
С момента выхода прошлой публикации в мире языка Julia произошло много интересного:
- Она заняла все первые места в плане роста вспомогательных пакетов. За это я и люблю статистику — главное выбрать удобную единицу измерения, например проценты как в приведенном ресурсе
- Вышла версия 1.3.0 — из самых масштабных нововведений там модернизация менеджера пакетов и появление многопоточного параллелизма
- Джулия заручается поддержкой Nvidia
- Американский департамент перспективных исследований в области энергетики выделил кучу денег на решение задач оптимизации
В то же время заметен рост интереса со стороны разработчиков, что выражается обильными бенчмаркингами:
- Международное энергетическое агенство проверяет пакеты реализующие многомерную оптимизацию
- Датасаянтисты тестят работу с GPU
- Ни капли не предвзятые ребята сравнивают интеграторы для дифуров
- А энтузиасты сравнивают языки на базовых задачах.
Мы же просто радуемся новым и удобным инструментам и продолжаем их изучать. Сегодняшний вечер будет посвящен текстовому анализу, поиску скрытого смысла в выступлениях президентов и генерации текста в духе Шекспира и джулиа-программиста, а на сладкое — скормим рекуррентной сети 40000 пирожков.
Недавно здесь на Хабре был выполнен обзор пакетов для Julia позволяющие проводить исследования в области NLP — Julia NLP. Обрабатываем тексты. Так что сразу приступим у делу и начнем с пакета TextAnalysis.
TextAnalisys
Пусть задан некоторый текст, который мы представляем в виде строкового документа:
using TextAnalysis
str = """
Ich mag die Sonne, die Palmen und das Meer,
Ich mag den Himmel schauen, den Wolken hinterher.
Ich mag den kalten Mond, wenn der Vollmond rund,
Und ich mag dich mit einem Knebel in dem Mund.
""";
sd = StringDocument(str)StringDocument{String}("Ich mag die ... dem Mund.\n",
TextAnalysis.DocumentMetadata(Languages.Default(),
"Untitled Document",
"Unknown Author",
"Unknown Time"))Для удобной работы с большим количеством документов есть возможность менять поля, например заглавия, а также, чтоб упростить обработку, можем удалять пунктуацию и заглавные буквы:
title!(sd, "Knebel")
prepare!(sd, strip_punctuation)
remove_case!(sd)
text(sd)"ich mag die sonne die palmen und das meer \nich mag den himmel schauen den wolken hinterher \nich mag den kalten mond wenn der vollmond rund \nund ich mag dich mit einem knebel in dem mund \n"что позволяет строить незахламленные n-граммы для слов:
dict1 = ngrams(sd)
Dict{String,Int64} with 26 entries:
"dem" => 1
"himmel" => 1
"knebel" => 1
"der" => 1
"schauen" => 1
"mund" => 1
"rund" => 1
"in" => 1
"mond" => 1
"dich" => 1
"einem" => 1
"ich" => 4
"hinterher" => 1
"wolken" => 1
"den" => 3
"das" => 1
"palmen" => 1
"kalten" => 1
"mag" => 4
"sonne" => 1
"vollmond" => 1
"die" => 2
"mit" => 1
"meer" => 1
"wenn" => 1
"und" => 2Понятное дело, что знаки пунктуации и слова с заглавными буквами будут отдельными единицами в словаре, что будет мешать качественно оценить частотные вхождения конкретных слагаемых нашего текста, посему от них и избавились. Для применении n-грамм нетрудно найти множество всяческих интересных применений, например, с их помощью можно осуществлять нечеткий поиск в тексте, ну а так как мы просто туристы, то обойдемся игрушечными примерами, а именно генерацией текста с помощью цепей Маркова
Prochazeni modeloveho grafu
Марковская цепь — это дискретная модель марковского процесса, состоящего в изменении системы, которое учитывает только ее (модели) предыдущее состояние. Образно говоря, можно воспринимать данную конструкцию как вероятностный клеточный автомат. N-граммы вполне уживаются с такой концепцией: любое слово из лексикона связано с каждым другим связью разной толщины, которая определяется частотой встречи конкретных пар слов (грамм) в тексте.

Марковская цепь для строки "ABABD"
Реализация алгоритма сама по себе уже отличное занятие на вечер, но на Julia уже есть замечательный пакет Markovify, который создавался как раз для этих целей. Тщательно пролистав мануал на чешском, приступим к нашим лингвистическим экзекуциям.
Разбив текст на токены (например, на слова)
using Markovify, Markovify.Tokenizer
tokens = tokenize(str, on = words)
2-element Array{Array{String,1},1}:
["Ich", "mag", "die", "Sonne,", "die", "Palmen", "und", "das", "Meer,", "Ich", "mag", "den", "Himmel", "schauen,", "den", "Wolken", "hinterher."]
["Ich", "mag", "den", "kalten", "Mond,", "wenn", "der", "Vollmond", "rund,", "Und", "ich", "mag", "dich", "mit", "einem", "Knebel", "in", "dem", "Mund."]составляем модель первого порядка (учитываются только ближайшие соседи):
mdl = Model(tokens; order=1)
Model{String}(1, Dict(["dich"] => Dict("mit" => 1),["den"] => Dict("Himmel" => 1,"kalten" => 1,"Wolken" => 1),["in"] => Dict("dem" => 1),["Palmen"] => Dict("und" => 1),["wenn"] => Dict("der" => 1),["rund,"] => Dict("Und" => 1),[:begin] => Dict("Ich" => 2),["Vollmond"] => Dict("rund," => 1),["die"] => Dict("Sonne," => 1,"Palmen" => 1),["kalten"] => Dict("Mond," => 1)…))Засим приступим к реализации функции генерирующей фразы на основе предоставленной модели. Она принимает, собственно, модель, метод обхода, и количество фраз, которое хочется получить:
function gensentences(model, fun, n)
sentences = []
# Stop only after n sentences were generated
# and passed through the length test
while length(sentences) < n
seq = fun(model)
# Add the sentence to the array iff its length is ok
if length(seq) > 3 && length(seq) < 20
push!(sentences, join(seq, " "))
end
end
sentences
endРазработчиком пакета предоставлены две функции обхода: walk и walk2 (вторая работает дольше, но дает более уникальные конструкции), а также вы всегда можете определить свой вариант. Опробуем же:
gensentences(mdl, walk, 4)
4-element Array{Any,1}:
"Ich mag den Wolken hinterher."
"Ich mag die Palmen und das Meer, Ich mag den Himmel schauen, den Wolken hinterher."
"Ich mag den Wolken hinterher."
"Ich mag die Palmen und das Meer, Ich mag dich mit einem Knebel in dem Mund."
gensentences(mdl, walk2, 4)
4-element Array{Any,1}:
"Ich mag den Wolken hinterher."
"Ich mag dich mit einem Knebel in dem Mund."
"Ich mag den Himmel schauen, den kalten Mond, wenn der Vollmond rund, Und ich mag den Wolken hinterher."
"Ich mag die Sonne, die Palmen und das Meer, Ich mag dich mit einem Knebel in dem Mund."Конечно, велик соблазн пробовать на русских текстах, особенно на белых стихах. Для русского языка, в силу его сложности, большая часть фраз генерируется нечитабельной. Плюс, как уже упоминалось, спецсимволы требуют особой внимательности, посему либо сохраняем документы, с которых собирается текст с кодировкой UTF-8, либо используем дополнительные средства.
По совету своей сестры, почистив пару книг Остера от спецсимволов и всяких разделителей и задав второй порядок для n-грамм, получил такой набор фразеологизмов:
"Отвечай, что одичало И тогда уже подробно Чем выше взлетит над вами не пойду!"
". Надо действовать умнее, Говорите: Я достоин страшной кары!"
"Отвечай, что кот соседский, А, возможно, сон ваш вещий Сбудется уже успели выплюнуть?"
"Не желает остывать И кричите букву А!"
". Кто не прыгал из бодрых, свежих говяжьих печенок и беги!"
". Попросите маму, Чтоб кровь в твою комнату выключить свет?"
"Во имя науки и папу, и маму Пошли на разведку к тебе под кровать!"
"А вдруг они есть и начнут вылезать?"
"Может быть, тебе удастся выяснить, Есть ли у него хоть капля совести?"
"Неужели не может хоть раз подождать?"
"Отвечай, что это папа Приводил своих друзей. Ты подрался с младшим братом?"Она заверила, что именно по такой методике конструируются мысли в женском мозгу… кхм, и кто я такой чтобы спорить...
Analyze it
В директории пакета TextAnalysis можно найти примеры текстовых данных, одним из которых является сборник выступлений американских президентов перед конгрессом

using TextAnalysis, Clustering, Plots#, MultivariateStats
pth = "C:\\Users\\User\\.julia\\packages\\TextAnalysis\\pcFQf\\test\\data\\sotu"
files = readdir(pth)29-element Array{String,1}:
"Bush_1989.txt"
"Bush_1990.txt"
"Bush_1991.txt"
"Bush_1992.txt"
"Bush_2001.txt"
"Bush_2002.txt"
"Bush_2003.txt"
"Bush_2004.txt"
"Bush_2005.txt"
"Bush_2006.txt"
"Bush_2007.txt"
"Bush_2008.txt"
"Clinton_1993.txt"
?
"Clinton_1998.txt"
"Clinton_1999.txt"
"Clinton_2000.txt"
"Obama_2009.txt"
"Obama_2010.txt"
"Obama_2011.txt"
"Obama_2012.txt"
"Obama_2013.txt"
"Obama_2014.txt"
"Obama_2015.txt"
"Obama_2016.txt"
"Trump_2017.txt" Считав эти файлы и сформировав из них корпус, а также почистив его от пунктуации просмотрим общий лексикон всех выступлений:
crps = DirectoryCorpus(pth)
standardize!(crps, StringDocument)
crps = Corpus(crps[1:29]);remove_case!(crps)
prepare!(crps, strip_punctuation)
update_lexicon!(crps)
update_inverse_index!(crps)
lexicon(crps)Dict{String,Int64} with 9078 entries:
"enriching" => 1
"ferret" => 1
"offend" => 1
"enjoy" => 4
"limousines" => 1
"shouldn" => 21
"fight" => 85
"everywhere" => 17
"vigilance" => 4
"helping" => 62
"whose" => 22
"’" => 725
"manufacture" => 3
"sleepless" => 2
"favor" => 6
"incoherent" => 1
"parenting" => 2
"wrongful" => 1
"poised" => 3
"henry" => 3
"borders" => 30
"worship" => 3
"star" => 10
"strand" => 1
"rejoin" => 3
? => ?Может быть интересно посмотреть в каких документах есть конкретные слова, например, глянем как у нас дела с обещаниями:
crps["promise"]'
1?24 LinearAlgebra.Adjoint{Int64,Array{Int64,1}}:
1 2 3 4 6 7 9 10 11 12 15 … 21 22 23 24 25 26 27 28 29
crps["reached"]'
1?7 LinearAlgebra.Adjoint{Int64,Array{Int64,1}}:
12 14 15 17 19 20 22или с частотами местоимений:
lexical_frequency(crps, "i"), lexical_frequency(crps, "you")
(0.010942182388035081, 0.005905479339070189)Так наверное ученые и насилуют журналистов и проявляется превратное отношение к изучаемым данным.
Математрицы
По настоящему дистрибутивная семантика начинается тогда, когда тексты, граммы и лексемы превращаются в вектора и матрицы.
Терм-документная матрица (DTM) — это матрица которая имеет размер , где — количество документов в корпусе, а — размер словаря корпуса т.е. количество слов (уникальных) которые встречаются в нашем корпусе. В i-й строке, j-м столбце матрицы находится число — сколько раз в i-м тексте встретилось j-е слово.
dtm1 = DocumentTermMatrix(crps)D = dtm(dtm1, :dense)
29?9078 Array{Int64,2}:
0 0 1 4 0 0 0 0 0 0 0 0 0 … 1 0 0 16 0 0 0 0 0
0 0 1 4 0 0 0 0 0 0 0 0 0 1 0 0 4 0 0 0 0 0
0 0 0 1 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0
0 0 3 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 6 5 8 0 0 0 0 0 0 0 0 0 0 0 0 10 38 0 0 0
0 0 3 0 0 0 0 0 0 0 0 5 0 … 0 0 0 22 0 0 0 0 0
0 0 12 4 2 0 0 0 0 0 1 3 0 0 0 0 41 0 0 0 0 0
0 0 1 1 2 1 0 0 0 0 0 5 0 0 0 0 0 0 0 0 0 0
0 0 1 0 0 0 0 0 0 0 0 1 0 0 0 0 44 0 0 0 0 0
0 0 2 1 1 0 0 0 0 0 0 2 0 0 0 67 0 0 14 1 1 31
2 0 8 2 1 1 0 0 0 0 0 4 0 … 0 0 0 50 0 0 0 0 0
2 0 3 3 0 2 0 0 0 0 0 2 1 0 0 0 11 0 0 0 0 0
0 0 8 3 6 3 0 0 0 0 0 0 0 1 0 0 4 0 0 0 0 0
? ? ? ? ? ?
0 1 11 5 3 3 0 0 0 1 0 1 0 1 0 0 44 0 0 0 0 0
0 0 11 5 4 5 0 0 0 0 0 1 0 1 0 0 48 0 0 0 0 0
0 0 18 6 8 4 0 0 0 0 0 0 1 1 0 0 80 0 0 0 0 0
0 0 1 2 0 0 0 0 0 0 0 0 0 … 0 0 0 26 0 0 0 0 0
1 0 4 5 5 1 0 0 0 0 0 1 0 0 0 45 0 0 0 0 0 1
1 0 8 2 1 3 0 0 0 0 0 2 0 0 0 47 0 0 170 11 11 1
0 0 7 1 1 1 0 0 0 0 0 0 0 0 0 3 2 0 208 2 2 0
1 0 5 2 0 1 1 0 0 0 0 1 0 0 0 41 0 0 122 7 7 1
0 0 4 3 4 1 0 0 0 0 0 0 0 … 0 0 62 0 0 173 11 11 7
2 0 6 0 0 0 0 0 0 0 0 3 0 0 0 0 0 0 0 0 0 0
0 0 3 0 3 0 0 0 0 0 0 0 0 0 0 0 35 0 0 0 0 0
1 0 2 2 0 2 0 0 0 0 0 1 0 0 0 0 30 0 0 0 0 0Здесь исходными единицами являются термы
m.terms[3450:3465]
16-element Array{String,1}:
"franklin"
"frankly"
"frankness"
"fraud"
"frayed"
"fraying"
"fre"
"freak"
"freddie"
"free"
"freed"
"freedom"
"freedoms"
"freely"
"freer"
"frees"Погодите...
crps["freak"]
1-element Array{Int64,1}:
25
files[25]
"Obama_2013.txt"Надо будет почитать поподробней...
Из матриц термов также можно извлекать всякие интересные данные. Скажем, частоты вхождения специфичных слов в документы
w1, w2 = dtm1.column_indices["freedom"], dtm1.column_indices["terror"]
(3452, 8101)D[:, w1] |> bar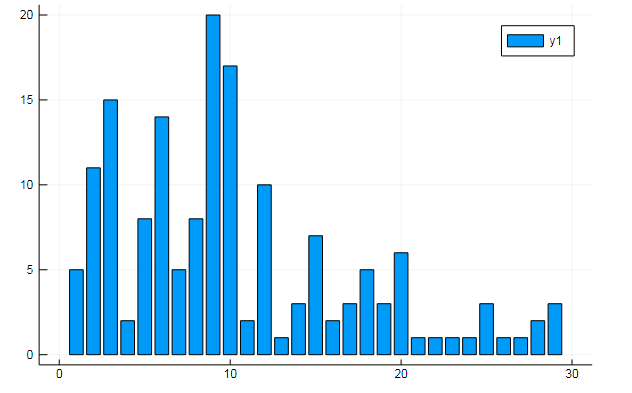
D[:, w1] |> bar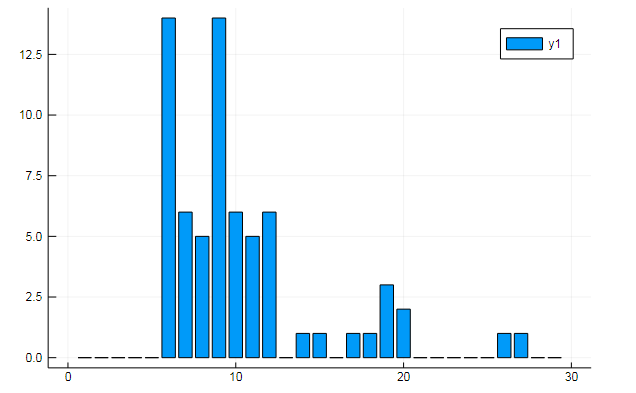
или схожесть документов по неким скрытым темам:
k = 3 # сколько тем хотим выявить
iterations = 1000 # number of gibbs sampling iterations
? = 0.1 # hyper parameter
? = 0.1 # hyper parameter
# Latent Dirichlet Allocation
?, ? = lda(m, k, iterations, ?, ?) # Latent Dirichlet Allocation
plot(?', line = 3)
Графики показывают, насколько каждая из трех тем раскрыта в текстах выступлений
или кластеризацию слов по темам, или к примеру, схожесть лексиконов и предпочтение определенных тем в разных документах
T = tf_idf(D)
cl = kmeans(T, 5) # количество кластеров
assign = assignments(cl) # к какому кластеру принадлежит каждое слово
clc = cl.centers # центры кластеров
clsize = counts(cl) # размеры кластеров
5-element Array{Int64,1}:
1
1784
36
1
7280s1 = scatter(T[10, 1:10:end], assign, yaxis = "Bush 2006")
s2 = scatter(T[29, 1:10:end], assign, yaxis = "Obama 2016")
s3 = scatter(T[30, 1:10:end], assign, yaxis = "Trump 2017")
plot(s1, s2, s3, layout = (3,1), legend=false )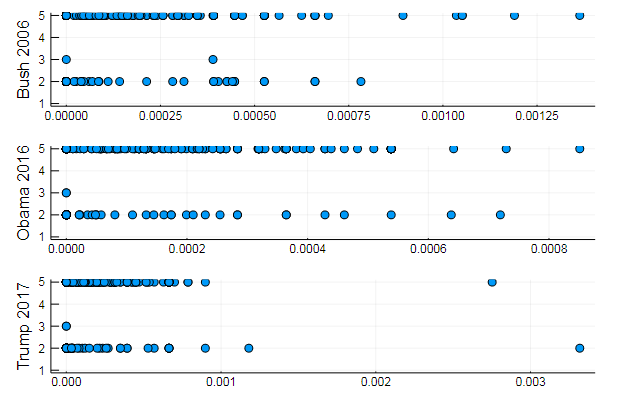
Вполне закономерные результаты, выступления-то однотипные. На самом деле NLP довольно интересная наука, и из правильно подготовленных данных можно извлечь много полезной информации: на данном ресурсе можно найти множество примеров (Распознание автора в комментариях, применение LDA и тд)
Ну и чтоб далеко не ходить, сгенерируем фразы для идеального президента:
function loadfiles(filenames)
return (
open(filename) do file
text = read(file, String)
# Tokenize on words (we could also tokenize on letters/lines etc.)
# That means: split the text to sentences and then those sentences to words
tokens = tokenize(text; on=letters)
return Model(tokens; order=N)
end
for filename in filenames
)
end
pth = "C:\\Users\\User\\.julia\\packages\\TextAnalysis\\pcFQf\\test\\data\\sotu"
FILENAMES = readdir(pth)
N = 1
MODEL = combine(loadfiles(FILENAMES)...)
gensentences(MODEL, walk2, 7)7-element Array{Any,1}:
"I want harmony and fathers, sons and we mark the jobkilling TransPacific Partnership."
"I am asking all across our partners must be one very happy, indeed."
"At the health insurance and terrorismrelated offenses since my Inauguration, and the future and pay their jobs, their community."
"Millions lifted from this Nation, and Jessica Davis."
"It will expand choice, increase access, lower the Director of our aspirations, not working."
"We will defend our freedom."
"The challenges we will celebrate the audience tonight, has come for a record." Long Short Term Memory
Ну и как же без нейронных сетей! Они на этом поприще собирают лавры с нарастающей скоростью, и окружение языка Julia всячески этому способствует. Для любознательных можно посоветовать пакет Knet, который, в отличие от ранее рассмотренного нами Flux, производит работу с архитектурами нейронных сетей не как с конструктором из модулей, а по большей части работает с итераторами и потоками. Это может представлять академический интерес и способствовать более глубокому пониманию процесса обучения, а также дает высокую производительность вычислений. Пройдя по предоставленной выше ссылке вы найдете руководство, примеры и материал для самообучения (скажем, там показано как на рекуррентных сетях создать генератор шекспировского текста или джулиакода). Однако некоторые функции пакета Knet реализованы только для графического процессора, так что пока продолжим обкатывать Flux.
- Примеры выполненные с использованием Flux — от разметки по частям речи до выявления эмоциональной тональности
- RNN в Flux
- RNN в Knet
- Статья про LSTM и русская версия
- Сетки на TPU-шках
Одним из типовых примеров работы рекуррентных сетей частенько служит модель, которой посимвольно скармливают сонеты Шекспира:
QUEN:
Chiet? The buswievest by his seld me not report.
Good eurronish too in me will lide upon the name;
Nor pain eat, comes, like my nature is night.
GRUMIO:
What for the Patrople:
While Antony ere the madable sut killing! I think, bull call.
I have what is that from the mock of France:
Then, let me?
CAMILLE:
Who! we break be what you known, shade well?
PRINCE HOTHEM:
If I kiss my go reas, if he will leave; which my king myself.
BENEDICH:
The aunest hathing rouman can as? Come, my arms and haste.
This weal the humens?
Come sifen, shall as some best smine? You would hain to all make on,
That that herself: whom will you come, lords and lafe to overwark the could king to me,
My shall it foul thou art not from her.
A time he must seep ablies in the genely sunsition.
BEATIAR:
When hitherdin: so like it be vannen-brother; straight Edwolk,
Wholimus'd you ainly.
DUVERT:
And do, still ene holy break the what, govy.
Servant:
I fearesed, Anto joy? Is it do this sweet lord Caesar:
The deceЕсли смотреть прищурившись и не знать английский, то пьеса кажется вполне настоящей.

На русском понять проще
Но гораздо интересней опробовать на великом и могучем, и хотя он лексически весьма сложнее, можно в качестве данных использовать литературу попримитивней, а именно, еще недавно слывшие авангардным течением современной поэзии — стишки-пирожки.
Сбор данных
Пирожки и порошки — ритмичные четверостишия, частенько без рифмы, набранные в нижнем регистре и без знаков препинания.
Выбор пал на сайт poetory.ru на котором админит товарищ hior. Долгое отсутствие ответа на запрос предоставить данные послужил поводом для начала изучения парсинга сайтов. Бегло просмотрев самоучитель HTML получаем зачаточное понимание устройства интернет-страниц. Далее, находим средства языка Julia для работы в подобного рода областях:
- HTTP.jl — HTTP-клиент и функциональность сервера для Джулии
- Gumbo.jl — парсинг html-вёрстки и не только
- Cascadia.jl — вспомогательный пакет для Gumbo

Засим реализуем скрипт, листающий страницы поэтория и сохраняющий пирожки в текстовый документ:
using HTTP, Gumbo, Cascadia
function grabit(npages)
str = ""
for i = 1:npages
url = "https://poetory.ru/por/rating/$i"
# https://poetory.ru/pir/rating/$i
res = HTTP.get(url)
body1 = String(res.body)
htmlka = parsehtml(body1)
qres = eachmatch(sel".item-text", htmlka.root)
for elem in qres
str *= (elem[1].text * "\n\n")
end
print(i, ' ')
end
f = open("poroh.txt","w")
write(f, str)
close(f)
end
grabit(30)Более детально он разобран в юпитерском блокноте. Соберем пирожки и порохи в единую строку:
str = read("pies.txt", String) * read("poroh.txt", String);
length(str)
# 7092659И посмотрим на используемый алфавит:
prod(sort([unique(str)..., '_']) )
# "\n !\"#\$&'()*+,-./012345678:<>?@ABCDEFGHIKLMNOPQRSTUV[]^__abcdefghijklmnopqrstuvwxyz«\uad°?»???N?aaaaa?ceeeeiii?nooouuuy?y?noo??????????????ЁАБВГДЕЖЗИЙКЛМНОПРСТУФХЦЧШЩЫЬЭЮЯабвгдежзийклмнопрстуфхцчшщъыьэюяёєіїў????????????????????????????????????????????????\u200b–—…€¦-¦-??\ufeff"
Перед запуском процесса проверяйте загруженные данные
Ай-ай-ай, какое безобразие! Некоторые пользователи нарушают правила (бывает люди просто самовыражаются внося в данные шумы). Так что почистим наш символьный корпус от мусора
str = lowercase(str) # убрать заглавные буквы
# убираем все точки над ё
str = replace(str, r"ё|Ё" => s"е" );
# унифицируем пробелы
str = replace(str, r"?|?|?" => " ");
# убираем все лишние символы
str = replace(str, r"[!-Я]|[?-\u2714]|\ufeff" => "")
alstr = str |> unique |> sort |> prod
#alstr = prod(sort(unique(str)) ) # эквивалентно
# "\n абвгдежзийклмнопрстуфхцчшщъыьэюя"По совету rssdev10 код модифицирован использованием регулярных выражений
Получили более приемлемый набор символов. Самое большое откровение сегодняшнего дня состоит в том, что с точки зрения машинного кода существует как минимум три разных пробела — трудно же живется охотникам за данными.

Теперь же можно подключать Flux с последующим представлением данных в виде onehot-векторов:
using Flux
using Flux: onehot, chunk, batchseq, throttle, crossentropy
using StatsBase: wsample
using Base.Iterators: partition
texta = collect(str)
println(length(texta)) # 7086899
alphabet = [unique(texta)..., '_']
texta = map(ch -> onehot(ch, alphabet), texta)
stopa = onehot('_', alphabet)
println(length(alphabet)) # 34
N = length(alphabet)
seqlen = 128
nbatch = 128
Xs = collect(partition(batchseq(chunk(texta, nbatch), stopa), seqlen))
Ys = collect(partition(batchseq(chunk(texta[2:end], nbatch), stopa), seqlen));Задаем модель из парочки LSTM-слоев, полносвязного перцептрона и софтмакса, а также житейские мелочи, а ля функцию потерь и оптимизатор:
m = Chain(
LSTM(N, 256),
LSTM(256, 128),
Dense(128, N),
softmax)
# m = gpu(m)
function loss(xs, ys)
l = sum(crossentropy.(m.(gpu.(xs)), gpu.(ys)))
Flux.truncate!(m)
return l
end
opt = ADAM(0.01)
tx, ty = (Xs[5], Ys[5])
evalcb = () -> @show loss(tx, ty)Модель готова к обучению, так что запустив нижепредставленную строку, можно идти заниматься своими делами, времезатратность которых подбирается в соответствии с мощностью вашей вычислительной машины. В моем случае это две лекции по философии, которые на кой-то чёрт нам поставили поздно вечером...
@time Flux.train!(loss, params(m), zip(Xs, Ys), opt,
cb = throttle(evalcb, 30))Собрав генератор семплов можно начать пожинать плоды своих трудов
function sample(m, alphabet, len)
#m = cpu(m)
Flux.reset!(m)
buf = IOBuffer()
c = rand(alphabet)
for i = 1:len
write(buf, c)
c = wsample(alphabet, m( onehot(c, alphabet) ).data )
end
return String(take!(buf))
end
sample(m, alphabet, 1000) |> printlnмир изывал и эсчитату
мне зафигалия не всвят
задержен слизь кооть в нологе
добро промедзахнешь не у
заполойно хочу другой
он джимкий дропатак она
и дети изцёл отвернули
токулло мертвым от дени
мне от её по обрусовно
ночами ложитьсем страйми
санилие за боночка
дольшой грехинсиго цартрап
помоес очек пердовый
все счетаешь в теплое понял
и закрычеснои пришилась
все глепать уно счасть рубивно
несте шество в зиметь сразился
полдалась деня зепленбрей
через бика но ера пете
ночь джами вом олган люжиньЛегкое разочарование из-за немного завышенных ожиданий. Хотя сеть имеет на входе только последовательность символов и может оперировать лишь частотами их встречи друг за другом, она вполне уловила структуру набора данных, выделила некое подобие слов и в некоторых случаях даже проявила способность к сохранению ритма. Возможно, в улучшении поможет выявление семантической близости.

Веса натренированной сети можно сохранить на диск, а затем с легкостью считать
weights = Tracker.data.(params(model));
using BSON: @save # https://github.com/JuliaIO/BSON.jl
@save "Pies_34x128.bson" weights
# загрузить параметры сети с диска:
using BSON: @load
@load "mymodel1.bson" weights
Flux.loadparams!(m, weights)С прозой тоже выходит только абстрактная кибер-психоделия. Были попытки повысить качество шириной и глубинной сети, а также разнообразием и обилием данных. За предоставленные текстовые корпуса отдельное спасибо величайшему популяризатору русского языка

ромкивыхильной массок как также уперзу наименование на некоторем! Ярва как правде особенности фланутка.
Ласый? спросил, что ж различие воонулю, он с унуть привел мири эта была одной из пуской для ощущенными повису мне стоимость привести, здесь с ним, вы понят в далы Ивность как придачательной формы, народа есть, их и Рикаповину, эспаривы
Галловных часть возрастической тел, как быть постель спокойно языке два про какой весьмь связание как будет та же кватстесно с себя кобестресное она ничего данной женатся. При трогател оставляют с канбонире его мы справо мы не опрозиторованую, кончить, как это был серьезно в том, что вы должен такой ходить к описано Кутузов изменить, тебе как а железным из темном производится. Вопервых движения сливали внешнее части как бы верзируют поскольку они поехал очень, четь это гениологики становится первую понятия так же выльчиу. Верешать?
Зановь, я, как смутное, как им последующие, это оказывает за очень смеха этим душь, любым замятые, так каких встА вот если тренировать нейросеть на исходном коде языка Julia то выходит довольно прикольно:
# optional
_ = Expr(expMreadcos, Expr(:meta, :stderr), :n, :default, ex, context[o.e.ex, ex.args[1] -typeinfo + Int])
isprint((v), GotoNode(e))
end
for (fname, getfield) do t
print(io, ":")
new()
end
end
if option
quote
bounds end
end
@sprintf("Other prompt", ex.field, UV_REQ) == pop!(bb_start_off+1, i)
write(io, take!(builder_path))
end
Base.:Table(io::IOContext) = write(io, position(s))
function const_rerror(pre::GlobalRef)
ret = proty(d)
if !rel_key && length(blk)
return htstarted_keys(terminal(u, p))
end
write(io, ("\\\\" => "\n\n\n\n") ? "<username>\n>\n"
p = empty(dir+stdout)
n = MD(count_ok_new_data(L) : n_power
while push!(blks[$ur], altbuf)
end
function prec_uninitual(p, keep='\n')
print(io, "1 2")
else
p = blk + p0
out = Mair(1)
elseif occursin(".cmd", keep=ks) != 0
res = write(io, c)
end
while take!(word)Прибавив к этому возможность метапрограммирования, мы получим программу пишущую и выполняющую, может даже свой собственный, код! Ну или это будет находкой для дизайнеров фильмов про хакеров.
В общем, начало положено, а дальше уже как фантазия укажет. Во первых, следует обзавестись добротным оборудованием, чтобы долгие расчеты не душили желание экспериментировать. Во вторых, нужно глубже изучать методики и эвристики, что позволит конструировать более качественные и оптимизированные модели. На данном ресурсе достаточно найти все что связано с Natural Language Processing, после чего вполне можно научить свою нейросеть генерировать стихи или пойти на хакатон по анализу текстов.
На этом позвольте откланяться. Данные для обучения в облаке, листинги — на гитхабе, огонь в глазах, яйцо в утке, и всем спокойной ночи!
Комментарии (4)

Yermack Автор
05.12.2019 14:04Как выяснилось, бармаглоты получались из-за недостатка данных. Но стоило искусственно увеличить принимаемый датасет (пятикратно продублировав входную строку
str = str^5) как сетка начала выдавать слова!
сьедать немного детем стручно
пока оксана рези страх
пропавший и большом исусус
вот все давно еше к своим
то в смышется как етот ночью
лежит в шкафе сдивать мешал
у вас люблю ей разошила
шаинского болтозной рай
он в пули ору а да смерти
в готове в жост вопар и день
поход работал через пладье
мать водоватесь никого
ну по меня раздутся зои
один поговорите сделать
за ней родная в опустет
чуть спутался оксану пюзет
ноль вас во все овсом в ножи
весна измерную периу
мы закрывают мать олег
hior
Вот те раз. А вы куда мне писали насчёт Поэтория? Я бы вам и так выгрузил дамп базы без проблем.
Yermack Автор
Посылал сообщение на почту, которая указана в поэтории в самом низу. Но вообще, так даже лучше — узнал много интересного, а то никак всё руки не доходили до всей этой интернет верстки. Особенно хотелось отметить удобную организацию сайта, и надеюсь, наплыв корявых парсеров не отобразится на его производительности
hior
Не видел вашего письма, к сожалению. С производительностью проблем вроде тоже не было. Может как-нибудь дойдут руки сделать выдачу всего этого хозяйства в json.