
В поиске интересного и простого ДатаСета я набрёл этого красавца.
Об этом красавце
В нём есть данные о росте и весе 10 000 мужчин и женщин. Никакого описания. Ничего «лишнего». Только рост, вес и метка пола. Эта таинственная простота мне понравилась.
Что ж, начнём!
Что мне было интересно?
- В каком диапазоне вес и рост у большинства мужчин и женщин?
- Какие они — «средний» мужчина и «средняя» женщина?
- Сможет ли простенькая модель машинного обучения «KNN» по этим данным угадать вес по росту?
Погнали!

Первый взгляд
Для начала подгрузим нужные модули
# Для работы с табличными данными
import pandas as pd
# Для моих любимых графиков
import matplotlib.pyplot as plt
%matplotlib inline
# Модель машинного обучения «К ближайших соседей»
from sklearn.neighbors import KNeighborsRegressor
# Для разбивки данных на тренировочный и тестовый наборы
from sklearn.model_selection import train_test_splitКогда библиотеки встали ровно — пришло время загрузить сам ДатаСет и посмотреть на первые 10 элементов. Это нужно, чтобы наше нутро было спокойно, что мы всё загрузили правильно.
Кстати, не пугайтесь, что рост и вес отличаются от привычных нам. Это из-за другой системы измерений: дюймы и фунты, вместо сантиметров и килограмм.
data = pd.read_csv('weight-height.csv')
data.head(10)| Gender | Height | Weight | |
|---|---|---|---|
| 0 | Male | 74 | 242 |
| 1 | Male | 69 | 162 |
| 2 | Male | 74 | 213 |
| 3 | Male | 72 | 220 |
| 4 | Male | 70 | 206 |
| 5 | Male | 68 | 152 |
| 6 | Male | 69 | 184 |
| 7 | Male | 68 | 168 |
| 8 | Male | 67 | 176 |
| 9 | Male | 63 | 156 |
Хорошо! Мы видим, что первые десять записей — «мужчины». Мы видим их рост (height) и вес (weight). Данные подгрузились хорошо.
Теперь можно посмотреть на количество строк в наборе.
data.shape
>> (10000, 3)Десять тысяч строк / записей. И у каждой по три параметра. То, что нужно!
Пришло время исправить систему измерений. Теперь тут сантиметры и килограммы.
data['Height'] *= 2.54
data['Weight'] /= 2.205
# И проверим результат
data.head(10)| Gender | Height | Weight | |
|---|---|---|---|
| 0 | Male | 188 | 110 |
| 1 | Male | 175 | 74 |
| 2 | Male | 188 | 96 |
| 3 | Male | 182 | 100 |
| 4 | Male | 177 | 94 |
| 5 | Male | 171 | 69 |
| 6 | Male | 175 | 83 |
| 7 | Male | 174 | 76 |
| 8 | Male | 170 | 80 |
| 9 | Male | 161 | 71 |
Вот теперь стало привычнее. И первая же запись нам говорит о мужчине с ростом ~190см и весом ~110кг. Большой человек. Назовём его Боб.
Но как понять: это много или мало по сравнению с остальными? Возможно ли, что мы все плюс-минус Бобы? Это немного позже.
А сейчас узнаем, насколько симметрично в этом наборе данных сочетаются два гендера?
data['Gender'].value_counts()
>> Male 5000
Female 5000
Name: Gender, dtype: int64Идеально поровну. И это хорошо, ведь если бы было: 9999 мужчин и 1 женщина, то не осталось бы смысла делать вид, что этот ДатаСет одинакого хорошо раскрывает оба пола. В нашем случае — всё ок!
Разделяй и изучай!
Сейчас интуиция подсказывает, что будет правильно разделить два пола и исследовать отдельно. Ведь в жизни мы часто видим, что мужчины и женщины имеют плюс-минус разные рост и вес
# Мужчины
data_male = data[data['Gender'] == 'Male'].copy()
# Женщины
data_female = data[data['Gender'] == 'Female'].copy()Давайте взглянем на небольшую описательную статистику, которую нам предлагает модуль pandas.
Мужчины:
data_male.describe()| Height | Weight | |
|---|---|---|
| count | 5000 | 5000 |
| mean | 175 | 85 |
| std | 7 | 9 |
| min | 148 | 51 |
| 25% | 171 | 79 |
| 50% | 175 | 85 |
| 75% | 180 | 91 |
| max | 201 | 122 |
Женщины:
data_female.describe()| Height | Weight | |
|---|---|---|
| count | 5000 | 5000 |
| mean | 162 | 62 |
| std | 7 | 9 |
| min | 138 | 29 |
| 25% | 157 | 56 |
| 50% | 162 | 62 |
| 75% | 167 | 67 |
| max | 186 | 92 |
Простым языком:
Описательная статистика — это набор чисел / характеристик для описания. Пожалуй, это самый простой для понимания вид статистики.
Представьте, что вы описываете параметры мяча. Он может быть:
- большой / маленький
- гладкий / шершавый
- синий / красный
- прыгучий / и не очень.
С сильным упрощением можно сказать, что этим и занимается описательная статистика. Но делает это не с мячиками, а с данными.
А вот параметры из таблицы выше:
- count — Количество экземпляров.
- mean — Среднее или сумма всех значений, делённая на их количество.
- std — Стандартное отклонение или корень из дисперсии. Показывает разброс величин относительно среднего.
- min — Минимальное значение или минимум.
- 25% — Первый квартиль. Показывает значение, меньше которого находится 25% записей.
- 50% — Второй квартиль или медиана. Показывает значение, выше и ниже которого одинаковое количество записей.
- 75% — Третий квартиль. По анологии с первым квартилем, но ниже 75% записей.
- max — Максимальное значение или максимум.
Среднее значение очень чувствительно к выбросам! Если четыре человека получают зарплату 10 000 ?, а пятый — 460 000 ?. То среднее будет — 100 000 ?. А медиана останется прежней — 10 000 ?.
Это не значит, что среднее — это плохой показатель. К нему нужно относиться внимательнее.
Кстати, с медианой тоже есть загвоздка.
Если количество измерений нечётное. То медиана — это значение посередине, если поставить данные «по росту».
А если чётное, то медиана — это среднее между двумя «самыми центральными».
Если в наборе данных только целые числа, а медиана получилась дробной — не удивляйтесь. Скорее всего количество измерений чётно.
Пример:
Сын принёс отметки со школы. Было пять уроков, он получил: 1, 5, 3, 2, 4
Пять оценок > нечётное количество
Сроим по росту: 1, 2, 3, 4, 5
Берём центральное — 3
Медианная оценка — 3
На следующий день сын принёс со школы новые оценки: 4, 2, 3, 5
Четыре оценки > нечётное количество
Строим по росту: 2, 3, 4, 5
Берём центральные: 3, 4
Находим их среднее: 3.5
Медиана — 3.5
Вывод: Молодец сына :)
Видим, что у мужчин среднее и медиана: 175см и 85кг. А у женщин: 162см и 62кг. Это говорит нам, что сильных выбросов нет. Либо они симметричны в обе стороны от медианы. Что бывает очень редко.
Но у обоих полов есть небольшие отклонения среднего от медианы. Но они несущественны и их видно только на сотых долях. Идём дальше!
Гистограма
Это график, который строит значения от минимума до максимума в порядке роста, и показывает количество отдельных экземпляров.
fig, axes = plt.subplots(2,2, figsize=(20,10))
plt.subplots_adjust(wspace=0, hspace=0)
axes[0,0].hist(data_male['Height'],
label='Male Height',
bins=100,
color='red')
axes[0,1].hist(data_male['Weight'],
label='Male Weight',
bins=100,
color='red',
alpha=0.4)
axes[1,0].hist(data_female['Height'],
label='Female Height',
bins=100,
color='blue')
axes[1,1].hist(data_female['Weight'],
label='Female Weight',
bins=100,
color='blue',
alpha=0.4)
axes[0,0].legend(loc=2,
fontsize=20)
axes[0,1].legend(loc=2,
fontsize=20)
axes[1,0].legend(loc=2,
fontsize=20)
axes[1,1].legend(loc=2,
fontsize=20)
plt.savefig('plt_histogram.png')
plt.show()
Данные распределяются колоколообразно. Очень похоже на нормальное распределение.
Помимо статистических тестов на нормальность распределения есть визуальный тест. Если распределение по виду и логике похоже на нормальное — можно считать с долей допущений, что мы имеем дело именно с ним.
Можно было бы сделать статистический тест на нормальность и определить p-value, но не умею это выходит за рамки статьи.
Учимся работать ручками
Pandas за нас может посчитать многое. Но нужно хотя бы раз посчитать некоторые статистики самому. Сейчас покажу, как скалькулировать стандартное отклонение.
Сделаем это на примере мужчин и характеристике — рост.
Среднее
Формула:
, где
- М — среднее значение
- N — количество экземпляров
- ni — отдельный экземпляр
Код:
mean = data_male['Height'].mean()
print('mean:\t{:.2f}'.format(mean))
>> mean: 175.33Средний рост — 175см
Квадрат отклонения от среднего
, где
- di — отдельное отклонение
- ni — отдельный экземпляр
- M — среднее
Код:
data_male['Height_d'] = (data_male['Height'] - mean) ** 2
data_male['Height_d'].head(10)
>> 0 149.927893
1 0.385495
2 166.739089
3 47.193692
4 4.721246
5 20.288347
6 0.375539
7 2.964214
8 25.997623
9 200.149603
Name: Height_d, dtype: float64Дисперсия
Формула:
, где
- D — значение дисперсии
- di — отдельное отклонение
- N — количество экземпляров
Код:
disp = data_male['Height_d'].mean()
print('disp:\t{:.2f}'.format(disp))
>> disp: 52.89Дисперсия — 53
Стандартное отклонение
Формула:
, где
- std — значение стандартного отклонения
- D — значение дисперсии
Код:
std = disp ** 0.5
print('std:\t{:.2f}'.format(std))
>> std: 7.27Стандартное отклонение — 7
Доверительные интервалы
Сейчас мы узнаем, в каких диапазонах роста и веса находятся 68%, 95% и 99.7% мужчин и женщин.
Это не так сложно — нужно прибавлять и отнимать стандартное отклонение от среднего. Выглядит это так:
- 68% — плюс-минус одно стандартное отклонение
- 95% — плюс-минус два стандартных отклонения
- 99.7% — плюс-минус три стандартных отклонения
Напишем вспомогательную функцию, которая будет считать это:
def get_stats(series, title='noname'):
# выводим название характеристики
print('= {} =\n'.format(title.upper()))
# получаем описательную статистику от pandas
descr = series.describe()
# выводим среднее
mean = descr['mean']
print('= Mean:\t{:.0f}'.format(mean))
# выводим стандартное отклонение
std = descr['std']
print('= Std:\t{:.0f}'.format(std))
# разделитель для красоты
print('\n= = = =\n')
# считаем интвервалы
## 68%
devi_1 = [mean - std, mean + std]
## 95%
devi_2 = [mean - 2 * std, mean + 2 * std]
## 99.7%
devi_3 = [mean - 3 * std, mean + 3 * std]
# выводим результат
print('= 68% is from\t\t{:.0f} to {:.0f}'.format(devi_1[0], devi_1[1]))
print('= 95% is from\t\t{:.0f} to {:.0f}'.format(devi_2[0], devi_2[1]))
print('= 99.7% is from\t\t{:.0f} to {:.0f}'.format(devi_3[0], devi_3[1]))Ну и применяем её к данным:
Мужчины | Рост
get_stats(data_male['Height'], title='Male Height')
>>
= MALE HEIGHT =
= Mean: 175
= Std: 7
= = = =
= 68% is from 168 to 183
= 95% is from 161 to 190
= 99.7% is from 154 to 197Мужчины | Вес
get_stats(data_male['Height'], title='Male Height')
>>
= MALE WEIGHT =
= Mean: 85
= Std: 9
= = = =
= 68% is from 76 to 94
= 95% is from 67 to 103
= 99.7% is from 58 to 112Женщины | Рост
get_stats(data_male['Height'], title='Male Height')
>>
= FEMALE HEIGHT =
= Mean: 162
= Std: 7
= = = =
= 68% is from 155 to 169
= 95% is from 148 to 176
= 99.7% is from 141 to 182Женщины | Вес
get_stats(data_male['Height'], title='Male Height')
>>
= FEMALE WEIGHT =
= Mean: 62
= Std: 9
= = = =
= 68% is from 53 to 70
= 95% is from 44 to 79
= 99.7% is from 36 to 87Отсюда выводы:
- Большинство мужчин: 154см–197см и 58кг–112кг.
- Большинство женщин: 141см–182см и 36кг–87кг.
Теперь осталось только применить машинное обучение к этому набору и попробовать предстазать вес по росту.
Ближайшие соседи
Алгоритм «К ближайших соседей» прост. Он существует для задач классификаций — отличить котика от собачки — и для задач регрессии — угадать вес по росту. Это то, что нам нужно!
Для регрессии он использует такой алгоритм:
- Запоминает все точки данных
- При появлении новой точки — ищет К её ближайших соседей (число К задаёт пользователь)
- Усредняет результат
- Выдаёт ответ
Для начала нужно разделить набор данных на обучающую и тестовую части и опробовать алгоритм
Экспериментируем на мужчинах
X_train, X_test, y_train, y_test = train_test_split(data_male['Height'], data_male['Weight'])Разделили, настало время пробовать.
# Три соседа
knr3 = KNeighborsRegressor(n_neighbors=3)
knr3.fit(X_train.values.reshape(-1,1), y_train.values.reshape(-1,1))
knr3.score(X_train.values.reshape(-1,1), y_train.values.reshape(-1,1))
>> 0.8298400793623182
# Пять соседей
knr5 = KNeighborsRegressor(n_neighbors=5)
knr5.fit(X_train.values.reshape(-1,1), y_train.values.reshape(-1,1))
knr5.score(X_train.values.reshape(-1,1), y_train.values.reshape(-1,1))
>> 0.7958051642678619
# Семь соседей
knr7 = KNeighborsRegressor(n_neighbors=7)
knr7.fit(X_train.values.reshape(-1,1), y_train.values.reshape(-1,1))
knr7.score(X_train.values.reshape(-1,1), y_train.values.reshape(-1,1))
>> 0.7769249318420969Не будем далеко ходить и остановимся на трёх соседях. Но вопрос: сможет ли такая модель угадать мой вес?
knr3.predict([[180]])[0, 0]
>> 88.6759623626588188кг — это очень близко. В эту секунду мой вес — 89.8кг
График предсказаний для мужчин
Время построить мою любимую часть науки — графики.
array_male = []
# доверительный интервал 99.7%
xaxis = range(154, 198)
for h in xaxis:
ans = knr3.predict([[h]])
array_male.append(ans[0, 0])
plt.figure(figsize=(20,10))
plt.plot(xaxis, array_male, 'r-', linewidth=4)
plt.title('Male heght-weight dependence', fontsize=30)
plt.xlabel('Height', fontsize=30)
plt.ylabel('Weight', fontsize=30)
plt.grid()
plt.savefig('plt_knn_male.png')
plt.show()
Модель и график предсказаний для женщин
X_train, X_test, y_train, y_test = train_test_split(data_female['Height'], data_female['Weight'])
knr3 = KNeighborsRegressor(n_neighbors=3)
knr3.fit(X_train.values.reshape(-1,1), y_train.values.reshape(-1,1))
knr3.score(X_train.values.reshape(-1,1), y_train.values.reshape(-1,1))
>> 0.8135681584074799array_female = []
# доверительный интервал 99.7%
xaxis = range(141, 183)
for h in xaxis:
ans = knr3.predict([[h]])
array_female.append(ans[0, 0])
plt.figure(figsize=(20,10))
plt.plot(xaxis, array_female, 'b-', linewidth=4)
plt.title('Female heght-weight dependence', fontsize=30)
plt.xlabel('Height', fontsize=30)
plt.ylabel('Weight', fontsize=30)
plt.grid()
plt.savefig('plt_knn_female.png')
plt.show()
Ну и конечно интересно, как выглядят эти графики вместе:
# объединение интервалов мужчин и женщин
xaxis = range(154, 183)
plt.figure(figsize=(20,10))
plt.plot(xaxis, array_male[:-15], 'r-', linewidth=4)
plt.plot(xaxis, array_female[13:], 'b-', linewidth=4)
plt.title('Together heght-weight dependence', fontsize=30)
plt.xlabel('Height', fontsize=30)
plt.ylabel('Weight', fontsize=30)
plt.grid()
plt.savefig('plt_knn_together.png')
plt.show()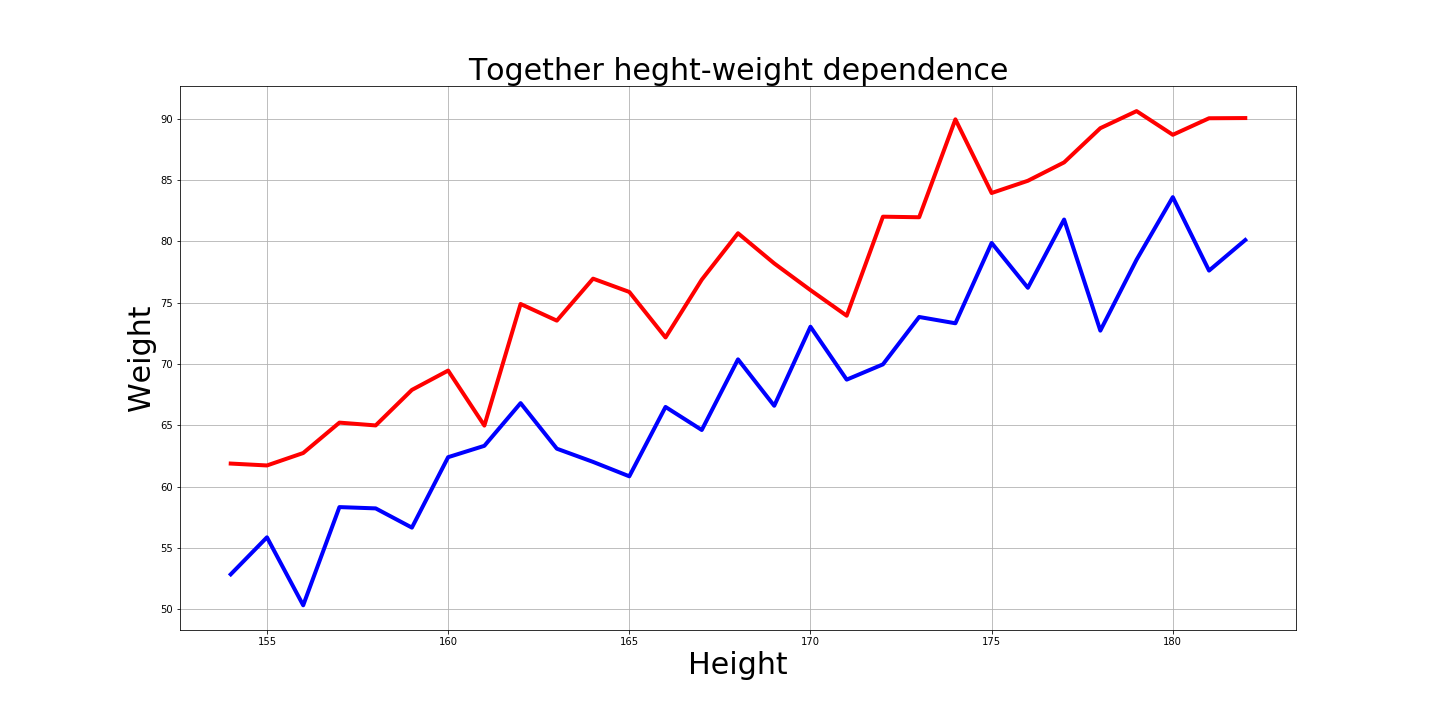
Ответы на вопросы
— В каком диапазоне вес и рост у большинства мужчин и женщин?
99.7% мужчин: от 154см до 197см и от 58кг до 112кг.
А 99.7% женщин: от 141см до 182см и от 36кг до 87кг.
— Какие они — «средний» мужчина и «средняя» женщина?
Средний мужчина — 175см и 85кг.
А средняя женщина — 162см и 62кг.
— Сможет ли простенькая модель машинного обучения «KNN» по этим данным угадать вес по росту?
Да, модель предсказала 88кг, а у меня 89.8кг.
Все, что сделал, собрал тут
Минусы статьи
- Нет описания ДатаСета. Вероятно, возраст и другие факторы у людей различались. Поэтому на веру принимать его нельзя, а ради эксперимента — пожалуйста.
- По-хорошему — нужно было сделать тест на нормальность распределения
Эпилог
Ставь лайк, если попал в 99.7% интервал
Комментарии (24)

Tyusha
08.09.2019 20:55Я вот только не поняла, зачем для вычисления простейшей корреляции «вес-рост» использовать машинное обучение.

RealSaniok
08.09.2019 22:33+1В наше время без этого никак

beardnessandy Автор
08.09.2019 13:29В наше время без этого никак
Точн :D
Я вот только не поняла, зачем для вычисления простейшей корреляции «вес-рост» использовать машинное обучение.
Ради эскперимента а-ля «Посмотреть, что будет»


Samouvazhektra
08.09.2019 21:14Что-то никак не могу въехать в логику попытки предсказывать вес по росту на таких данных, так как вес помимо роста, зависит от множества других факторов, и по сути результат будет просто усредненный по выборке, для данного пола и роста. С таким же успехом можно курс доллара по прогнозу погоды предсказывать.
Если от нефиг делать — то интереснее было бы рассмотреть корреляцию с ИМТbeardnessandy Автор
08.09.2019 13:30Да, данных нехватает. Об этом написал в начале
Я согласен, что эта модель не идеальная от слова совсем
Тут я решил показать результат и провести опрос: «Получится ли угадать по этим данным хоть немного?»

Griboks
08.09.2019 22:56+1Обожаю смотреть на таблицы с оверхреноллионом знаков после запятой и рандомные гистограммы вместо красивых графиков.
Интересный у вас подход к выбору модели и её обучения: ну… к-средних где-то там используется для регрессии, поэтому используем его… с какими-то рандомными параметрами обучения.
И не забываем про гениальные результаты: много рандомных точек (без доверительных окрестностей!!!) на плоскости, зачем-то соединённых линиями (чтобы хоть какой-то график был). И 1/3 угаданных весов.
Ради интереса конечно круто, но я бы улучшил это всё 1)ядерной оценкой с какими-нибудь 2)усами или интервалами, 3)обосновал выбор модели или хотя бы построил несколько моделей, 4)построил прямую/дугу регрессии с доверительными областями вместо двух рандомных ломанных и 5) убрал бы бесполезные первые 10 строк датасета.beardnessandy Автор
08.09.2019 13:31Согласен с вами. Статью можно сделать в разу лучше по всем пяти пунктам
С знаками после запятой разобрались. Они больше не виднеются на горизонте :)
Спасибо!

alex6999
08.09.2019 23:36Средняя женщина какая-то тяжеловатая выходит
beardnessandy Автор
08.09.2019 13:33Да, я тоже заметил :)
Хотя в жизни, по субъективной оценке — это не так)
Не стоит доверять этому анализу на 146%
Он очень общий и далеко не самый точный
Просто ДатаСет показался мне интересным, решил поделиться

vanxant
08.09.2019 01:56Распределение больше похоже на логистическое (ну так на глаз). Посчитайте критерий Колмогорова, заодно научитесь:)

Izaron
08.09.2019 10:02То, что описано в посте — не таинственное машинное обучение, а самая что ни на есть мужицкая Математическая Статистика из четвёртого семестра тех. вуза ;)
Непонятно, зачем в самом конце статьи начинать тыкать пальцем в небо и что-то подгонять с k=1,3,5,..., когда можно использовать какой-нибудь крутой алгоритм аппроксимации функции (из курса Численных Методов третьего семестра) с потенциально наименьшей ошибкой. А если предположить, что средние вес и рост на нашей отрезке зависят линейно, то использовать линейную регрессию, приводя функцию к прямой.
Датасет наверное либо старый на несколько десятилетий, либо про подростков — часто вижу вокруг себя людей ростом 185-190, но по графику, мои наблюдения крайне маловероятны.

WhiteBlackGoose
08.09.2019 10:54Четвертого? Это? Но это же просто линейная регрессия первой степени. Ее можно по линейке построить!
beardnessandy Автор
08.09.2019 13:35Да, вы оба правы)
Можно было бы сделать анализ в разы глубже
Мне интереснее было посмотреть на результат работы KNN, как, на мой взгляд, самой простой модели МО
maxzhurkin
08.09.2019 12:44Ставь лайк, если попал в 99.7% интервал
а автор хитрец!
Почему не 100%?beardnessandy Автор
08.09.2019 13:34Ну это уже лайковымогание)
А так шанс не попасть присутствует)
Matshishkapeu
08.09.2019 17:39У вас криво построена панель из 4 распределений по росту и весу. Ось показана только для двух нижних, но у двух верних они другие. В противном случае медиана по росту у мужчин и женщин одинакова в районе 160 см а вес у медианного мужчины что-то около 60 кг и он легче медианной женщины. В целом по итогам вся модель укладывается в формулу для реферата по физкультуре в восьмом классе: вес[кг]=рост[см] -100 (110 для женщин), но тогда вместо машинлернинга достаточно однострочника в матплотлиб чтоб построить один график.
ABATAPA
Что-то у Вас не сходится… Какие-то толстые карлики или дети…
beardnessandy Автор
Это в дюймах и фунтах. Я там дальше перевёл в см и кг :)
ABATAPA
Да, там дальше есть про это. Просмотрел, т. к. дальше уже в метрической системе. Но выглядит всё равно напрягающе. :)
Ох уж эти «не такие как все»…
beardnessandy Автор
Ага) Жиза)