

Источник: xkcd
Линейная регрессия является одним из базовых алгоритмов для многих областей, связанных с анализом данных. Причина этому очевидна. Это очень простой и понятный алгоритм, что способствует его широкому применению уже многие десятки, если не сотни, лет. Идея заключается в том, что мы предполагаем линейную зависимость одной переменной от набора других переменных, а потом пытаемся эту зависимость восстановить.
Но в этой статье речь пойдет не про применение линейной регрессии для решения практических задач. Здесь будут рассмотрены интересные особенности реализации распределенных алгоритмов её восстановления, с которыми мы столкнулись при написании модуля машинного обучения в Apache Ignite. Немного базовой математики, основ машинного обучения и распределенных вычислений помогут разобраться, как восстанавливать линейную регрессию, даже если данные распределены между тысячами узлов.
О чём речь?
Перед нами стоит задача восстановления линейной зависимости. В качестве входных данных дается множество векторов предположительно независимых переменных, каждому из которых ставится в соответствие некоторое значение зависимой переменной. Эти данные можно представить в виде двух матриц:
Теперь, раз уж предполагается зависимость, да к тому же еще и линейная, запишем наше предположение в виде произведения матриц (для упрощения записи здесь и далее предполагается, что свободный член уравнения скрывается за , а последний столбец матрицы содержит единицы):
Очень похоже на систему линейных уравнений, не так ли? Похоже, но решений у такой системы уравнений скорее всего не будет. Причиной тому является шум, который присутствует практически в любых реальных данных. Так же причиной может быть отсутствие линейной зависимости как таковой, с которой можно пытаться бороться введением дополнительных переменных, нелинейно зависящих от исходных. Рассмотрим следующий пример:
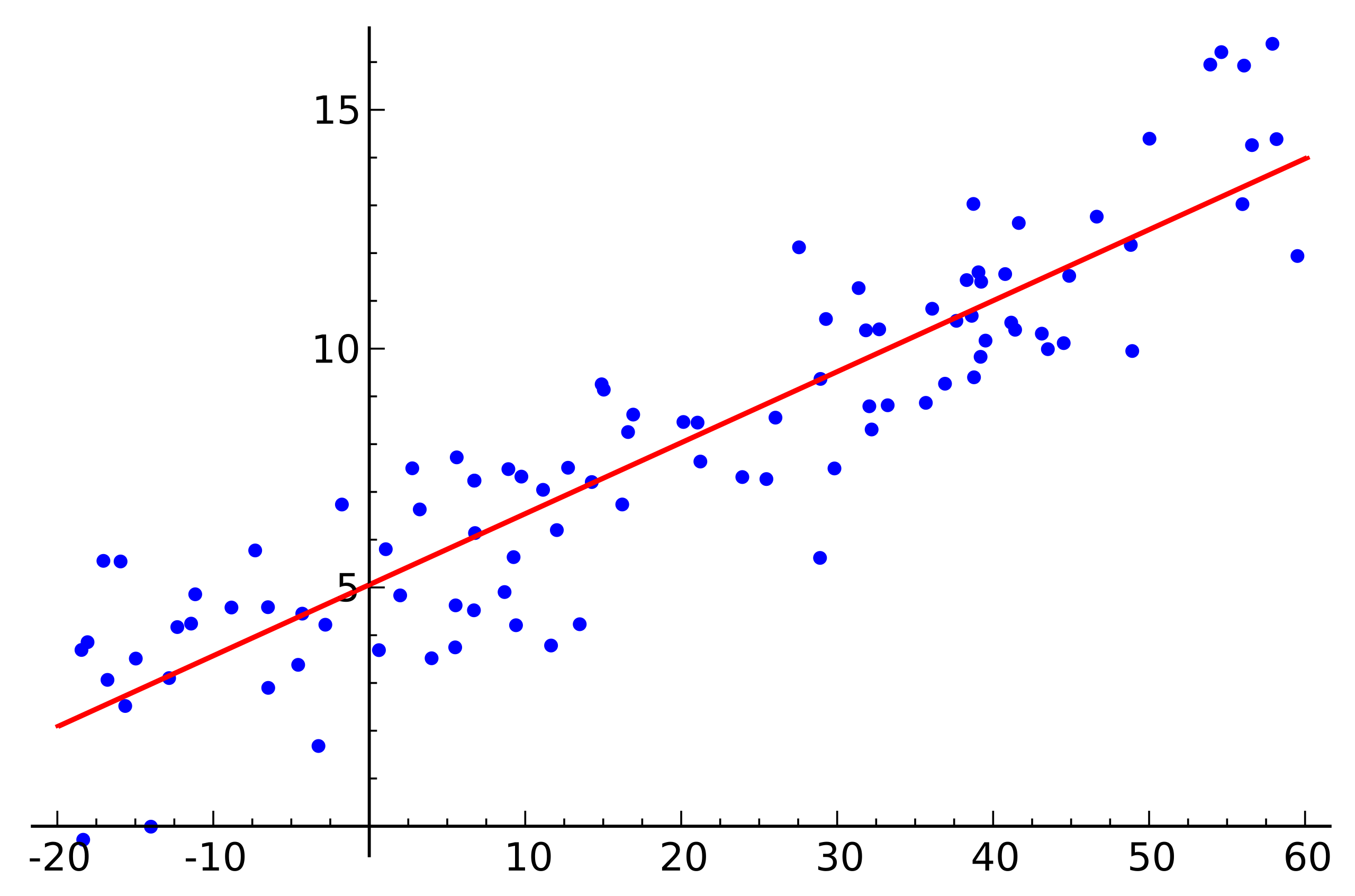
Источник: Wikipedia
Это простой пример линейной регрессии, который демонстрирует зависимость одной переменной (по оси ) от другой переменной (по оси ). Чтобы соответствующая данному примеру система линейных уравнений имела решение, все точки должны лежать точно на одной прямой. Но это не так. А не лежат они на одной прямой именно из-за шума (или из-за того что предположение о наличии линейной зависимости было ошибочным). Таким образом, чтобы восстановить линейную зависимость по реальным данным обычно требуется ввести еще одно предположение: входные данные содержат шум и этот шум имеет нормальное распределение. Можно делать предположения и о других типах распределения шума, но в подавляющем большинстве случаев рассматривают именно нормальное распределение, о котором далее и пойдет речь.
Метод максимального правдоподобия
Итак, мы предположили наличие случайного нормально распределенного шума. Как же быть в такой ситуации? На этот случай в математике существует и широко используется метод максимального правдоподобия. Если кратко, его суть заключается в выборе функции правдоподобия и последующей её максимизации.
Возвращаемся к восстановлению линейной зависимости по данным с нормальным шумом. Заметим, что предполагаемая линейная зависимость является математическим ожиданием имеющегося нормального распределения. В то же время, вероятность того, что принимает то или иное значение, при условии наличия наблюдаемых , выглядит следующим образом:
Подставим теперь вместо и нужные нам переменные:
Осталось только найти вектор , при котором эта вероятность максимальна. Чтобы максимизировать такую функцию удобно сначала её прологарифмировать (логарифм функции будет достигать максимума в той же точке, что и сама функция):
Что, в свою очередь, сводится к минимизации следующей функции:
Кстати, это называется методом наименьших квадратов. Зачастую все приведенные выше рассуждения опускаются и просто используется этот метод.
QR разложение
Минимум приведенной выше функции можно найти, если найти точку в которой градиент этой функции равен нулю. А градиент будет записан следующим образом:
QR разложение является матричным методом решения задачи минимизации используемом в методе наименьших квадратов. В связи с этим перепишем уравнение в матричной форме:
Итак, мы раскладываем матрицу на матрицы и и выполняем ряд преобразований (сам алгоритм QR разложения здесь рассматриваться не будет, только его использование применительно к поставленной задаче):
Матрица является ортогональной. Это позволяет нам избавиться от произведения :
А если заменить на , то получится . Учитывая, что является верхней треугольной матрицей, выглядит это следующим образом:
Это можно решать методом подстановки. Элемент находится как , предыдущий элемент находится как и так далее.
Здесь стоит отметить, что сложность получившегося алгоритма за счет использования QR разложения равна . При этом, несмотря на то, что операция умножения матриц хорошо распараллеливается, написать эффективную распределенную версию этого алгоритма не представляется возможным.
Градиентный спуск
Говоря о минимизации некоторой функции, всегда стоит вспоминать метод (стохастического) градиентного спуска. Это простой и эффективный метод минимизации, основанный на итеративном вычислении градиента функции в точке и последующем её смещении в сторону, противоположную градиенту. Каждый такой шаг приближает решение к минимуму. Градиент при этом выглядит все так же:
Ещё этот метод хорошо распараллеливается и распределяется за счет линейных свойств оператора градиента. Заметим, что в приведенной выше формуле под знаком суммы находятся независимые слагаемые. Другими словами, мы можем посчитать градиент независимо для всех индексов с первого до , параллельно с этим посчитать градиент для индексов с до . Затем сложить получившиеся градиенты. Результатом сложения будет таким же, как если бы мы посчитали сразу градиент для индексов с первого до . Таким образом, если данные распределены между несколькими частями данных, градиент может быть вычислен независимо на каждой части, а затем результаты этих вычислений могут быть просуммированы для получения окончательного результата:
С точки зрения реализации, это укладывается в парадигму MapReduce. На каждом шаге градиентного спуска на каждый узел данных отправляется задание на вычисление градиента, затем вычисленные градиенты собираются вместе, и результат их суммирования используется для улучшения результата.
Несмотря на простоту реализации и возможность выполнения в парадигме MapReduce градиентный спуск обладает и своими недостатками. В частности, количество шагов, необходимое для достижения сходимости, существенно больше в сравнении с другими более специализированными методами.
LSQR
LSQR — еще один метод решения поставленной задачи, который подходит как для восстановления линейной регрессии, так и для решения систем линейных уравнений. Его главная особенность заключается в том, что он совмещает в себе преимущества матричных методов и итеративного подхода. Реализации этого метода можно найти как в библиотеки SciPy, так и в MATLAB. Описание данного метода приводиться здесь не будет (его можно найти в статье LSQR: An algorithm for sparse linear equations and sparse least squares). Вместо этого будет продемонстрирован подход, позволяющий адаптировать LSQR к выполнению в распределенной среде.
В основе метода LSQR лежит процедура бидиагонализации. Это итеративная процедура, каждая итерация которой состоит из следующих шагов:

Но если исходить из того, что матрица горизонтально партиционирована, то каждую итерацию можно представить в виде двух шагов MapReduce. Таким образом удается минимизировать пересылками данных в ходе каждой из итераций (только вектора длиной равной количеству неизвестных):
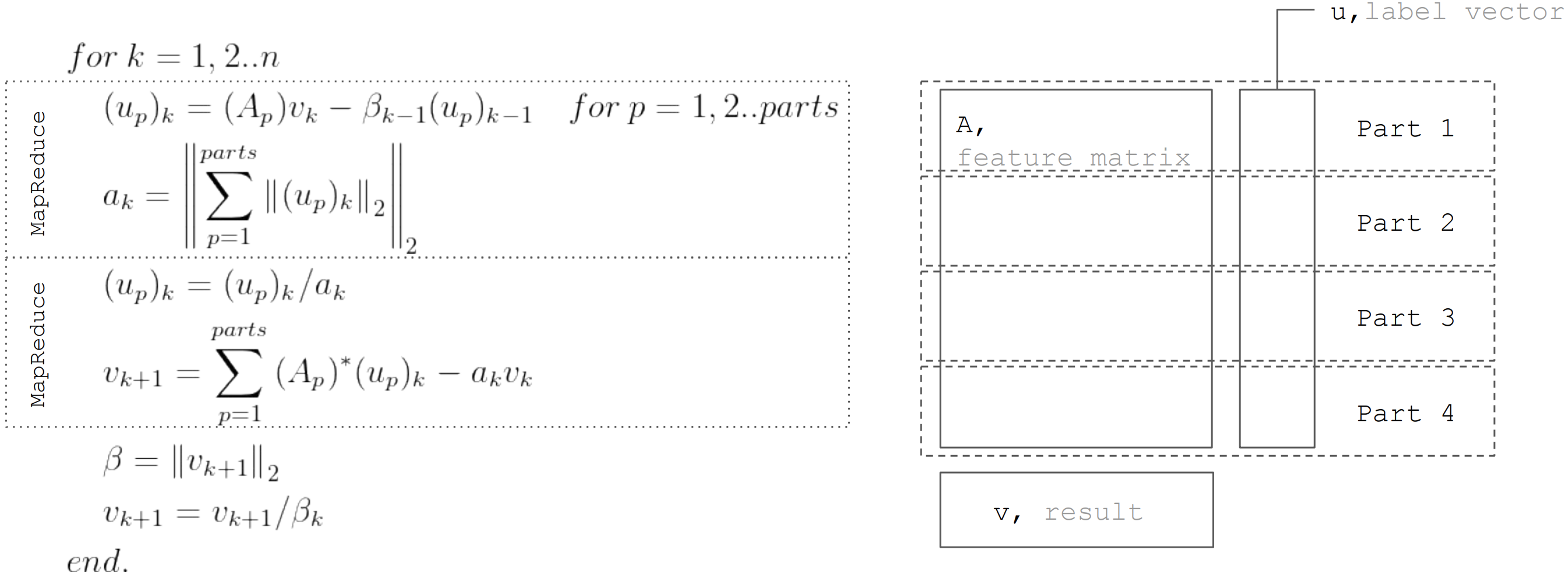
Именно этот подход используется при реализации линейной регрессии в Apache Ignite ML.
Заключение
Существует много алгоритмов восстановления линейной регрессии, но не все из них могут применяться в любых условиях. Так QR разложение отлично подходит для точного решения на небольших массивах данных. Градиентный спуск просто реализуется и позволяет быстро найти приближенное решение. А LSQR сочетает в себе лучшие свойства предыдущих двух алгоритмов, так как он может быть распределен, быстрее сходится в сравнении с градиентным спуском, а так же позволяет раннюю остановку алгоритма в отличие от QR-разложения для поиска приближенного решения.
Комментарии (10)

mikeus
09.09.2019 12:50Кстати, это называется методом наименьших квадратов. Зачастую все приведенные выше рассуждения опускаются и просто используется этот метод.
МНК сам по себе есть просто самостоятельный метод аппроксимации. В данном случае к нему все сводится только из-за вида показателя экспоненты в формуле нормального распределения в связи с упоминанием про метод максимального правдоподобия.
dmitrievanthony Автор
09.09.2019 20:08Здесь важно понимать, что применяя метод наименьших квадратов мы предполагаем что шум имеет нормальное распределение. Если это не так, то нужно использовать другой подход.
mikeus
09.09.2019 21:38Я как раз и хотел уточнить, что связь: предположение о нормальном распределении шума для метода максимального правдоподобия ==> МНК — не более чем математическое совпадение. МНК — просто метод аппроксимации, и не обязательно линейной. Обратной глубинной связи от МНК к чему либо относительно шумов и прочего нет ни какой. Если так хочется использовать какие-то предположения о распределении шумов, то этого и надо плясать и соответственно как основную идею выносить в заголовок.

Costic
09.09.2019 19:25Если бы вы картинки добавили, то было бы шикарно!

Но я не понял, где же на практике у вас применяются эти методы и для каких задач, каких объёмов данных?dmitrievanthony Автор
09.09.2019 20:06Картинка правда хорошая, учту. На практике все это реализовывалось для Apache Ignite, а примеры можно посмотреть здесь.

frobeniusfg
09.09.2019 22:03Кажется, в ряде формул в разделе «Метод максимального правдоподобия» пропущен индекс i возле a и b, хотя по нему берется произведение.
ooprizrakoo
как можно этого не увидеть?
