
Привет, Хабр!
В данной статье мы бы хотели поговорить про автоматизацию сетевой инфраструктуры. Будет представлена рабочая схема сети, которая функционирует в одной маленькой, но очень гордой компании. Все совпадения с реальным сетевым оборудованием являются случайными. Мы рассмотрим кейс, произошедший в данной сети, которой мог привести к остановке бизнеса на продолжительное время и серьезным денежным потерям. Решение данного кейса очень хорошо вписывается в концепцию «Автоматизация сетевой инфраструктуры». С помощью средств автоматизации мы покажем, как можно эффективно решать сложные задачи в сжатые сроки, и поразмышляем на тему, почему перспективнее эти задачи надо решать именно так, а не иначе(через консоль).
Disclaimer
Основными инструментами для автоматизации у нас являются Ansible (как средство автоматизации) и Git (как хранилище playbook-ов Ansible). Сразу хочется оговориться, что это не ознакомительная статья, где мы говорим про логику работы Ansible или Git, и объясняем базовые вещи (например, что такое роли\таски\модули\инвентаризационные файлы\переменные в Ansible, или что происходит при введении команд git push или git commit). Это история не про то, как можно поупражняться в Ansible, настроить на оборудовании NTP или SMTP. Это история про то, как можно быстро и желательно без ошибок решать сетевую проблему. Также желательно иметь хорошее представление о том, как работает сеть, в частности, что такое стек протоколов TCP/IP, OSPF, BGP. Выбор Ansible и Git тоже вынесем за скобки. Если для вас еще стоит выбор конкретного решения, то очень рекомендуем прочитать книжку «Network Programmability and Automation. Skills for the Next-Generation Network Engineer» by Jason Edelman, Scott S. Lowe, and Matt Oswalt.
Теперь к делу.
Представим ситуацию: 3 часа ночи, вы крепко спите и видите сны. Звонок на телефон. Звонит технический директор:
— Да?
— ###, ####, #####, кластер межсетевых экранов упал и не поднимается!!!
Вы протираете глаза, пытаетесь осознать происходящее и представить, как такое вообще могло произойти. В трубке слышно, как рвутся волосы на голове директора, и он просит перезвонить, потому что по второй линии ему звонит генеральный.
Спустя полчаса вы собрали первые вводные от дежурной смены, разбудили всех, кого можно было разбудить. В итоге технический директор не соврал, все так и есть, основной кластер межсетевых экранов упал, и никакие базовые телодвижения не приводят его в чувства. Все сервисы, которые предлагает компания, не работают.
Выберите проблему на ваш вкус, каждый вспомнит что-то свое. Например, после ночного обновления в отсутствие большой нагрузки все работало хорошо, и все довольные поехали спать. Пошел трафик, и стали переполняться буферы интерфейсов из-за бага в драйвере сетевой карты.
Ситуацию хорошо может описать Джеки Чан.

Спасибо, Джеки.
Не очень приятна ситуация, не правда ли?
Оставим на время нашего сетевого бро с его грустными мыслями.
Обсудим, как будут развиваться события дальше.
Предлагаем следующий порядок изложения материала

Рассмотрим логическую схему нашей организации. Мы не будем называть конкретных производителей оборудования, в рамках статьи это не имеет значения (Внимательный читатель сам догадается, что за оборудование используется). Это как раз один из хороших плюсов работы с Ansible, при настройке нам в целом все равно, что это за оборудование. Просто для понимания, это оборудование известных вендоров, типа Cisco, Juniper, Check Point, Fortinet, Palo Alto …можете подставить свой вариант.
У нас есть две основные задачи по перемещению трафика:
Начнем с основных элементов:
В сети настроен динамический протокол маршрутизации OSPF со следующими area-ми:
На пограничных маршрутизаторах создано по виртуальному маршрутизатору (VRF-INTERNET), на которых поднят eBGP full view с соответствующим присвоенным AS. Между VRF-ами настроен iBGP. У компании есть пул белых адресов, которые опубликованы на этих VRF-INTERNET. Часть белых адресов маршрутизируется напрямую на FW-CLUSTER (адреса, на которых работают сервисы компании), часть маршрутизируется через зону EXCHANGE (внутренние сервисы компании, требующие внешних ip-адресов, и внешние адреса NAT для офисов). Далее трафик попадает на виртуальные роутеры, созданные на L3-CORE с белыми и серыми адресами (зоны безопасности).
В Management-сети используются выделенные коммутаторы и представляют собой физически выделенную сеть. Management сеть также поделена на зоны безопасности.
Маршрутизатор EMERGENCY физически и логически дублирует FW-CLUSTER. На нем отключены все интерфейсы кроме тех, которые смотрят в management-сеть.
Мы разобрались, как работает сеть. Теперь разберем по шагам, что же мы будем делать, чтобы перебросить трафик с FW-CLUSTER на EMERGENCY:
Опять же возвращаемся к изначальной постановке задачи. Три часа ночи, огромный стресс, ошибка на любом из этапов может привести к новым проблемам. Готовы набирать команды через CLI? Да? Ок, идите хотя бы сполосните лицо, кофе выпейте и соберите волю в кулак.
Брюс, помоги, пожалуйста, ребятам.

Ну а мы продолжаем пилить нашу автоматизацию.
Ниже представлена схема работы playbook-а в терминах Ansible. Это схема отражает то, что мы описали чуть выше, просто уже конкретная реализация в Ansible.
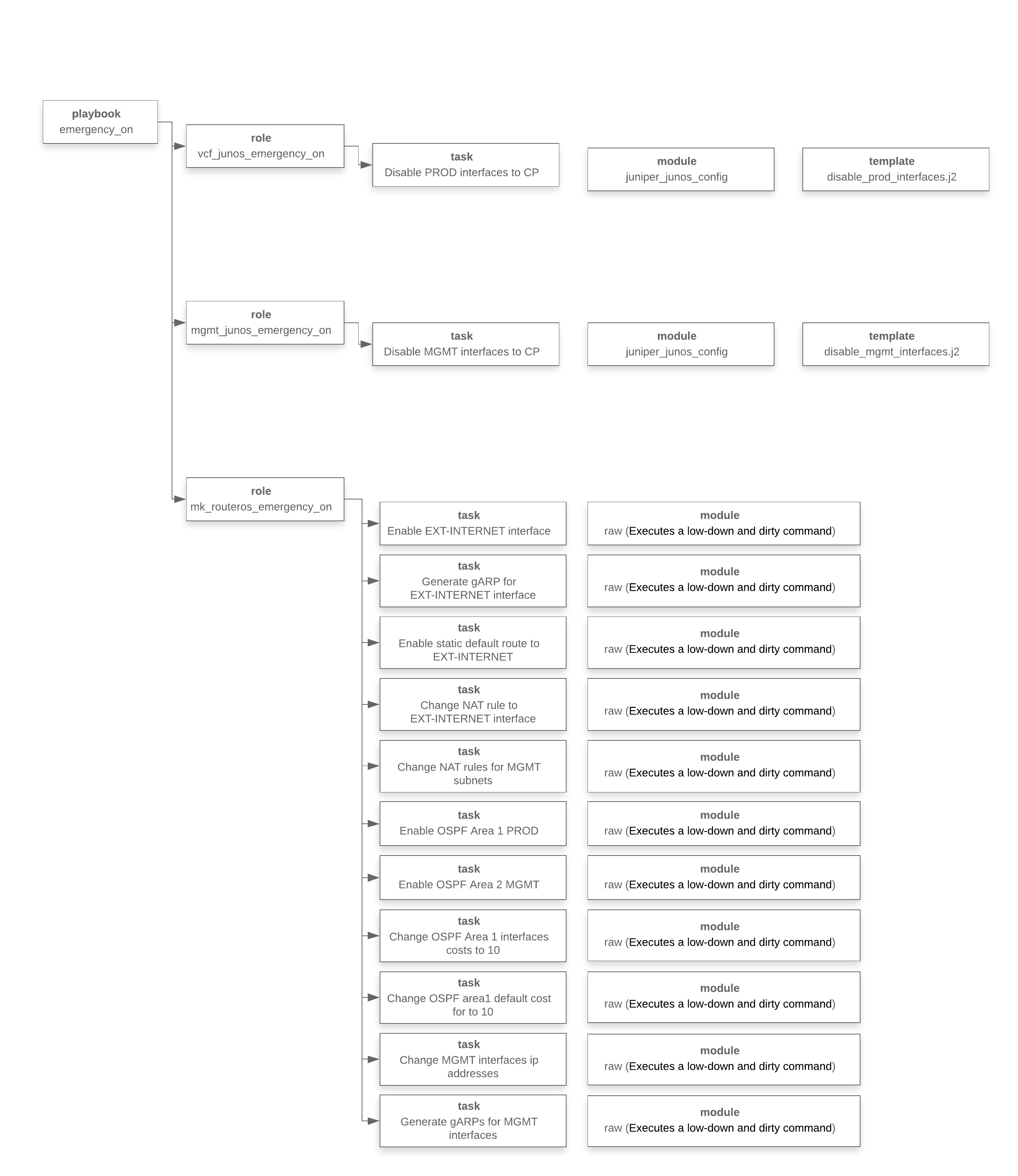
На данном этапе мы осознали, что надо сделать, разработали playbook, провели тестирование, теперь мы готовы его запустить.
Еще одно небольшое лирическое отступление. Легкость повествования не должна вводить вас в заблуждение. Процесс написания playbook-ов не был простыми и быстрым, как может показаться. Тестирование заняло довольно много времени, был создан виртуальный стенд, решение многократно обкатывалось, было проведено порядка 100 тестов.
Запускаем… Есть ощущение, что все происходит очень медленно, где-то есть ошибка, что-то в итоге не заработает. Ощущение прыжка с парашютом, а парашют что-то сразу не хочет открываться…это нормально.
Далее читаем результат выполненных операций playbook-а Ansible (ip-адреса в целях конспирации заменили ):
Готово!
На самом деле, не совсем готово, не забываем про сходимость динамических протоколов маршрутизации и загрузку большого количества маршрутов в FIB. На это мы повлиять никак не можем. Ждем. Сошлось. Вот теперь готово.
А в деревне Вилабаджо (которая не хочет автоматизировать настройку сети) продолжают мыть посуду. Брюс (правда, уже другой, но не менее крутой) пытается понять сколько еще вручную перенастраивать оборудование.

Хотелось бы еще остановиться на одном важном моменте. Как нам все вернуть назад? Спустя какое-то время, мы вернем к жизни наш FW-CLUSTER. Это основное оборудование, а не резервное, на нем должна работать сеть.
Чувствуете, как начинает подгорать у сетевиков? Технический директор услышит тысячу аргументов, почему этого делать не надо, почему это можно сделать потом. К сожалению, так и складывается работа сети из кучи заплаток, кусков, остатков былой роскоши. Получается лоскутное одеяло. Наша задача в целом, не в данной конкретной ситуации, а вообще в принципе, как ИТ-специалистов — привести работу сети к красивому английскому слову «consistency», оно очень многогранное, можно перевести как: согласованность, непротиворечивость, логичность, слаженность, системность, сопоставимость, связность. Это все про него. Только в таком состоянии сеть является управляемой, мы четко понимаем, что и как работает, мы четко осознаем, что нужно изменить, в случае необходимости, мы четко знаем куда посмотреть, в случае возникновения проблем. И только в такой сети можно проделывать фокусы, подобные тем, что мы сейчас описали.
Собственно, был подготовлен еще один playbook, который возвращал настройки в исходное состояние. Логика его работы такая же (важно помнить, порядок тасков очень важен), чтобы не удлинять и так довольно длинную статью, мы решили не выкладывать листинг выполнения playbook-а. Проведя такие учения, вы почувствуете себя намного спокойнее и увереннее в будущем, кроме того, любые костыли, которые вы там нагородили, сразу себя обнаружат.
Все желающие могут написать нам и получить исходники всего написанного кода, вместе со всеми palybook-ами. Контакты в профиле.
На наш взгляд, процессы, которые можно автоматизировать, еще не выкристаллизовались. Исходя из того, с чем мы сталкивались, и того, что обсуждают наши западные коллеги, пока видны следующие темы:
Если будет интерес, мы сможем продолжить обсуждение на одну из заданных тем.
Еще хочется немного порассуждать на тему автоматизации. Какой она должна быть в нашем понимании:
И к чему эти пункты должны привести:
Авторы статьи: Александр Человеков (CCIE RS, CCIE SP) и Павел Кириллов. Нам интересно обсуждать и предлагать решения на тему Автоматизация ИТ-инфраструктуры.
В данной статье мы бы хотели поговорить про автоматизацию сетевой инфраструктуры. Будет представлена рабочая схема сети, которая функционирует в одной маленькой, но очень гордой компании. Все совпадения с реальным сетевым оборудованием являются случайными. Мы рассмотрим кейс, произошедший в данной сети, которой мог привести к остановке бизнеса на продолжительное время и серьезным денежным потерям. Решение данного кейса очень хорошо вписывается в концепцию «Автоматизация сетевой инфраструктуры». С помощью средств автоматизации мы покажем, как можно эффективно решать сложные задачи в сжатые сроки, и поразмышляем на тему, почему перспективнее эти задачи надо решать именно так, а не иначе
Disclaimer
Основными инструментами для автоматизации у нас являются Ansible (как средство автоматизации) и Git (как хранилище playbook-ов Ansible). Сразу хочется оговориться, что это не ознакомительная статья, где мы говорим про логику работы Ansible или Git, и объясняем базовые вещи (например, что такое роли\таски\модули\инвентаризационные файлы\переменные в Ansible, или что происходит при введении команд git push или git commit). Это история не про то, как можно поупражняться в Ansible, настроить на оборудовании NTP или SMTP. Это история про то, как можно быстро и желательно без ошибок решать сетевую проблему. Также желательно иметь хорошее представление о том, как работает сеть, в частности, что такое стек протоколов TCP/IP, OSPF, BGP. Выбор Ansible и Git тоже вынесем за скобки. Если для вас еще стоит выбор конкретного решения, то очень рекомендуем прочитать книжку «Network Programmability and Automation. Skills for the Next-Generation Network Engineer» by Jason Edelman, Scott S. Lowe, and Matt Oswalt.
Теперь к делу.
Постановка задачи
Представим ситуацию: 3 часа ночи, вы крепко спите и видите сны. Звонок на телефон. Звонит технический директор:
— Да?
— ###, ####, #####, кластер межсетевых экранов упал и не поднимается!!!
Вы протираете глаза, пытаетесь осознать происходящее и представить, как такое вообще могло произойти. В трубке слышно, как рвутся волосы на голове директора, и он просит перезвонить, потому что по второй линии ему звонит генеральный.
Спустя полчаса вы собрали первые вводные от дежурной смены, разбудили всех, кого можно было разбудить. В итоге технический директор не соврал, все так и есть, основной кластер межсетевых экранов упал, и никакие базовые телодвижения не приводят его в чувства. Все сервисы, которые предлагает компания, не работают.
Выберите проблему на ваш вкус, каждый вспомнит что-то свое. Например, после ночного обновления в отсутствие большой нагрузки все работало хорошо, и все довольные поехали спать. Пошел трафик, и стали переполняться буферы интерфейсов из-за бага в драйвере сетевой карты.
Ситуацию хорошо может описать Джеки Чан.
Спасибо, Джеки.
Не очень приятна ситуация, не правда ли?
Оставим на время нашего сетевого бро с его грустными мыслями.
Обсудим, как будут развиваться события дальше.
Предлагаем следующий порядок изложения материала
- Рассмотрим схему сети и разберем как она работает;
- Опишем как мы переносим настройки с одного роутера на другой с помощью Ansible;
- Поговорим про автоматизацию ИТ-инфраструктуры в целом.
Схема сети и ее описание
Схема
Рассмотрим логическую схему нашей организации. Мы не будем называть конкретных производителей оборудования, в рамках статьи это не имеет значения (Внимательный читатель сам догадается, что за оборудование используется). Это как раз один из хороших плюсов работы с Ansible, при настройке нам в целом все равно, что это за оборудование. Просто для понимания, это оборудование известных вендоров, типа Cisco, Juniper, Check Point, Fortinet, Palo Alto …можете подставить свой вариант.
У нас есть две основные задачи по перемещению трафика:
- Обеспечить публикацию наших сервисов, которые являются бизнесом компании;
- Обеспечить связь с филиалами, удаленным ЦОДом и сторонними организациями (партнерами и клиентами), а также выход филиалов в интернет через центральный офис.
Начнем с основных элементов:
- Два пограничных маршрутизатора (BRD-01, BRD-02);
- Кластер межсетевых экранов (FW-CLUSTER);
- Коммутатор ядра (L3-CORE);
- Роутер, который станет спасательным кругом (по ходу решения проблемы мы перенесем сетевые настройки с FW-CLUSTER на EMERGENCY) (EMERGENCY);
- Коммутаторы для управления сетевой инфраструктурой (L2-MGMT);
- Виртуальная машина с Git и Ansible (VM-AUTOMATION);
- Ноутбук, на котором производится тестирование и разработка playbook-ов для Ansible (Laptop-Automation).
В сети настроен динамический протокол маршрутизации OSPF со следующими area-ми:
- Area 0 – область, в которую включены роутеры, отвечающие за перемещение трафика в зоне EXCHANGE;
- Area 1 – область, в которую включены роутеры, отвечающие за работу сервисов компании;
- Area 2 – область, в которую включены роутеры, отвечающие за маршрутизацию management-трафика;
- Area N – области филиальных сетей.
На пограничных маршрутизаторах создано по виртуальному маршрутизатору (VRF-INTERNET), на которых поднят eBGP full view с соответствующим присвоенным AS. Между VRF-ами настроен iBGP. У компании есть пул белых адресов, которые опубликованы на этих VRF-INTERNET. Часть белых адресов маршрутизируется напрямую на FW-CLUSTER (адреса, на которых работают сервисы компании), часть маршрутизируется через зону EXCHANGE (внутренние сервисы компании, требующие внешних ip-адресов, и внешние адреса NAT для офисов). Далее трафик попадает на виртуальные роутеры, созданные на L3-CORE с белыми и серыми адресами (зоны безопасности).
В Management-сети используются выделенные коммутаторы и представляют собой физически выделенную сеть. Management сеть также поделена на зоны безопасности.
Маршрутизатор EMERGENCY физически и логически дублирует FW-CLUSTER. На нем отключены все интерфейсы кроме тех, которые смотрят в management-сеть.
Автоматизация и ее описание
Мы разобрались, как работает сеть. Теперь разберем по шагам, что же мы будем делать, чтобы перебросить трафик с FW-CLUSTER на EMERGENCY:
- Отключаем интерфейсы на коммутаторе ядра (L3-CORE), которые связывают его с FW-CLUSTER;
- Отключаем интерфейсы на коммутаторе ядра L2-MGMT, которые связывают его с FW-CLUSTER;
- Настраиваем маршутизатор EMERGENCY (по умолчанию на нем выключены все интерфейсы, кроме тех, которые связаны с L2-MGMT):
- Включаем интерфейсы на EMERGENCY;
- Настраиваем внешний ip-адрес (для NAT), который был на FW-Cluster;
- Генерируем gARP запросы, чтобы в arp-таблицах L3-CORE поменялись мак-адреса с FW-Cluster на EMERGENCY;
- Прописываем маршрут по умолчанию статикой до BRD-01, BRD-02;
- Создаем правила NAT;
- Поднимаем на EMERGENCY OSPF Area 1;
- Поднимаем на EMERGENCY OSPF Area 2;
- Меняем стоимость маршрутов в Area 1 на 10;
- Меняем стоимость дефолтного маршрута в Area 1 на 10;
- Меняем ip-адреса, связанные с L2-MGMT (на те, которые были на FW-CLUSTER);
- Генерируем gARP запросы, чтобы в arp-таблицах L2-MGMT поменялись мак-адреса с FW-CLUSTER на EMERGENCY.
Опять же возвращаемся к изначальной постановке задачи. Три часа ночи, огромный стресс, ошибка на любом из этапов может привести к новым проблемам. Готовы набирать команды через CLI? Да? Ок, идите хотя бы сполосните лицо, кофе выпейте и соберите волю в кулак.
Брюс, помоги, пожалуйста, ребятам.
Ну а мы продолжаем пилить нашу автоматизацию.
Ниже представлена схема работы playbook-а в терминах Ansible. Это схема отражает то, что мы описали чуть выше, просто уже конкретная реализация в Ansible.
На данном этапе мы осознали, что надо сделать, разработали playbook, провели тестирование, теперь мы готовы его запустить.
Еще одно небольшое лирическое отступление. Легкость повествования не должна вводить вас в заблуждение. Процесс написания playbook-ов не был простыми и быстрым, как может показаться. Тестирование заняло довольно много времени, был создан виртуальный стенд, решение многократно обкатывалось, было проведено порядка 100 тестов.
Запускаем… Есть ощущение, что все происходит очень медленно, где-то есть ошибка, что-то в итоге не заработает. Ощущение прыжка с парашютом, а парашют что-то сразу не хочет открываться…это нормально.
Далее читаем результат выполненных операций playbook-а Ansible (ip-адреса в целях конспирации заменили ):
[xxx@emergency ansible]$ ansible-playbook -i /etc/ansible/inventories/prod_inventory.ini /etc/ansible/playbooks/emergency_on.yml
PLAY [------->Emergency on VCF] ********************************************************
TASK [vcf_junos_emergency_on : Disable PROD interfaces to FW-CLUSTER] *********************
changed: [vcf]
PLAY [------->Emergency on MGMT-CORE] ************************************************
TASK [mgmt_junos_emergency_on : Disable MGMT interfaces to FW-CLUSTER] ******************
changed: [m9-03-sw-03-mgmt-core]
PLAY [------->Emergency on] ****************************************************
TASK [mk_routeros_emergency_on : Enable EXT-INTERNET interface] **************************
changed: [m9-04-r-04]
TASK [mk_routeros_emergency_on : Generate gARP for EXT-INTERNET interface] ****************
changed: [m9-04-r-04]
TASK [mk_routeros_emergency_on : Enable static default route to EXT-INTERNET] ****************
changed: [m9-04-r-04]
TASK [mk_routeros_emergency_on : Change NAT rule to EXT-INTERNET interface] ****************
changed: [m9-04-r-04] => (item=12)
changed: [m9-04-r-04] => (item=14)
changed: [m9-04-r-04] => (item=15)
changed: [m9-04-r-04] => (item=16)
changed: [m9-04-r-04] => (item=17)
TASK [mk_routeros_emergency_on : Enable OSPF Area 1 PROD] ******************************
changed: [m9-04-r-04]
TASK [mk_routeros_emergency_on : Enable OSPF Area 2 MGMT] *****************************
changed: [m9-04-r-04]
TASK [mk_routeros_emergency_on : Change OSPF Area 1 interfaces costs to 10] *****************
changed: [m9-04-r-04] => (item=VLAN-1001)
changed: [m9-04-r-04] => (item=VLAN-1002)
changed: [m9-04-r-04] => (item=VLAN-1003)
changed: [m9-04-r-04] => (item=VLAN-1004)
changed: [m9-04-r-04] => (item=VLAN-1005)
changed: [m9-04-r-04] => (item=VLAN-1006)
changed: [m9-04-r-04] => (item=VLAN-1007)
changed: [m9-04-r-04] => (item=VLAN-1008)
changed: [m9-04-r-04] => (item=VLAN-1009)
changed: [m9-04-r-04] => (item=VLAN-1010)
changed: [m9-04-r-04] => (item=VLAN-1011)
changed: [m9-04-r-04] => (item=VLAN-1012)
changed: [m9-04-r-04] => (item=VLAN-1013)
changed: [m9-04-r-04] => (item=VLAN-1100)
TASK [mk_routeros_emergency_on : Change OSPF area1 default cost for to 10] ******************
changed: [m9-04-r-04]
TASK [mk_routeros_emergency_on : Change MGMT interfaces ip addresses] ********************
changed: [m9-04-r-04] => (item={u'ip': u'х.х.n.254', u'name': u'VLAN-803'})
changed: [m9-04-r-04] => (item={u'ip': u'х.х.n+1.254', u'name': u'VLAN-805'})
changed: [m9-04-r-04] => (item={u'ip': u'х.х.n+2.254', u'name': u'VLAN-807'})
changed: [m9-04-r-04] => (item={u'ip': u'х.х.n+3.254', u'name': u'VLAN-809'})
changed: [m9-04-r-04] => (item={u'ip': u'х.х.n+4.254', u'name': u'VLAN-820'})
changed: [m9-04-r-04] => (item={u'ip': u'х.х.n+5.254', u'name': u'VLAN-822'})
changed: [m9-04-r-04] => (item={u'ip': u'х.х.n+6.254', u'name': u'VLAN-823'})
changed: [m9-04-r-04] => (item={u'ip': u'х.х.n+7.254', u'name': u'VLAN-824'})
changed: [m9-04-r-04] => (item={u'ip': u'х.х.n+8.254', u'name': u'VLAN-850'})
changed: [m9-04-r-04] => (item={u'ip': u'х.х.n+9.254', u'name': u'VLAN-851'})
changed: [m9-04-r-04] => (item={u'ip': u'х.х.n+10.254', u'name': u'VLAN-852'})
changed: [m9-04-r-04] => (item={u'ip': u'х.х.n+11.254', u'name': u'VLAN-853'})
changed: [m9-04-r-04] => (item={u'ip': u'х.х.n+12.254', u'name': u'VLAN-870'})
changed: [m9-04-r-04] => (item={u'ip': u'х.х.n+13.254', u'name': u'VLAN-898'})
changed: [m9-04-r-04] => (item={u'ip': u'х.х.n+14.254', u'name': u'VLAN-899'})
TASK [mk_routeros_emergency_on : Generate gARPs for MGMT interfaces] *********************
changed: [m9-04-r-04] => (item={u'ip': u'х.х.n.254', u'name': u'VLAN-803'})
changed: [m9-04-r-04] => (item={u'ip': u'х.х.n+1.254', u'name': u'VLAN-805'})
changed: [m9-04-r-04] => (item={u'ip': u'х.х.n+2.254', u'name': u'VLAN-807'})
changed: [m9-04-r-04] => (item={u'ip': u'х.х.n+3.254', u'name': u'VLAN-809'})
changed: [m9-04-r-04] => (item={u'ip': u'х.х.n+4.254', u'name': u'VLAN-820'})
changed: [m9-04-r-04] => (item={u'ip': u'х.х.n+5.254', u'name': u'VLAN-822'})
changed: [m9-04-r-04] => (item={u'ip': u'х.х.n+6.254', u'name': u'VLAN-823'})
changed: [m9-04-r-04] => (item={u'ip': u'х.х.n+7.254', u'name': u'VLAN-824'})
changed: [m9-04-r-04] => (item={u'ip': u'х.х.n+8.254', u'name': u'VLAN-850'})
changed: [m9-04-r-04] => (item={u'ip': u'х.х.n+9.254', u'name': u'VLAN-851'})
changed: [m9-04-r-04] => (item={u'ip': u'х.х.n+10.254', u'name': u'VLAN-852'})
changed: [m9-04-r-04] => (item={u'ip': u'х.х.n+11.254', u'name': u'VLAN-853'})
changed: [m9-04-r-04] => (item={u'ip': u'х.х.n+12.254', u'name': u'VLAN-870'})
changed: [m9-04-r-04] => (item={u'ip': u'х.х.n+13.254', u'name': u'VLAN-898'})
changed: [m9-04-r-04] => (item={u'ip': u'х.х.n+14.254', u'name': u'VLAN-899'})
PLAY RECAP ************************************************************************Готово!
На самом деле, не совсем готово, не забываем про сходимость динамических протоколов маршрутизации и загрузку большого количества маршрутов в FIB. На это мы повлиять никак не можем. Ждем. Сошлось. Вот теперь готово.
А в деревне Вилабаджо (которая не хочет автоматизировать настройку сети) продолжают мыть посуду. Брюс (правда, уже другой, но не менее крутой) пытается понять сколько еще вручную перенастраивать оборудование.
Хотелось бы еще остановиться на одном важном моменте. Как нам все вернуть назад? Спустя какое-то время, мы вернем к жизни наш FW-CLUSTER. Это основное оборудование, а не резервное, на нем должна работать сеть.
Чувствуете, как начинает подгорать у сетевиков? Технический директор услышит тысячу аргументов, почему этого делать не надо, почему это можно сделать потом. К сожалению, так и складывается работа сети из кучи заплаток, кусков, остатков былой роскоши. Получается лоскутное одеяло. Наша задача в целом, не в данной конкретной ситуации, а вообще в принципе, как ИТ-специалистов — привести работу сети к красивому английскому слову «consistency», оно очень многогранное, можно перевести как: согласованность, непротиворечивость, логичность, слаженность, системность, сопоставимость, связность. Это все про него. Только в таком состоянии сеть является управляемой, мы четко понимаем, что и как работает, мы четко осознаем, что нужно изменить, в случае необходимости, мы четко знаем куда посмотреть, в случае возникновения проблем. И только в такой сети можно проделывать фокусы, подобные тем, что мы сейчас описали.
Собственно, был подготовлен еще один playbook, который возвращал настройки в исходное состояние. Логика его работы такая же (важно помнить, порядок тасков очень важен), чтобы не удлинять и так довольно длинную статью, мы решили не выкладывать листинг выполнения playbook-а. Проведя такие учения, вы почувствуете себя намного спокойнее и увереннее в будущем, кроме того, любые костыли, которые вы там нагородили, сразу себя обнаружат.
Все желающие могут написать нам и получить исходники всего написанного кода, вместе со всеми palybook-ами. Контакты в профиле.
Выводы
На наш взгляд, процессы, которые можно автоматизировать, еще не выкристаллизовались. Исходя из того, с чем мы сталкивались, и того, что обсуждают наши западные коллеги, пока видны следующие темы:
- Device provisioning;
- Data collection;
- Reporting;
- Troubleshooting;
- Compliance.
Если будет интерес, мы сможем продолжить обсуждение на одну из заданных тем.
Еще хочется немного порассуждать на тему автоматизации. Какой она должна быть в нашем понимании:
- Система должна жить без человека, при этом улучшаться человеком. Система не должна зависеть от человека;
- Эксплуатация должна быть экспертной. Отсутствует класс специалистов, которые выполняют рутинные задачи. Есть эксперты, которые всю рутину автоматизировали, и решают только сложные задачи;
- Рутинные\стандартные задачи делаются автоматически «по кнопке», не тратятся ресурсы. Результат таких задач всегда предсказуем и понятен.
И к чему эти пункты должны привести:
- Прозрачность ИТ-инфраструктуры (Меньше риски эксплуатации, модернизации, внедрения. Меньше downtime в год);
- Возможность планировать ИТ-ресурсы (Capacity-planning system — видно сколько потребляется, видно сколько требуется ресурсов в единой системе, а не по письмам и хождениям к топам отделов);
- Возможность сократить количество обслуживающего ИТ-персонала.
Авторы статьи: Александр Человеков (CCIE RS, CCIE SP) и Павел Кириллов. Нам интересно обсуждать и предлагать решения на тему Автоматизация ИТ-инфраструктуры.

igorbezr
Спасибо за ваш труд, коллеги!
Из любопытсва хочется поинтересоваться: а вариант написания собственной утилиты для мониторинга/управления зоопарком устройств не расматривался?
По моему скромному опыту, NETCONF очень выручает, особенно если имеется оборудование малоизвестных вендоров, для которого нет готовых модулей Ansible. Но которое хотя бы минимальным образом поддерживает RFC 6241.
При этом можно написать своего рода «единый API» для единообразной работы со всем железом. Например, условный «get_osfp_neighbors» который может отличаться нюансами реализации для разных устройств.
pavel_kirillov Автор
Спасибо за комментарий!
NETCONF — это уже следующий уровень зрелости, как нам видится. Если ansible — это первый этап, если так можно выразиться (пусть меня поправят) — template-based automation, то netconf — это уже более программистский подход, model-driven. Здесь YANG, XML, модели данных. Сама идея структурированного, программисткого подхода к сети требует серьезной команды, но к этому все должно прийти в итоге. Идея единообразного api на базе netconf/yang — это громко, амбициозно и заслуживает отдельной беседы