другими способами. В итоге, получился класс кэша транзакций, при доступе к которому любым способом каждая сущность загружается не более одного раза. Если мы, например, запросим сущность сначала по Id, а потом по уникальному строковому идентификатору, то второй запрос выполнен не будет и метод доступа вернет сущность из кэша.
Так как у нас в любом репозитории теперь есть кэш транзакции, для поддержки статического кэширования достаточно при создании DataContext заполнять кэш транзакции из статического кэша, не забывая при этом клонировать и аттачить каждую сущность. Все это выглядит следующим образом:

Если говорить конкретно о кэшировании кампаний, то загрузка статического кэша работает так:
Далее можно по мере необходимости настраивать кэширование для других транзакций. Кроме статического кэша для кампаний были созданы общие классы для статического кэширования словарей, которые меняются только при выкладке приложения. Т.е. кэширование любых сущностей, для которых не нужно проверять актуальность кэша, включить очень легко. В дальнейшем хочется расширить этот функционал, добавив возможность сбрасывать кэш через определенное время, либо за счет простых запросов в БД. Возможно, получится переделать кэширование кампаний на использование стандартных классов статического кэша с нужными настройками.
Хотя получившаяся архитектура выглядит стройно и позволяет однообразно реализовать разные виды кэширования, необходимость в начале транзакции явно указывать, какие сущности нам понадобятся, не радует. Кроме того, для того чтобы подгрузить все нужные в транзакции сущности и при этом не аттачить к контексту кучу лишних объектов, нужно знать устройство транзакции во всех подробностях.
Есть еще один вариант реализации кэша, который, к сожалению, нельзя реализовать в Linq to SQL — заменить стандартный IdentityMap своей реализацией, которая перед добавлением сущности пытается получить ее из кэша. При таком подходе кэшируемая сущность, загруженная любым способом, будет заменяться на свою копию из кэша, у которой уже загружены все EntityRef и EntitySet. Таким образом, не нужно будет делать никаких подзапросов для их получения. Если при этом добавить в наиболее часто используемые методы репозитория поиск сущности в IdentityMap перед запросом к БД, то количество запросов к БД сократится радикально. При этом искать в IdentityMap перед запросом можно любые сущности, а не только те, для которых используется статическое кэширование. Так как после получения любой сущности из БД она заменяется на свою копию из IdentityMap (если она уже там есть), за время жизни DataContext нельзя получить две разные копии одной сущности, даже если она была изменена в другой транзакции (всегда будет возвращаться первая загруженная сущность). Поэтому нет никакого смысла два раза за транзакцию запрашивать сущность, например, по ключу, и любые запросы по ключу на время транзакции можно кэшировать за счет проверки IdentityMap перед запросом.
Попыткой реализовать эту архитектуру мы займемся после того, как перейдём на Entity Framework. EF позволяет получать сущности из IdentityMap, так что как минимум частично архитектуру удастся улучшить.
Однако, за перенос настроек в базу данных пришлось расплачиваться. Об архитектуре, позволяющий кэшировать редко меняющиеся Linq to SQL сущности, смотрите под катом.
Основным агрегатом настроек системы является промо-кампания. В промо-кампанию входит множество элементов: триггерные рассылки, призы и операции, которые потребитель может совершить на сайте. У каждого элемента есть множество настроек, которые ссылаются на другие сущности в базе. В итоге получается дерево с большой вложенностью. Чтобы вытащить это дерево, необходимо совершить десятки запросов к БД, которые негативно сказываются на производительности.
Изначально было понятно, что придется приписывать кэширование кампаний, но мы строго следовали первому правилу оптимизации — не оптимизировать, пока производительность системы нас удовлетворяет. Но, конечно же, в итоге настал момент когда без кэширования уже жить было нельзя.
Вопросов, в какой момент должен сбрасывать кэш, не было — его нужно обновлять при любом изменении кампании или ее элемента (так как кампания является агрегатом, никаких сложностей в реализации такой логики не возникает). А вот над вопросом, где этот кэш хранить и каким образом его сбрасывать, пришлось немного задуматься. Были рассмотрены следующие варианты:
- хранить кэш в Redis и очищать при редактировании кампании
- хранить кэш в Redis и перед каждым использованием делать запрос в БД для проверки, не поменялась ли дата кампании
- хранить кэш в памяти процесса и перед каждым использованием делать запрос в БД для проверки, не поменялась ли дата кампании
Вариант с использованием Redis привлекателен, так как позволяет держать только одну копию кэша для всех WEB-серверов, а не загружать его для каждого сервера, но по факту — это экономия на спичках: кампании после окончания настройки меняются редко и не важно, будет ли кэш загружен четыре раза в день или шестнадцать. Так как никаких распределенных транзакций между Redis и БД нет, сложно гарантировать, что при изменении кампании будет сброшен кэш, поэтому первый вариант отпадает.
У третьего варианта есть следующие преимущества перед вторым:
- для получения кэша нужно выполнить один запрос по сети вместо двух
- не надо возиться с сериализацией (даже если для этого достаточно поставить DataMemberAttribute у нужных полей)
В общем, проблема и общий подход к решению ясны. Дальше пойдут технические подробности.
Версия 1.0
Для того, чтобы полноценно использовать в рамках текущего DataContext сущности загруженные в другом DataContext, их необходимо клонировать и зааттачить. При аттаче сущность добавляется в IdentityMap текущего DataContext. Зааттачить одну и ту же сущность к двум разным DataContext нельзя (поэтому каждый клон может использоваться только в одном DataContext, т. е. в одной бизнес транзакции). MemberwiseClone для клонирования использовать нельзя, так как при этом в клоне будут ссылки на сущности, зааттаченные к DataContext, в котором сущность была загружена, а не к текущем DataContext.
В итоге для того, чтобы можно было использовать сущности из статического кэша, в базовом классе репозитория был написан следующий код, использующий Linq MetaModel и немного Reflection:
код
public TEntity CloneAndAttach(TEntity sourceEntity)
{
if (sourceEntity == null)
throw new ArgumentNullException("sourceEntity");
var entityType = sourceEntity.GetType();
var entityMetaType = GetClonningMetaType(entityType);
var entityKey = entityMetaType.GetKey(sourceEntity);
// Проверка, не позволяющая клонировать одну и ту же сущность более одного раза.
// Кроме прочего помогает разобраться с циклическими ссылками.
if (attachedEntities.ContainsKey(entityKey))
{
return attachedEntities[entityKey];
}
var clonedObject = Activator.CreateInstance(entityType);
var clonedEntity = (TEntity)clonedObject;
attachedEntities.Add(entityKey, clonedEntity);
// клонируем поля
foreach (var dataMember in entityMetaType.Fields)
{
var value = dataMember.StorageAccessor.GetBoxedValue(sourceEntity);
dataMember.StorageAccessor.SetBoxedValue(ref clonedObject, value);
}
// клонируем EntityRef'ы
foreach (var dataMember in entityMetaType.EntityRefs)
{
var thisKeyValues = dataMember.Association.ThisKey
.Select(keyDataMember => keyDataMember.StorageAccessor.GetBoxedValue(sourceEntity))
.ToArray();
if (thisKeyValues.All(keyValue => keyValue == null))
{
continue;
}
var repository = Repositories.GetRepositoryCheckingBaseTypeFor(dataMember.Type);
var value = repository.CloneAndAttach(dataMember.MemberAccessor.GetBoxedValue(sourceEntity));
dataMember.MemberAccessor.SetBoxedValue(ref clonedObject, value);
}
// клонируем EntitySet'ы
foreach (var dataMember in entityMetaType.EntitySets)
{
var repository = Repositories
.GetRepositoryCheckingBaseTypeFor(dataMember.Type.GenericTypeArguments[0]);
var sourceEntitySet = (IList)dataMember.MemberAccessor.GetBoxedValue(sourceEntity);
var clonedEntitySet = (IList)Activator.CreateInstance(dataMember.Type);
foreach (var sourceItem in sourceEntitySet)
{
var clonedItem = repository.CloneAndAttach(sourceItem);
clonedEntitySet.Add(clonedItem);
}
dataMember.MemberAccessor.SetBoxedValue(ref clonedObject, clonedEntitySet);
}
table.Attach(clonedEntity);
return clonedEntity;
}
private ClonningMetaType GetClonningMetaType(Type type)
{
ClonningMetaType result;
// Информация о клонируемом типе кэшируется в статическом ConcurrentDictionary, чтобы не юзать Reflection каждый раз
if (!clonningMetaTypes.TryGetValue(type, out result))
{
result = clonningMetaTypes.GetOrAdd(type, key => new ClonningMetaType(MetaModel.GetMetaType(key)));
}
return result;
}
private class ClonningMetaType
{
private readonly MetaType metaType;
private readonly IReadOnlyCollection<MetaDataMember> keys;
public ClonningMetaType(MetaType metaType)
{
this.metaType = metaType;
keys = metaType.DataMembers
.Where(dataMember => dataMember.IsPrimaryKey)
.ToArray();
Fields = metaType.DataMembers
.Where(dataMember => dataMember.IsPersistent)
.Where(dataMember => !dataMember.IsAssociation)
.ToArray();
EntityRefs = metaType.DataMembers
.Where(dataMember => dataMember.IsPersistent)
.Where(dataMember => dataMember.IsAssociation)
.Where(dataMember => !dataMember.Association.IsMany)
.Where(dataMember => dataMember.Member.HasCustomAttribute<CacheableAssociationAttribute>())
.ToArray();
EntitySets = metaType.DataMembers
.Where(dataMember => dataMember.IsPersistent)
.Where(dataMember => dataMember.IsAssociation)
.Where(dataMember => dataMember.Association.IsMany)
.Where(dataMember => dataMember.Member.HasCustomAttribute<CacheableAssociationAttribute>())
.ToArray();
}
public IReadOnlyCollection<MetaDataMember> Fields { get; private set; }
public IReadOnlyCollection<MetaDataMember> EntityRefs { get; private set; }
public IReadOnlyCollection<MetaDataMember> EntitySets { get; private set; }
public ItcEntityKey GetKey(object entity)
{
return new ItcEntityKey(
metaType,
keys.Select(dataMember => dataMember.StorageAccessor.GetBoxedValue(entity)).ToArray());
}
}
Чтобы при клонировании, при проходе по EntityRef и EntitySet, не выгрузить половину БД, клонируются только те, которые помечены специальным атрибутом CacheableAssociationAttribute.
Так как кэш загружается в отдельном DataContext, и клонирование происходит уже после его Dispose, нам пришлось написать метод, который подгружает все кэшируемые ассоциации у загружаемой сущности:
код
public void LoadEntityForClone(TEntity entity)
{
// Проверка, устраняющая проблемы с циклическими ссылками
if (loadedEntities.Contains(entity))
{
return;
}
loadedEntities.Add(entity);
var entityType = entity.GetType();
var entityMetaType = GetClonningMetaType(entityType);
// Загружаем все EntityRef'ы
foreach (var dataMember in entityMetaType.EntityRefs)
{
var repository = Repositories.GetRepositoryCheckingBaseTypeFor(dataMember.Type);
var value = dataMember.MemberAccessor.GetBoxedValue(entity);
if (value != null)
{
repository.LoadEntityForClone(value);
}
}
// Загружаем все EntitySet'ы
foreach (var dataMember in entityMetaType.EntitySets)
{
var repository = Repositories
.GetRepositoryCheckingBaseTypeFor(dataMember.Type.GenericTypeArguments[0]);
var entitySet = (IList)dataMember.MemberAccessor.GetBoxedValue(entity);
foreach (var item in entitySet)
{
repository.LoadEntityForClone(item);
}
}
}
Конечно же, если использовать DataLoadOptions, то понадобится меньше запросов для загрузки EntityRef. Но мы даже не думали заниматься динамическим построением DataLoadOptions, потому что в Linq to SQL есть баг, из-за которого при использовании DataLoadOptions для загрузки EntitySet некорректно загружается тип сущности (дискриминатор типа игнорируется и вместо дочернего типа загружается родительский).
Так как доступ к записям в БД у нас происходит через репозитории, обращения к кэшу я также вынес туда. При попытке получить кампанию или элемент кампании происходит следующее:
- Проверяется, была ли кампания уже добавлена в текущий DataContext из кэша. Если да, то возвращаем объект, который уже был клонирован и зааттачен.
- В случае, если, кампании нет в кэше, загружаем её в кэш. Иначе сравниваем дату последнего изменения кампании в БД с датой последнего изменения у кампании, хранящейся в кэше, и если они отличаются, перезагружаем кампанию.
- Клонируем и аттачим кампанию и все ее элементы в текущий DataContext.
При таком подходе мы аттачим только те кампании, которые нам нужны и проверяем актуальность кэша (дату изменения кампании) только один раз за транзакцию (один раз за время жизни DataContext). Так как в репозиториях есть множество методов для получения элементов кампаний (по Id, по кампании, по уникальному строковому идентификатору) структура данных кэша получилась сложной, но с этим можно жить.
Новая архитектура кэширования прошла все интеграционные тесты и была успешно выложена на Production одного из проектов. Все стабильно работало и ничто не предвещало беды.
Что-то пошло не так
После выкладки кэша на очередной проект, массово повалились ошибки: «DuplicateKeyException: cannot add an entity with a key that is already in use» при аттаче кампании к текущему DataContext. Первая мысль: «Мы ошиблись где-то в своем рекурсивном коде клонирования и аттачим одну и ту же сущность два раза.» — оказалась неверной. Ошибка была более концептуальной.
Кто виноват
Виноват оказался код в конечном проекте, обращавшийся к кампании без использования кэша перед тем, как происходил аттач этой же кампании из кэша. Как я писал выше, при аттаче сущность добавляется в IdentityMap, но если перед этим сущность уже была загружена из БД, то она уже есть в IdentiyMap и попытка добавить сущность с тем же ключом вызывает ошибку. Linq to SQL не позволяет проверить есть ли сущность в IdentityMap перед аттачем. А если отлавливать и игнорировать ошибки при аттаче, кэширование получилось бы неполноценным.
Была идея убрать у репозиториев, работающих с кэшем, возможность обращаться к базе минуя кэш. Кроме того, что это далеко непростая задача, это не решило бы проблему полностью, так как у многих некэшируемых сущностей имеются EntityRef на кэшируемые сущности, а при обращении к EntityRef запрос идет минуя репозиторий.
Что делать
Есть два варианта решения этой проблемы:
- Убрать у кэшируемых репозиториев возможность обращаться к БД минуя кэш и убрать у всех некэшируемых сущностей ссылки на кэшируемые.
- Аттачить кэш при создании DataContext до того как будут выполнены любые другие запросы к БД.
Первый вариант потребовал бы переписать половину кода. При этом получившийся код был бы более громоздким, так как везде, где было обращение к EntityRef, пришлось бы использовать методы репозиториев. Так что пришлось остановиться на втором варианте.
Так как мы аттачим сущности при создании DataContext, а не при обращении к конкретным сущностям, нам придется в начале транзакции явно указывать какие сущности из кэша нам понадобятся (загружать весь кэш каждый раз было бы явно излишним). То есть выбранный подход — это не универсальное кэширование; он всего лишь позволяет тонко настраивать использование кэша для отдельных транзакций.
Новая архитектура
В некоторых наших репозиториях результаты запросов по Id к сущностям кэшировались на время транзакции в Dictionary. По факту этот кэш транзакции можно считать нашим IdentityMap, используемым поверх IdentityMap Linq to SQL. Нам оставалось только перенести кэш транзакции в базовый репозиторий и добавить в него методы доступа не только по Id, но и другими способами. В итоге, получился класс кэша транзакций, при доступе к которому любым способом каждая сущность загружается не более одного раза. Если мы, например, запросим сущность сначала по Id, а потом по уникальному строковому идентификатору, то второй запрос выполнен не будет и метод доступа вернет сущность из кэша.
Так как у нас в любом репозитории теперь есть кэш транзакции, для поддержки статического кэширования достаточно при создании DataContext заполнять кэш транзакции из статического кэша, не забывая при этом клонировать и аттачить каждую сущность. Все это выглядит следующим образом:
Если говорить конкретно о кэшировании кампаний, то загрузка статического кэша работает так:
- В фабрику, создающую DataContext вместе со всем репозиториями, передается IQueryable от кампаний, описывающий какие кампании нам понадобятся.
- Одним запросом вытаскиваются Id и дата последнего изменения кампаний из переданного IQueryable.
- Для каждой кампании вытащенная дата сверяется с датой этой кампании в кэше и, в случае отличия, кампания вместе со всеми ее элементами перезагружается.
- Все вытащенные из статического кэша сущности аттачатся и загружаются в кэши транзакций соответствующих репозиториев.
Что дальше
Далее можно по мере необходимости настраивать кэширование для других транзакций. Кроме статического кэша для кампаний были созданы общие классы для статического кэширования словарей, которые меняются только при выкладке приложения. Т.е. кэширование любых сущностей, для которых не нужно проверять актуальность кэша, включить очень легко. В дальнейшем хочется расширить этот функционал, добавив возможность сбрасывать кэш через определенное время, либо за счет простых запросов в БД. Возможно, получится переделать кэширование кампаний на использование стандартных классов статического кэша с нужными настройками.
Хотя получившаяся архитектура выглядит стройно и позволяет однообразно реализовать разные виды кэширования, необходимость в начале транзакции явно указывать, какие сущности нам понадобятся, не радует. Кроме того, для того чтобы подгрузить все нужные в транзакции сущности и при этом не аттачить к контексту кучу лишних объектов, нужно знать устройство транзакции во всех подробностях.
Есть еще один вариант реализации кэша, который, к сожалению, нельзя реализовать в Linq to SQL — заменить стандартный IdentityMap своей реализацией, которая перед добавлением сущности пытается получить ее из кэша. При таком подходе кэшируемая сущность, загруженная любым способом, будет заменяться на свою копию из кэша, у которой уже загружены все EntityRef и EntitySet. Таким образом, не нужно будет делать никаких подзапросов для их получения. Если при этом добавить в наиболее часто используемые методы репозитория поиск сущности в IdentityMap перед запросом к БД, то количество запросов к БД сократится радикально. При этом искать в IdentityMap перед запросом можно любые сущности, а не только те, для которых используется статическое кэширование. Так как после получения любой сущности из БД она заменяется на свою копию из IdentityMap (если она уже там есть), за время жизни DataContext нельзя получить две разные копии одной сущности, даже если она была изменена в другой транзакции (всегда будет возвращаться первая загруженная сущность). Поэтому нет никакого смысла два раза за транзакцию запрашивать сущность, например, по ключу, и любые запросы по ключу на время транзакции можно кэшировать за счет проверки IdentityMap перед запросом.
Попыткой реализовать эту архитектуру мы займемся после того, как перейдём на Entity Framework. EF позволяет получать сущности из IdentityMap, так что как минимум частично архитектуру удастся улучшить.
bushart
Почему сложно гарантировать, что при изминение админки будет сброшен кешь? В чем сложность?
Youkai Автор
Необходимо, чтобы кэш гарантированно сбрасывался в случае успешного редактирования кампании. Для этого придется делать что-то вроде распределенной транзакции между Redis'ом и MS-SQL. В принципе можно редактирование кампании сделать так:
Так как и редактирование кампании и загрузка кэша происходит в транзакции с уровнем изоляции Serializable, то загрузка кэша будет ждать завершения редактировании кампании. Однако такой подход добавляет зависимость админки от кэша (кэш не работает — редактировании кампании не работает) и сервисов от админки (пока редактируется кампания — все запросы сервисов ждут).
Альтернативный вариант — по окончании редактирования кампании добавлять в очередь Rabbit сообщение с командой на сброс кэша. Затем в windows-сервисе, где у нас обрабатываются сообщения, будет гарантированно сброшен кэш, но с некоторой задержкой, что в принципе приемлемо. При этом надо еще гарантировать, что команда на сброс кэша будет добавлена в очередь (правда распределенные транзакции между SQL и Rabbit мы уже сделали — об этом в следующей статье напишем).
bushart
А зачем вы такие вещи как сброс кеша делаете асинхронными (т.е. используете очереди команда, вместо прямого общение сервис ту сервис)? И почему ожидается, что очередь на сброс кеша будет работать с задержкой?
Youkai Автор
Сброс кэша мы не делали асинхронным. Его можно бы было сделать через очередь, чтобы кэш был сброшен даже в случае падения запроса к Redis (если не удалось сбросить кэш, повторяем пока не получится). В случае использовании очереди будет задержка, но в общем то совсем небольшая — максимум несколько миллисекунд, так что можно было про это и не упоминать, наверное.
Если мы просто дергаем сброс кэша после редактирования кампании, то в случае если запрос на сброс кэша упадет, у нас останется старая версия кампании до тех пор пока кэш не устареет, что не очень приятно. Причем хотелось бы, чтобы период устаревания кэша был побольше (в текущей реализации кэш вообще не устаревает со временем — он обновляется, только если кампания изменилась).
bushart
А от куда взялись опасения, что запрос на сброс кеша может провалиться? На моем опыте не было случаев, чтоб сервисы кеширования, работающие в штатном режиме давали отбой на сброс кеша.
Youkai Автор
Может упасть timeout, могут быть проблемы с сетью, сервер кэша может не ответить из-за слишком большой нагрузки и т.д. Мы логируем все ошибки и случаи падения запросов к Redis'у имеются. Проблем со сбросом кэша может не быть только при использовании InMemory кэша. Если кэш хранится на другом сервере, полагаться на то, что запрос к нему обработается в 100% случаев, не стоит.
bushart
> Если кэш хранится на другом сервере, полагаться на то, что запрос к нему обработается в 100% случаев, не стоит.
Ну, вообще не на что не стоит полагаться на 100%. Но я обычно стараюсь оставить приложение отвественным за бизнес логику, а отвественным за отказоустойчивость сделать сторонние приложения логирования-оповещения. Я предполагаю, что описанные вами ситуации с проблемами с сетью и т.п. — это исключительные ситуации, требующие реакции специалистов. Во первых специалисты устраняют причину проблемы, а во вторых на основание логов принимают ришение по актуализации системы — в данном случае частичного или полного сброса кеша, если есть основания полагать, что по факту поломки он стал не актуален.
bushart
+ Я бы использовал ваш алгоритм в отдельном сервисе отвественном за востановление кеша в случае форс-мажоров. Если есть подозрения на неактуальность, не сбрасывать его полностью, а сверить даты и обновить записи в которых даты не совпадают.
Youkai Автор
Получается сложновато, не хотелось бы столько сложностей добавлять к и так не простой архитектуре кэширования.
У нас есть места, где кэшируются данные для отдельных потребителей. Этот кэш у нас сбрасывается простым вызовом Redis'а, так как даже если сбросить кэш не удастся — он сам устареет через 5 минут и нас это устраивает. В большинстве случаев это наиболее хороший подход к кэшированию.
Можно бы было кэш кампаний также сделать устаревающим раз в 5 минут, но тогда у нас было бы значительно больше перезагрузок кэша по сравнению с кэшированием в памяти процесса.