
Предлагаю вашему вниманию перевод оригинальной статьи от Mike Nakhimovich

Давным-давно я работал в «Нью-Йорк Таймс» и создал библиотеку под названием Store, которая была «библиотекой Java для легкой, реактивной загрузки данных». Мы создали Store, используя RxJava и шаблоны, взятые из реализации Guava’s Cache. Сегодняшние пользователи приложений ожидают, что обновления данных будут происходить в UI без необходимости делать такие вещи, как pull-to-refresh, чтобы обновить данные или переходить между экранами туда-сюда. Реактивный фронтенд заставил меня задуматься о том, как мы можем иметь декларативные хранилища данных с простыми API, которые абстрагируют сложные функции, такие как многозадачный троттлинг и дисковое кэширование, которые необходимы в современных мобильных приложениях. За три года работы у Store 45 контрибьютеров и более 3500 звёзд на GitHub. Отныне я рад объявить, что Dropbox возьмет на себя активное развитие Store и выпустит его полностью на Kotlin с поддержкой Coroutines и Flow. И теперь Store 4 — это возможность воспользоваться тем, что мы узнали, переосмысливая API и текущие потребности экосистемы Android.
Android проделал большой путь за последние несколько лет. Шаблон размещения сетевого кода в Активити и Фрагментах остался в прошлом. Вместо этого, сообщество все больше сближается с новыми, полезными библиотеками от Google. Эти библиотеки, в сочетании с архитектурной документацией и предложениями теперь составляют основу современных разработок для Android. В качестве примера можно привести руководство по архитектуре Android Jetpack:
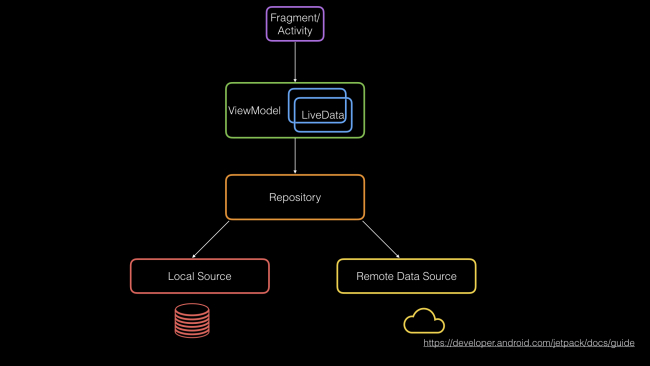
Одно дело предоставлять документацию для шаблонов, но команда Android Jetpack пошла дальше и фактически предоставила нам реализации:

https://developer.android.com/jetpack/docs/guide
- Фрагменты и Активити: Они всегда были рядом, но теперь есть версии AndroidX с такими вещами, как Lifecycle и Scopes для корутин. Фрагменты и Активити дают нам то, что нужно для создания view-слоя нашего приложения.
- View Model и Live Data: Они помогают нам передавать данные, которые мы получаем из репозиториев, без необходимости самостоятельно управлять поворотом экрана и жизненным циклом (Ух ты, мы прошли длинный путь!).
- Room: Избавляет от сложностей при работе с SQLite, предоставляя нам полноценный ORM с поддержкой RxJava и корутин.
- Remote Data Source: Не входя в состав Jetpack, Retrofit и Okhttp от Square решили проблему сетевого доступа на двух различных уровнях абстракции.
Внимательные читатели, возможно, заметили, что я пропустил Репозиторий (не только я, похоже, что команда Jetpack также пропустила его ;-) ). В настоящее время в репозитории есть только несколько примеров кода и нет абстракций многоразового использования, которые работают в различных реализациях. Это одна из главных причин, по которой Dropbox вкладывается в Store, чтобы заполнить этот пробел в архитектурной модели, описанной выше.
Перед тем, как погрузиться в реализацию Store, давайте рассмотрим определение репозитория. Майкрософт предлагает хорошее определение, описывая репозитории как
«… классы или компоненты, инкапсулирующие логику, необходимую для доступа к источникам данных. Они обеспечивают централизованную функциональность общего доступа к данным, для лучшей поддержки и отделения инфраструктуры или технологии, используемой для доступа к базам данных, от слоя предметной области».
Репозитории позволяют работать с данными декларативно. Когда вы объявляете репозиторий, вы определяете, как получить данные, как кэшировать их и что вы будете использовать для их передачи. Затем клиенты могут объявить объекты запроса для интересующих их частей данных, а репозиторий обрабатывает остальные.
Какую проблему пытается решить Store?
Четыре года назад, еще до того, как мы начали работать над Store, использование больших объемов данных в Android-приложениях было нелёгким делом. Это была серьезная инженерная задача — выяснить, как поддерживать низкое потребление траффика при постоянном подключении к Интернету. Большинство компаний сделали выбор в пользу постоянного сетевого взаимодействия, чтобы обеспечить наилучший UX. К сожалению, счета за мобильные телефоны большинства пользователей масштабировались в соответствии с количеством используемых данных, поэтому такой подход был более дорогостоящим для пользователей. Учитывая это, приложениям было важно найти способы свести к минимуму использование данных. Мы создали Store, чтобы частично решить эту проблему и облегчить инженерам задачу по минимизации использования данных.
Основным фактором, усугубляющим проблему использования больших объемов данных, были дублированные запросы на одни и те же данные. Общий пример…

Вот как оригинальная версия Store решила эту проблему:
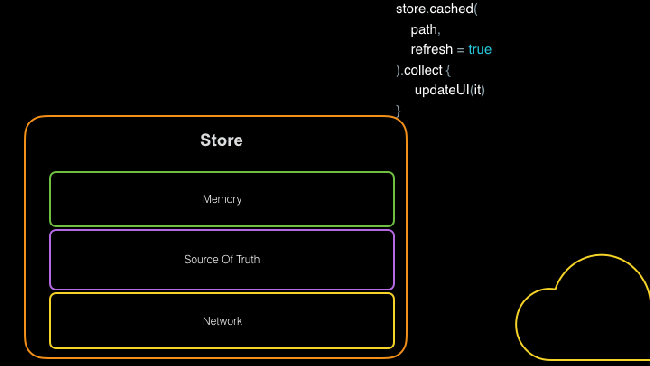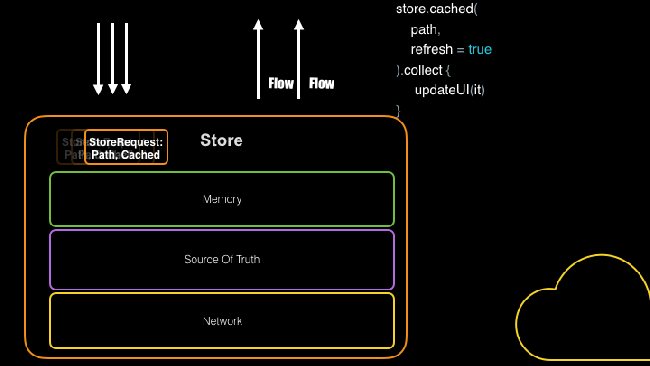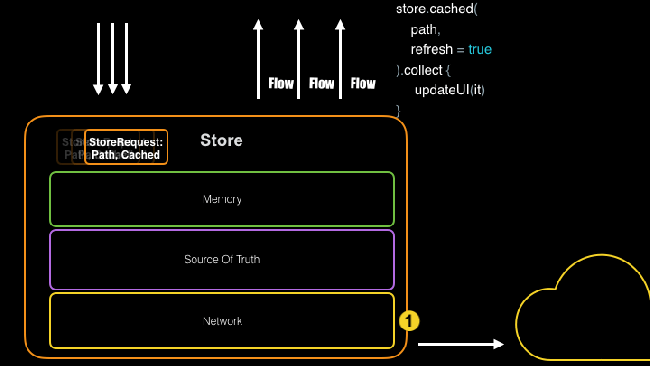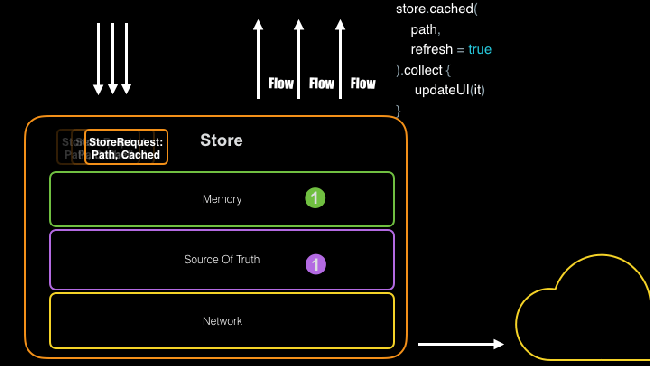
Передача данных при помощи Store
Как видно выше, абстракция репозитория, подобная Store, дает вам централизованное место для управления вашими запросами и ответами, позволяя вам выполнять групповую загрузку, а не выполнять одну и ту же работу многократно.
Перенесёмся на 4 года – мир Android изменился с головокружительной скоростью. Ранее мы работали с сетью и базами данных, которые возвращали скалярные значения. Теперь, с выходом Room и SQLDelight, приложения могут подписываться на изменения данных, которые им необходимы. Точно так же все большее распространение получают веб-сокеты, push-библиотеки, такие как Firebase, и другие «живые» сетевые источники. Изначально Store не был написан для того, чтобы обрабатывать эти новые наблюдаемые источники данных, но, учитывая их новую распространенность, мы решили, что пришло время для переписывания. После долгого сотрудничества и множества поздних ночей, мы рады представить четвертую версию Store: http://github.com/dropbox/Store.
Store 4 полностью написан на Котлине. Мы также заменили RxJava на новую стабильную, реактивную реализацию потоков Котлина под названием Flow.
Вы, наверное, спросите, зачем бросать такого лидера индустрии, как RxJava? Первым и самым важным является концепция структурного параллелизма. Структурный параллелизм означает определение объема или контекста, в котором будут выполняться фоновые операции до, а не после подачи запроса. Это важно, потому что способ обработки фоновых операций оказывает огромное влияние на предотвращение утечек памяти. Требование о том, чтобы объем работ был определен в начале фоновой работы, гарантирует, что когда эта работа будет завершена или больше не понадобится, ресурсы будут гарантированно очищены.
Структурный параллелизм — не единственный способ определить объем фоновой работы. RxJava по-разному решает одну и ту же задачу. Рассмотрим основной API RxJava для определения объема фоновых работ:
// Observable.java
@CheckReturnValue
public final Disposable subscribe(Consumer onNext) {}Обратите внимание, что в сигнатуре метода выше, RxJava Observable вернет Disposable в качестве обработчика подписки. У него есть функция dispose(), которая позволяет наблюдателям завершить получение данных. Между началом подписки и вызовом этого метода как раз и определяется объём фоновой работы. Недавно в RxJava2 добавили @CheckReturnValue— аннотацию о том, что вызов flowable.subscribe вернет значение, и пользователь должен сохранить его для последующей отмены. К сожалению, это только предупреждение линтера, которое не помешает компиляции. Считайте, что это предупреждение RxJava, предупреждающее об утечке.
Большая проблема RxJava при определении фоновых операций заключается в том, что программисту слишком легко забыть вызвать dispose(). Неспособность избавиться от активных подписок напрямую приводит к утечкам памяти. В отличие от RxJava, который позволяет сначала запустить наблюдаемую подписку, а затем напоминает об необходимости отмены, Kotlin Flow заставляет вас определить прямо при создании источника данных, когда наблюдаемые подписки должны быть утилизированы. Это происходит потому, что Flow реализован для обеспечения структурного параллелизма. Давайте рассмотрим Flow и то, как он предотвращает утечки.
suspend fun Flow.collect(...)Collect аналогичен подписке в RxJava, он берет потребителя, который вызывается при каждом излучении данных из Flow. В отличие от RxJava, функция collect() помечена ключевым словом "suspend". Это означает, что это приостанавливающая функция (типа async/await), которая может быть вызвана только внутри корутины. Это заставляет Flow.collect вызываться внутри корутины, гарантируя, что потоки будут иметь четко определенную область визимости.
Хотя это кажется небольшой отличительной особенностью, в мире Android (а это встраиваемая система с ограниченными ресурсами памяти) имеются лучшие контракты для асинхронной работы, которые напрямую приводят к уменьшению утечек памяти, повышению производительности и снижению риска сбоев. Теперь, благодаря структурному параллелизму из корутин Kotlin, мы можем использовать такие вещи, как viewModelScope в Jetpack, которое автоматически отменяет наш рабочий поток, когда модель представления очищается. Это чётко решает основную проблему, с которой сталкиваются все приложения Android: как определить, когда ресурсы из фоновых задач больше не нужны.
public fun CoroutineScope.launch(...)
viewModelScope.launch {
flow.collect{ handle(it) }
}Структурный параллелизм был основной причиной, по которой мы переключились на Flow. Нашей следующей важной причиной для перехода было стремление соответствовать направлению более широкого сообщества Android. Мы уже видели, что AndroidX любит Котлин и Корутины. Многие библиотеки, такие как ViewModel, уже поддерживают корутины, а в Room есть первоклассная поддержка Flow. Говорят даже о новых библиотеках, которые были преобразованы для использования корутин в качестве асинхронных примитивов (Paging). Для нас было важно переписать Store таким образом, чтобы он соответствовал экосистеме Android не только сегодня, но и на долгие годы вперед.
Наконец, хотя у нас нет текущих планов по использованию Store ни для чего, кроме Android, мы чувствуем, что в будущем, возможно, подключим Kotlin multi-platform, и мы хотели бы иметь как можно меньше зависимостей. RxJava не совместима с Kotlin native/js и тянет за собой более 6000 функций.
Что есть Store?
Store отвечает за управление определенным запросом данных. Когда вы создаете реализацию Store, вы предоставляете ему Fetcher, который является функцией, определяющей, как данные будут доставляться из сети. По желанию можно указать, как ваш Store будет кэшировать данные в памяти и на диске. Поскольку Store возвращает данные как Flow, потоковая передача данных — это просто! После создания Store обрабатывает логику получения/обмена/кэширования данных, позволяя вашим вьюхам использовать самые свежие источники данных и гарантируя, что данные всегда будут доступны для использования в автономном режиме.
Полная настройка Store
Давайте начнем с того, что посмотрим как выглядит полностью настроенный Store. Затем мы рассмотрим более простые примеры, показывающие каждую деталь:
StoreBuilder.fromNonFlow { api.fetchSubreddit(it, "10")}
.persister(
reader = db.postDao()::loadPosts,
writer = db.postDao()::insertPosts,
delete = db.postDao()::clearFeed)
.cachePolicy(MemoryPolicy)
.build()Этим билдером мы объявляем:
- Кэширование во внутренней памяти для обработки поворотов экрана
- Дисковый кэш, когда пользователь находится в автономном режиме
- Богатый API для запроса данных, которые вы можете кэшировать, обновлять или выводить в поток будущих обновлений данных.
Store дополнительно использует троттлинг дублирующих запросов для предотвращения чрезмерных вызовов в сеть и позволяет использовать дисковый кэш как основной источник. Реализация дискового кэша передается через функцию билдера persister() и может быть использована для непосредственной модификации данных на диске без прохождения через Store. Реализации основного источника лучше всего работают с базами данных, которые могут предоставлять Observable, такие как Jetpack Room, SQLDelight или Realm.
А теперь о деталях:
Создание Store?
Создаётся Store с помощью билдера. Единственным требованием является включение функции, возвращающей Flow, или функции приостановки, возвращающей ReturnType.
val store = StoreBuilder.from {
articleId -> api.getArticle(articleId) //Flow<Article>
}
.build()В качестве идентификатора данных в Store используются ключ, которым может быть любой объект, корректно реализующий функции toString(), equals() и hashCode(). Он будет передан в функцию Fetcher при ее вызове. Аналогично ключ будет использоваться в качестве первичного идентификатора в кэше. Для сложных ключей настоятельно рекомендуется использовать встроенные типы, реализующие equals() и hashcode() или data-классы Kotlin.
Публичный интерфейс: Stream?
Основным публичным API, предоставляемым экземпляром Store, является потоковая функция со следующей сигнатурой:
fun stream(request: StoreRequest<Key>):Flow<StoreResponse>Output>>Каждый потоковый вызов получает объект StoreRequest, который определяет, какой ключ извлечь и какие источники данных использовать. Ответ представляет собой поток StoreResponse. StoreResponse — это закрытый класс Kotlin, который может быть как экземпляром Loading, Data или Error. Каждое StoreResponse включает в себя поле ResponseOrigin, в котором указывается, откуда приходит событие.

- Класс
Loadingимеет только одно поле ResponseOrigin. Это может быть хорошим сигналом для активации загрузочного спиннера или прогрессбара в вашем пользовательском интерфейсе. - Класс
Dataимеет поле значений, которое включает в себя экземпляр типа, возвращаемого Store. - Класс
Errorвключает в себя поле ошибки, которое содержит исключение, брошенное данным ResponseOrigin.
При возникновении ошибки Store не бросает исключение, а оборачивает его в тип StoreResponse.Error, который позволяет Flow не прерывать поток и все равно получать обновления, которые могут быть вызваны как изменениями в источнике данных, так и последующими операциями по их извлечению. Это позволяет вам иметь по-настоящему реактивный пользовательский интерфейс, в котором ваша функция render/updateUI является приёмником для вашего потока без необходимости перезапускать поток после выброса ошибки. См. пример ниже:
lifecycleScope.launchWhenStarted {
store.stream(StoreRequest.cached(key = key, refresh=true)).collect { response ->
when(response) {
is StoreResponse.Loading -> showLoadingSpinner()
is StoreResponse.Data -> {
if (response.origin == ResponseOrigin.Fetcher) hideLoadingSpinner()
updateUI(response.value)
}
is StoreResponse.Error -> {
if (response.origin == ResponseOrigin.Fetcher) hideLoadingSpinner()
showError(response.error)
}
}
}
}Для удобства использования имеются функции расширения: Store.get(key), Store.stream(key) и Store.fresh(key).
suspend fun Store.get(key: Key): Value?— этот метод возвращает одно значение для данного ключа. Если доступно, то оно будет возвращено из кэша внутренней памяти или дискового кэша.suspend fun Store.fresh(key: Key): Value?— этот метод возвращает единственное значение для данного ключа, которое получается при запросе фетчера.suspend fun Store.stream(key: Key): Flow?— этот метод возвращает поток значений (Flow) для данного ключа.
Приведем пример использования функции get():
lifecycleScope.launchWhenStarted {
val article = store.get(key)
updateUI(article)
}Когда вы впервые вызываете store.get(key), сетевой ответ будет сначала сохранен в дисковом кэше (если это предусмотрено), а затем в кэше внутренней памяти. Все последующие вызовы store.get(key) с тем же ключом будут получать кэшированную версию данных, сводя к минимуму лишние вызовы. Это предотвратит получение данных из сети (или из другого внешнего источника данных) в ситуациях, когда это может привести к излишнему использованию полосы пропускания и батареи. Огромным преимуществом является то, что в любой момент, когда ваши вьюхи воссоздаются после поворота экрана, они смогут запросить кэшированные данные из вашего Store. Постоянное наличие этих данных в Store поможет вам избежать необходимости сохранять копии больших объектов на уровне представлений. В Store ваш пользовательский интерфейс должен только сохранять идентификаторы для использования в качестве ключей, когда вы определяете, возвращать значение из кэша или нет.
Пробираясь через кэш?
Также вы можете вызвать store.fresh(key) чтобы получить результат минуя память (и дополнительный дисковый кэш). Хорошим вариантом использования являются фоновые обновления, использующие fresh() чтобы убедиться, что store.get()/stream() не придется обращаться к сети во время обычного использования. Другой хороший вариант использования для fresh() это когда пользователь использует pull-to-refresh для обновления данных.
Вызов обоих методов fresh() и get() выдают одно значение или выбрасывают ошибку.
Stream?
Для получения обновлений в реальном времени, вы также можете вызвать store.stream(key), который создает поток, который испускается каждый раз, когда дисковый кэш выдаёт данные или когда происходят события загрузки/ошибки из сети. Вы можете думать о функции stream() как о способе создания реактивных потоков, которые обновляются при обновлении вашей базы данных или кэша в памяти.
lifecycleScope.launchWhenStarted {
store.stream(StoreRequest.cached(3, refresh = false))
.collect{ }
store.stream(StoreRequest.get(3)) //пропускаем кэш, вызываем фетчер напрямую
.collect{ }
Холодный старт и перезагрузка
Обработка множественных запросов на лету?
Чтобы предотвратить дублирование запросов на одни и те же данные, в Store имеется встроенный оптимизатор. Если будет сделан вызов, идентичный предыдущему запросу, который еще не завершен, то будет возвращен тот же ответ на исходный запрос. Это полезно в ситуациях, когда приложению необходимо выполнить множество асинхронных вызовов для одних и тех же данных при запуске или когда пользователи навязчиво тянут за обновлениями. В качестве примера можно асинхронно вызывать Store.get() из 12 различных мест при запуске. Первый вызов блокируется, в то время как все остальные ждут поступления данных. После внедрения этой логики мы наблюдали резкое снижение использования данных.
Дисковый кэш
?В Store можно включить дисковое кэширование, передав реализацию persister() в билдер. Всякий раз, когда делается новый сетевой запрос, Store сначала записывает в дисковый кэш, а затем читает из дискового кэша, чтобы выдать значение.
Диск как единый источник данных
?Предоставление persister(), чья функция чтения может вернуть Flow позволяет Store относиться к диску как к единому источнику данных. Любые изменения, сделанные на диске, даже если они не были сделаны посредством Store, обновят активные потоки Store.
Эта функция в сочетании с библиотеками хранения данных, которые предоставляют Observable (Jetpack Room, SQLDelight или Realm), позволяет создавать оффлайн приложения, которые можно использовать без активного сетевого подключения, обеспечивая при этом достойный UX.
StoreBuilder.fromNonFlow {api.fetchSubreddit(it, "10")}
.persister(
reader = db.postDao()::loadPosts,
writer = db.postDao()::insertPosts,
delete = db.postDao()::clearFeed)
.cachePolicy(MemoryPolicy)
.build()Store все равно, как вы будете хранить или извлекать данные с диска. В результате, вы можете использовать Store с объектным хранилищем или с любой базой данных (Realm, SQLite, Firebase и т.д.). При использовании SQLite мы рекомендуем работать с Room, разработанным нашими друзьями из команды Jetpack.
Вышеуказанный конструктор и потоковое API Store — это наши рекомендации по тому, как современные приложения должны работать с данными. Полностью сконфигурированное хранилище предоставит вам следующие возможности:
- Кэширование в памяти с политиками времени жизни и размера данных
- Дисковое кэширование, включая простую интеграцию с Room
- Групповая передача ответов на идентичные запросы
- Возможность получить кэшированные данные (
StoreRequest) - Возможность получения новых данных из сети (
stream) - Структурный параллелизм через API, построенный на базе корутин и Kotlin.
Завершение
Надеемся, вам понравилось узнать о Store. Мы не можем дождаться, чтобы услышать обо всех замечательных вещах, которые создаст сообщество Android, и приветствуем любые отзывы. Если вы хотите быть еще более вовлеченными, мы в настоящее время нанимаем мобильных инженеров всех уровней в наших офисах в Нью-Йорке, Сан-Франциско и Сиэттле. Приходите и помогите нам продолжать создавать отличные продукты, как для наших пользователей, так и для сообщества разработчиков.
Эта информация была представлена на KotlinConf:
Библиотеку Store можно найти здесь: github.com/dropbox/Store
Части этой страницы являются модификациями, основанными на работе, созданной и распространяемой Android Open Source Project, и используемой в соответствии с терминами, описанными в Creative Commons 2.5 Attribution License
demonit
гифки с не читаемыми текстами просто режут глаз