

Сегодня свершился релиз нового и очень полезного опенсорсного проекта, созданного дирекцией разработки ITSumma — плагина в Grafana для мониторинга Kubernetes. Он включён в официальный графана-стор — grafana.com/grafana/plugins/devopsprodigy-kubegraf-app
Его ключевые полезности:
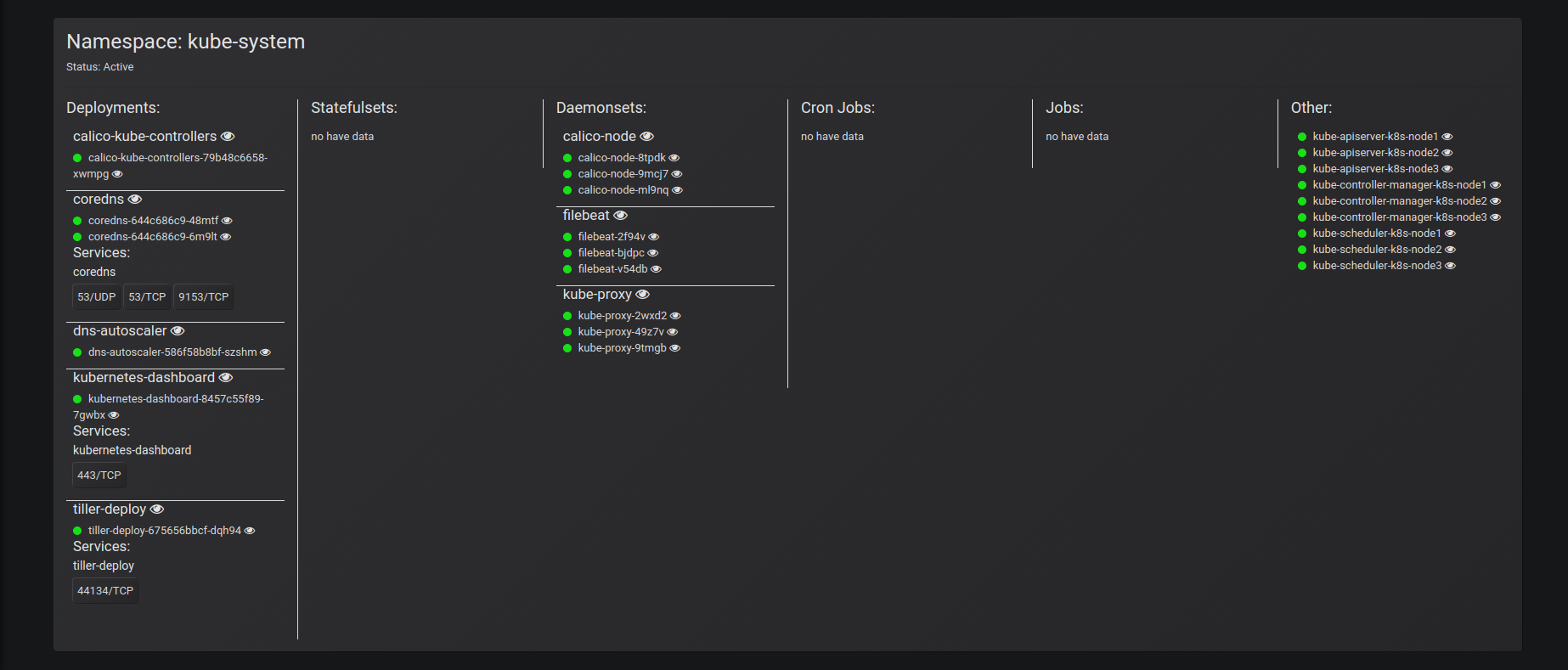
- интеграция с k8s-api для построения полной карты ваших приложений + группировка по неймспейсам + привязка к подам/сервисам.
- графическое представление распределения приложений по нодам k8s-кластера в реальном времени.
- реалтайм статистика о статусе приложений/подов в кластере и сообщений об ошибках (например, если ваше приложение перестало проходить liveness-probes).
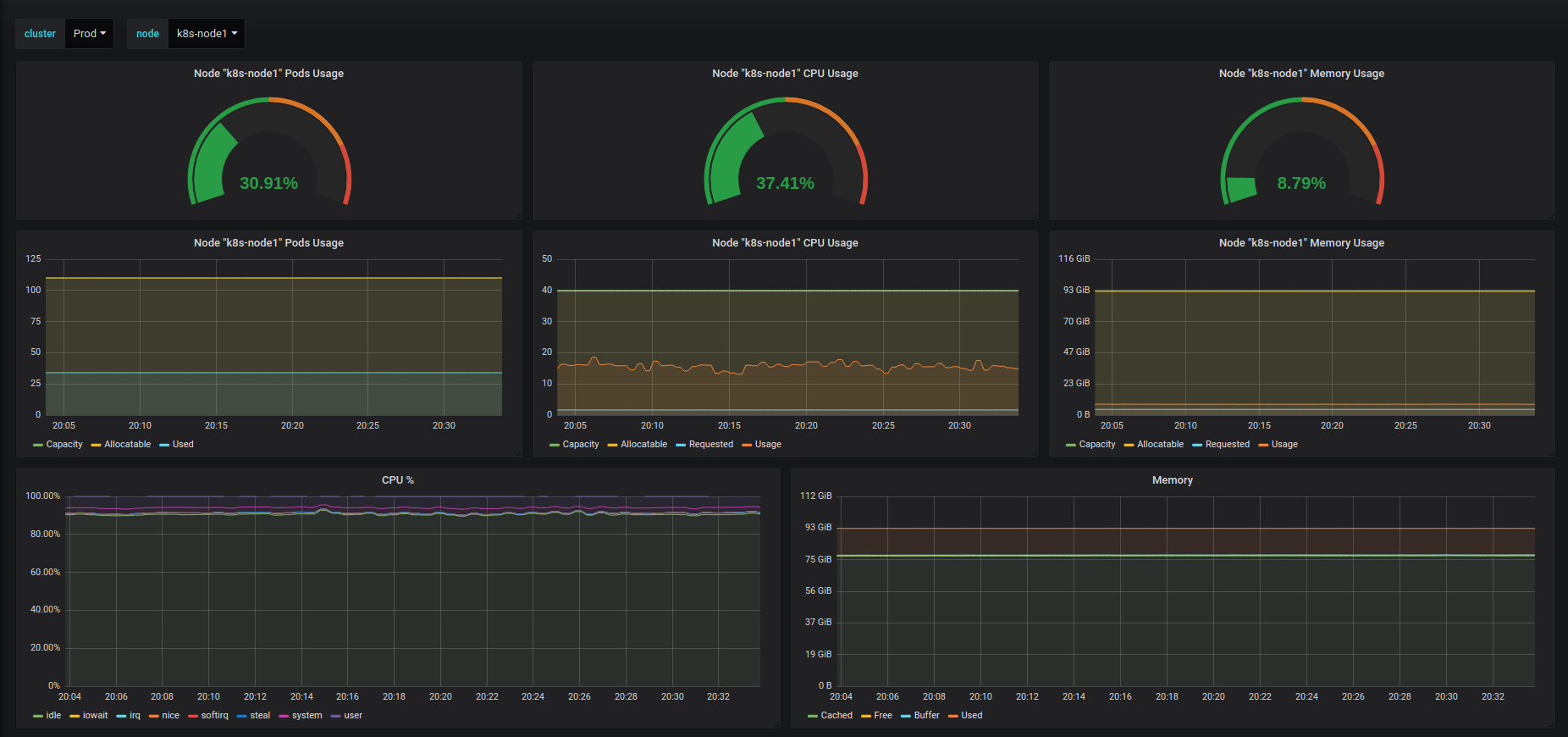
- дашборды со статистикой различных параметров нод кластера (использование CPU, памяти, нагрузки на дисковую подсистему и сетевые интерфейсы), а также со статистикой по использованию ресурсов конкретным подом (CPU, память, сетевые интерфейсы ) и по статусам deployment’ов/statefulset’ов/daemonset’ов, в которых можно посмотреть количество доступных реплик приложения, количество запущенных контейнеров этим приложением и количество рестартов контейнеров.
- отдельная визуализация для просмотра реалтайм статистики о состоянии нод в кластере.
Откуда плагин собирает информацию?
Конфигурация плагина предусматривает сбор данных, во-первых, с API-сервера k8s (для построения карты ваших приложений, сбора состояний приложений, информации о пройденных пробах и т.д.). Также в плагине отдельно выставляется дополнительный Prometeus datasource (сбор метрик с kube-state-metrics и node-exporter’а).
Почему и зачем мы это сделали?
Всё просто: аналогичных плагинов — ровно один, и он уже около года не поддерживается.
Что нас в нём, помимо этого, не устраивало:
- отсутствие грамотной визуализации карты приложений.
- несовместимость с текущими версиями node-exporter'a и kube-state-metrics'a.
- отсутствие поддержки мониторинга statefulset'ов.
Ну, и и мы просто можем себе это позволить! ;-)
Звёздочки, ишшуи и пулреквесты приветствуются — github.com/devopsprodigy/kubegraf
И, конечно, большое спасибо Александру Зобнину за поддержку с воздуха!
Очень скоро я расскажу всю историю создания: «как это было». Не переключайтесь (с)
Комментарии (10)

ferocactus
11.09.2019 14:46Есть ли варианты применения этого плагина к Openshift кластеру?

sergei_sporyshev Автор
12.09.2019 11:30честно сказать — пока даже не пробовали) но идею в блокнотик с идеями записали!


gecube
прошу больше скриншотов. А что такое карта приложений? Я вообще ожидаю увидеть что-то типа графа связей как у Appdynamics или хотя бы как Istio рисует.
sergei_sporyshev Автор
В данный момент «Карта приложений» — это визуальное разбиение всего проекта на неймспейсы, в каждом из которых есть 6 блоков: deployments, statefulsets, daemonsets, jobs, cronjobs, other (отдельные поды)
В каждой из вложенных сущностей указан список подов, активных в данный момент, и сервисов, по которым приложение доступно (с указанием порта, протокола)
Визуальный граф у нас в планах, следите за изменениями)
gecube
ну, мы пока визуально кластер видим в панели ранчера. Там вся эта разбивка по workloads/secrets есть и далее проваливаться по pod'ам и контейнерам тоже можно. Пока ранчеровский взгляд как это надо отображать кажется самым вменяемым. Но, повторюсь, это не совсем "карта сервисов"
iwram
Тоже используем ранчер. Сделал такие же экспортеры и графики, пробовал на голом кластере. Не понимаю, чем решение в статье отличается от хорошо настроенного прометеуса в том же ранчере (ну и с дальнейшим переносом на голый кластер с такими же метриками).
sergei_sporyshev Автор
Изначальная идея пошла от «хочу все видеть в одном месте» (и данные о кластере из апи, и метрики, и «просто лампочки что все хорошо»)
Вариант с хорошо настроенным промом и собственными дашбордами никто не отменял, мы в своем решении собрали наработки с всех проектов мониторинга прошедших через нас, причем как с точки зрения адмнистраторов-дежурных-отделамониторинга, так и с точки зрения девелоперов и бизнеса