

Статей с подобным заголовком достаточно много, поэтому постараюсь избежать банальных тем. Надеюсь, что даже очень опытные разработчики найдут здесь что-то полезное для себя. В данной статье будут рассмотрены только простые механизмы и подходы оптимизации, которые позволят применить их, затратив минимум усилий. И эти изменения не увеличат энтропию вашего кода. В статье не будет уделено внимания, что и когда нужно оптимизировать, эта статья скорее о подходе к написанию кода в целом.
1. ToArray vs ToList
public IEnumerable<string> GetItems()
{
return _storage.Items.Where(...).ToList();
}Согласитесь, очень типовой код для промышленных проектов. Но что в нём не так? IEnumerable интерфейс возвращает коллекцию, по которой можно «пробежаться», данный интерфейс не предполагает того, что мы можем добавлять/удалять элементы. Соответственно, нет необходимости заканчивать LINQ выражение приведением к List'у (ToList). В данном случае, предпочтительнее будет приведение к Array (ToArray). Так как List является обёрткой над Array, а все дополнительные возможности, предоставляемые этой обёрткой, мы срезаем интерфейсом. Массив потребляет меньше памяти, а доступ к его значениям быстрее. Соответственно, зачем платить больше. С одной стороны эта оптимизация не существенная, как говорят «оптимизация на спичках», но это не совсем так. Дело в том, что в типовом приложении, в котором многочисленные сервисы возвращают модели для слоя представления, таких «лишних» вызовов ToList может быть мириады. В описанном выше примере интерфейс IEnumerable введён для большей наглядности. Данный подход актуален для всех случаев, когда нужно возвращать коллекцию, которую в последствии вы не собираетесь менять.
Предвижу комментарий о том, что Array и List будут работать не эквивалентно в случае многопоточного обращения к коллекции. Это действительно так. Но если вы, как разработчик, рассматриваете возможность многопоточного доступа к такой коллекции c возможностью её изменения, то с высокой степенью вероятности, вам уже не подходят ни Array, ни List.
2. Параметр «путь к файлу» не всегда лучший выбор для вашего метода
При разработке API избегайте сигнатур методов, которые на вход получают путь к файлу (для последующей обработки вашим методом). Вместо этого предоставляйте возможность передать на вход массив байт или в крайнем случае Stream. Дело в том, что со временем, ваш метод может быть применён не только к файлу с диска, но и к файлу, переданному по сети или к файлу из архива, к файлу из базы данных, к файлу содержание которого сформировано динамически в памяти и т. д. Предоставляя метод с входным параметром «путь к файлу» вы обязываете пользователя вашего API предварительно сохранить данные на диск, чтобы потом прочесть их снова. Это бессмысленная операция критически влияет на производительность. Диск – крайне медленная штука. Для удобства вы можете предоставить метод с входным параметром «путь к файлу», но внутри всегда используйте публичный перегруженный метод с массивом байт или stream'ом на входе. Есть «маркер», который может помочь найти лишние операции записи/чтения диска, попробуйте найти в вашем проекте использование стандартных методов:
Path.GetTempPath(), Path.GetRandomFileName() (из System.IO). С высокой степенью вероятности, вы встретите workaround вышеописанной проблемы или похожей.Внимательный и опытный читатель заметит, что в некоторых случаях, запись на диск может наоборот улучшить производительность, например, если мы имеем дело с очень большими файлами. Это действительно так, это необходимо учитывать, но предполагаю что это очень редкая ситуация со специфичной реализацией.
3. Избегайте использования потоков в качестве параметров и возвращаемого результата ваших методов
В чём здесь проблема… когда мы получаем поток из некоторого «чёрного ящика», мы должны держать в голове его состояние. Т.е. открыт ли поток? Где находится маркер чтения/записи? Может ли измениться его состояние независимо от нашего кода? Если поток объявлен как базовый класс Stream, мы даже не владеем информацией, какие операции над ним доступны. Всё это решается дополнительными проверками, а это дополнительный код и издержки. Также, неоднократно сталкивался с ситуацией, когда, получая Stream из некоторого «неясного» метода, разработчик предпочитал перестраховаться и «перегнать» данные из него в полностью контролируемый новый локальный MemoryStream. Хотя, исходный поток мог быть вполне безопасным. Может даже это и был уже любезно подготовленный для чтения MemoryStream. Иногда может доходить до абсурда – внутри метода, массив байт кладётся в MemoryStream, далее данный MemoryStream возвращается как результат метода, объявленного как базовый Stream. Снаружи этот Stream оборачивается новым MemoryStream'ом и далее вызов ToArray() возвращает массив байт, который изначально у нас и был. Точнее это уже будет его копия. Ирония в том, что внутри и снаружи нашего метода код вполне корректный. По-моему, этот пример тоже не из головы, а встречался где-то в коммерческом коде.
В итоге, если у вас есть возможность передавать / получать «чистые» данные, не используйте для этого потоки – не создавайте капканов, для тех, кто будет этим пользоваться. Если же в вашем приложении уже есть передача / возврат потоков, проанализируйте их использование на основе вышеизложенного.
4. Наследование enum'ов
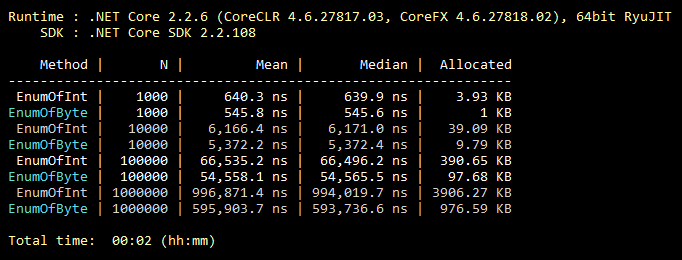
Данная оптимизация банальная, её знают все, даже студенты. Но из моего опыта, ей крайне редко пользуются. Итак, по умолчанию enum наследуется от int. Однако его можно наследовать от byte, который вмещает 256 значений (или 8 «flaggable» значений). Что почти всегда покрывает функциональность «среднего» enum’а. Минимальное изменение в коде и все значения вашего enum’а занимают меньше памяти навсегда. Ниже иллюстрация бенчмарка по заполнению коллекции значениями enum’ов, наследуемых от int и byte.
public class CollectEnums
{
[Params(1000, 10000, 100000, 1000000)] public int N;
[Benchmark]
public EnumFromInt[] EnumOfInt()
{
EnumFromInt[] results = new EnumFromInt[N];
for (int i = 0; i < N; i++)
{
results[i] = EnumFromInt.Value1;
}
return results;
}
[Benchmark]
public EnumFromByte[] EnumOfByte()
{
EnumFromByte[] results = new EnumFromByte[N];
for (int i = 0; i < N; i++)
{
results[i] = EnumFromByte.Value1;
}
return results;
}
}
public enum EnumFromInt
{
Value1,
Value2
}
public enum EnumFromByte: byte
{
Value1,
Value2
}5. Ещё пару слов о классах Array и List
Следуя логике, итерирование по массиву всегда эффективнее итерирования по «листу», так как «лист» это обёртка над массивом. Также, следуя логике, «for» всегда быстрее «foreach», так как «foreach» делает много действий, требуемых реализацией интерфейса IEnumerable. Здесь всё логично, но неверно! Давайте взглянем на результаты бенчмарка:

public class IterationBenchmark
{
private List<int> _list;
private int[] _array;
[Params(100000, 10000000)] public int N;
[GlobalSetup]
public void Setup()
{
const int MIN = 1;
const int MAX = 10;
Random random = new Random();
_list = Enumerable.Repeat(0, N).Select(i => random.Next(MIN, MAX)).ToList();
_array = _list.ToArray();
}
[Benchmark]
public int ForList()
{
int total = 0;
for (int i = 0; i < _list.Count; i++)
{
total += _list[i];
}
return total;
}
[Benchmark]
public int ForeachList()
{
int total = 0;
foreach (int i in _list)
{
total += i;
}
return total;
}
[Benchmark]
public int ForeachArray()
{
int total = 0;
foreach (int i in _array)
{
total += i;
}
return total;
}
[Benchmark]
public int ForArray()
{
int total = 0;
for (int i = 0; i < _array.Length; i++)
{
total += _array[i];
}
return total;
}
}Дело в том, что для итерирования по массиву, «foreach» не использует реализацию IEnumerable. В этом частном случае выполняется максимально оптимизированное итерирование по индексу, без проверки на выход за границы массива, так как конструкция «foreach» не оперирует индексами, соответственно у пользователя нет возможности «накосячить» в коде. Такое вот исключение. Поэтому, если в каком-то критичном участке кода вы заменили использование «foreach» на «for» ради оптимизации – вы выстрелили себе в ногу. Обратите внимание, это актуально только для массивов. На StackOverflow есть несколько веток, где обсуждается это особенность.
6. Всегда ли поиск через хеш-таблицу оправдан?
Все знают, что хеш-таблицы очень эффективны для поиска. Но часто забывают, что цена за быстрый поиск — медленное добавление в хеш-таблицу. Что из этого следует? Для того чтобы использование хеш-таблицы было оправданным, необходимо, чтобы кол-во элементов хеш-таблицы было не менее 8 (примерно). И чтобы кол-во операций поиска было хотя бы на порядок больше кол-ва операций добавления. В противном случае используйте коллекцию попроще. Качество хеш-функции может внести свои коррективы в эффективность, но смысл от этого не измениться. На моей практике был случай, когда самым «узким местом» в нагруженном коде был вызов метода Dictionary.Add(). Ключом был обычный string, небольшой длины. Воспоминание об этом и стало триггером к написание этого пункта. Для иллюстрации, пример очень плохого кода:
private static int GetNumber(string numberStr)
{
Dictionary<string, int> dictionary = new Dictionary<string, int>
{
{"One", 1},
{"Two", 2},
{"Three", 3}
};
dictionary.TryGetValue(numberStr, out int result);
return result;
}Может что-то подобное встречается и в вашем проекте?
7. Встраивание методов
Код разбит на методы чаще всего по 2-ум причинам. Обеспечить повторное использование кода и обеспечить декомпозицию, когда одна задача разбивается на несколько подзадач. Для человека так проще. Inlining – это обратный процесс декомпозиции, т.е. код метода встраивается в то место, где метод должен вызываться, в итоге мы экономим на стеке вызовов и передаче параметров. Я никоим образом не рекомендую всё «запихивать» в один метод. Но те методы, которые мы могли бы теоретически «заинлайнить» можно пометить соответствующим атрибутом:
[MethodImpl(MethodImplOptions.AggressiveInlining)]Данный атрибут подскажет системе, что этот метод можно встраивать. Это вовсе не значит что метод, помеченный этим атрибутом, будет обязательно встроен. Например, невозможно встроить рекурсивные или виртуальные методы. Стоит также отметить, что механизм встраивания чрезвычайно «нежный». Есть много других причин, по которым система откажется встраивать ваш метод. Тем не менее, команда Microsoft, работающая над .NET Core, активно пользуется этим атрибутом. В исходных кодах .NET Core много примеров его использования.
8. Оценочный Capacity
У меня (и надеюсь, у большинства разработчиков тоже) выработан рефлекс: проинициализировал коллекцию – задумался, можно ли для неё задать Capacity. Однако, далеко не всегда заранее известно точное кол-во элементов коллекции. Но это не повод игнорировать этот параметр. Например, если, рассуждая о том, какое кол-во элементов будет в вашей коллекции, вы предполагаете размытое «пару тыщ» это уже повод задать Capacity равное 1000. Немного теории, например, для List по умолчанию Capacity = 16, для того чтобы только дойти до 1000, система сделает 1008 (16 + 32 + 64 + 128 + 256 + 512) лишних копирований элементов и создаст 7 временных массивов на откуп следующему вызову GC. Т.е. вся эта работа выполнится впустую. Также, в качестве Capacity никто не запрещает использовать формулу. Если размер вашей коллекции оценочно равен одной трети другой коллекции, можно задать Capacity равное otherCollection.Count / 3. При установке Capacity стоит хорошо понимать диапазон возможного размера коллекции и насколько его значение плотно распределено. Всегда есть вероятность навредить, но при правильном использовании, оценочный Capacity даст вам хороший выигрыш.
9. Всегда конкретизируйте ваш код
Активно используйте (на первый взгляд, необязательные) ключевые слова C#, такие как: static, const, readonly, sealed, abstract и т.д. Естественно, там, где они имеют смысл. Причём здесь производительность? Дело в том, что чем более детально вы опишете компилятору свою систему, тем более оптимальный код он сможет сгенерировать. Внимательный и опытный читатель может заметить что, например ключевое слово sealed никак не влияет на производительность. Сейчас это действительно так, но в следующих версиях всё может измениться. Дайте компилятору и виртуальной машине шанс! Бонусом получите, выявление многих ошибок неправильного использования вашего кода на этапе компиляции. Общее правило: чем более чётко система описана, тем оптимальнее результат. Судя по всему, с людьми также.
10. По возможности используйте одну версию .NET для всех проектов Solution'а
Стоит стремиться к тому, чтобы все сборки в рамках вашего приложения относились к одной и той же версии .NET. Это касается как NuGet пакетов (редактируется в packages.config/json), так и ваших собственных сборок (редактируется в Project properties). Это позволит сэкономить оперативную память и ускорить «холодный» старт, так как в памяти вашего приложения не будет копий одних и тех же библиотек, под разные версии .NET. Стоит отметить, что не во всех случаях разные версии .NET будут порождать копии в памяти. Но исходите из того, что приложение, построенное на одной версии .NET, это всегда лучше. Также, это избавит от целого ряда потенциальных проблем, лежащих за пределами темы данной статьи. Консолидация версий всех NuGet пакетов, используемых вами, тоже внесёт вклад в улучшение производительности вашего приложения.
Несколько полезных инструментов
ILSpy – бесплатный инструмент, позволяющий посмотреть восстановленный исходный код сборки. Если у меня возникает вопрос о том, какой механизм .NET более эффективный, в первую очередь я открываю ILSpy (а не Google или StackOverflow), и уже там смотрю, как он реализован. Например, чтобы узнать, что лучше использовать с точки зрения производительности для получения данных по HTTP, класс HttpWebRequest или WebClient, достаточно посмотреть их реализацию через ILSpy. В данном конкретном случае WebClient это обёртка над HttpWebRequest. Исходных кодов .NET не стоит боятся, их пишут такие же обычные программисты.
BenchmarkDotNet – бесплатная библиотека «бенчмарков». Есть простой и понятный StopWatch (из System.Diagnostics). Но иногда его бывает недостаточно. Так как по-хорошему нужно учитывать не единичный результат, а среднее нескольких сравнений, а лучше сравнить их медиану, чтоб минимизировать влияние ОС. Также, нужно учесть «холодный старт» и объём выделяемой памяти. Для таких сложных тестов BenchmarkDotNet и создан. Именно эту библиотеку используют разработчики .NET Core в официальных тестах. Библиотека простая в использовании, но если вдруг её авторы читают сей пост, прошу, дайте более удобную возможность влиять на структуру таблицы результатов.
U2U Consult Performance Analyzers – бесплатный плагин к Visual Studio, дающий подсказки по улучшению кода с точки зрения производительности. Полагаться 100% на советы данного анализатора не стоит. Так как сталкивался с ситуацией, когда один совет меня немного удивил и после детального анализа он действительно оказался ошибочным. К сожалению, сей пример утерян, так что верьте на слово. Тем не менее, если им пользоваться вдумчиво, очень полезный инструмент. Например, он подскажет, что вместо
myStr.Replace("*", "-") эффективнее использовать myStr.Replace('*', '-'). А два Where выражения в LINQ лучше объединить в одно. Всё это «оптимизации на спичках», но они легко применяются и не приводят к увеличению кода/сложности.В качестве заключения
Если каждый 10-ый прочитавший статью, применит вышеуказанные подходы к своему текущему проекту (или критической его части), а также будет придерживаться этих подходов в будущем, то ВМЕСТЕ мы сможем спасти целый лес! Лес??? Т.е. сэкономленные ресурсы компьютерных систем, в виде электричества, полученного от сжигания древесины, останутся неиспользованными. В данном случае «лес» это лишь некий эквивалент. Вероятно, странное заключение получилось, но, надеюсь, вы прониклись мыслью.
P.S. Обновление на основе комментариев к посту
Преимущество ToArray над ToList актуально только для .NET Core. Если вы используйте старый .NET Framework, то для вас ToList будет предпочтительнее. В целом, этот вопрос оказался более сложным, так как у разных классов, реализующих IEnumerable, могут быть разные реализации ToArray и ToList, с разным уровнем эффективности.
Если enum используется как член класса (структуры), а не отдельно, то экономии памяти у enum'а наследуемого от byte не будет. Из-за выравнивания занимаемой памяти всех членов класса (структуры). Этот момент в статье упущен. Тем не менее, потенциальный выигрыш лучше его отсутствия, так как помимо занимаемой памяти enum'ы ещё и используются. Поэтому пункт 4, по-прежнему актуален, но с данной важной оговоркой.
Спасибо KvanTTT и epetrukhin за конструктивные комментарии по этим вопросам.
Также, как заметил Taritsyn, оптимизация на этапе JIT-компиляции для ключевого слова «sealed» всё же существует. Но, это только подтверждает все тезисы 9-го пункта.
Вроде, учтены все конструктивные замечания.
Я очень рад этим замечаниям. Так как я сам, как автор, получил фидбек и узнал для себя тоже что-то новое.
Комментарии (47)

Dimtry44
10.09.2019 20:40+2Каждую статью по производительности надо заканчивать этой табличкой.
Latency Comparison Numbers ---------------------------------- L1 cache reference 0.5 ns Branch mispredict 5 ns L2 cache reference 7 ns 14x L1 cache Mutex lock/unlock 25 ns Main memory reference 100 ns 20x L2 cache, 200x L1 cache Compress 1K bytes with Zippy 3,000 ns 3 us Send 1K bytes over 1 Gbps network 10,000 ns 10 us Read 4K randomly from SSD* 150,000 ns 150 us ~1GB/sec SSD Read 1 MB sequentially from memory 250,000 ns 250 us Round trip within same datacenter 500,000 ns 500 us Read 1 MB sequentially from SSD* 1,000,000 ns 1,000 us 1 ms ~1GB/sec SSD, 4X memory Disk seek 10,000,000 ns 10,000 us 10 ms 20x datacenter roundtrip Read 1 MB sequentially from disk 20,000,000 ns 20,000 us 20 ms 80x memory, 20X SSD Send packet CA->Netherlands->CA 150,000,000 ns 150,000 us 150 ms Notes ----- 1 ns = 10^-9 seconds 1 us = 10^-6 seconds = 1,000 ns 1 ms = 10^-3 seconds = 1,000 us = 1,000,000 ns Credit ------ By Jeff Dean: http://research.google.com/people/jeff/ Originally by Peter Norvig: http://norvig.com/21-days.html#answers

KvanTTT
10.09.2019 20:48+7- ToArray vs ToList
Не согласен.
ToArrayдляIEnumerable— это сначалаToList, а потомToArray, тримминг лишних элементов (TrimExcess), т.е. лишняя аллокация. Так что если вам не нужен массив или это не какие-то постоянные коллекции, особенно большие, тоToListвыигрывает. Узнал это от Игоря Лабутина в докладе Коллекционируем данные в .NET.
- Параметр «путь к файлу» не всегда лучший выбор для вашего метода
- Избегайте использования потоков в качестве параметров и возвращаемого результата ваших методов
Это все сводится к общему совету "не плодите промежуточные сущности без необходимости", к которому можно приписать и другие ситуации.
Минимальное изменение в коде и все значения вашего enum’а занимают вдвое меньше памяти навсегда.
Навсегда, но не всегда. Если enum используется как член класса или структуры, то разницы никакой не будет из-за выравнивания как минимум по 4 байта. А это используется почаще, чем массивы из енамов.
Этот атрибут подскажет системе, что этот метод можно встраивать. Это вовсе не значит что метод, помеченный этим атрибутом, будет обязательно встроен.
Почти не использую, и у меня вопрос. А разве JIT не в состоянии сам заинлайнить маленькие методы, если даже этот атрибут не используется? Если может и JIT умнее, то зачем вообще помечать?
ILSpy
А еще есть бесплатные dotPeek, dnSpy и кроссплатформенный AvaloniaILSpy. dnSpyне боится обфусцированных сборок.
Если у меня возникает вопрос о том, какой механизм .NET более эффективный, в первую очередь, я открываю ILSpy (а не Google или StackOverflow), и уже там смотрю, как он реализован.
Если нужно посмотреть код именно самого .NET, то можно использовать онлайн https://referencesource.microsoft.com/. Если надо узнать как оптимизируется код на уровне ассемблера, то https://sharplab.io/ незаменим.

Bartez Автор
10.09.2019 22:05KvanTTT, спасибо за информативный комментарий! +1, именно такой фидбек я очень люблю! Про выравнивание enum'ов не знал, это не противоречит статье, однако с этой точки зрения я даже не оценивал.
А вот по рекомендациям Игоря Лабутина не всё так очевидно. Возможно, в его докладе фигурировала более старая версия .NET. Или наоборот, его доклад был по .NET Core 3 Preview. Или иная причина расхождения результатов.
Если запустить простой бенчарк, то по времени выполнения мы получим эквивалентный результат, нельзя выявить победителя. А вот по выделению памяти ToArray стабильно расходует меньше.

epetrukhin
10.09.2019 23:24Выложите, пожалуйста, код бенчмарка, сравнивающего ToList и ToArray.
Bartez Автор
10.09.2019 23:58Код бенчмарка:
public class ListvsArrayBenchmark { private const int VALUE = 1; private IEnumerable<int> _source; [Params(1000, 10000, 100000, 1000000)] public int N; [GlobalSetup] public void Setup() { _source = Enumerable.Repeat(0, N).Select(x => VALUE); } [Benchmark] public List<int> ToList() { return _source.ToList(); } [Benchmark] public int[] ToArray() { return _source.ToArray(); } }
Не забудьте поделиться своими результатами запуска.epetrukhin
11.09.2019 10:13У меня результаты под .NET Core аналогичные Вашим, так что выкладывать не буду. А вот под .NET Framework ситуация другая:

В .NET Core ToArray и ToList были оптимизированы:
- Многие linq операторы начали возвращать не голый IEnumerable, а IIListProvider, в котором есть информация о количестве элементов в последовательности. Это позволяет сразу выделять под массив/список нужное количество памяти. В Вашем бенчмарке это как раз и проявилось — Repeat точно знает, сколько элементов будет в последовательности, а Select эту информацию передаёт дальше.
- ToArray для материализации последовательностей неизвестной длины стал использовать хитрые оптимизации. В определённый момент он переходит от использования одного промежуточного буфера с его ресайзом к списку буферов, что уменьшает memory traffic.
А в .NET Framework всё работает так как описал KvanTTT, поэтому ToList там аллоцирует меньше.
KvanTTT
11.09.2019 00:50Про выравнивание enum'ов не знал, это не противоречит статье, однако с этой точки зрения я даже не оценивал.
На самом деле это касается всех типов. Если вы создадите структуру S с одним свойством типа byte, то sizeof(T) вернет 1. Однако если добавить к ней более длинный тип, например int, то уже sizeof(T) == 8, а не 5 как могло бы показаться. C long будет вообще 16. Т.е. если свойства типа байтового enum будет хотя бы с одним свойством int, то оптимизации по памяти не будет. Выравнивание сделано для оптимизации, так как доступ к выровненным элементам гораздо быстрее. Однако это касается архитектуры x64. На x86, возможно, будут другие цифры.
Если запустить простой бенчарк, то по времени выполнения мы получим эквивалентный результат, нельзя выявить победителя. А вот по выделению памяти ToArray стабильно расходует меньше.
По памяти тоже нельзя что-то сказать однозначно. Ок, давайте сравним код обеих имплементаций на вышеупомянутом https://referencesource.microsoft.com
В методе ToList(this IEnumerable collection) вызывается конструктор списка List(IEnumerable collection), внутри которого происходит перебор коллекции и обычное добавление в список с помощью метода
Add, пустая часть не отсекается.
В методе ToArray(this IEnumerable source) вызывается конструктор интернального класса Buffer(IEnumerable source), после чего на результирующем коллекции вызывается метод ToArray().
Bufferработает аналогичноList, а методToArray, в свою очередь, триммит результирующий массив. Из чего можно я делаю вывод, здесь все же происходит лишняя аллокация.
Кстати, еще более оптимально использовать запись, в которой лишняя коллекция вообще не создается без необходимости:
enumerable as List<Item> ?? enumerable.ToList();
P.S. у вас ошибка — там имелось в виду ToArray, а не ForArray?
Bartez Автор
11.09.2019 00:56у вас ошибка — там имелось в виду ToArray, а не ForArray?
Да, вы правы. Поздно заметил, не успел исправить комментарий. В полном коде бенчмарка, приведённого выше, ошибка в названии метода уже исправлена.
Bartez Автор
11.09.2019 02:19Прошу прощения за ошибку в названии метода, не «ForArray», а «ToArray».
Deosis
11.09.2019 08:43Почти не использую, и у меня вопрос. А разве JIT не в состоянии сам заинлайнить маленькие методы, если даже этот атрибут не используется? Если может и JIT умнее, то зачем вообще помечать?
Возможно, если будет несколько кандидатов на инлайн, то JIT сначала будет рассматривать методы, помеченные данным атрибутом.
Karl_Marx
11.09.2019 15:00JIT примерно знает, даст встраивание прирост производительности или нет. Кроме сокращения затрат на вызов метода, встраивание плохо отразится на кэшировании кода и увеличит его объем. Но данный товарищ считает себя умнее компилятора и предлагает лепить везде принудительное встраивание. Многие другие пункты, например, тот же пункт про ToArray, тоже похожи на вредные советы и повторять их в реальной жизни не стоит. КГ/АМ, короче.
Bartez Автор
12.09.2019 01:35Но данный товарищ считает себя умнее компилятора и предлагает лепить везде принудительное встраивание.
Я даже не знаю, что на это ответить.
:-)
В разделе про Inlining, в принципе нет никаких советов и рекомендаций. Я как автор, ещё не до конца сформировал своё личное отношение к принудительному встраиванию. Как раз поэтому в статье описан лишь сам механизм, сама возможность. Всё остальное вы додумали. И на основе своих фантазий обвинили человека, вам должно быть стыдно.

GrimMaple
11.09.2019 17:16Почти не использую, и у меня вопрос. А разве JIT не в состоянии сам заинлайнить маленькие методы, если даже этот атрибут не используется? Если может и JIT умнее, то зачем вообще помечать?
Не просто в состоянии, а даже активно это делает, когда может.
Вот тут есть небольшой текст с рационализацией процесса инлайнинга. Я тоже не до конца понимаю смысла помечать методы агрессивным инлайнингом — это то, что я бы назвал premature optimization. Пока нету метрик перформанса с явным пониманием, что метод мог бы быть быстрее, если заинлайнен — зачем вообще писать лишний код?
Taritsyn
11.09.2019 21:17Я тоже не до конца понимаю смысла помечать методы агрессивным инлайнингом — это то, что я бы назвал premature optimization.
Бывают случаи, когда это действительно необходимо.KvanTTT
12.09.2019 14:47Почему это такой случай? Методы статические, маленькие, с инлайнингом не должно возникнуть проблем по идее.

AnarchyMob
11.09.2019 18:59Навсегда, но не всегда. Если enum используется как член класса или структуры, то разницы никакой не будет из-за выравнивания как минимум по 4 байта. А это используется почаще, чем массивы из енамов.
Так, а если в структуре больше одного enum поля, тогда выигрыш, хоть и небольшой, но есть
Dimtry44
10.09.2019 22:24Про хеш-таблицы у вас не очень написано. Добавление новых пунктов в хеш-таблицу может быть не сильно затратно если правильно определить initial capacity. Поиск тоже может быть быстрее если взять initial capacity побольше, будет меньше коллизий.
Конечно плата за это памятью.
Плюс, если вы знаете эффективную хэш функцию для ваших данных, это может существенно ускорить процесс.
Количество элементов хеш-таблицы было не менее 8
От куда это утверждение? Личный опыт? Тут сильно зависит от типа данных.Bartez Автор
10.09.2019 22:31Число «8» встречал где-то в оф. документации Microsoft, попробую сейчас найти ссылку.
Bartez Автор
10.09.2019 23:08Ссылку на оригинальный пост Microsoft не нашёл. Лет 5 назад попадалась статья с рекомендациями, когда нужно использовать Dictionaty. Цифра условная (для Capacity по умолчанию, с каким-нибудь простым ключом, типа int). Основной смысл 6-го раздела в том, что на очень малом кол-ве элементов, Dictionary результата не даст, так же как и с малым соотношением добавлений к поиску в рамках критичного кода.
Karl_Marx
11.09.2019 15:07Суть в том, что локальность ссылок в словарях меньше, чем в массивах, проще держать в одной строке кэша L1 небольшой массив, чем собирать данные словаря по разным уголкам памяти и подгружать несколько строк в кэш. Увы, сам автор этого не понимает.
Karl_Marx
11.09.2019 15:14Дополню: размер строки кэша данных L1 в семействе x86 равен 64 байтам, соответственно, в нее помещается 8 64-разрядных ссылок на объекты. Если целевая платформа 32 разрядная, то 16 ссылок. Все они в случае массива могут быть загружены за одну операцию чтения.
White_Scorpion
11.09.2019 10:33по умолчанию enum наследуется от int. Однако его можно наследовать от byte, который вмещает 256 значений (или 8 «flaggable» значений). Что почти всегда покрывает функциональность «среднего» enum’а.
Я как-то читал, что подобные ассоциативно похожие целочисленные типы или расположение структур в памяти компилятор всё равно приводит к Int32 размерам — потому что системе удобнее прыгать со смещением по 32 бита (даж в 64-битных операционках), чем прыгать по byte- или другим менее нестандартным размерам. Т.е. в случае приведённых к Int32 типам — операций требуется в среднем меньше.

DreamWalker
11.09.2019 12:07Библиотека простая в использовании, но если вдруг её авторы читают сей пост, прошу, дайте более удобную возможность влиять на структуру таблицы результатов.
А чего не хватает?
Bartez Автор
11.09.2019 16:001) Отображать только 4 стоблца: Method, N, Mean, Median, Allocated.
2) Изменить цвета строк, Цвет групп запуска должен чередоваться, например белого и серого, чтоб не сливались. А метод, с наименьшими значениями по 3-м столбцам (Mean, Median, Allocated) — выделять цветом.
Примерно пол года назад, пробовал реализовать вышеописанное стандартными, через конфигурации. Не помню, во что именно упёрся, но пришлось написать свой конвертер таблицы результатов. Код конвертора получился «грязным», но зато таблицу результатов анализировать стало намного удобнее и приятнее. Картинки с бечмарками из поста как раз и иллюстрируют отображение, которое хотелось бы получить через конфигурацию.
Если вы знаете, как реализовать вышеописанное, буду очень благодарен.

force
11.09.2019 18:02Можно добавить ещё про культуры и сравнения. Всякие string.IndexOf, .ToString — которые любят использовать текущую культуру. А если мы точно знаем что у нас есть тупой ascii или нам нужен подобный формат, то можно на подобном не один коробок спичек сэкономить.
Taritsyn
11.09.2019 21:09Внимательный и опытный читатель может заметить что, например ключевое слово sealed никак не влияет на производительность. Сейчас это действительно так, но в следующих версиях всё может измениться.
Еще в первом издании «CLR via C#. Программирование на платформе Microsoft .NET Framework 2.0 на языке C#. Мастер класс» на странице 159 у Рихтера написано:
Производительность. Как уже говорилось, невиртуальные методы вызываются быстрее виртуальных, поскольку для последних CLR во время выполнения проверяет тип объекта, чтобы выяснить, где находится метод. Однако, встретив вызов виртуального метода в изолированном типе, JIT-компилятор может сгенерировать более эффективный код, задействовав невиртуальный вызов. Это возможно потому, что у изолированного класса не может быть производных классов.
Там еще был пример, но я не могу показать его, потому что могу этим нарушить авторские права.Bartez Автор
12.09.2019 01:17Для времени, когда был актуален .NET Framework 2.0, скорее всего, всё именно так и было. Но сейчас, sealed класс с виртуальным методом даже не скомпилируется (код ошибки CS0549). Поэтому сейчас такой оптимизации нет. Лично для меня, такое поведение было ожидаемым.
Тем не менее, как раз ваш пример и подтверждает основной посыл, заложенный в 9-ом разделе. Теоретически, любое уточняющее ключевое слово может улучшить производительность, если не сегодня так завтра.Deosis
12.09.2019 09:30Оптимизация есть, просто sealed нужно ставить не в базовом классе.
Если код сильно виртуальный, то подобная оптимизация экономит одно обращение к памяти.
А вместе с инлайнингом работает ещё эффективнее.
ПС. В sealed классе компилятор не выдает предупреждение на использование виртуальных методов в конструкторе.
Taritsyn
12.09.2019 10:12Оптимизация есть, просто sealed нужно ставить не в базовом классе.
Класс, помеченный модификаторомsealedне может быть базовым, потому чтоsealedзапрещает наследование.
Taritsyn
12.09.2019 10:53Но сейчас, sealed класс с виртуальным методом даже не скомпилируется (код ошибки CS0549).
Error CS0549 'SealedClass.Bar()' is a new virtual member in sealed class 'SealedClass'
Виртуальные методы никогда нельзя было определять в классе, помеченном модификаторомsealed. Они должны определяться в базовом классе.
Это совершенно базовые вещи, без которых, в принципе, нельзя устроиться на работу C#-программистом.

marshinov
13.09.2019 17:37Там еще был пример, но я не могу показать его, потому что могу этим нарушить авторские права.
Мне объясняли, что в «целях цитирования» не нарушите, если явно скажете про Рихтера (что сделано): www.consultant.ru/document/cons_doc_LAW_64629/84bbd636598a59112a4fe972432343dd4f51da1d. Но я не юрист.Taritsyn
13.09.2019 18:21+1Пример из книги Джеффри Рихтера «CLR via C#. Программирование на платформе Microsoft .NET Framework 2.0 на языке C#. Мастер-класс. / Пер. с англ. — М.: Издательство «Русская Редакция»; СПб.: Питер, 2007», который показывает как модификатор
sealedвлияет на производительность:
Например, в следующем коде JIT-компилятор может вызвать виртуальный метод
ToStringневиртуально.
using System; public sealed class Point { private Int32 m_x, m_y; public Point(Int32 x, Int32 y) { m_x = x; m_y = y; } public override String ToString() { return String.Format("({0}, {1})", m_x, m_y); } public static void Main() { Point p = new Point(3, 4); // Компилятор C# вставит здесь инструкцию callvirt, // но JIT-компилятор оптимизирует этот вызов и сгенерирует код // для невиртуального вызова ToString, // поскольку p имеет тип Point, являющийся изолированным. Console.WriteLine(p.ToString()); } }
Taritsyn
12.09.2019 09:43Оптимизация есть, просто sealed нужно ставить не в базовом классе.
Класс, помеченный модификаторомsealedне может быть базовым, потому чтоsealedзапрещает наследование.White_Scorpion
12.09.2019 11:41-1Ээээ…
Что вы подразумеваете под понятием "базовый тип"?
String — являается вроде как базовым классом в .NET, и между тем он вполне себе — sealed.Taritsyn
12.09.2019 11:48Базовый класс, а не базовый (элементарный) тип. Вы подменяете понятия или просто троллите.
Базовый класс – это любой класс, от которого можно наследоваться.White_Scorpion
12.09.2019 13:08Нет, я точно не троллю, а уточняю, для себя. Во избежание непонимания.
И вы тогда немного не точны: Базовый класс — это не любой класс, а не имеющий суперкласса, т.е. тот что находится в основании дерева.
Taritsyn
12.09.2019 13:54…, а не имеющий суперкласса, …
Это вообще терминология из Java. Вы, наверное, это описание в Википедии подсмотрели?
marshinov
12.09.2019 12:21+1Статью хорошо дополняет: Federico Lois — Patterns for high-performance C#.

Sineni
12.09.2019 12:42Когда писал аналогичную статью, но решил задержать её до выхода .NET Core 3.0 -_-
Taritsyn
12.09.2019 14:33Прочитав эту статью и комментарии к ней, я прихожу к неутешительному выводу, что Хабр становиться похож на книгу моего детства:

На данный момент, многие хорошие фронтендеры уже мигрировали на Medium. И не хочется, чтобы тоже самое произошло с .NET-разработчиками. Перед тем, как публиковать статьи проверяйте информацию в авторитетных источниках или давайте прочитать их своим старшим коллегам.
Kanut
Вопрос к пункту 1: а .Where() разве не возвращает IQueryable который уже автоматом имплементирует IEnumerable? Или я что-то путаю?
Bartez Автор
Всё верно! Но так обычно не делают — небезопасно. Например, в данном случае connceton к БД может быть закрыт до того, как данные реально попадут в слой представления. И это не единственная причина. Нельзя представлению никак влиять на БД. В случае возврата IQueryable объекта, такая возможность есть.
Kanut
Ну это спорный пункт. У нас например бизнес-логика специально получает IQueryable чтобы добавить к нему свои LINQ выражения. И таким образом запрос к базе данных формируется динамически и выполняется ровно в тот момент когда БЛ действительно нужны данные. И следовательно не надо тащить из базы данных ненужные Item's. И это как бы тоже приличная оптимизация получается.
Ну и даже если такое не нужно, то на мой взгляд логичнее всё равно вещи, которые касаются БД, закапсулировать в ваш storage. Как раз таки чтобы каждый раз не думать есть там ещё открытое соединение или нет. И не думать при написании БЛ надо ставить.ТoArray() или.ТoList() или вообще ничего не ставить....
П.С. А если взять проекты где используется какой-нибудь NHibernate, то там за "совет" везде ставить.ТoArray() или.ТoList() с вами могут и очень нехорошие вещи сделать :) Это я к тому что на мой взгляд ваш пункт 1 является хорошим советом далеко не во всех ситуациях.